目錄
一、各階段的架構簡介
二、各個架構的詳細解釋
1. 傳統離線架構
2.1. Lambda架構-離線數倉分析+實時鏈路分析
2.2. Lambda架構-離線數倉+實時數倉
3. Kappa/流批一體架構
4. 湖倉一體架構
三、總結
一、各階段的架構簡介
| 技術架構 | 核心驅動(核心需求) | ?關鍵技術 | 特點 | |
| 傳統離線架構 | 海量存儲需求 | Hadoop生態 | 1.僅支持離線數據分析 | |
| Lambda架構 | 離線數倉分析 +實時鏈路分析 | 實時分析需求 | 批流雙引擎 | 1.支持離線、實時數據分析 |
| 離線數倉 +實時數倉 | 1.支持離線、實時數據分析 | |||
| Kappa/流批一體架構 | 開發效率與一致性 | Flink/Spark 統一API | 1.以實時數據分析為主,適用于離線分析少的場景 | |
| 湖倉一體架構 | 存儲治理與靈活性平衡 | Delta Lake /Iceberg | 1.存儲中的小文件問題 | |
二、各個架構的詳細解釋
1. 傳統離線架構

核心特點?
1. 批處理主導?
數據通過周期性ETL(如每日全量同步)導入HDFS等分布式存儲,計算依賴MapReduce、Hive等離線引擎。
2. 高存儲性價比?
基于HDFS的廉價存儲適合PB級歷史數據,但時效性僅為T+1。
技術棧?
Hadoop生態(HDFS/Hive)為主,結合關系型數據庫作數據源。
2.1. Lambda架構-離線數倉分析+實時鏈路分析
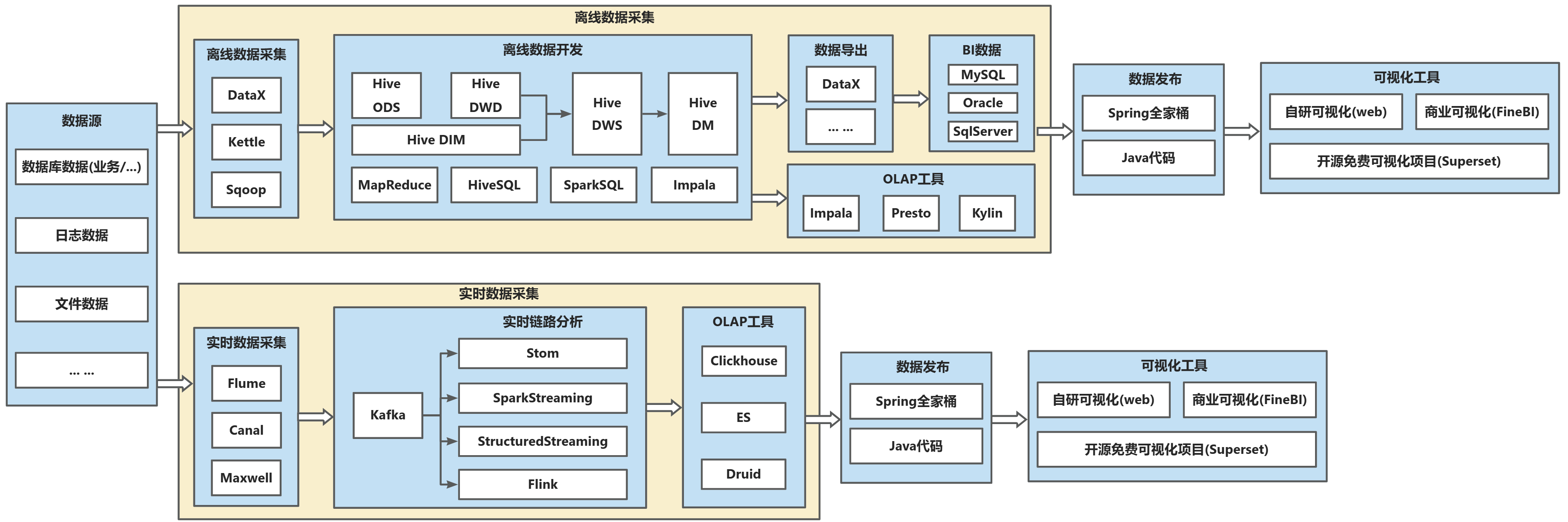
核心特點
1.支持離線、實時兩種數據分析
離線數據、實時數據各有一套處理邏輯,能夠對關鍵性指標進行實時數據分析處理。
2.實時數據分析不分層,數據無法復用
實時分析中僅僅是通過Kafka分發消息后通過Flink進行流處理,沒有分層的結構,導致每個需求都要單獨開發,數據幾乎無法復用。
技術棧?
Hadoop生態(HDFS/Hive)+ 實時相關生態技術(Kafka + Flink + Sparkstreaming ... ...)。
2.2. Lambda架構-離線數倉+實時數倉
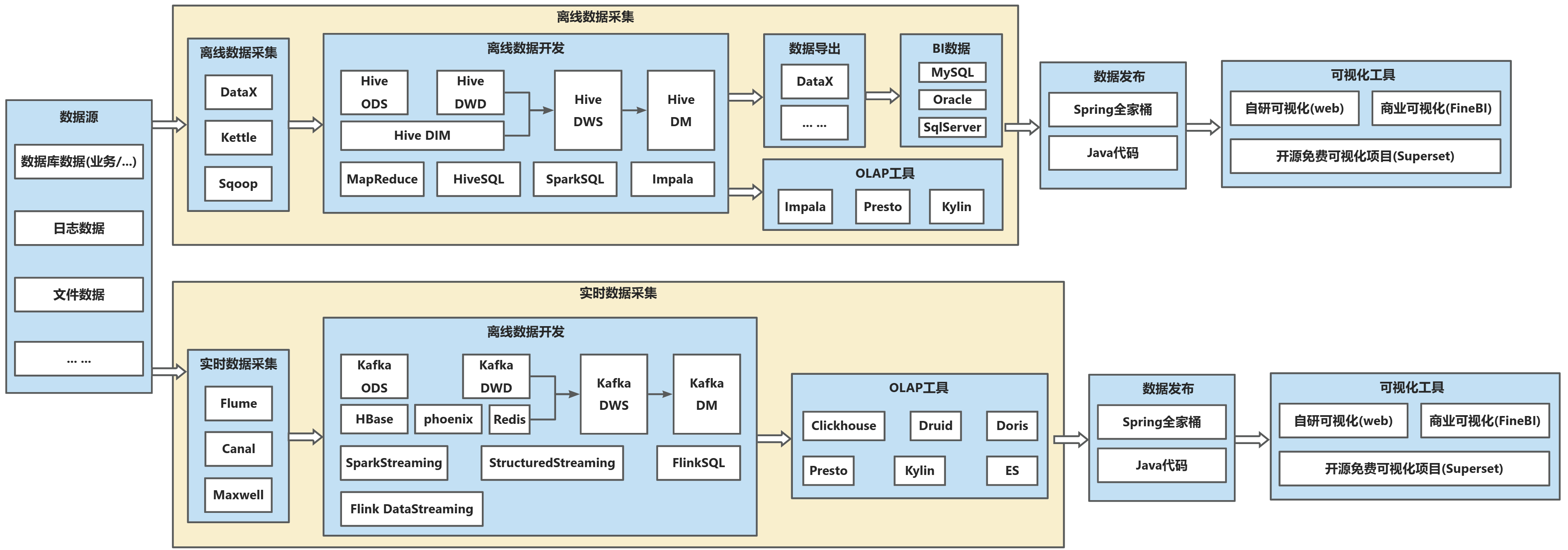
核心特點
1.開發、維護成本高
離線、實時各有一套代碼,開發時要開發兩套,維護時也要維護兩套,成本翻倍。
2.存儲成本、計算成本開銷大
離線、實時各有一套數倉,數據冗余度高,存儲成本、計算成本翻倍。?
技術棧?
Hadoop生態(HDFS/Hive)+ 實時相關生態技術(Kafka + Flink + Sparkstreaming ... ...)。
注:2.2相較于2.1其實就是引入了數倉的概念到實時鏈路中。
3. Kappa/流批一體架構

核心特點?
1. 以實時分析為主,離線分析少?
2. 放棄離線批處理,直接通過實時數據分析進行數據處理。
2. Kafka在流批一體場景下存在一定的缺陷?
- Kafka 無法存儲海量數據
- 數據治理平臺無法遷移使用
- Kafka 不支持數據的更新操作
技術棧?
Flink/Spark統一API
流批一體架構的思想
- 架構角度:一套架構既能完成流處理也能完成批處理
- 計算框架:一個框架既可以處理批數據也可以處理流數據
- SQL 層面:一套 SQL 可以處理批也可以處理流數據
- 存儲層面:離線數據和實時數據只需要存儲一份
4. 湖倉一體架構

核心特點?
1. 數據孤島與整合難題?
統一存儲結構化、半結構化和非結構化數據,消除傳統架構中數據倉庫與數據湖的割裂,減少數據冗余和遷移成本。
2. 小文件問題
傳統離線數倉,HDFS中其實也會存在類似的問題。
3. 實時數據處理慢
索引機制(如Bloom索引假陽性)和寫入模式(COW小文件問題)可能導致實時數據處理延遲。
技術棧?
HDFS、Delta Lake 、Iceberg
三、總結
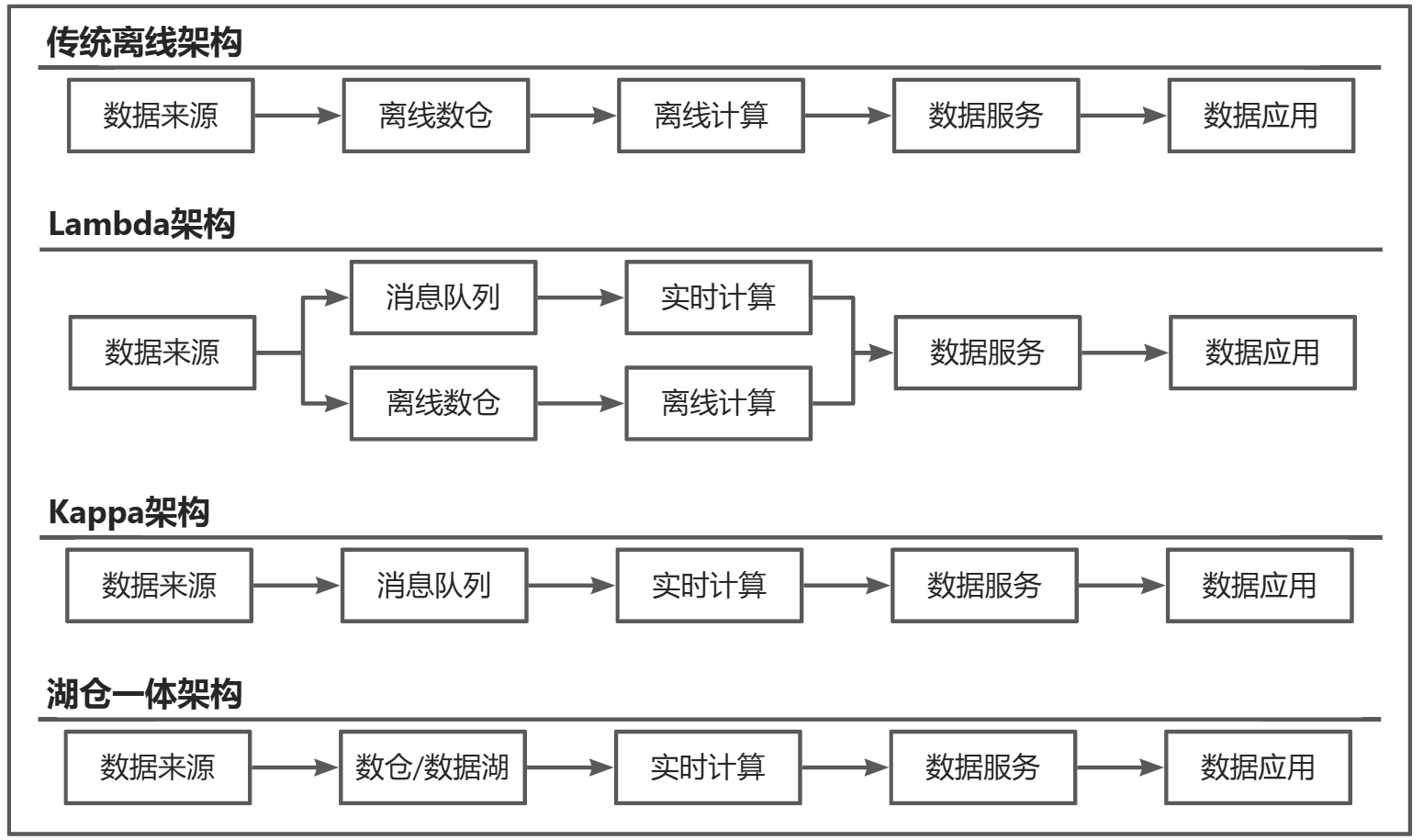


)









)

利用unity實現彎管機仿真)




