簡述
需求進展
之前,我嘗試用Longformer模型來訓練工單分類系統,但問題很快就暴露出來:Longformer訓練時間長得讓人抓狂,每次訓練只能針對一個租戶的數據,無法快速適配多個租戶的需求。
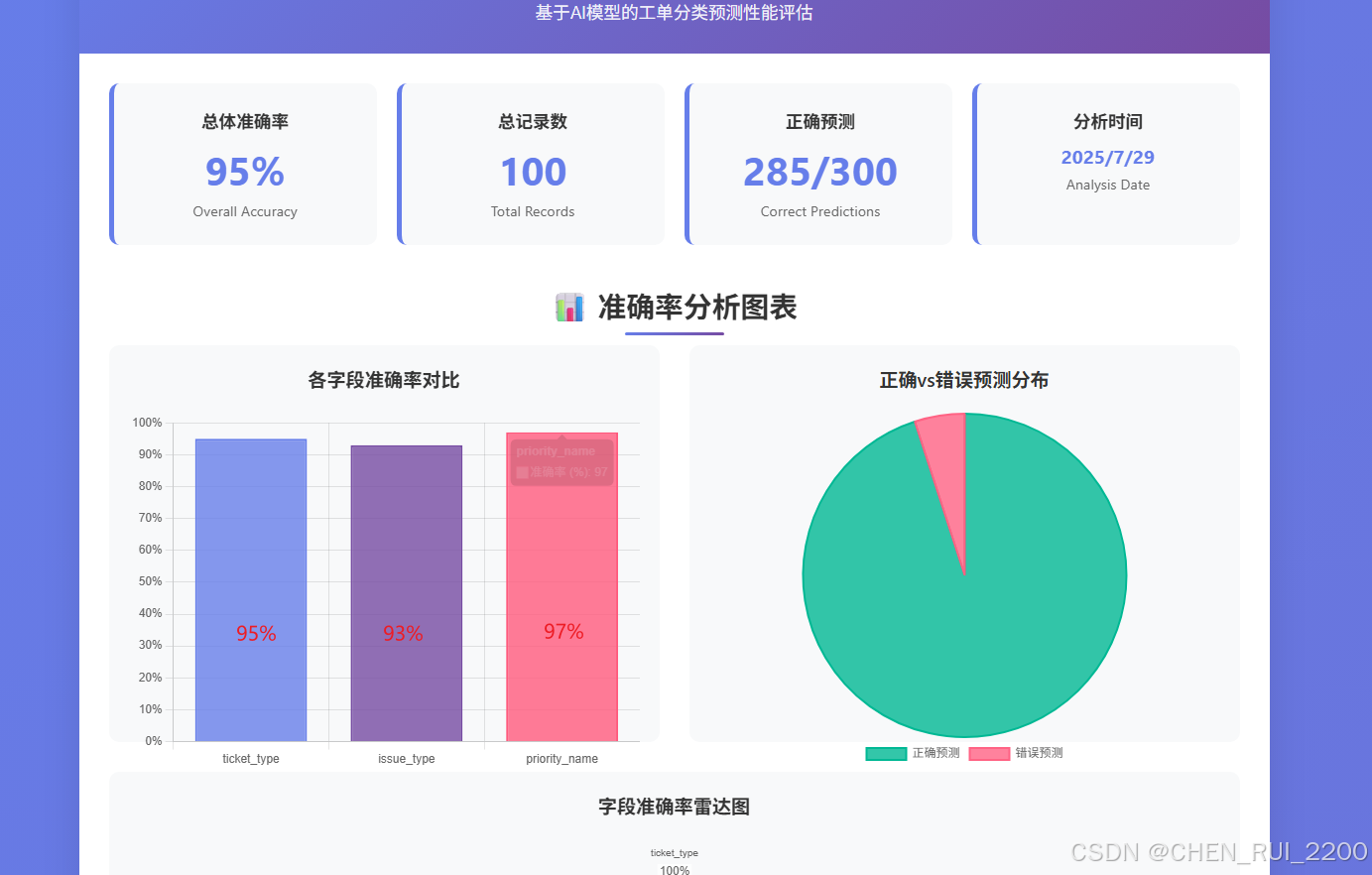
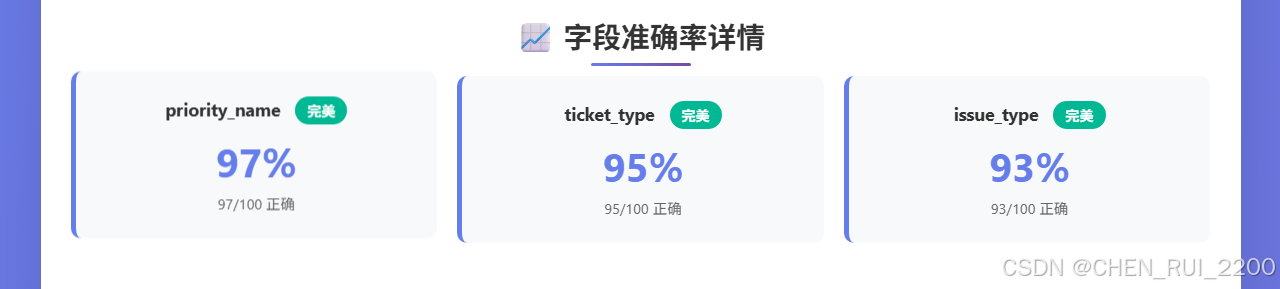
切換一個使用相同標簽的租戶還能夠保持較高的準確率
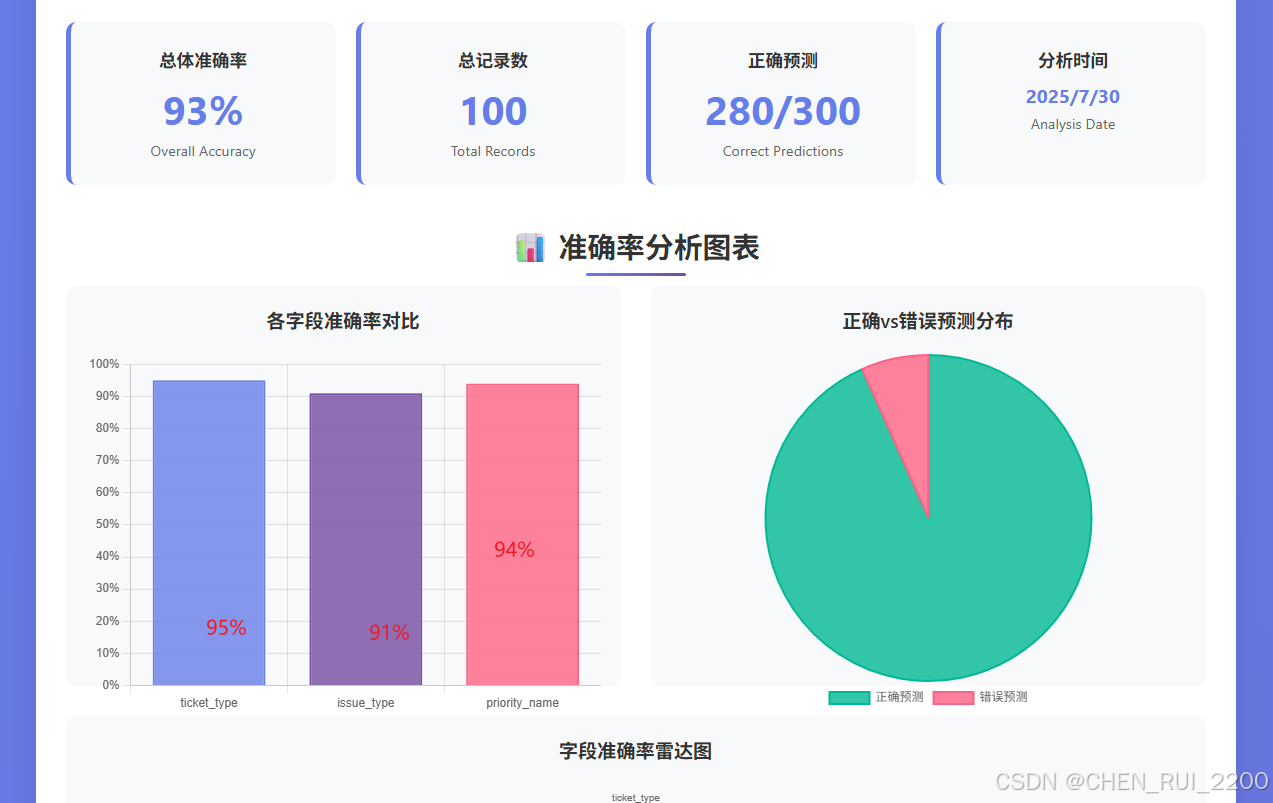
但是切換到一個使用客戶自定義issue type和priority的租戶就出現問題了
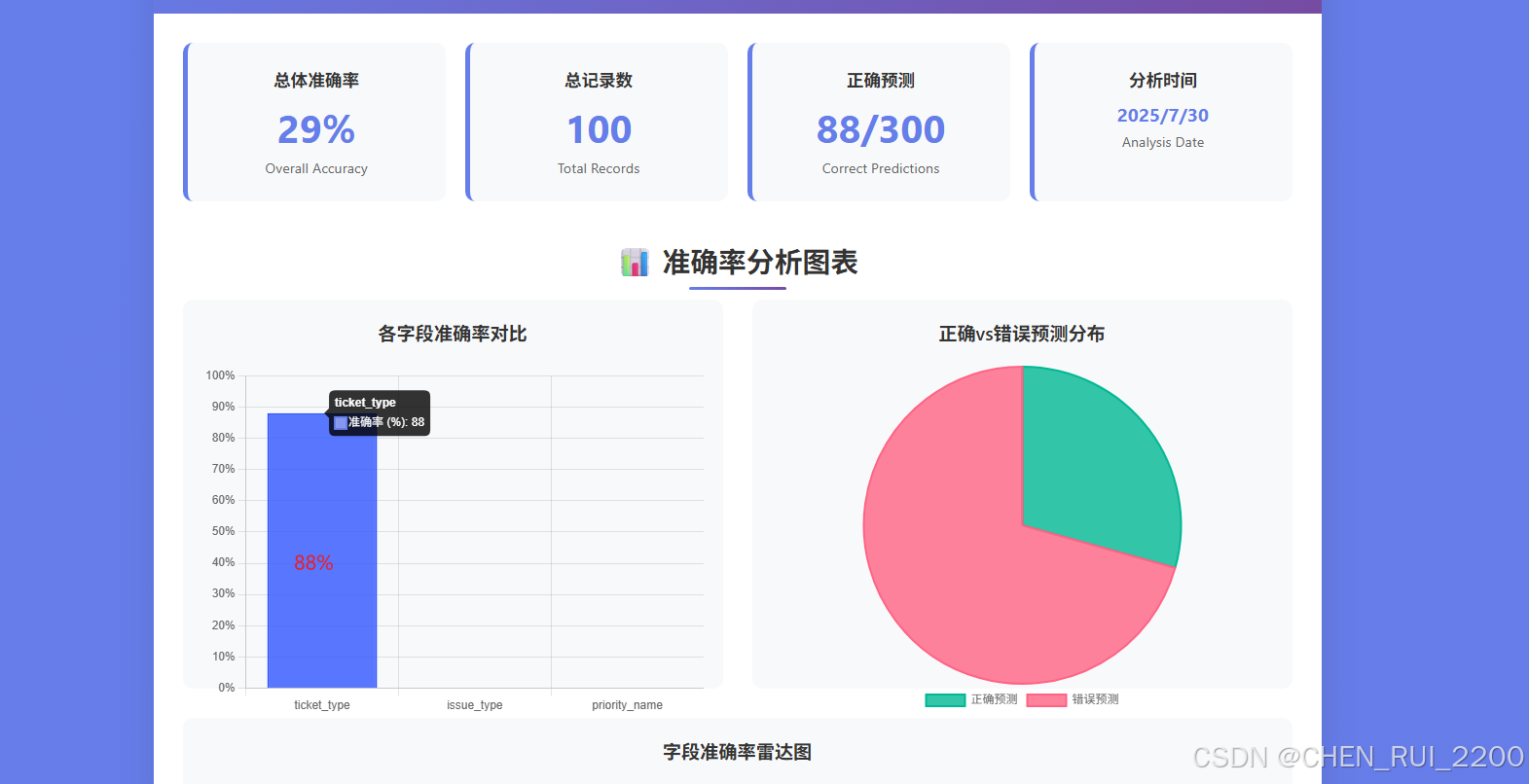
更糟的是,當客戶提交緊急工單時,系統因為訓練耗時過長,根本無法及時響應,客戶滿意度直線下降。這讓我們意識到,必須找到一個更高效、更靈活的解決方案。
于是我開啟了一場技術冒險,目標是打造一個智能工單分類系統(Ticket Triage AI),不僅能快速微調模型以服務多個租戶,還能實時響應用戶需求。我們選擇了Unsloth來加速模型微調,結合其他技術,構建了一個高效、用戶友好的系統
從需求到落地的技術冒險
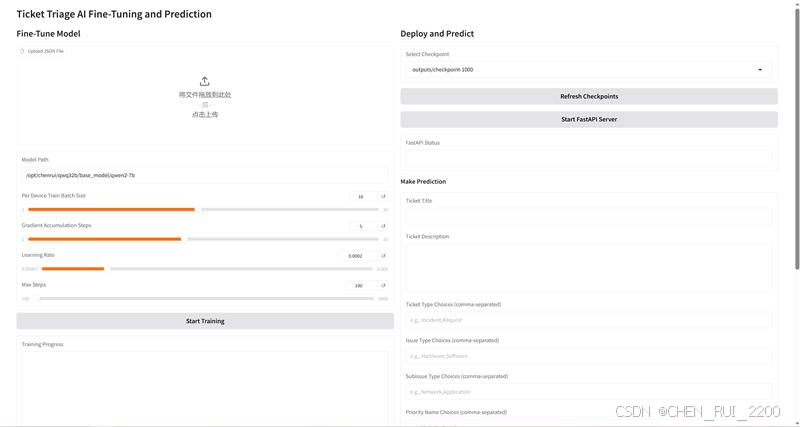
我們的目標是打造一個既能訓練AI模型,又能實時部署和預測的工單分類系統。整個開發過程就像一場技術冒險:我們需要選擇合適的工具、設計直觀的界面、解決實時日志和端口沖突等問題,還要讓系統既強大又易用。以下是我們如何一步步實現這個目標的旅程。
需求拆解,明確藍圖
我們希望系統能完成以下任務:
模型訓練:用戶上傳包含工單數據的JSON文件,系統自動加載并微調一個大語言模型(如Qwen2-7B),生成可用于預測的檢查點(checkpoint)。
實時日志:訓練過程中,實時顯示進度和損失值,讓用戶隨時了解模型狀態。
模型部署:從生成的檢查點中選擇一個,快速部署為FastAPI服務,避免端口沖突。
工單預測:輸入工單標題和描述,系統自動預測分類(如工單類型、優先級等),并支持用戶提供的候選選項。
用戶友好:界面清晰,訓練和部署分開布局,操作簡單,即使是非技術人員也能輕松上手。
這些需求看似簡單,實現起來卻需要協調多種技術解決一系列實際問題。
集成的技術
為了實現這個系統,我們調用了一支“技術全明星陣容”,每種技術都在冒險中扮演了關鍵角色:
Gradio:直觀的交互界面Gradio是我們打造用戶界面的利器。它簡單易用,能快速生成Web界面,讓用戶通過瀏覽器上傳文件、調整參數、查看日志和預測結果。我們使用了Gradio的Blocks API,通過Row和Column設計了一個左右布局:左邊是訓練專區,右邊是部署和預測專區,清晰直觀,像一個精心設計的控制臺。
Unsloth與Transformers:高效微調大模型我們選擇了Qwen2-7B作為基礎模型,結合Unsloth和Hugging Face的Transformers庫進行高效微調。Unsloth的LoRA(低秩適配)技術讓我們能在有限的GPU資源下快速微調模型,節省內存的同時保持性能。Transformers的SFTTrainer則負責訓練過程,確保模型能從工單數據中學習分類邏輯。
FastAPI:實時預測的API后端FastAPI是我們部署模型的“高速公路”。它輕量高效,支持異步請求,非常適合將微調后的模型快速轉為在線預測服務。我們通過FastAPI提供/predict端點,接受工單標題和描述,返回分類結果和置信度。
SentenceTransformers:精準匹配候選選項對于用戶提供的候選選項(比如工單類型可能的值),我們用SentenceTransformers的all-MiniLM-L6-v2模型計算語義相似度,確保模型預測的結果與候選選項最匹配。這種“后處理”機制讓分類更貼合實際業務需求。
Psutil與Socket:解決端口沖突部署模型時,端口沖突是個大麻煩。我們引入psutil來檢測和終止占用8000端口的進程,用socket驗證端口是否可用,確保每次部署都能順利啟動FastAPI服務。
Threading與異步日志:實時反饋訓練過程可能耗時較長,我們使用Python的threading模塊在后臺運行訓練,同時通過監控trainer_log.jsonl文件,實時提取訓練進度(如步數和損失值),通過Gradio的yield機制動態更新界面,讓用戶感覺像在看一場“直播”。
這些技術就像拼圖的每一塊組合在一起,產出一個簡潔的工單分單工具。
模型訓練和評估
訓練代碼
按照一般的方式做模型訓練和評估
import json
import os
import torch
from datasets import Dataset
from unsloth import FastLanguageModel, is_bfloat16_supported
from transformers import TrainingArguments
from trl import SFTTrainer# ? Step 1: 加載和格式化數據
def load_and_format_data(path):def format_example(sample):user_msg = f"""
Title: {sample['title']}
Description: {sample['description']}Predict the following fields:
- ticket_type
- issue_type
- subissue_type
- priority_name
- queue_id_name
- billing_codes
"""assistant_msg = f"""
ticket_type: {sample['ticket_type']}
issue_type: {sample['issue_type']}
subissue_type: {sample['subissue_type']}
priority_name: {sample['priority_name']}
queue_id_name: {sample['queue_id_name']}
billing_codes: {sample['billing_codes']}
"""return {"input": user_msg.strip(), "output": assistant_msg.strip()}with open(path, 'r', encoding='utf-8') as f:data = json.load(f)formatted = [format_example(x) for x in data]return Dataset.from_list(formatted)max_seq_length = 8096
lora_rank = 16
dtype = torch.bfloat16 if is_bfloat16_supported() else torch.float16
load_in_4bit = True
model_path = '/opt/chenrui/qwq32b/base_model/qwen2-7b'def load_or_create_peft_model(model_path_or_checkpoint: str,max_seq_length: int = 2048,dtype=None,load_in_4bit: bool = False,lora_config: dict = None,
):assert os.path.exists(model_path_or_checkpoint), f"路徑不存在:{model_path_or_checkpoint}"print(f"Loading model from {model_path_or_checkpoint}")try:if torch.cuda.is_available():torch.cuda.empty_cache()model, tokenizer = FastLanguageModel.from_pretrained(model_name=model_path_or_checkpoint,max_seq_length=max_seq_length,dtype=dtype,load_in_4bit=load_in_4bit,)print(f"Model loaded, parameters: {sum(p.numel() for p in model.parameters())}")except Exception as e:print(f"Failed to load model: {e}")raiseadapter_config_path = os.path.join(model_path_or_checkpoint, "adapter_config.json")if os.path.exists(adapter_config_path):print(f"檢測到 LoRA adapter: {adapter_config_path}")else:print("未檢測到 LoRA adapter,初始化新 LoRA...")assert lora_config is not None, "首次訓練需提供 lora_config"try:model = FastLanguageModel.get_peft_model(model,r=lora_config.get("r", 16),target_modules=lora_config.get("target_modules", ["q_proj", "k_proj", "v_proj", "o_proj","gate_proj", "up_proj", "down_proj"]),lora_alpha=lora_config.get("lora_alpha", 32),lora_dropout=lora_config.get("lora_dropout", 0),bias=lora_config.get("bias", "none"),use_gradient_checkpointing=lora_config.get("use_gradient_checkpointing", "unsloth"),random_state=lora_config.get("random_state", 42),use_rslora=lora_config.get("use_rslora", False),loftq_config=lora_config.get("loftq_config", None),)print(f"LoRA adapter initialized, parameters: {sum(p.numel() for p in model.parameters())}")except Exception as e:print(f"Failed to initialize LoRA: {e}")raisereturn model, tokenizerlora_config = {"r": lora_rank,"lora_alpha": lora_rank*2,"lora_dropout": 0,"target_modules": ["q_proj", "k_proj", "v_proj", "o_proj","gate_proj", "up_proj", "down_proj"],"use_gradient_checkpointing": "unsloth","bias": "none","use_rslora": False,"loftq_config": None
}model, tokenizer = load_or_create_peft_model(model_path_or_checkpoint=model_path,max_seq_length=max_seq_length,dtype=dtype,load_in_4bit=load_in_4bit,lora_config=lora_config,
)# ? Step 3: 加載數據集
dataset = load_and_format_data("adit_net_au.json")
print(f"Dataset loaded, size: {len(dataset)}") # 應為 58,000def formatting_prompts_func(examples):system_prompt = """
You are an intelligent Ticket Triage AI Agent designed to assist Managed Service Providers (MSPs) in efficiently managing and prioritizing support tickets. Your goal is to improve ticket handling speed, accuracy, and overall client satisfaction.**Core Responsibilities**:
- Analyze the ticket's **title** and **description** to understand user intent, system context, and impact scope.
- Prioritize technical accuracy, business logic, and enterprise IT norms over superficial keyword matching.
- Avoid speculation, hallucination, or subjective interpretation. Resolve ambiguity by focusing on actionable intent and system behavior.
- Output **exactly one** classification for requested fields in the format (eg, ticket_type: <ticket_type_value>)
"""texts = []for input_text, output_text in zip(examples["input"], examples["output"]):messages = [{"role": "system", "content": system_prompt},{"role": "user", "content": input_text},{"role": "assistant", "content": output_text}]prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=False)texts.append(prompt)return texts# ? Step 4: 構建 Trainer
trainer = SFTTrainer(model=model,tokenizer=tokenizer,train_dataset=dataset,dataset_text_field="text",formatting_func=formatting_prompts_func,max_seq_length=max_seq_length,dataset_num_proc=2,args=TrainingArguments(per_device_train_batch_size=16,gradient_accumulation_steps=5, # 有效 batch size = 100learning_rate=2e-4,lr_scheduler_type="linear",num_train_epochs=1,warmup_ratio=0.03,logging_steps=50,save_steps=200,save_total_limit=1,fp16=not is_bfloat16_supported(),bf16=is_bfloat16_supported(),optim="adamw_8bit",weight_decay=0.01,seed=3407,max_steps=1000,output_dir="outputs",resume_from_checkpoint=True,report_to="none",dataloader_num_workers=1,)
)# ? Step 5: 開始訓練
trainer.train()步驟 1:加載和格式化數據 (load_and_format_data)
- 作用:讀取JSON文件(adit_net_au.json)中的工單數據,并將其格式化為適合訓練的結構。
- 實現方式:
- 打開JSON文件,加載工單數據(如標題、描述、工單類型等)。
- 對每條工單,生成一個用戶提示,包含標題和描述,要求模型預測字段(如ticket_type、issue_type等)。
- 將預期輸出格式化為結構化文本(例如:ticket_type: Incident)。
- 將格式化后的數據轉換為Hugging Face的Dataset對象,包含input(輸入提示)和output(預期輸出)字段。
- 關鍵輸出:一個包含58,000條樣本的數據集,每條樣本都有輸入提示和預期輸出。
步驟 2:設置模型配置
- 作用:定義模型和訓練的全局參數。
- 細節:
- max_seq_length = 8096:設置最大輸入序列長度為8096個token,能處理長描述的工單。
- lora_rank = 16:設置LoRA(低秩適配)的秩為16,優化內存使用。
- dtype = torch.bfloat16(或torch.float16):如果支持,使用bfloat16加速計算,否則用float16。
- load_in_4bit = True:啟用4位量化,減少內存占用,適合Qwen2-7B這樣的大型模型。
- model_path:指定預訓練模型路徑為/opt/chenrui/qwq32b/base_model/qwen2-7b。
步驟 3:加載或創建PEFT模型 (load_or_create_peft_model)
- 作用:加載Qwen2-7B模型,并應用LoRA進行高效微調。
- 實現方式:
- 檢查模型路徑是否存在,并清空GPU緩存以釋放內存。
- 使用FastLanguageModel.from_pretrained加載模型和分詞器,啟用4位量化和指定數據類型。
- 檢查是否存在LoRA適配器(adapter_config.json)。如果沒有,初始化新的LoRA適配器,設置:
- r=16:低秩矩陣大小,優化效率。
- target_modules:對特定Transformer層(如q_proj、k_proj)應用LoRA。
- lora_alpha=32、lora_dropout=0:配置LoRA的縮放和丟棄率。
- use_gradient_checkpointing="unsloth":降低訓練時的內存占用。
- 記錄模型參數數量和任何錯誤信息。
- 關鍵輸出:一個準備好微調的模型和分詞器,已應用LoRA(如果需要)。
步驟 4:加載數據集
- 作用:準備工單數據集用于訓練。
- 實現方式:
- 調用load_and_format_data加載adit_net_au.json。
- 打印數據集大小(58,000條樣本)以驗證。
- 關鍵輸出:一個格式化的Dataset對象,準備好供訓練器使用。
步驟 5:格式化提示 (formatting_prompts_func)
- 作用:將數據集樣本轉換為模型能理解的訓練提示。
- 實現方式:
- 定義系統提示,指導模型作為工單分類AI,強調準確性和業務邏輯。
- 對每條樣本,生成聊天風格的提示,包括:
- 系統消息:工單分類AI的指令。
- 用戶消息:工單標題、描述和要預測的字段。
- 助手消息:預期輸出(如ticket_type: Incident)。
- 使用分詞器的apply_chat_template將消息格式化為單條文本。
- 關鍵輸出:一組格式化的提示文本,用于訓練。
步驟 6:構建訓練器 (SFTTrainer)
- 作用:配置訓練過程,包括模型、數據集和超參數。
- 實現方式:
- 初始化SFTTrainer(監督微調訓練器),設置:
- model和tokenizer:Qwen2-7B模型及其分詞器。
- train_dataset:格式化的數據集。
- dataset_text_field="text":指定包含格式化提示的字段。
- formatting_func:使用formatting_prompts_func格式化數據。
- max_seq_length=8096:與模型序列長度匹配。
- dataset_num_proc=2:使用2個CPU核心加速數據預處理。
- 配置TrainingArguments:
- per_device_train_batch_size=16、gradient_accumulation_steps=5:有效批量大小為80(16×5),平衡內存和訓練速度。
- learning_rate=2e-4:控制模型學習速度。
- num_train_epochs=1:數據集訓練一次。
- warmup_ratio=0.03:訓練開始時逐漸增加學習率。
- logging_steps=50、save_steps=200:每50步記錄進度,每200步保存檢查點。
- save_total_limit=1:僅保留最新檢查點,節省磁盤空間。
- fp16或bf16:根據硬件支持使用混合精度。
- optim="adamw_8bit":使用8位Adam優化器,提升效率。
- output_dir="outputs":檢查點保存到outputs目錄。
- resume_from_checkpoint=True:支持從上次檢查點恢復訓練。
- 初始化SFTTrainer(監督微調訓練器),設置:
- 關鍵輸出:一個配置好的訓練器,準備微調模型。
步驟 7:開始訓練 (trainer.train)
- 作用:執行微調過程。
- 實現方式:
- 運行訓練循環,訓練1000步(max_steps=1000)。
- 根據數據集更新模型權重,優化工單分類任務。
- 每200步保存檢查點到outputs目錄。
- 每50步記錄訓練進度(如損失值)到控制臺或日志文件。
- 關鍵輸出:微調后的模型,以檢查點形式保存在outputs目錄,供后續部署使用。
模型服務化
import json
import json
import torch
import reimport uvicorn
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel
from unsloth import FastLanguageModel
from sentence_transformers import SentenceTransformer, util
from typing import Dict, List
import numpy as npapp = FastAPI()model = './outputs/checkpoint-1000'
load_in_4bit = True
max_seq_length = 8096# Load the trained Qwen-7B model and tokenizer
model, tokenizer = FastLanguageModel.from_pretrained(model_name=model,max_seq_length=max_seq_length,dtype=None,load_in_4bit=load_in_4bit,
)
model.eval()
FastLanguageModel.for_inference(model)# Load the sentence transformer model for similarity comparison
similarity_model = SentenceTransformer('all-MiniLM-L6-v2')# Define input schema
class TicketInput(BaseModel):title: strdescription: strclass Choices(BaseModel):ticket_type: List[str] = Noneissue_type: List[str] = Nonesubissue_type: List[str] = Nonepriority_name: List[str] = Nonequeue_id_name: List[str] = Nonebilling_codes: List[str] = Noneclass PredictionRequest(BaseModel):input: TicketInputchoices: Choices# System message for the model
system_prompt = """
You are an intelligent Ticket Triage AI Agent designed to assist Managed Service Providers (MSPs) in efficiently managing and prioritizing support tickets. Your goal is to improve ticket handling speed, accuracy, and overall client satisfaction.**Core Responsibilities**:
- Analyze the ticket's **title** and **description** to understand user intent, system context, and impact scope.
- Prioritize technical accuracy, business logic, and enterprise IT norms over superficial keyword matching.
- Avoid speculation, hallucination, or subjective interpretation. Resolve ambiguity by focusing on actionable intent and system behavior.
- Output **exactly one** classification for requested fields in the format (eg:ticket_type: <ticket_type_value>)
"""# Format input for the model with clear instruction for JSON output
def format_input(title: str, description: str) -> str:return f"""
<|startoftext|>System: {system_prompt}User: Title: {title}
Description: {description}Predict the following fields:
- ticket_type
- issue_type
- subissue_type
- priority_name
- queue_id_name
- billing_codesAssistant: """def parse_output(output):# Split the output to isolate the assistant responseassistant_response = output.split("Assistant: ")[1].strip()# Parse the assistant response into a dictionarypredictions = {}clean_key = Nonefor line in assistant_response.split("\n"):if line.strip(): # Ensure the line is not emptyif ':' in line: # Handle colon formatkey, value = line.split(':', 1) # Split at the first colonclean_key = key.split('. ', 1)[-1].strip() # Remove numeric prefixpredictions[clean_key] = value.strip()elif line.startswith('- '): # Handle hyphen formatvalue = line.split('- ', 1)[-1].strip()if clean_key: # Ensure there's a valid clean_keypredictions[clean_key] = valueelse: # Handle keys without hyphens or colonskey_parts = line.split('. ')if len(key_parts) > 1:clean_key = key_parts[1].strip()return predictions# Parse model output to extract field predictions
def parse_model_output(output: str) -> Dict[str, str]:try:# Extract the assistant responsepredictions = parse_output(output)print('predictions', predictions)# Validate expected keysexpected_keys = {"ticket_type", "issue_type", "subissue_type", "priority_name", "queue_id_name","billing_codes"}if not all(key in predictions for key in expected_keys):raise ValueError("Missing expected keys in model output")return predictionsexcept json.JSONDecodeError as e:raise ValueError(f"Failed to parse model output as JSON: {e}")except Exception as e:raise ValueError(f"Error parsing model output: {e}")# Compute confidence score for a single field# Compute similarity and select the best choice with confidence
def get_best_choice(predicted: str, choices: List[str], similarity_model) -> tuple[str, float]:if not choices:return predicted, Nonepredicted_embedding = similarity_model.encode(predicted, convert_to_tensor=True)choice_embeddings = similarity_model.encode(choices, convert_to_tensor=True)similarities = util.cos_sim(predicted_embedding, choice_embeddings)[0]best_idx = similarities.argmax().item()confidence = similarities[best_idx].item() * 100 # Scale to 0-100confidence = min(max(confidence, 0.0), 100.0)print(f'predicted:{predicted}, best choice:{choices[best_idx]}')return choices[best_idx], round(confidence, 5) # Format to 5 decimal places@app.post("/predict")
async def predict(request: PredictionRequest):try:# Format input promptprompt = format_input(request.input.title, request.input.description)# Tokenize and generateinputs = tokenizer(prompt, return_tensors="pt", truncation=True, max_length=8096).to("cuda")with torch.no_grad():outputs = model.generate(**inputs, max_new_tokens=256, do_sample=False)generated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)print('generated_text', generated_text)# Parse the assistant responsepredictions = parse_model_output(generated_text)# Initialize output with predictions and confidencesresult = {"predictions": {}, "confidences": {}}choices_dict = request.choices.dict(exclude_none=True)# Compute confidence for each fieldfor field in predictions:if field in choices_dict and choices_dict[field]:# Use similarity model for fields with choicespredicted_value, confidence = get_best_choice(predictions[field], choices_dict[field], similarity_model)result["predictions"][field] = predicted_valueresult["confidences"][field] = confidence* 0.9 if confidence is not None else 0.0else:# Use LLM output directly and compute confidenceresult["predictions"][field] = predictions[field]result["confidences"][field] = 0.9return resultexcept ValueError as e:raise HTTPException(status_code=500, detail=str(e))except Exception as e:raise HTTPException(status_code=500, detail=f"Unexpected error: {str(e)}")if __name__ == "__main__":uvicorn.run(app, host="0.0.0.0", port=8000)SentenceTransformers進行語義匹配,接受工單標題和描述,預測分類字段(如工單類型、優先級等),并支持用戶提供的候選選項。以下是代碼的逐步解釋:
1. 初始化與模型加載
- 導入庫:
- FastAPI:用于構建高效的API服務。
- Unsloth:加載微調后的Qwen2-7B模型,支持4位量化以節省內存。
- SentenceTransformer:使用all-MiniLM-L6-v2模型計算語義相似度,匹配預測結果與候選選項。
- torch:處理模型推理的張量操作。
- 其他庫(json, numpy, pydantic等)用于數據處理和API輸入驗證。
- 模型配置:
- model_path = './outputs/checkpoint-1000':指定微調后的模型檢查點路徑。
- load_in_4bit = True:啟用4位量化,降低內存需求。
- max_seq_length = 8096:設置最大輸入序列長度,適配長描述。
- 模型加載:
- 使用FastLanguageModel.from_pretrained加載Qwen2-7B模型和分詞器,設置為推理模式(model.eval()和for_inference)。
- 加載SentenceTransformer模型(all-MiniLM-L6-v2)用于語義相似度計算。
- 輸出:準備好用于推理的模型和分詞器,以及語義匹配模型。
2. 定義API輸入結構
- Pydantic模型:
- TicketInput:定義輸入的標題(title)和描述(description)。
- Choices:定義可選的候選選項(如ticket_type: ["Incident", "Request"]),支持六個字段(ticket_type, issue_type, subissue_type, priority_name, queue_id_name, billing_codes)。
- PredictionRequest:組合TicketInput和Choices,作為API的輸入格式。
- 作用:確保API接收的數據結構清晰,自動驗證輸入格式。
3. 系統提示與輸入格式化 (format_input)
- 作用:生成模型的輸入提示,確保模型理解任務。
- 實現:
- 定義system_prompt,指導模型作為工單分類AI,強調準確性和業務邏輯,避免猜測。
- format_input函數將標題和描述格式化為包含系統提示、用戶輸入(標題+描述)和預測字段的文本,格式為:
<|startoftext|>System: <system_prompt>User: Title: <title>Description: <description>Predict the following fields:- ticket_type- issue_type...Assistant:
- 輸出:格式化的提示文本,供模型推理。
4. 解析模型輸出 (parse_output 和 parse_model_output)
- 作用:從模型生成的文本中提取分類結果。
- 實現:
- parse_output:
- 提取“Assistant:”后的響應部分。
- 逐行解析,處理包含冒號(:)或連字符(-)的行,提取字段名(如ticket_type)和值(如Incident)。
- 處理可能出現的格式變體(如帶編號的行)。
- 返回字段名和值的字典。
- parse_model_output:
- 調用parse_output解析響應。
- 驗證是否包含所有預期字段(ticket_type, issue_type等)。
- 捕獲JSON解析錯誤或缺失字段,拋出異常。
- parse_output:
- 輸出:一個包含分類結果的字典(如{"ticket_type": "Incident", ...})。
5. 語義相似度匹配 (get_best_choice)
- 作用:將模型預測結果與用戶提供的候選選項進行語義匹配,輸出最接近的選項和置信度。
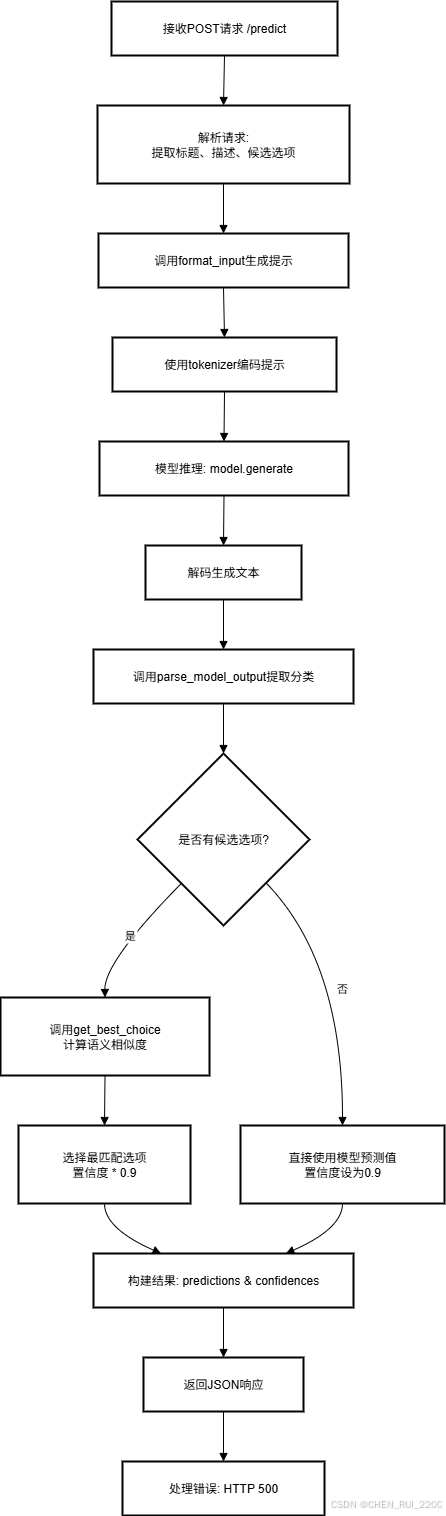
- 實現:
- 如果沒有候選選項,直接返回模型預測值和None置信度。
- 使用SentenceTransformer將預測值和候選選項編碼為嵌入向量。
- 計算預測值與候選選項的余弦相似度(util.cos_sim)。
- 選擇相似度最高的候選選項,計算置信度(0-100%)。
- 輸出:最匹配的候選值和置信度(如("Incident", 95.12345))。
6. FastAPI預測端點 (/predict)
- 作用:處理POST請求,接受工單標題、描述和候選選項,返回分類結果和置信度。
- 實現:
- 接收PredictionRequest(包含標題、描述和候選選項)。
- 調用format_input生成提示,tokenize后輸入模型。
- 使用model.generate生成預測(最大256個新token,無隨機采樣)。
- 解碼生成文本,調用parse_model_output提取分類結果。
- 對每個字段:
- 如果有候選選項,使用get_best_choice匹配最接近的選項,置信度乘以0.9。
- 如果無候選選項,直接使用模型預測值,置信度設為0.9。
- 返回JSON結果,包含predictions(分類結果)和confidences(置信度)。
覆蓋測試
def load_test_data(file_path: str) -> List[Dict]:"""Load test data from JSON file with UTF-8 encoding and shuffle dictionary keys."""try:with open(file_path, 'r', encoding='utf-8') as f:data = json.load(f)if not isinstance(data, list):raise ValueError("Test file must contain a list of test cases")# Shuffle keys in each dictionary to achieve disordered loadingshuffled_data = []for item in data:if not isinstance(item, dict):raise ValueError("Each test case must be a dictionary")# Get keys and shuffle themkeys = list(item.keys())random.shuffle(keys)# Create a new dictionary with shuffled key ordershuffled_item = {key: item[key] for key in keys}shuffled_data.append(shuffled_item)return shuffled_dataexcept UnicodeDecodeError as e:print(f"Encoding error in test file: {e}")# Attempt to read file content to show problematic linetry:with open(file_path, 'rb') as f:lines = f.readlines()error_position = e.startfor i, line in enumerate(lines):if error_position >= len(line):error_position -= len(line)else:print(f"Problematic line {i + 1}: {line.decode('utf-8', errors='replace')}")breakexcept Exception as ex:print(f"Could not read file for debugging: {ex}")sys.exit(1)except Exception as e:print(f"Error loading test file: {e}")sys.exit(1)def make_api_request(test_case: Dict) -> Dict:"""Send test case to API using requests and return predictions."""# Prepare API request payloadpayload = {"input": {"title": test_case["title"],"description": test_case["description"]},"choices": {"ticket_type": ["Service Request","Problem","Incident"],"issue_type": [...],"subissue_type": [...],"priority_name": ["Low","High","Critical","Medium"],"queue_id_name": [...],"billing_codes": [...]}}try:# Make POST requestresponse = requests.post(API_URL, headers=HEADERS, json=payload, timeout=10)response.raise_for_status() # Raise exception for bad status codesreturn response.json()["predictions"]except requests.exceptions.RequestException as e:print(f"API request failed: {e}")return Noneexcept (KeyError, ValueError) as e:print(f"Invalid response format: {e}")return Nonedef calculate_accuracy(predictions: List[Dict], ground_truth: List[Dict]) -> Dict[str, float]:"""Calculate accuracy for each field."""fields = ["ticket_type", "issue_type", "subissue_type", "priority_name", "queue_id_name", "billing_codes"]correct_counts = {field: 0 for field in fields}total_counts = {field: 0 for field in fields}for pred, truth in zip(predictions, ground_truth):for field in fields:if field in pred and field in truth:total_counts[field] += 1if pred[field] == truth[field]:correct_counts[field] += 1return {field: (correct_counts[field] / total_counts[field] * 100) if total_counts[field] > 0 else 0.0for field in fields}def main(test_file: str):"""Run coverage test and report progress and accuracy."""# Load test datatest_cases = load_test_data(test_file)total_cases = len(test_cases)if total_cases == 0:print("No test cases found in the file.")returnpredictions = []print(f"Starting coverage test with {total_cases} test cases...")# Process each test case with tqdm progress barfor i, test_case in enumerate(tqdm(test_cases, desc="Processing test cases", unit="case")):prediction = make_api_request(test_case)if prediction:predictions.append(prediction)else:predictions.append({})# Report intermediate accuracy every 10 test cases or at the endif (i + 1) % 10 == 0 or (i + 1) == total_cases:accuracy = calculate_accuracy(predictions, test_cases[:i + 1])print("\nIntermediate Accuracy Report:")for field, acc in accuracy.items():print(f"{field}: {acc:.2f}%")print()# Final accuracy reportaccuracy = calculate_accuracy(predictions, test_cases)print("\nFinal Accuracy Report:")for field, acc in accuracy.items():print(f"{field}: {acc:.2f}%")隨機抽取進行測試,在跨租戶數據上進行測試,使用沒有新租戶的數據進行微調
Final Accuracy Report:
ticket_type: 85.00%
issue_type: 81.00%
subissue_type: 9.00%
priority_name: 72.00%
queue_id_name: 2.00%
billing_codes: 95.00%
可以看到某些字段如queue_id_name,由于租戶和租戶之間的數據差異太大簡單的使用在基礎數據上做相似度匹配方式做預測已經不管用了
盡管已經有了單獨的微調腳本和評估腳本,但開發一個集成化的系統,允許用戶隨時上傳文件進行微調和評估,仍然具有重要意義。以下是原因的簡潔說明:
- 簡化操作流程:單獨的微調和評估腳本需要用戶在命令行或不同環境中手動運行,涉及文件路徑配置、參數調整和結果查看,操作復雜且易出錯。集成系統提供一個直觀的界面(如Gradio的Web界面),讓用戶只需上傳JSON文件、設置參數并點擊按鈕,就能完成微調和評估,極大降低使用門檻。
- 實時反饋與監控:微調腳本運行時,用戶往往只能通過日志文件或控制臺查看進度,缺乏實時交互。集成系統通過實時顯示訓練進度(如損失值、步數)
- 多租戶支持與快速迭代:單獨腳本每次運行通常針對單一數據集,難以快速適配多租戶場景。集成系統允許用戶隨時上傳不同租戶的JSON文件,快速微調模型并生成檢查點(checkpoint),支持動態切換租戶數據,滿足實時業務需求
應用集成
全量代碼
import gradio as gr
import json
import os
import torch
import uvicorn
from datasets import Dataset
from unsloth import FastLanguageModel, is_bfloat16_supported
from transformers import TrainingArguments
from trl import SFTTrainer
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel
from sentence_transformers import SentenceTransformer, util
from typing import Dict, List
import numpy as np
import subprocess
import threading
import requests
import time
import logging
import shutil
import glob
import psutil
import socket# Configure logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)# FastAPI app for predictions
app = FastAPI()# Global variables for model and tokenizer
global_model = None
global_tokenizer = None
global_similarity_model = None
max_seq_length = 8096
load_in_4bit = True
server_thread = None # Track the FastAPI server thread# Define input schema for FastAPI
class TicketInput(BaseModel):title: strdescription: strclass Choices(BaseModel):ticket_type: List[str] = Noneissue_type: List[str] = Nonesubissue_type: List[str] = Nonepriority_name: List[str] = Nonequeue_id_name: List[str] = Nonebilling_codes: List[str] = Noneclass PredictionRequest(BaseModel):input: TicketInputchoices: Choices# System prompt for predictions
system_prompt = """
You are an intelligent Ticket Triage AI Agent designed to assist Managed Service Providers (MSPs) in efficiently managing and prioritizing support tickets. Your goal is to improve ticket handling speed, accuracy, and overall client satisfaction.**Core Responsibilities**:
- Analyze the ticket's **title** and **description** to understand user intent, system context, and impact scope.
- Prioritize technical accuracy, business logic, and enterprise IT norms over superficial keyword matching.
- Avoid speculation, hallucination, or subjective interpretation. Resolve ambiguity by focusing on actionable intent and system behavior.
- Output **exactly one** classification for requested fields in the format (eg:ticket_type: <ticket_type_value>)
"""def format_input(title: str, description: str) -> str:return f"""
<|startoftext|>System: {system_prompt}User: Title: {title}
Description: {description}Predict the following fields:
- ticket_type
- issue_type
- subissue_type
- priority_name
- queue_id_name
- billing_codesAssistant: """def parse_output(output):assistant_response = output.split("Assistant: ")[1].strip()predictions = {}clean_key = Nonefor line in assistant_response.split("\n"):if line.strip():if ':' in line:key, value = line.split(':', 1)clean_key = key.split('. ', 1)[-1].strip()predictions[clean_key] = value.strip()elif line.startswith('- '):value = line.split('- ', 1)[-1].strip()if clean_key:predictions[clean_key] = valueelse:key_parts = line.split('. ')if len(key_parts) > 1:clean_key = key_parts[1].strip()return predictionsdef parse_model_output(output: str) -> Dict[str, str]:try:predictions = parse_output(output)logger.info(f"Parsed predictions: {predictions}")expected_keys = {"ticket_type", "issue_type", "subissue_type", "priority_name", "queue_id_name","billing_codes"}if not all(key in predictions for key in expected_keys):raise ValueError("Missing expected keys in model output")return predictionsexcept Exception as e:raise ValueError(f"Error parsing model output: {e}")def get_best_choice(predicted: str, choices: List[str], similarity_model) -> tuple[str, float]:if not choices:return predicted, Nonepredicted_embedding = similarity_model.encode(predicted, convert_to_tensor=True)choice_embeddings = similarity_model.encode(choices, convert_to_tensor=True)similarities = util.cos_sim(predicted_embedding, choice_embeddings)[0]best_idx = similarities.argmax().item()confidence = similarities[best_idx].item() * 100 # Scale to 0-100confidence = min(max(confidence, 0.0), 100.0)print(f'predicted:{predicted}, best choice:{choices[best_idx]}')return choices[best_idx], round(confidence, 5)@app.post("/predict")
async def predict(request: PredictionRequest):try:prompt = format_input(request.input.title, request.input.description)inputs = global_tokenizer(prompt, return_tensors="pt", truncation=True, max_length=8096).to("cuda")with torch.no_grad():outputs = global_model.generate(**inputs, max_new_tokens=256, do_sample=False)generated_text = global_tokenizer.decode(outputs[0], skip_special_tokens=True)logger.info(f"Generated text: {generated_text}")predictions = parse_model_output(generated_text)result = {"predictions": {}, "confidences": {}}choices_dict = request.choices.dict(exclude_none=True)for field in predictions:if field in choices_dict and choices_dict[field]:predicted_value, confidence = get_best_choice(predictions[field], choices_dict[field],global_similarity_model)result["predictions"][field] = predicted_valueresult["confidences"][field] = confidence * 0.9 if confidence is not None else 0.0else:result["predictions"][field] = predictions[field]result["confidences"][field] = 0.9return resultexcept ValueError as e:raise HTTPException(status_code=500, detail=str(e))except Exception as e:raise HTTPException(status_code=500, detail=f"Unexpected error: {str(e)}")# Fine-tuning functions
def load_and_format_data(path):def format_example(sample):user_msg = f"""
Title: {sample['title']}
Description: {sample['description']}Predict the following fields:
- ticket_type
- issue_type
- subissue_type
- priority_name
- queue_id_name
- billing_codes
"""assistant_msg = f"""
ticket_type: {sample['ticket_type']}
issue_type: {sample['issue_type']}
subissue_type: {sample['subissue_type']}
priority_name: {sample['priority_name']}
queue_id_name: {sample['queue_id_name']}
billing_codes: {sample['billing_codes']}
"""return {"input": user_msg.strip(), "output": assistant_msg.strip()}with open(path, 'r', encoding='utf-8') as f:data = json.load(f)formatted = [format_example(x) for x in data]return Dataset.from_list(formatted)def load_or_create_peft_model(model_path_or_checkpoint: str,max_seq_length: int = 2048,dtype=None,load_in_4bit: bool = False,lora_config: dict = None,
):assert os.path.exists(model_path_or_checkpoint), f"路徑不存在:{model_path_or_checkpoint}"logger.info(f"Loading model from {model_path_or_checkpoint}")try:if torch.cuda.is_available():torch.cuda.empty_cache()model, tokenizer = FastLanguageModel.from_pretrained(model_name=model_path_or_checkpoint,max_seq_length=max_seq_length,dtype=dtype,load_in_4bit=load_in_4bit,)logger.info(f"Model loaded, parameters: {sum(p.numel() for p in model.parameters())}")except Exception as e:logger.error(f"Failed to load model: {e}")raiseadapter_config_path = os.path.join(model_path_or_checkpoint, "adapter_config.json")if os.path.exists(adapter_config_path):logger.info(f"檢測到 LoRA adapter: {adapter_config_path}")else:logger.info("未檢測到 LoRA adapter,初始化新 LoRA...")assert lora_config is not None, "首次訓練需提供 lora_config"try:model = FastLanguageModel.get_peft_model(model,r=lora_config.get("r", 16),target_modules=lora_config.get("target_modules", ["q_proj", "k_proj", "v_proj", "o_proj","gate_proj", "up_proj", "down_proj"]),lora_alpha=lora_config.get("lora_alpha", 32),lora_dropout=lora_config.get("lora_dropout", 0),bias=lora_config.get("bias", "none"),use_gradient_checkpointing=lora_config.get("use_gradient_checkpointing", "unsloth"),random_state=lora_config.get("random_state", 42),use_rslora=lora_config.get("use_rslora", False),loftq_config=lora_config.get("loftq_config", None),)logger.info(f"LoRA adapter initialized, parameters: {sum(p.numel() for p in model.parameters())}")except Exception as e:logger.error(f"Failed to initialize LoRA: {e}")raisereturn model, tokenizerdef train_model(json_file, model_path, batch_size, grad_steps, learning_rate, max_steps):try:# Initialize progress messagesprogress_messages = []# Extract filename for checkpoint directoryjson_filename = os.path.basename(json_file.name)output_dir = os.path.join("outputs", os.path.splitext(json_filename)[0])os.makedirs(output_dir, exist_ok=True)# Load datasetdataset = load_and_format_data(json_file.name)progress_messages.append(f"Dataset loaded, size: {len(dataset)}\n")yield "\n".join(progress_messages), []# Model configurationmax_seq_length = 2048lora_rank = 16dtype = torch.bfloat16 if is_bfloat16_supported() else torch.float16load_in_4bit = Truelora_config = {"r": lora_rank,"lora_alpha": lora_rank * 2,"lora_dropout": 0,"target_modules": ["q_proj", "k_proj", "v_proj", "o_proj","gate_proj", "up_proj", "down_proj"],"use_gradient_checkpointing": "unsloth","bias": "none","use_rslora": False,"loftq_config": None}# Load modelmodel, tokenizer = load_or_create_peft_model(model_path_or_checkpoint=model_path,max_seq_length=max_seq_length,dtype=dtype,load_in_4bit=load_in_4bit,lora_config=lora_config,)progress_messages.append("Model and tokenizer loaded successfully.\n")yield "\n".join(progress_messages), []# Formatting function for promptsdef formatting_prompts_func(examples):system_prompt = """
You are an intelligent Ticket Triage AI Agent designed to assist Managed Service Providers (MSPs) in efficiently managing and prioritizing support tickets. Your goal is to improve ticket handling speed, accuracy, and overall client satisfaction.**Core Responsibilities**:
- Analyze the ticket's **title** and **description** to understand user intent, system context, and impact scope.
- Prioritize technical accuracy, business logic, and enterprise IT norms over superficial keyword matching.
- Avoid speculation, hallucination, or subjective interpretation. Resolve ambiguity by focusing on actionable intent and system behavior.
- Output **exactly one** classification for requested fields in the format (eg, ticket_type: <ticket_type_value>)
"""texts = []for input_text, output_text in zip(examples["input"], examples["output"]):messages = [{"role": "system", "content": system_prompt},{"role": "user", "content": input_text},{"role": "assistant", "content": output_text}]prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=False)texts.append(prompt)return texts# Configure trainertrainer = SFTTrainer(model=model,tokenizer=tokenizer,train_dataset=dataset,dataset_text_field="text",formatting_func=formatting_prompts_func,max_seq_length=max_seq_length,dataset_num_proc=2,args=TrainingArguments(per_device_train_batch_size=batch_size,gradient_accumulation_steps=grad_steps,learning_rate=learning_rate,lr_scheduler_type="linear",num_train_epochs=1,warmup_ratio=0.03,logging_steps=50,save_steps=200,save_total_limit=1,fp16=not is_bfloat16_supported(),bf16=is_bfloat16_supported(),optim="adamw_8bit",weight_decay=0.01,seed=3407,max_steps=max_steps,output_dir=output_dir,resume_from_checkpoint=True,report_to="none",dataloader_num_workers=1,))# Train and update progressdef log_training_progress(trainer, progress_queue):trainer.train()progress_queue.append("Training completed successfully!\n")# Use a list as a simple queue for thread-safe progress updatesprogress_queue = []training_thread = threading.Thread(target=log_training_progress, args=(trainer, progress_queue))training_thread.start()# Monitor training progresslog_file = os.path.join(output_dir, "trainer_log.jsonl")last_step = 0while training_thread.is_alive():if os.path.exists(log_file):with open(log_file, 'r') as f:lines = f.readlines()if lines:last_line = lines[-1]try:log_entry = json.loads(last_line)current_step = log_entry.get('global_step', last_step)if current_step > last_step:loss = log_entry.get('loss', 'N/A')progress_messages.append(f"Step {current_step}/{max_steps}, Loss: {loss}\n")last_step = current_stepyield "\n".join(progress_messages), []except json.JSONDecodeError:passtime.sleep(2)training_thread.join()# Append any final messages from the training threadprogress_messages.extend(progress_queue)# Return checkpoint pathscheckpoints = glob.glob(os.path.join(output_dir, "checkpoint-*"))progress_messages.append(f"Training completed. Checkpoints saved at: {output_dir}\n")yield "\n".join(progress_messages), checkpointsexcept Exception as e:progress_messages.append(f"Training failed: {str(e)}\n")yield "\n".join(progress_messages), []def check_and_free_port(port):"""Check if the port is in use and terminate any process using it."""progress_messages = []try:# Check if port is in usefor conn in psutil.net_connections():if conn.laddr.port == port and conn.status == psutil.CONN_LISTEN:pid = conn.pidif pid:progress_messages.append(f"Found process {pid} using port {port}. Terminating...\n")try:p = psutil.Process(pid)p.terminate()p.wait(timeout=3) # Wait for process to terminateprogress_messages.append(f"Process {pid} terminated.\n")except psutil.NoSuchProcess:progress_messages.append(f"Process {pid} no longer exists.\n")except psutil.TimeoutExpired:p.kill() # Force kill if it doesn't terminateprogress_messages.append(f"Process {pid} forcefully terminated.\n")except Exception as e:progress_messages.append(f"Failed to terminate process {pid}: {str(e)}\n")# Verify port is freewith socket.socket(socket.AF_INET, socket.SOCK_STREAM) as s:s.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)try:s.bind(("0.0.0.0", port))progress_messages.append(f"Port {port} is free.\n")except socket.error:progress_messages.append(f"Port {port} still in use, may require manual intervention.\n")except Exception as e:progress_messages.append(f"Error checking/freeing port {port}: {str(e)}\n")return progress_messagesdef start_fastapi(checkpoint_path):global global_model, global_tokenizer, global_similarity_model, server_threadprogress_messages = []try:# Free port 8000 if in useprogress_messages.extend(check_and_free_port(8000))# Load model and tokenizerglobal_model, global_tokenizer = FastLanguageModel.from_pretrained(model_name=checkpoint_path,max_seq_length=max_seq_length,dtype=None,load_in_4bit=load_in_4bit,)global_model.eval()FastLanguageModel.for_inference(global_model)global_similarity_model = SentenceTransformer('all-MiniLM-L6-v2')progress_messages.append(f"Model loaded from {checkpoint_path}\n")# Start FastAPI server in a separate threaddef run_server():uvicorn.run(app, host="0.0.0.0", port=8000, log_level="error")# Terminate existing server thread if it existsif server_thread and server_thread.is_alive():progress_messages.append("Existing FastAPI server thread detected. Attempting to stop...\n")# Note: Thread termination is tricky in Python; rely on port freeing insteadserver_thread = Noneserver_thread = threading.Thread(target=run_server)server_thread.daemon = Trueserver_thread.start()time.sleep(2) # Wait for server to start# Verify server is runningtry:response = requests.get("http://localhost:8000", timeout=2)if response.status_code == 200:progress_messages.append("FastAPI server started at http://0.0.0.0:8000\n")else:progress_messages.append("FastAPI server started but returned unexpected status.\n")except requests.ConnectionError:progress_messages.append("FastAPI server failed to start (connection error).\n")return "\n".join(progress_messages)except Exception as e:progress_messages.append(f"Failed to start FastAPI server: {str(e)}\n")return "\n".join(progress_messages)def make_prediction(title, description, ticket_type_choices, issue_type_choices, subissue_type_choices,priority_name_choices, queue_id_name_choices, billing_codes_choices, progress_output):try:# Initialize progress messagesprogress_messages = [progress_output] if progress_output else []choices_dict = {"ticket_type": ticket_type_choices.split(",") if ticket_type_choices else None,"issue_type": issue_type_choices.split(",") if issue_type_choices else None,"subissue_type": subissue_type_choices.split(",") if subissue_type_choices else None,"priority_name": priority_name_choices.split(",") if priority_name_choices else None,"queue_id_name": queue_id_name_choices.split(",") if queue_id_name_choices else None,"billing_codes": billing_codes_choices.split(",") if billing_codes_choices else None,}request_data = {"input": {"title": title,"description": description},"choices": choices_dict}response = requests.post("http://localhost:8000/predict", json=request_data)response.raise_for_status()result = response.json()progress_messages.append(f"Prediction result: {json.dumps(result, indent=2)}\n")return "\n".join(progress_messages)except Exception as e:progress_messages.append(f"Prediction failed: {str(e)}\n")return "\n".join(progress_messages)# Gradio interface
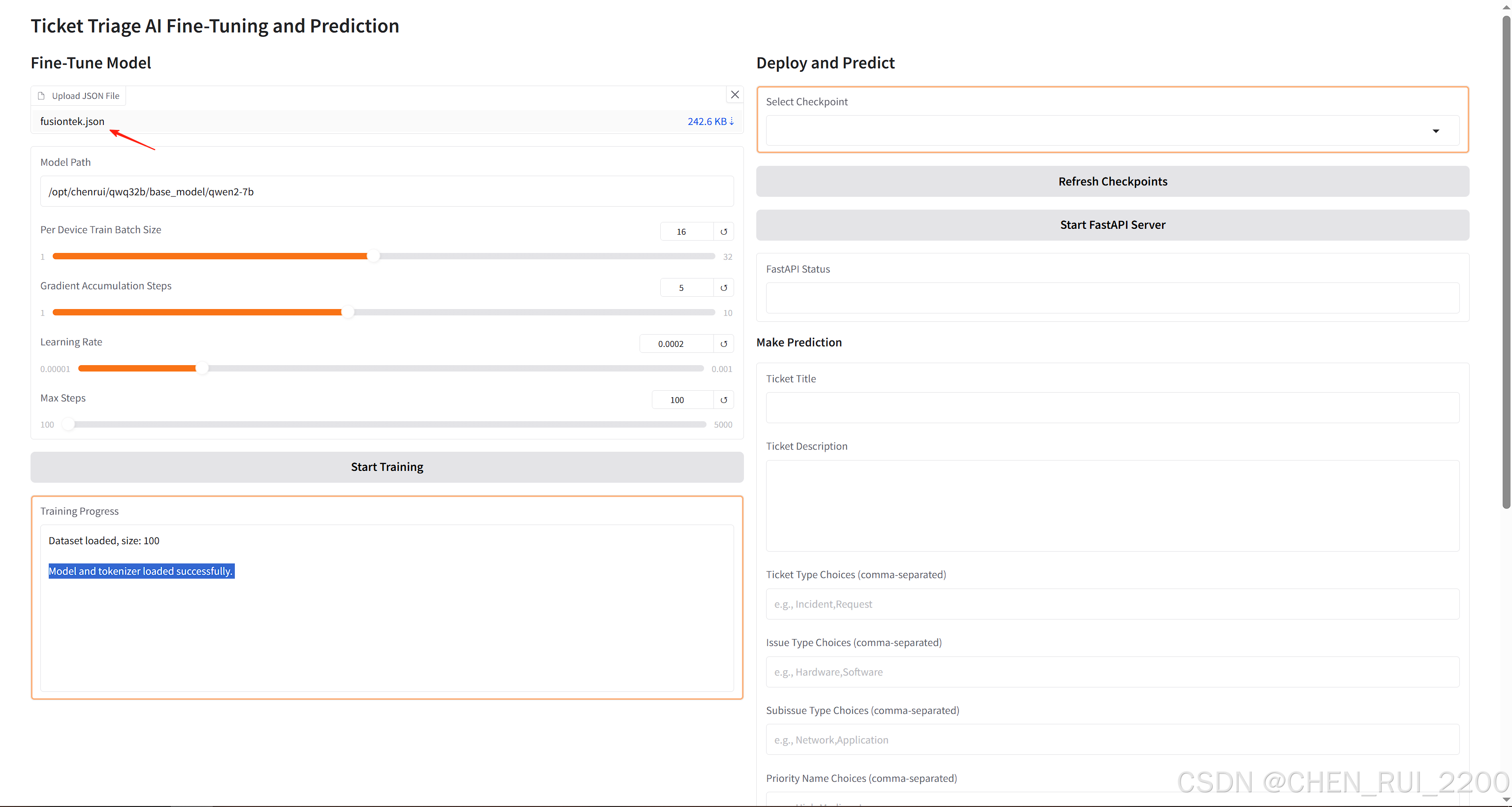
def create_gradio_app():with gr.Blocks() as demo:gr.Markdown("# Ticket Triage AI Fine-Tuning and Prediction")with gr.Row():# Left Column: Trainingwith gr.Column():gr.Markdown("## Fine-Tune Model")json_file = gr.File(label="Upload JSON File")model_path = gr.Textbox(label="Model Path", value="/opt/chenrui/qwq32b/base_model/qwen2-7b")batch_size = gr.Slider(minimum=1, maximum=32, value=16, step=1, label="Per Device Train Batch Size")grad_steps = gr.Slider(minimum=1, maximum=10, value=5, step=1, label="Gradient Accumulation Steps")learning_rate = gr.Slider(minimum=1e-5, maximum=1e-3, value=2e-4, step=1e-5, label="Learning Rate")max_steps = gr.Slider(minimum=100, maximum=5000, value=100, step=100, label="Max Steps")train_button = gr.Button("Start Training")training_progress = gr.Textbox(label="Training Progress", lines=10, interactive=False)# Right Column: Deployment and Predictionwith gr.Column():gr.Markdown("## Deploy and Predict")checkpoint_dropdown = gr.Dropdown(label="Select Checkpoint", choices=[])refresh_checkpoints = gr.Button("Refresh Checkpoints")start_fastapi_button = gr.Button("Start FastAPI Server")fastapi_status = gr.Textbox(label="FastAPI Status", interactive=False)gr.Markdown("### Make Prediction")title_input = gr.Textbox(label="Ticket Title")description_input = gr.Textbox(label="Ticket Description", lines=5)ticket_type_choices = gr.Textbox(label="Ticket Type Choices (comma-separated)",placeholder="e.g., Incident,Request")issue_type_choices = gr.Textbox(label="Issue Type Choices (comma-separated)",placeholder="e.g., Hardware,Software")subissue_type_choices = gr.Textbox(label="Subissue Type Choices (comma-separated)",placeholder="e.g., Network,Application")priority_name_choices = gr.Textbox(label="Priority Name Choices (comma-separated)",placeholder="e.g., High,Medium,Low")queue_id_name_choices = gr.Textbox(label="Queue ID Name Choices (comma-separated)",placeholder="e.g., IT,Support")billing_codes_choices = gr.Textbox(label="Billing Codes Choices (comma-separated)",placeholder="e.g., BILL001,BILL002")predict_button = gr.Button("Make Prediction")prediction_output = gr.Textbox(label="Prediction Output", lines=10, interactive=False)# Event handlersdef update_checkpoints():output_dir = "outputs"checkpoints = []if os.path.exists(output_dir):# Scan all subdirectories in outputs for checkpoint-* foldersfor root, dirs, _ in os.walk(output_dir):for dir_name in dirs:if dir_name.startswith("checkpoint-"):checkpoints.append(os.path.join(root, dir_name))checkpoints.sort() # Sort for consistent displayreturn gr.Dropdown(choices=checkpoints, value=checkpoints[0] if checkpoints else None)train_button.click(fn=train_model,inputs=[json_file, model_path, batch_size, grad_steps, learning_rate, max_steps],outputs=[training_progress, checkpoint_dropdown])refresh_checkpoints.click(fn=update_checkpoints,inputs=[],outputs=[checkpoint_dropdown])start_fastapi_button.click(fn=start_fastapi,inputs=[checkpoint_dropdown],outputs=[fastapi_status])predict_button.click(fn=make_prediction,inputs=[title_input, description_input, ticket_type_choices, issue_type_choices,subissue_type_choices, priority_name_choices, queue_id_name_choices,billing_codes_choices, prediction_output],outputs=[prediction_output])return demoif __name__ == "__main__":demo = create_gradio_app()demo.launch(server_name="0.0.0.0")上傳特定格式的json 格式文件開始訓練
選擇checkpoint啟動模型服務
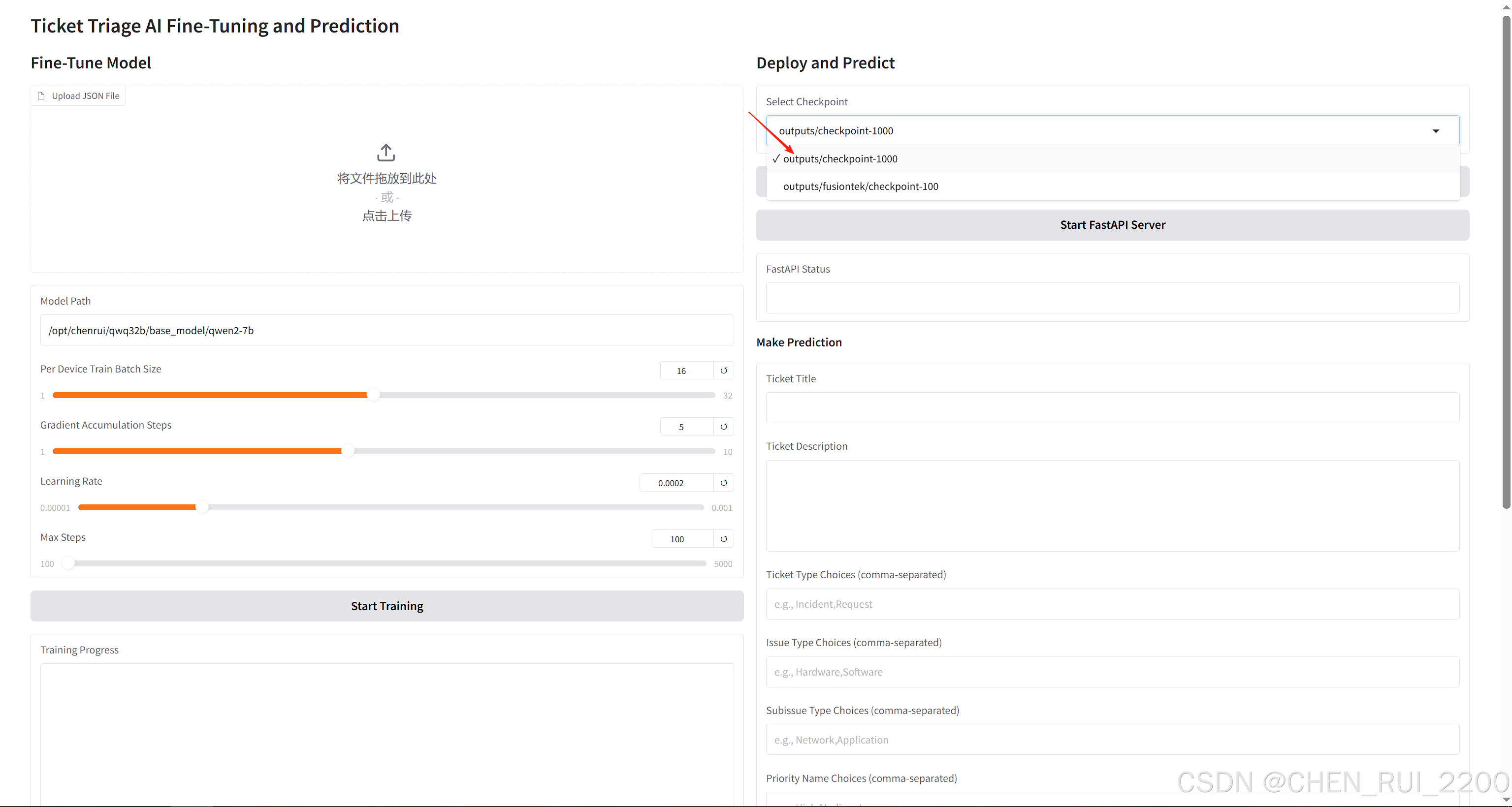
啟動服務
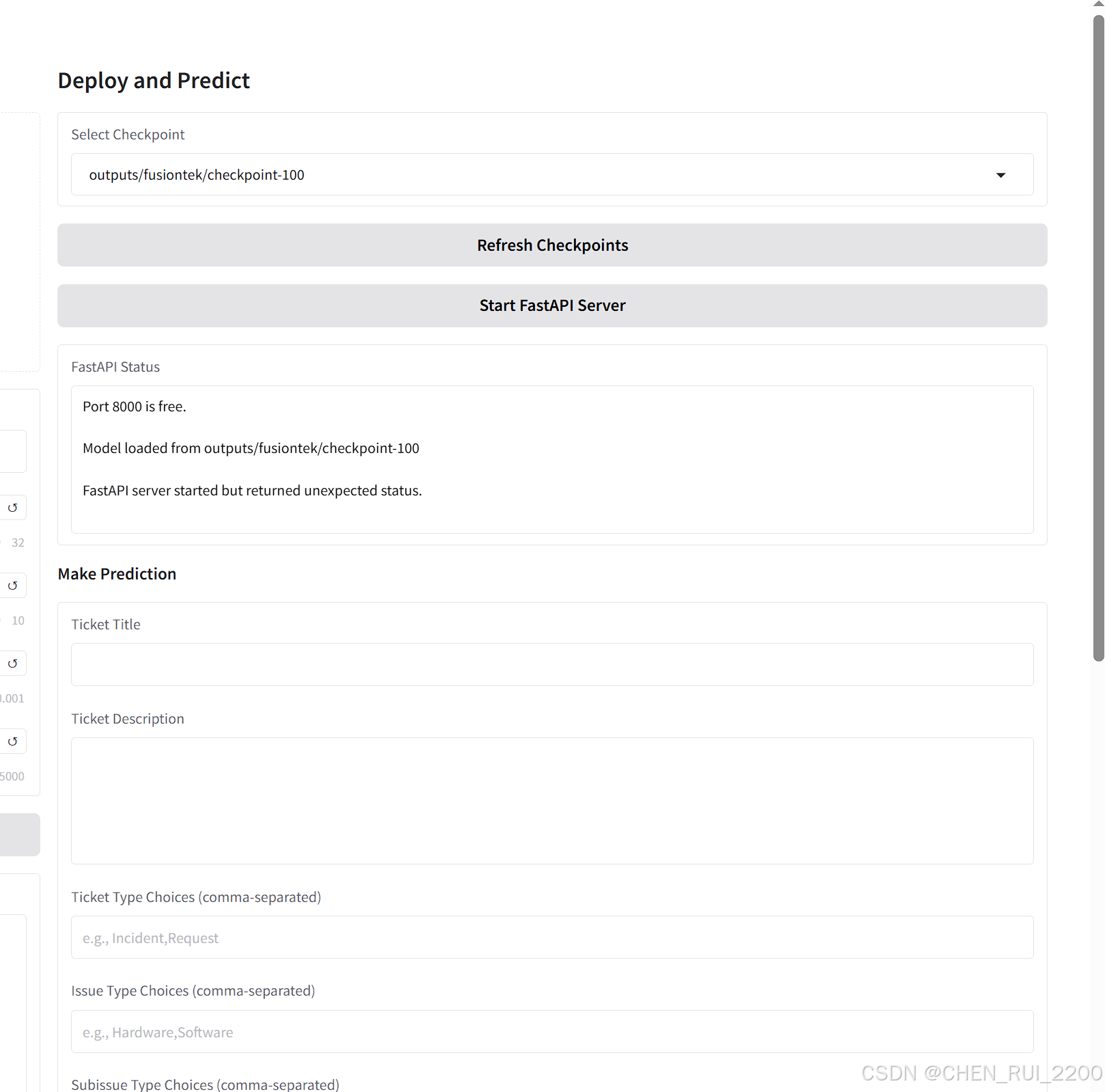
再次測試,看到各項指標的準確率都上去了
Final Accuracy Report:
ticket_type: 95.18%
issue_type: 96.39%
subissue_type: 78.31%
priority_name: 66.27%
queue_id_name: 78.31%
billing_codes: 98.80%

—Hint簡介與Hint分類及語法(1))





 表單提交、數據處理)

、更新(修改)、刪除)
?)

:OpenAI重返開源,Anthropic放大招,Claude4.1、GPT5相繼發布)


)



