目錄
- 1.摘要
- 2.問題定義
- 3.SA-NNO-DRL方法
- 4.結果展示
- 5.參考文獻
- 6.算法輔導·應用定制·讀者交流

1.摘要
無人機(UAV)因其高自主性和靈活性,廣泛應用于偵察任務,多無人機任務規劃在交通監控和數據采集等任務中至關重要,但現有方法在計算需求上較高,導致常常無法得到最優解。為解決這一問題,本文提出了一種分治框架將任務分為兩個階段:目標分配和無人機路徑規劃,從而有效降低了計算復雜度。本文提出混合方法SA-NNO-DRL結合了基于最近鄰最優的深度強化學習(NNO-DRL)和模擬退火(SA)算法。在路徑規劃階段,NNO-DRL為每個無人機構建路徑;在目標分配階段,SA重新分配未覆蓋的目標。兩個階段交替進行,直到滿足終止條件。
2.問題定義
MURMPP的目標是為無人機群體規劃路徑,最大化其在監控目標時的總利潤。每個無人機從同一中心出發并返回,成功監控指的是訪問或經過目標。目標的利潤預先定義,且僅在成功監控后收取。由于電池限制,部分目標可能無法覆蓋。MURMPP是一個復雜的組合優化問題,隨著目標數量增加,其難度呈指數級增長,該問題可通過混合整數線性規劃(MILP)形式化,其中涉及多個無人機、目標、利潤、路徑分配和飛行范圍的約束。
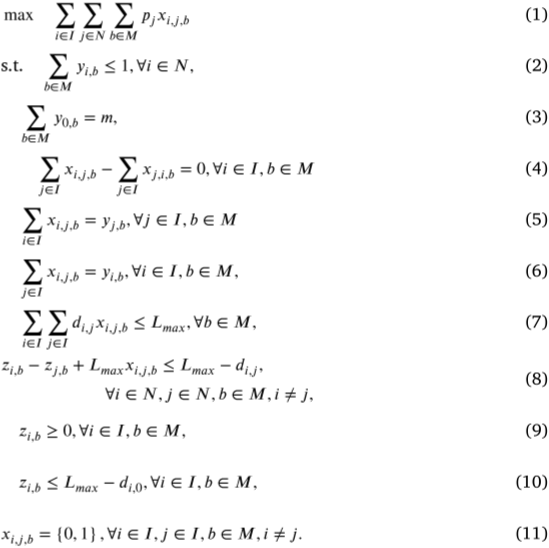
3.SA-NNO-DRL方法
為解決MURMPP,論文提出了一種迭代的兩階段框架——SA-NNO-DRL,在該框架中目標分配和無人機路徑規劃交替進行并相互作用。
單無人機NNO-DRL路徑規劃方法
路徑規劃可視為一個順序決策問題,通過馬爾可夫決策過程來實現。無人機智能體根據環境狀態(如目標信息和剩余飛行范圍)決定下一步行動 (即選擇訪問的目標節點),并獲得相應的獎勵。NNO-DRL的目標是學習一個策略pθp_\thetapθ?,構建路徑τ\tauτ,最大化總利潤,同時遵循約束條件。生成路徑的概率通過鏈式法則表示:
pθ(τ∣s)=∏t=1Tpθ(τt∣s,τ1:t?1)p_\theta\left(\tau|s\right)=\prod_{t=1}^Tp_\theta\left(\tau_t|s,\tau_{1:t-1}\right) pθ?(τ∣s)=t=1∏T?pθ?(τt?∣s,τ1:t?1?)
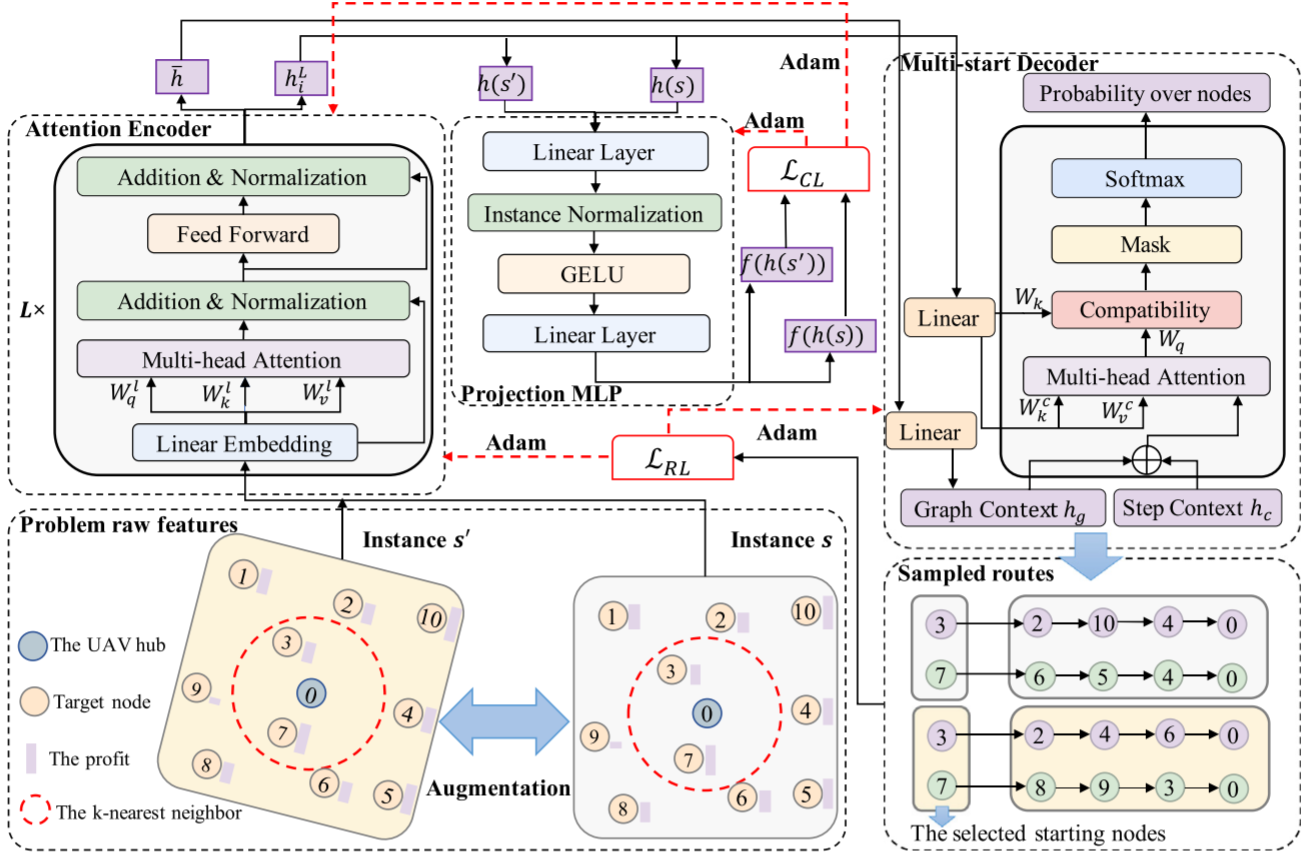
NNO-DRL由改進注意力模型和投影MLP組成,用于解決路徑規劃問題。其創新之處在于結合投影MLP和對比學習(CL)進行復雜問題表示,并通過kkk最近鄰策略的多啟動解碼器提高解空間探索效率。通過最大化原始實例和增強版本節點嵌入的余弦相似度,增強了表示的魯棒性。多啟動解碼器采用kkk最近鄰策略,生成多個軌跡,以避免因電池限制產生次優解。

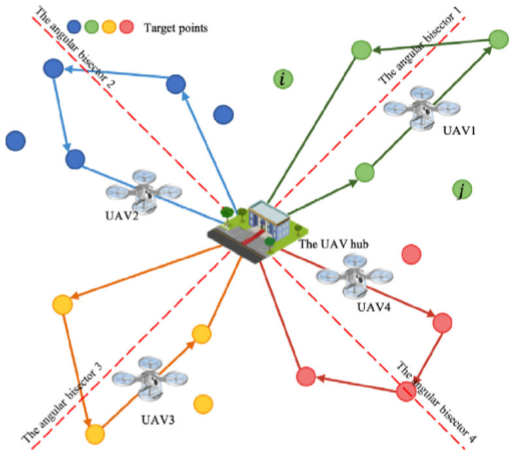
目標分配SA方法
給定位于區域中心的無人機中心,論文根據目標節點與水平軸之間的角度,將區域內的所有目標均勻地分成mmm組,角度定義為:
anglei=arctanlocyi?locy0locxi?locy0angle_i=arctan\frac{loc_y^i-loc_y^0}{loc_x^i-loc_y^0} anglei?=arctanlocxi??locy0?locyi??locy0??

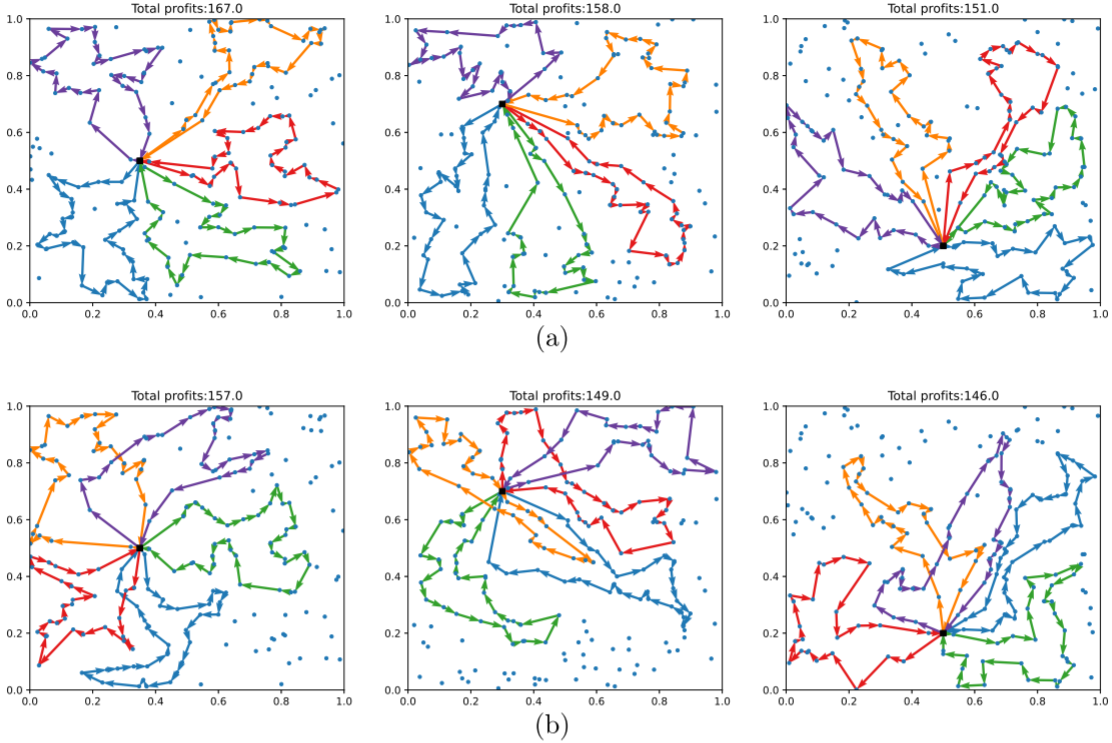
4.結果展示
5.參考文獻
[1] Fan M, Liu H, Wu G, et al. Multi-UAV reconnaissance mission planning via deep reinforcement learning with simulated annealing[J]. Swarm and Evolutionary Computation, 2025, 93: 101858.
6.算法輔導·應用定制·讀者交流
xx



 表單提交、數據處理)

、更新(修改)、刪除)
?)

:OpenAI重返開源,Anthropic放大招,Claude4.1、GPT5相繼發布)


)







