
摘要
多視圖聚類通過挖掘多個視圖之間的共同聚類結構,近年來受到了越來越多的關注。現有的大多數多視圖聚類算法使用淺層、線性嵌入函數來學習多視圖數據的公共結構。然而,這些方法無法充分利用多視圖數據的非線性特性,而這種特性對于揭示復雜的聚類結構非常重要。本文提出了一種新穎的多視圖聚類方法——深度對抗多視圖聚類(Deep Adversarial Multi-view Clustering, DAMC)網絡,用于學習嵌入在多視圖數據中的內在結構。具體而言,我們的模型采用深度自編碼器來學習由多個視圖共享的潛在表示,同時利用對抗訓練進一步捕獲數據分布并解耦潛在空間。在多個真實數據集上的實驗結果表明,該方法優于當前最先進的方法。
引言
1 引言
聚類分析是機器學習、模式識別、計算機視覺和數據挖掘等多個領域中的一項基礎任務。在這一主題上,研究人員投入了大量精力,其中多視圖聚類(multi-view clustering, MVC)[Yang and Wang, 2018] 受到了特別的關注。多視圖數據能夠為聚類任務提供互補信息,這在許多真實應用中是可以獲取的。例如,一張圖像可以由多種描述符來表征,如 SIFT [Lowe, 2004]、方向梯度直方圖(HOG)[Dalal and Triggs, 2005]、GIST [Oliva and Torralba, 2001] 和局部二值模式(LBP)[Ojala et al., 2002]。由于這些特征從不同角度描述了對象的屬性,因此它們被視為多視圖數據。近年來,多視圖聚類方法 [Zhao et al., 2017; Luo et al., 2018] 得到了快速發展,其核心在于挖掘多視圖之間共享的互補信息。在此基礎上,過去幾十年中,已經有許多先進的多視圖聚類算法被提出。
例如,[Liu et al., 2013b] 從非負矩陣分解的角度解決了這一問題,通過在多個視圖間進行非負矩陣分解來尋找公共潛在因子;一致性與特定性多視圖子空間聚類(CSMSC)[Luo et al., 2018] 則利用一個公共一致性表示和一組特定性表示來刻畫多視圖數據的自表達特性,更好地適配了真實的多視圖數據集。雖然傳統的多視圖聚類算法已取得了較好效果,但它們主要使用淺層、線性嵌入函數來揭示數據的內在結構,無法有效建模復雜數據的非線性特性。
近年來,深度聚類方法被提出,用于利用深度神經網絡建模數據樣本之間的關系,從而獲得聚類結果。在單視圖聚類方法中,DSC [Ji et al., 2017] 以堆疊自編碼器為基礎模型,利用自表達特性在潛在空間中學習數據的相似度;DAC [Chang et al., 2017] 將聚類問題轉化為二值對分類框架,推動相似的圖像對歸入同一簇;DEC [Xie et al., 2016] 通過最小化預測簇標簽分布與預定義分布之間的 KL 散度設計了一種新的聚類目標函數。另一方面,一些最新研究嘗試將深度學習引入多視圖聚類問題。例如,[Andrew et al., 2013] 提出了典型相關分析(CCA)的深度神經網絡擴展——深度 CCA,用于多視圖聚類;[Abavisani and Patel, 2018] 則使用卷積神經網絡進行無監督多模態子空間聚類。然而,利用深度神經網絡在多視圖間學習低維潛在空間的研究仍然較少。
在本文中,我們提出了一種新穎的深度對抗多視圖聚類(Deep Adversarial Multi-view Clustering, DAMC)網絡,用于學習嵌入在多視圖數據中的內在結構(見圖1)。我們的模型通過共享權重的多視圖自編碼器網絡,從原始特征有效映射到公共低維嵌入空間。與傳統算法相比,該方法能夠揭示多視圖數據的非線性特性,這對于處理復雜和高維數據至關重要。此外,我們采用對抗訓練 [Goodfellow et al., 2014] 作為正則化器來引導編碼器訓練,從而捕獲每個單視圖的數據分布,并進一步解耦公共潛在空間。在圖像和文本數據集上的實驗結果表明,該方法優于其他多視圖聚類方法。
我們的主要貢獻如下:
提出一種新穎的 DAMC 網絡:不同于現有的多視圖聚類方法,所提方法能夠充分建模任意視圖之間的多層非線性相關性。
針對每個視圖設計判別器網絡:能夠進一步捕獲數據分布并解耦潛在空間。
設計聚類損失約束公共表示:通過最小化預測標簽分布與預定義分布之間的相對熵,實現公共表示的優化。
方法
?網絡架構
給定一個包含 VV 個視圖的數據集 χ={X1,…,Xv,…,XV},其中 Xv∈Rdv×n表示來自第 vv 個視圖的 n?個樣本(每個樣本維度為 dv),我們構建了一個 DAMC 網絡,該網絡由以下部分組成:
一個全連接的多視圖去噪編碼器 EE;
一個全連接的多視圖去噪生成器 GG;
VV 個全連接判別器;
以及位于編碼器頂部的深度嵌入聚類層。
圖 1 展示了在 VV 視圖場景下的 DAMC 網絡結構。
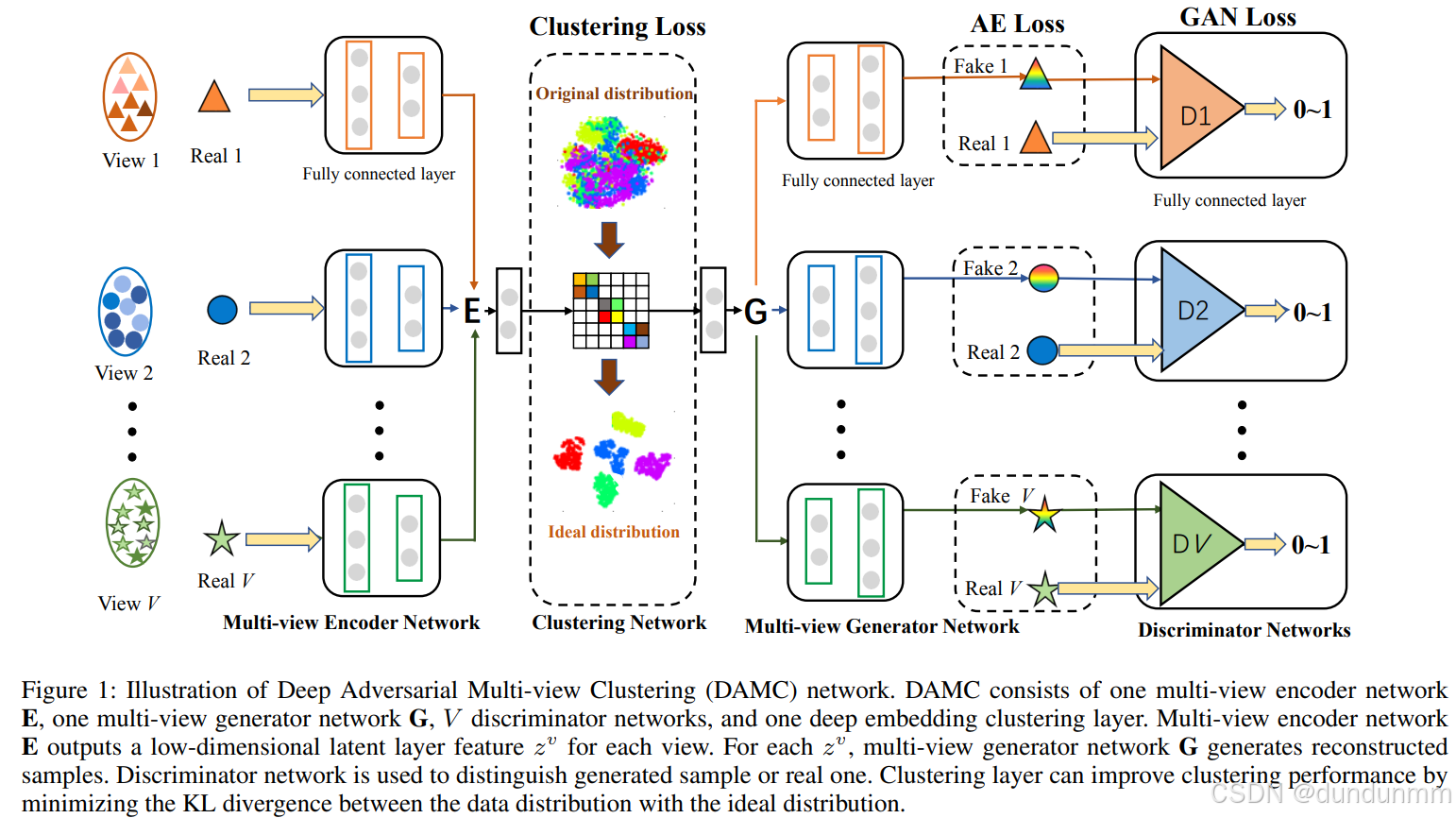
1. 多視圖去噪編碼器 E
在多視圖去噪編碼器網絡中,每個視圖包含 M 層獨立全連接網絡 和 N 層共享參數的全連接網絡。獨立層用于處理各視圖不同的特征維度。對于第 v?個視圖,給定 Xv={x1(v),x2(v),…,xn(v)},多視圖去噪編碼器 E 旨在學習該視圖的潛在表示 Zv={z1(v),z2(v),…,zn(v)},即將 dv?維的輸入數據 xi(v)映射到低維表示 zi(v):
![]()
其中 fv表示由參數 ΘE 定義的第 v 個視圖的編碼網絡。
2. 多視圖去噪生成器 G
多視圖去噪生成器的結構與編碼器相反,由 N 層共享參數的全連接網絡 和 M 層每個視圖獨立的全連接網絡 組成,可根據各視圖的潛在表示生成相應的重構樣本:
{Y1,Y2,…,Yv,…,YV}=G(Zv)
其中 Yv 表示第 v個視圖的重構樣本矩陣。
3. 判別器網絡 Dv
判別器網絡由 V個全連接判別器組成,每個判別器 Dv包含 3 層全連接層,用于區分生成樣本 yi(v)和真實樣本 xi(v)。GAN 損失定義為:
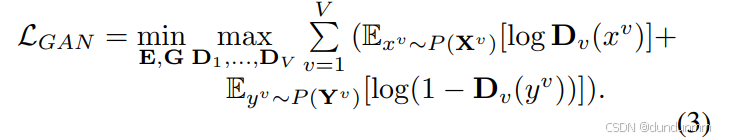
訓練過程中,編碼器和生成器生成與真實數據相似的假樣本,各判別器學習區分真假樣本,二者進行對抗直至收斂。由于 GAN 本身并不能在樣本級別保證輸出的可控性,這對聚類任務是不利的,因此我們將 GAN 損失與 AE(自編碼器)損失結合,以提升重構數據的可靠性。
聚類損失(Clustering Loss)
AE 損失和 GAN 損失鼓勵生成器生成與真實樣本更相似的樣本,從而使嵌入表示盡可能保留原始特征信息。但它們無法保證編碼后的低維空間具備良好的聚類結構。為了獲得有利于聚類劃分的表示空間,我們在 DAMC 網絡中引入基于 KL 散度的聚類損失。
首先,針對每個視圖學習潛在表示:
Z1=f1(X1;θE),?Z2=f2(X2;θE),…,ZV=fV(XV;θE)
然后得到公共潛在表示:
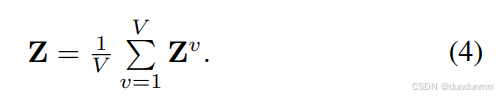
給定初始簇中心 {μj}j=1k,根據 [Xie et al., 2016],采用 Student’s t 分布作為核函數來計算公共潛在表示點 zi 與簇中心 μj?的相似度:
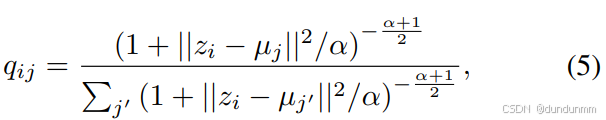
其中 α為自由度(實驗中取 α=1),qij 表示樣本 i?屬于簇 j?的概率(軟分配)。
為了優化聚類結構,我們引入輔助目標分布 pij,并通過最小化 qij與 pij 之間的 KL 散度來訓練模型:
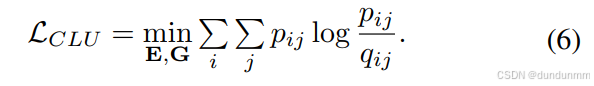
其中,pij 通過提升高置信度樣本的權重獲得:
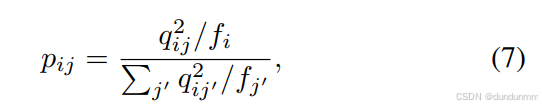
這樣可以使同類數據在表示空間中更加集中,從而獲得更有效的公共表示。
訓練流程
步驟 1:訓練多視圖去噪編碼器 E?和生成器 G,最小化 AE 損失。輸入 {x1,x2,…,xV} 得到潛在特征 {z1,z2,…,zV},再輸入生成器得到重構樣本,更新 E?和 G。然后在公共表示 Z 上運行 k-means 獲取初始簇中心 {μj}。
步驟 2:聯合訓練 E、G?和判別器 D1,…,DV,優化 AE 損失與 GAN 損失之和。將生成樣本與真實樣本送入各判別器,交替更新生成網絡與判別器。
步驟 3:在步驟 2 的基礎上,加入嵌入聚類層訓練整個網絡。每次迭代更新聚類中心,最終在獲得的公共表示上使用譜聚類得到最終聚類結果。
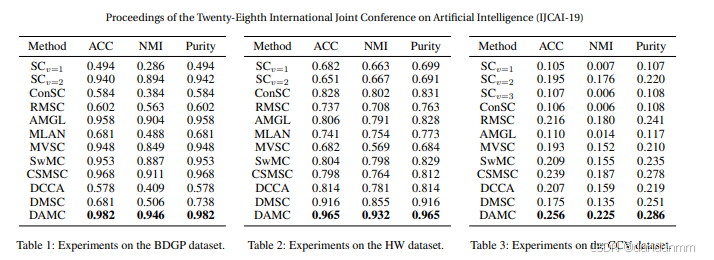
實驗

 表單提交、數據處理)

、更新(修改)、刪除)
?)

:OpenAI重返開源,Anthropic放大招,Claude4.1、GPT5相繼發布)


)








路由策略)
