目錄
一、什么是隨機森林?
1. 從決策樹到集成學習:為什么需要 "森林"?
2.什么是集成學習
二、隨機森林的工作原理
三、隨機森林構造過程
四、隨機森林api介紹
五、隨機森林的優缺點
六、垃圾郵件判斷案例
1.數據集介紹
?編輯
2.代碼解析
(1) 導入必要的庫
(2)?數據讀取與準備
(3) 劃分訓練集和測試集
(4)創建并訓練隨機森林模型
(5) 模型預測與評估
(6) 特征重要性分析
(7)特征重要性可視化
完整代碼如下
一、什么是隨機森林?
提到隨機森林,很多人會直觀地想:"不就是很多決策樹湊在一起嗎?" 這句話對了一半,但忽略了其核心的 "隨機性" 設計。要理解隨機森林,我們需要先從它的 "積木"—— 決策樹和 "組裝方式"—— 集成學習說起。
1. 從決策樹到集成學習:為什么需要 "森林"?
決策樹是一種直觀的機器學習模型,它像一棵倒置的樹,通過對特征的逐步判斷(如 "年齡是否大于 30?"" 收入是否超過 5 萬?")來實現分類或回歸。單棵決策樹的優點是簡單易懂、訓練速度快,但缺點也很明顯:容易過擬合(對訓練數據擬合過好,泛化能力差),且預測結果受數據微小變化影響較大(穩定性差)。
為了解決單棵決策樹的缺陷,集成學習(Ensemble Learning)?應運而生。集成學習的核心思想是:"三個臭皮匠頂個諸葛亮"—— 通過組合多個 "弱學習器"(性能略優于隨機猜測的模型)的預測結果,得到一個更強大的 "強學習器"。隨機森林就是集成學習中最成功的代表之一,它的 "弱學習器" 正是決策樹。
2.什么是集成學習
? 集成學習:通過組合多個基礎學習器(如決策樹、邏輯回歸等)提升模型性能,典型方法包括:
? Bagging(如隨機森林)
? Boosting(如AdaBoost、XGBoost)
? 堆疊模型(Stacking)
二、隨機森林的工作原理
隨機森林的核心在于 "隨機" 二字,主要體現在兩個方面:
1. 數據隨機:使用 Bootstrap 抽樣法從原始數據中隨機抽取樣本,為每棵樹創建不同的訓練集
2. 特征隨機:在構建每棵樹的每個節點時,隨機選擇部分特征進行分裂
3.森林結構:由多棵決策樹組成,最終結果通過投票(分類)或平均(回歸)決定。
其具體工作流程如下:
1. 從原始數據集中隨機有放回地抽取 N 個樣本,形成新的訓練集
2. 對于每個樣本集,隨機選擇部分特征,構建一棵決策樹
3. 重復上述過程,構建多棵決策樹
4. 對于分類問題,通過投票決定最終類別;對于回歸問題,取平均值作為結果
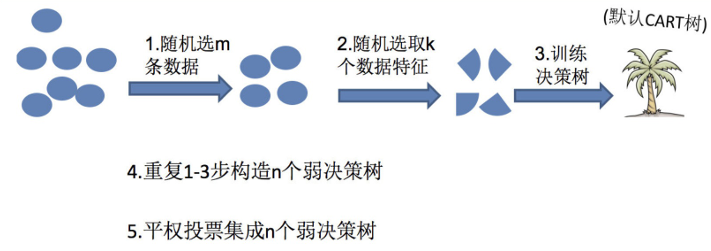
三、隨機森林構造過程
在機器學習中,隨機森林是?個包含多個決策樹的分類器,并且其輸出的類別是由個別樹輸出的類別的眾數?定。
隨機森林?? ?=?? ?Bagging?? ?+?? ?決策樹
例如,?? ?如果你訓練了5個樹,?? ?其中有4個樹的結果是True,?? ?1個樹的結果是False,?? ?那么最終投票結果就是True
隨機森林夠造過程中的關鍵步驟(M表示特征數?):
1)?次隨機選出?個樣本,有放回的抽樣,重復N次(有可能出現重復的樣本)
?2)?? ?隨機去選出m個特征,?? ?m?? ?<<M,建?決策樹
四、隨機森林api介紹
以下是隨機森林的源碼參數:
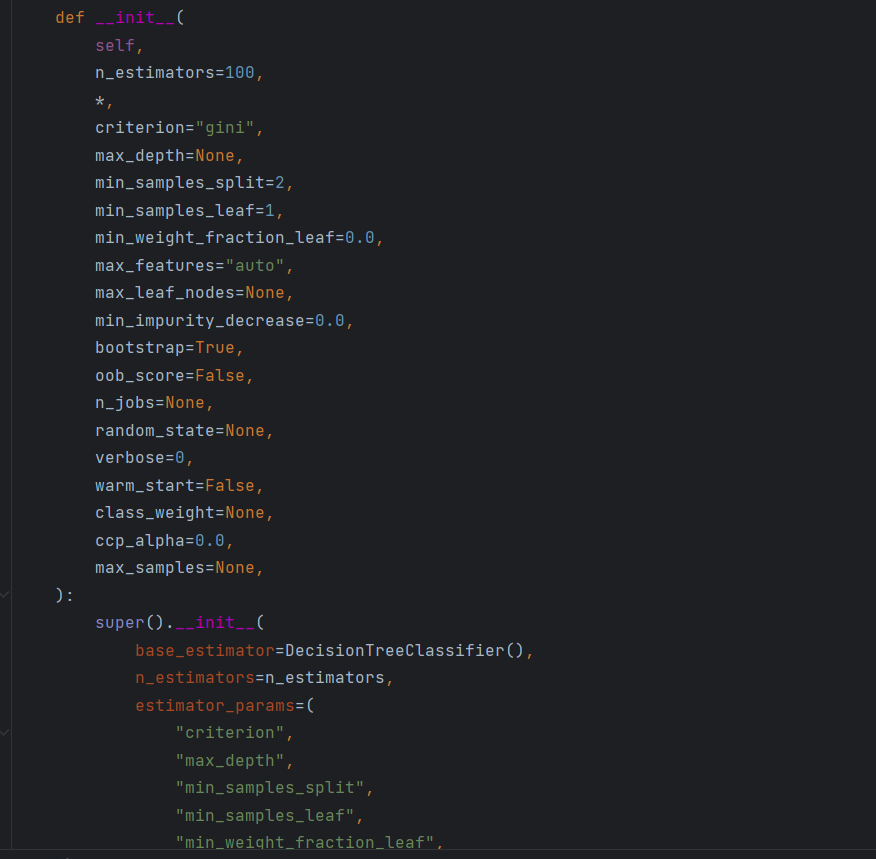
sklearn.ensemble.RandomForestClassifier(n_estimators=10,?? ?criterion=’gini’,?? ?max_depth=None,?? ?bootstrap=True,random_state=None,?? ?min_samples_split=2)
?n_estimators:integer,optional(default?? ?=?? ?10)森林?的樹?數量120,200,300,500,800,1200
在利?最?投票數或平均值來預測之前,你想要建??樹的數量。
Criterion:string,可選(default?? ?=“gini”)
分割特征的測量?法
max_depth:integer或None,可選(默認=?)
樹的最?深度?? ?5,8,15,25,30
?max_features="auto”,每個決策樹的最?特征數量
If?? ?"auto",?? ?then?? ?max_features=sqrt(n_features)?? ?.
?If?? ?"sqrt",?? ?then?? ?max_features=sqrt(n_features)?? ?(same?? ?as?? ?"auto").
?If?? ?"log2",?? ?then?? ?max_features=log2(n_features)?? ?.
?If?? ?None,?? ?then?? ?max_features=n_features?? ?.
?bootstrap:boolean,optional(default?? ?=?? ?True)
是否在構建樹時使?放回抽樣
min_samples_split?? ?內部節點再劃分所需最?樣本數
這個值限制了?樹繼續劃分的條件,如果某節點的樣本數少于min_samples_split,則不會繼續再嘗試選擇最優特征來進?劃分,默認是2。
如果樣本量不?,不需要管這個值。如果樣本量數量級?常?,則推薦增?這個值。
min_samples_leaf?? ?葉?節點的最?樣本數
這個值限制了葉?節點最少的樣本數,如果某葉?節點數??于樣本數,則會和兄弟節點?起被剪枝,默認是1。
葉是決策樹的末端節點。?? ?較?的葉?使模型更容易捕捉訓練數據中的噪聲。
?般來說,我更偏向于將最?葉?節點數?設置為?于50。
min_impurity_split:?? ?節點劃分最?不純度
這個值限制了決策樹的增?,如果某節點的不純度(基于基尼系數,均?差)?于這個閾值,則該節點不再?成?節點。即為葉?節點?? ?。
?般不推薦改動默認值1e-7。
上?決策樹參數中最重要的包括
最?特征數max_features,
最?深度max_depth,
內部節點再劃分所需最?樣本數min_samples_split
葉?節點最少樣本數min_samples_leaf。
五、隨機森林的優缺點
優點:
1.準確率高:通常優于單一決策樹,甚至在很多情況下表現優于 SVM、神經網絡等算法
2. 抗過擬合能力強:通過多棵樹的集成,有效降低了過擬合風險
3. 處理高維數據能力強:不需要特征選擇,可以自動處理高維數據
4. 能處理非線性數據:無需對數據進行復雜轉換
5. 對缺失值不敏感:有較好的容錯能力
6. 可以評估特征重要性:幫助理解數據
缺點:
計算成本高:訓練時間和內存消耗較大(因多棵決策樹)
解釋性較弱:模型解釋性較差(“黑盒”特性),雖然單棵決策樹易解釋,但 "森林" 的整體決策過程難以可視化(可通過特征重要性部分彌補);
對超高維稀疏數據(如文本)可能不如線性模型高效。
六、垃圾郵件判斷案例
1.數據集介紹
我們使用的是經典的spambase.csv數據集,該數據集包含了 4601 條郵件記錄,每條記錄有 57 個特征和 1 個標簽。這些特征主要包括:
郵件中某些特定單詞出現的頻率
某些特定字符出現的頻率
郵件的平均長度、最長連續大寫字母長度等
標簽為 0(正常郵件)或 1(垃圾郵件),我們的目標是根據這些特征預測一封郵件是否為垃圾郵件。
2.代碼解析
(1) 導入必要的庫
from sklearn.ensemble import RandomForestClassifier
from sklearn import metrics
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split這部分代碼導入了后續需要用到的庫:
? RandomForestClassifier:隨機森林分類器,是我們要使用的核心算法
? metrics:sklearn 中的評估指標模塊,用于模型性能評估
? pandas:數據處理庫,用于讀取和處理數據
? matplotlib.pyplot:繪圖庫,用于可視化特征重要性
? train_test_split:用于將數據集分割為訓練集和測試集
(2)?數據讀取與準備
data = pd.read_csv('spambase.csv')使用 pandas 的read_csv函數讀取垃圾郵件數據集spambase.csv,將其存儲在data變量中,這是一個 DataFrame 對象。
X = data.iloc[:, :-1]
y = data.iloc[:, -1]X = data.iloc[:, :-1]:提取所有行,除最后一列外的所有列作為特征數據(特征矩陣)
y = data.iloc[:, -1]:提取所有行的最后一列作為標簽數據(目標變量),其中 1 表示垃圾郵件,0 表示正常郵件
(3) 劃分訓練集和測試集
x_train, x_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=100)使用train_test_split函數將數據集劃分為訓練集和測試集
? test_size=0.2:表示測試集占總數據的 20%,訓練集占 80%
? random_state=100:設置隨機種子,確保每次運行代碼時得到相同的劃分結果,保證實驗的可重復性
? 返回的四個變量分別是:訓練特征、測試特征、訓練標簽、測試標簽
(4)創建并訓練隨機森林模型
rf = RandomForestClassifier(n_estimators=100, max_depth=10, min_samples_split=3)創建隨機森林分類器實例,并設置超參數:
? n_estimators=100:森林中包含 100 棵決策樹
? max_depth=10:每棵樹的最大深度限制為 10,防止樹過度生長導致過擬合
? min_samples_split=3:節點分裂所需的最小樣本數為 3,即當節點樣本數少于 3 時不再分裂
rf.fit(x_train, y_train)使用訓練集對模型進行訓練,fit方法會根據輸入的訓練數據調整模型參數,使模型能夠學習到特征與標簽之間的關系。
(5) 模型預測與評估
predict = rf.predict(x_train)
print(metrics.classification_report(predict, y_train))- 用訓練好的模型對訓練集進行預測,得到預測結果
predict - 使用
classification_report生成詳細的分類評估報告,包括精確率(precision)、召回率(recall)、F1 分數(f1-score)和支持度(support) - 這一步主要是查看模型在訓練數據上的表現,判斷是否存在欠擬合
predict1 = rf.predict(x_test)
print(metrics.classification_report(predict1, y_test))用模型對測試集進行預測,得到預測結果predict1
? 同樣生成分類評估報告,這是評估模型泛化能力的關鍵步驟
? 比較訓練集和測試集的評估結果,可以判斷模型是否過擬合
(6) 特征重要性分析
feature_names = X.columns
feature_importance = pd.DataFrame({'特征名稱': feature_names,'重要性得分': rf.feature_importances_
})X.columns獲取所有特征的名稱
? 創建一個 DataFrame 來存儲特征名稱及其對應的重要性得分
? rf.feature_importances_獲取隨機森林計算出的各特征重要性得分,得分越高表示該特征對分類結果的影響越大
feature_importance = feature_importance.sort_values(by='重要性得分', ascending=False)
print(feature_importance.head(10))按 "重要性得分" 降序排列特征
打印出前 10 個最重要的特征,幫助我們理解哪些特征對垃圾郵件分類最關鍵
(7)特征重要性可視化
plt.rcParams["font.sans-serif"] = ["SimHei"]
plt.rcParams["axes.unicode_minus"] = False設置 matplotlib 的字體參數,確保中文能正常顯示,避免負號顯示異常。
top_features = feature_importance.head(10)
plt.figure(figsize=(12, 8))
bars = plt.barh(top_features['特征名稱'], top_features['重要性得分'], color='skyblue')
plt.title('隨機森林模型中前10個重要特征的重要性得分', fontsize=14)
plt.xlabel('重要性得分', fontsize=12)
plt.ylabel('特征名稱', fontsize=12)
plt.show()提取前 10 個最重要的特征
創建一個大小為 12x8 的圖形
使用水平條形圖barh可視化這些特征的重要性得分
設置圖表標題、x 軸標簽和 y 軸標簽
plt.show()顯示圖表
完整代碼如下:
from sklearn.ensemble import RandomForestClassifier
from sklearn import metrics
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
data=pd.read_csv('spambase.csv')
X=data.iloc[:,:-1]
y=data.iloc[:,-1]
x_train,x_test,y_train,y_test=train_test_split(X,y,test_size=0.2,random_state=100)
rf=RandomForestClassifier(n_estimators=100,max_depth=10,min_samples_split=3)
rf.fit(x_train,y_train)
predict=rf.predict(x_train)
print(metrics.classification_report(predict,y_train))
predict1=rf.predict(x_test)
print(metrics.classification_report(predict1,y_test))
feature_names = X.columns
feature_importance = pd.DataFrame({'特征名稱': feature_names,'重要性得分': rf.feature_importances_
})
feature_importance = feature_importance.sort_values(by='重要性得分', ascending=False)
print(feature_importance.head(10))
plt.rcParams["font.sans-serif"] = ["SimHei"]
plt.rcParams["axes.unicode_minus"] = False
top_features = feature_importance.head(10)
plt.figure(figsize=(12, 8))
bars = plt.barh(top_features['特征名稱'], top_features['重要性得分'], color='skyblue')
plt.title('隨機森林模型中前10個重要特征的重要性得分', fontsize=14)
plt.xlabel('重要性得分', fontsize=12)
plt.ylabel('特征名稱', fontsize=12)
plt.show()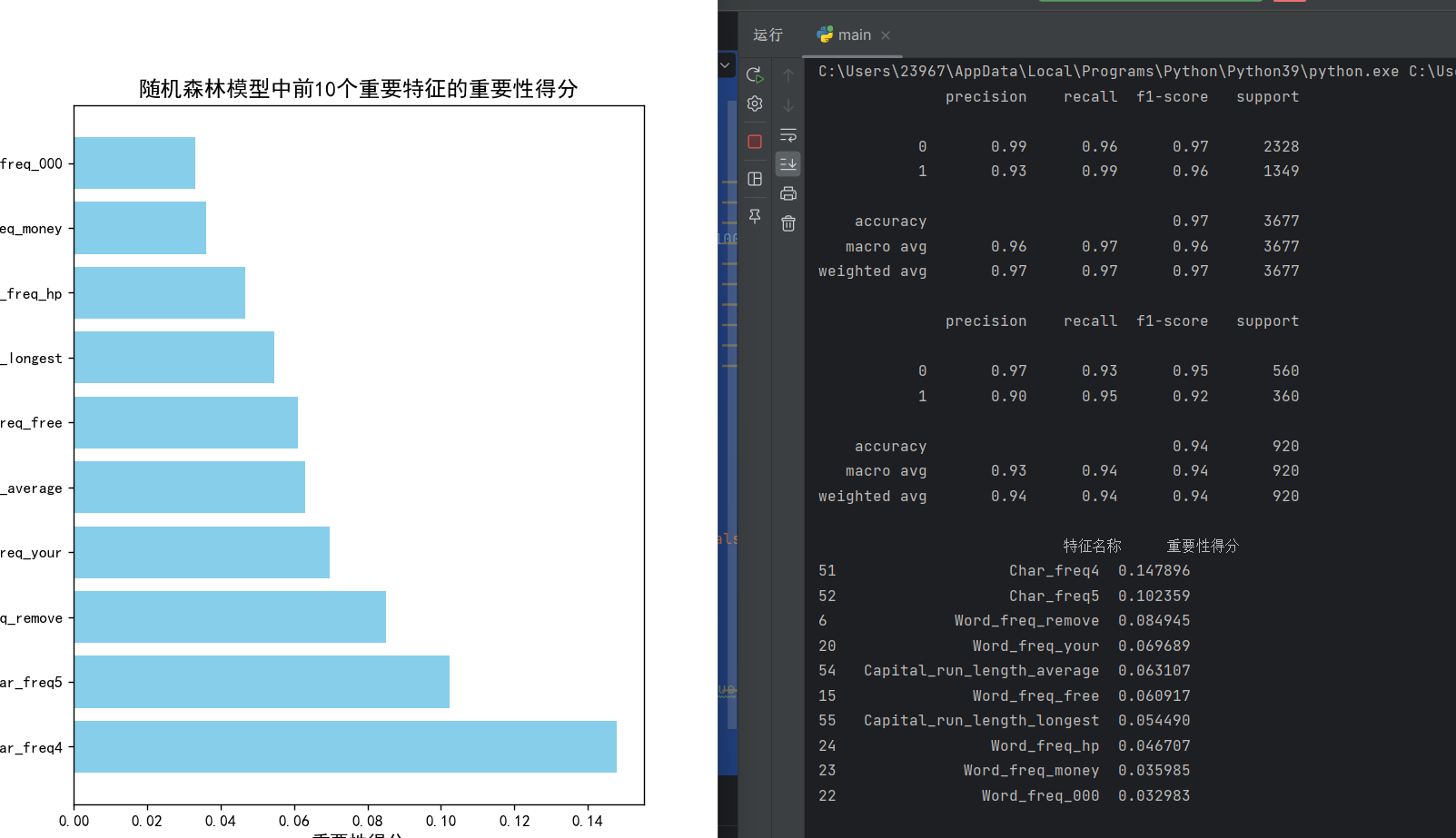





![P1044 [NOIP 2003 普及組] 棧](http://pic.xiahunao.cn/P1044 [NOIP 2003 普及組] 棧)







和BERT技術概述)




決策樹算法)
