目錄
一、決策樹概述
1.1 概述
1.2 基本數學原理
二、熵原理形象解讀與計算
2.1 熵的概念
2.2 熵的計算示例
2.3 條件熵
三、決策樹構造實例
3.1 數據集示例
3.2 計算信息增益
3.3 遞歸構建決策樹
四、信息增益和信息增益率
4.1 信息增益的缺陷
4.2 信息增益率
4.3 信息增益與信息增益率的比較
五、三種決策樹算法
5.1 ID3算法
5.2 C4.5算法
5.3 CART決策樹
ps.三種決策樹算法的比較
六、決策樹剪枝
6.1 過擬合問題
6.2 剪枝方法
6.3 CART剪枝算法
第七部分:決策樹案例實戰與參數分析
7.1 案例一:電信客戶流失預測分析
案例背景
代碼實現詳解
實現步驟解析
關鍵點說明
7.2 案例二:客戶流失預測進階分析
案例背景
代碼實現詳解
實現步驟解析
進階技巧說明
7.3 sklearn決策樹參數深度解析
核心參數詳解
關鍵參數應用場景
參數調優實戰策略
參數選擇經驗法則
總結
一、決策樹概述
1.1 概述
決策樹(Decision Tree)是一種基本的分類與回歸方法,它通過構建樹狀結構來進行決策。決策樹模型呈樹形結構,在分類問題中,表示基于特征對實例進行分類的過程。它可以被認為是if-then規則的集合,也可以被認為是定義在特征空間與類空間上的條件概率分布。
決策樹學習通常包括三個步驟:
- ??特征選擇??:選擇最優劃分特征
- ??決策樹生成??:遞歸構建決策樹
- ??決策樹剪枝??:防止過擬合
決策樹的主要優點:
- 模型具有可解釋性,容易向業務人員解釋
- 能夠處理數值型和類別型數據
- 不需要對數據進行復雜的預處理(如標準化)
- 可以通過可視化直觀展示模型邏輯
1.2 基本數學原理
決策樹的核心是通過遞歸地選擇最優特征進行數據劃分。在選擇劃分特征時,我們需要一個衡量標準來判斷劃分的好壞。常用的標準有:
- ??信息增益??(ID3算法使用)
- ??信息增益比??(C4.5算法使用)
- ??基尼指數??(CART算法使用)
這些標準都基于信息論中的熵概念,我們將在下一節詳細介紹熵的原理。
決策樹的數學本質是一個分段常數函數,它將特征空間劃分為若干互不重疊的區域(R?到R?),每個區域對應一個確定的預測值(c?到c?)。當輸入樣本x落入某個區域R?時,模型就輸出該區域對應的值c?。這種劃分通過遞歸的"if-then"規則實現,最終形成樹狀結構。
二、熵原理形象解讀與計算
2.1 熵的概念
熵(Entropy)是信息論中用于度量信息不確定性的概念。在決策樹中,熵用來衡量數據集的不純度。熵越大,表示數據集的不確定性越高。
熵的數學定義為:
對于一個概率分布P=(p?, p?, ..., p?),其熵H(P)定義為:
H(P) = -∑_{i=1}^n p_i · log?(p_i)
其中,p_i是第i類樣本所占的比例,log?以2為底的對數使得熵的單位為比特(bit)。
2.2 熵的計算示例
假設我們有一個二分類數據集,其中正例占比為p,負例占比為1-p,則其熵為:
H(p) = -p·log?(p) - (1-p)·log?(1-p)
我們來看幾個特殊值:
- 當p=0或p=1時,H(p)=0,表示數據集完全純凈
- 當p=0.5時,H(p)=1,表示數據集最混亂
2.3 條件熵
條件熵H(Y|X)表示在已知隨機變量X的條件下,隨機變量Y的不確定性。定義為:
H(Y|X) = ∑_{x∈X} p(x)·H(Y|X=x)
在決策樹中,我們通過計算特征劃分前后的熵變化來選擇最優劃分特征。
三、決策樹構造實例
3.1 數據集示例
我們通過一個簡單的例子來說明決策樹的構造過程。假設有以下天氣數據集,用于判斷是否適合打網球:
| 天氣 | 溫度 | 濕度 | 風力 | 是否打球 |
|---|---|---|---|---|
| 晴 | 高 | 高 | 弱 | 否 |
| 晴 | 高 | 高 | 強 | 否 |
| 陰 | 高 | 高 | 弱 | 是 |
| 雨 | 中 | 高 | 弱 | 是 |
| 雨 | 低 | 正常 | 弱 | 是 |
| 雨 | 低 | 正常 | 強 | 否 |
| 陰 | 低 | 正常 | 強 | 是 |
| 晴 | 中 | 高 | 弱 | 否 |
| 晴 | 低 | 正常 | 弱 | 是 |
| 雨 | 中 | 正常 | 弱 | 是 |
| 晴 | 中 | 正常 | 強 | 是 |
| 陰 | 中 | 高 | 強 | 是 |
| 陰 | 高 | 正常 | 弱 | 是 |
| 雨 | 中 | 高 | 強 | 否 |
3.2 計算信息增益
首先計算整個數據集的熵:
- 打球(是):9例
- 不打球(否):5例
- 總樣本數:14例
H(D) = - (9/14)·log?(9/14) - (5/14)·log?(5/14) ≈ 0.940
然后計算以"天氣"為劃分特征的條件熵:
- 晴:5例(2是,3否)
- 陰:4例(4是,0否)
- 雨:5例(3是,2否)
H(D|天氣) = (5/14)·H(晴) + (4/14)·H(陰) + (5/14)·H(雨)
= (5/14)·(-(2/5)log?(2/5)-(3/5)log?(3/5)) + (4/14)·0 + (5/14)·(-(3/5)log?(3/5)-(2/5)log?(2/5))
≈ 0.694
信息增益:
Gain(天氣) = H(D) - H(D|天氣) ≈ 0.940 - 0.694 = 0.246
類似地可以計算其他特征的信息增益,選擇信息增益最大的特征作為根節點。
3.3 遞歸構建決策樹
按照上述方法遞歸地對每個子節點選擇最優劃分特征,直到:
- 所有樣本屬于同一類別
- 沒有剩余特征可用于劃分
- 達到預定義的停止條件(如最大深度)
四、信息增益和信息增益率
4.1 信息增益的缺陷
信息增益傾向于選擇取值較多的特征,因為這類特征往往能夠將數據集劃分得更細,從而獲得更高的信息增益。但這可能導致過擬合問題。
4.2 信息增益率
為了克服信息增益的缺陷,C4.5算法引入了信息增益率(Gain Ratio),定義為:
即:GR(D,A) = Gain(D,A) / SplitInfo(D,A)
其中SplitInfo(D,A)是特征A的固有值(Intrinsic Value),表示特征A將數據集D劃分的信息量:
信息增益率通過除以特征的固有值來懲罰取值較多的特征。
4.3 信息增益與信息增益率的比較
- 信息增益:傾向于選擇取值較多的特征
- 信息增益率:傾向于選擇取值較少的特征
- 實際應用中,通常先計算信息增益高于平均水平的特征,再從中選擇信息增益率最高的特征
五、三種決策樹算法
5.1 ID3算法
ID3(Iterative Dichotomiser 3)是最早的決策樹算法,由Ross Quinlan于1986年提出。
??特點??:
- 使用信息增益作為特征選擇標準
- 只能處理離散型特征
- 不能處理缺失值
- 容易過擬合,沒有剪枝步驟
- 傾向于選擇取值較多的特征
??算法步驟??:
- 計算所有特征的信息增益
- 選擇信息增益最大的特征作為當前節點的劃分特征
- 對每個子節點遞歸執行上述步驟,直到:
- 所有樣本屬于同一類別
- 沒有剩余特征可用于劃分
5.2 C4.5算法
C4.5是ID3的改進算法,同樣由Quinlan提出。
??改進點??:
- 使用信息增益率代替信息增益
- 能夠處理連續型特征(通過離散化)
- 能夠處理缺失值
- 加入了剪枝步驟防止過擬合
- 可以生成規則集
??處理連續特征的方法??:
- 對連續特征的值進行排序
- 計算相鄰值的中間點作為候選劃分點
- 選擇信息增益率最高的劃分點
5.3 CART決策樹
CART(Classification And Regression Tree)由Breiman等人于1984年提出。
??特點??:
- 可以用于分類和回歸任務
- 分類樹使用基尼指數作為劃分標準
- 回歸樹使用平方誤差最小化作為劃分標準
- 二叉樹結構(每個節點只有兩個子節點)
- 有完善的剪枝方法
??基尼指數??:
基尼指數(Gini Index)是另一種衡量數據集不純度的指標:
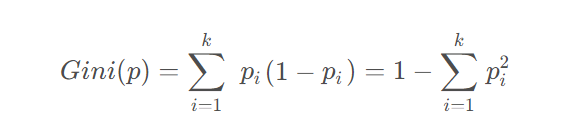
其中p_k是第k類樣本的比例。基尼指數越小,數據集純度越高。
- p:數據集
- k:類別總數量
p_i:數據集中第i類樣本的占比
??CART分類樹的構建??:
- 對每個特征A,計算其每個可能取值的基尼指數
- 選擇基尼指數最小的特征和取值作為最優劃分
- 遞歸地對子節點執行上述步驟
??CART回歸樹的構建??:
- 對每個特征A,尋找最優切分點s,使得:
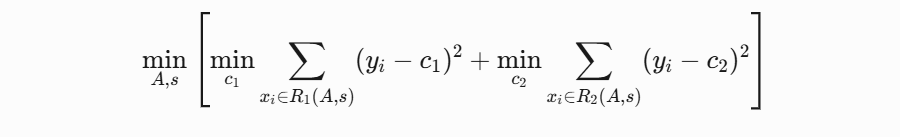
其中R1、R2是劃分后的兩個區域,c1、c2是兩個區域的輸出均值
-
A和?s是劃分區域的參數(例如,分割變量和分割點)
-
R1?(A,s)和?R2?(A,s)是由?A和?s定義的區域
-
c1?和?c2?分別是區域?R1?和?R2?內的最優常數(通常是區域內的均值)
- 遞歸地對子區域執行上述劃分
ps.三種決策樹算法的比較
| 算法 | 任務類型 | 特征選擇指標 | 樹結構 | 優勢 | 缺點 |
|---|---|---|---|---|---|
| ID3 | 分類 | 信息增益 | 多叉樹 | 簡單直觀 | 不支持連續特征,易過擬合 |
| C4.5 | 分類 | 信息增益率 | 多叉樹 | 支持連續特征、缺失值處理 | 計算復雜,不支持回歸 |
| CART | 分類 / 回歸 | 基尼指數(分類)、MSE(回歸) | 二叉樹 | 可處理分類和回歸,效率高 | 對不平衡數據敏感 |
六、決策樹剪枝
6.1 過擬合問題
決策樹容易過擬合,特別是當樹深度較大時。過擬合表現為在訓練集上表現很好,但在測試集上表現較差。
6.2 剪枝方法
剪枝(Pruning)是解決過擬合的主要方法,分為預剪枝和后剪枝:
??預剪枝(Pre-Pruning)??:
在樹構建過程中提前停止樹的生長。常用方法包括:
- 設置最大深度
- 設置葉子節點最小樣本數
- 設置信息增益/基尼指數閾值
??后剪枝(Post-Pruning)??:
先構建完整的樹,然后自底向上剪枝。常用方法包括:
- 代價復雜度剪枝(Cost Complexity Pruning)
- 悲觀剪枝(Pessimistic Pruning)
- 最小誤差剪枝(Minimum Error Pruning)
6.3 CART剪枝算法
CART采用代價復雜度剪枝,定義樹的代價復雜度:
Cα(T) = C(T) + α·|T|
其中:
- Cα(T):優化后的成本函數
- C(T)是樹T在訓練數據上的誤差(原始成本函數)
- |T|:模型復雜度(如決策樹的葉子節點數)
- α是正則化系數
剪枝過程:
- 從完整樹T0開始,生成子樹序列T1, T2, ..., Tn,其中Ti+1是Ti的最優子樹
- 通過交叉驗證選擇最優子樹
第七部分:決策樹案例實戰與參數分析
7.1 案例一:電信客戶流失預測分析
案例背景
??數據集說明??:
- 數據維度:601個樣本,17個特征
- 特征說明:
- 在網月數:客戶使用電信服務的時間(月)
- 年齡:客戶年齡
- 婚姻狀況:客戶婚姻狀態
- 現地址住居時間:在當前地址居住時間
- 教育程度:客戶教育水平
- 工作狀態:就業狀況
- 性別:客戶性別
- 租設備:是否租賃設備
- IP電話:是否使用IP電話服務
- 無線電話:是否使用無線電話服務
- 本月話費:當月消費金額
- 語音信箱:是否使用語音信箱
- 網絡:是否使用網絡服務
- 來電顯示:是否使用來電顯示
- 呼叫等待:是否使用呼叫等待
- 呼叫轉移:是否使用呼叫轉移
- 流失狀態(標簽):客戶是否流失(二元分類)
??業務背景??:
電信行業客戶流失預測是客戶關系管理的重要組成部分。通過分析客戶特征和行為數據,建立預測模型識別可能流失的客戶,從而采取針對性的客戶保留措施,降低客戶流失率,提高企業收益。
代碼實現詳解
# 可視化混淆矩陣函數
def cm_plot(y, yp):from sklearn.metrics import confusion_matriximport matplotlib.pyplot as plt# 計算混淆矩陣:真實值y與預測值yp的混淆矩陣cm = confusion_matrix(y, yp)# 使用熱圖顯示混淆矩陣,顏色使用藍色漸變plt.matshow(cm, cmap=plt.cm.Blues)plt.colorbar() # 添加顏色條# 在熱圖中添加數值標注for x in range(len(cm)):for y in range(len(cm)):# 在每個單元格中心位置添加數值plt.annotate(cm[x,y], xy=(y,x),horizontalalignment='center', # 水平居中verticalalignment='center') # 垂直居中# 添加坐標軸標簽plt.ylabel('True label') # y軸為真實標簽plt.xlabel('Predicted label') # x軸為預測標簽return plt# 數據加載與預處理
# 使用pandas讀取Excel格式的數據文件
datas = pd.read_excel("電信客戶流失數據.xlsx")# 特征與標簽分離
# iloc[:, :-1]選取所有行和除最后一列外的所有列作為特征
data = datas.iloc[:,:-1]
# iloc[:, -1]選取所有行和最后一列作為標簽
target = datas.iloc[:,-1]# 數據集劃分
from sklearn.model_selection import train_test_split# 使用train_test_split劃分訓練集和測試集
# test_size=0.2表示測試集占20%
# random_state=42保證每次劃分結果相同(可復現性)
data_train, data_test, target_train, target_test = \train_test_split(data, target, test_size=0.2, random_state=42)# 決策樹模型構建
from sklearn import tree# 創建決策樹分類器對象
# criterion='gini':使用基尼系數作為劃分標準
# max_depth=8:限制樹的最大深度為8層,防止過擬合
# random_state=42:保證模型可復現
dtr = tree.DecisionTreeClassifier(criterion='gini', max_depth=8, random_state=42)# 模型訓練:使用訓練集數據擬合決策樹模型
dtr.fit(data_train, target_train)# 訓練集性能評估
# 使用訓練好的模型對訓練集進行預測
train_predicted = dtr.predict(data_train)from sklearn import metrics
# 打印分類報告:包含精確率、召回率、F1值等指標
print("訓練集分類報告:")
print(metrics.classification_report(target_train, train_predicted))# 可視化訓練集混淆矩陣
print("訓練集混淆矩陣:")
cm_plot(target_train, train_predicted).show() # 測試集性能評估
# 使用訓練好的模型對測試集進行預測
test_predicted = dtr.predict(data_test)# 打印測試集分類報告
print("測試集分類報告:")
print(metrics.classification_report(target_test, test_predicted))# 可視化測試集混淆矩陣
print("測試集混淆矩陣:")
cm_plot(target_test, test_predicted).show() # 計算模型在測試集上的準確率
print("測試集準確率:", dtr.score(data_test, target_test))# 決策樹可視化
import matplotlib.pyplot as plt
from sklearn.tree import plot_tree# 創建大尺寸圖像(32x32英寸)以清晰顯示決策樹
fig, ax = plt.subplots(figsize=(32, 32)) # 繪制決策樹
# filled=True:填充顏色表示類別
plot_tree(dtr, filled=True, ax=ax)
plt.title("決策樹可視化") # 添加標題
plt.show()實現步驟解析
-
??數據準備階段??:
- 加載電信客戶流失數據集
- 分離特征和標簽
- 劃分訓練集和測試集(80%訓練,20%測試)
-
??模型構建階段??:
- 創建決策樹分類器
- 設置基尼系數作為劃分標準
- 限制樹的最大深度為8層防止過擬合
- 使用訓練數據擬合模型
-
??模型評估階段??:
- 在訓練集和測試集上分別進行預測
- 生成分類報告(精確率、召回率、F1值)
- 可視化混淆矩陣
- 計算準確率指標
-
??模型可視化??:
- 使用plot_tree繪制完整的決策樹結構
- 調整圖像尺寸確保節點清晰可見
關鍵點說明
-
??數據劃分??:
- 使用random_state保證每次劃分結果一致,便于結果復現
- 保持訓練集和測試集的比例合理(通常70-80%訓練)
-
??模型參數??:
- max_depth=8是經過調優的參數,平衡了模型復雜度和泛化能力
- 使用基尼系數而非信息增益,計算效率更高且效果相當
-
??評估指標??:
- 關注測試集而非訓練集的表現,反映模型真實泛化能力
- 混淆矩陣直觀展示分類錯誤分布
-
??可視化??:
- 大尺寸圖像確保復雜的決策樹結構清晰可讀
- 顏色填充幫助快速識別不同類別
7.2 案例二:客戶流失預測進階分析
案例背景
??數據集說明??:
- 數據維度:601個樣本,17個特征(與案例一相同數據,但特征名稱為英文)
- 特征說明:
- months:在網月數
- age:年齡
- marry:婚姻狀況
- duration:現地址住居時間
- edu:教育程度
- work:工作狀態
- sex:性別
- rent:租設備
- phone:IP電話
- cellphone:無線電話
- huafei:本月話費
- vmail:語音信箱
- net:網絡
- ring:來電顯示
- wait:呼叫等待
- move:呼叫轉移
- station(標簽):流失狀態
??分析目標??:
在案例一基礎上,進一步優化模型參數,探索更精細的決策樹調參策略,并通過更專業的可視化方法展示決策樹結構。
代碼實現詳解
import pandas as pd# 增強版混淆矩陣可視化函數
def cm_plot(y, yp):from sklearn.metrics import confusion_matriximport matplotlib.pyplot as plt# 計算混淆矩陣cm = confusion_matrix(y, yp)# 創建熱圖,使用藍色漸變配色plt.matshow(cm, cmap=plt.cm.Blues)plt.colorbar() # 添加顏色條# 添加數值標注for x in range(len(cm)):for y in range(len(cm)):# 在單元格中心位置顯示數值,設置字體顏色根據背景深淺自動調整plt.annotate(cm[x,y], xy=(y,x),horizontalalignment='center',verticalalignment='center',color='white' if cm[x,y] > cm.max()/2 else 'black')# 添加坐標軸標簽和標題plt.ylabel('True label')plt.xlabel('Predicted label')plt.title('Confusion Matrix')return plt# 數據加載與預處理
# 讀取Excel數據文件
datas = pd.read_excel("電信客戶流失數據2.xlsx")# 特征與標簽分離
# 使用iloc基于位置索引選取數據
data = datas.iloc[:,:-1] # 所有特征列
target = datas.iloc[:,-1] # 最后一列是標簽# 數據集劃分
from sklearn.model_selection import train_test_split# 劃分訓練集和測試集
# test_size=0.2:測試集占比20%
# random_state=0:固定隨機種子保證可復現性
data_train, data_test, target_train, target_test = \train_test_split(data, target, test_size=0.2, random_state=0)# 決策樹模型構建與調優
from sklearn import tree # 創建調優后的決策樹分類器
# criterion='gini':使用基尼系數
# max_depth=10:增大最大深度嘗試捕捉更多模式
# min_samples_leaf=5:設置葉節點最小樣本數為5,防止過擬合
# random_state=0:固定隨機種子
dtr = tree.DecisionTreeClassifier(criterion='gini', max_depth=10,min_samples_leaf=5,random_state=0)# 模型訓練
dtr.fit(data_train, target_train)# 訓練集評估
train_predicted = dtr.predict(data_train)from sklearn import metrics
# 生成詳細的分類報告
print("訓練集性能評估:")
print(metrics.classification_report(target_train, train_predicted))# 可視化訓練集混淆矩陣
print("訓練集混淆矩陣:")
cm_plot(target_train, train_predicted).show() # 測試集評估
test_predicted = dtr.predict(data_test)# 生成測試集分類報告
print("測試集性能評估:")
print(metrics.classification_report(target_test, test_predicted))# 可視化測試集混淆矩陣
print("測試集混淆矩陣:")
cm_plot(target_test, test_predicted).show() # 計算并打印測試集準確率
accuracy = dtr.score(data_test, target_test)
print(f"測試集準確率:{accuracy:.4f}")# 高級決策樹可視化
# 導出決策樹為Graphviz格式
dot_data = tree.export_graphviz(dtr,out_file=None, # 不輸出到文件feature_names=data.columns, # 使用特征名作為節點標簽filled=True, # 填充顏色impurity=False, # 不顯示不純度rounded=True # 圓角節點)# 使用pydotplus渲染決策樹
import pydotplus
graph = pydotplus.graph_from_dot_data(dot_data)# 自定義節點顏色(示例:修改第7個節點的填充色)
graph.get_nodes()[7].set_fillcolor("#FFF2DD")# 在Jupyter Notebook中顯示圖像
from IPython.display import Image
Image(graph.create_png())# 將決策樹保存為PNG圖像文件
graph.write_png("dtr_advanced.png")
print("決策樹已保存為dtr_advanced.png")實現步驟解析
-
??數據準備階段??:
- 加載英文特征名的相同數據集
- 使用iloc方法確保正確分離特征和標簽
- 保持與案例一相同的劃分比例和隨機種子
-
??模型調優階段??:
- 增大max_depth至10,嘗試捕捉更復雜模式
- 設置min_samples_leaf=5,確保葉節點有足夠樣本
- 保持基尼系數作為劃分標準
-
??增強可視化??:
- 改進混淆矩陣顯示,添加自適應文本顏色
- 使用Graphviz生成更專業的決策樹可視化
- 自定義節點顏色增強可讀性
- 將決策樹導出為高質量PNG圖像
-
??評估與分析??:
- 對比訓練集和測試集表現,分析模型泛化能力
- 關注精確率、召回率等細粒度指標
- 通過可視化識別重要特征和決策路徑
進階技巧說明
-
??參數調優??:
- max_depth從8增加到10,允許更復雜的決策邊界
- 通過min_samples_leaf=5防止葉節點過擬合
- 平衡模型復雜度和泛化能力
-
??可視化增強??:
- Graphviz提供的可視化比matplotlib更專業
- 節點顏色填充幫助快速理解決策邏輯
- 特征名稱直接顯示提高可解釋性
-
??模型解釋??:
- 通過生成的決策樹可以直觀看到重要特征
- 分析關鍵決策路徑有助于業務理解
- 識別影響客戶流失的主要因素
7.3 sklearn決策樹參數深度解析
核心參數詳解
class sklearn.tree.DecisionTreeClassifier(criterion='gini', # 分裂質量衡量標準splitter='best', # 分裂策略選擇max_depth=None, # 樹的最大深度min_samples_split=2, # 分裂所需最小樣本數min_samples_leaf=1, # 葉節點最小樣本數min_weight_fraction_leaf=0.0, # 葉節點最小權重和max_features=None, # 考慮的最大特征數random_state=None, # 隨機種子max_leaf_nodes=None, # 最大葉節點數min_impurity_decrease=0.0, # 分裂所需最小不純度減少min_impurity_split=None, # 分裂閾值(已棄用)class_weight=None, # 類別權重presort=False # 預排序(已棄用)
)關鍵參數應用場景
-
??max_depth??:
- ??作用??:控制樹的最大深度,防止過擬合
- ??調優建議??:
- 從3-10開始嘗試,通過交叉驗證選擇最優值
- 數據特征多時可適當增大
- 可視化決策樹輔助確定合理深度
-
??min_samples_split??和??min_samples_leaf??:
- ??區別??:
- min_samples_split控制節點是否可以繼續分裂
- min_samples_leaf保證葉節點的最小樣本量
- ??設置建議??:
- 對于大數據集(>10k樣本),可設為0.1%或1%
- 對于小數據集,保持默認或設為5-10
- ??區別??:
-
??criterion??:
- ??選擇依據??:
- 'gini':計算更快,適合大多數情況
- 'entropy':生成更平衡的樹,但計算量略大
- ??經驗??:
- 兩者效果通常相似
- 當特征有較多類別時,熵可能更合適
- ??選擇依據??:
-
??max_features??:
- ??作用??:限制每次分裂考慮的特征數,增加隨機性
- ??推薦值??:
- None:考慮所有特征(默認)
- 'sqrt':平方根數量,適用于特征較多時
- 0.2-0.3:特征非常多時可嘗試
-
??class_weight??:
- ??不平衡數據處理??:
- None:假設類別平衡
- 'balanced':自動按類別頻率調整權重
- 字典:手動指定類別權重
- ??應用場景??:
- 當正負樣本比例大于1:5時建議使用
- 特別關注少數類的預測準確率時
- ??不平衡數據處理??:
參數調優實戰策略
-
??基礎調優流程??:
- 固定random_state確保結果可復現
- 先設置max_depth尋找合理樹深度
- 再調整min_samples_leaf防止過擬合
- 最后考慮class_weight處理不平衡數據
-
??網格搜索示例??:
from sklearn.model_selection import GridSearchCVparam_grid = {'max_depth': [3, 5, 7, 10],'min_samples_leaf': [1, 3, 5, 10],'class_weight': [None, 'balanced']
}grid_search = GridSearchCV(tree.DecisionTreeClassifier(random_state=42),param_grid,cv=5,scoring='f1'
)
grid_search.fit(data_train, target_train)print("最優參數:", grid_search.best_params_)
print("最佳分數:", grid_search.best_score_)- ??學習曲線分析??:
- 繪制不同max_depth對應的訓練/驗證分數
- 觀察過擬合和欠擬合點
- 選擇驗證分數最高的參數
參數選擇經驗法則
-
??大數據集??:
- 增大max_depth和min_samples_leaf
- 考慮使用max_features
- 可能需要限制max_leaf_nodes
-
??高維數據??:
- 優先使用'gini'降低計算成本
- 設置max_features='sqrt'
- 適當增大min_samples_split
-
??不平衡數據??:
- 使用class_weight='balanced'
- 關注召回率而非準確率
- 可能需降低min_samples_leaf
-
??過擬合問題??:
- 減小max_depth
- 增大min_samples_leaf
- 嘗試設置max_leaf_nodes
通過系統化的參數調優和業務理解,可以構建出既準確又具有良好解釋性的決策樹模型,為電信客戶流失預測等業務問題提供可靠的數據支持。
總結
決策樹是一種強大且易于理解的機器學習算法,具有以下特點:
- 直觀易懂,可以可視化展示
- 能夠處理數值型和類別型數據
- 不需要復雜的特征預處理
- 可以通過剪枝防止過擬合
在實際應用中,需要注意:
- 選擇合適的劃分標準(基尼指數/信息增益)
- 合理設置樹的最大深度等參數防止過擬合
- 對于類別不平衡數據調整類別權重
- 使用交叉驗證評估模型性能
決策樹也是許多集成方法(如隨機森林、梯度提升樹)的基礎,理解決策樹有助于學習更復雜的集成算法。


)






線性規劃+多項式回歸+邏輯回歸+決策樹)
)






(1天))

