文章目錄
- 1、 消息隊列的作用什么?
- 思:消息隊列是什么?
- 消息隊列的定義
- 消息隊列的工作原理
- 消息隊列的作用
- 消息隊列的常見類型
- 消息隊列的簡單例子
- 2、Kafka 集群的架構是什么樣子的?
- 3、Kafka 消費者組和生產者組是什么?
- 定義與核心作用
- 關鍵機制
- 典型場景
- `切記`
- 常見問題解答
- Q1:消費者組內多個消費者如何避免重復消費?
- Q2:生產者如何實現消息的順序性?
- Q3:消費者組能否消費多個主題?
- 4、 Kafka 如何保證消息的的不丟失?
- 5、Kafka 為什么性能高?比 RocketMQ 吞吐率高的根本原因是什么?
- 1、順序磁盤 I/O 的極致利用
- 2、零拷貝(Zero-Copy)技術`(核心、根本)`
- 3、頁緩存(Page Cache)優先策略
- 4、批量處理與高效壓縮
- 6、 Kafka 如何保證消息的順序消費?
1、 消息隊列的作用什么?
1. 解耦
定義:解耦是指將系統中的各個組件或模塊之間的直接依賴關系降低,使它們之間的交互更加靈活和獨立。
實現原理:生產者將消息發送到消息隊列中,消費者從隊列中獲取消息進行處理。生產者和消費者之間不再直接通信,而是通過消息隊列這個中間件進行交互。
應用場景:在電商系統中,訂單系統和庫存系統可以通過消息隊列進行通信。訂單系統生成訂單后,將訂單信息發送到消息隊列,庫存系統從隊列中獲取訂單信息并處理庫存更新。即使庫存系統暫時不可用,訂單系統也可以正常運行,不會受到影響。
2. 異步通信
定義:異步通信是指生產者發送消息后,不需要等待消費者立即處理消息,而是可以繼續執行其他任務。
實現原理:消息隊列允許生產者將消息發送到隊列后立即返回,消費者則根據自己的處理能力從隊列中拉取消息進行處理。
應用場景:在用戶注冊場景中,主流程(如數據庫寫入)完成后,非關鍵操作(如發送郵件、短信通知)可以通過消息隊列異步處理。這樣可以快速響應用戶請求,提高用戶體驗。
3. 削峰填谷
定義:削峰填谷是指通過消息隊列緩沖瞬時高流量,將其平滑為持續的低流量,避免系統因瞬時高并發而崩潰。
實現原理:當生產者生成消息的速度超過消費者處理的速度時,消息會被存儲在隊列中,消費者按固定速率消費消息。這樣可以減少對消費者的壓力,防止系統因突發高負載而崩潰。
應用場景:在秒殺活動或雙十一等高流量場景中,用戶下單請求量激增。通過將請求寫入消息隊列,后臺服務按能力處理,避免瞬時壓力導致系統崩潰。
思:消息隊列是什么?
消息隊列的定義
消息隊列(Message Queue,簡稱MQ)是一種中間件,用于在應用程序之間傳遞消息。它允許一個或多個生產者(消息的發送者)將消息發送到隊列中,同時允許一個或多個消費者(消息的接收者)從隊列中讀取消息。消息隊列的主要功能是存儲和轉發消息,從而實現應用程序之間的通信。
消息隊列的工作原理
生產者(Producer):生產者是消息的發送方,它將消息發送到消息隊列中。
消息隊列(Message Queue):消息隊列是一個中間存儲,用于暫存消息。它是一個先進先出(FIFO)的隊列。
消費者(Consumer):消費者是消息的接收方,它從消息隊列中讀取消息并進行處理。
消息隊列的作用
解耦:生產者和消費者之間不需要直接通信,通過消息隊列間接交互。
異步通信:生產者發送消息后可以繼續執行其他任務,不需要等待消費者處理。
削峰填谷:緩沖瞬時高流量,平滑負載。
消息隊列的常見類型
點對點(Point-to-Point):一個消息只能被一個消費者消費。
發布-訂閱(Publish-Subscribe):一個消息可以被多個消費者消費。
消息隊列的常見實現
Apache Kafka:高性能、分布式的消息隊列,適合高吞吐量場景。
RabbitMQ:支持多種協議,功能豐富,適合多種應用場景。
ActiveMQ:功能強大的消息中間件,支持多種消息協議。
RocketMQ:高性能、高吞吐量的消息隊列,適合大規模分布式系統。
消息隊列的簡單例子
假設你有一個電商系統,用戶下單后需要發送郵件通知用戶。如果沒有消息隊列,下單模塊需要直接調用郵件發送模塊,這會導致以下問題:
如果郵件發送模塊不可用,下單模塊也會失敗。
下單模塊需要等待郵件發送完成才能返回,用戶體驗差。
使用消息隊列后:
下單模塊將訂單信息發送到消息隊列。
郵件發送模塊從消息隊列中讀取訂單信息并發送郵件。
下單模塊不需要等待郵件發送完成,用戶體驗更好。
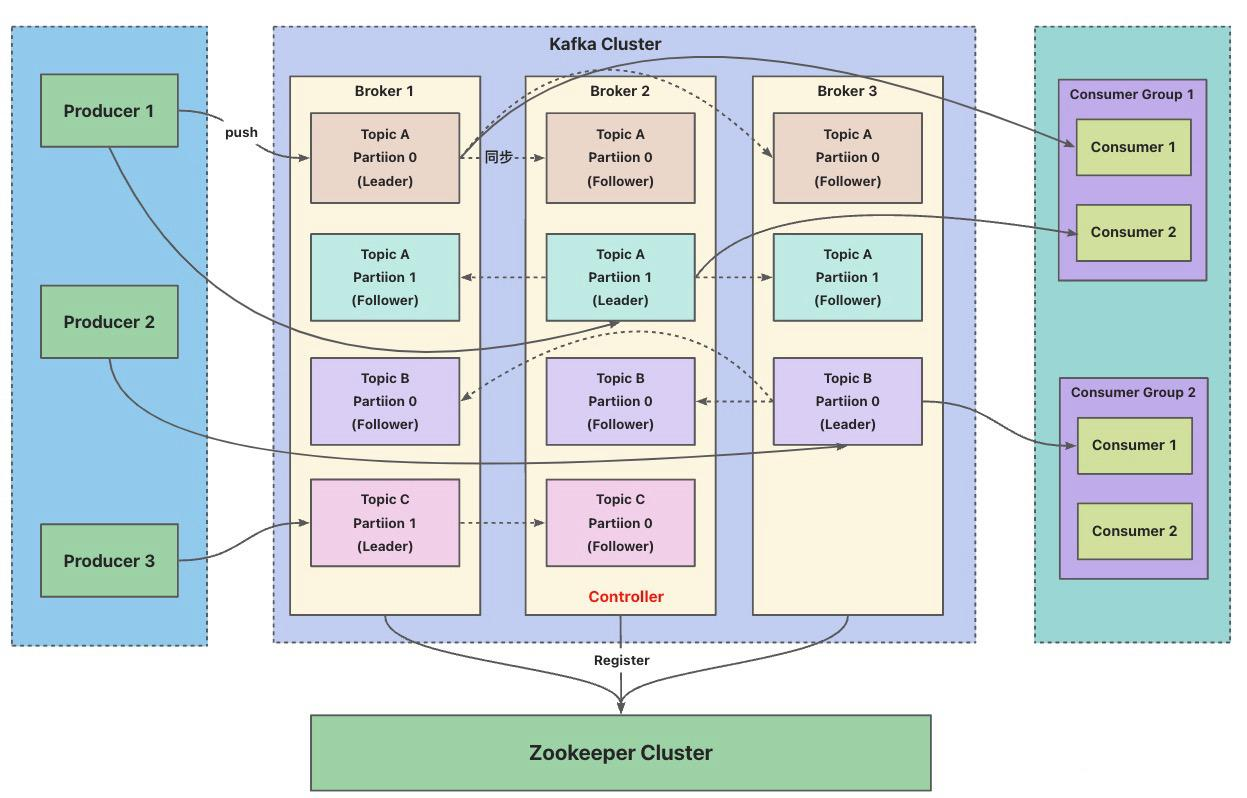
2、Kafka 集群的架構是什么樣子的?
3、Kafka 消費者組和生產者組是什么?
定義與核心作用
- 定義:消費者組(Consumer Group)是由多個消費者實例組成,共同訂閱并消費一個或多個主題(Topic)的消息。
- 核心作用:實現消息的并行消費和負載均衡,確保高吞吐量和容錯性。消費者組下可以有一個或多個消費者實例,它們共享一個公共的 ID,這個 ID 被稱為 Group ID。
關鍵機制
-
分區分配:
- 每個分區(Partition)只能被同一消費者組內的一個消費者消費。
- 若消費者數量 > 分區數,多余的消費者處于閑置狀態。
- 示例:主題有3個分區,消費者組有3個消費者 → 每個消費者負責1個分區。
-
重平衡(Rebalance):
- 觸發條件:消費者加入/離開、分區數量變化。
- 過程:重新分配分區所有權,確保負載均衡。
- 缺點:重平衡期間消費者暫停消費,可能影響實時性。
-
偏移量(Offset)管理:
- 消費者組通過提交偏移量記錄消費進度(存儲于
__consumer_offsets主題)。 - 支持自動提交(默認)或手動提交(精確控制)。
- 消費者組通過提交偏移量記錄消費進度(存儲于
典型場景
- 橫向擴展:增加消費者實例提升消費速度。
- 容災恢復:消費者故障后,其他消費者接管其分區。
- 多租戶隔離:不同消費者組獨立消費同一主題(如日志分發)。
切記
一個主題中的一個 Partition 只能被同一個消費者組中的一個消費者消費!!!如果一個消費者組中的消費者數量大于 Partition 數量,則會導致多出來的消費者無法消費到消息。
常見問題解答
Q1:消費者組內多個消費者如何避免重復消費?
- 答案:每個分區僅由一個消費者消費,偏移量由組統一管理,天然避免重復。
Q2:生產者如何實現消息的順序性?
- 答案:對同一分區(如相同Key的消息),Kafka保證順序寫入;跨分區無法保證。
Q3:消費者組能否消費多個主題?
- 答案:可以,消費者組可訂閱多個主題,按分區分配策略統一管理。
4、 Kafka 如何保證消息的的不丟失?
從以下三個方面進行保證:
- 生產者Producer,使用帶回調通知的send(msg,callback)方法,并且設置acks = all 。它的消息投遞要采用同步的方式。Producer要保證消息到達服務器,就需要使用到消息確認機制,也就是說,必須要確保消息投遞到服務端,并且得到投遞成功的響應,確認服務器已接收,才會繼續往下執行。
- 設置broker中的配置項unclean.leader.election.enable = false,保證所有副本同步。同時,Producer將消息投遞到服務器的時候,我們需要將消息持久化,也就是說會同步到磁盤。注意,同步到硬盤的過程中,會有同步刷盤和異步刷盤。如果選擇的是同步刷盤,那是一定會保證消息不丟失的。就算刷盤失敗,也可以即時補償。但如果選擇的是異步刷盤的話,這個時候,消息有一定概率會丟失。
- 就是消費者Consume。設置enable.auto.commit為false。在Kafka中,消息消費完成之后,它不會立即刪除,而是使用定時清除策略,也就是說,我們消費者要確保消費成功之后,手動ACK提交。如果消費失敗的情況下,我們要不斷地進行重試。所以,消費端不要設置自動提交,一定設置為手動提交才能保證消息不丟失。
5、Kafka 為什么性能高?比 RocketMQ 吞吐率高的根本原因是什么?
1、順序磁盤 I/O 的極致利用
- 日志追加寫入(Append-Only Log):
Kafka 將消息按順序追加到磁盤文件,完全避免隨機寫。
優勢:順序 I/O 性能遠超隨機 I/O(機械硬盤順序寫速度可達 100MB/s,隨機寫僅 1MB/s)。 - RocketMQ 的妥協:
雖然 RocketMQ 也采用順序寫入(CommitLog),但需維護 索引文件(ConsumeQueue) 支持消息查詢,引入輕微隨機讀,降低 I/O 效率。
2、零拷貝(Zero-Copy)技術(核心、根本)
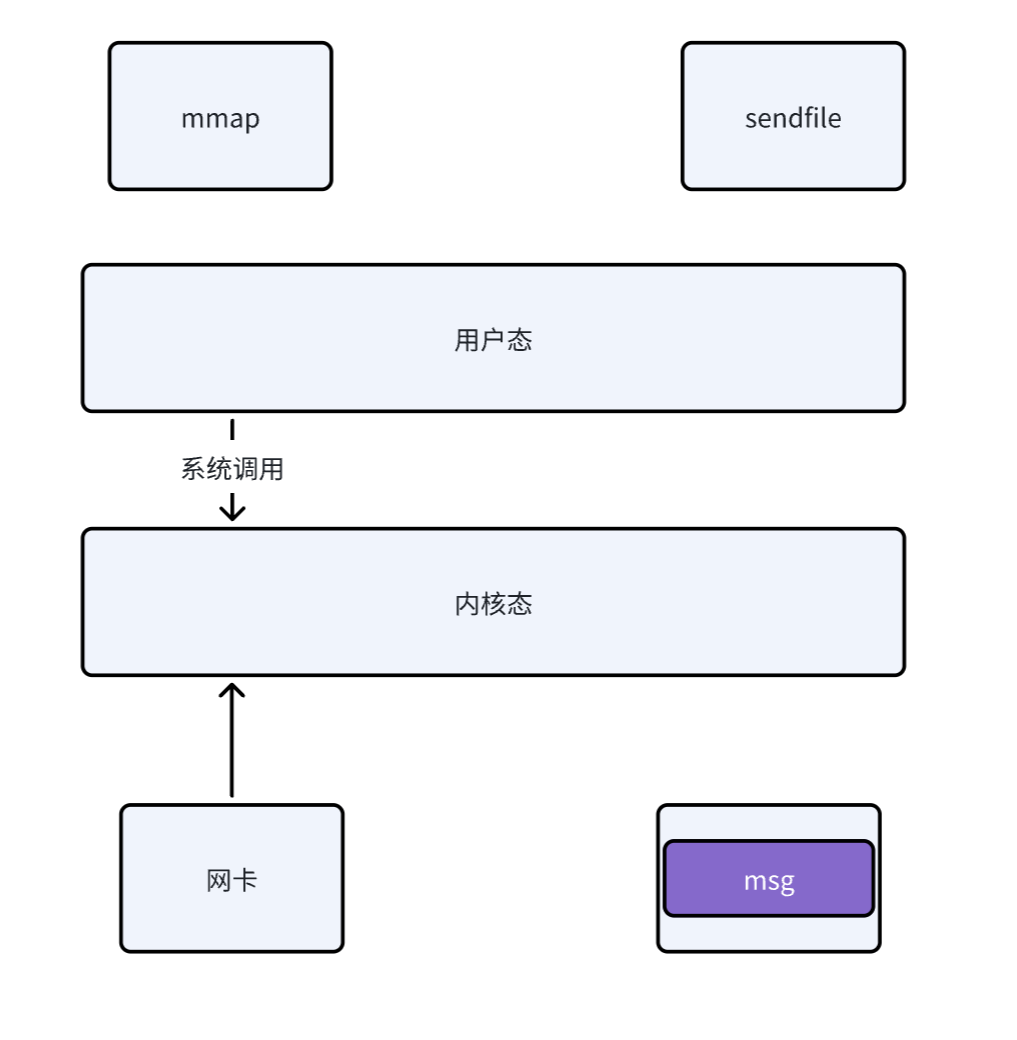
由于 Kafka 僅提供基礎功能,并不提供死信隊列、延遲隊列等功能
- Kafka 的實現:
使用sendfile(函數返回字節數)系統調用,數據直接從 頁緩存(Page Cache) 傳輸到網卡,跳過用戶態與內核態的數據拷貝。
效果:減少 2 次內存拷貝(傳統流程需 4 次),降低 CPU 和內存占用。 - RocketMQ 的局限:
雖然 RocketMQ 也采用了零拷貝技術,但是需要由于 RocketMQ 實現了信隊列、延遲隊列等高級功能,所以必然需要從內核態將數據拷貝到用戶態,因此其系統調用使用的是mmap(函數返回了消息的具體內容),得到的具體消息內容,因此其零拷貝實際進行了三次數據的拷貝,而 kafka 僅進行了兩次。
3、頁緩存(Page Cache)優先策略
- Kafka 的設計哲學:
- 數據讀寫直接依賴操作系統的頁緩存,避免 JVM 堆內存管理開銷(如 GC 停頓)。
- 消息寫入時僅追加到頁緩存,由操作系統異步刷盤,最大化 I/O 吞吐。
- RocketMQ 的取舍:
默認使用 堆外內存(DirectBuffer) 存儲消息,減少 GC 影響,但需手動管理內存,復雜度高。
4、批量處理與高效壓縮
- 批量寫入與拉取:
- 生產者積累一批消息后批量發送,減少網絡請求次數。
- 消費者批量拉取消息,提升單次請求效率。
- 壓縮算法(如 LZ4、ZStandard)顯著降低網絡傳輸量。
- RocketMQ 的平衡點:
默認配置更偏向低延遲(如批量閾值較小),犧牲部分吞吐量。
- 分區(Partition)并行模型
- 無鎖化設計:
每個 Partition 獨立處理讀寫,天然支持水平擴展。
生產者、消費者在 Partition 級別無競爭,避免鎖開銷。 - RocketMQ 的隊列(Queue)模型:
類似 Kafka 的 Partition,但事務消息、順序消息需額外協調,可能引入鎖競爭。
- 異步副本與一致性權衡
- Kafka 的 ISR 機制:
異步復制數據到 Follower,只需 Leader 確認寫入即可響應生產者,高吞吐優先。
允許副本短暫不一致(通過 min.insync.replicas 控制可靠性)。 - RocketMQ 的同步雙寫:
主從副本同步寫入后才返回確認(SYNC_MASTER 模式),強一致性優先,吞吐量降低。
6、 Kafka 如何保證消息的順序消費?
**Kafka只能保證單個分區內的消息順序,而無法保證跨分區的順序。**這一點很重要,因為很多用戶可能會誤以為只要在一個主題下就能保證全局順序,但實際上需要依賴分區的設計。
接下來需要詳細解釋如何利用分區來保證順序。比如生產者通過指定消息鍵(Key)將相關消息發送到同一分區,消費者則按分區順序消費。這時候可能會提到生產者發送消息時使用相同的Key,確保進入同一分區,消費者單線程處理每個分區的消息,或者使用多線程但確保同一分區的消息由同一線程處理。
同時,用戶可能想知道如何應對消費者組內的多個消費者實例,這時候需要解釋分區的分配機制,每個分區只能被一個消費者實例消費,從而保證順序。如果有多個消費者實例,每個實例處理不同的分區,而每個分區內的消息是順序的。
題目,純手工注入教程)
![[硬件電路-140]:模擬電路 - 信號處理電路 - 鎖定放大器概述、工作原理、常見芯片、管腳定義](http://pic.xiahunao.cn/[硬件電路-140]:模擬電路 - 信號處理電路 - 鎖定放大器概述、工作原理、常見芯片、管腳定義)
)
 深度解析與實踐)







![C語言-指針[指針數組和數組指針]](http://pic.xiahunao.cn/C語言-指針[指針數組和數組指針])





免安裝中文版)

