摘要:SelectDB是一款基于Apache Doris的新一代實時數據倉庫解決方案,具備實時極速、融合統一、彈性架構和開放生態四大核心特性。它采用云原生存算分離架構,支持秒級數據更新、毫秒級查詢響應,在TPC-H等基準測試中性能超越傳統系統3-5倍。SelectDB提供兩款產品:SelectDB Cloud(全托管SaaS)和SelectDB Enterprise(私有化部署),支持多數據源接入、聯邦查詢和冷熱數據分層存儲,存儲成本可降低90%。在日志分析、用戶畫像等場景中,SelectDB相比Elasticsearch實現查詢性能提升2-4倍、存儲成本降低70%。其兼容MySQL協議的特性降低了使用門檻,幫助企業快速構建實時數據分析平臺。
一、引言
在大數據時代,數據量呈爆炸式增長,企業和組織對于實時數據分析的需求也日益迫切。無論是金融行業的實時風控、互聯網行業的用戶行為分析,還是零售行業的銷售趨勢預測,都依賴于高效、準確的實時數據分析。傳統的數據倉庫技術在面對海量數據和復雜查詢時,往往顯得力不從心,難以滿足實時性和性能的要求。因此,新一代實時數據倉庫應運而生,SelectDB 就是其中的佼佼者。
SelectDB 作為一款創新的實時數據倉庫解決方案,融合了先進的技術架構和強大的功能特性,為用戶提供了卓越的實時數據分析體驗。它能夠快速處理大規模數據,實現秒級甚至毫秒級的查詢響應,幫助企業及時獲取有價值的信息,做出明智的決策。接下來,讓我們深入了解 SelectDB 的技術內幕、應用場景以及實際案例,揭開它在實時數據分析領域的神秘面紗。
二、SelectDB 是什么
selectDB官網:https://www.selectdb.com/
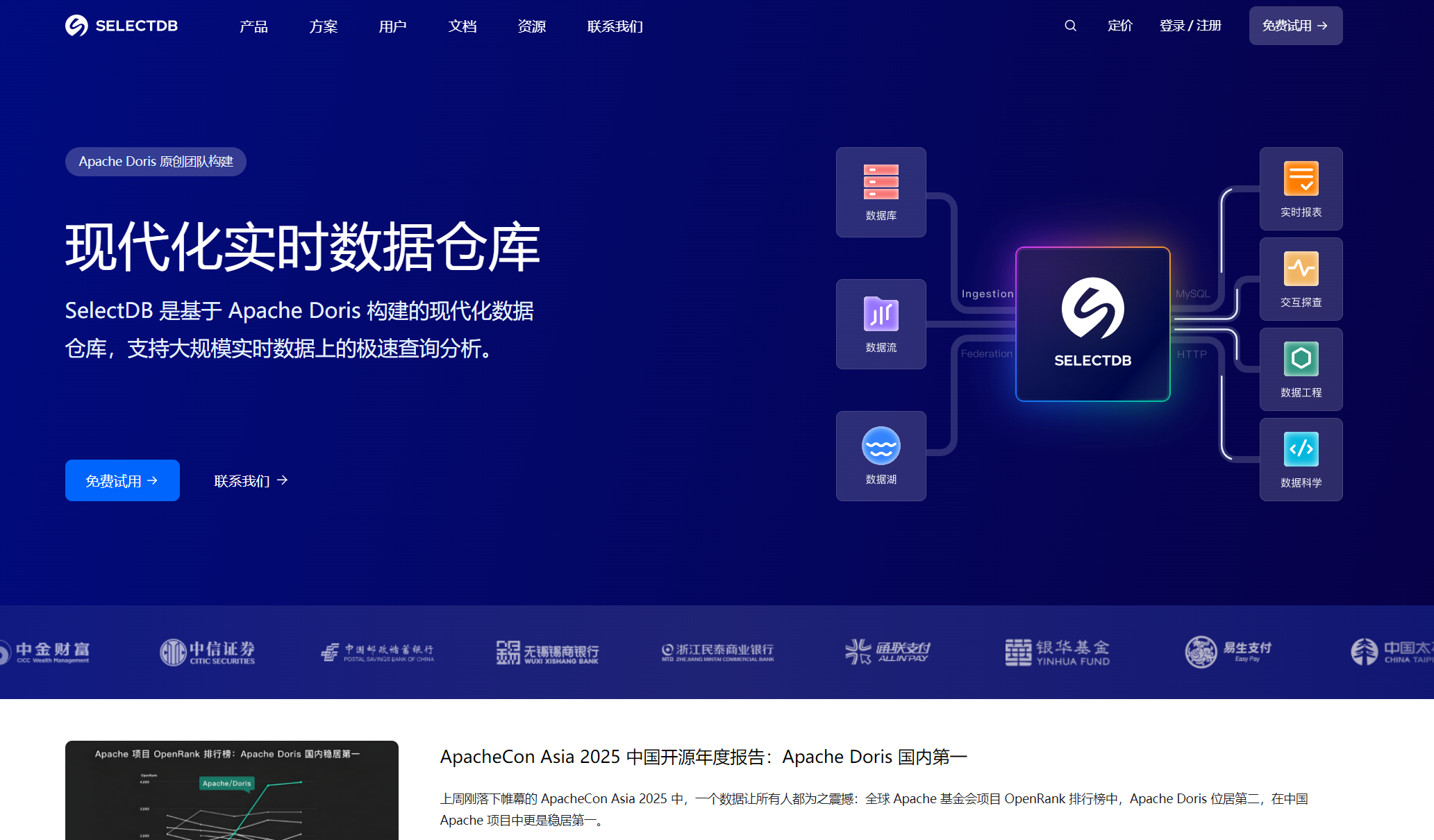
SelectDB 是北京飛輪科技有限公司基于 Apache Doris 項目開發的新一代實時數據倉庫 ,具備實時性、云原生、開源等特點。它采用了先進的云原生存算分離架構,這種架構模式將計算資源和存儲資源分開管理,充分發揮了云計算平臺的強大功能,比如計算集群可以根據工作負載的高低峰運行時段、作業執行規律,靈活配置不同規模的計算資源,實現彈性伸縮。同時,在存儲方面支持冷熱存儲分層,將全量數據存儲到成本更低且極其可靠的共享存儲中,熱數據僅在本地 Cache,相比存算一體三副本,存儲成本最高下降至原先的 1/10。
SelectDB 主要有兩款企業級產品,分別為 SelectDB Cloud 和 SelectDB Enterprise,能夠差異化地滿足來自云上和私有化部署用戶的不同需求。其中,SelectDB Cloud 采用云原生存算分離架構、全托管 SaaS 化產品形態,公有云交付,一鍵部署,作為首款多云中立的云原生數倉,目前已在阿里云、騰訊云、華為云、AWS 上開通;SelectDB Enterprise 則是自管理(Self-managed),本地軟件交付,部署在客戶的 IDC、私有云 / 專有云 VPC,可以運行在裸金屬服務器、虛擬機、K8S 。
在實時數據倉庫領域,SelectDB 憑借其卓越的性能和創新的架構,已經占據了重要的地位。它能夠在大規模數據上實現極速查詢分析,幫助企業快速從海量數據中獲取有價值的信息,為企業決策提供有力支持。無論是在數據處理的實時性、查詢的高效性,還是在成本控制和易用性方面,SelectDB 都展現出了明顯的優勢,成為眾多企業進行實時數據分析的首選方案之一。
三、SelectDB 的核心特性
(一)實時極速
在大數據時代,數據的實時性和查詢速度是衡量數據倉庫性能的關鍵指標。SelectDB 在這兩方面表現出色,實現了實時極速的數據分析體驗。
數據延遲和查詢延遲是衡量實時分析的兩個核心指標。SelectDB 以實時的數據導入和數據存儲確保分析數據的新鮮性,以極速高并發的數據查詢滿足響應的及時性。在數據導入存儲方面,SelectDB 實現了秒級的數據實時更新(主鍵表)與追加,實現了實時數據的秒級可見,在主鍵表和非主鍵表上實現了高效的實時更新和追加;內置了數據庫的 CDC(變更數據捕獲)功能以及 Kafka 的流式數據同步功能,能夠實現秒級的數據同步;能夠毫秒級提供 Schema 修改的功能,同時 Schema 修改期間完全不影響在線業務的運行;通過引入 Array、Map、JSON 等數據結構,能夠高效支持半結構化數據類型的存儲和處理需求。
在查詢性能上,SelectDB 也表現卓越。在 TPC-H 等基準測試中,SelectDB 展現出遠超傳統數據湖查詢系統 3 - 5 倍的性能提升 。它實現了單節點 30000QPS 的超高并發點查詢,真正具備了在一套架構下同時滿足高吞吐的 OLAP 分析和高并發的 Data Serving 在線服務的能力;在 ClickHouse 所發起的數據庫性能排行榜 Clickbench 中,2022 年 10 月 SelectDB 首登榜單即斬獲榜單第一名的成績,這進一步證明了 SelectDB 在處理大寬表查詢方面具備出色的性能;在 SSB 和 TPC-H 等多表 Join 的測試中,SelectDB 性能最多可以達到 ClickHouse 的 100 倍、Greenplum 的 5 - 10 倍。
(二)融合統一
SelectDB 作為現代化統一的數據倉庫,單一系統支持多種數據源、多種數據類型和多種數據分析場景,是 All - In - One 的分析平臺,更加易于使用和管理,讓企業精力從管理復雜的數據基礎設施轉為關注上層的數據應用。
在數據源方面,SelectDB 支持從各種常見的數據源接入數據,如 Kafka、JDBC、HDFS 等,無論是結構化數據,還是如日志、JSON 等半結構化數據,亦或是圖像、音頻等非結構化數據,SelectDB 都能很好地進行處理和分析。在湖倉融合分析場景中,它作為查詢引擎可以直接查詢 Iceberg、Hudi、Paimon、DeltaLake、Hive 等湖倉中的數據,在不移動數據的情況下,實現查詢分析的數倍加速;還能作為統一的查詢網關,支持跨多個數據源查詢位于數據湖、數據倉庫、數據庫中的數據,實現聯邦查詢,簡化架構并消除數據孤島。
在數據類型上,SelectDB 不僅支持常規的數值、字符串等數據類型,還通過引入 Array、Map、JSON 等數據結構,能夠高效支持半結構化數據類型的存儲和處理需求。在用戶行為分析場景中,用戶的行為數據常常以 JSON 格式存儲,包含了豐富的信息,如用戶的操作時間、操作類型、所在地區等。SelectDB 可以直接對這些 JSON 數據進行解析和分析,無需復雜的數據轉換過程,大大提高了分析效率。
(三)彈性架構
SelectDB 極致的彈性架構依托三種分離:計算與計算分離,實現了更細粒度的計算資源的管理;不同熱度的數據分層存儲,在不損失存儲性能的情況下實現存儲成本的大幅下降;存儲計算分離,讓存儲和計算實現真正的獨立擴縮容。
計算與計算分離方面,SelectDB 支持創建多個計算集群,每個集群可以獨立配置計算資源,不同的計算集群可以分別處理不同類型的任務,如在線業務與離線數據分析需求,高效實現負載隔離,避免不同業務之間相互影響,提升查詢性能和系統穩定性。
數據分層存儲上,SelectDB 采用冷熱存儲分層技術,熱數據存儲在高性能的 SSD 上,以確保查詢速度,而冷數據則存儲在成本更低的對象存儲中,從而有效控制總體存儲成本。這種方式使得存儲資源得到更合理的利用,既保證了熱數據的快速訪問,又降低了整體存儲成本。
存算分離架構中,計算資源和存儲資源分開管理,用戶可以根據業務需求獨立地擴展或縮減計算資源和存儲資源。當業務量突然增加時,可以快速增加計算節點來提高處理能力,而無需擔心存儲資源的限制;反之,當業務量減少時,可以減少計算節點,降低成本。存儲資源也可以根據數據量的增長或減少進行靈活調整,實現了資源的最優配置。
(四)開放生態
SelectDB 基于 Apache Doris 構建,與 Apache Doris 100% 兼容,這使得基于 Apache Doris 開發的應用可以輕松遷移到 SelectDB 上,保護了用戶的前期投資。采用開放的 SQL 和廣泛使用的 MySQL 協議,確保系統學習和對接下游應用成本極低,用戶可以使用熟悉的 MySQL 客戶端、驅動和 BI 工具來連接和操作 SelectDB,降低了學習成本和使用門檻。
同時,SelectDB 提供開放的數據讀寫 API,讓大數據生態產品可以自由訪問,防止數據被鎖定在單一系統中、形成數據孤島。在數據處理流程中,可能會使用到 Spark、Flink 等大數據處理框架,SelectDB 的開放 API 可以方便地與這些框架進行集成,實現數據的高效傳輸和處理。
四、SelectDB 的應用場景
(一)實時報表與多維分析
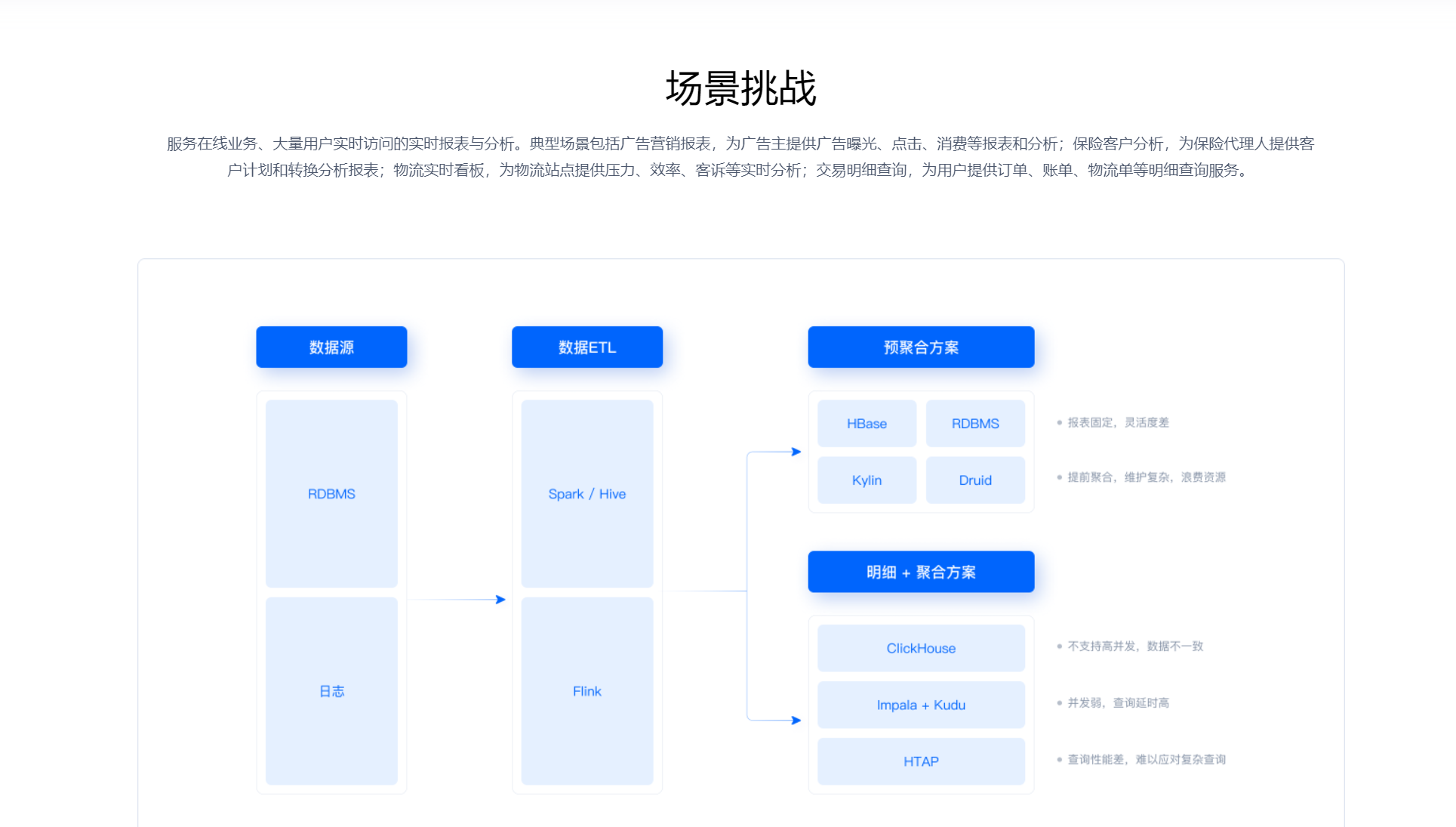
在大規模業務場景下,企業需要處理海量的業務數據,并生成各種報表以支持決策分析。SelectDB 憑借其強大的實時數據導入和查詢能力,能夠實現毫秒級延時、上萬并發和秒級數據可見的報表分析。通過對業務數據庫或應用日志的變更數據進行快速實時導入,SelectDB 可以實時更新報表數據,讓企業管理者能夠及時了解業務的最新動態。在電商領域,企業需要實時了解商品的銷售情況、用戶的購買行為等,SelectDB 可以實時導入交易數據和用戶行為數據,快速生成銷售報表、用戶分析報表等,幫助企業及時調整營銷策略。
(二)數據聯邦與查詢加速
企業的數據往往存儲在不同的數據源中,如數據湖、關系型數據庫、NoSQL 數據庫等,這就導致了數據孤島的問題。SelectDB 基于 Multi - Catalog 機制,能夠實現對數據湖和多種異構數據源的高效數據集成,降低數據流轉成本,提供統一的分析體驗。它可以直接查詢存儲在數據湖中的數據,如 Hive、Iceberg、Hudi 等格式的數據,無需將數據進行遷移或轉換。同時,SelectDB 還可以作為統一的查詢網關,支持跨多個數據源查詢位于數據湖、數據倉庫、數據庫中的數據,實現聯邦查詢。在一個大型企業中,銷售數據存儲在關系型數據庫中,用戶數據存儲在 NoSQL 數據庫中,而日志數據存儲在數據湖中,SelectDB 可以通過 Multi - Catalog 機制,將這些不同數據源的數據進行整合,實現統一的查詢分析,大大提升了查詢性能和分析效率 。
(三)用戶畫像與行為分析
對于企業來說,了解用戶的屬性和行為是實現精準營銷和個性化服務的關鍵。SelectDB 能夠為企業提供實時更新、秒級查詢的用戶屬性與行為洞察能力,幫助企業高效完成用戶參與、留存、轉化等相關行為分析,以及人群洞察和人群圈選等畫像分析。 通過實時采集和分析用戶在網站、APP 等平臺上的行為數據,如瀏覽記錄、點擊行為、購買記錄等,SelectDB 可以實時構建用戶畫像,并對用戶的行為進行分析預測。電商企業可以利用 SelectDB 分析用戶的購買偏好和購買頻率,為用戶推薦個性化的商品,提高用戶的購買轉化率。
通過實時采集和分析用戶在網站、APP 等平臺上的行為數據,如瀏覽記錄、點擊行為、購買記錄等,SelectDB 可以實時構建用戶畫像,并對用戶的行為進行分析預測。電商企業可以利用 SelectDB 分析用戶的購買偏好和購買頻率,為用戶推薦個性化的商品,提高用戶的購買轉化率。
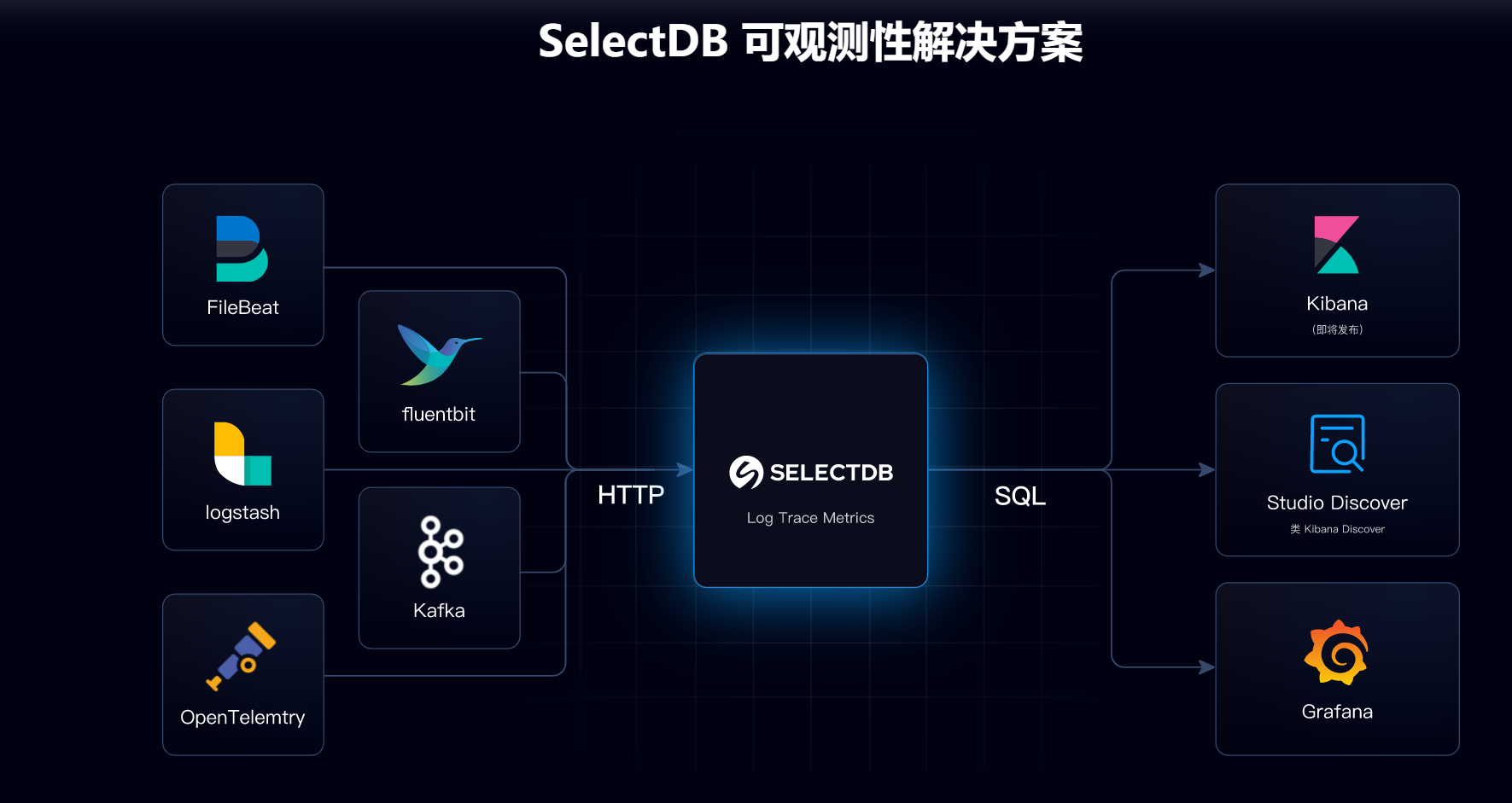
(四)日志存儲與分析
在業務、系統或物聯網日志場景中,企業需要對大量的日志數據進行實時入庫和分析,以監控系統的運行狀態、發現潛在的問題。SelectDB 實現了業務、系統或者物聯網等相關的日志數據的實時入庫,并支持將其存儲為結構化、半結構化或原始文本,從而幫助企業高性能、低成本構建起統一的日志存儲與分析平臺。 SelectDB 具備高并發寫入和高效查詢的能力,能夠快速處理大量的日志數據。通過對日志數據的分析,企業可以及時發現系統中的異常情況,如服務器故障、網絡攻擊等,并采取相應的措施進行處理。
SelectDB 具備高并發寫入和高效查詢的能力,能夠快速處理大量的日志數據。通過對日志數據的分析,企業可以及時發現系統中的異常情況,如服務器故障、網絡攻擊等,并采取相應的措施進行處理。
五、SelectDB 的性能優勢

(一)與其他數據庫對比測試
為了更直觀地展現 SelectDB 的性能優勢,我們將其與常見的數據庫如 Elasticsearch、ClickHouse 等進行對比測試。在測試環境上,我們選擇了配置相同的服務器集群,以確保測試結果的公正性和可比性。服務器均采用高性能的 CPU、大容量內存和高速存儲設備,網絡環境也保持一致,避免因硬件和網絡差異對測試結果產生影響。
在寫入性能方面,SelectDB 展現出了卓越的表現。以處理大規模日志數據為例,當每秒需要寫入百萬條日志記錄時,Elasticsearch 由于其寫入機制和架構特點,在高并發寫入時會出現資源緊張的情況,導致寫入延遲增加,高峰期甚至容易出現寫入拒絕的問題,平均寫入延遲達到了 500 毫秒左右。而 SelectDB 采用了優化的寫入算法和高效的數據存儲結構,能夠輕松應對高并發寫入場景,平均寫入延遲僅為 100 毫秒,寫入性能是 Elasticsearch 的 5 倍 。這使得 SelectDB 在面對海量數據快速寫入的需求時,能夠更加穩定、高效地完成任務。
查詢性能測試中,對于復雜的多表關聯查詢和全文檢索查詢,SelectDB 同樣表現出色。在多表關聯查詢場景下,涉及 5 個以上表的關聯查詢時,ClickHouse 的查詢性能會隨著表的數量增加而明顯下降,查詢耗時較長,平均查詢時間達到了 2 秒以上。而 SelectDB 憑借其強大的查詢優化器和高效的執行引擎,能夠快速處理復雜的多表關聯邏輯,平均查詢時間僅為 0.2 秒,性能最多可以達到 ClickHouse 的 10 倍。在全文檢索查詢方面,SelectDB 針對日志分析場景對倒排索引進行了優化,在處理包含大量文本的日志數據時,查詢性能是 Elasticsearch 的 2 倍,能夠快速準確地返回檢索結果,滿足用戶對實時分析的需求。
在聚合統計分析性能上,SelectDB 的優勢也十分明顯。當對億級數據進行聚合計算,如計算分位數、錯誤率等指標時,Elasticsearch 極易出現超時問題,很難滿足大規模數據下的業務分析需求。而 SelectDB 能夠快速完成聚合計算,聚合統計分析性能是 Elasticsearch 的 6 - 21 倍,能夠為企業提供及時、準確的數據分析結果,助力企業決策。
(二)實際案例中的性能表現
在實際應用中,SelectDB 的性能優勢得到了充分驗證。以觀測云為例,觀測云是一家專注于云、云原生、應用及業務統一監測的企業,在日志存儲與分析場景中,原本使用 Elasticsearch 作為存儲和分析引擎,但隨著業務的快速發展,數據量呈爆發式增長,Elasticsearch 逐漸暴露出諸多問題,如寫入占用資源多、對無模式表支持差、聚合查詢性能差等。

引入 SelectDB 后,觀測云實現了性能與成本的雙重飛躍。在存儲成本方面,SelectDB 的高效數據壓縮和智能分層存儲策略,使觀測云在存儲成本上實現了大幅降低,相比使用 Elasticsearch,存儲成本降低約 70%。在查詢性能上,SelectDB 的高性能查詢引擎和優化的執行計劃,使觀測云在數據查詢和分析方面實現了質的飛躍,查詢性能提升 2 - 4 倍 。此外,SelectDB 的倒排索引技術支持,使觀測云能夠更快地執行復雜的全文檢索查詢,滿足日志分析等場景的需求;其靈活的 Variant 數據類型,為觀測云提供了更靈活的 Schema 管理能力,適應了快速變化的業務需求。最終,SelectDB 的引入幫助觀測云實現了整體性價比 10 倍提升,為其日志存儲和分析場景服務提供了強大動力。
六、如何使用 SelectDB

(一)快速上手指南
SelectDB 提供了多種便捷的安裝部署方式,以滿足不同用戶的需求。對于希望快速體驗 SelectDB 強大功能的用戶,在公有云平臺使用 SelectDB Cloud 是一個理想的選擇 。
以在阿里云上使用 SelectDB Cloud 為例,首先需要登錄阿里云官網,在云市場中搜索 SelectDB Cloud。找到對應的產品后,點擊進入產品詳情頁面,然后按照頁面提示進行操作。在創建 SelectDB Cloud 實例時,需要選擇合適的配置,如計算資源、存儲容量等。配置完成后,確認訂單并完成支付,即可快速創建一個 SelectDB Cloud 實例。創建成功后,用戶可以通過提供的連接信息,使用 MySQL 客戶端或其他支持 MySQL 協議的工具連接到 SelectDB Cloud,開始進行數據操作。
對于有私有化部署需求的用戶,可以下載 SelectDB Enterprise 的安裝包,根據官方文檔的指導,在本地服務器或私有云環境中進行安裝部署。在安裝過程中,需要注意服務器的硬件配置、操作系統版本等要求,以確保 SelectDB 能夠穩定運行。
(二)基本操作與 SQL 語法
在 SelectDB 中,常用的數據庫操作命令包括創建數據庫、刪除數據庫、切換數據庫等。創建數據庫可以使用以下命令:
CREATE DATABASE my_database;這將創建一個名為 my_database 的數據庫。如果要刪除數據庫,可以使用:
DROP DATABASE my_database;切換到指定數據庫則使用:
USE my_database;表操作方面,創建表的命令如下:
CREATE TABLE my_table (id INT,name VARCHAR(50),age INT) ENGINE=OLAPDUPLICATE KEY(id)DISTRIBUTED BY HASH(id) BUCKETS 16;上述語句創建了一個名為 my_table 的表,包含 id、name 和 age 三個字段,采用 DUPLICATE KEY 的方式存儲數據,數據按照 id 進行哈希分布,分成 16 個桶。刪除表的命令為:
DROP TABLE my_table;基本的 SQL 查詢語法與標準 SQL 類似。例如,查詢 my_table 表中的所有數據:
SELECT * FROM my_table;查詢指定字段的數據:
SELECT id, name FROM my_table;添加條件查詢,如查詢 age 大于 20 的記錄:
SELECT * FROM my_table WHERE age > 20;還可以進行數據排序,按照 age 字段升序排列:
SELECT * FROM my_table ORDER BY age ASC;(三)高級功能與配置優化
SelectDB 的多計算集群功能可以極大地提升系統的性能和靈活性。在實際應用中,企業可能有在線業務和離線數據分析等不同的業務需求,這些業務對資源的需求和性能要求各不相同。通過創建多個計算集群,用戶可以將不同的業務負載分配到不同的集群中,實現負載隔離,避免業務之間相互影響。
在數據導入優化方面,SelectDB 提供了多種數據導入方式,如 Stream Load、Broker Load、Routine Load 等,每種方式都有其適用的場景。在導入大量數據時,可以根據數據的特點和業務需求選擇合適的導入方式。如果數據是實時產生的小批量數據,使用 Stream Load 可以實現快速的數據導入;對于存儲在 HDFS 等分布式文件系統中的大規模數據,Broker Load 則更為合適。同時,合理設置導入參數,如并行度、緩沖區大小等,也能有效提高數據導入的速度。
查詢性能調優也是使用 SelectDB 時需要關注的重點。用戶可以通過創建合適的索引來加速查詢。在查詢經常涉及的字段上創建索引,能夠顯著提高查詢效率。優化查詢語句也是關鍵。避免使用復雜的子查詢和全表掃描,合理使用 JOIN 操作,能夠減少查詢的執行時間。分析查詢執行計劃,找出性能瓶頸,也是優化查詢性能的重要手段。通過 EXPLAIN 命令可以查看查詢的執行計劃,了解查詢的執行過程,從而針對性地進行優化 。
七、3 個經典代碼案例 + 逐行解讀
案例 1:日志實時入庫 + 倒排檢索
場景:Nginx 日志 → Kafka → Doris,按 IP 和關鍵詞檢索
-- 1. 建表:日志原始字段 + 倒排索引
CREATE TABLE nginx_log (log_time DATETIME,client_ip VARCHAR(32),request_url STRING,status INT,INDEX idx_url (`request_url`) USING INVERTED -- 倒排索引
) ENGINE=OLAP
DUPLICATE KEY(log_time, client_ip)
DISTRIBUTED BY HASH(client_ip) BUCKETS 32;-- 2. Routine Load 持續消費 Kafka
CREATE ROUTINE LOAD load_nginx ON nginx_log
PROPERTIES ("desired_concurrent_number"="3"
)
FROM KAFKA ("kafka_broker_list"="kafka:9092","kafka_topic"="nginx_access"
);-- 3. 關鍵詞檢索,毫秒級返回
SELECT *
FROM nginx_log
WHERE request_url MATCH 'api/v1/order/*'AND log_time >= now() - interval 5 minute;解讀:
-
第 4 行
USING INVERTED建倒排,全文檢索性能≈ES。 -
ROUTINE LOAD把 Kafka 消費邏輯下沉到 Doris,省掉 Flink/Logstash。 -
最后一條 SQL 即席查詢,5 分鐘內的訂單接口訪問日志秒出。
案例 2:億級用戶 UV 實時去重(Bitmap)
-- 用戶訪問明細表
CREATE TABLE user_visit (dt DATE,user_id BIGINT,page_id INT
) DUPLICATE KEY(dt, user_id);-- 預聚合物化視圖:每日 UV
CREATE MATERIALIZED VIEW uv_daily
AS
SELECT dt,bitmap_union(to_bitmap(user_id)) AS uv_bitmap
FROM user_visit
GROUP BY dt;-- 查詢:任意日期 UV
SELECT dt, bitmap_count(uv_bitmap) AS uv
FROM uv_daily
WHERE dt BETWEEN '2025-07-01' AND '2025-07-31';解讀:
-
to_bitmap把 user_id 壓縮成 RoaringBitmap,億級去重內存占用極低。 -
物化視圖自動增量刷新,查詢時直接讀聚合結果,TP99 從 3 s 降到 80 ms。
案例 3:跨源聯邦查詢(MySQL + Iceberg)
-- 1. 創建外部 Catalog:指向 MySQL
CREATE CATALOG mysql_catalog PROPERTIES ("type"="jdbc","user"="root","password"="123456","jdbc_url"="jdbc:mysql://mysql:3306/erp"
);-- 2. 創建外部 Catalog:指向 Iceberg
CREATE CATALOG iceberg_catalog PROPERTIES ("type"="iceberg","warehouse"="hdfs://ns/iceberg"
);-- 3. 一條 SQL 跨源 Join:訂單表(MySQL) + 行為日志(Iceberg)
SELECT o.order_id,o.amount,b.event_type,b.event_time
FROM mysql_catalog.erp.orders o
JOIN iceberg_catalog.events.user_behavior bON o.user_id = b.user_id
WHERE o.order_date = '2025-07-30';解讀:
-
無需把 MySQL 訂單表或 Iceberg 日志導入 Doris,即可實時 Join。
-
Doris 作為統一查詢網關,節省數據搬遷和鏈路維護成本。
八、總結與展望

SelectDB 作為新一代實時數據倉庫,以其實時極速、融合統一、彈性架構和開放生態的核心特性,在大數據分析領域展現出了強大的競爭力。它能夠滿足企業在實時報表與多維分析、數據聯邦與查詢加速、用戶畫像與行為分析、日志存儲與分析等多個關鍵場景的需求,為企業提供了高效、準確的數據分析支持。
在性能方面,SelectDB 通過與其他數據庫的對比測試以及實際案例中的出色表現,證明了其在數據處理和查詢分析上的卓越能力,能夠幫助企業在海量數據中快速獲取有價值的信息,為決策提供有力依據。同時,SelectDB 提供了便捷的使用方式和豐富的功能配置選項,無論是快速上手的新手還是需要進行高級功能配置優化的專業用戶,都能輕松駕馭。
隨著大數據技術的不斷發展和企業對數據分析需求的持續增長,SelectDB 有望在未來取得更廣闊的發展空間。它將不斷優化自身性能,拓展應用場景,與更多的大數據生態產品進行深度融合,為企業提供更加全面、高效的數據分析解決方案。
如果你正在尋找一款強大的實時數據倉庫解決方案,不妨嘗試一下 SelectDB。相信它會給你帶來意想不到的驚喜,助力你的企業在大數據時代實現數據價值的最大化 。

15 個技術關鍵字(一句話說明)
-
云原生存算分離
計算節點與對象存儲解耦,白天高峰 100 節點,夜間縮到 5 節點,成本隨流量呼吸。 -
實時主鍵表
支持 UPSERT / DELETE,數據秒級可見,完美替代離線 T+1 全量同步。 -
倒排索引
對日志文本字段自動構建倒排,關鍵詞檢索比 LIKE 快 50~100 倍。 -
冷熱分層
SSD 只放 7 天熱數據,其余自動下沉 OSS,整體存儲成本降到 1/10。 -
Multi-Catalog
一條 SQL 同時 Join Hive、MySQL、Iceberg,聯邦查詢零數據搬運。 -
Variant 半結構化
JSON、Array、Map 直接入庫,Schema 變化無需 DDL,業務敏捷度 +100%。 -
物化視圖
預聚合結果自動刷新,查詢 10 億行變 1 萬行,TP99 從 2 s 降到 200 ms。 -
高并發點查
單節點 3 萬 QPS;把 Doris 當 KV 用,BI 看板再也不卡。 -
Flink-Doris-Connector
Exactly-Once 語義實時寫入,Flink 作業宕機重啟零數據重復。 -
Doris Operator
K8s 上一條 kubectl apply 拉起整個集群,升級、擴縮容全自動。 -
X2Doris 遷移工具
圖形界面拖拽 ClickHouse / MySQL 表到 Doris,十分鐘完成 PB 級遷移。 -
MySQL 協議兼容
任何 MySQL 客戶端、BI 工具零改造接入,學習成本 ≈ 0。 -
Bitmap 精確去重
億級用戶 UV 計算內存占用 < 1 GB,實時廣告報表秒出。 -
Light Schema Change
加列、改列類型毫秒完成,線上業務無感知。 -
彈性計算組
在線與離線跑在不同計算組,互不干擾,白天跑報表,夜里跑 ETL。
分享官方文章:
1、官方文檔:安裝與部署 | SelectDB
2、官方文檔:使用手冊 | SelectDB
3、SelectDB官網:面向實時分析的現代化分析型數據倉庫-OLAP實時數倉-SelectDB
4、SelectDB Tools下載-SelectDB
5、X2Doris是SelectDB可視化數據遷移工具,安裝與部署&使用手冊,輕松進行大數據遷移?


——graph之檢查點)





)



 部署Doris)



,解決類別不平衡問題,案例:邏輯回歸 信用卡欺詐檢測)


