下采樣:機器學習——下采樣(UnderSampling),解決類別不平衡問題,案例:邏輯回歸 信用卡欺詐檢測-CSDN博客
(完整代碼在底部)
解決樣本不平衡問題:SMOTE 過采樣實戰講解
在實際的機器學習任務中,數據集往往存在類別不平衡問題,尤其是在信用卡欺詐檢測、疾病預測等場景中,正樣本極其稀少。若不處理這一問題,模型更傾向于預測多數類,導致 recall 值(召回率)偏低。
SMOTE 的核心思想是:不是復制已有少數類樣本,而是通過“插值”方式生成新的樣本點,使少數類樣本在特征空間中更豐富、分布更自然。
說白了就是在每兩個同類別的點之間插入新點,也同樣是此類別
工作步驟如下:
-
找鄰居:
對于每一個少數類樣本,SMOTE 會在該類中找到若干個(如 5 個)“最近鄰”樣本。 -
隨機選擇鄰居:
從這幾個鄰居中,隨機選一個作為“參考點”。 -
插值生成新樣本:
在原樣本和參考點之間,以一定比例隨機插值,生成一個“新的樣本點”。
也就是說,這個新樣本不是原樣本的復制,也不是鄰居樣本的復制,而是它們之間的“連線上的點”。數學公式如下(對特征向量來說):
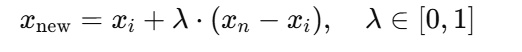
-
xi?:原始少數類樣本
-
xn?:其某個鄰居
-
λ:0~1之間的隨機數,決定插值比例
-
-
重復以上過程,直到少數類樣本數量和多數類一樣多,達到“類別平衡”。
本篇文章將通過信用卡欺詐檢測數據集(creditcard.csv),演示如何使用 SMOTE 方法對訓練集進行過采樣,并對比模型在過采樣前后的性能表現差異。
一、引入所需模塊
import numpy as np
import pandas as pd
from sklearn import metrics
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
# from imblearn.over_sampling import SMOTE # 過采樣二、數據預處理
信用卡欺詐檢測數據集?creditcard.csv
-
數據來源信用卡欺詐檢測實戰數據集_數據集-阿里云天池
 https://tianchi.aliyun.com/dataset/101562?accounttraceid=c1258603818f44d6a57fe125248cc969rkgu
https://tianchi.aliyun.com/dataset/101562?accounttraceid=c1258603818f44d6a57fe125248cc969rkgu -
樣本總數:284,807 條
-
特征數:30(28個匿名特征 + 金額
Amount+ 時間Time) -
目標變量:
Class(0=正常交易,1=欺詐交易)
?? ? ?
? ?
讀取數據并標準化金額列
# 讀取信用卡欺詐數據集
data = pd.read_csv('creditcard.csv')# 對“Amount”金額列進行標準化(均值為0,標準差為1)
scaler = StandardScaler()
data['Amount'] = scaler.fit_transform(data[['Amount']])# 刪除無關的“Time”列
data = data.drop("Time", axis=1)特征與標簽劃分
# 分離特征和目標變量
X = data.drop("Class", axis=1) # 特征變量
y = data.Class # 目標變量(是否欺詐)劃分訓練集與測試集
# 將數據劃分為訓練集和測試集,比例為7:3
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=100)
三、原始數據模型訓練與評估
# 使用原始訓練數據訓練邏輯回歸模型
model = LogisticRegression()
model.fit(X_train, y_train)查看原始類別分布
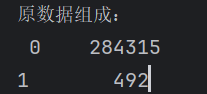
# 查看原始數據中正負樣本(欺詐/正常交易)的數量
labels_count = pd.value_counts(data['Class'])
print("原數據組成:\n", labels_count)結果:
在原始測試集上評估模型
# 在原始測試集上評估原始模型的性能
print("‘原數據訓練得到的模型’ 對 ‘原數據的測試集’ 的測試:")
predictions_test = model.predict(X_test)
print(metrics.classification_report(y_test, predictions_test))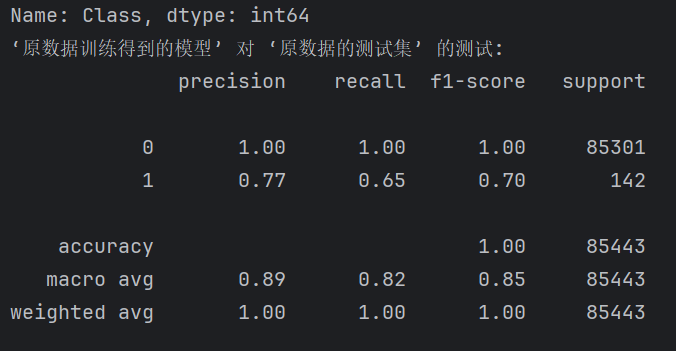
這種情況下,模型可能在類別為“1”(欺詐)的召回率較低,常見表現為:
-
precision 較高,但 recall 偏低
-
模型傾向于預測為正常交易
四、使用 SMOTE 進行過采樣
進行訓練集過采樣
# ======================== 使用 SMOTE 過采樣 ========================
from imblearn.over_sampling import SMOTE
# 對訓練數據進行過采樣,使正負樣本數量相同
oversampler = SMOTE(random_state=100)
X_train_os, y_train_os = oversampler.fit_resample(X_train, y_train)? 注意:測試集不要過采樣,保持原始分布才能真實評估模型性能。
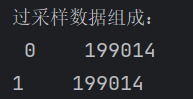
查看過采樣后的數據組成
# 查看過采樣后訓練數據中正負樣本的數量
labels_count_under = pd.value_counts(y_train_os)
print("下采樣數據組成:\n", labels_count_under)示例輸出:199014為284807的%70
原理步驟:
-
對每個少數類樣本,找到其最近的 k?個同類鄰居(默認 k=5)
-
隨機選取若干鄰居點
-
在原樣本和鄰居之間插值生成“合成樣本”(就是在兩兩之間多插入幾個數據)
-
不是復制已有樣本,而是生成新的樣本點,更豐富、更自然
五、使用過采樣數據訓練模型
# 使用過采樣后的數據重新訓練邏輯回歸模型
model_os = LogisticRegression(C=10, penalty='l2', max_iter=1000)
model_os.fit(X_train_os, y_train_os)在原始測試集上評估新模型
# 在原始測試集上評估過采樣模型的性能
print("‘過采樣數據訓練得到的模型’ 對 ‘原數據的測試集’ 的測試:")
predictions_test = model_os.predict(X_test)
print(metrics.classification_report(y_test, predictions_test))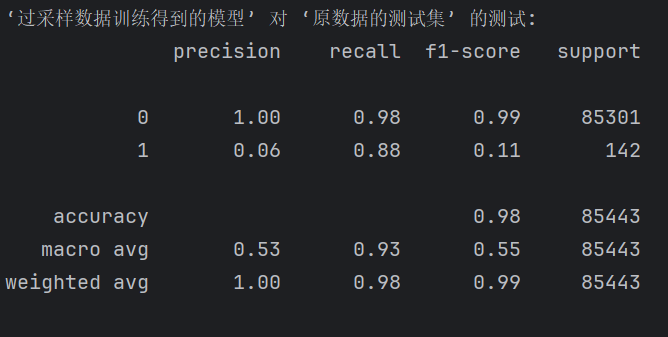
評估對比與說明
| 指標/類別 | 原模型 | 過采樣模型 | 解讀 |
|---|---|---|---|
| 類別 1 Recall(召回率) | 0.65 | 0.88 ? | 過采樣顯著提高了識別能力 |
| 類別 1 Precision(精準率) | 0.77 ? | 0.06 ? | 誤報大幅增加,很多 0 被錯判為 1(寧殺錯) |
| 類別 1 F1-score(平衡指標) | 0.70 ? | 0.11 ? | 整體準確性下降 |
| 類別 0 Recall | 1.00 ? | 0.98 | 正常交易略受影響 |
| 總體 Accuracy | 1.00 ? | 0.98 | 正確率略下降 |
| Macro avg Recall | 0.82 | 0.93 ? | 兩類平均召回提升 |
六、結果對比分析
| 指標 | 原始模型 | SMOTE過采樣模型 |
|---|---|---|
| Precision(1類) | 較高 | 較高 |
| Recall(1類) | 較低 | 明顯提升 |
| F1-score(1類) | 偏低 | 顯著提升 |
| Accuracy | 接近1 | 可能略有下降 |
🎯 結論:SMOTE 有效提高了模型對少數類(欺詐行為)的識別能力,在保持總體準確率的同時顯著改善了 recall 和 F1-score,是處理不平衡問題的有效方法之一。
七、總結與建議
-
SMOTE(Synthetic Minority Over-sampling Technique)通過生成新的少數類樣本來平衡數據分布,是一種優于簡單復制的過采樣方式。
-
在不平衡數據場景中,評估指標應以 recall/F1-score 為主,而非 accuracy。
-
SMOTE 適合用于訓練集,而不應作用于測試集。
-
邏輯回歸 + SMOTE 是一種簡單有效的基線方案,可用于模型初步構建與對比。
完整代碼:
import numpy as np
import pandas as pd
from sklearn import metrics
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split, cross_val_score
from sklearn.preprocessing import StandardScaler# 讀取信用卡欺詐數據集
data = pd.read_csv('creditcard.csv')# 對“Amount”金額列進行標準化(均值為0,標準差為1)
scaler = StandardScaler()
data['Amount'] = scaler.fit_transform(data[['Amount']])# 刪除無關的“Time”列
data = data.drop("Time", axis=1)# 分離特征和目標變量
X = data.drop("Class", axis=1) # 特征變量
y = data.Class # 目標變量(是否欺詐)# 將數據劃分為訓練集和測試集,比例為7:3
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=100)# 使用原始訓練數據訓練邏輯回歸模型
model = LogisticRegression()
model.fit(X_train, y_train)# 查看原始數據中正負樣本(欺詐/正常交易)的數量
labels_count = pd.value_counts(data['Class'])
print("原數據組成:\n", labels_count)# 在原始測試集上評估原始模型的性能
print("‘原數據訓練得到的模型’ 對 ‘原數據的測試集’ 的測試:")
predictions_test = model.predict(X_test)
print(metrics.classification_report(y_test, predictions_test))# ======================== 使用 SMOTE 過采樣 ========================
from imblearn.over_sampling import SMOTE
# 對訓練數據進行過采樣,使正負樣本數量相同
oversampler = SMOTE(random_state=100)
X_train_os, y_train_os = oversampler.fit_resample(X_train, y_train)# 使用過采樣后的數據重新訓練邏輯回歸模型
model_os = LogisticRegression(C=10, penalty='l2', max_iter=1000)
model_os.fit(X_train_os, y_train_os)# 查看過采樣后訓練數據中正負樣本的數量
labels_count_under = pd.value_counts(y_train_os)
print("過采樣數據組成:\n", labels_count_under)# 在原始測試集上評估過采樣模型的性能
print("‘過采樣數據訓練得到的模型’ 對 ‘原數據的測試集’ 的測試:")
predictions_test = model_os.predict(X_test)
print(metrics.classification_report(y_test, predictions_test))








)

:mysql連接池)






:建容器需要進一步了解的概念)
)
