本篇介紹了Netflix的視頻標注器(VA),一個利用視覺-語言模型和主動學習的交互式框架。其技術亮點在于通過人機協作系統,結合零樣本能力和主動學習,引導領域專家高效標注視頻數據,顯著提升了模型樣本效率和平均精度。VA通過搜索、主動學習和審查三步流程,實現視頻分類器的快速構建與迭代。
這個視頻標注器(VA)模型主要有三個步驟:
- 搜索:用戶通過文字描述(如“建筑物的廣角鏡頭”)來搜索視頻片段,找到初步的示例。
- 主動學習:模型根據已有的標注訓練一個輕量級分類器,然后用它來篩選出“最積極的”、“最消極的”、“最模糊的”或“隨機的”視頻片段,供用戶繼續標注,不斷優化模型。
- 審查:用戶查看所有已標注的片段,檢查是否有錯誤,并尋找新的標注想法。
文章來自于:Video annotator: a framework for efficiently building video classifiers using vision-language models and active learning
文章目錄
- 問題
- 影響
- 解決方案
- 視頻理解
- 視頻分類
- 通過可擴展的視頻分類器集實現視頻理解
- 視頻標注器 (VA)
- 步驟 1 — 搜索
- 步驟 2 — 主動學習
- 步驟 3 — 審查
- 實驗
- 結論
問題
高質量且一致的標注是成功開發穩健機器學習模型的基礎。訓練機器學習分類器的傳統技術是資源密集型的。它們涉及一個循環:領域專家標注數據集,然后將其移交給數據科學家進行模型訓練、結果審查和修改。這種標注過程往往耗時且效率低下,有時在幾個標注周期后就會中斷。
影響
因此,相比于迭代復雜模型和算法方法以提高性能和修復邊緣案例,在標注高質量數據集上投入的精力較少。結果是,機器學習系統的復雜性迅速增長。
此外,時間和資源的限制常常導致利用第三方標注人員而非領域專家。這些標注人員在不深入理解模型預期部署或用途的情況下執行標注任務,這使得對臨界或困難示例進行一致性標注成為一項挑戰,尤其是在更主觀的任務中。
這需要與領域專家進行多輪審查,從而導致意想不到的成本和延誤。這種漫長的周期還可能導致模型漂移,因為修復邊緣案例和部署新模型需要更長時間,這可能會損害實用性和利益相關者的信任。
解決方案
我們認為,通過人機協作系統讓領域專家更直接地參與,可以解決許多實際挑戰。我們引入了一個新穎的框架——視頻標注器(VA),它利用大型視覺-語言模型的主動學習技術和零樣本能力來引導用戶將精力集中在漸進式更困難的示例上,從而提高模型的樣本效率并降低成本。
VA 將模型構建無縫集成到數據標注過程中,便于用戶在部署前驗證模型,從而有助于建立信任并培養主人翁意識。VA 還支持持續標注過程,允許用戶快速部署模型,監控其在生產中的質量,并通過標注更多示例和部署新模型版本來迅速修復任何邊緣案例。
這種自助服務架構使用戶能夠在沒有數據科學家或第三方標注人員積極參與的情況下進行改進,從而實現快速迭代。
視頻理解
我們設計 VA 旨在協助細粒度視頻理解,這需要識別視頻片段中的視覺、概念和事件。視頻理解對于眾多應用至關重要,例如搜索和發現、個性化以及宣傳素材的創作。我們的框架允許用戶通過開發一套可擴展的二元視頻分類器來高效訓練視頻理解的機器學習模型,這些分類器為海量內容的規模化評分和檢索提供支持。
視頻分類
視頻分類是將標簽分配給任意長度視頻片段的任務,通常伴隨一個概率或預測分數,如圖 1 所示。

圖 1 - 二元視頻分類器的功能視圖。來自《高校舞弊案:美國大學招生丑聞》的一個幾秒鐘的片段被傳遞給一個二元分類器,用于檢測“定場鏡頭”標簽。分類器輸出一個非常高的分數(分數介于 [0] 和 [1] 之間),表明該視頻片段很可能是一個定場鏡頭。在電影制作中,定場鏡頭是一個廣角鏡頭(即連續兩個剪輯之間的視頻片段),旨在確立場景的時間和地點。
通過可擴展的視頻分類器集實現視頻理解
二元分類允許獨立性和靈活性,使我們能夠獨立于其他模型添加或改進一個模型。它還具有一個額外的好處,即對我們的用戶來說更容易理解和構建。結合多個模型的預測,我們可以更深入地理解視頻內容在不同粒度級別上的含義,如圖 2 所示。

圖 2 - 三個視頻片段以及三個視頻理解標簽對應的二元分類器分數。請注意,這些標簽并非互斥。視頻片段分別來自《高校舞弊案:美國大學招生丑聞》、《鬼影特攻:以暴制暴》和《斷訊》。
視頻標注器 (VA)
在本節中,我們將描述 VA 構建視頻分類器的三步過程。
步驟 1 — 搜索
用戶首先在一個大型、多樣化的語料庫中找到一組初始示例,以啟動標注過程。我們利用文本到視頻搜索來實現這一點,該搜索由視覺-語言模型中的視頻和文本編碼器提供支持,用于提取嵌入。例如,一個正在處理定場鏡頭模型的標注人員可以通過搜索“建筑物的廣角鏡頭”來啟動該過程,如圖 3 所示。

圖 3 - 步驟 1 — 文本到視頻搜索以啟動標注過程。
步驟 2 — 主動學習
下一階段涉及經典的主動學習循環。VA 隨后在視頻嵌入上構建一個輕量級二元分類器,該分類器隨后用于對語料庫中的所有片段進行評分,并在信息流中呈現一些示例以供進一步標注和細化,如圖 4 所示。

圖 4 - 步驟 2 — 主動學習循環。標注人員點擊“構建”,這將啟動分類器訓練和視頻語料庫中所有片段的評分。評分后的片段被組織在四個信息流中。
得分最高的正向和負向信息流分別顯示得分最高和最低的示例。我們的用戶反饋稱,這提供了有價值的指示,表明分類器在訓練的早期階段是否捕獲了正確的概念,并發現了訓練數據中他們隨后能夠修復的偏差情況。我們還包含了一個模型不確定的“臨界”示例信息流。這個信息流有助于發現有趣的邊緣案例,并激發標注額外概念的需求。最后,隨機信息流包含隨機選擇的片段,有助于標注多樣化的示例,這對于泛化很重要。
標注人員可以在任何信息流中標注額外的片段,并構建新的分類器,并根據需要重復多次。
步驟 3 — 審查
最后一步只是向用戶展示所有已標注的片段。這是一個發現標注錯誤并識別通過步驟 1 中的搜索進行進一步標注的想法和概念的好機會。從這一步開始,用戶通常會回到步驟 1 或步驟 2 來完善他們的標注。
實驗
為了評估 VA,我們邀請了三位視頻專家在一個包含 50 萬個鏡頭的視頻語料庫中標注了 56 個不同標簽。我們將 VA 與幾種基線方法的性能進行了比較,并觀察到 VA 能夠創建更高質量的視頻分類器。圖 5 比較了 VA 與基線方法在不同標注片段數量下的性能。
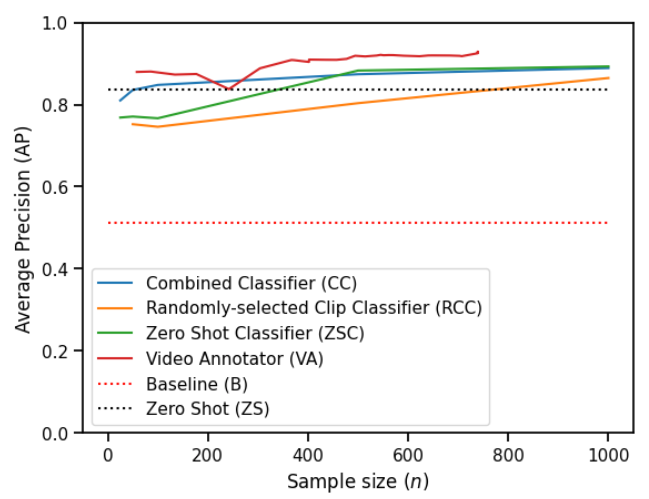
圖 5 - “定場鏡頭”標簽的模型質量(即平均精度 [Average Precision])作為標注片段數量的函數。我們觀察到所有方法都優于基線,并且所有方法都受益于額外的標注數據,盡管程度不同。
您可以在這篇論文中找到有關 VA 和我們實驗的更多詳細信息。
結論
我們介紹了視頻標注器(VA),這是一個交互式框架,解決了與訓練機器學習分類器傳統技術相關的許多挑戰。VA 利用大型視覺-語言模型的零樣本能力和主動學習技術來提高樣本效率并降低成本。它提供了一種獨特的標注、管理和迭代視頻分類數據集的方法,強調領域專家在人機協作系統中的直接參與。通過使這些用戶能夠在標注過程中快速對困難樣本做出明智決策,VA 提高了系統的整體效率。此外,它還支持持續標注過程,允許用戶快速部署模型,監控其在生產中的質量,并迅速修復任何邊緣案例。
這種自助服務架構使領域專家能夠在沒有數據科學家或第三方標注人員積極參與的情況下進行改進,并培養主人翁意識,從而建立對系統的信任。
我們進行了實驗來研究 VA 的性能,發現它在廣泛的視頻理解任務中,相對于最具競爭力的基線,平均精度中位數提高了 [8.3] 個百分點。我們發布了一個數據集,其中包含由三位專業視頻編輯使用 VA 標注的 [15.3] 萬個標簽,涵蓋 [56] 個視頻理解任務,并發布了代碼以復現我們的實驗。





)



)

:Channel 的實現剖析)

)

)



)