作者:來自 Elastic?Martijn Van Groningen

探索 TSDS 和 LogsDB 的最新增強功能,包括優化 I/O、提升合并性能等。
Elasticsearch 帶來了許多新功能,幫助你為你的使用場景構建最佳搜索解決方案。通過我們的示例筆記本深入學習,開始免費云試用,或立即在本地機器上試用 Elastic。
Elasticsearch 存儲引擎團隊專注于提升存儲效率、索引吞吐量和資源利用率。我們很高興宣布在 Elasticsearch 8.19.0 和 9.1.0 版本中, Time Series Data Streams(TSDS)和 LogsDB 索引模式獲得了多項增強。這些改進源于我們致力于幫助 DevOps、SRE 和安全團隊更有效、更經濟地管理海量日志和指標數據。
LogsDB 和 TSDS 的最新改進自動解決了成本和規模的挑戰,實現了顯著的性能和效率提升:
-
通過優化恢復源數據處理,攝取期間的磁盤 I/O 降低了 50%,帶來更高的索引吞吐量和更低的資源消耗。
-
提升帶有數組的文檔(如 IP 地址列表)的存儲效率,進一步減少磁盤使用并加快索引速度。
-
doc_values 的段合并性能提升最高達 40%。段合并是一個資源密集型的后臺過程,在數據攝取時持續運行。大多數字段啟用了 doc_values 和倒排索引等數據結構,這降低了索引時的整體 CPU 使用率。
-
通過用更高效的跳表實現替換 BKD 樹(僅在 9.1.0 版本提供),_seq_no 字段的存儲減少約 50%。這導致整體存儲使用減少,具體減少量取決于每個文檔的字段數量;在我們的內部時間序列數據基準測試中,總存儲使用減少約 10%。
在我們的內部 LogsDB 基準測試中,這些改進相比 Elasticsearch 8.17.0 版本發布時的 LogsDB,實現了約 16% 的存儲減少和約 19% 的中位索引吞吐量提升。
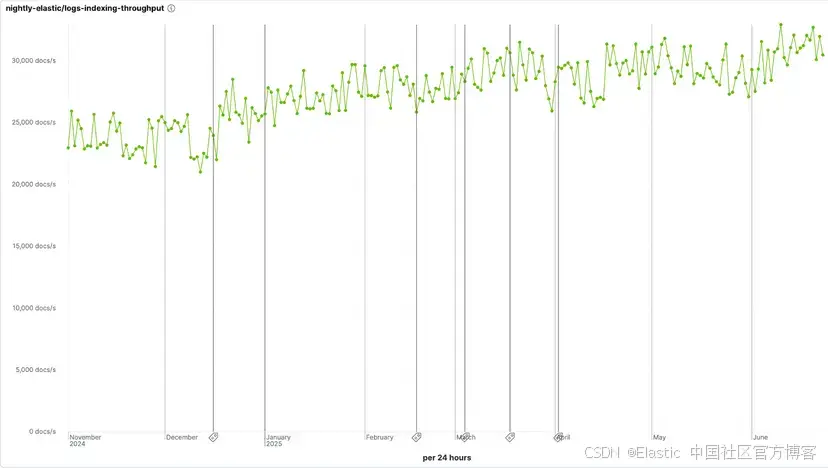
總的來說,與 8.17 版本中的標準模式相比,LogsDB 現在的存儲效率提升最高達 4 倍,而索引吞吐量的損失最多僅為 10%。
| Compared to 8.17 standard | 8.19 logsdb basic | 8.19 logsdb enterprise | 9.1 logsdb basic | 9.1 logsdb enterprise |
|---|---|---|---|---|
| Median indexing throughput overhead | 11.00% | 10.02% | 11.64% | 4.94% |
| Storage (cost) improvement | 2.68x | 3.65x | 2.87x | 3.83x |
除了存儲效率,我們還持續關注索引吞吐量的開銷,因為我們認識到這是采用 LogsDB 的關鍵考量。對此,我們已將該開銷(overhead)降低至 10% 以內(9.1 企業版中甚至低于 5%),使 LogsDB 能夠適用于各種日志管理場景,包括高吞吐量的數據攝取。
基礎:LogsDB 和 TSDS 如何優化存儲
在深入了解新功能之前,讓我們回顧一下 LogsDB 和 TSDS 在管理日志和指標數據方面如此強大的核心原理。這兩種模式都會自動觸發一系列優化,以提升存儲效率,其中兩個最重要的優化是 synthetic _source 和索引排序(index sorting)。
-
索引排序(Index Sorting):該功能確保文檔以特定順序存儲在磁盤上。通過對數據排序(例如按 host.name 和 @timestamp 排序),相似數據被聚集在一起,使現有壓縮技術更為高效,并啟用專門的、依賴順序的編解碼器(如 delta of deltas 和運行長度編碼)。這能進一步減少存儲使用,代價是在索引過程中略微增加 CPU 消耗。
-
synthetic _source:默認情況下,Elasticsearch 在 _source 字段中存儲索引時發送的原始 JSON 文檔。而 synthetic _source 的做法是不存儲 _source,而是從其他已索引的數據結構(如 doc values)實時重建 _source。其權衡是顯著減少存儲空間使用,代價是重建后的 _source 可能在細節上略有不同(例如字段順序可能變化)。這是 LogsDB 和 TSDS 實現存儲節省的核心功能之一。注意:該功能僅對 Elastic Cloud 無服務器客戶和擁有 Enterprise 許可證的組織開放。
這些基礎功能已經帶來了極大的價值,而最新更新則在此基礎上進一步提升了效率。
通過移除恢復源大幅減少磁盤 I/O
即使啟用了 synthetic _source,舊版本的 Elasticsearch 仍會將原始 source 寫入磁盤的一個特殊字段,用于確保副本分片可以通過主分片重放數據來恢復。然而,即使這些原始數據最終會被丟棄,臨時存儲它們也會帶來顯著的磁盤 I/O 開銷。
從 8.19.0 和 9.1.0 版本開始,我們已完全移除這一步驟。Elasticsearch 不再寫入這個臨時恢復源,從而極大提升了索引性能。僅此一項更改,在我們的 TSDS 基準測試中,將寫入時的磁盤 I/O 降低了約 50%。
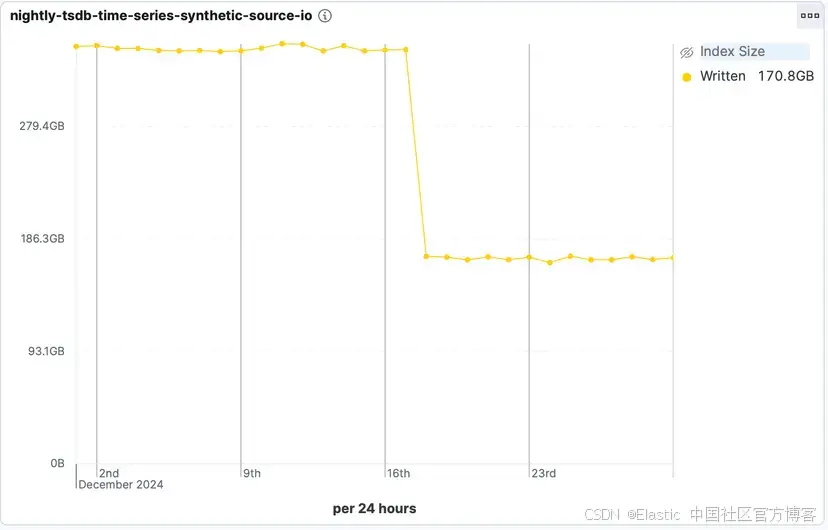
這種磁盤 I/O 的大幅減少直接帶來了 16% 的中位索引吞吐量提升,讓你能夠更快地攝取更多數據。
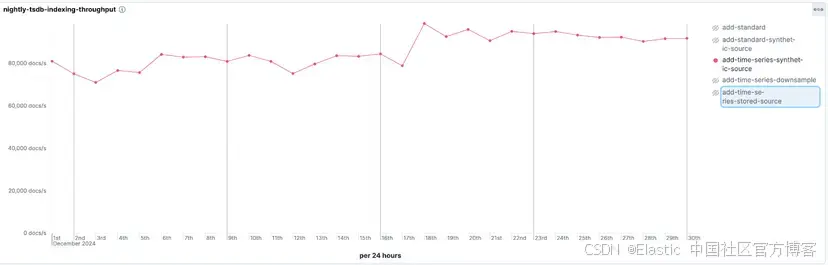
加速段合并以降低 CPU 開銷
Lucene 的 doc values 在 Elasticsearch 中作為列式存儲使用,支撐了排序、聚合和過濾等多種功能(當沒有倒排索引或 BKD 樹時)。啟用索引排序后,將數據刷新到磁盤以及段合并的開銷會增加,因為所有數據結構(包括倒排索引、doc values 和存儲字段,例如 source)都需要按照排序配置進行排序。
我們對這個過程進行了重大優化。此前,每個字段在合并時需多次遍歷文檔(最多四次),每次遍歷都執行一次合并排序,這是一項 CPU 密集型操作。
從 8.19.0 和 9.1.0 版本開始,我們將這個流程優化為每個字段只需一次遍歷即可完成合并。這一更改使 doc values 的段合并速度提升最多達 40%。結果是索引過程中的整體 CPU 占用顯著下降,特別適合高攝取場景,在這些場景下系統需要持續合并段。
更智能的數組處理,實現更高的存儲效率
此前,synthetic _source 無法重建數組中值的順序,因此必須將整個數組存儲在一個名為 _ignored_source 的單獨字段中。這意味著對于包含數組的字段(如安全標簽列表或 IP 地址列表),數據被存儲了兩次:一次在 doc_values 中,另一次在 _ignored_source 中。
現在,我們改進了對基本類型數組的處理方式。在 8.19.0 和 9.1.0 版本中,葉子(leaf)數組字段的順序被保存在一個專門的 doc_values 字段中。這消除了將數據存儲在 _ignored_source 中的需求,減少了存儲使用,并提升了包含大量數組字段的文檔的索引性能。
用跳表替代 BKD 樹,實現最終的存儲壓縮
Elasticsearch 中的每個文檔都有一個 sequence number,存儲在 _seq_no 元數據字段中。該字段原本使用 BKD 樹進行索引,以支持高效的范圍查詢,這對副本同步非常關鍵。例如,副本分片會請求 _seq_no 在 X 和 Y 之間的操作。然而,BKD 樹構建代價高,且占用大量磁盤空間。
在 9.1.0 及更高版本中,LogsDB 和 TSDS 已將 _seq_no 字段的 BKD 樹替換為 Lucene 的新 doc value skippers(基于 doc_values 的輕量跳表實現)。這一變更提升了索引性能,使 _seq_no 字段的存儲減少約 50%,并在我們的時間序列數據內部基準測試中,整體存儲使用進一步降低約 10%。代價是范圍查詢性能略有下降,這些查詢用于主分片到副本分片的復制操作。
整合一切:今天就開始吧
Elasticsearch 8.19.0 和 9.1.0 的最新增強功能,為你的日志和時間序列數據帶來了強大的存儲節省和性能提升。通過優化 I/O、提升合并性能、更智能地處理數組以及精簡元數據,我們讓你比以往任何時候都更輕松、更經濟地長期保留并分析關鍵的運維數據。
想要獲得這些自動優化帶來的好處,今天就升級到 Elastic 8.19.0 或 9.1.0 吧。
準備好深入了解如何優化你的數據存儲了嗎?
-
如果你還沒有賬號,注冊 Elastic Cloud
-
查看 LogsDB 文檔
-
深入了解 Time Series Data Streams(TSDS)
-
享受存儲節省帶來的收益
原文:LogsDB and TSDS performance and storage improvements in Elasticsearch 8.19.0 and 9.1.0 - Elasticsearch Labs
)


關于bosststrap.yml與@RefreshScope)
![[Qt]QString 與Sqlite3 字符串互動[漢字不亂碼]](http://pic.xiahunao.cn/[Qt]QString 與Sqlite3 字符串互動[漢字不亂碼])











上海AI研究院7月22日關閉事件)
)
底層實現原理詳細介紹)
