目錄
一、常見指標
1、IoU
2、Confidence置信度
3、精準度和召回率
4、mAP
5、NMS方法
6、檢測速度
前傳耗時
FPS
7、FLOPs
二、YOLOv1
檢測流程
1、圖像網格劃分
2、類別預測
3、輸出張量
損失函數
優點
缺點
如題,這篇介紹一下目標檢測中常見的一些指標以及簡單分析一下 yolov1 的模型結構。
首先得知道什么是目標檢測:目標檢測(Object Detection)是計算機視覺領域的核心任務之一,旨在識別圖像或視頻中感興趣的物體,并確定它們的位置和類別。與圖像分類(僅識別物體類別)不同,目標檢測需要同時解決分類(whats)和定位(where)兩個問題。
一、常見指標
1、IoU
I 代表【交集】Intersection ,U 代表【并集】Union,IoU全稱是?Intersection over?Union,也就是交并比,舉個例子:
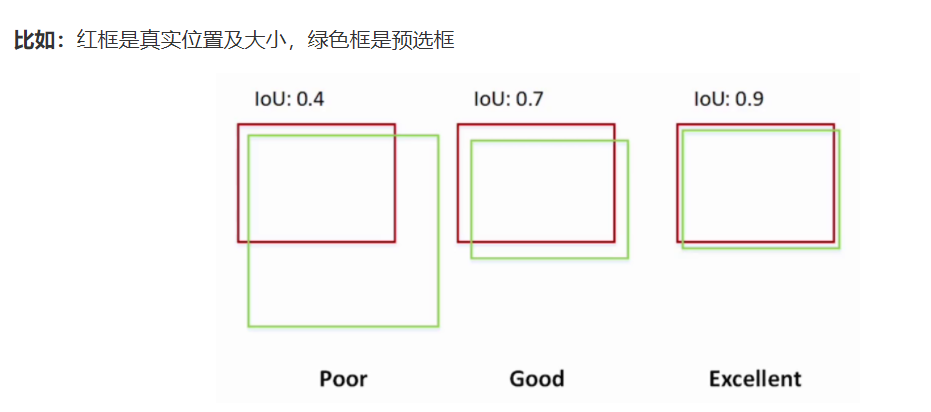
?IoU 值越大代表兩個框的重疊度就越高
2、Confidence置信度
在 YOLO 中,每個預測框都有一個 置信度分數,表示該框包含目標的概率以及預測框的定位準確性,公式如下:
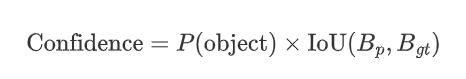
?因此,一個框的置信度越高說明:模型認為該框中高概率存在目標,以及預測框和真實框的位置高度吻合。
3、精準度和召回率
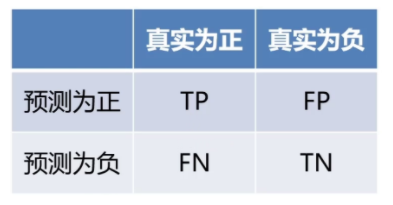
首先要了解混淆矩陣:
-
TP(真正例):模型正確預測為正類(如“是貓”且真是貓)。
-
FN(假反例):模型錯誤預測為負類(真實是貓但預測“非貓”)。
-
FP(假正例):模型錯誤預測為正類(真實非貓但預測“是貓”)。
-
TN(真反例):模型正確預測為負類(真實非貓且預測“非貓”)。
混淆矩陣可以直觀展示分類模型的預測結果與真實標簽的對比,而由混淆矩陣又衍生出精準度(Precision )和召回率(Recall )。
精準度(Precision )定義:模型預測為正類的樣本中,有多少是真正的正類,一句話:檢查誤檢的情況。
公式:
?
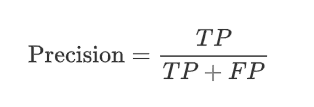
召回率(Recall )定義:真正為正類的樣本中,有多少被模型正確地預測,一句話:檢查漏檢的情況。
公式:
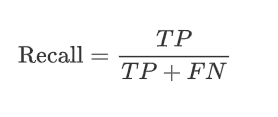
4、mAP
首先要知道 AP是什么,AP 是針對單個類別的檢測質量評估,綜合考量不同置信度閾值下的精準率(Precision)和召回率(Recall),而 mAP(Mean Average Precision) 就是所有類別的AP的平均值,綜合評估模型在所有類別上的整體性能。先計算AP才能得到 mAP,舉個小例子:
現在假設有8個目標,但是檢測出來有20個目標框,目標框的置信度以及正負樣本預測結果如下(IoU閾值假設為0.5):
| ID | Confidence | TP | FP | IoU | Label |
|---|---|---|---|---|---|
| 1 | 0.23 | 0 | 1 | 0.1 | 0 |
| 2 | 0.76 | 1 | 0 | 0.8 | 1 |
| 3 | 0.01 | 0 | 1 | 0.2 | 0 |
| 4 | 0.91 | 1 | 0 | 0.9 | 1 |
| 5 | 0.13 | 0 | 1 | 0.2 | 0 |
| 6 | 0.45 | 0 | 1 | 0.3 | 0 |
| 7 | 0.12 | 1 | 0 | 0.8 | 1 |
| 8 | 0.03 | 0 | 1 | 0.2 | 0 |
| 9 | 0.38 | 1 | 0 | 0.9 | 1 |
| 10 | 0.11 | 0 | 1 | 0.1 | 0 |
| 11 | 0.03 | 0 | 1 | 0.2 | 0 |
| 12 | 0.09 | 0 | 1 | 0.4 | 0 |
| 13 | 0.65 | 0 | 1 | 0.3 | 0 |
| 14 | 0.07 | 0 | 1 | 0.2 | 0 |
| 15 | 0.12 | 0 | 1 | 0.1 | 0 |
| 16 | 0.24 | 1 | 0 | 0.8 | 1 |
| 17 | 0.10 | 0 | 1 | 0.1 | 0 |
| 18 | 0.23 | 0 | 1 | 0.1 | 0 |
| 19 | 0.46 | 0 | 1 | 0.1 | 0 |
| 20 | 0.08 | 1 | 0 | 0.9 | 1 |
計算AP步驟:首先將所有目標框按置信度從高到低排序(這里嚴格來講是要再重新標記TP 和FP的,但是因為表格的 TP/FP 列嚴格基于 IoU≥0.5 和 Label 匹配規則所以可以直接使用,然后我直接用 label 為1 表示 TP,為0 表示 FP ):
| ID | Confidence | Label |
|---|---|---|
| 4 | 0.91 | 1 |
| 2 | 0.76 | 1 |
| 13 | 0.65 | 0 |
| 19 | 0.46 | 0 |
| 6 | 0.45 | 0 |
| 9 | 0.38 | 1 |
| 16 | 0.24 | 1 |
| 1 | 0.23 | 0 |
| 18 | 0.23 | 0 |
| 5 | 0.13 | 0 |
| 7 | 0.12 | 1 |
| 15 | 0.12 | 0 |
| 10 | 0.11 | 0 |
| 17 | 0.10 | 0 |
| 12 | 0.09 | 0 |
| 20 | 0.08 | 1 |
| 14 | 0.07 | 0 |
| 8 | 0.03 | 0 |
| 11 | 0.03 | 0 |
| 3 | 0.01 | 0 |
然后對前 N?個框計算?Precision 和?Recall,N取 1-20:例如 N 為5時,前五行的 TP=2,FP=3,目標一共有8個,則 Precision = 2/5 = 40%,Recall = 2/8 = 25%,計算表格如下:
| 前N行 | Confidence | Label | Recall | Precision |
|---|---|---|---|---|
| 1 | 0.91 | 1 | 1/8(0.125) | 1/1 |
| 2 | 0.76 | 1 | 2/8(0.25) | 2/2 |
| 3 | 0.65 | 0 | 2/8(0.25) | 2/3 |
| 4 | 0.46 | 0 | 2/8(0.25) | 2/4 |
| 5 | 0.45 | 0 | 2/8(0.25) | 2/5 |
| 6 | 0.38 | 1 | 3/8(0.375) | 3/6 |
| 7 | 0.24 | 1 | 4/8(0.5) | 4/7 |
| 8 | 0.23 | 0 | 4/8(0.5) | 4/8 |
| 9 | 0.23 | 0 | 4/8(0.5) | 4/9 |
| 10 | 0.13 | 0 | 4/8(0.5) | 4/10 |
| 11 | 0.12 | 1 | 5/8(0.625) | 5/11 |
| 12 | 0.12 | 0 | 5/8(0.625) | 5/12 |
| 13 | 0.11 | 0 | 5/8(0.625) | 5/13 |
| 14 | 0.10 | 0 | 5/8(0.625) | 5/14 |
| 15 | 0.09 | 0 | 5/8(0.625) | 5/15 |
| 16 | 0.08 | 1 | 6/8(0.75) | 6/16 |
| 17 | 0.07 | 0 | 6/8(0.75) | 6/17 |
| 18 | 0.03 | 0 | 6/8(0.75) | 6/18 |
| 19 | 0.03 | 0 | 6/8(0.75) | 6/19 |
| 20 | 0.01 | 0 | 6/8(0.75) | 6/20 |
最后再由11點插值法計算 AP,公式如下:

比如當 Recall=0.1時,精度值為?Recall=0.1-0.2 (當前閾值和下一級閾值都能取到)之間的最大值,即1,當Recall=0.2時,?精度值為?Recall=0.2-0.3?之間的最大值,也為1,依次計算得到:
| R | 0 | 0.1 | 0.2 | 0.3 | 0.4 | 0.5 | 0.6 | 0.7 | 0.8 | 0.9 | 1.0 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| P | 1.0 | 1.0 | 1.0 | 0.5 | 0.571 | 0.571 | 0.455 | 0.375 | 0 | 0 | 0 |
所以 AP 為:

這里因為只有一個類別,所以 mAP = AP = 49.75%,若再多一個類別 label = 2,則再重復上面的操作,假設得到 label = 2的 AP 為70.25%,則整個 mAP 為 (0.4975+0.7025)/2 = 0.6,即 60%
5、NMS方法
NMS 非極大值抑制(Non-maximum suppression)不是一個指標,而是一個目標檢測的后處理方法,當檢測目標有多個目標框時就需要 NMS來確定最終的一個框,主要用于優化檢測結果,計算步驟如下:
-
設定目標框置信度閾值,常用閾值0.5,小于該值的框(質量不太好)會被過濾掉;
-
根據置信度降序排列候選框;
-
選取置信度最高的框A 將其添加到輸出列表,并從候選框列表中刪除;
-
候選框列表中所有框依次與 框A 計算 loU,刪除大于IoU閾值(高度重疊)的框(可以檢測同一個類別的多個目標,比如一張圖中不會只有一個人,如果光找置信度最高的框,只會選出一個人的框,因為置信度包含某一個大類別的概率)
-
重復上述過程,直到候選框列表為空;
-
輸出列表就是最后留下的目標框,在保留多個目標的同時,去掉對同一個目標的重復預測框。
但是缺點也比較明顯,就是一個框只能預測一個結果,如果有兩個及其以上的目標重疊在一起,則可能會丟失目標,所以后續會優化
6、檢測速度
前傳耗時
單位 ms,從輸入圖像到輸出最終結果所消耗的時間,包括前處理耗時(如圖像歸一化)、網絡前傳耗時、后處理耗時(如非極大值抑制)。
FPS
Frames Per Second,每秒鐘能處理的圖像數量,一般每秒處理36幀才能處理實時數據。
7、FLOPs
浮點運算量,處理一張圖像所需要的浮點運算數量,跟具體軟硬件沒有關系,可以公平地比較不同算法之間的檢測速,計算公式為:
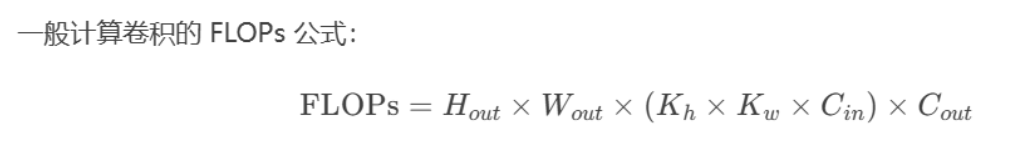
例如,一張64x64x128的特征圖用 3x3 的卷積核卷完后,最終輸出的通道數為256,則這個過程中的浮點運算量為 (64x64) x128x (3x3) x256 .
二、YOLOv1
YOLOv1(You Only Look Once version 1)是2016年由Joseph Redmon等人提出的首個基于單階段(one-stage)目標檢測算法,其核心思想是將目標檢測任務轉化為單一的回歸問題,通過一次前向傳播即可直接預測目標的類別和位置,下面具體講解一下檢測流程(網絡結構這些苯人就不說了):
檢測流程
1、圖像網格劃分
?將輸入圖像劃分為 SxS 個網格(論文中S=7),每個格子預測 B 個?Bounding Box(論文中B=2),其中每個框包括中心點坐標(x, y)、寬w、高h、置信度conf
2、類別預測
每個格子預測 20 個類別的概率(當時VOC數據集是20分類 )
3、輸出張量
最終輸出維度為 7x7x30:
這里的 7x7 代表格子數,30 = 2x5+20,2x5 表示兩個框內的中心坐標、寬高以及置信度,20表示每個格子代表的20個類別概率,最終會選擇置信度較大的框作為預測結果。
損失函數
整個YOLOv1的損失函數由五部分組成:
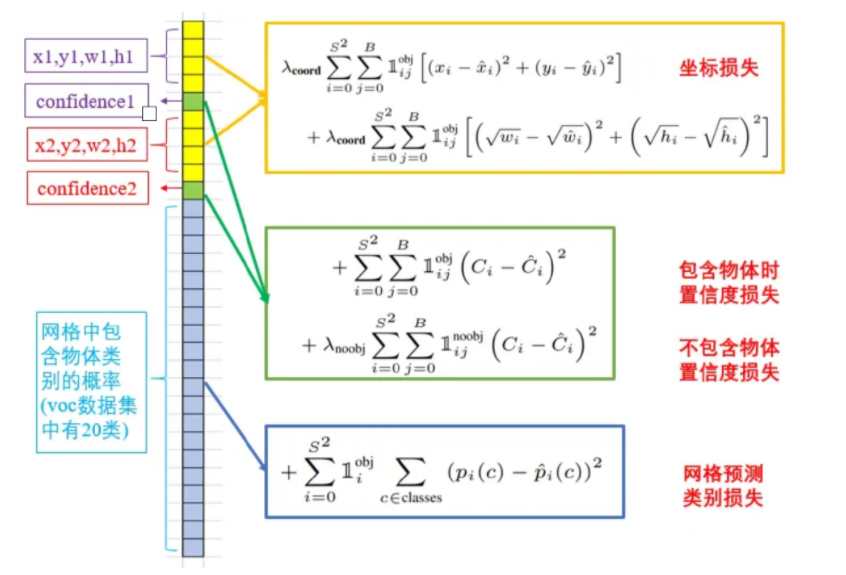
合并后的公式如下:

這里就不詳細介紹了,可以自己研究研究,那個?(下標為ij) 代表的意思是如果第i個格子第j個框有物體時則值為1,反之為0.
優點
-
速度快:單階段檢測,實時性強(45 FPS,快速版達150 FPS)。
-
全局推理:直接處理整張圖像,減少背景誤檢(相比R-CNN系列)。
-
端到端訓練:簡化流程,無需區域提議。
缺點
-
定位精度較低:尤其對小目標和密集目標檢測效果差(網格劃分限制)。
-
每個網格僅預測一類:難以處理重疊目標。
-
邊界框形狀受限:預設的Anchor機制未引入(YOLOv2改進)
這篇就到此為止,下一篇可能是YOLOv2?~ (??????)??
以上有問題可以指出。


游記))
 部署資源的完整配置OceanBase)
)



如何以硬核科技重塑專業音頻版圖)
:Java客戶端開發(原生API)詳解)




 A - D題詳細題解)
)



