“基于森林的分類與回歸”,它可以幫助分析師有效地設計、測試和部署預測模型。
基于森林的分類與回歸應用了 Leo Breiman 的隨機森林算法,這是一種用于分類和預測的流行監督機器學習方法。該工具允許分析師輕松整合表格屬性、基于距離的要素和解釋柵格來構建預測模型,并擴展預測模型,使其可供所有 GIS 用戶使用。
為了展示基于森林的分類與回歸模型的潛力,我們解決了數據科學界的一個熱門問題:預測房屋售價。讓我們來看一個基礎練習,構建一個融入空間因素的模型,以幫助改進加州房屋售價的預測。
預測加州房價
我們將首先使用 Kaggle 上流行的加州住房數據集,其中包含加州的各個地區以及每個地區房屋的一系列聚合屬性。
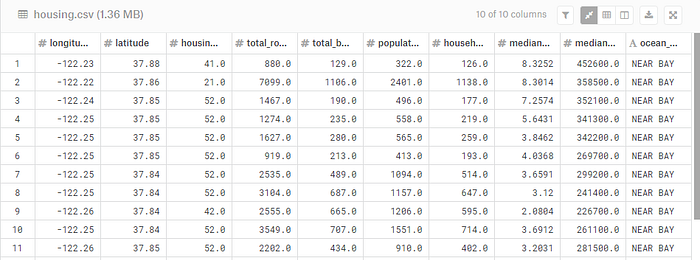
僅通過查看上表很難做出任何有意義的事情,因此讓我們繪制每個區域的地圖,并用每個地點的平均房屋銷售價值來表示:
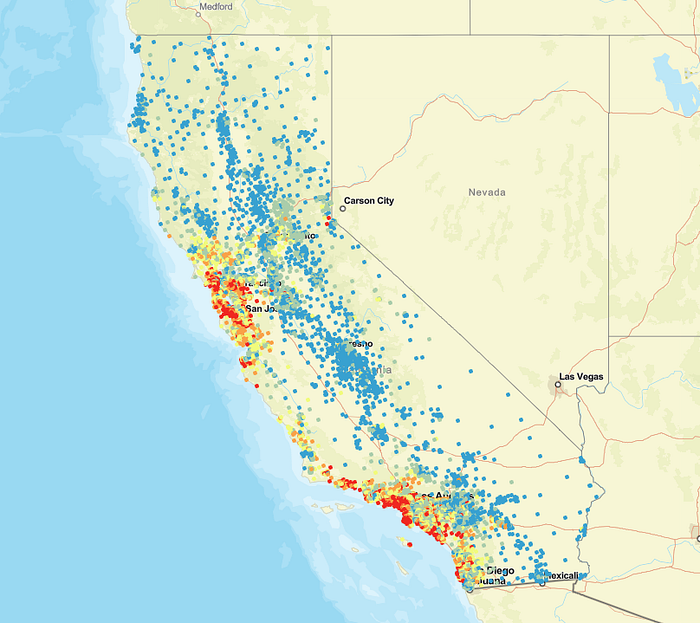
加州各地區房屋銷售價值
在這張地圖中,每個點都代表加利福尼亞州某個區域的質心。顏色范圍代表該區域內所有房屋的平均售價。藍色代表低售價,黃色代表中等售價,紅色代表最高售價。
僅從這張地圖來看,您是否注意到了任何一般模式?
您可能會注意到,價格較高的房屋通常位于最大的都市區附近。您還可能會注意到,價格較高的房屋通常位于海岸線附近。ArcGIS Pro 中的快速探索性圖表可幫助我們探索這些模式:
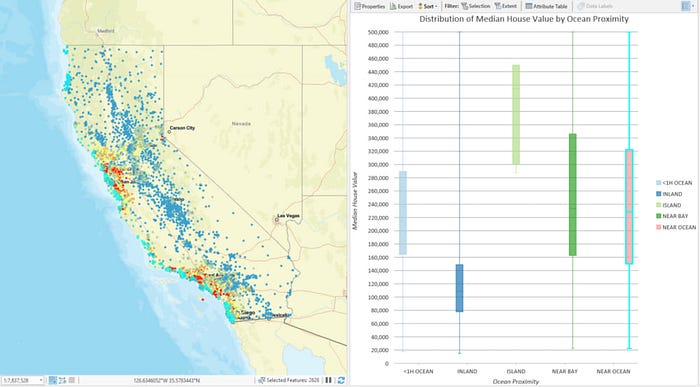
房屋中位價按距離海洋的分布
讓我們查看所提供表格中的其余數據。每條記錄包含該區域內所有房屋的一些基本數據點:
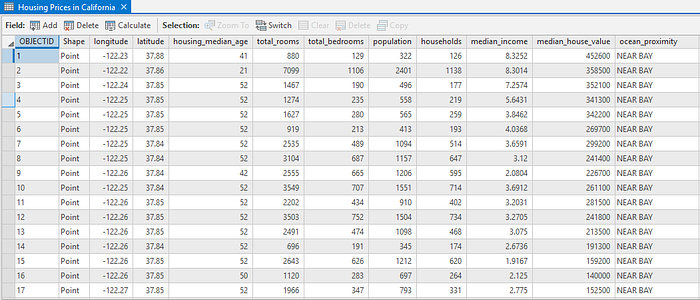
每個區域的房屋中位價是我們要預測的變量,這些屬性對于幫助估計每個價值可能很重要。
我們將首先參考 Aurélien Geron 在其著作《使用 Scikit-Learn 和 TensorFlow 進行機器學習》中提供的示例,該書主要使用非空間因素(即上表中所示的屬性)構建了一個隨機森林模型。我們將此模型與第二個模型進行比較,在該模型中,我們開始引入其他 GIS 圖層,以評估每個區域與感興趣地點的距離如何幫助該模型在估算房屋中位價時有所改進。
非空間模型
我們的第一個模型將遵循使用 Scikit-Learn 和 TensorFlow 進行機器學習的示例,對每個道記錄使用以下特征:
- 中位數收入
- 住房平均年齡
- 客房總數
- 臥室總數
- 人口
- 家庭
- 靠近海洋
讓我們打開基于森林的分類和回歸工具并開始吧:
第一個參數指定要執行的運行類型。對于此基礎探索,我們希望評估模型診斷(即預測性能),并在引入和測試因子組合時監測變化。因此,我們將此參數保留為“僅訓練”。
我們將指定輸入訓練特征,使用“median_house_value”屬性傳遞加利福尼亞州各區域的 GIS 圖層作為預測變量,然后在“解釋訓練變量”參數部分中,通過選擇輸入數據中相應的列來指定模型將使用哪些屬性。完成后,您的地理處理工具輸入應如下所示:
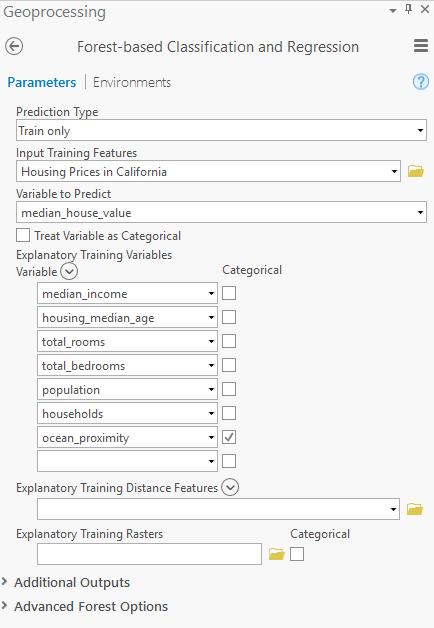
執行模型后,該工具會構建一個森林,用于建立解釋變量與指定要預測的變量之間的關系。有關此工具工作原理的更多信息,請務必閱讀此內容。
一旦工具完成運行,您應該收到有關模型性能的詳細診斷:
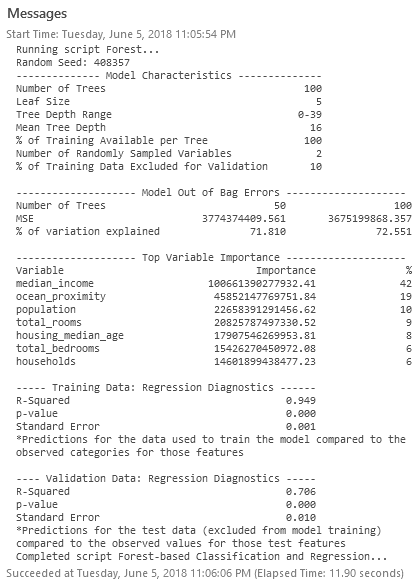
對主要變量重要性的評估可以大致了解哪些因素對模型有幫助(中位數收入和海洋距離非常重要)。現在,讓我們記下 R 平方值:0.706(實際執行時可能會略有不同)。
請注意:要創建一個每次運行都不會發生變化的模型,可以在隨機數生成器環境設置中設置種子。模型中仍然會存在隨機性,但該隨機性在每次運行之間保持一致。
空間模型
既然我們已經嘗試了主要使用非空間因素的房屋銷售價值估算方法,那么讓我們來探索一下,隨著引入基于距離的訓練特征,模型會發生怎樣的變化。目標是計算每個地塊與一系列與房價相關的潛在重要特征之間的距離。為了進行簡單的探索性練習,我們引入了高爾夫球場、學校、醫院、休閑區和墓地等點要素類。我們還將引入加州海岸線的折線要素類。
為了計算所有這些距離,您可以構思一個腳本來迭代每個記錄并運行一些鄰近函數來確定每個幾何記錄之間的距離……或者您可以簡單地打開基于森林的分類和回歸工具并將每個要素類拖放到解釋訓練距離要素參數中:

加載完每個距離要素后,我們就可以運行該工具了。此時我們的參數如下所示:
請隨意嘗試您自己的潛在解釋訓練因素!舉個簡單的例子:您能否找到一個公共交通站點位置的數據集,將其導入 ArcGIS Pro 項目,并將這些位置加載到“解釋訓練距離要素”參數中?這個因素會如何改變您的模型?
一旦工具運行,我們就可以評估我們的診斷并與原始模型進行比較:
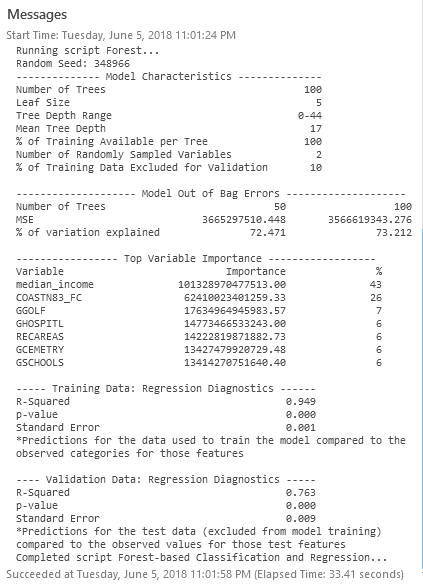
新的回歸診斷結果的 R 平方為 0.763。有趣的是,一個主要考慮距離因素的基礎模型的表現比主要考慮房屋非空間特征(例如浴室數量等)的原始模型略好。總而言之,這證明了“位置、位置、位置”這句格言的真實性!
該工具的運行還將提供輸入數據的模型輸出:
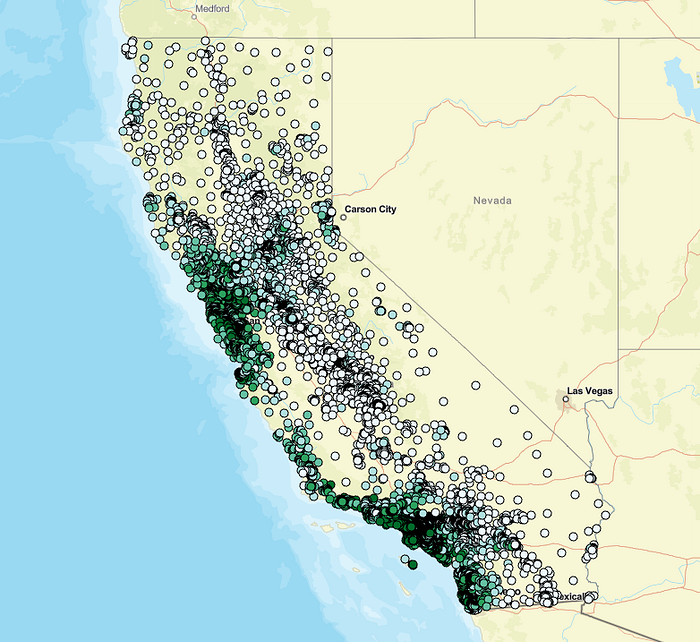
由于我們基本上是基于已知值的記錄進行預測,因此這本身并沒有什么用處,但它有助于了解基于距離的特征如何影響模型性能。更棒的是,能夠以如此快速直觀的方式將現有的額外 GIS 數據整合到模型的鄰近性考量中,這非常有用。
注意:基于森林的分類與回歸的另一個重要方面是,候選解釋因素中的多重共線性效應不會妨礙您創建有效的模型。為了了解隨機森林如何緩解多重共線性問題,我建議您進一步探索工具文檔和其他隨機森林文檔。
結論和資源
執行分析以預測任何事件或值必然是一項探索性、迭代性、混亂且耗時的工作。為了支持這些工作流程,我們需要能夠快速整合空間數據、支持測試、快速評估結果并允許重復操作直至獲得滿意結果的工具。
基于森林的分類和回歸擴展了強大的隨機森林機器學習算法的實用性,它不僅能夠考慮模型中的屬性數據,還能考慮基于距離的訓練特征和解釋柵格,以便在分析中利用位置。

網絡協議封裝)
)
/夏令營:讓AI理解列車排期表(Task3))






)
數據結構動態鏈表list)






:Pandas 在機器學習中的應用)
