要構建自定義模型,需完成兩個核心步驟:繼承 nn.Module 類;重載 __init__ 方法(初始化)和 forward 方法(前向計算)
神經網絡的構造
初始化方法(__init__)
def __init__(self, **kwargs):# 調用父類構造函數,確保Module的初始化邏輯被執行super(MLP, self).__init__(** kwargs)# 定義隱藏層:輸入784維,輸出256維self.hidden = nn.Linear(784, 256)# 定義激活函數self.act = nn.ReLU()# 定義輸出層:輸入256維,輸出10維self.output = nn.Linear(256, 10)super(MLP, self).__init__(**kwargs)這行代碼非常重要,它會調用父類 Module 的構造函數,完成必要的初始化工作;self.hidden、self.act、self.output這些是我們定義的網絡組件
**kwargs 是一個特殊的語法,用于在函數定義時接收任意數量的關鍵字參數(Keyword Arguments)。** 的作用是將參數收集為一個字典(dict),鍵為參數名,值為參數值。必須放在函數參數列表的末尾,否則會報錯。

前向傳播方法(forward)
def forward(self, x):o = self.act(self.hidden(x)) # 輸入→隱藏層→激活函數return self.output(o) # 激活結果→輸出層輸入 x 首先通過隱藏層 self.hidden 進行線性變換;變換結果通過激活函數 self.act(ReLU)引入非線性特性;最后通過輸出層 self.output 得到最終輸出
我們只需要定義前向傳播,反向傳播會由 PyTorch 的自動求導機制自動生成
創建模型實例
net = MLP() # 實例化MLP模型
print(net) # 打印模型結構輸出:
MLP((hidden): Linear(in_features=784, out_features=256, bias=True)(act): ReLU()(output): Linear(in_features=256, out_features=10, bias=True)
)這表明我們的模型包含:
一個名為 hidden 的線性層(輸入 784 維,輸出 256 維)
一個 ReLU 激活函數層
一個名為 output 的線性層(輸入 256 維,輸出 10 維)
執行前向計算
X = torch.rand(2, 784)
output = net(X) # 執行前向計算
print(output)輸出:
tensor([[ 0.0149, -0.2641, -0.0040, 0.0945, -0.1277, -0.0092, 0.0343, 0.0627,-0.1742, 0.1866],[ 0.0738, -0.1409, 0.0790, 0.0597, -0.1572, 0.0479, -0.0519, 0.0211,-0.1435, 0.1958]], grad_fn=<AddmmBackward>)輸出結果是一個形狀為 (2, 10) 的張量,表示:2 個樣本的輸出,每個樣本有 10 個輸出值
這里并沒有將?
Module?類命名為?Layer?(層)或者?Model?(模型)之類的名字,這是因為該類是一個可供?由組建的部件。它的子類既可以是?個層(如PyTorch提供的 Linear 類),?可以是一個模型(如這里定義的 MLP 類),或者是模型的?個部分。
神經網絡中常見的層
不含模型參數的層
import torch
from torch import nnclass MyLayer(nn.Module):def __init__(self, **kwargs):super(MyLayer, self).__init__(**kwargs)def forward(self, x):return x - x.mean()# 測試
layer = MyLayer()
print(layer(torch.tensor([1, 2, 3, 4, 5], dtype=torch.float)))
# 輸出: tensor([-2., -1., 0., 1., 2.])這個層不含模型參數,作用是把輸入減去均值后輸出
- 無參數:不需要訓練參數
- 功能單一:通常執行固定的數學變換
- 可復用:可以在多個模型中重復使用
含模型參數的自定義層
Parameter?類其實是?Tensor?的子類,如果一個?Tensor?是?Parameter?,那么它會?動被添加到模型的參數列表里。所以在?定義含模型參數的層時,我們應該將參數定義成?Parameter?,除了直接定義成?Parameter?類外,還可以使??ParameterList?和?ParameterDict?分別定義參數的列表和字典。
使用?ParameterList?管理參數列表
與普通 Python 列表的關鍵區別在于,nn.ParameterList會通知 PyTorch 這些是需要優化的參數。
class MyListDense(nn.Module):def __init__(self):super(MyListDense, self).__init__()# 創建3個4x4的參數矩陣self.params = nn.ParameterList([nn.Parameter(torch.randn(4, 4)) for _ in range(3)])# 添加一個4x1的參數矩陣self.params.append(nn.Parameter(torch.randn(4, 1)))def forward(self, x):for param in self.params:x = torch.mm(x, param)return x# 測試
net = MyListDense()
print(net)使用?ParameterDict?管理參數字典
ParameterDict?用于管理帶鍵名的參數字典,適合需要根據條件選擇不同參數的場景:
class MyDictDense(nn.Module):def __init__(self):super(MyDictDense, self).__init__()# 初始化參數字典self.params = nn.ParameterDict({'linear1': nn.Parameter(torch.randn(4, 4)),'linear2': nn.Parameter(torch.randn(4, 1))})# 添加新參數self.params.update({'linear3': nn.Parameter(torch.randn(4, 2))})def forward(self, x, choice='linear1'):return torch.mm(x, self.params[choice])# 測試
net = MyDictDense()
print(net)
print(net(torch.randn(1, 4), 'linear2')) # 使用指定參數進行前向計算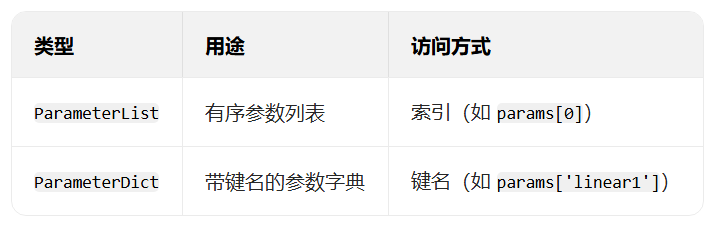
自定義二維卷積層
import torch
from torch import nn# 卷積運算(二維互相關)
def corr2d(X, K):h, w = K.shapeX, K = X.float(), K.float()Y = torch.zeros((X.shape[0] - h + 1, X.shape[1] - w + 1))for i in range(Y.shape[0]):for j in range(Y.shape[1]):Y[i, j] = (X[i: i + h, j: j + w] * K).sum()return Y# 二維卷積層
class Conv2D(nn.Module):def __init__(self, kernel_size):super(Conv2D, self).__init__()# 初始化卷積核參數self.weight = nn.Parameter(torch.randn(kernel_size))# 初始化偏置參數self.bias = nn.Parameter(torch.randn(1))def forward(self, x):return corr2d(x, self.weight) + self.bias首先根據卷積核的大小確定輸出特征圖的尺寸,然后通過雙重循環遍歷輸入的每個可能區域,在每個區域上執行元素級乘法并求和,得到對應位置的輸出值。這個過程可以看作是使用一個小的矩陣(卷積核)在大矩陣(輸入)上滑動,每次計算重疊區域的相似度。
自定義的 Conv2D 模塊繼承自 nn.Module,包含權重和偏置兩個核心參數。權重參數表示卷積核,其形狀由 kernel_size 參數指定,而偏置參數則為每個輸出值添加一個可學習的常數。前向傳播過程簡單直接:調用 corr2d 函數執行卷積操作,然后添加偏置項。
卷積層的填充與步幅
保持輸出尺寸與輸入相同
這段代碼展示了如何使用 PyTorch 的卷積層并通過填充 (padding) 操作保持輸入輸出尺寸相同。我們先看comp_conv2d輔助函數,它的作用是簡化卷積操作的調用:將輸入張量擴展為包含批量維度和通道維度的四維張量 (格式為[批量, 通道, 高度, 寬度]),然后通過卷積層計算輸出,最后再移除批量和通道維度,返回二維的輸出結果。
具體來看卷積層的定義:這里創建了一個nn.Conv2d實例,設置了輸入通道數和輸出通道數都為 1(處理單通道圖像),卷積核大小為 3×3,并指定了兩側各填充 1 個像素。當卷積核在圖像上滑動時,填充操作會在輸入圖像的邊界周圍添加額外的像素(默認填充值為 0),這樣可以避免卷積操作導致的尺寸縮減。
在二維卷積操作中,輸出尺寸的計算公式為:
輸出高度 = (輸入高度 + 2× 填充 - 卷積核高度) / 步長 + 1
輸出寬度 = (輸入寬度 + 2× 填充 - 卷積核寬度) / 步長 + 1
填充(padding)是指在輸?高和寬的兩側填充元素(通常是0元素)。
例子中,參數設置如下:
- 輸入尺寸:8×8
- 卷積核大小:3×3(高度 = 3,寬度 = 3)
- 填充(padding):1(兩側各填充 1 個像素)
- 步長(stride):默認值 1(代碼中未顯式指定)
當我們設置padding=1時,PyTorch 會在輸入張量的上下左右各添加 1 行 / 列的零值像素。因此,實際參與卷積計算的輸入尺寸變為:
原始高度 + 2×填充 = 8 + 2×1 = 10
原始寬度 + 2×填充 = 8 + 2×1 = 10對于 3×3 的卷積核,在填充后的 10×10 輸入上滑動時,其中心點可以到達的有效區域為:
- 垂直方向:從第 2 行(索引 1)到第 9 行(索引 8),共 8 個位置
- 水平方向:從第 2 列(索引 1)到第 9 列(索引 8),共 8 個位置
因此有:
輸出高度 = (10 - 3) / 1 + 1 = 7 + 1 = 8? ? ? ? ?輸出寬度 = (10 - 3) / 1 + 1 = 7 + 1 = 8
import torch
from torch import nn# 輔助函數:計算卷積結果
def comp_conv2d(conv2d, X):X = X.view((1, 1) + X.shape) # 添加批量和通道維度Y = conv2d(X)return Y.view(Y.shape[2:]) # 移除批量和通道維度# 3x3卷積核,兩側各填充1
conv2d = nn.Conv2d(in_channels=1, out_channels=1, kernel_size=3, padding=1)X = torch.rand(8, 8) # 輸入尺寸8x8
print(comp_conv2d(conv2d, X).shape) # 輸出尺寸仍為8x8非對稱填充與步幅
# 5x3卷積核,高度方向填充2,寬度方向填充1,步幅為(3, 4)
conv2d = nn.Conv2d(1, 1, kernel_size=(5, 3), padding=(2, 1), stride=(3, 4))
print(comp_conv2d(conv2d, X).shape) # 輸出尺寸: [2, 2]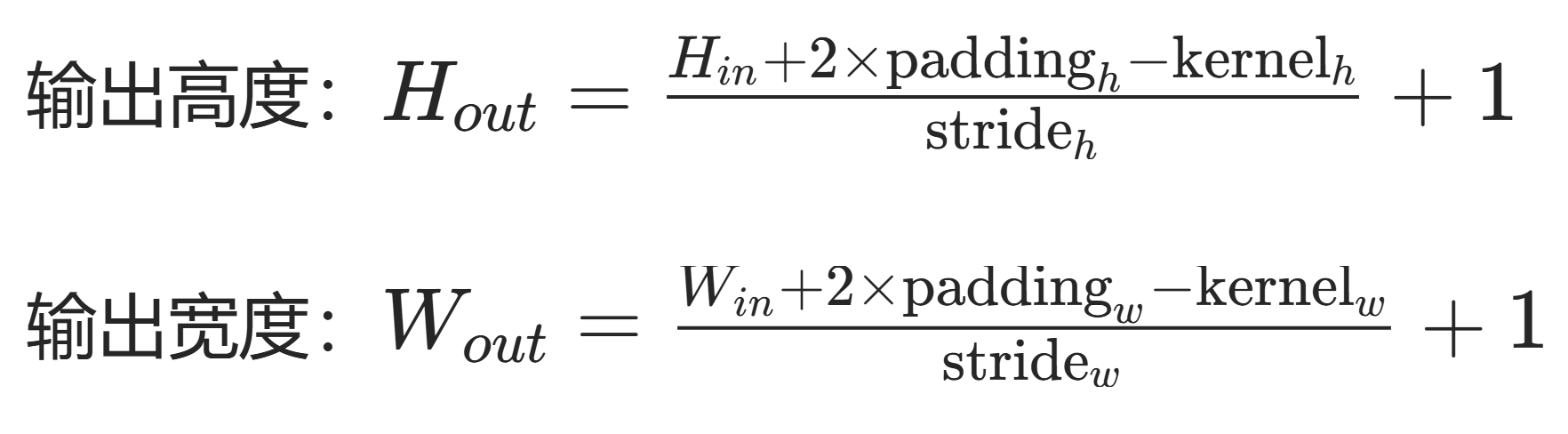
自定義池化層
池化層(Pooling Layer)是一種重要的下采樣操作層,它的核心作用是通過對輸入特征圖的局部區域進行聚合計算,在減少特征圖尺寸的同時保留關鍵信息。池化層就像一個 “信息篩選器”,它會滑動過輸入的特征圖,對每個局部區域提取一個代表性的值,讓特征圖變得更緊湊。
import torch
from torch import nndef pool2d(X, pool_size, mode='max'):p_h, p_w = pool_sizeY = torch.zeros((X.shape[0] - p_h + 1, X.shape[1] - p_w + 1))for i in range(Y.shape[0]):for j in range(Y.shape[1]):if mode == 'max':Y[i, j] = X[i: i + p_h, j: j + p_w].max() # 最大池化elif mode == 'avg':Y[i, j] = X[i: i + p_h, j: j + p_w].mean() # 平均池化return Y# 測試
X = torch.tensor([[0, 1, 2], [3, 4, 5], [6, 7, 8]], dtype=torch.float)
print(pool2d(X, (2, 2))) # 最大池化結果
print(pool2d(X, (2, 2), 'avg')) # 平均池化結果pool2d函數模擬了池化操作的基本過程。它需要輸入張量X、池化窗口大小pool_size,以及指定池化模式(最大池化或平均池化)。函數首先根據輸入尺寸和池化窗口大小計算輸出特征圖的尺寸,輸出高度為輸入高度減去池化窗口高度再加 1,寬度同理,這和卷積操作中計算輸出尺寸的邏輯類似,因為池化窗口也是通過滑動來覆蓋輸入的。然后通過兩層循環遍歷輸出特征圖的每個位置,對輸入中對應池化窗口覆蓋的局部區域進行聚合計算,得到輸出特征圖的每個元素。
最大池化(Max Pooling)是池化層中最常用的一種方式,它的計算邏輯是在每個池化窗口覆蓋的局部區域內,選取數值最大的元素作為該區域的代表值。比如在測試用例中,輸入X是一個 3×3 的張量[[0, 1, 2], [3, 4, 5], [6, 7, 8]],使用 2×2 的池化窗口進行最大池化時,第一個窗口覆蓋的區域是[[0, 1], [3, 4]],其中最大的值是 4;第二個窗口覆蓋[[1, 2], [4, 5]],最大值是 5;第三個窗口覆蓋[[3, 4], [6, 7]],最大值是 7;第四個窗口覆蓋[[4, 5], [7, 8]],最大值是 8,所以輸出的最大池化結果是[[4., 5.], [7., 8.]]。最大池化的優勢在于能夠突出局部區域中最顯著的特征,比如圖像中亮度最高的像素點,適合保留邊緣、紋理等關鍵信息。
平均池化(Average Pooling)則是另一種常見的池化方式,它在每個池化窗口覆蓋的局部區域內,計算所有元素的平均值作為該區域的代表值。同樣以測試用例為例,2×2 池化窗口下,第一個窗口[[0, 1], [3, 4]]的平均值是(0+1+3+4)/4 = 2;第二個窗口[[1, 2], [4, 5]]的平均值是(1+2+4+5)/4 = 3;第三個窗口[[3, 4], [6, 7]]的平均值是(3+4+6+7)/4 = 5;第四個窗口[[4, 5], [7, 8]]的平均值是(4+5+7+8)/4 = 6,所以平均池化的輸出結果是[[2., 3.], [5., 6.]]。平均池化的特點是能夠平滑局部區域的特征,保留區域的整體趨勢,避免個別極端值對特征的過度影響。
- 無參數:不需要訓練參數
- 降維:減小特征圖尺寸,降低計算復雜度
- 特征提取:保留主要特征,增強模型魯棒性
模型示例
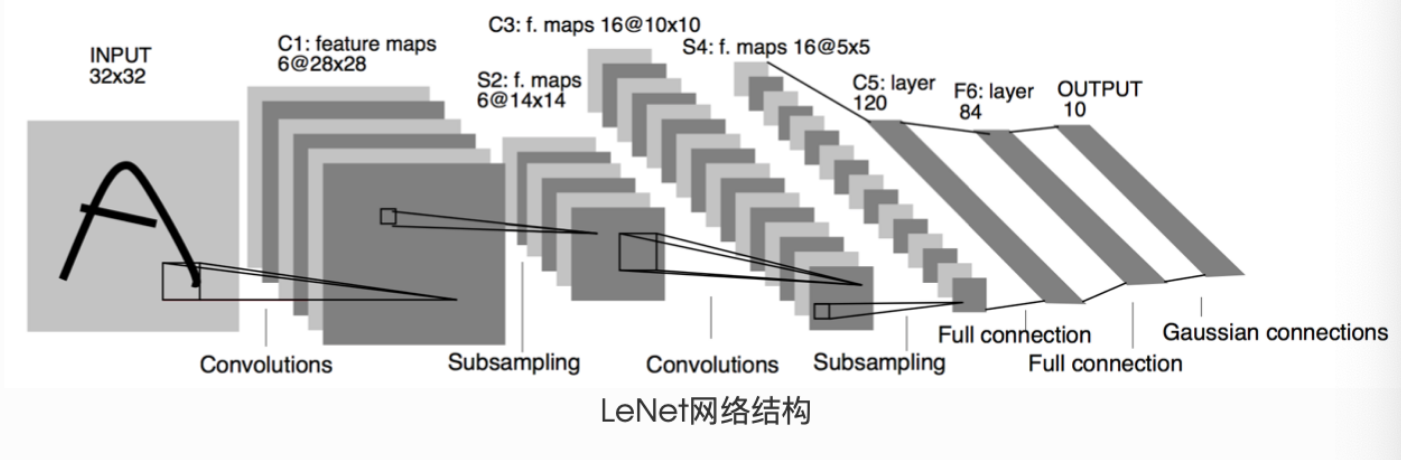
LeNet
LeNet 是由深度學習先驅 Yann LeCun 于 1998 年提出的卷積神經網絡,專門用于手寫數字識別任務。作為早期卷積神經網絡的經典代表,LeNet 展示了卷積操作在圖像處理中的強大能力,為后續深度學習的發展奠定了重要基礎。
LeNet 采用了卷積層 + 池化層 + 全連接層的經典組合結構,其核心思想是利用卷積操作提取圖像局部特征,通過池化層降低特征維度,最后通過全連接層完成分類。標準 LeNet-5 結構包含 7 層(不含輸入層),分為特征提取和分類兩個部分:
- 特征提取部分:由 2 個卷積層和 2 個池化層交替組成
- 分類部分:由 3 個全連接層組成
一個神經網絡的典型訓練過程如下:
定義包含一些可學習參數(或者叫權重)的神經網絡
在輸入數據集上迭代
通過網絡處理輸入
計算 loss (輸出和正確答案的距離)
將梯度反向傳播給網絡的參數
更新網絡的權重,一般使用一個簡單的規則:
weight?=?weight?-?learning_rate?*?gradient
Net((conv1): Conv2d(1, 6, kernel_size=(5, 5), stride=(1, 1)) # 第一個卷積層(conv2): Conv2d(6, 16, kernel_size=(5, 5), stride=(1, 1)) # 第二個卷積層(fc1): Linear(in_features=400, out_features=120, bias=True) # 第一個全連接層(fc2): Linear(in_features=120, out_features=84, bias=True) # 第二個全連接層(fc3): Linear(in_features=84, out_features=10, bias=True) # 第三個全連接層
)網絡初始化(__init__?方法)
import torch
import torch.nn as nn
import torch.nn.functional as Fclass Net(nn.Module):def __init__(self):super(Net, self).__init__()# 輸入圖像channel:1;輸出channel:6;5x5卷積核self.conv1 = nn.Conv2d(1, 6, 5)self.conv2 = nn.Conv2d(6, 16, 5)# 全連接層:y = Wx + bself.fc1 = nn.Linear(16 * 5 * 5, 120)self.fc2 = nn.Linear(120, 84)self.fc3 = nn.Linear(84, 10)- conv1:輸入通道數 = 1(灰度圖像),輸出通道數 = 6,卷積核大小 = 5×5
- conv2:輸入通道數 = 6(上一層輸出),輸出通道數 = 16,卷積核大小 = 5×5
- fc1:輸入特征數 = 16×5×5(上一層輸出展平后),輸出特征數 = 120
- fc2:輸入特征數 = 120,輸出特征數 = 84
- fc3:輸入特征數 = 84,輸出特征數 = 10(對應 10 個類別)
前向傳播(forward?方法)
def forward(self, x):# 第一層:卷積 → ReLU激活 → 2x2最大池化x = F.max_pool2d(F.relu(self.conv1(x)), (2, 2))# 第二層:卷積 → ReLU激活 → 2x2最大池化(方陣可簡化參數)x = F.max_pool2d(F.relu(self.conv2(x)), 2)# 展平特征圖:將多維特征轉為一維向量x = x.view(-1, self.num_flat_features(x))# 第三層:全連接 → ReLU激活x = F.relu(self.fc1(x))# 第四層:全連接 → ReLU激活x = F.relu(self.fc2(x))# 輸出層:全連接(無激活函數,通常配合softmax使用)x = self.fc3(x)return x輸入圖像 [batch_size, 3, 224, 224]
↓ 第一層卷積+池化 [batch_size, 16, 112, 112]
↓ 第二層卷積+池化 [batch_size, 32, 56, 56]
↓ 展平 [batch_size, 100352]
↓ 全連接層1 [batch_size, 1024]
↓ 全連接層2 [batch_size, 512]
↓ 輸出層 [batch_size, 10]輔助函數:特征展平計算
def num_flat_features(self, x):size = x.size()[1:] # 除去批處理維度的其他所有維度num_features = 1for s in size:num_features *= sreturn num_features在卷積神經網絡中,當我們從卷積層過渡到全連接層時,需要將多維的特征圖(例如[batch_size, channels, height, width])展平為一維向量。這個函數就是用來計算展平后的向量長度的。
LeNet 的參數與計算特性
params = list(net.parameters())
print(f"參數總數: {len(params)}")
print(f"conv1權重維度: {params[0].size()}") # conv1的權重參數輸出:
參數總數: 10
conv1權重維度: torch.Size([6, 1, 5, 5])每個卷積層包含:權重參數(out_channels × in_channels × kH × kW)+ 偏置參數(out_channels)
每個全連接層包含:權重參數(out_features × in_features)+ 偏置參數(out_features)
總參數計算:卷積層參數 + 全連接層參數 = 10 組參數(5 層 ×2 組參數 / 層)
前向傳播測試
# 創建隨機輸入:batch_size=1,通道=1,高=32,寬=32
input = torch.randn(1, 1, 32, 32)
# 前向傳播計算
out = net(input)
print(out) # 輸出10個類別的原始分數(logits)輸出:
tensor([[ 0.0672, -0.0743, 0.1058, -0.0181, 0.0536, 0.0736, -0.0764, -0.0423,0.0332, -0.0425]], grad_fn=<AddmmBackward>)反向傳播
# 清零所有參數的梯度緩存
net.zero_grad()
# 隨機創建梯度張量,模擬反向傳播
out.backward(torch.randn(1, 10))torch.nn包對輸入數據的處理要求 —— 它只支持小批量(mini-batches)樣本輸入,不直接接受單個樣本。這意味著無論是卷積層、全連接層還是其他網絡層,輸入張量都需要包含批量維度。例如nn.Conv2d要求輸入是 4 維張量,形狀為nSamples x nChannels x Height x Width,其中nSamples就是批量大小。如果只有單個樣本,需要用input.unsqueeze(0)在第 0 維添加一個 “假的” 批量維度,把形狀從nChannels x Height x Width變成1 x nChannels x Height x Width,這樣才能被網絡層正確處理。
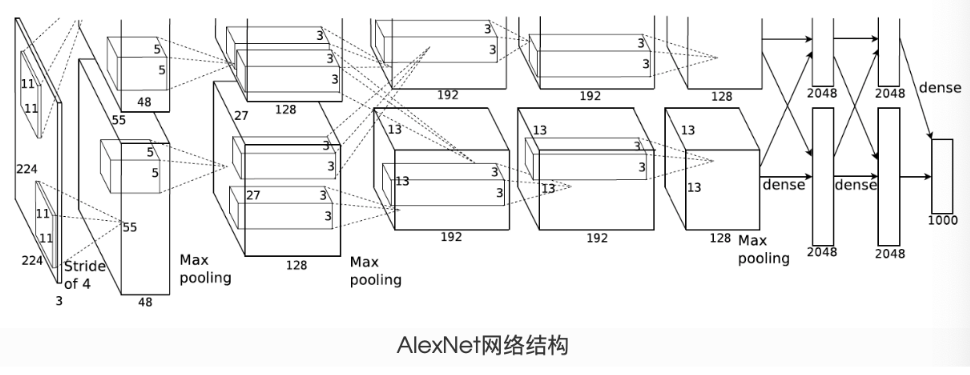
AlexNet
AlexNet 是由 Alex Krizhevsky、Ilya Sutskever 和 Geoffrey Hinton 在 2012 年提出的卷積神經網絡,它在當年的 ImageNet 大規模視覺識別挑戰賽 (ILSVRC) 中以顯著優勢奪冠,標志著深度學習在計算機視覺領域的突破性進展。AlexNet 的成功開啟了深度學習的黃金時代,其架構設計理念深刻影響了后續神經網絡的發展。
AlexNet 由 5 個卷積層和 3 個全連接層組成,總參數超過 6000 萬個。網絡結構分為兩部分:
- 特征提取部分:由卷積層和池化層構成,負責提取圖像特征
- 分類部分:由全連接層構成,負責基于提取的特征進行分類
| 層操作 | 輸入維度 | 操作細節 | 輸出維度 |
|---|---|---|---|
| conv1 | (1, 1, 224, 224) | 11×11 卷積,步長 4,96 通道 | (1, 96, 54, 54) |
| ReLU + 池化 | (1, 96, 54, 54) | 3×3 池化,步長 2 | (1, 96, 26, 26) |
| conv2 | (1, 96, 26, 26) | 5×5 卷積,步長 1,填充 2,256 通道 | (1, 256, 26, 26) |
| ReLU + 池化 | (1, 256, 26, 26) | 3×3 池化,步長 2 | (1, 256, 12, 12) |
| conv3 | (1, 256, 12, 12) | 3×3 卷積,步長 1,填充 1,384 通道 | (1, 384, 12, 12) |
| conv4 | (1, 384, 12, 12) | 3×3 卷積,步長 1,填充 1,384 通道 | (1, 384, 12, 12) |
| conv5 | (1, 384, 12, 12) | 3×3 卷積,步長 1,填充 1,256 通道 | (1, 256, 12, 12) |
| ReLU + 池化 | (1, 256, 12, 12) | 3×3 池化,步長 2 | (1, 256, 5, 5) |
| 展平 | (1, 256, 5, 5) | 多維轉一維 | (1, 6400) |
| fc1 | (1, 6400) | 全連接到 4096 維 | (1, 4096) |
| fc2 | (1, 4096) | 全連接到 4096 維 | (1, 4096) |
| fc3 | (1, 4096) | 全連接到 10 維 | (1, 10) |
| 特性 | LeNet | AlexNet |
|---|---|---|
| 網絡深度 | 5 層(2 卷積 + 3 全連接) | 8 層(5 卷積 + 3 全連接) |
| 激活函數 | Sigmoid/Tanh | ReLU |
| 正則化 | 無 | Dropout(丟棄率 0.5) |
| 卷積核大小 | 5×5 | 11×11、5×5、3×3 |
| 通道數 | 6→16 | 96→256→384→384→256 |
| 全連接層維度 | 120→84→10 | 4096→4096→10 |
| 數據增強 | 無 | 有(隨機裁剪、水平翻轉等) |
| 計算平臺 | CPU | GPU |
?
參考文章
datawhalechina/thorough-pytorch: PyTorch入門教程,在線閱讀地址:https://datawhalechina.github.io/thorough-pytorch/![]() https://github.com/datawhalechina/thorough-pytorch
https://github.com/datawhalechina/thorough-pytorch









 BUG)

:WebAssembly 嘗鮮)




)


