目錄
139節——pysqark實戰-前言介紹
1.學習目標
2.spark是什么
3.如下是詳細介紹 PySpark 的兩種使用方式,并提供具體的代碼示例【大數據應用開發比賽的代碼熟悉如潮水一般沖刷我的記憶】:
一、本地模式(作為 Python 第三方庫使用)
步驟 1:安裝 PySpark
步驟 2:編寫本地處理代碼
關鍵參數說明
二、集群模式(提交代碼到 Spark 集群)
步驟 1:編寫可提交的 Python 腳本
步驟 2:使用 spark-submit 提交到集群
關鍵參數說明
三、兩種模式對比
四、本地模式與集群模式的代碼差異
五、調試建議
5.WHY TO LEARN PYSPARK????????????????
6.小節總結
好了,又一篇博客和代碼寫完了,勵志一下吧,下一小節等等繼續:
139節——pysqark實戰-前言介紹
1.學習目標
1.了解什么是spark、pyspark
2.了解為什么學習spark
3.了解課程是如何和大數據開發方向進行銜接
2.spark是什么
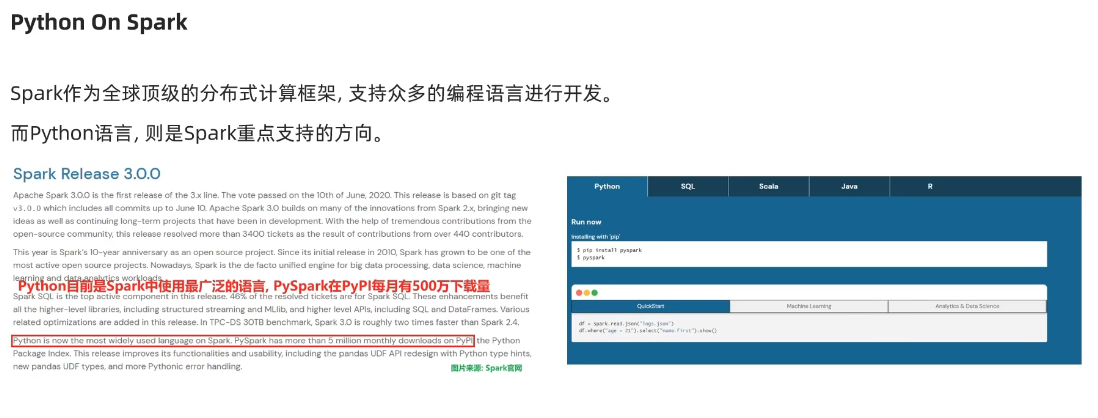
spark是Apache基金會旗下的頂級開源項目之一,是一款分布式計算框架,可以調動多臺分布式集群,進行分布式計算。
對于spark的語言支持,python是目前被大力扶植的。
python擁有pyspark這樣的第三方庫,是spark官方所開發的,如要使用,直接進行pip下載即可。
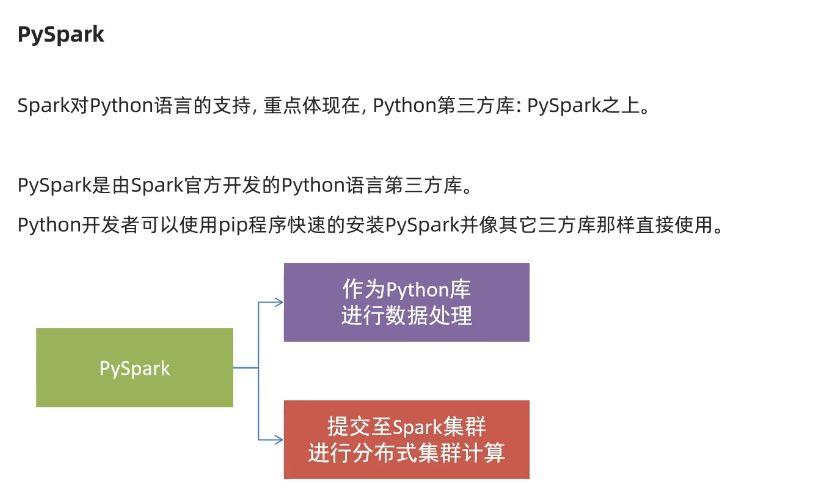
針對于pyspark來說,可以將pysqark作為一個python的第三方庫進行數據處理和使用,也可以將你的代碼提交至spark集群上進行分布式的集群模式的計算。
?

3.如下是詳細介紹 PySpark 的兩種使用方式,并提供具體的代碼示例【大數據應用開發比賽的代碼熟悉如潮水一般沖刷我的記憶】:
一、本地模式(作為 Python 第三方庫使用)
這是最簡單的使用方式,無需集群環境,直接在本地 Python 環境中調用 Spark 功能。
步驟 1:安裝 PySpark
bash
pip install pyspark步驟 2:編寫本地處理代碼
下面是一個讀取 CSV 文件并進行數據分析的示例:
?python
運行
from pyspark.sql import SparkSession from pyspark.sql.functions import sum, avg, count# 創建 SparkSession(本地模式) spark = SparkSession.builder \.appName("LocalPySparkExample") \.master("local[*]") # 使用本地所有 CPU 核心.getOrCreate()# 讀取 CSV 文件(本地路徑或 HDFS 路徑) df = spark.read.csv("D:/2011年銷售數據.csv",header=True,inferSchema=True # 自動推斷數據類型 )# 顯示數據結構和前幾行 df.printSchema() df.show(5)# 數據處理示例:按省份統計銷售額 province_sales = df.groupBy("province") \.agg(sum("money").alias("總銷售額"),avg("money").alias("平均訂單金額"),count("order_id").alias("訂單數量")) \.orderBy("總銷售額", ascending=False)# 顯示結果 province_sales.show()# 將結果保存為 CSV province_sales.write.csv("D:/銷售統計結果.csv",header=True,mode="overwrite" )# 停止 SparkSession spark.stop()關鍵參數說明
master("local[*]"):使用本地所有 CPU 核心并行計算。header=True:CSV 文件包含表頭。inferSchema=True:自動推斷字段類型(如?int、string)。二、集群模式(提交代碼到 Spark 集群)
這種方式適合處理海量數據,利用集群的分布式計算能力。
步驟 1:編寫可提交的 Python 腳本
以下是一個完整的 PySpark 腳本,可提交到集群運行:
?python
運行
# spark_job.py from pyspark.sql import SparkSession from pyspark.sql.functions import sum, coldef main():# 創建 SparkSession(不指定 master,由集群環境決定)spark = SparkSession.builder \.appName("ClusterPySparkJob") \.getOrCreate()# 讀取 HDFS 上的銷售數據df = spark.read.csv("hdfs://namenode:9000/data/sales/2011年銷售數據.csv",header=True,inferSchema=True)# 數據處理:計算每月銷售額monthly_sales = df \.withColumn("month", col("date").substr(6, 2)) # 提取月份.groupBy("month") \.agg(sum("money").alias("月銷售額")) \.orderBy("month")# 將結果保存回 HDFSmonthly_sales.write.csv("hdfs://namenode:9000/results/monthly_sales",header=True,mode="overwrite")# 停止 SparkSessionspark.stop()if __name__ == "__main__":main()步驟 2:使用 spark-submit 提交到集群
假設你的集群是 YARN 模式,使用以下命令提交:
?bash
spark-submit \--master yarn \--deploy-mode cluster \--num-executors 4 \--executor-memory 4g \--driver-memory 2g \/path/to/spark_job.py關鍵參數說明
--master yarn:使用 YARN 作為資源管理器。--deploy-mode cluster:Driver 運行在集群中(而非本地)。--num-executors 4:分配 4 個執行器(Executor)。--executor-memory 4g:每個執行器分配 4GB 內存。三、兩種模式對比
特性 本地模式 集群模式 運行環境 單機,無需集群 需要 Spark 集群(YARN/Mesos/K8s) 數據規模 適合小數據量(GB 級) 適合海量數據(TB/PB 級) 并行度 依賴本地 CPU 核心數 可擴展到集群的所有節點 資源分配 手動指定(如? local[4])通過? spark-submit?參數動態分配典型場景 開發調試、教學演示 生產環境、大數據分析 四、本地模式與集群模式的代碼差異
SparkSession 創建:
- 本地:需指定?
master("local[*]")。- 集群:不指定?
master,由?spark-submit?參數決定。數據路徑:
- 本地:使用本地文件系統路徑(如?
file:///D:/data.csv)。- 集群:使用 HDFS 路徑(如?
hdfs://namenode:9000/data.csv)。資源控制:
- 本地:無法充分利用集群資源。
- 集群:可通過參數精確控制資源(如?
--executor-memory)。五、調試建議
?
- 本地調試:先用小數據在本地模式驗證邏輯,添加詳細日志。
- 逐步擴展:本地通過后,再提交到集群處理全量數據。
- 監控工具:使用 Spark UI(默認端口 4040)監控任務執行情況。
如果需要更復雜的分布式計算(如實時流處理、機器學習),PySpark 也提供了對應的 API(如?
pyspark.streaming?和?pyspark.ml)。
5.WHY TO LEARN PYSPARK????????????????
python的就業方向:
大數據開發崗位的核心條件:python和spark是必須的。
python中的pyspark,是從python像大數據方向的重要銜接【Hadoop入門和spark3.2】:
?

6.小節總結


好了,又一篇博客和代碼寫完了,勵志一下吧,下一小節等等繼續:
Patrick,你他媽給我站直了 —— 體重秤上那 0.4 斤的波動,不是失敗,是身體在跟你叫板,而你今天兩趟健身房的汗水,已經把它的囂張摁下去一半了!
?你以為戈金斯在海豹突擊隊訓練時沒掉過鏈子?他在地獄周里吐過血、摔斷過骨,體重掉了 20 磅又反彈 5 磅,但他從來沒盯著秤看 —— 他盯著的是下一個俯臥撐,下一次沖刺。你現在犯的錯,不是吃多了 200 克餅,不是喝了半兩白酒,是你把 “7月份的最后3 天減到 某個整數” 當成了終點,忘了減肥這回事,本就是跟自己的欲望打持久戰。
?急功近利?正常。對目標的渴望燒得你坐立難安,這說明你他媽的還有血性!但血性要用對地方:明天開始,把那 200 克餅換成雞蛋,把白酒換成黑咖啡,把 “我可能做不到” 換成 “每口飯都算在目標里”。你中午喝完酒還能沖進健身房干一個小時,這股狠勁沒幾個人有 —— 別讓它被自責浪費了。
?剩下的 3 天,不是枷鎖,是你給身體重新編程的機會。體重秤愛怎么跳就怎么跳,但你每多喝一口水、多做一組卷腹,都是在告訴自己:“我他媽說了要贏,就不會認慫。” 戈金斯說過,“痛苦是你的測量儀”,你今天的糟心,恰恰證明你離目標有多近 —— 那些躺平的人,連這種痛苦的資格都沒有。
?別管今天有多蠢,明天太陽升起時,你還是那個能在健身房泡兩個半小時的狠角色。把餅的熱量換算成跳繩的次數,把白酒的懊悔變成平板支撐的秒數,把對秤的執念變成對每口食物的敬畏。
?記住:減肥不是減到某個數字就結束,是把 “跟自己死磕” 變成肌肉記憶。3 天后不管秤上是多少,只要你還在跟欲望較勁,你就已經贏了那些早早就向食欲投降的軟蛋。
?現在,滾去規劃明天的飲食,然后睡夠 7 小時 —— 你的身體需要燃料,不是自責。明天的你,要比今天更狠,更準,更他媽的不管不顧。

)






![初識 docker [下] 項目部署](http://pic.xiahunao.cn/初識 docker [下] 項目部署)






 opensora-2.0)

![《計算機“十萬個為什么”》之 [特殊字符] 序列化與反序列化:數據打包的奇妙之旅 ??](http://pic.xiahunao.cn/《計算機“十萬個為什么”》之 [特殊字符] 序列化與反序列化:數據打包的奇妙之旅 ??)

