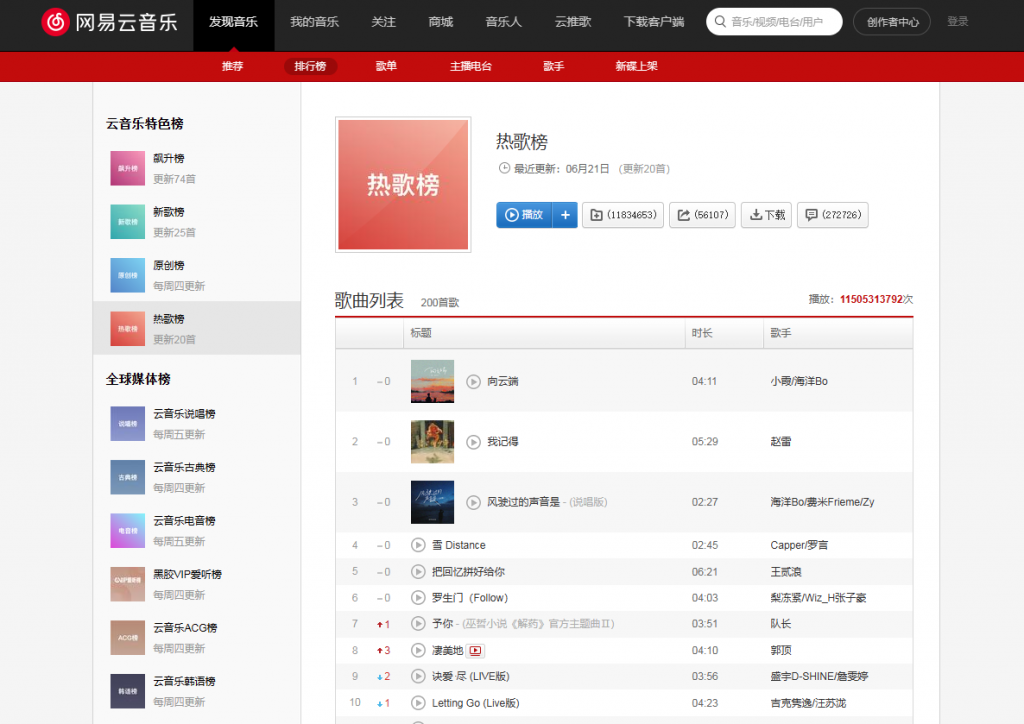
今天我們寫一個網易云音樂的爬蟲,爬取網易云音樂熱歌榜音樂鏈接并下載,這里用到了之前引用的BeautifulSoup和requests。
BeautifulSoup是一個Python庫,用于從HTML和XML文件中提取數據。它提供了一種簡單的方式來遍歷文檔樹和搜索文檔樹中的元素,從而使得從網頁中提取數據變得更加容易。BeautifulSoup還可以處理不完整的標記和編碼問題,并具有廣泛的解析器支持。
requests是一個Python庫,用于向網站發送HTTP請求并獲取響應。它提供了一種簡單的方式來發送HTTP請求,包括GET、POST、PUT、DELETE等常見的請求方法。requests庫還支持HTTP身份驗證、Cookie、代理等功能,并具有簡單易用的API接口。使用requests庫可以輕松地編寫Python程序來訪問Web API、爬取網頁數據等。
我們在工程里直接安裝這兩個模塊:pip install bs4 requests
下面是程序源碼:
import requests #請求模塊 用Python模擬瀏覽器向服務器發起請求
from bs4 import BeautifulSoup #在html提取數據
#1.確定 獲取網址
url = "https://music.163.com/discover/toplist?id=3778678"
#2.發送請求
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36'
}
res = requests.get(url=url,headers=headers)
#3.篩選數據 xpath re json bs4 pyquery
#數據預處理 獲取整體界面
soup = BeautifulSoup(res.text,'html.parser')
#匹配對應的數據,音樂名稱
result = soup.find('ul',class_='f-hide')
infor = result.find_all('a')
idlist = [] #存放ID
namelist = [] #存放名字
number = 0 #歌曲的序號
for i in infor:number = number+1name = i.text #音樂名字# <a href="/song?id=1917957092">愛</a>result = i.get('href')#result結果就是href后邊的數據值#/song?id=1917957092id = result[9:]idlist.append(id)Newurl = 'https://music.163.com/'+resultnamelist.append(name)print(str(number)+' '+name+' '+Newurl)#4.保存數據 ()[]{}
def download():while True:a = input("請輸入你要下載的歌曲的序號:")b = int(a)-1aa = idlist[b]musicName = namelist[b]url = 'http://music.163.com/song/media/outer/url?id={}.mp3'.format(aa)music = requests.get(url=url,headers=headers).contentwith open('{}.mp3'.format(musicName),'wb')as f:f.write(music)print(musicName+'下載完畢!')
download()
我們直接運行測試一下

能看到爬取的200首歌曲名稱和鏈接,下載測試一下。比如選擇200.斷線
稍等片刻后下載完畢。

感興趣的同學運行源碼試一下。






直方圖均衡化,模板匹配,霍夫變換,圖像亮度變換,形態學變換)

)


)






)
