生成式人工智能(Gen AI)的迅猛發展,對大型語言模型(LLM)的部署提出了更高的性能、靈活性和效率要求。
無論部署在何種環境中,紅帽AI推理服務器都為用戶提供經過強化并獲得官方支持的vLLM發行版,配套智能LLM壓縮工具,以及在Hugging Face平臺上優化的模型倉庫。結合紅帽的企業級技術支持與靈活的第三方支持政策,為企業部署生成式AI應用提供強有力的支撐。
借助vLLM內核與先進并行技術,加速AI推理性能
紅帽AI推理服務器的核心是vLLM推理引擎。vLLM因其高吞吐量與內存效率優異而廣受認可,核心技術包括源自加州大學伯克利分校的PagedAttention(用于優化GPU內存管理)以及持續批處理(Continuous Batching),通常能帶來數倍于傳統推理方法的性能提升。該服務器還通常提供一個兼容OpenAI的API端點,便于快速集成。
為應對當前體量龐大、結構復雜的生成式AI模型,vLLM融合了多種先進的推理優化技術,包括:
張量并行(Tensor Parallelism,TP):將單個模型層拆分并并行分布到同一節點內的多個GPU上執行,從而降低延遲并提升計算吞吐能力。
流水線并行(Pipeline Parallelism,PP):將模型的不同層劃分為若干階段,分別部署在不同GPU或節點上,適用于單一多GPU節點也無法容納的超大模型。
專家并行(Expert Parallelism,EP):針對混合專家(Mixture of Experts,MoE)模型進行專門優化,能夠高效處理其獨特的路由邏輯和計算資源分配。
數據并行(Data Parallelism,DP):支持將不同的推理請求分發至多個vLLM實例。在進入MoE層時,各數據并行引擎協同工作,將專家模塊在所有數據并行與張量并行的工作器之間進行切分。此機制特別適用于如DeepSeek V3或Qwen3這類KV注意力頭較少的模型,可避免張量并行造成的KV緩存冗余,提升資源利用率與擴展能力。
量化(Quantization):AI推理服務器內置的LLM Compressor提供統一的模型壓縮庫,支持權重+激活量化或僅權重量化,從而加速vLLM推理流程。vLLM同時提供自定義內核(如Marlin和Machete)以進一步提升量化模型的運行效率。
推測解碼(Speculative Decoding):通過引入一個小型草稿模型預測多個未來token,主模型僅對其進行驗證或修正,從而顯著降低整體解碼延遲,提高推理吞吐量,同時保持生成質量不受影響。
值得一提的是,上述優化技術通常可靈活組合使用,例如節點間應用流水線并行、節點內應用張量并行,以適應復雜的硬件拓撲結構,在大規模推理場景中高效擴展LLM的計算能力。
通過容器化實現部署可移植性
紅帽AI推理服務器以標準容器鏡像形式交付,具備出色的部署靈活性。這種容器化交付方式是實現混合云環境下可移植性的核心,確保無論部署在紅帽OpenShift、紅帽企業Linux(RHEL)、非紅帽Kubernetes平臺,還是其他標準Linux系統上,均可提供一致的推理運行環境。它為在任意業務場景中部署大型語言模型(LLM)奠定了標準化、可預測的基礎,有效簡化了跨異構基礎設施的運維工作。
多加速器支持
紅帽AI推理服務器自設計之初便將多加速器支持作為核心能力,能夠無縫兼容多種硬件加速器,包括NVIDIA GPU、AMD GPU和Google TPU。通過構建統一的推理服務層,平臺有效屏蔽底層硬件差異,帶來極大的靈活性和優化空間。
這一能力讓用戶能夠:
優化性能與成本:根據模型特性、延遲要求和成本預算,在最適合的加速器上運行推理任務,實現更高性能和資源利用效率。
保障未來適應性:支持新一代加速器的無縫集成,無需修改基礎架構或應用代碼,確保平臺具備持續演進能力。
靈活擴展推理能力:可按需添加同類或異構加速器,輕松應對業務增長和模型復雜度提升。
降低廠商依賴:兼容多家加速器供應商,避免對單一硬件平臺的綁定,增強采購靈活性與成本控制能力。
簡化運維管理:在不同硬件上提供一致的管理接口,顯著降低推理服務在異構環境中的運維負擔。
憑借這一面向未來的架構設計,紅帽AI推理服務器不僅滿足當前生成式AI的高性能推理需求,也為企業構建可持續、可拓展的AI基礎設施奠定堅實基礎。
由紅帽內部Neural Magic專業技術驅動的模型優化
高效部署大型語言模型(LLM)通常需要模型優化。AI推理服務器集成了強大的LLM壓縮能力,利用已加入紅帽的Neural Magic的前沿優化技術。通過SparseGPT等業界領先的量化與稀疏化方法,壓縮器可在準確率幾乎無損的前提下大幅減小模型體積和計算負擔。這提升了推理速度與資源利用效率,顯著降低內存占用,使模型即使在GPU資源受限的系統中也能順暢運行。
通過優化的模型倉庫實現簡化訪問
為進一步簡化部署,AI推理服務器提供對一系列主流LLM(如Llama、Mistral和Granite系列)的優化模型倉庫訪問,托管于Hugging Face的紅帽AI頁面。
這些模型并非普通版本,而是經過集成壓縮技術專門優化,適配vLLM引擎的高性能推理。用戶可直接使用這些高效模型,大幅縮短部署時間,加快AI應用落地。
紅帽AI推理服務器技術概覽
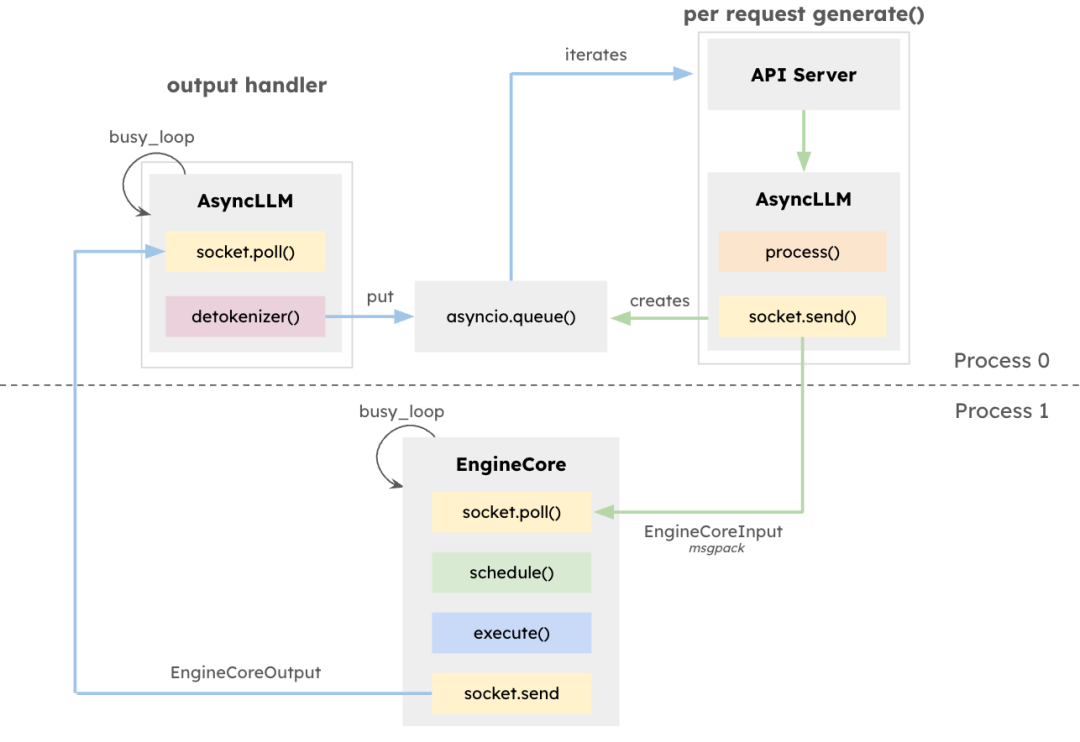
vLLM架構旨在最大化LLM推理的吞吐量并最小化延遲,尤其適用于高并發、請求長度多樣的場景。核心組件EngineCore是專用推理引擎,負責前向計算調度、鍵值(KV)緩存管理以及多請求令牌的動態批處理。
EngineCore不僅降低了長上下文窗口管理的開銷,還能智能預處理或交錯處理短時延請求與長任務。這依賴于隊列調度機制與PagedAttention——一種為每個請求虛擬化KV緩存的新方法。其結果是更高的GPU內存利用率與更少的計算空閑時間。
作為接口適配器,EngineCoreClient負責連接API(如HTTP、gRPC等)并將請求轉發至EngineCore。多個EngineCoreClient可與一個或多個EngineCore通信,支持分布式或多節點部署。vLLM將請求處理與底層推理解耦,便于實施如多EngineCore負載均衡或根據需求擴展客戶端等策略。
該架構不僅便于集成多種服務接口,還支持可擴展的分布式部署。EngineCoreClient可在獨立進程中運行,通過網絡連接EngineCore,從而實現負載均衡并降低CPU負載。
紅帽AI推理服務器結合領先性能與靈活部署能力。其容器化特性賦予真正的混合云靈活性,支持在任意數據與應用所在環境中一致部署先進AI推理,打造企業AI負載的強大基礎。



直方圖均衡化,模板匹配,霍夫變換,圖像亮度變換,形態學變換)

)


)






)



的浮點數精度計數異常問題解決思路)