目錄
一、本次賽事目標:讓大模型理解表格數據(列車信息表)
二、分析賽題、對問題進行建模
賽事背景
賽題解讀
數據分析與探索
賽題要點與難點
解題思考過程
三、Baseline方案
Baseline概況
Baseline運行步驟
Baseline文件概況
Baseline方案思路
Baseline核心邏輯
一、輸入數據處理
二、問題構建與生成方式
三、大模型調用與結果提取
四、標準格式轉換與訓練集構建
五、最后使用星辰MaaS平臺進行微調
四、有哪些方式可以提升方案?
附錄:知識點概述
歡迎回到Datawhale AI夏令營第二期,大模型技術方向的學習~
我們將聚焦在訊飛項目實踐。
作為此次項目實踐的第二個Task,我們將—— 理解項目目標、從業務理解到技術實現!
也許大家很好奇,我們Task1所使用的微調數據集是如何得來的,我們將在本節揭秘!一起來——
-
理解用AI理解列車信息表,究竟有哪些難點和價值、
-
以及,具體要如何判斷AI是否真的理解了列車信息表
-
基于列車信息表,使用大模型構建QA對
一、本次賽事目標:讓大模型理解表格數據(列車信息表)
本次賽事聚焦智慧交通領域中的一個重要場景——列車信息查詢與問答。
在實際應用中,乘客和調度人員經常需要從復雜的列車時刻表中快速獲取精準信息,如檢票口位置、停留時間、跨車次關聯等信息。
傳統的人工查詢方式效率低下,且難以應對復雜的多條件查詢需求。因此本項目將和大家一起探討,如何用AI賦能這項工作。
知識點提要 : 表結構數據處理、微調數據集構造、模型蒸餾
相關知識點清單:
| 學習模塊 | 核心知識點 | 一句話介紹 |
| 大語言模型基礎 | 大模型 API 調用方法 | 學習如何通過 API 使用大語言模型,發送請求并獲取結果。 |
| Prompt 工程 | 掌握如何編寫有效的提示詞,引導模型輸出期望的結果。 | |
| 參數高效微調 | LoRA 和合并精調的區別 | 了解 LoRA(低秩適配)與合并精調在模型微調中的不同原理和使用場景。 |
| 全量微調 | 對整個模型的所有參數進行訓練,以適應特定任務或數據集。 | |
| 數據集構建 | pandas 的基本使用 | 學習使用 pandas 進行數據讀寫、整理和基礎操作。 |
| pandas 的數據篩選 | 掌握 pandas 中按條件篩選和提取數據的方法,如 loc、iloc 和布爾索引等。 |
二、分析賽題、對問題進行建模
在開始建立AI模型之前,我們需要全面理解賽題的背景和要求,
對問題進行清晰的定義,并分析數據的特征,理解解題的要點和難點。
這將有助于我們選擇合適的模型和方法來解決問題。
賽事背景
在智慧交通平臺中,乘客和調度人員需快速從龐雜的列車時刻表中獲取精準信息(如檢票口位置、停留時間、跨車次關聯)。
傳統方法依賴人工查詢和分析,效率低且難以應對復雜問題。
大模型在表格理解方面已經取得了顯著的進展,正在幫助用戶以更直觀、更高效的方式處理和解釋數據。
簡單而言,構建一個讓大模型可以理解表格數據的方案,對于提升系統效率等具有重大意義。
賽題解讀
本次大賽提供了結構化數據表格(列車時刻表)作為數據集,參賽者需基于訊飛星辰MaaS平臺構建一個人工智能模型。
該模型能基于給定表格中的結構化數據,結合表格內容提取信息并回答指定的問題。
賽事任務分為兩個階段:
-
讓模型學習如何解析和表示表格數據。【生成可用于微調的QA對】
-
回答與表格數據對應的自然語言問題。【微調,讓大模型掌握這個表格的知識并進行回答】
該模型應具備自然語言處理(NLP)能力,能夠理解用戶自然語言問題中的意圖(如查詢始發站、終到站、檢票口等),以支持多種問題類型,例如:

模型的輸出應該是包含數值結果、文本描述及必要推理步驟的結構化回答,能夠直接展示提取的指標和相關信息。
平臺限制: 本次賽事規定選手須在訊飛星辰MaaS平臺進行任務開發。需要注意的是,該平臺目前主要支持模型的微調、訓練和部署,不直接提供應用開發或Agent功能嵌入。
這意味著我們主要的解題手段將圍繞 微調(學會列車信息表的)模型 展開,核心在于 構建高質量的(圍繞列車信息表的信息的)微調數據集(QA對)。
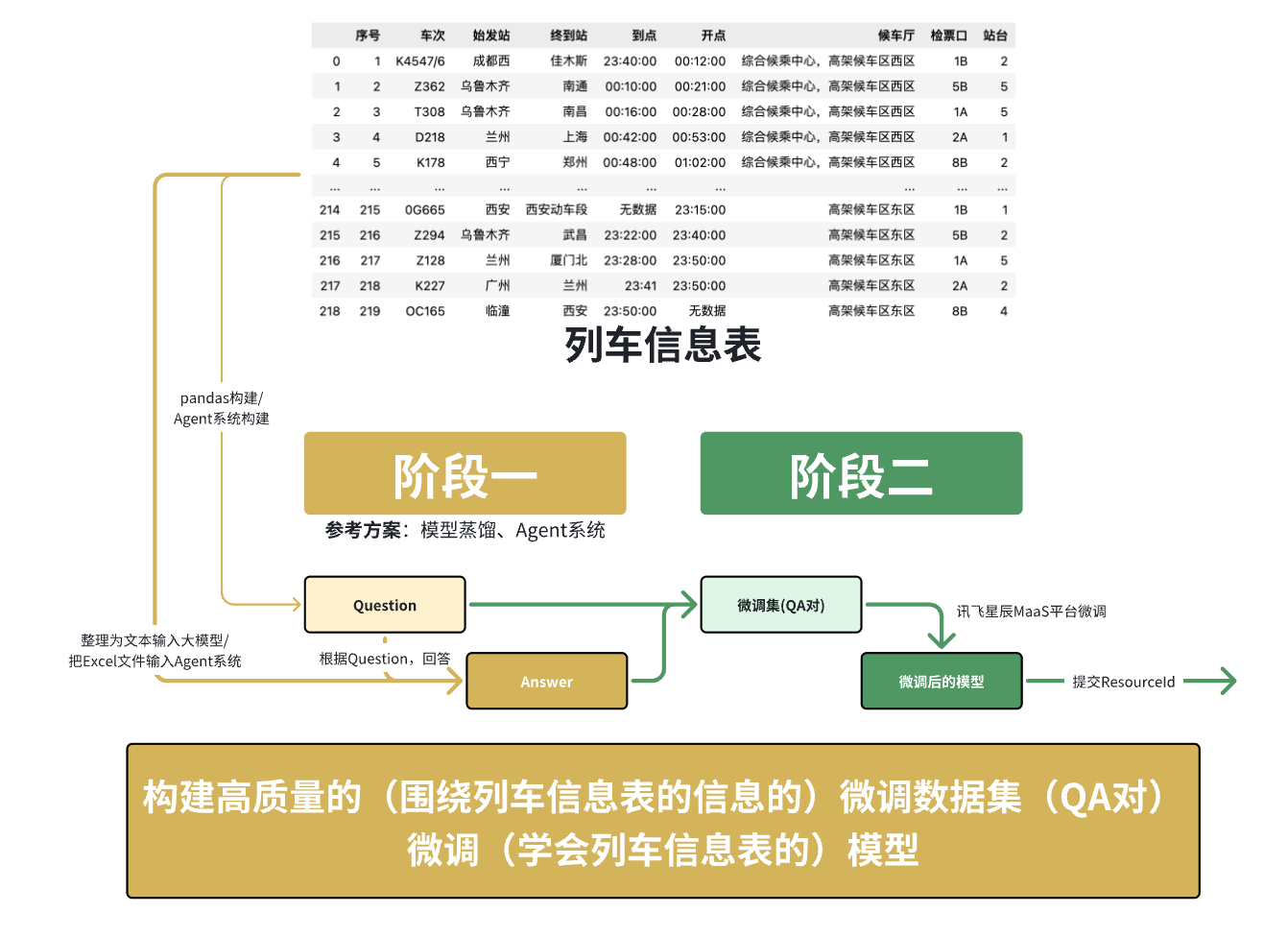
數據分析與探索
然后我們可以通過 經驗/資料查閱肉眼觀測/代碼 等手段,對 賽事提供的數據 有大致的理解和把握
本賽題圍繞 列車時刻表結構化數據 展開,核心任務目標是構造覆蓋關于給定列車時刻表的多類型問題的問答對,供大模型在訊飛星辰MaaS平臺進行微調。
輸入數據:info_table(訓練+驗證集).xlsx(結構化的列車時刻表)

-
格式:.xlsx文件
-
數據量:200+條列車時刻信息
-
字段:包含“序號”、“車次”、“始發站”、“終到站”、“到點”、“開點”、“候車廳”、“檢票口”、“站臺”等信息。
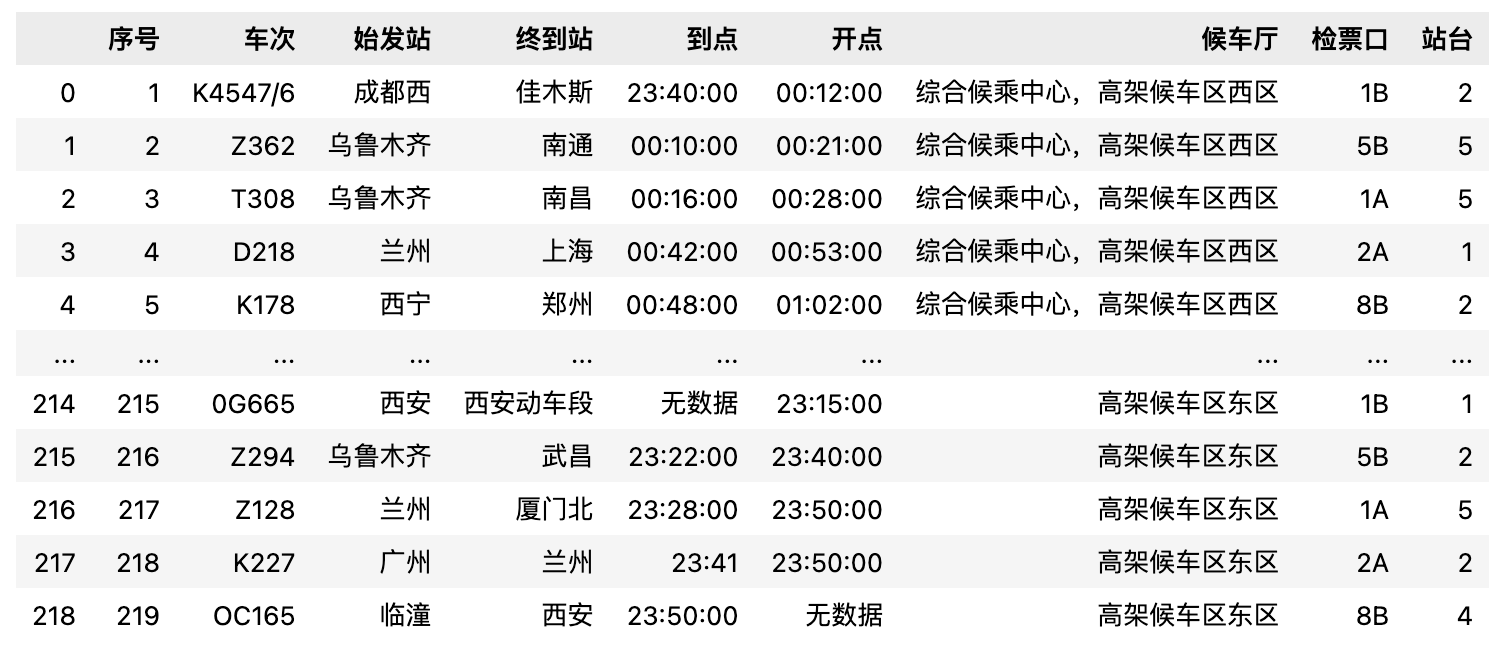
從整體查看數據我們可以了解到,數據當中存在一些信息缺失,我們可以針對性進行人工清洗、補充
SFT數據:基于輸入數據,生成的可在星辰MaaS平臺上微調模型的數據(QA對)
-
格式:Alpaca 或 Sharegpt
-
Alpaca字段舉例:一定要有“instruction”和“output”
-
Alpaca基本格式:
{"instruction": "Z152次列車的終到站是哪里?", "output": "Z152次列車的終到站是北京西。"}數據處理的關鍵點:
-
時間格式統一化處理:原始數據中時間格式可能不統一,需要進行標準化處理,便于后續的時間計算和推理。
-
缺失值處理策略:數據中可能存在“無數據”或空值,需要定義合適的填充或處理策略。
-
字段間關系分析:理解各字段之間的邏輯關系,例如“車次”與“檢票口”、“站臺”的對應關系,以及“到點”、“開點”與“停留時長”的計算關系。
-
數據清洗和標準化:確保數據質量,移除異常值或不一致的數據。
賽題要點與難點
| 核心要點 |
|
| 主要難點 |
|
Baseline:理解數據、訓練數據構造、模型訓練
提升:Agent工具構造、模型蒸餾
解題思考過程
你看到題目會首先思考到什么、做什么、找了什么參考資料,遇到了什么卡點,如何解決?
本賽題要求大家使用給定的 CSV 表格數據來構造大模型可以接受的文本數據,然后在此基礎上進行模型訓練,最終使得模型擁有表格解讀的能力。
在面對這類結構化數據問答賽題時,我們最初的思路是,直接利用大模型來生成問題和答案。
例如,在Prompt里給定一行表格數據,讓大模型直接基于我們給定的輸出模板給出 “問題-答案”的json信息。
這種方法看似高效,但經過實踐和深入討論,我們發現這種 “讓模型既生成問題又生成答案” 的方式存在一個核心問題:無法保證生成的問題和答案的準確性。
如果模型生成的問題本身就是錯誤的,或者答案與表格數據不符,那么用這樣的數據去微調我們的目標模型(學生模型),會導致學生模型學到錯誤的知識,最終影響其在真實測試集上的表現。
因此,我們調整了數據構建的策略,采用了 模型蒸餾(Model Distillation)的思想:
-
編程生成問題(確保問題正確性):我們不再讓大模型憑空生成問題,而是通過編程(例如使用Pandas結合模板)來構造基于表格數據的確定性問題。例如,針對每一行數據,我們可以生成“X車次的終到站是哪里?”、“Y車次應該從哪個檢票口檢票?”等單字段查詢問題。對于更復雜的問題類型,也可以設計相應的編程邏輯來生成。這樣,我們能確保問題的正確性和相關性。
-
使用更強大的大模型(教師模型)生成答案(確保答案質量):對于這些編程生成的問題,我們再將其輸入給一個能力更強、更穩定的教師模型(例如一個大型的通用LLM,如Qwen3-8B),讓教師模型根據給定的表格數據和問題來生成答案。由于教師模型能力更強,它生成答案的準確性會更高。
-
構建高質量SFT數據集:將編程生成的“正確問題”和教師模型生成的“高質量答案”配對,形成
{"instruction": "問題", "output": "答案"}格式的SFT(Supervised Fine-Tuning)數據集。 -
微調目標模型(學生模型):最后,使用這個高質量的SFT數據集來微調我們的目標模型(學生模型)。通過這種方式,我們讓學生模型學習如何從結構化數據中提取信息并生成準確的答案,從而在訊飛星辰MaaS平臺上達到更好的性能。
這種方法的優點在于:
-
保證了問題的正確性:避免了模型生成無效或錯誤的問題。
-
提升了答案的質量:通過強大的教師模型生成答案,確保了訓練數據的準確性。
-
實現了模型蒸餾:將大模型的知識“蒸餾”到我們微調的小模型中,使其在特定任務上表現優異,同時可能具備更快的推理速度,這對于賽題的“回答響應時長”指標至關重要。
-
契合平臺限制:由于平臺只支持微調,這種數據構建方式是克服平臺無Agent功能限制的有效途徑。
但如果僅限于此,分數會有上限和瓶頸,且不適合擴展。
因此更好的方法可能是構造一個表格問答Agent,這個Agent擁有以下7個工具(tool),可用于構造正確的回答。

三、Baseline方案
Baseline概況
| 核心信息 | 信息詳情 |
| 賽題任務類型 | 賽題的任務是微調一個用于領域知識問答的大模型,核心任務是sft數據的制作。 |
| Baseline 代碼 |
|
| Baseline 所需要使用的庫 | pandas、requests、re、json、tqdm |
| Baseline 所需環境和時間 | CPU環境可運行,重點是計算機能通過http調用大模型。 免費注冊即可獲得大模型API額度:硅基流動 |
| Baseline 分數 | 57 |
| Baseline 方案概述 |
|
| Baseline 必備知識點清單 |
|

Baseline運行步驟
-
準備免費的大模型api資源,申請地址:硅基流動
-
安裝必要依賴:
pip install pandas requests tqdm -
數據準備:確保
info_table(訓練+驗證集).xlsx - Sheet1.csv文件位于正確路徑。項目根目錄下創建 data 和 train_data 的文件夾,它們的作用發如下:
-
data:存放賽題的原始數據
-
train_data:存放生成的訓練數據,后續用于上傳到平臺中微調大模型
然后將賽題的數據放入data文件夾中
-
-
環境配置:安裝Python及其所需的庫,如
pandas,requests,tqdm。 -
API Key配置:在
baseline.ipynb中填入你申請的硅基流動(或其他教師模型)的API Token。 -
運行Jupyter Notebook:一鍵運行
baseline.ipynb中的所有單元格。-
第一個單元格讀取并初步處理數據。
-
第二個單元格定義了
call_llm函數(用于調用教師模型)和create_question_list函數(用于編程生成問題),并執行問題和答案的生成過程。 -
第三個單元格將生成的數據轉換為SFT所需的JSON格式,并保存為
single_row.json。
-
-
模型微調:將生成的
single_row.json文件上傳至訊飛星辰MaaS平臺,并根據平臺指引進行LoRA微調訓練。
Baseline文件概況
-
info_table(訓練+驗證集).xlsx - Sheet1.csv:原始的列車時刻表數據。 -
baseline.ipynb:Jupyter Notebook文件,包含數據預處理、編程問題生成、教師模型調用生成答案、SFT數據格式轉換的核心代碼。 -
微調數據集_列車信息.json(或single_row.json): 經過處理和生成后的SFT數據集示例,包含instruction(問題) 和output(答案) 對。
點擊查看代碼詳情
import pandas as pd
import requests
import re
import json
from tqdm import tqdm# 讀取數據
data = pd.read_excel('data/info_table(訓練+驗證集).xlsx')
data = data.fillna('無數據')def call_llm(content: str):"""調用大模型Args:content: 模型對話文本Returns:list: 問答對列表"""# 調用大模型(硅基流動免費模型,推薦學習者自己申請)url = "https://api.siliconflow.cn/v1/chat/completions"payload = {"model": "Qwen/Qwen3-8B","messages": [{"role": "user","content": content # 最終提示詞,"/no_think"是關閉了qwen3的思考}]}headers = {"Authorization": "", # 替換自己的api token"Content-Type": "application/json"}resp = requests.request("POST", url, json=payload, headers=headers).json()# 使用正則提取大模型返回的jsoncontent = resp['choices'][0]['message']['content'].split('</think>')[-1]pattern = re.compile(r'^```json\s*([\s\S]*?)```$', re.IGNORECASE) # 匹配 ```json 開頭和 ``` 結尾之間的內容(忽略大小寫)match = pattern.match(content.strip()) # 去除首尾空白后匹配if match:json_str = match.group(1).strip() # 提取JSON字符串并去除首尾空白data = json.loads(json_str)return dataelse:return contentreturn response['choices'][0]['message']['content']def create_question_list(row: dict):"""根據一行數創建問題列表Args:row: 一行數據的字典形式Returns:list: 問題列表"""question_list = []# ----------- 添加問題列表數據 begin ----------- ## 檢票口question_list.append(f'{row["車次"]}號車次應該從哪個檢票口檢票?')# 站臺question_list.append(f'{row["車次"]}號車次應該從哪個站臺上車?')# 目的地question_list.append(f'{row["車次"]}次列車的終到站是哪里?')# ----------- 添加問題列表數據 end ----------- #return question_list# 簡單問題的prompt
prompt = '''你是列車的乘務員,請你基于給定的列車班次信息回答用戶的問題。
# 列車班次信息
{}# 用戶問題列表
{}'''
output_format = '''# 輸出格式
按json格式輸出,且只需要輸出一個json即可
```json
[{"q": "用戶問題","a": "問題答案"
},
...
]
```'''train_data_list = []
error_data_list = []
# 提取列
cols = data.columns
# 遍歷數據(baseline先10條數據)
i = 1
for idx, row in tqdm(data.iterrows(), desc='遍歷生成答案', total=len(data)):try:# 組裝數據row = dict(row)row['到點'] = str(row['到點'])row['開點'] = str(row['開點'])# 創建問題對question_list = create_question_list(row)# 大模型生成答案llm_result = call_llm(prompt.format(row, question_list) + output_format)# 總結結果train_data_list += llm_resultexcept:error_data_list.append(row)continue# 轉換訓練集
data_list = []
for data in tqdm(train_data_list, total=len(train_data_list)):if isinstance(data, str):continuedata_list.append({'instruction': data['q'], 'output': data['a']})json.dump(data_list, open('train_data/single_row.json', 'w', encoding='utf-8'), ensure_ascii=False)Baseline方案思路
你知道、我們是如何想到和選取這樣的baseline方案的嗎?
本Baseline方案的核心思路是通過模型蒸餾的方法,將一個強大的教師模型(如Qwen3-8B)在特定任務上的知識,遷移到我們最終需要微調的學生模型上。具體步驟如下:
-
表格數據文本化:將結構化的列車時刻表數據(每一行代表一趟列車的信息)轉換為易于大模型理解的文本格式。
-
編程生成問題:針對每一行列車數據,我們手動設計問題模板,并通過編程方式(例如Python腳本)批量生成問題。例如,對于“車次”、“檢票口”、“終到站”等字段,可以生成“
{車次}號車次應該從哪個檢票口檢票?”、“{車次}次列車的終到站是哪里?”等問題。這種方式確保了生成問題的語法正確性和與表格內容的強相關性。 -
教師模型生成答案:將文本化的列車信息和編程生成的問題作為Prompt輸入給一個能力更強的教師模型。教師模型根據其強大的理解和推理能力,為每個問題生成對應的答案。
-
構建SFT數據集:將編程生成的問題和教師模型生成的答案配對,形成
{"instruction": "問題", "output": "答案"}的JSON格式數據集。這個數據集就是用于微調學生模型的SFT數據。 -
學生模型LoRA微調:將構建好的SFT數據集上傳到訊飛星辰MaaS平臺,并使用LoRA技術對選定的基礎模型(學生模型)進行微調。微調后的模型將能夠根據用戶提出的問題,從內部學習到的表格知識中給出準確的回答。
Baseline核心邏輯
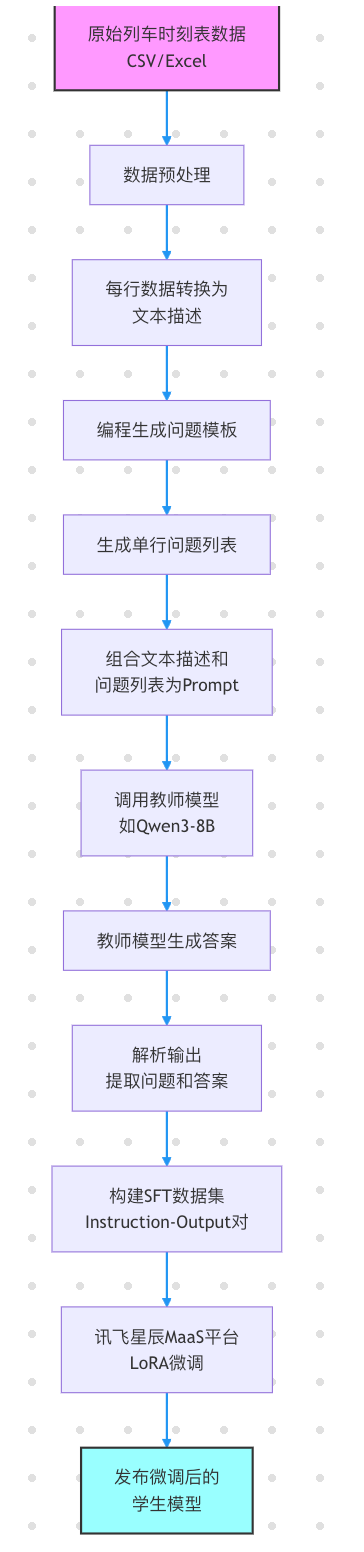
整個流程聚焦于 數據清洗、問題構建、生成與格式轉換 四個步驟,確保模型能準確理解并回答與表格相關的自然語言問題。
核心函數說明:
-
pd.read_excel('data/info_table.xlsx'):使用pandas庫讀取原始的列車時刻表數據。 -
data.fillna('無數據'):對數據中的缺失值進行填充,統一處理。 -
create_question_list(row: dict):-
作用:根據傳入的單行列車數據(字典形式),編程生成一系列針對該行數據的單字段查詢問題。
-
示例:對于車次“K4547/6”,會生成“K4547/6號車次應該從哪個檢票口檢票?”、“K4547/6號車次應該從哪個站臺上車?”、“K4547/6次列車的終到站是哪里?”等問題。
-
-
call_llm(content: str):-
作用:調用外部大模型API(教師模型)來生成答案。
-
輸入:包含列車信息和問題列表的Prompt。
-
輸出:教師模型根據Prompt生成的答案(通常是JSON格式的問答對)。
-
注意:需要替換
Authorization中的token為你的API Key。
-
-
prompt.format(row, question_list) + output_format:構建發送給教師模型的完整Prompt,其中row是當前列車行的文本描述,question_list是編程生成的問題列表,output_format是要求模型輸出的JSON格式。 -
json.dump(data_list, open('single_row.json', 'w', encoding='utf-8'), ensure_ascii=False):將最終生成的SFT數據集保存為JSON文件,以便上傳到微調平臺。
一、輸入數據處理
-
原始數據文件為
info_table(訓練+驗證集).xlsx,格式為結構化表格,每行代表一趟列車信息。 -
包含字段有:車次、始發站、終到站、到點時間、開點時間、候車廳、檢票口、站臺等。
為便于處理,我們進行了如下操作:
-
對缺失字段填充
'無數據'; -
將“到點”“開點”等時間字段統一為字符串格式;
-
刪除如“序號”等無關字段,保留核心字段用于生成問題。
二、問題構建與生成方式
為了構造覆蓋度廣的問題集,我們設計了包含多種類型的 Prompt 模板,指導大模型從用戶視角生成問題及其答案:
常見問題類型包括:
-
單字段查詢 (如:“Z152次列車的終到站是哪里?”)
-
多條件查詢 (如:“在哪候車、幾點發車、幾號檢票口?”)
-
時間推理 (如:“列車在某站停留多久?”)
-
推薦類問題 (如:“凌晨從X地出發去Y地坐哪趟車?”)
輸出格式統一要求為結構化 JSON:
[{"q": "生成的問題","a": "對應的答案"},...
]三、大模型調用與結果提取
我們調用硅基流動中的 Qwen/Qwen3-8B 模型進行自然語言生成,核心過程如下:
-
將單條列車記錄轉換為結構化輸入(dict → JSON)
-
拼接 prompt + 數據,作為輸入發送到模型接口
-
使用正則表達式從返回內容中提取
json格式的問答對數組
四、標準格式轉換與訓練集構建
為了適配訊飛星辰MaaS平臺的模型訓練輸入,我們將生成結果進一步轉換為 instruction 格式的訓練樣本:
{"instruction": "Z152次列車的終到站是哪里?","output": "Z152次列車的終到站是北京西"
}五、最后使用星辰MaaS平臺進行微調
詳見Task1的步驟
四、有哪些方式可以提升方案?
可以嘗試思考以下問題:
-
如何設計編程邏輯,高效且準確地生成涉及多行數據、跨字段計算和時間推理的復雜問答對?
-
在模型蒸餾過程中,除了選擇更強大的教師模型,還有哪些方法可以進一步提升生成答案的質量和多樣性?
-
在有限的計算資源下,如何平衡模型的準確率、回答響應時長和信息傳達效率,以在賽題中取得更高的綜合得分?
階段 1:復雜問答對的生成邏輯 ?
目標:一次生成 N 組「多行-跨字段-時間推理」問答,準確率>95%,可并行。 ?1. 數據層: ?
? ?? 用 Arrow/Feather 把原始表轉列式存儲,按「主鍵+時間戳」雙索引。 ?
? ?? 預計算常用聚合:滑動窗口統計、環比、同比、累計值,落盤為物化視圖。 ?2. 邏輯層(DSL → SQL → QA): ?
? ?? 定義一套輕量級 DSL(YAML 即可),描述“計算單元 + 條件 + 時間錨點”。 ?
? ? ?例: ?
? ? ?```
? ? ?- name: q1
? ? ? ?select: [user_id, order_amt]
? ? ? ?where: "region='華東'"
? ? ? ?window: [-7d, -1d]
? ? ? ?op: sum(order_amt) / sum(order_cnt) - 1
? ? ?``` ?
? ?? 用 Jinja2 模板把 DSL 實時渲染成 SQL;SQL 走 DuckDB/ClickHouse,毫秒級出結果。 ?
? ?? 結果+DSL 喂給 LLM(教師模型)生成自然語言問句和答案,Prompt 模板: ?
? ? ?```
? ? ?你是一名數據分析師。請基于下面 SQL 及結果,生成一個中文問答對。
? ? ?SQL: {{sql}}
? ? ?結果: {{result}}
? ? ?要求:
? ? ?1. 問題必須包含時間推理(如“過去7天”)。
? ? ?2. 答案給出數值和簡短解釋。
? ? ?``` ?
? ?? 用 JSON Schema 驗證輸出,不合法立即重試。 ?3. 并發層: ?
? ?? DSL 文件拆成 block,Ray/ multiprocessing 并行渲染,單機 8 核可跑 2k QA/分鐘。 ?
? ?? 對命中緩存的 DSL 直接復用,減少 60% 計算。 ?──────────────── ?
階段 2:蒸餾階段的“除教師模型外”的增效手段 ?1. 數據端增強 ?
? ?? 問題改寫:用 T5-small 做 paraphrase,同義句 3× 擴充。 ?
? ?? 邏輯反轉:把“最大值”改成“最小值”,把“7 天”改成“30 天”,保持答案也相應翻轉,防止模型死記。 ?2. 訓練端技巧 ?
? ?? R-Distillation:除了常規 KL 散度,再加一個 Ranking Loss,讓學生的 top-1 概率與老師排序一致。 ?
? ?? 分階段凍結:先訓 embedding+最后一層 1 epoch,再全量微調 2-3 epoch,省 40% 時間。 ?3. 推理端后處理 ?
? ?? 多學生投票:3 個不同初始化的小模型投票,取多數答案;對數值題可加權平均。 ?
? ?? 基于規則的 sanity checker:數值超出 3σ 或日期不合法直接觸發二次推理。 ?──────────────── ?
階段 3:有限算力下的“三指標”平衡(準確率 / 響應時長 / 信息效率) ?1. 指標量化 ?
? ?? Score = 0.5·Acc + 0.3·(1/Latency) + 0.2·InfoRatio ?
? ?其中 InfoRatio = 有效信息字節數 / 答案總字節數(用中文分詞器計算)。 ?2. 資源分配策略 ?
? ?? 建立“模型階梯”: ?
? ? ?A. 規則/緩存 → 1 ms,覆蓋率 40% ?
? ? ?B. 1.3B 小模型 LoRA → 50 ms,覆蓋率 85% ?
? ? ?C. 7B 大模型 → 300 ms,兜底 100% ?
? ?? 用輕量級 router(一個 3 層 MLP)按問題復雜度打分,動態路由。 ?3. 運行時優化 ?
? ?? KV-Cache 復用:同一 batch 中相似前綴共享 KV,顯存下降 25%。 ?
? ?? 動態 batching + continuous batching(如 vLLM),可把 RTT 再降 20-30%。 ?
? ?? 量化:INT4 weight + FP16 KV-Cache,顯存減半,精度掉 <1%。 ?4. 信息效率 ?
? ?? 答案模板化:固定“數值+單位+原因”三段式,減少冗余 15-20%。 ?
? ?? 后處理壓縮:用中文標點壓縮 + 指代消解,把“2025 年 7 月 26 日” → “今日”。 ?──────────────── ?
落地方案小結 ?
1. 用 DSL+列式存儲先把「復雜計算」轉成可緩存的 SQL,LLM 只負責自然語言包裝。 ?
2. 蒸餾階段靠數據增強、Ranking Loss、多學生投票,在不換教師模型的情況下提 3-5 pt。 ?
3. 競賽/業務場景下,把模型切成規則-小-大三級,量化+KV-Cache+動態 batching,把 Score 提升 10-15% 的同時顯存占用減半。
附錄:知識點概述
-
LoRA (Low-Rank Adaptation):一種高效的參數微調技術,通過在預訓練模型中注入小的、可訓練的低秩矩陣來適應新任務,從而大大減少了需要訓練的參數量和計算成本,同時保持了模型性能。
-
SFT (Supervised Fine-Tuning):監督式微調,指使用帶有明確“指令”(Instruction)和“輸出”(Output)的標注數據集來訓練模型,使其學習如何遵循指令并生成期望的響應。
-
模型蒸餾 (Model Distillation):一種模型壓縮技術,通過訓練一個小型模型(學生模型)來模仿一個大型模型(教師模型)的行為,從而在保持大部分性能的同時,減小模型體積并提高推理速度。
-
提示工程 (Prompt Engineering):設計和優化輸入給大模型的文本提示(Prompt),以引導模型生成期望的、高質量的輸出。





)
|SVM-拉格朗日函數求解中-KKT條件)






)

)



