爬取B站視頻評論數據爬取與分析
如果只要單純的腳本可以直接看項目結構里的b_comments.py
一、技術架構
1、環境配置
- Python 3.8
- PyCharm
2、模塊配置
- requests:用于發送HTTP請求
- time:用于處理時間相關的操作
- csv:用于讀寫CSV文件
- json:用于處理JSON數據
- hashlib:用于生成哈希值
- urllib.parse:用于URL解析和編碼
quote:URL編碼urlparse:解析URLparse_qs:解析查詢字符串
- selenium:用于自動化Web瀏覽器操作
webdriver:控制瀏覽器驅動By:定位頁面元素的方式WebDriverWait:等待條件滿足expected_conditions(別名EC):定義期望條件Options:配置瀏覽器選項TimeoutException:超時異常NoSuchElementException:找不到元素異常
- scrapy:用于構建爬蟲框架
使用指令下載:pip install 模塊名
-
使用阿里云鏡像
pip install 模塊名 -i https://mirrors.aliyun.com/pypi/simple/ -
使用清華鏡像
pip install 模塊名 -i https://pypi.tuna.tsinghua.edu.cn/simple
3、數據來源
- 指定視頻地址,比如"火柴人 VS 玩家 第零集 - 村莊保衛戰":https://www.bilibili.com/video/BV1uDMXzBELa/?vd_source=2cedb2069146c8936939b253694aab4f
4、抓包分析獲取數據包地址
b站的視頻評論需要抓包獲取
- 打開開發者工具F12按鍵,找到Network(網絡)
- 搜索評論區的一些關鍵字,找到評論區數據所在地址
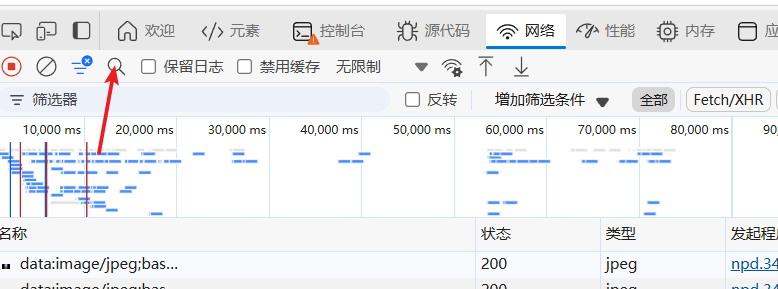
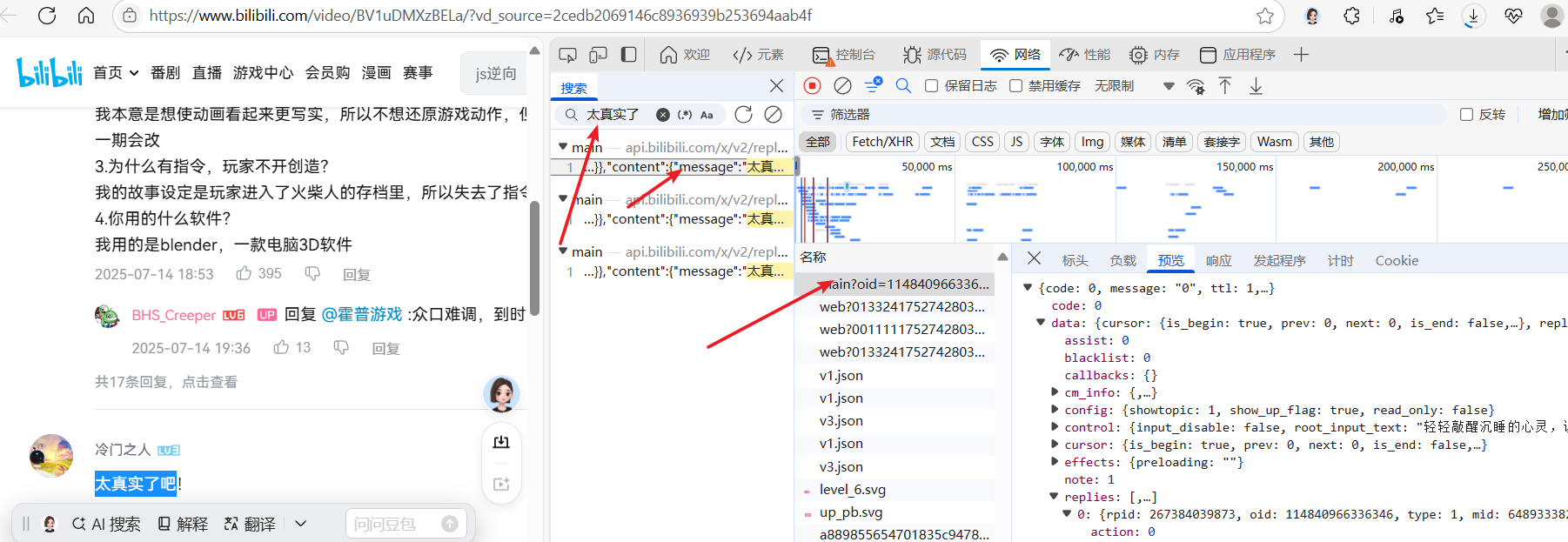
-
找到數據包,復制地址
-
該視頻評論數據包地址:https://api.bilibili.com/x/v2/reply/wbi/main?oid=114840966336346&type=1&mode=3&pagination_str=%7B%22offset%22:%22%22%7D&plat=1&seek_rpid=&web_location=1315875&w_rid=d4269d68b7c818cabfd749dd8da6663d&wts=1752742803
二、實現步驟(發送,獲取,解析,保存)
1. 發送請求
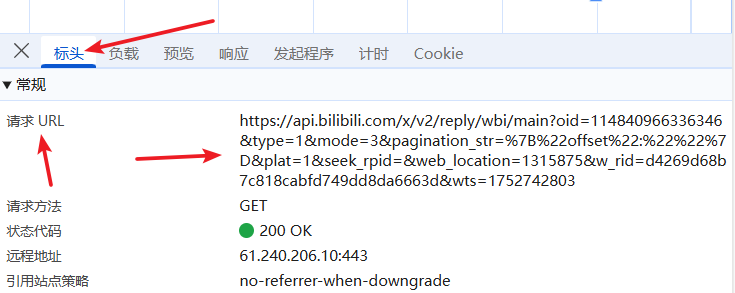
設置請求頭,防止403錯誤(拒絕訪問)
- 在請求標頭里找到 Cookie,User-Agent,Referer,把值復制過來



headers = {"Cookie": "你的b站cookie","User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/138.0.0.0 Safari/537.36 Edg/138.0.0.0","Referer": "https://www.bilibili.com/video/BV1uDMXzBELa/?vd_source=2cedb2069146c8936939b253694aab4f"
}
response = reponse_get(url, headers=headers)
2、獲取數據
請求網址: https://api.bilibili.com/x/v2/reply/wbi/main (不需要完整數據包地址,只需要?號前的鏈接,后面是查詢參數)
參數:

獲取響應json數據
link = 'https://api.bilibili.com/x/v2/reply/wbi/main'
params = {'oid': '114840966336346','type': '1','mode': '3','pagination_str': '{"offset":""}','plat': '1','seek_rpid': '','web_location': '1315875','w_rid': 'd4269d68b7c818cabfd749dd8da6663d','wts': '1752742803'
}
JsonData = requests.get(link, params=params).json()
print(JsonData)
3、解析數據
找到數據位置

- 可以看到數據在replies列表里,所以可以遍歷replies列表,提取列表里的元素,再提取具體的數據
具體數據
for index in JsonData['data']['replies']:dit = {'uid': index['member']['mid'],'昵稱': index['member']['uname'],'性別': index['member']['sex'],'地區': index['reply_control']['location'].replace('IP屬地:',''), # 去除IP屬地字段'簽名': index['member']['sign'],'等級': index['member']['level_info']['current_level'],'評論內容': index['content']['message'],'評論時間': index['ctime']'點贊數': index['like']}
評論時間戳解析
import time
time.strftime('%Y-%m-%d %H:%M:%S',time.localtime(index['ctime']))
4、保存數據
import csv
with open('B站視頻評論數據.csv', 'w', newline='', encoding='utf-8') as f:writer = csv.writer(f)writer.writerow(['uid', '昵稱', '性別', '地區', '簽名', '等級', '評論內容', '評論時間', '點贊數'])for index in data:writer.writerow([index['mid'], index['uname'], index['sex'], index['location'], index['sign'], index['level'], index['content'], time.strftime('%Y-%m-%d %H:%M:%S',time.localtime(index['ctime'])), index['like']])
三、翻頁爬取(數據量大,需要翻頁的視頻)
分析請求鏈接/參數的變化規律
加載新的評論頁參看參數變化
-
不斷往下翻滾頁面,請求的參數會改變
-
查看各頁碼的請求鏈接、參數

-
可以看到鏈接不變,參數有pagination_str、w_rid、wts改變,然后是只有第一頁有seek_rpid參數

找出變化規律
- wts:時間戳,可以用time模塊獲取當前時間戳
- pagination_str:翻頁參數,每次翻頁都會改變
- w_rid:評論id,每次翻頁都會改變
我們可以發現wts和pagination_str的變化比較明顯,wts與當前時間有關,
pagination_str除了第一頁,后面都是一樣的參數
找出w_rid的變化規律
- 按鍵:Ctrl+shift+f搜索w_rid

發現有四個匹配項
- 匹配項1:web.min.js
- 匹配項2:bili-headerumd.js
- 匹配項3:video.871f5df8af85b2dfea40b0804ba2a6f4c883dc90.js
- 匹配項4:core.deb01adc.js
通過斷點觀察,發現w_rid的參數值是在web.min.js文件中的,最后得到固定密鑰和MD5加密

- 密鑰: ea1db124af3c7062474693fa704f4ff8
- 計算過程:

得出w_rid計算方法
def get_w_rid(params, wts):"""動態生成w_rid參數"""keys_order = ['mode', 'oid', 'pagination_str', 'plat', 'seek_rpid', 'type', 'web_location']items = []for key in keys_order:value = params[key]if key == 'pagination_str':value = quote(value)items.append(f"{key}={value}")items.append(f"wts={wts}")s = '&'.join(items) + 'ea1db124af3c7062474693fa704f4ff8'md5 = hashlib.md5()md5.update(s.encode('utf-8'))return md5.hexdigest()
通過上面的方法,我們可以得到w_rid參數,然后就可以進行翻頁爬取了
四、指定視頻爬取
分析不同視頻的參數

-發現參數中有區別的是oid,w_rid,wts
我們在前面就得到了wts和w_rid的計算方法,現在只需要獲取oid即可,而oid就是b站視頻的av/bv號。
而有時候b站視頻的鏈接除了主要鏈接部分,其余部分是參數,所以需要提取出av/bv號
def extract_bvid(url):"""從 B 站視頻鏈接中提取 BV 號或 AV 號支持各種參數、短鏈接、移動端鏈接等"""parsed = urlparse(url)# 嘗試從路徑中提取if parsed.netloc in ["www.bilibili.com", "m.bilibili.com"]:path_parts = parsed.path.strip('/').split('/')for part in path_parts:if part.startswith("BV") or part.startswith("AV"):return part# 嘗試從查詢參數中提取query = parse_qs(parsed.query)if 'BV' in query:return query['BV'][0]elif 'AV' in query or 'av' in query:return query.get('AV', query.get('av', [''])[0])raise ValueError("無法從鏈接中提取有效的 BV 號或 AV 號")
五、功能優化
在運行爬取之后我們發現爬取到的數據只是一級評論,沒有回復一級評論的二級評論,所以我們需要爬取二級評論以獲取完整數據
1.參看二級評論數據所在位置
和查找一級評論數據一樣,直接搜索二級評論

-
請求URL:https://api.bilibili.com/x/v2/reply/reply
-
然后參看二級評論的參數以及參數變化

-
發現只有root和pn有變化,然后是在同一個root下,pn代表頁碼,現在我們要找到root從哪里獲取
-
搜索root

-
發現二級評論的root值就是一級評論的rpid,而一級評論也有root,不過值為0
2.函數編寫
所以我們可以編寫一個函數用來爬取二級評論
def fetch_sub_comments(oid, type, root, ps=10):"""獲取二級評論數據"""sub_comments = []pn = 1while True:params = {'oid': oid,'type': type,'root': root,'ps': ps,'pn': pn,'web_location': '333.788'}try:print(f" 正在獲取二級評論,root: {root}, 頁碼: {pn}")response = requests.get(reply_url, headers=headers, params=params)if response.status_code != 200:print(f" 獲取二級評論失敗,狀態碼: {response.status_code}")breakjson_data = response.json()# 檢查是否有數據if not json_data.get("data") or not json_data["data"].get("replies"):print(f" 第{pn}頁沒有二級評論數據")break# 解析二級評論for reply in json_data['data']['replies']:comment_time = reply.get('ctime')like_count = reply.get('like', 0)comment_content = reply.get('content', {})reply_control = reply.get('reply_control', {})member_info = reply.get('member', {})# 格式化時間format_time = time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(comment_time)) if comment_time else "未知時間"comment = {'uid': member_info.get('mid', ''),'昵稱': member_info.get('uname', ''),'性別': member_info.get('sex', ''),'地區': reply_control.get('location', '').replace('IP屬地:', '').strip(),'簽名': member_info.get('sign', ''),'等級': member_info.get('level_info', {}).get('current_level', ''),'評論內容': comment_content.get('message', ''),'評論時間': format_time,'點贊數': like_count,'評論等級': '二級評論','父評論ID': root}sub_comments.append(comment)# 檢查是否還有下一頁if json_data['data'].get('page'):acount = json_data['data']['page'].get('acount', 0)size = json_data['data']['page'].get('size', ps)count = json_data['data']['page'].get('count', 0)# 如果當前頁是最后一頁,則停止if pn * size >= acount:breakelse:breakpn += 1time.sleep(0.5) # 避免請求過快except Exception as e:print(f" 獲取二級評論時發生錯誤: {e}")breakprint(f" 共獲取到 {len(sub_comments)} 條二級評論")return sub_comments
對一級評論爬取函數修改
def parse_comments(json_data, oid, type_val):"""解析評論數據,安全訪問字段,并獲取二級評論"""comments = []if not json_data.get("data") or not json_data["data"].get("replies"):if json_data.get("data", {}).get("cursor", {}).get("is_end", True):return comments, None # 沒有更多數據raise Exception("未找到評論數據,請檢查參數或 Cookie 是否有效")for index in json_data['data']['replies']:comment_time = index.get('ctime')like_count = index.get('like', 0)comment_content = index.get('content', {})reply_control = index.get('reply_control', {})member_info = index.get('member', {})rpid = index.get('rpid', 0) # 一級評論ID,用于獲取二級評論root_val = index.get('root', 0)# 格式化時間format_time = time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(comment_time)) if comment_time else "未知時間"# 一級評論comment = {'uid': member_info.get('mid', ''),'昵稱': member_info.get('uname', ''),'性別': member_info.get('sex', ''),'地區': reply_control.get('location', '').replace('IP屬地:', '').strip(),'簽名': member_info.get('sign', ''),'等級': member_info.get('level_info', {}).get('current_level', ''),'評論內容': comment_content.get('message', ''),'評論時間': format_time,'點贊數': like_count,'評論等級': '一級評論' if root_val == 0 else '二級評論','父評論ID': root_val if root_val != 0 else ''}comments.append(comment)# 如果有一級評論有回復,獲取其二級評論if index.get('replies'):for sub_reply in index['replies']:sub_comment_time = sub_reply.get('ctime')sub_like_count = sub_reply.get('like', 0)sub_comment_content = sub_reply.get('content', {})sub_reply_control = sub_reply.get('reply_control', {})sub_member_info = sub_reply.get('member', {})sub_root_val = sub_reply.get('root', 0)sub_format_time = time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(sub_comment_time)) if sub_comment_time else "未知時間"sub_comment = {'uid': sub_member_info.get('mid', ''),'昵稱': sub_member_info.get('uname', ''),'性別': sub_member_info.get('sex', ''),'地區': sub_reply_control.get('location', '').replace('IP屬地:', '').strip(),'簽名': sub_member_info.get('sign', ''),'等級': sub_member_info.get('level_info', {}).get('current_level', ''),'評論內容': sub_comment_content.get('message', ''),'評論時間': sub_format_time,'點贊數': sub_like_count,'評論等級': '二級評論','父評論ID': sub_root_val}comments.append(sub_comment)elif index.get('count', 0) > 0: # 如果有更多二級評論需要單獨請求# 獲取完整的二級評論sub_comments = fetch_sub_comments(oid, type_val, rpid)comments.extend(sub_comments)# 獲取下一頁的offsetnext_offset = json_data['data']['cursor']['pagination_reply'].get('next_offset', None)return comments, next_offset
3.cookie自動獲取
對于一個爬蟲腳本,有時候對cookie的獲取可以自動化或者手動輸入
- 這里我們選擇用selenium模擬瀏覽器獲取cookie
自動登錄獲取cookie的函數
def login_bilibili():"""使用Selenium登錄B站獲取Cookie"""print("正在啟動瀏覽器進行B站登錄...")# 設置Chrome選項chrome_options = Options()# 注釋掉下面這行可以查看登錄過程# chrome_options.add_argument('--headless') # 無頭模式chrome_options.add_argument('--no-sandbox')chrome_options.add_argument('--disable-dev-shm-usage')chrome_options.add_argument('--disable-blink-features=AutomationControlled')chrome_options.add_experimental_option("excludeSwitches", ["enable-automation"])chrome_options.add_experimental_option('useAutomationExtension', False)driver = Nonetry:# 啟動瀏覽器driver = webdriver.Chrome(options=chrome_options)driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {"source": "Object.defineProperty(navigator, 'webdriver', {get: () => undefined})"})# 訪問B站登錄頁面driver.get("https://passport.bilibili.com/login")print("請在瀏覽器中完成登錄操作...")print("登錄成功后,程序會自動繼續執行...")# 等待登錄成功(通過檢查是否跳轉到首頁)WebDriverWait(driver, 300).until(EC.url_contains("https://www.bilibili.com/"))# 等待頁面完全加載time.sleep(3)# 獲取Cookiecookies = driver.get_cookies()cookie_str = "; ".join([f"{cookie['name']}={cookie['value']}" for cookie in cookies])print("登錄成功,Cookie獲取完成!")return cookie_strexcept TimeoutException:print("登錄超時,請重試")return Noneexcept Exception as e:print(f"登錄過程中發生錯誤: {e}")return Nonefinally:if driver:driver.quit()
六、項目打包
1. 項目結構說明
項目采用模塊化結構設計,便于維護和擴展(dist目錄是在運行時生成,用于存放打包后的文件,不用手動創建):
B站評論爬蟲/
│
├── src/ # 源代碼目錄
│ ├── b_comments.py # 主爬蟲腳本
│ ├── build.py # 打包腳本
│ └── dist/ # 打包輸出目錄
│ └── B站評論爬蟲.exe # 生成的可執行文件
├── resources/ # 資源文件目錄
│ ├── chromedriver.exe # Chrome瀏覽器驅動
│ └── b_crawler_config.json # 配置文件
└── README.md # 項目說明文檔
2. src/b_comments.py
import requests
import time
import csv
import json
import hashlib
import os
import sys
from urllib.parse import quote, urlparse, parse_qs
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.chrome.options import Options
from selenium.common.exceptions import TimeoutException, NoSuchElementException
from selenium.webdriver.chrome.service import Service as ChromeServiceclass BilibiliCommentCrawler:def __init__(self):self.config_file = 'b_crawler_config.json'self.cookie = Noneself.headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/138.0.0.0 Safari/537.36 Edg/138.0.0.0","Referer": "https://www.bilibili.com"}# 評論接口基礎 URLself.base_url = "https://api.bilibili.com/x/v2/reply/wbi/main"# 二級評論接口 URLself.reply_url = "https://api.bilibili.com/x/v2/reply/reply"# 加載配置self.load_config()def resource_path(self, relative_path):"""獲取資源的絕對路徑。用于PyInstaller打包后定位資源文件。"""base_path = getattr(sys, '_MEIPASS', os.path.dirname(os.path.abspath(__file__)))return os.path.join(base_path, relative_path)def load_config(self):"""加載配置文件"""if os.path.exists(self.config_file):try:with open(self.config_file, 'r', encoding='utf-8') as f:config = json.load(f)self.cookie = config.get('cookie')print("已加載保存的Cookie")except:print("配置文件損壞,將創建新的配置文件")self.cookie = Noneelse:print("未找到配置文件,將創建新的配置文件")def save_config(self):"""保存配置到文件"""config = {'cookie': self.cookie}with open(self.config_file, 'w', encoding='utf-8') as f:json.dump(config, f, ensure_ascii=False, indent=2)print("配置已保存")def login_bilibili(self):"""使用Selenium登錄B站獲取Cookie"""print("正在啟動瀏覽器進行B站登錄...")# 設置Chrome選項chrome_options = Options()# 注釋掉下面這行可以查看登錄過程# chrome_options.add_argument('--headless') # 無頭模式chrome_options.add_argument('--no-sandbox')chrome_options.add_argument('--disable-dev-shm-usage')chrome_options.add_argument('--disable-blink-features=AutomationControlled')chrome_options.add_experimental_option("excludeSwitches", ["enable-automation"])chrome_options.add_experimental_option('useAutomationExtension', False)driver = Nonetry:# 獲取chromedriver路徑chromedriver_path = self.resource_path('chromedriver.exe')print(f"使用chromedriver路徑: {chromedriver_path}")# 啟動瀏覽器service = ChromeService(executable_path=chromedriver_path)driver = webdriver.Chrome(service=service, options=chrome_options)driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {"source": "Object.defineProperty(navigator, 'webdriver', {get: () => undefined})"})# 訪問B站登錄頁面driver.get("https://passport.bilibili.com/login")print("請在瀏覽器中完成登錄操作...")print("登錄成功后,程序會自動繼續執行...")# 等待登錄成功(通過檢查是否跳轉到首頁)WebDriverWait(driver, 300).until(EC.url_contains("https://www.bilibili.com/"))# 等待頁面完全加載time.sleep(3)# 獲取Cookiecookies = driver.get_cookies()cookie_str = "; ".join([f"{cookie['name']}={cookie['value']}" for cookie in cookies])print("登錄成功,Cookie獲取完成!")return cookie_strexcept TimeoutException:print("登錄超時,請重試")return Noneexcept Exception as e:print(f"登錄過程中發生錯誤: {e}")return Nonefinally:if driver:driver.quit()def auto_get_cookie(self):"""使用Selenium自動獲取B站Cookie(非登錄方式)"""print("正在自動獲取B站Cookie...")# 設置Chrome選項chrome_options = Options()chrome_options.add_argument('--headless') # 無頭模式chrome_options.add_argument('--no-sandbox')chrome_options.add_argument('--disable-dev-shm-usage')chrome_options.add_argument('--disable-blink-features=AutomationControlled')chrome_options.add_experimental_option("excludeSwitches", ["enable-automation"])chrome_options.add_experimental_option('useAutomationExtension', False)driver = Nonetry:# 獲取chromedriver路徑chromedriver_path = self.resource_path('chromedriver.exe')print(f"使用chromedriver路徑: {chromedriver_path}")# 啟動瀏覽器service = ChromeService(executable_path=chromedriver_path)driver = webdriver.Chrome(service=service, options=chrome_options)driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {"source": "Object.defineProperty(navigator, 'webdriver', {get: () => undefined})"})driver.get("https://www.bilibili.com")# 等待頁面加載WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.TAG_NAME, "body")))# 獲取Cookiecookies = driver.get_cookies()cookie_str = "; ".join([f"{cookie['name']}={cookie['value']}" for cookie in cookies])print("Cookie獲取成功!")return cookie_strexcept Exception as e:print(f"自動獲取Cookie失敗: {e}")return Nonefinally:if driver:driver.quit()def manual_input_cookie(self):"""手動輸入Cookie"""print("\n請手動輸入Cookie:")print("1. 打開瀏覽器訪問 https://www.bilibili.com")print("2. 按F12打開開發者工具")print("3. 切換到Network標簽頁")print("4. 刷新頁面,在任意請求中找到Request Headers中的Cookie")print("5. 復制完整的Cookie值并粘貼到這里\n")cookie = input("請輸入Cookie: ").strip()return cookiedef get_cookie(self):"""獲取Cookie的主函數"""# 如果已有cookie,詢問是否使用現有cookieif self.cookie:print("\n檢測到已保存的Cookie")choice = input("是否使用現有Cookie? (y/n): ").strip().lower()if choice == 'y' or choice == '':# 驗證現有cookieif self.validate_cookie(self.cookie):return self.cookieelse:print("現有Cookie已失效,請重新獲取")while True:print("\n請選擇獲取Cookie的方式:")print("1. 自動獲取Cookie (無需登錄,可能只能獲取部分評論)")print("2. 手動輸入Cookie")print("3. 登錄獲取Cookie (推薦,可獲取完整評論)")print("4. 退出程序")choice = input("請輸入選擇 (1/2/3/4): ").strip()cookie = Noneif choice == "1":cookie = self.auto_get_cookie()elif choice == "2":cookie = self.manual_input_cookie()elif choice == "3":cookie = self.login_bilibili()elif choice == "4":print("程序已退出")exit()else:print("無效選擇,請重新輸入")continueif cookie:# 驗證Cookie是否有效if self.validate_cookie(cookie):# 保存新cookieself.cookie = cookieself.save_config()return cookieelse:print("Cookie無效,請重新獲取")else:print("獲取Cookie失敗,請重新嘗試")def validate_cookie(self, cookie):"""驗證Cookie是否有效"""try:headers = {"Cookie": cookie,"User-Agent": self.headers["User-Agent"],"Referer": self.headers["Referer"]}# 嘗試訪問一個簡單的API來驗證Cookietest_url = "https://api.bilibili.com/x/web-interface/nav"response = requests.get(test_url, headers=headers, timeout=5)if response.status_code == 200:data = response.json()if data.get("code") == 0:print("Cookie驗證成功!")return Trueprint("Cookie驗證失敗!")return Falseexcept Exception as e:print(f"Cookie驗證出錯: {e}")return Falsedef get_w_rid(self, params, wts):"""動態生成w_rid參數"""keys_order = ['mode', 'oid', 'pagination_str', 'plat', 'seek_rpid', 'type', 'web_location']items = []for key in keys_order:value = params[key]if key == 'pagination_str':value = quote(value)items.append(f"{key}={value}")items.append(f"wts={wts}")s = '&'.join(items) + 'ea1db124af3c7062474693fa704f4ff8'md5 = hashlib.md5()md5.update(s.encode('utf-8'))return md5.hexdigest()def fetch_comments(self, url, headers, params):"""發送請求,獲取評論數據"""response = requests.get(url, headers=headers, params=params)if response.status_code != 200:raise Exception(f"請求失敗,狀態碼: {response.status_code}")return response.json()def fetch_sub_comments(self, oid, type_val, root, ps=20):"""獲取二級評論數據,支持分頁獲取所有二級評論"""sub_comments = []pn = 1while True:params = {'oid': oid,'type': type_val,'root': root,'ps': ps,'pn': pn,'web_location': '333.788'}try:print(f" 正在獲取二級評論,一級評論ID: {root}, 頁碼: {pn}")response = requests.get(self.reply_url, headers=self.headers, params=params)if response.status_code != 200:print(f" 獲取二級評論失敗,狀態碼: {response.status_code}")breakjson_data = response.json()# 檢查是否有數據if not json_data.get("data") or not json_data["data"].get("replies"):print(f" 第{pn}頁沒有二級評論數據")break# 解析二級評論for reply in json_data['data']['replies']:comment_time = reply.get('ctime')like_count = reply.get('like', 0)comment_content = reply.get('content', {})reply_control = reply.get('reply_control', {})member_info = reply.get('member', {})# 格式化時間format_time = time.strftime('%Y-%m-%d %H:%M:%S',time.localtime(comment_time)) if comment_time else "未知時間"comment = {'uid': member_info.get('mid', ''),'昵稱': member_info.get('uname', ''),'性別': member_info.get('sex', ''),'地區': reply_control.get('location', '').replace('IP屬地:', '').strip(),'簽名': member_info.get('sign', ''),'等級': member_info.get('level_info', {}).get('current_level', ''),'評論內容': comment_content.get('message', ''),'評論時間': format_time,'點贊數': like_count,'評論等級': '二級評論','父評論ID': root}sub_comments.append(comment)# 檢查是否還有下一頁if json_data['data'].get('page'):# 獲取總評論數和當前頁信息count = json_data['data']['page'].get('count', 0)page_size = json_data['data']['page'].get('size', ps)page_count = (count + page_size - 1) // page_size # 向上取整計算總頁數# 如果當前頁是最后一頁,則停止if pn >= page_count:breakelse:breakpn += 1time.sleep(0.5) # 避免請求過快except Exception as e:print(f" 獲取二級評論時發生錯誤: {e}")breakprint(f" 一級評論 {root} 下共獲取到 {len(sub_comments)} 條二級評論")return sub_commentsdef parse_comments(self, json_data, oid, type_val):"""解析評論數據,安全訪問字段,并獲取二級評論"""comments = []if not json_data.get("data") or not json_data["data"].get("replies"):if json_data.get("data", {}).get("cursor", {}).get("is_end", True):return comments, None # 沒有更多數據raise Exception("未找到評論數據,請檢查參數或 Cookie 是否有效")for index in json_data['data']['replies']:comment_time = index.get('ctime')like_count = index.get('like', 0)comment_content = index.get('content', {})reply_control = index.get('reply_control', {})member_info = index.get('member', {})rpid = index.get('rpid', 0) # 一級評論ID,用于獲取二級評論root_val = index.get('root', 0)reply_count = index.get('count', 0) # 二級評論總數# 格式化時間format_time = time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(comment_time)) if comment_time else "未知時間"# 一級評論comment = {'uid': member_info.get('mid', ''),'昵稱': member_info.get('uname', ''),'性別': member_info.get('sex', ''),'地區': reply_control.get('location', '').replace('IP屬地:', '').strip(),'簽名': member_info.get('sign', ''),'等級': member_info.get('level_info', {}).get('current_level', ''),'評論內容': comment_content.get('message', ''),'評論時間': format_time,'點贊數': like_count,'評論等級': '一級評論','父評論ID': ''}comments.append(comment)print(f"獲取到一級評論: {comment_content.get('message', '')[:30]}...")# 如果該一級評論有二級評論,則獲取所有二級評論if reply_count > 0:print(f"檢測到一級評論 {rpid} 有 {reply_count} 條二級評論,正在獲取...")sub_comments = self.fetch_sub_comments(oid, type_val, rpid, ps=20)comments.extend(sub_comments)else:print(f"一級評論 {rpid} 沒有二級評論")# 獲取下一頁的offsetnext_offset = json_data['data']['cursor']['pagination_reply'].get('next_offset', None)return comments, next_offsetdef save_to_csv(self, comments, filename='B站視頻評論數據.csv', mode='a'):"""保存評論數據到 CSV 文件"""with open(filename, mode=mode, newline='', encoding='utf-8-sig') as f:writer = csv.DictWriter(f, fieldnames=['uid', '昵稱', '性別', '地區', '簽名', '等級', '評論內容', '評論時間', '點贊數', '評論等級', '父評論ID'])if mode == 'w' or (not os.path.exists(filename) and mode == 'a'):writer.writeheader()writer.writerows(comments)print(f"成功保存 {len(comments)} 條評論到文件:{filename}")def extract_bvid(self, url):"""從 B 站視頻鏈接中提取 BV 號或 AV 號支持各種參數、短鏈接、移動端鏈接等"""parsed = urlparse(url)# 從路徑中提取if parsed.netloc in ["www.bilibili.com", "m.bilibili.com"]:path_parts = parsed.path.strip('/').split('/')for part in path_parts:if part.startswith("BV") or part.startswith("av"):return part# 從查詢參數中提取query = parse_qs(parsed.query)if 'bvid' in query:return query['bvid'][0]elif 'BV' in query:return query['BV'][0]elif 'av' in query:return query.get('av', [''])[0]# 處理短鏈接if "b23.tv" in url:try:response = requests.head(url, allow_redirects=True)final_url = response.urlreturn self.extract_bvid(final_url)except:passraise ValueError("無法從鏈接中提取有效的 BV 號或 AV 號")def get_page_limit(self):"""獲取用戶想要爬取的頁數限制"""while True:print("\n請選擇爬取頁數:")print("1. 爬取全部評論")print("2. 指定爬取頁數")print("3. 退出程序")choice = input("請輸入選擇 (1/2/3): ").strip()if choice == "1":return None # 無限制elif choice == "2":try:pages = int(input("請輸入要爬取的最大頁數: ").strip())if pages > 0:return pageselse:print("頁數必須大于0,請重新輸入")except ValueError:print("請輸入有效的數字")elif choice == "3":print("程序已退出")exit()else:print("無效選擇,請重新輸入")def run(self):try:# 獲取Cookieself.headers["Cookie"] = self.get_cookie()# 輸入視頻鏈接video_url = input("請輸入視頻鏈接: ")# 獲取頁數限制max_pages = self.get_page_limit()# 提取 BV 號bvid = self.extract_bvid(video_url)print(f"成功提取視頻 ID: {bvid}")# 構造標準視頻鏈接(可選)standard_url = f"https://www.bilibili.com/video/{bvid}"print(f"標準視頻鏈接: {standard_url}")# 基礎參數配置base_params = {'oid': bvid,'type': '1','mode': '3','plat': '1','seek_rpid': '','web_location': '1315875'}# 初始化分頁參數next_offset = ""page = 1total_comments = 0all_comments = []output_file = 'B站視頻評論數據.csv'# 如果是第一頁,創建新文件(覆蓋舊文件)if page == 1:if os.path.exists(output_file):os.remove(output_file)while True:# 檢查是否達到頁數限制if max_pages and page > max_pages:print(f"已達到指定的最大頁數 {max_pages},停止爬取")break# 構建分頁參數pagination_str = json.dumps({"offset": next_offset}, separators=(',', ':'))params = base_params.copy()params['pagination_str'] = pagination_str# 生成動態參數wts = int(time.time())w_rid = self.get_w_rid(params, wts)params['w_rid'] = w_ridparams['wts'] = wtsprint(f"正在請求第 {page} 頁評論數據...")json_data = self.fetch_comments(self.base_url, self.headers, params)print(f"正在解析第 {page} 頁評論數據...")comments, next_offset = self.parse_comments(json_data, bvid, '1')if not comments:print(f"第 {page} 頁沒有評論數據,停止爬取")break# 收集所有評論all_comments.extend(comments)total_comments += len(comments)print(f"第 {page} 頁爬取成功,獲取 {len(comments)} 條評論")# 保存當前頁數據(追加模式)self.save_to_csv(comments, output_file, mode='a')# 檢查是否還有下一頁if next_offset is None:print("已到達最后一頁,停止爬取")breakpage += 1time.sleep(1)print(f"爬取完成!共獲取 {total_comments} 條評論")except Exception as e:print(f"發生錯誤:{e}")import tracebacktraceback.print_exc()if __name__ == "__main__":crawler = BilibiliCommentCrawler()crawler.run()
3. src/build.py
import PyInstaller.__main__
import os
import json# 獲取當前腳本目錄
script_dir = os.path.dirname(os.path.abspath(__file__))# 資源文件路徑
config_path = os.path.join(script_dir, "..", "resources", "b_crawler_config.json")
chromedriver_path = os.path.join(script_dir, "..", "resources", "chromedriver.exe")# 確保配置文件存在
if not os.path.exists(config_path):with open(config_path, 'w') as f:json.dump({}, f)# 打包命令
PyInstaller.__main__.run(['b_comments.py','--onefile','--console','--name=B站評論爬蟲','--add-data', f'{config_path};resources','--add-data', f'{chromedriver_path};resources','--clean'
])
4.resources/chromedriver.exe
下載Good Chrome驅動查詢
-https://googlechromelabs.github.io/chrome-for-testing/
找到win32版本下載,解壓后把chromedriver.exe復制到當前目錄下
5.README.md
# B站評論爬蟲項目這是一個用于爬取B站視頻評論的工具,支持:
- 自動獲取Cookie- 爬取一級和二級評論- 保存為CSV文件- 打包為可執行程序## 使用說明### 首次運行
1. 雙擊運行 `B站評論爬蟲.exe`2. 程序將引導您獲取B站Cookie3. 輸入視頻鏈接開始爬取### 后續運行
1. 程序會檢測已保存的Cookie2. 可選擇使用現有Cookie或更新Cookie3. 輸入視頻鏈接開始爬取### 打包說明
1. 安裝依賴:`pip install pyinstaller selenium requests`2. 將chromedriver.exe放在resources目錄3. 運行打包腳本:`python build.py`4. 生成的可執行文件在dist目錄## 注意事項
1. 確保安裝了與chromedriver匹配的Chrome瀏覽器2. 首次運行需要登錄獲取Cookie3. 爬取大量數據時可能需要較長時間
6. 運行build.py
進入build.py所在文件夾,在索引欄輸入cmd,進入終端,命令行運行
python build.py
七、總結
1. 項目概述
- 實現了對B站視頻評論數據的自動化爬取與分析
- 支持一級評論和二級評論的完整數據獲取
- 采用模塊化設計,具備良好的可維護性和擴展性
2. 核心技術要點
網絡請求與反爬蟲處理
- 使用
requests庫發送HTTP請求獲取數據 - 通過設置合理的請求頭(Cookie、User-Agent、Referer)繞過基礎反爬蟲機制
- 實現了WBI簽名參數(w_rid)的動態計算,這是B站反爬蟲的關鍵點
數據解析與處理
- 對JSON格式響應數據進行深度解析
- 提取用戶信息、評論內容、時間、點贊數等關鍵字段
- 實現時間戳到可讀時間的轉換
翻頁與深度爬取
- 分析并實現分頁參數的構造邏輯
- 支持無限滾動加載的評論數據獲取
- 特別處理了二級評論的獨立請求機制
自動化與用戶體驗
- 利用
selenium實現Cookie的自動獲取,提升用戶使用體驗 - 設計了完整的項目打包方案,生成獨立的可執行文件
- 提供友好的命令行交互界面
3. 項目亮點
技術難點攻克
- 成功逆向分析B站WBI簽名算法
- 實現了完整的評論層級結構爬取(一級+二級評論)
- 解決了動態參數構造問題
工程化實踐
- 采用模塊化項目結構設計
- 實現了完整的打包和部署方案
- 編寫了詳細的使用說明文檔
4. 應用價值
- 可用于輿情分析、用戶行為研究等場景
- 為社交媒體數據挖掘提供實踐案例
- 展示了完整的網絡爬蟲開發流程和技術棧應用
5. 注意事項
- 需要遵守網站的robots協議和使用條款
- 應控制請求頻率,避免對服務器造成過大壓力
- Cookie等認證信息具有時效性,需要定期更新
該項目完整地展示了從需求分析、技術調研、代碼實現到產品打包的全流程,是一個具有實際應用價值的數據爬取解決方案。
項目運行結果演示
n build.py`
4. 生成的可執行文件在dist目錄
## 注意事項
1. 確保安裝了與chromedriver匹配的Chrome瀏覽器2. 首次運行需要登錄獲取Cookie3. 爬取大量數據時可能需要較長時間
6. 運行build.py
進入build.py所在文件夾,在索引欄輸入cmd,進入終端,命令行運行
python build.py
七、總結
1. 項目概述
- 實現了對B站視頻評論數據的自動化爬取與分析
- 支持一級評論和二級評論的完整數據獲取
- 采用模塊化設計,具備良好的可維護性和擴展性
2. 核心技術要點
網絡請求與反爬蟲處理
- 使用
requests庫發送HTTP請求獲取數據 - 通過設置合理的請求頭(Cookie、User-Agent、Referer)繞過基礎反爬蟲機制
- 實現了WBI簽名參數(w_rid)的動態計算,這是B站反爬蟲的關鍵點
數據解析與處理
- 對JSON格式響應數據進行深度解析
- 提取用戶信息、評論內容、時間、點贊數等關鍵字段
- 實現時間戳到可讀時間的轉換
翻頁與深度爬取
- 分析并實現分頁參數的構造邏輯
- 支持無限滾動加載的評論數據獲取
- 特別處理了二級評論的獨立請求機制
自動化與用戶體驗
- 利用
selenium實現Cookie的自動獲取,提升用戶使用體驗 - 設計了完整的項目打包方案,生成獨立的可執行文件
- 提供友好的命令行交互界面
3. 項目亮點
技術難點攻克
- 成功逆向分析B站WBI簽名算法
- 實現了完整的評論層級結構爬取(一級+二級評論)
- 解決了動態參數構造問題
工程化實踐
- 采用模塊化項目結構設計
- 實現了完整的打包和部署方案
- 編寫了詳細的使用說明文檔
4. 應用價值
- 可用于輿情分析、用戶行為研究等場景
- 為社交媒體數據挖掘提供實踐案例
- 展示了完整的網絡爬蟲開發流程和技術棧應用
5. 注意事項
- 需要遵守網站的robots協議和使用條款
- 應控制請求頻率,避免對服務器造成過大壓力
- Cookie等認證信息具有時效性,需要定期更新
該項目完整地展示了從需求分析、技術調研、代碼實現到產品打包的全流程,是一個具有實際應用價值的數據爬取解決方案。
項目運行結果演示
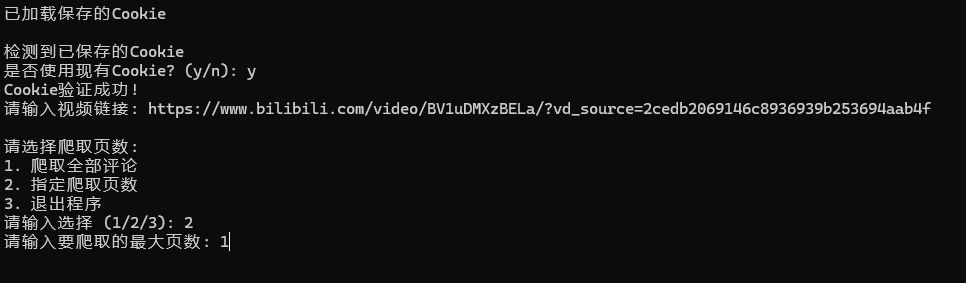




)




)


平臺搭建)



![[RPA] Excel中的字典處理](http://pic.xiahunao.cn/[RPA] Excel中的字典處理)



