摘要:近期,大型語言模型已從流暢的文本生成發展至能在多個領域進行高級推理,由此催生了推理語言模型(RLMs)。在眾多領域中,數學推理堪稱代表性基準,因為它需要精確的多步驟邏輯與抽象推理能力,且這種能力可推廣至其他任務。雖然像GPT-o3這樣的閉源推理語言模型展現出了驚人的推理能力,但其專有屬性限制了透明度和可復現性。盡管許多開源項目旨在彌補這一差距,但其中多數因省略了數據集和詳細訓練配置等關鍵資源而缺乏足夠的開放性,進而阻礙了可復現性。為推動推理語言模型開發實現更高透明度,我們推出了MiroMind-M1系列模型,這是一套基于Qwen-2.5主干構建的完全開源的推理語言模型,其性能可媲美或超越現有的開源推理語言模型。具體而言,我們的模型分兩個階段進行訓練:先在精心整理的、包含71.9萬個數學推理問題及已驗證思維鏈(CoT)軌跡的語料庫上進行監督微調(SFT),隨后在6.2萬個具有挑戰性且可驗證的問題上進行基于驗證的強化學習(RLVR)。為增強RLVR過程的穩健性和效率,我們引入了情境感知多階段策略優化算法,該算法將漸進式長度訓練與自適應重復懲罰相結合,以鼓勵基于情境感知的強化學習訓練。我們的模型在AIME24、AIME25和MATH基準測試中,在基于Qwen-2.5的開源70億(7B)和320億(32B)參數模型中取得了最先進或具有競爭力的性能,且具有更高的標記(token)效率。為便于復現,我們公開了全套資源:模型(MiroMind-M1-SFT-7B、MiroMind-M1-RL-7B、MiroMind-M1-RL-32B);數據集(MiroMind-M1-SFT-719K、MiroMind-M1-RL-62K);以及所有訓練和評估配置。我們希望這些資源能支持進一步的研究并推動社區發展。Huggingface鏈接:Paper page,論文鏈接:2507.14683
研究背景和目的
研究背景:
近年來,大型語言模型(LLMs)在自然語言處理領域取得了顯著進展,尤其是基于Transformer架構的模型,通過大規模預訓練和上下文學習能力,在規劃、推理和問題解決等方面表現出色。然而,盡管這些模型在文本生成上非常流暢,但在復雜推理任務上仍面臨挑戰。推理語言模型(RLMs)作為專門訓練以產生多步思維鏈(CoT)的模型,逐漸成為研究熱點。特別是在數學推理領域,由于其需要精確的多步驟邏輯和抽象推理能力,成為評估RLMs性能的理想基準。
盡管閉源RLMs如GPT-o3和Claude Sonnet 4展示了令人印象深刻的推理能力,但其專有性限制了透明度和可復現性。雖然許多開源項目試圖彌補這一差距,但大多數項目因缺乏關鍵資源(如精心整理的數據集和詳細的訓練配置)而不足以支持完全的可復現性。這種不透明性阻礙了科學創新的進一步發展,尤其是在需要高度透明度和可驗證性的推理任務中。
研究目的:
本研究旨在通過開發一個完全開源的RLMs系列——MiroMind-M1,來提高RLMs開發的透明度,并推動該領域的進一步研究。具體目標包括:
- 構建一個高質量的數學推理數據集,用于監督微調(SFT)和基于驗證的強化學習(RLVR)。
- 提出一種情境感知多階段策略優化(CAMPO)算法,以提高RLVR過程的穩健性和效率。
- 開發一系列基于Qwen-2.5主干的開源RLMs,在數學推理基準測試上達到或超過現有開源模型的性能。
- 公開所有模型、數據集和訓練配置,以支持進一步的研究和社區發展。
研究方法
數據集構建:
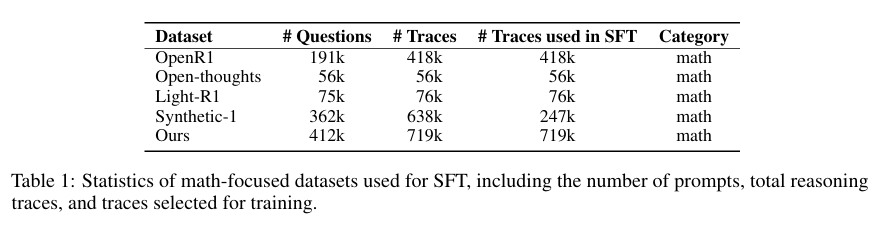
研究從多個公開來源收集數學推理問題,包括OpenR1、OpenThoughts、Light-R1和Synthetic-1等數據集。通過嚴格的去重和去污染處理,確保數據質量,并避免與評估基準的數據泄露。最終構建了包含71.9萬個數學推理問題的SFT數據集(MiroMind-M1-SFT-719K)和6.2萬個具有挑戰性且可驗證問題的RLVR數據集(MiroMind-M1-RL-62K)。
模型訓練:
- 監督微調(SFT): 使用Qwen-2.5-Math-7B作為初始檢查點,在71.9萬個數學推理問題上進行了3個epoch的SFT訓練。采用無填充(no-packing)策略,設置峰值學習率為5.0×10^-5,批量大小為128,最大位置嵌入增加到32,768。
- 基于驗證的強化學習(RLVR): 在6.2萬個具有挑戰性且可驗證的問題上進行了RLVR訓練。采用多階段訓練策略,逐步增加最大響應長度,從初始的16,384逐步增加到32,768和49,152。引入CAMPO算法,通過長度漸進式訓練和自適應重復懲罰,提高訓練的穩健性和效率。
CAMPO算法:
CAMPO算法通過多階段訓練策略,結合長度漸進式訓練和自適應重復懲罰,鼓勵情境感知的強化學習訓練。具體實現包括:
- 多階段訓練: 逐步增加最大響應長度,提高訓練效率。
- 自適應重復懲罰: 通過動態調整重復懲罰系數,減少冗余輸出,提高輸出多樣性。
- 準確的驗證器: 改進數學驗證器,提高獎勵信號的準確性,減少驗證錯誤對訓練的干擾。
研究結果
模型性能:
MiroMind-M1系列模型在AIME24、AIME25和MATH基準測試上取得了顯著性能提升。具體而言:
- MiroMind-M1-RL-32B在AIME24上達到了77.5%的準確率,在AIME25上達到了65.6%,在MATH500上達到了96.4%。
- MiroMind-M1-RL-7B在AIME24上達到了73.4%的準確率,在AIME25上達到了57.8%,在MATH500上達到了96.7%。
效率提升:
通過CAMPO算法,MiroMind-M1系列模型在保持高性能的同時,顯著提高了標記效率。特別是在較短的響應長度下,MiroMind-M1-RL-32B和MiroMind-M1-RL-7B均表現出比基準模型更高的準確率。
開源貢獻:
研究公開了所有模型、數據集和訓練配置,包括MiroMind-M1-SFT-7B、MiroMind-M1-RL-7B和MiroMind-M1-RL-32B模型,MiroMind-M1-SFT-719K和MiroMind-M1-RL-62K數據集,以及詳細的訓練和評估配置。這些資源為進一步的研究和社區發展提供了有力支持。
研究局限
盡管MiroMind-M1系列模型在數學推理任務上取得了顯著進展,但研究仍存在一些局限性:
- 數據集覆蓋有限: 盡管研究構建了大規模的數學推理數據集,但仍可能無法覆蓋所有類型的數學問題。特別是某些高度專業化或復雜的數學領域,可能需要更多的數據進行訓練。
- 模型規模限制: 當前研究主要基于Qwen-2.5系列的7B和32B參數模型。雖然這些模型在數學推理任務上表現出色,但更大規模的模型可能進一步提高性能。然而,更大規模模型的訓練需要更多的計算資源和數據支持。
- 評估穩定性: 在AIME24和AIME25等具有挑戰性的基準測試上,評估結果的穩定性成為一個問題。由于這些基準測試包含的問題數量較少,微小的正確答案數量變化可能導致性能波動較大。
未來研究方向
針對上述研究局限,未來研究可以從以下幾個方面展開:
- 擴展數據集覆蓋: 進一步收集和整理更多類型的數學推理問題,特別是那些高度專業化或復雜的數學領域。同時,考慮引入多語言和多領域的推理問題,提高模型的泛化能力。
- 開發更大規模的模型: 利用更多的計算資源和數據支持,開發基于更大規模預訓練模型的RLMs。通過增加模型參數和復雜度,進一步提高模型在數學推理任務上的性能。
- 提高評估穩定性: 探索更穩定的評估方法和指標,減少因問題數量較少導致的性能波動。例如,可以增加評估問題數量、采用多次運行取平均值等方法,提高評估結果的可靠性和穩定性。
- 探索其他推理任務: 將MiroMind-M1系列模型的研究方法應用于其他類型的推理任務,如科學推理、邏輯推理和代碼生成等。通過擴展模型的應用領域,進一步驗證CAMPO算法的有效性和普適性。
- 優化訓練過程: 進一步研究CAMPO算法的優化策略,如更精細的長度漸進式訓練計劃、更智能的自適應重復懲罰機制等。通過優化訓練過程,提高模型的訓練效率和性能表現。
總之,本研究通過開發完全開源的MiroMind-M1系列模型,提高了RLMs開發的透明度,并在數學推理任務上取得了顯著進展。未來研究可以從擴展數據集覆蓋、開發更大規模的模型、提高評估穩定性、探索其他推理任務和優化訓練過程等方面展開,進一步推動RLMs領域的發展。





)

)




)




)

