一、數據檢索的根本問題與索引產生的必然性
1.1、數據檢索的本質挑戰
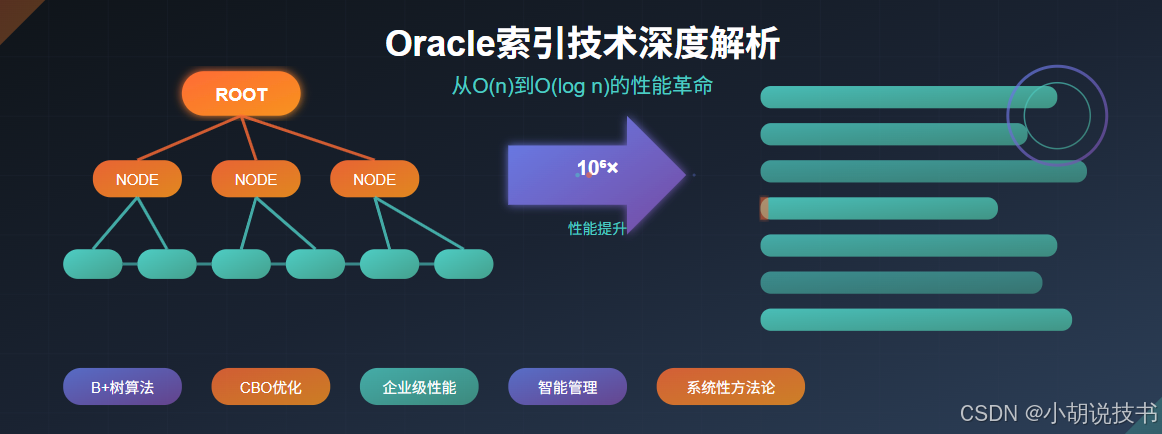
在理解Oracle索引的性能優勢之前,必須回到數據檢索的根本問題。當面對海量數據時,傳統的線性搜索(Sequential Search)面臨著不可調和的性能瓶頸。這種瓶頸源于計算復雜度理論中的時間復雜度問題。
線性搜索的局限性:在包含n條記錄的數據集中,最壞情況下需要檢查每一條記錄,其時間復雜度為O(n)。當數據量增長時,檢索時間呈線性增長,這在企業級應用中是不可接受的。
1.2、索引技術的理論基礎
索引技術的核心思想來源于分治算法和層次化組織理論。通過將數據按照特定規則重新組織,建立一種間接訪問機制,從而將線性時間復雜度降低為對數時間復雜度。
| 數據組織方式 | 時間復雜度 | 適用場景 | 典型性能表現 |
|---|---|---|---|
| 無序線性存儲 | O(n) | 小規模數據 | 檢索100萬條記錄需100萬次比較 |
| 有序線性存儲 | O(log n) | 靜態數據 | 檢索100萬條記錄需20次比較 |
| 樹形索引結構 | O(log n) | 動態數據 | 檢索10億條記錄需27次比較 |
1.3、磁盤I/O與內存訪問的性能鴻溝
現代數據庫系統面臨的另一個根本挑戰是存儲層次結構中各級存儲的性能差異。這種差異直接影響了索引設計的技術決策。
存儲性能層次:
- CPU緩存訪問:1-10納秒
- 內存隨機訪問:50-100納秒
- SSD隨機讀取:0.1-0.2毫秒
- 機械硬盤隨機讀取:5-10毫秒
正是這種巨大的性能差異,使得最小化磁盤I/O次數成為數據庫索引設計的核心目標。
二、B樹索引的技術原理與Oracle的工程實現
2.1、B樹數據結構的數學基礎
Oracle選擇B+樹作為主要索引結構并非偶然,而是經過嚴密的數學分析和工程權衡的結果。B+樹具備以下關鍵數學特性:
平衡性保證:所有葉節點都位于同一層級,確保任何查詢的路徑長度相同
高扇出比:每個節點可以包含多個鍵值,最大化每次磁盤I/O的信息獲取量
順序訪問優化:葉節點通過鏈表連接,支持高效的范圍查詢
2.2、Oracle B+樹的工程優化
Oracle在標準B+樹基礎上進行了多項工程優化,這些優化直接影響了實際性能表現:
| 優化技術 | 技術原理 | 性能收益 | 適用場景 |
|---|---|---|---|
| 節點壓縮 | 前綴壓縮算法 | 減少存儲空間30-50% | 高重復度數據 |
| 塊預讀 | 順序塊批量加載 | 提升范圍查詢性能3-5倍 | 分析型查詢 |
| 延遲分裂 | 推遲節點分裂操作 | 減少維護開銷20-30% | 高并發寫入 |
| 反向鍵索引 | 字節序列反轉 | 消除熱點塊爭用 | 序列號類型字段 |
2.3、成本優化器的決策機制
Oracle的成本優化器(Cost-Based Optimizer, CBO)通過復雜的數學模型來評估索引使用的成本效益。這個決策過程涉及多個關鍵統計信息:
聚簇因子(Clustering Factor):衡量表數據相對于索引的物理組織程度
選擇性(Selectivity):查詢條件篩選出的數據比例
基數(Cardinality):預估的結果集大小
CBO的決策公式可以簡化為:
總成本 = 索引訪問成本 + 表訪問成本 + CPU處理成本
其中,聚簇因子對成本計算的影響最為顯著。當聚簇因子接近表的行數時,意味著索引順序與表的物理存儲順序差異很大,此時索引訪問可能導致大量隨機I/O,CBO會傾向于選擇全表掃描。
三、Oracle索引技術的核心優勢分析
3.1、算法效率的數量級提升
Oracle索引帶來的性能提升并非簡單的倍數關系,而是數量級的躍升。這種提升源于算法復雜度的根本性改變:
| 數據規模 | 無索引掃描次數 | 索引掃描次數 | 性能提升倍數 | 實際業務意義 |
|---|---|---|---|---|
| 1萬條記錄 | 10,000 | 13 | 769倍 | 小型企業級應用 |
| 100萬條記錄 | 1,000,000 | 20 | 50,000倍 | 中型企業級應用 |
| 1億條記錄 | 100,000,000 | 27 | 3,700,000倍 | 大型企業級應用 |
| 100億條記錄 | 100,000,000,000 | 33 | 3,000,000,000倍 | 超大規模系統 |
3.2、企業級功能的技術優勢
Oracle索引系統的技術優勢不僅體現在基礎算法層面,更重要的是在企業級功能的深度集成:
| 技術領域 | Oracle實現 | 核心技術 | 競爭優勢 |
|---|---|---|---|
| 并發控制 | 多版本讀一致性 | MVCC + 行級鎖 | 讀寫操作不互相阻塞 |
| 高可用性 | RAC集群索引 | Cache Fusion技術 | 多實例間索引狀態同步 |
| 智能優化 | 自適應索引管理 | 機器學習算法 | 自動創建和刪除索引 |
| 存儲優化 | 高級壓縮算法 | 自適應壓縮 | 存儲空間減少70% |
3.3、查詢執行計劃的智能化
Oracle的查詢優化器在索引選擇方面體現出高度的智能化特征。這種智能化主要體現在以下幾個維度:
多索引協同:當單個索引無法提供最優性能時,CBO能夠智能地組合多個索引
動態調整:基于實際執行統計,優化器會調整后續相似查詢的執行計劃
自適應游標:Oracle 12c引入的自適應游標技術,能夠在執行過程中動態調整計劃
四、Oracle索引的技術局限與挑戰
4.1、存儲開銷的系統性分析
索引帶來性能提升的同時,也引入了不可忽視的存儲開銷。這種開銷具有非線性增長的特征:
| 索引類型 | 典型存儲開銷 | 影響因素 | 優化策略 |
|---|---|---|---|
| B樹索引 | 表大小的10-20% | 鍵值長度、填充因子 | 壓縮、合理設計復合索引 |
| 位圖索引 | 表大小的5-15% | 數據基數、壓縮比 | 適用于低基數列 |
| 函數索引 | 表大小的15-25% | 函數復雜度、結果長度 | 謹慎使用,定期評估 |
| Oracle Text索引 | 原始文本的50-200% | 文檔類型、分詞策略 | 調整詞匯表、過濾策略 |
4.2、維護成本的深層分析
索引維護成本的復雜性遠超表面認知。每個DML操作(INSERT、UPDATE、DELETE)都會觸發相應的索引維護操作,這種維護具有級聯效應:
寫放大效應:單個INSERT操作可能導致多個索引的更新,在極端情況下,一次表插入可能觸發十幾次索引頁面的修改
| DML操作類型 | 索引維護復雜度 | 性能影響程度 | 典型場景 |
|---|---|---|---|
| INSERT | O(log n) × 索引數量 | 高 | 批量數據導入 |
| DELETE | O(log n) × 索引數量 | 中等 | 數據清理作業 |
| UPDATE索引列 | O(log n) × 2 × 相關索引數 | 極高 | 維度表更新 |
| UPDATE非索引列 | 最小 | 低 | 事實表狀態更新 |
4.3、索引失效的技術根源
索引失效并非簡單的"不使用"問題,而是涉及復雜的查詢重寫和成本計算機制。理解這些失效場景對于索引設計至關重要:
| 失效類型 | 技術原因 | 解決方案 | 預防策略 |
|---|---|---|---|
| 隱式類型轉換 | 數據類型不匹配導致函數包裝 | 修正數據類型 | 嚴格的數據建模 |
| 函數應用 | 列上應用函數破壞索引順序 | 創建函數索引 | 設計時考慮查詢模式 |
| NULL值處理 | B樹索引不存儲全NULL行 | 使用復合索引或位圖索引 | 合理的NULL值策略 |
| 統計信息過時 | CBO基于錯誤信息做決策 | 定期收集統計信息 | 自動化統計收集 |
五、索引技術的方法論與實踐框架
5.1、索引設計的系統方法論
有效的索引設計需要遵循系統性方法論,這個方法論基于業務需求分析、技術架構評估和性能目標量化三個維度:
業務驅動原則:索引設計必須以實際業務查詢模式為驅動
成本效益分析:每個索引都需要進行嚴格的成本效益評估
持續優化循環:索引策略需要基于監控數據持續調整
5.2、索引評估的定量框架
| 評估維度 | 關鍵指標 | 量化標準 | 決策依據 |
|---|---|---|---|
| 查詢性能 | 響應時間改善比例 | >50%提升視為有效 | 業務SLA要求 |
| 存儲成本 | 索引大小/表大小比例 | <30%視為可接受 | 存儲預算約束 |
| 維護開銷 | DML操作延遲增加 | <20%增加視為可接受 | 業務操作要求 |
| 并發影響 | 鎖等待時間變化 | 無顯著增加 | 并發性能要求 |
5.3、索引監控的技術體系
建立完善的索引監控體系是確保索引策略有效性的關鍵。這個體系需要覆蓋實時監控、趨勢分析和預測性維護三個層次:
實時監控:通過V$視圖實時跟蹤索引使用情況和性能指標
歷史分析:基于AWR數據進行長期趨勢分析
智能預警:建立基于閾值的自動預警機制
六、技術工具與實踐指南
6.1、索引分析的專業工具體系
| 工具類別 | 具體工具 | 主要功能 | 適用場景 |
|---|---|---|---|
| 性能監控 | SQL Monitor、AWR | 查詢性能分析 | 日常性能優化 |
| 索引分析 | SQL Access Advisor | 索引推薦 | 新系統索引設計 |
| 統計分析 | DBMS_STATS包 | 統計信息管理 | 優化器調優 |
| 空間分析 | Segment Advisor | 存儲空間分析 | 容量規劃 |
6.2、索引設計的決策樹模型
可以建立如下的索引設計決策樹:
第一層判斷:查詢頻率 > 每日100次?
第二層判斷:查詢選擇性 < 5%?
第三層判斷:維護開銷可接受?
第四層判斷:存儲成本在預算內?
6.3、企業級索引治理框架
| 治理層次 | 責任主體 | 核心職責 | 關鍵輸出 |
|---|---|---|---|
| 戰略層 | 數據架構師 | 索引策略制定 | 索引設計原則 |
| 戰術層 | DBA團隊 | 索引實施管理 | 索引標準規范 |
| 操作層 | 開發團隊 | 日常索引維護 | 性能監控報告 |
七、未來發展趨勢與技術展望
7.1、智能化索引管理的技術趨勢
Oracle在索引技術方面的發展呈現出明顯的智能化趨勢。這種趨勢主要體現在以下幾個方面:
機器學習驅動:基于歷史查詢模式自動推薦索引
自適應調整:根據工作負載變化動態調整索引策略
預測性維護:提前識別索引性能衰減并主動優化
7.2、新興存儲技術對索引的影響
| 存儲技術 | 對索引的影響 | 技術機遇 | 挑戰與應對 |
|---|---|---|---|
| 內存數據庫 | 降低I/O成本重要性 | 更復雜的索引結構 | 內存使用優化 |
| 列式存儲 | 改變數據組織方式 | 列級索引優化 | 查詢模式適配 |
| 分布式存儲 | 索引分片管理 | 并行索引處理 | 一致性保證 |
附錄:專業術語詳解
B+樹(B+ Tree):一種平衡的多路搜索樹,是B樹的變種,所有數據都存儲在葉節點,內部節點只存儲鍵值用于索引
成本優化器(Cost-Based Optimizer, CBO):Oracle數據庫的查詢優化器,通過計算不同執行計劃的成本來選擇最優執行路徑
聚簇因子(Clustering Factor):衡量表數據相對于索引鍵值的物理組織程度的指標,影響索引訪問成本
多版本并發控制(MVCC):通過為每個數據項維護多個版本來實現并發控制的技術,Oracle稱之為多版本讀一致性
扇出比(Fan-out Ratio):B樹節點中子指針的平均數量,決定了樹的高度和查詢效率
時間復雜度(Time Complexity):算法執行時間與輸入規模之間的數學關系,通常用大O記號表示
寫放大(Write Amplification):單次邏輯寫操作觸發多次物理寫操作的現象,在索引維護中較為常見
選擇性(Selectivity):查詢謂詞條件篩選出的行數占總行數的比例,影響優化器的執行計劃選擇
延遲分裂(Deferred Split):B樹節點分裂操作的優化技術,通過推遲分裂時機來減少維護開銷
自適應游標(Adaptive Cursor):Oracle 12c引入的技術,允許在SQL執行過程中動態調整執行計劃
通過這個系統性的知識體系,讀者可以從根本原理到實踐應用全面理解Oracle索引技術的優勢與局限,為實際工作中的索引設計和優化提供科學的理論指導和方法論支撐。















)

)
+ 模板方法模式(Template Method Pattern)的組合使用)
