Transformer架構展現出卓越的擴展特性,其性能隨模型容量增長而持續提升。大規模模型在獲得優異性能的同時,也帶來了顯著的計算和存儲開銷。深入分析主流Transformer架構發現,多層感知器(MLP)模塊占據了模型參數的主要部分,這為模型壓縮提供了重要切入點。
針對這一問題,研究者提出了多樣性引導MLP縮減(Diversity-Guided MLP Reduction, DGMR)方法,該方法能夠在保持性能近乎無損的前提下顯著縮減大型視覺Transformer模型。DGMR采用基于Gram-Schmidt的剪枝策略,系統性地移除MLP層中的冗余神經元,同時通過精心設計的策略確保剩余權重的多樣性,從而在知識蒸餾過程中實現高效的性能恢復。
實驗結果表明,經過剪枝的模型僅需使用LAION-2B數據集的0.06%(無標簽數據)即可恢復至原始精度水平。在多個最先進的視覺Transformer模型上的廣泛實驗驗證了DGMR的有效性,該方法能夠減少超過57%的參數量和浮點運算次數(FLOPs),同時保持性能幾乎無損。值得注意的是,在EVA-CLIP-E(4.4B參數)模型上,DGMR實現了71.5%的參數縮減率,且未出現性能下降。
Transformer架構在計算機視覺和自然語言處理領域展現出強大的能力,其性能與模型規模呈現正相關關系。然而,大規模Transformer模型雖然能夠達到極高的準確率,但其帶來的計算復雜度和內存需求也呈指數級增長,嚴重限制了模型的實際部署和廣泛應用。
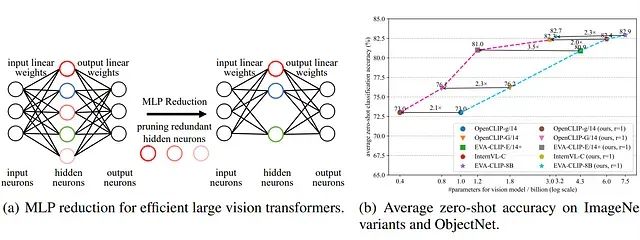
(a)視覺Transformer模型中較大的MLP擴展比導致存在大量冗余參數,為模型壓縮提供了機會。(b)本方法在現有最先進大型Transformer模型的壓縮任務中實現了近似無損的優異性能
為應對這一挑戰,研究界主要探索了模型剪枝和知識蒸餾兩大技術路徑來實現大型視覺Transformer(ViTs)的高效化。傳統剪枝方法通常基于重要性評分機制移除相對不重要的權重或注意力頭,但這類方法往往忽視了權重多樣性的維護需求,而權重多樣性對于模型原始性能的恢復具有關鍵作用。此外,基于梯度的剪枝策略需要進行大量的計算開銷和多輪微調過程,對于大規模模型而言成本尤為高昂。知識蒸餾方法則通過訓練小規模學生模型來學習大規模教師模型的行為模式,但由于學生模型與教師模型在架構上的差異,通常需要從零開始進行訓練,這同樣需要消耗大量的時間和數據資源,特別是在處理大型ViTs時計算成本極其昂貴。
深入分析Transformer架構可以發現,MLP模塊由于采用了較高的擴展比例而包含了大量參數。以EVA-CLIP-E模型為例,MLP模塊占據了全部模型參數的約81.1%。如上圖所示,輸入層通過擴展機制轉換為更大的隱藏層,其擴展比例通常在2.67(DINOv2-g)到8.57(EVA-CLIP-E)之間變化。雖然這種大規模擴展有助于模型的訓練收斂和性能提升,但也不可避免地引入了大量冗余參數。因此,針對MLP模塊隱藏層規模的優化成為提升大型視覺Transformer效率的有效途徑。
研究專注于大型視覺Transformer MLP模塊中冗余神經元的識別與移除。核心思想在于,經過適當的微調過程,大量神經元可以通過少數關鍵"主導"神經元的線性組合進行有效替代。這一過程面臨兩個關鍵技術挑戰:如何科學地選擇這些主導神經元,以及如何在剪枝操作后有效恢復模型的原始性能。
為解決上述挑戰,研究提出了多樣性引導MLP縮減(DGMR)方法。DGMR通過量化神經元與輸入神經元之間的連接強度(基于權重幅度)來識別最重要的神經元。為確保所選神經元的多樣性并避免信息冗余,算法在每次選擇后對剩余權重進行更新。這一迭代過程持續進行直至達到預設的神經元數量目標,確保每個新選擇的神經元都能提供已選神經元未能捕獲的獨特信息。
與傳統方法相比,DGMR的顯著優勢在于無需額外的梯度計算或迭代式剪枝-微調流程,從而大幅提升了算法效率。在剪枝完成后,方法采用知識蒸餾技術協助縮減后的模型恢復原始性能,其中原始模型作為教師模型,剪枝模型作為學生模型進行學習。
主要貢獻包括:提出了一種適用于大型視覺Transformer的高效壓縮方法,避免了昂貴的迭代剪枝開銷;設計了多樣性引導的神經元選擇策略,確保剪枝模型的有效性和可恢復性;通過僅在ImageNet-1K數據集(無標簽)上進行知識蒸餾,在EVA-CLIP-8B等模型上實現了超過57%的參數和FLOPs縮減,在EVA-CLIP-E上達到71.5%的縮減率,且性能損失微乎其微。
研究在多個大規模模型上驗證了方法的有效性,包括EVA-CLIP-E、EVA-CLIP-8B和DINOv2-g,均展現出強大的壓縮能力和近似無損的性能表現。
視覺Transformer模型剪枝技術
為提升視覺Transformer(ViTs)的推理效率并降低內存占用,現有研究主要通過壓縮多頭自注意力模塊或多層感知器(MLP)模塊來實現模型優化。這些方法的核心在于評估模型權重的重要性并移除相對不重要的組件。
基于權重幅度的剪枝方法通過分析權重數值的大小來判斷其重要性,保留具有較大數值的權重。ViT-Slim方法引入了可學習的稀疏性約束機制來發現高效的模型結構,而DIMAP方法則通過分析權重移除對信息傳遞的影響程度來避免誤刪重要權重。
基于注意力機制的剪枝方法利用注意力分數來確定模型組件的重要性。SNP方法移除具有低注意力分數的查詢和鍵層,同時維持模型整體注意力分布的穩定性,以確保最終預測結果不受顯著影響。
基于泰勒展開的剪枝方法采用數學近似技術來估計權重剪枝對損失函數的影響,從而在最小化性能損失的前提下進行權重移除。SAViT方法利用該思想評估模型不同組件的綜合重要性以實現均衡剪枝,VTC-LFC方法采用基于泰勒展開估計的低頻敏感性度量來指導權重選擇,而NViT方法則引入了與泰勒展開相關的Hessian矩陣方法來評估Transformer塊中參數組的重要性。
現有方法主要關注于減少剪枝操作對模型輸出的負面影響。相比之下,本研究方法的創新之處在于強調保持剪枝模型中權重的多樣性,這一特性顯著有助于模型在知識蒸餾過程中的性能恢復。此外,與需要進行耗時的迭代剪枝-微調過程或額外梯度計算的傳統方法不同,本方法在壓縮大型視覺Transformer方面展現出更高的實用性和效率。
視覺Transformer的令牌縮減策略
除參數縮減外,另一種提升視覺Transformer推理速度的有效途徑是減少模型處理的令牌數量。這一目標可通過令牌剪枝和令牌合并兩種主要技術實現。
令牌剪枝技術通過從序列中移除相對不重要的令牌來加速推理過程。A-ViT方法在每個層級僅保留信息量最豐富的令牌,AdaViT方法根據輸入圖像特征自適應選擇使用的補丁、注意力頭或層級。DynamicViT方法采用注意力掩碼技術阻斷特定令牌間的交互,LRP方法通過計算"語義密度"分數評估各補丁的重要程度以指導令牌篩選,Zero-TPrune方法則從預訓練Transformer的注意力圖中構建重要性分布來指導令牌剪枝策略。
令牌合并技術將相似令牌組合以減少處理的令牌總數。ToMe方法采用快速匹配算法合并最相似的令牌,BAT方法將令牌分為高注意力和低注意力兩類,合并相似的低注意力令牌同時保持高注意力令牌的獨特性以維護多樣性。TPS方法識別令牌間的最近鄰關系并進行合并以保留重要信息,STViT方法引入語義令牌來全局或局部總結整個令牌集合,TokenLearner方法識別圖像或視頻中的關鍵區域并集中處理,Vid-TLDR方法檢測視頻中的關鍵區域以合并背景令牌同時增強對主要對象的關注。
本研究方法專注于通過剪枝MLP模塊中的冗余神經元來減少大型視覺Transformer的參數數量。值得注意的是,該方法與現有的令牌縮減技術具有良好的兼容性。通過結合參數縮減和令牌縮減策略,可以進一步提升視覺Transformer的推理速度并降低內存使用量。
DGMR方法論
整體框架
模型壓縮的核心目標是在最小化性能損失的前提下顯著減少模型規模。針對大型視覺Transformer,本研究重點關注MLP模塊的參數縮減,因為這些模塊包含了模型的主要參數量。同時,方法致力于在剪枝過程中保持剩余權重的多樣性,使壓縮后的模型能夠最大程度地保留原始模型的有效信息。
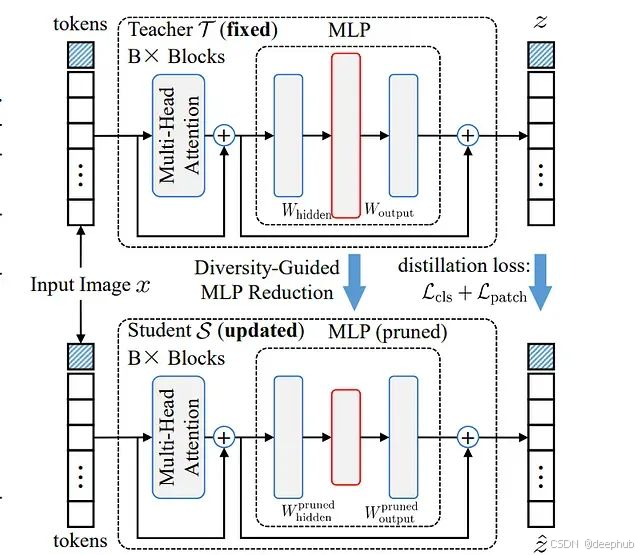
方法整體框架概述。第一階段采用多樣性保持策略對包含Transformer模型主要參數的MLP模塊隱藏神經元進行剪枝。第二階段利用原始Transformer模型作為教師模型指導剪枝模型的訓練以實現性能恢復。
如上圖所示,本方法采用兩階段壓縮策略來實現高效的模型縮減和最小的性能損失。在第一階段,方法對大型MLP模塊的隱藏層進行神經元剪枝,同時精心維護權重連接的多樣性。這一剪枝操作的關鍵優勢在于不改變令牌的特征維度,從而避免對模型其他組件產生影響。
第二階段采用知識蒸餾技術,原始大型模型充當教師角色,剪枝后的小型模型作為學生進行學習。學生模型通過模仿教師模型的行為模式來恢復性能。由于剪枝操作保持了輸出維度的一致性,學生模型能夠直接與教師模型的輸出進行對齊,整個過程無需額外的模塊設計或復雜的架構調整。
多樣性引導的MLP縮減算法
本節詳細闡述參數密集型MLP模塊的縮減方法,旨在壓縮大型視覺Transformer模型。算法的主要目標是減少冗余信息的同時在剪枝后維持權重或神經元的多樣性,從而提升剪枝模型的可恢復性。
根據圖2所示的架構,MLP隱藏層的權重表示為W(hidden)= [w?, w?, …, w?]? ∈ ??×?,其中M表示隱藏神經元數量,N表示輸入神經元數量。每個w? ∈ ??代表連接至第i個隱藏神經元的權重向量。隱藏層包含偏置項b(hidden)∈ ??,MLP輸出層權重表示為W(output)∈ ??×?。
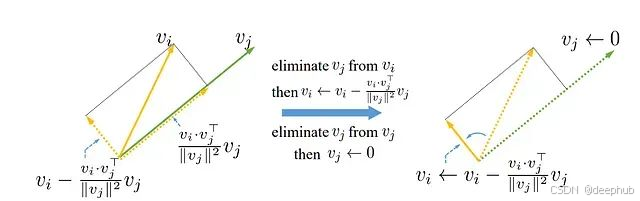
算法從集合{vi}i中移除神經元j對應的vj。通過Gram-Schmidt算法獲得的具有最大?2范數的神經元{vi}i在下一輪迭代中被選擇。因此,下一個選擇的神經元包含了前序神經元未能捕獲的最大信息量。


基于知識蒸餾的性能恢復機制
多樣性引導的MLP縮減技術在不顯著改變模型整體架構的前提下實現對Transformer中大型MLP模塊的有效剪枝。通過精心設計的神經元選擇策略,剪枝后的模型保持了與原始完整模型相似的架構特征和權重分布模式。
基于這種結構和權重的相似性特征(即權重和結構親和性),剪枝后的模型能夠通過以原始模型為教師的學習過程有效恢復其損失的性能。這一被稱為知識蒸餾的過程使得參數量顯著減少的小型模型仍能恢復原始精度的絕大部分。
輸入圖像x同時輸入教師模型T和學生模型S,獲得最終Transformer塊的輸出表示:
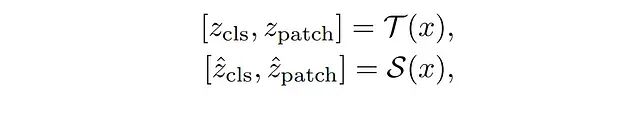
其中,z_cls ∈ ??和z_patch ∈ ??×?分別表示模型生成的特征向量。z_cls是類別令牌的表示,具有維度C;z_patch是所有補丁令牌的表示,組織為長度L的序列,每個元素具有維度C。
剪枝或蒸餾后的新表示?_cls和?_patch與原始表示保持相同的維度結構:?_cls ∈ ??,?_patch ∈ ??×?。這一設計確保了即使在剪枝操作后,特征尺寸與原始模型保持完全一致,從而保證了與網絡其余部分的兼容性。
實驗評估
實驗配置
為協助剪枝模型恢復原始性能,研究在ImageNet-1K數據集上對模型進行知識蒸餾訓練。該數據集不包含標簽信息,僅占用于訓練原始大型模型的LAION-2B數據集的約0.06%。所有用于蒸餾和評估的圖像均被統一調整至224×224像素分辨率。
為全面驗證方法有效性,研究在多個主流基準數據集上進行了測試。對于CLIP風格模型,在零樣本圖像分類任務上評估蒸餾后的視覺模型,采用的數據集包括ImageNet-1K驗證集、ImageNet-V2、ImageNet-Adv、ImageNet-R、ImageNet-Sketch和ObjectNet,嚴格遵循CLIP基準測試協議。此外,在Flickr30K和COCO數據集上進行了零樣本圖像-文本檢索任務的評估。
對于DINOv2-g等純視覺模型,采用k近鄰(kNN)評估協議在ImageNet-1K上測量性能。同時使用kNN協議對CLIP風格模型進行更全面的比較分析。為驗證方法的通用適用性,將其應用于另一種Transformer架構Swin Transformer的監督圖像分類任務(詳細信息見附錄)。
在剪枝階段,將所有視覺Transformer模型的MLP模塊壓縮至目標擴展比r=1和r=2。當r=1時,MLP隱藏層尺寸與令牌維度尺寸相等;當r=2時,隱藏層尺寸為令牌維度的兩倍。對于CLIP風格模型,僅對視覺Transformer部分進行壓縮,文本編碼器保持不變。
蒸餾訓練在配備8×A6000 GPU的服務器上進行,訓練周期為10個epoch,首個epoch用于學習率預熱。采用AdamW優化器配合bfloat16精度,應用余弦學習率調度策略,學習率從lr = base_lr × batch_size / 256開始逐漸衰減至零。不同模型的具體基礎學習率和批量大小參數詳見補充材料。
OpenCLIP-g、OpenCLIP-G、EVA-CLIP-E和DINOv2-g等大型模型采用分布式數據并行(DDP)策略進行訓練。對于超過60億參數的模型(如InternVL-C和EVA-CLIP-8B),采用完全分片數據并行(FSDP)策略。所有模型均使用14的補丁尺寸進行嵌入處理。更詳細的實現信息見附錄部分。
零樣本圖像分類性能分析
為驗證方法的有效性,研究通過設置MLP擴展比為r = 1和r = 2對最先進的CLIP風格模型進行壓縮,并在多種ImageNet變體和ObjectNet數據集上評估其零樣本圖像分類性能。實驗結果表明,壓縮后的模型在平均零樣本分類精度上始終與對應的原始模型保持可比性能,同時將參數數量和FLOPs均減少至原始模型的50%以下。此外,剪枝模型的圖像處理吞吐量獲得顯著提升。
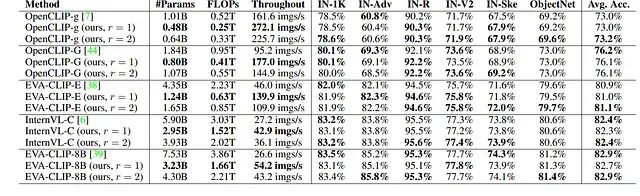
多種ImageNet變體和ObjectNet數據集上零樣本圖像分類任務的性能對比分析。
以EVA-CLIP-E模型為例,參數數量從43.5億減少至12.4億,實現71.5%的壓縮率。相應地,FLOPs同樣減少71.5%,EVA-CLIP-E(r = 1)的圖像處理吞吐量相比原始模型實現3倍加速。當擴展比設置為r = 2時,剪枝后的EVA-CLIP-E在平均零樣本分類精度上甚至超越原始模型0.2%。這些結果充分證明了本方法能夠在零樣本分類任務上實現大型視覺Transformer模型的近似無損壓縮。
進一步的對比分析顯示,剪枝后的OpenCLIP-G(r = 1)模型擁有8.0億參數,在平均零樣本精度上顯著優于擁有10.1億參數的OpenCLIP-g模型3.1%。剪枝后的EVA-CLIP-E(r = 1)模型擁有12.4億參數,相比擁有18.4億參數的OpenCLIP-G模型在性能上實現4.9%的大幅提升。總體而言,剪枝模型相比同等規模甚至更大規模的對比模型展現出更優越的性能表現,進一步驗證了所提方法的有效性。
k近鄰評估結果
為進行更全面的性能比較,研究進一步在ImageNet-1K純視覺任務上評估剪枝后的視覺Transformer模型,采用kNN評估協議且不涉及文本編碼器。實驗結果顯示,采用r = 1剪枝的模型實現了與對應原始模型相似的kNN精度。例如,剪枝后的OpenCLIP-g(r = 1)達到81.9%的kNN精度,較原始OpenCLIP-g模型提升0.2%。盡管參數量和FLOPs顯著減少,r = 2設置下的剪枝模型始終優于原始模型。特別地,剪枝后的OpenCLIP-g(r = 1)相比原始模型展現出0.4%的kNN精度提升。
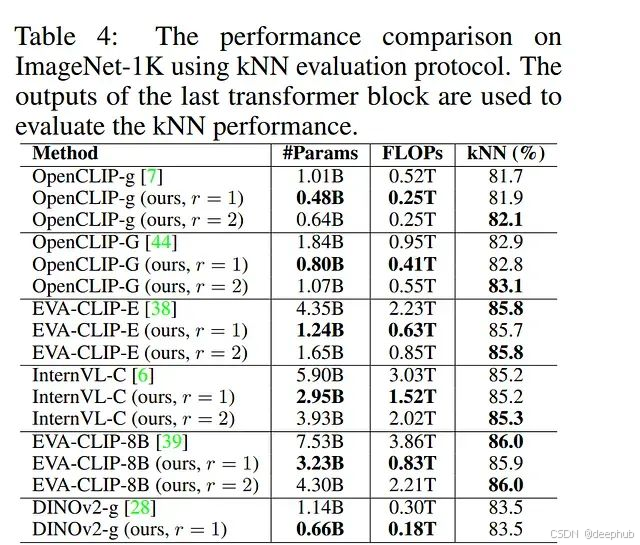
與參數規模相近的模型對比顯示,本研究的剪枝模型展現出明顯的性能優勢。盡管參數量較少,擁有8.0億參數的OpenCLIP-G(r = 1)在kNN精度上顯著優于擁有10.1億參數的OpenCLIP-g模型1.1%。同樣,擁有12.4億參數的EVA-CLIP-E(r = 1)在kNN精度上超越擁有18.4億參數的OpenCLIP-G模型2.8%。為進一步驗證方法的泛化能力,研究將其應用于純視覺Transformer模型DINOv2-g。實驗結果證實了本方法能夠有效壓縮大型視覺Transformer模型同時保持近似無損的性能水平。
MLP擴展比例影響分析
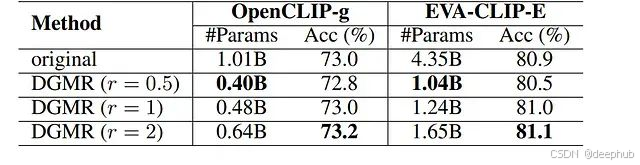
表5:MLP縮減比例對平均零樣本分類精度的影響分析。"original"表示未經壓縮的原始模型。
研究系統探索了不同MLP擴展比例對大型視覺Transformer壓縮效果的影響。實驗結果展示在表5中。采用DGMR方法以擴展比r = 1進行剪枝的OpenCLIP-g模型在五個ImageNet變體和ObjectNet數據集上實現了與原始OpenCLIP-g模型幾乎相同的平均零樣本分類精度,同時僅使用原始模型48.0%的參數量。當擴展比r增加至2時,剪枝模型在平均零樣本精度上甚至超越原始OpenCLIP-g模型0.2%,參數使用量仍僅為64.0%。
研究還探索了r = 0.5的更小擴展比以實現更高的壓縮率。實驗結果顯示,r = 0.5設置下的剪枝模型將參數數量減少60.0%,零樣本分類精度僅從73.0%輕微下降至72.8%。相比r = 1的剪枝模型,該設置以0.2%精度下降為代價實現了額外8.0%的參數縮減。基于綜合考慮,研究選擇r = 1作為默認配置,以在顯著壓縮和良好性能恢復之間取得最佳平衡。
總結
本研究提出的方法主要針對參數密集型MLP模塊的縮減優化,而注意力模塊的壓縮技術仍有待深入探索。在未來的研究工作中,計劃將當前方法擴展至注意力模塊的縮減,并適配于自然語言、音頻和視頻等其他模態的大規模Transformer模型。期望這一研究方向能夠為實現跨領域大規模Transformer模型加速的更廣泛目標做出重要貢獻。
論文和源代碼:
https://avoid.overfit.cn/post/a14cb35858d44dfa994c52fdb2c008c6
Devang Vashistha
)












多媒體--相冊和相機)





