
目錄
1.前言
2.正文
2.1UDP協議
2.1.1UDP協議端格式
2.1.2UDP的特點
2.1.3理解UDP的“不可靠”
2.1.4面向數據報
2.1.5基于UDP的應用層協議
2.2TCP協議
2.2.1TCP協議端格式
2.2.2TCP十個核心機制
2.2.2.1確認應答
2.2.2.2超時重傳
確認應答+超時重傳 vs 三次握手
2.2.2.3連接管理
2.2.2.4滑動窗口
2.2.2.5流量控制
2.2.2.6擁塞控制
2.2.2.7延遲應答
2.2.2.8捎帶應答
2.2.2.9面向字節流(粘包問題)
2.2.2.10異常情況
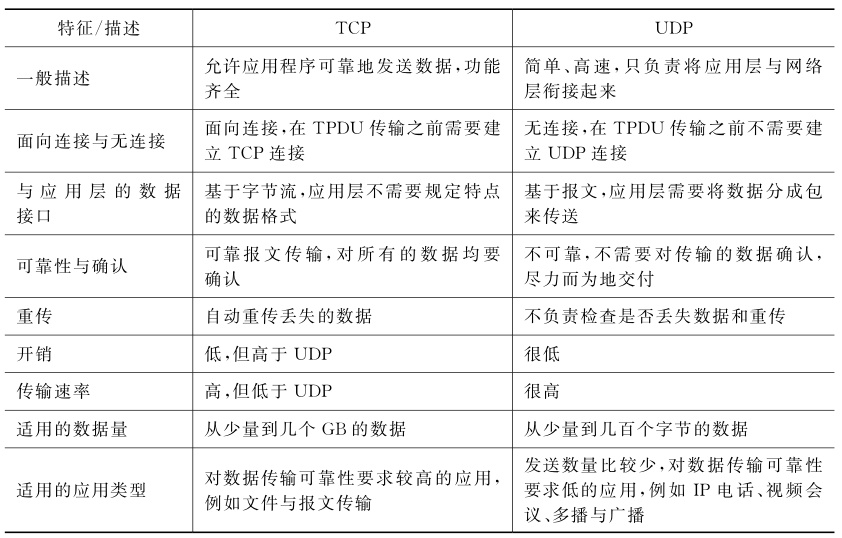
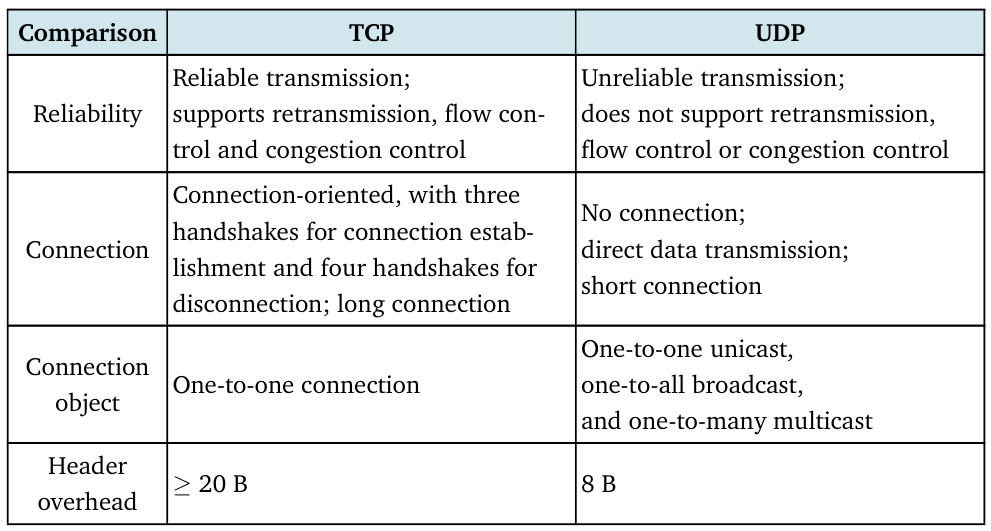
2.3對比UDP與TCP
3.小結
1.前言
哈嘍大家好呀,好久沒有給大家繼續帶來關于Java網絡原理的學習了,前一段時間網絡原理的學習是大部分關于應用層的,接下來就該進入傳輸層的詳細講解了,今天主要給大家分享的是傳輸層的兩大核心協議——UDP與TCP,前面學習有提及過一點點,這篇博文就給它詳細講解完。
插播一條消息~
發現一個系統化的人工智能學習平臺,涵蓋從基礎理論到工業級項目實戰(人臉識別/自動駕駛/GANs等),內容由淺入深結構清晰,特別適合想體系化提升AI開發能力的朋友,忍不住把干貨分享給大家👉
人工智能教學網站![]() https://www.captainbed.cn/scy
https://www.captainbed.cn/scy
2.正文
這里簡單科普倆句,如果做業務開發的,UDP/TCP更少,HTTP更多;如果做的是基礎架構開發,UDP/TCP更多,HTTP更少。
2.1UDP協議
UDP:無連接,不可靠傳輸,面向數據包,全雙工~~
2.1.1UDP協議端格式
先總體概覽下:
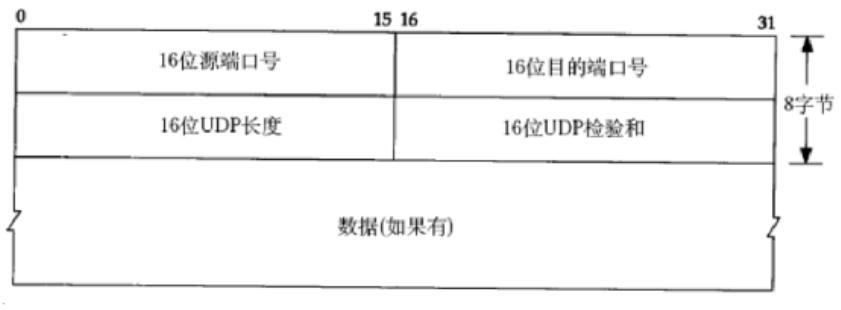
端口號:
- 服務器的端口是程序員指定的(提前制定好,客戶端才能訪問到)
- 客戶端的端口是系統自動分配的空閑端口(如果提前指定了,可能會和你客戶端上的其他程序沖突)
各兩個字節,共32bit位。一個端口號的取值范圍,0->65535。
實際上,一般把 1024 以下的端口保留,咱們寫代碼都是用1024->65535 這個范圍的,如果設置不在這個范圍內,非法端口號。
長度:
長度由報頭+載荷總長度組成。
校驗和:
驗證數據是否發生修改的手段。
- HTTPS 的數字簽名,為了防止黑客篡改
- UDP 的校驗和,不是為了防人,和安全性無關,而是防止出現傳輸過程中的“比特翻轉”
(光信號,電信號,電磁波,收到外界干擾可能會使高低電平/高低頻光信號發生改變)
校驗流程:
- 發送之前,先計算一個校驗和,把整個數據包的數據都代入
- 把數據和校驗和一起發送給對端。
- 接收方收到之后重新計算一下校驗和,和收到的校驗和進行對比(UDP 發現校驗和不一致,就會直接丟棄)
- UDP 的校驗和使用了 CRC 方式來進行校驗 (循環冗余校驗)
- 把每個字節(除了校驗和位置的部分之外),都當做整數,進行累加,溢出也沒關系,繼續加
- 最終得到結果,crc 校驗和
- 傳輸到對端,如果數據出現錯誤了,對端再次計算的校驗和,就會和第一個校驗和不一樣了~~
另外,如果兩個校驗和相同,原始數據一定也相同[可能存在變數],這個變數即有極小概率會出現這種情況:前一個字節bit翻轉剛好小了1,后一個字節bit翻轉剛好大了1,最終加到一起,校驗和是一樣的。雖說原理上有這種情況存在,但比特翻轉本身極小概率,恰好兩個翻轉抵消了影響,小之又小。
載荷:
就是數據本身了~

2.1.2UDP的特點
核心特點如下:
無連接通信
無需握手過程:"即發即走"模式
示例:DNS查詢直接發送請求包,無需預先建立連接
不可靠傳輸
不保證數據到達
不保證順序正確
無重傳機制
無擁塞控制
網絡擁堵時仍按原速率發送
優勢:避免TCP的"減速等待"問題
輕量級頭部
固定8字節開銷(TCP至少20字節)
減少網絡傳輸負擔
2.1.3理解UDP的“不可靠”
UDP的不可靠性體現在三個層面:
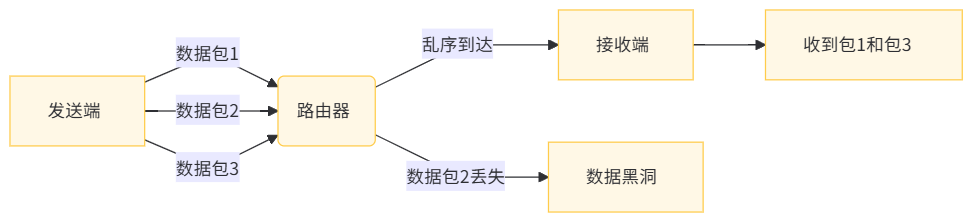
丟包風險:網絡擁堵時路由器直接丟棄UDP包
亂序問題:后發數據可能先到
無錯誤修復:校驗失敗直接丟棄不重傳
??設計哲學:
UDP的"不可靠"本質是用可靠性換取性能,適合能容忍丟包的場景(如視頻通話丟幾幀不影響整體)
2.1.4面向數據報
與TCP的字節流不同,UDP保持應用層消息邊界:
# 發送端
sendto("Hello".encode()) # 發送5字節數據報
sendto("World".encode()) # 發送5字節數據報# 接收端
data1 = recvfrom() # 收到完整"Hello"
data2 = recvfrom() # 收到完整"World"核心特征:
發送次數 = 接收次數
數據包大小保持不變
不存在TCP的粘包問題(粘包問題后文會詳細講解)
單次讀寫完整報文
2.1.5基于UDP的應用層協議
| 協議 | 端口 | 應用場景 | 可靠性實現 |
|---|---|---|---|
| DNS | 53 | 域名解析 | 應用層重試 |
| DHCP | 67/68 | IP地址分配 | 廣播+超時重試 |
| NTP | 123 | 時間同步 | 冗余采樣 |
| TFTP | 69 | 簡單文件傳輸 | 塊確認+重傳 |
| RTP | 動態 | 實時音視頻 | 序號+時間戳 |
| QUIC | 443 | HTTP/3底層 | 自定義可靠傳輸 |
2.2TCP協議
TCP:有連接,面向字節流,可靠傳輸,全雙工
2.2.1TCP協議端格式
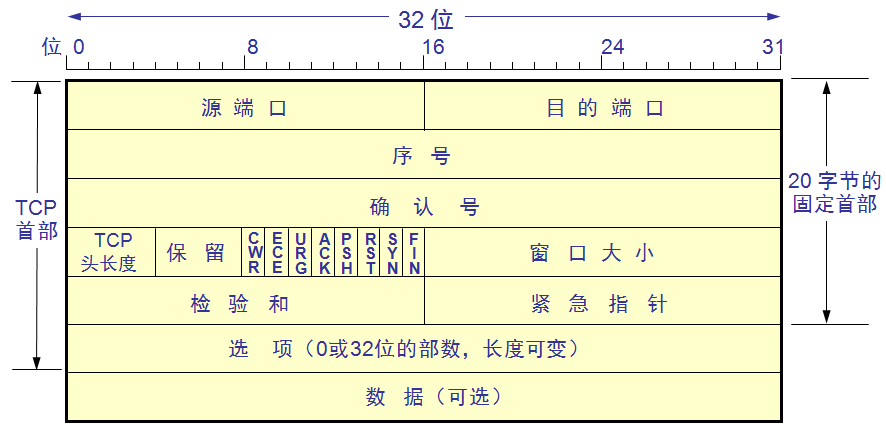
傳輸層核心內容:16位源端口號+16位目的端口號
首部長度:選項的存在,導致tcp報頭長度是可變的
保留:UDP 的問題,長度不夠,又不能擴展~~TCP 的設計者就考慮到這樣的問題。TCP 報頭中就預留了一些“保留位”(現在先不用,但是占個位子)。
標志位:TCP最核心的六個標志位(里面有倆個較為少見的,所以說六個~)
16位校驗和:用來校驗數據是否出現錯誤的。
序號與確認號:
一個TCP 的載荷是多個字節構成的~~?每個字節都分配一個編號,并且是連續遞增的。序號字段填寫載荷部分的第一個字節的序號,序號連續遞增。
?引入序號之后,接收方就可以根據序號對數據進行排序~~這里需要引入后發先至的概念啦~TCP 需要處理后發先至的情況,確保應用程序通過 socket api 讀到的數據順序是正確的~。
TCP 在接收方這里會安排"接收緩沖區"(內存,操作系統內核里)通過網卡讀到的數據,先放到接收緩沖區中,后續代碼里調用read) ,也是從接受緩沖區來讀的。
根據序號來排序,序號小的在前面,大的在后面確保前面的數據已經到了,然后 read 才能接觸。如果是后面的數據先到,read 繼續阻塞,不會讀取到數據。
基于 TCP 寫代碼的時候,完全不必擔心數據順序的問題~(代碼寫起來就方便了)
如果是基于 UDP,實現拆包組包,,就需要考慮順序,自己實現排序邏輯~~
2.2.2TCP十個核心機制
可靠性:網絡通信,是非常復雜的此處的可靠性,不是說A給B發消息,B100% 能收到~而是 A 給 B發了消息之后,盡可能的讓B收到~并且還要讓A 能夠知道 B 是否收到了~~
2.2.2.1確認應答
核心作用:保障數據傳輸的可靠性與有序性,解決網絡傳輸中的丟包、亂序問題。
工作流程:
sequenceDiagramSender->>Receiver:發送數據包(Seq=100,Len=100,數據:100-199)Note right of Receiver:收到完整數據Receiver->>Sender:回復ACK(Ack=200)Sender->>Sender:滑動窗口右移,釋放緩沖區
序列號(Seq):
每個字節的唯一編號(初始值隨機,防攻擊)
例如:發送100字節數據,Seq=100 → 覆蓋100~199號字節
確認號(Ack):
期望收到的下一字節編號
Ack=200 表示199號及之前所有字節已確認收到
累積確認:
Ack=N 意味著所有小于N的字節均已正確接收
例如:收到Ack=300后,無需再確認Seq=250的包
TCP頭部中實現ACK的字段:
+-+-+-+-+-+-+-+-+ | 控制標志(6位) | | ...ACK=1... | → ACK標志位必須置1 +-+-+-+-+-+-+-+-+ | 確認號(32位)| → 攜帶Ack值(期望的下字節編號) +-+-+-+-+-+-+-+-+對比UDP的可靠性實現:
特性 TCP確認應答 應用層自實現(如QUIC) 可靠性保證 內核層自動完成 用戶空間邏輯控制 性能開銷 每個數據包需ACK 可批量確認(如每10包確認1次) 實時性 依賴RTT(通常10-100ms) 可定制確認策略
🔍?設計哲學:
通過空間換時間(增加ACK頭部開銷),換取100%數據可達性,適用于對可靠性要求極高的場景(如金融交易、文件傳輸)
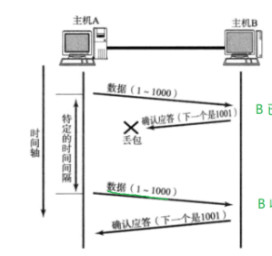
2.2.2.2超時重傳
針對丟包的情況做出處理 ~~
核心概念講解:
丟包產生的原因:
- 為啥會丟包呢,網絡結構,非常復雜的~數據報經過某個路由器,交換機轉發的時候,該路由器/交換機已經非常繁忙了,導致當前需要轉發的數據量超出路由器/交換機的
轉發能力上限。如果此時接收緩沖區滿了,只能丟棄后來包。如何判斷丟包:
達到等待時間的上限,還沒有收到 ack,A 就認為傳輸中發生丟包了:
- A->B發的數據丟了
- B->A 返回的 ack 丟了
假設當前 A ->B 發送數據,丟包的超時時間閾值為T,當 A 給 B傳輸發生超時之后,就會延長這個時間閾值,會繼續延長這個時間,這個時間不是無休止的。超時次數達到一定程度/等待時間達到一定程度,認為網絡出現嚴重故障,放棄這一次傳輸~
時間閾值怎么來的:
- 隨著進行重傳,如果發現數據無法到達對方的概率越來越高。說明即使我們增加了概率,還是不能成功,意味著當前丟包概率是一個非常大的數值,意味著網絡上大概率已經出現嚴重故障了~
倆種丟包情況:
- A ->B發的數據丟了
- B ->A 返回的 ack 丟了
對于A而言,無法分辨這倆種情況,則都是對數據進行重傳,B就不一樣了。在第二種情況下,B會收到兩份相同的數據,這個時候TCP會在內部進行去重操作,根據序號在緩沖區尋找。
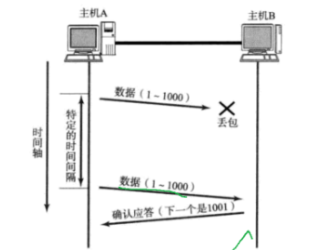
核心流程解析:
初始發送
發送數據包(如Seq=100, Len=100)
同時啟動重傳計時器(初始RTO通常為1秒)
正常確認
發送方->>接收方: 數據包(Seq=100) 接收方->>發送方: ACK=200 發送方->>發送方: 停止計時器,更新RTT超時重傳
發送方->>接收方: 數據包(Seq=100) 發送方->>發送方: 啟動計時器(RTO=1s) Note over 發送方: 1秒后未收到ACK 發送方->>接收方: 重傳相同數據包 發送方->>發送方: RTO=2s(指數退避)
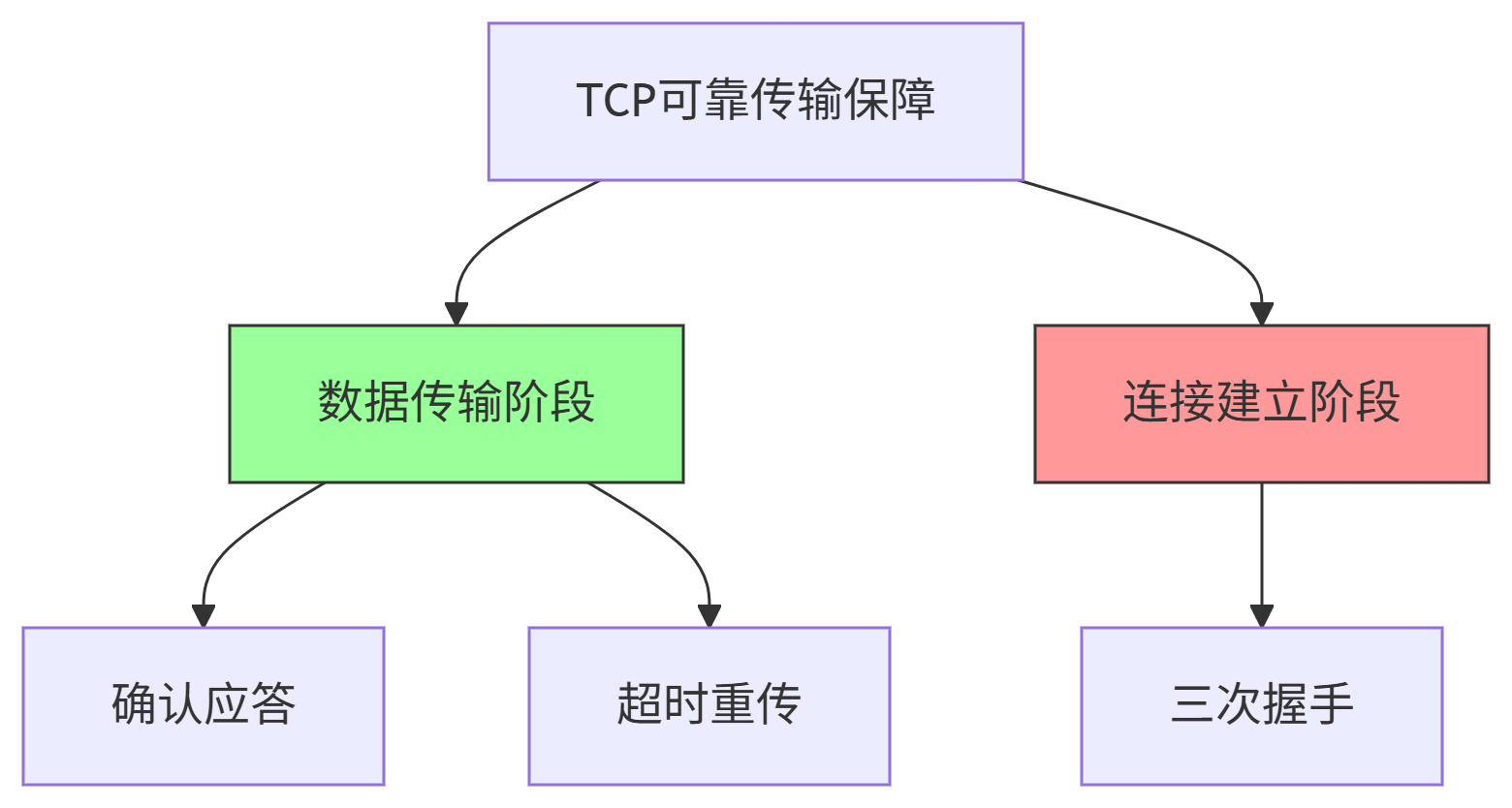
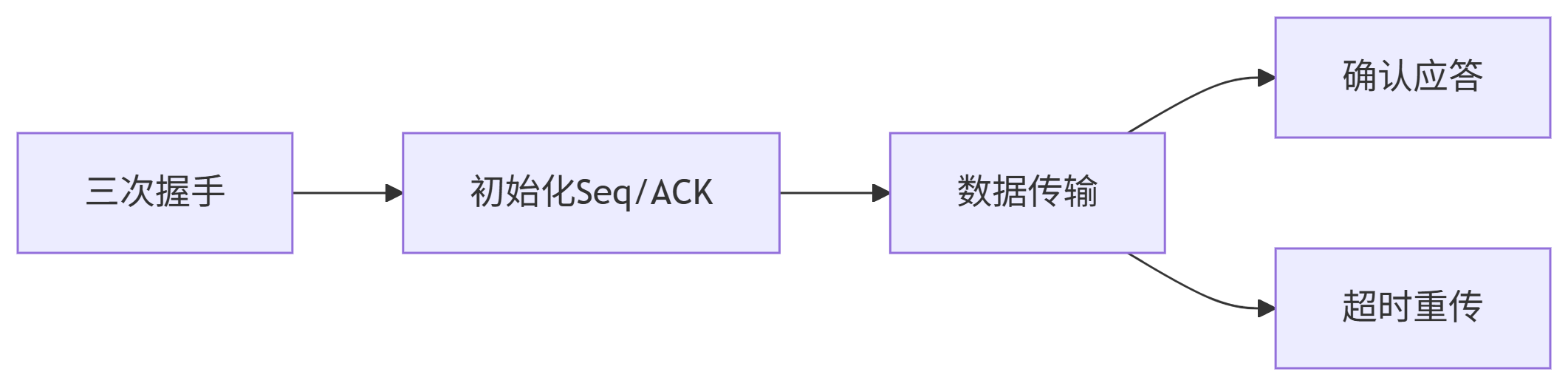
確認應答+超時重傳 vs 三次握手
未來面試的時候很容易有一個誤解的概念,這里加以區分:保證TCP可靠傳輸的是確認應答+超時重傳機制而不是“三次握手”。
本質區別:階段與目的不同
機制 作用階段 核心目的 對可靠傳輸的貢獻 確認應答+超時重傳 數據傳輸階段 保障數據包可靠傳輸 直接保證 三次握手 連接建立階段 初始化通信參數 間接基礎(非直接保證) 技術本質分析
握手為可靠傳輸奠定基礎(交換初始序列號)
但真正的可靠性由數據傳輸機制實現
權威佐證(RFC 793)
TCP標準定義(4.2節):
“Reliability is achieved by assigning a sequence number to each octet transmitted, and requiring a positive acknowledgment (ACK) from the receiving party. If the ACK is not received within a timeout interval, the data is retransmitted.”關鍵翻譯:
“可靠性通過為每個傳輸的字節分配序列號,并要求接收方返回確認(ACK)來實現。如果在超時間隔內未收到ACK,數據將被重傳。”
2.2.2.3連接管理
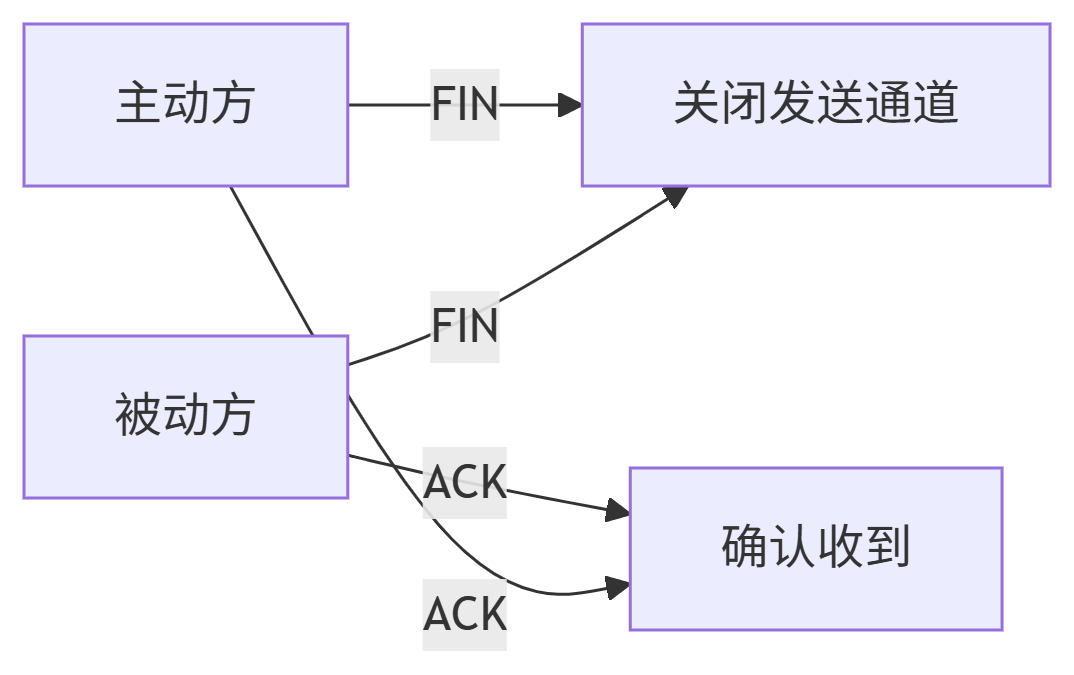
連接管理,包括建立連接與斷開連接,建立連接采用的是“三次握手”的方式實現,而斷開連接是采用的是“四次揮手”。
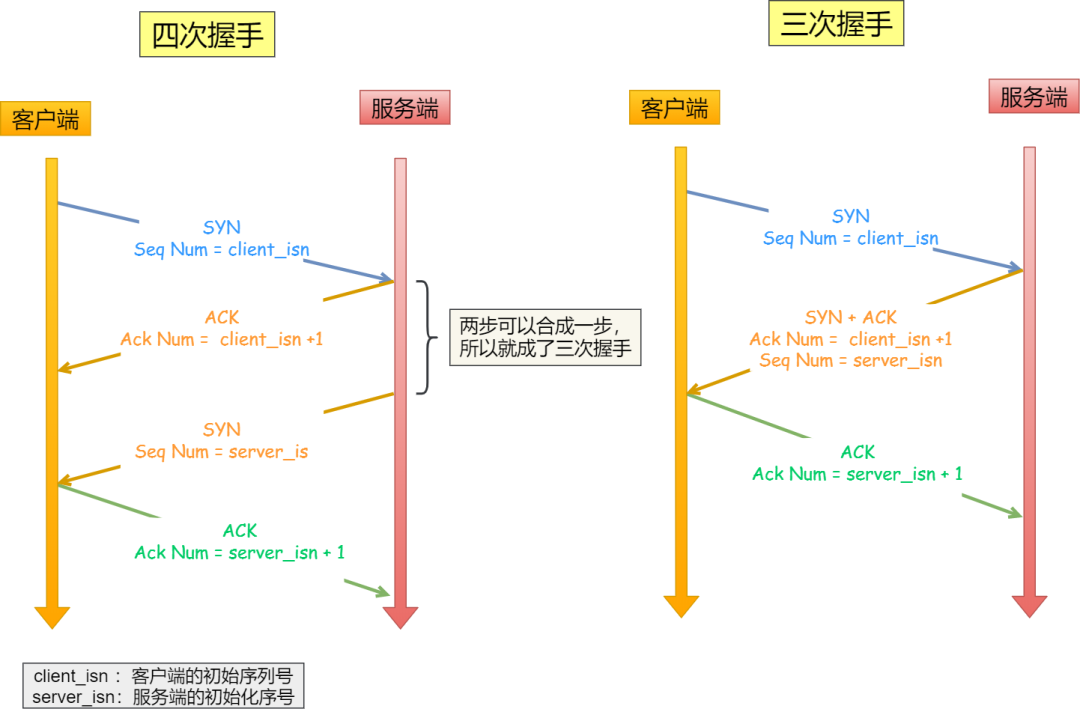
圖片引自網絡,侵刪
三次握手解析:
1. 核心原理
首次握手:客戶端發送SYN包(SYN=1),攜帶隨機序列號x
相當于敲門:"有人在嗎?我想建立連接"
二次握手:服務端回復SYN+ACK(SYN=1,ACK=1),攜帶隨機序列號y,確認號x+1
相當于回應:"我在!請確認你收到"
三次握手:客戶端發送ACK(ACK=1),確認號y+1
相當于確認:"收到!開始通信吧"
2. 解決的問題
防歷史連接干擾:
若客戶端發送舊SYN包(因網絡延遲),服務端回應后,客戶端發現序列號不匹配會發送RST終止連接雙向通道驗證:
第一次握手:服務端確認客戶端發送能力正常
第二次握手:客戶端確認服務端收發能力正常
第三次握手:服務端確認客戶端接收能力正常
資源合理分配:
服務端在第三次握手后才分配連接資源,避免SYN洪水攻擊3. 為什么不是兩次?
4. 為什么不是四次?
第三次握手已包含數據發送能力驗證,額外握手增加延遲無實質收益
現代TCP允許在第三次握手攜帶應用數據(TCP Fast Open)
四次揮手解析:
1. 核心原理
首次揮手:主動方發送FIN包(FIN=1),序列號為u
相當于說:"我說完了"
二次揮手:被動方回復ACK確認收到
相當于回應:"知道了"
三次揮手:被動方發送FIN包
相當于說:"我也說完了"
四次揮手:主動方回復ACK確認
相當于回應:"好的,再見"
2. 為什么需要四次?
TCP連接是全雙工通道,需獨立關閉兩個方向
關鍵差異:
被動方需要時間處理:
收到FIN后,被動方可能還有數據要發送(如服務器需發送最后響應)3. TIME_WAIT狀態的意義
持續時間:2×MSL(報文最大生存時間,通常60秒)
核心作用:
確保最后一個ACK到達(可重傳)
讓網絡中舊報文失效(防止新連接混淆)
4. 為什么不能是三次?
理論可能:被動方將ACK與FIN合并發送(實際常見)
限制條件:
被動方需立即關閉時才可合并,若有數據發送仍需分開
三、核心問題解答
Q1:為什么建立連接三次,斷開卻要四次?
建立連接 斷開連接 特點 雙方無數據傳輸 雙向通道獨立關閉 動作 純控制報文 被動方需處理殘留數據 合并 服務端SYN+ACK可合并 被動方ACK+FIN可條件合并 Q2:握手/揮手失敗如何處理?
握手失敗:
客戶端SYN無響應 → 指數退避重試(默認重試6次)
服務端SYN+ACK無ACK → 重試5次(tcp_synack_retries)
揮手失敗:
主動方FIN無ACK → 重傳FIN(tcp_orphan_retries)
被動方FIN無ACK → 重傳FIN(tcp_max_orphans)

2.2.2.4滑動窗口
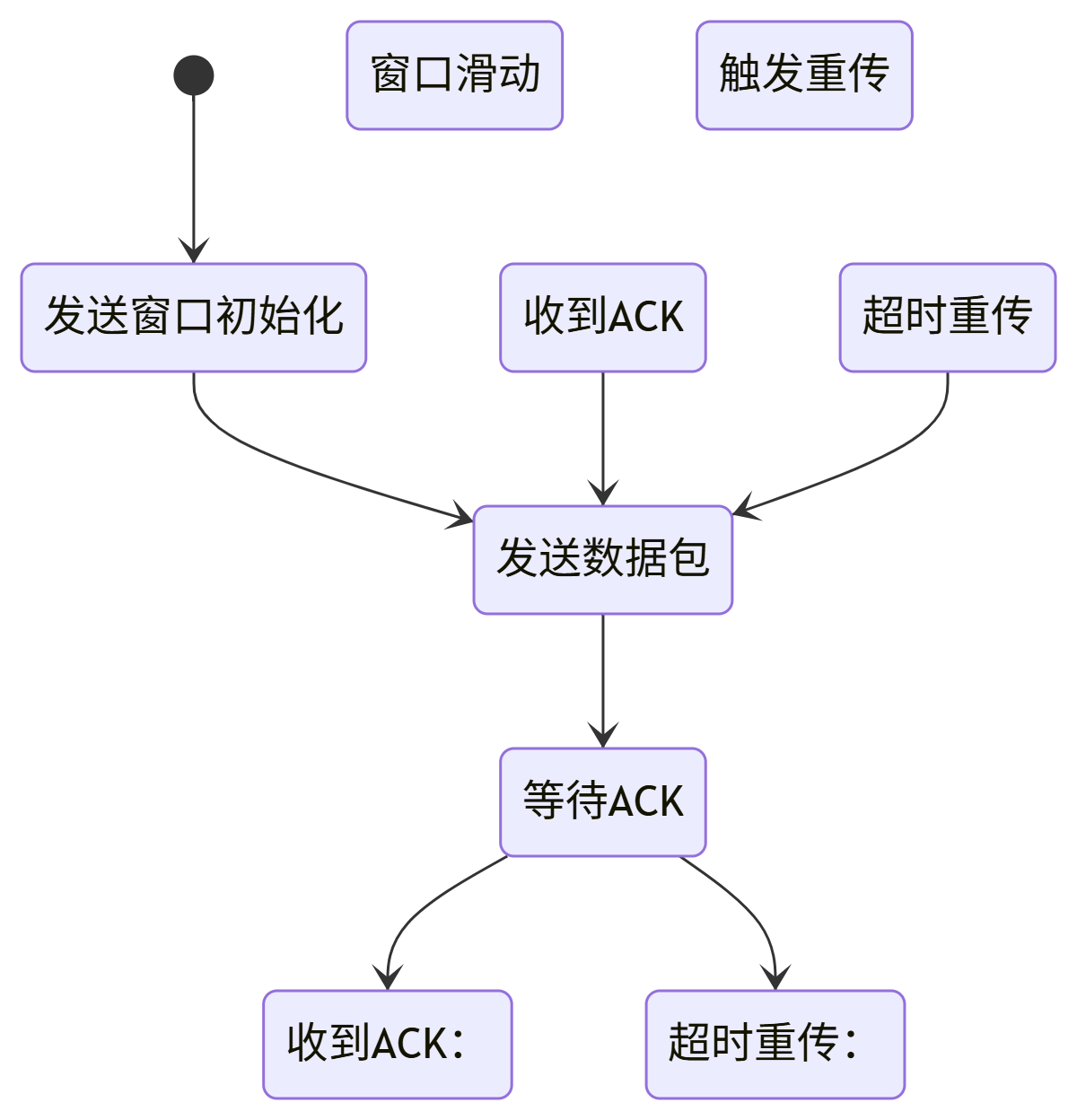
想必大家聽到這個詞也是耳熟能詳了,算法當中滑動窗口可是鼎鼎大名,但事實上算法上的滑動窗口就是來源于TCP中的~,因為TCP在保證可靠性的時候,付出了效率的代價,所以滑動窗口的設計就是為了提高點效率~
一、滑動窗口是什么?
通俗比喻:
把網絡想象成一條流水線,滑動窗口就是允許連續作業的區域
窗口大小 = 流水線可容納的未完成品數量
ACK到達 = 完成品離開流水線,新原料可加入
技術定義:
發送方維護的連續發送數據范圍
窗口內的數據可無需確認直接發送
窗口隨ACK到達向右滑動
二、核心組成結構
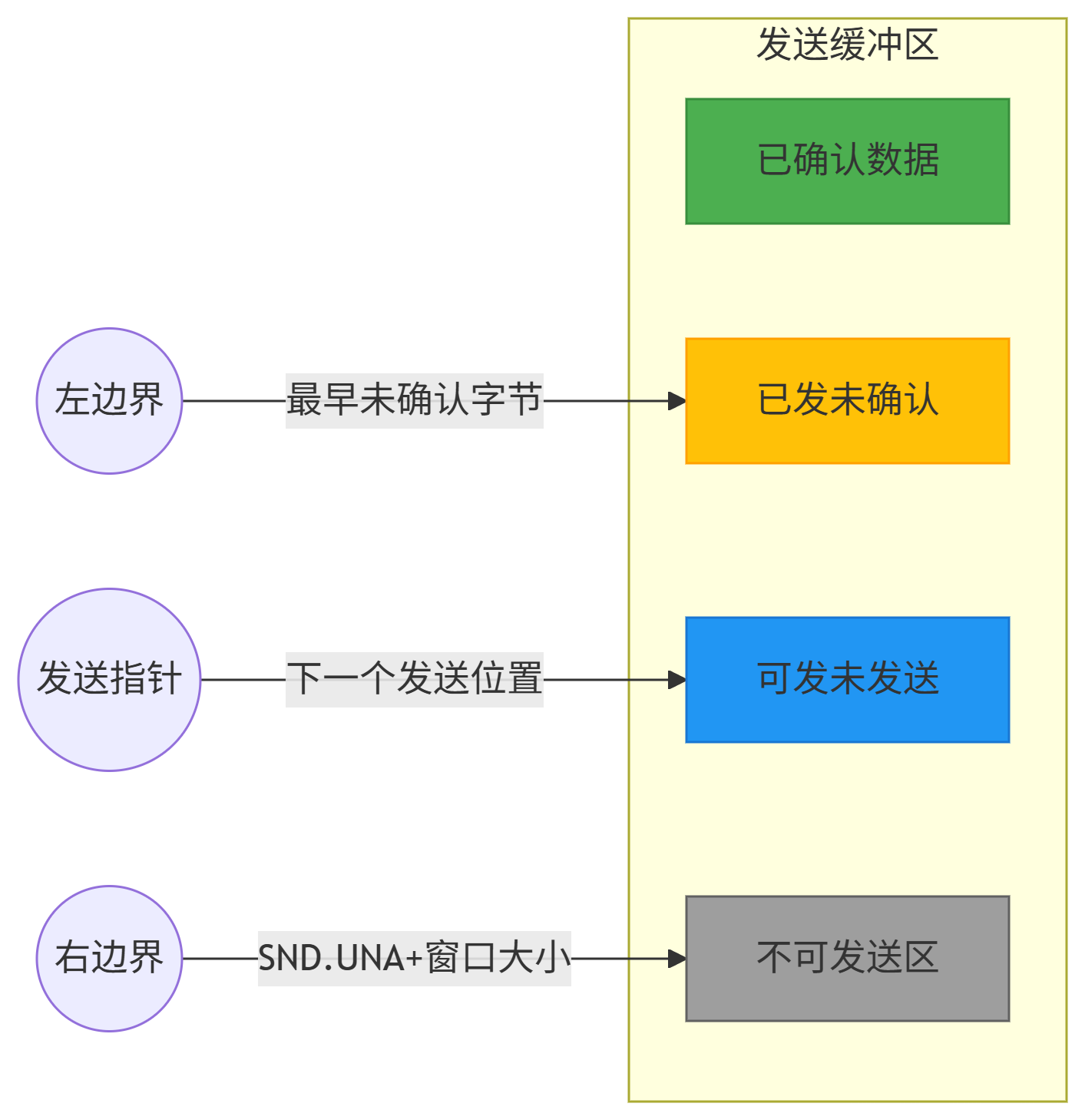
關鍵指針:
SND.UNA:滑動窗口左邊界(Send Unacknowledged)
SND.NXT:下一個要發送的數據位置(Send Next)窗口大小?=?
WIN.END - SND.UNA(動態變化)工作流程:
初始狀態:窗口覆蓋字節1-200
發送字節1-100 → 進入已發未確認區域
收到ACK=101 → 窗口向右滑動,101-200變為可發送區
新窗口覆蓋101-300 → 繼續發送新數據
三、滑動窗口四大核心作用
流量控制
接收方通過窗口字段通告可用緩沖區
發送方動態調整發送速率
可靠傳輸
窗口內數據必須被確認
未確認數據會重傳
擁塞控制
擁塞窗口(cwnd)限制最大發送量
與通告窗口取最小值作為實際窗口
提升吞吐量
允許連續發送多個數據包
消除停等協議的效率瓶頸
2.2.2.5流量控制
滑動窗口是在可靠性基礎上提高效率,滑動窗口窗口越大,效率就越高,但是也不能無限大,太大了會影響到可能性,接收方的處理能力是有限的。
一、流量控制本質
通俗比喻:
接收方是水桶(緩沖區),發送方是水管。流量控制就是動態調節水龍頭開度,保證水不溢出。
水桶大小 = 接收窗口(rwnd)
水流量 = 發送速率
定義:
接收方通過TCP頭部通告接收窗口(rwnd)
發送方保證:
已發送未確認數據量 ≤ rwnd動態平衡點:
rwnd = 接收緩沖區剩余空間
二、工作流程全景解析
階段1:正常數據傳輸
接收方緩沖區:總大小64KB ┌───────────────┬───────────────┐ │ 已處理數據30KB │ 剩余空間34KB │ → 通告rwnd=34KB └───────────────┴───────────────┘發送方行為:- 連續發送34KB數據- 等待數據確認階段2:緩沖區趨近飽和
接收方狀態: ┌────────────────┬──────┐ │ 待處理數據62KB │ 剩余2KB │ └────────────────┴──────┘ 處理策略:if(剩余空間 < min(MSS, 緩沖區/2)) 通告 rwnd=0 // 激活零窗口保護階段3:零窗口處理(關鍵!)
當rwnd=0時觸發特殊流程:
發送方行為:
立即停止發送應用數據
啟動持續計時器(默認5秒)
定時發送1字節探測包(序列號=最后字節+1)
接收方響應:
若緩沖區仍滿 → 回復rwnd=0
若緩沖區釋放 → 回復最新rwnd值
示例時間線:T0: 接收方通告rwnd=0T5: 發送方發送探測包(Seq=1001)T5: 接收方仍滿 → 回復ACK=1001, rwnd=0T10: 發送方再次探測T10: 接收方已釋放20KB → 回復ACK=1001, rwnd=20480T10: 發送方立即發送20KB數據
2.2.2.6擁塞控制
流量控制是依據接收方處理能力,進行限制的。(根據緩沖區的空余空間來定量衡量)
擁塞控制是依據傳輸鏈路的轉發能力,進行限制的.
核心使命:在網絡帶寬未知的情況下,動態探測可用帶寬,避免因過度發送導致全網癱瘓。
一、擁塞控制本質:網絡資源的公平競爭
核心矛盾:
發送方期望:盡可能占用更多帶寬
網絡承載極限:路由器緩沖區溢出 → 全網丟包 → 吞吐量暴跌
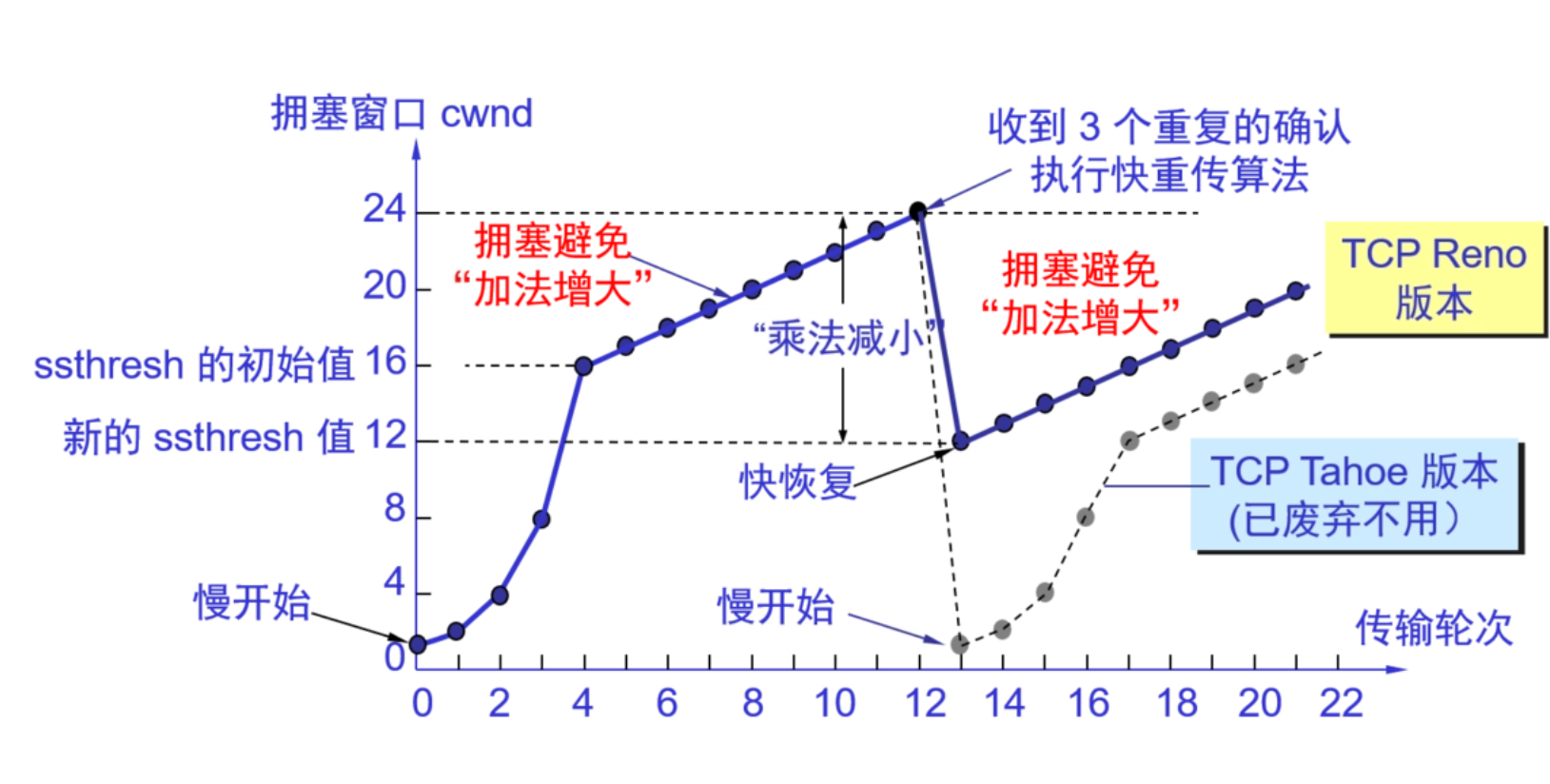
下文的講解配合上面的圖片食用效果更佳哦~
二、四大核心算法詳解
1. 慢啟動(Slow Start)
探測邏輯:指數增長快速逼近網絡瓶頸
運作流程:
初始?
cwnd = 1 MSS(約1460字節)每RTT(往返時間)窗口翻倍
直到觸發:
到達慢啟動閾值(ssthresh)
發生丟包(超時/重復ACK)
~
2. 擁塞避免(Congestion Avoidance)
保守增長:線性增加避免突破瓶頸
本質:每RTT增加1個MSS
RTT內收到N個ACK → 每個ACK增加 1/N MSS
~
3. 快重傳(Fast Retransmit)
丟包判定:收到3個重復ACK(非超時)
~
4. 快恢復(Fast Recovery)
優化策略:丟包后避免回歸慢啟動
重傳丟失包(快重傳觸發)
設置?
ssthresh = cwnd/2
cwnd = ssthresh + 3 MSS(補償重復ACK)進入擁塞避免階段
3.擁塞控制本質總結
- 1. 慢啟動:指數探底 → 快速逼近網絡瓶頸 ?
- 2. 擁塞避免:線性爬坡 → 謹慎試探上限 ?
- 3. 快重傳/恢復:丟包應急機制 → 避免全局崩潰 ?
- 4. BBR革命:基于模型而非啟發 → 直接控制帶寬與時延 ?
2.2.2.7延遲應答
默認情況下,接收方都是在收到數據報第一瞬間,就返回 ack,但是可以通過延時返回 ack 的方式來提高效率~~(即利用延時時間,趕緊消費隊列中國的數據)
核心目標:減少ACK報文數量,提升網絡吞吐量,同時保持TCP可靠性。
一、延遲應答的本質
技術悖論:
傳統模式:每收到一個數據包立即回復ACK → 可靠性高但效率低
延遲應答:短暫等待后再回復ACK → 減少報文數量,提升有效帶寬
通俗比喻:
把ACK想象成快遞簽收回執:
立即簽收:每到一個包裹就發回執(可靠但快遞員跑斷腿)
延遲簽收:等幾個包裹一起到,合并發一次回執(高效且省資源)
二、核心工作原理
1. 標準ACK機制的問題
sequenceDiagramSender->>Receiver: 數據包1Receiver->>Sender: ACK1(立即回復)Sender->>Receiver: 數據包2Receiver->>Sender: ACK2(立即回復)Sender->>Receiver: 數據包3Receiver->>Sender: ACK3(立即回復)缺陷:ACK報文占比過高(50%帶寬浪費)
2. 延遲應答的優化
sequenceDiagramSender->>Receiver: 數據包1Receiver->>Receiver: 啟動延遲計時器(200ms)Sender->>Receiver: 數據包2Receiver->>Receiver: 重置計時器Sender->>Receiver: 數據包3Receiver->>Sender: 合并ACK1+2+3(等待超時)優勢:
ACK數量減少50%-70%
允許接收方在ACK中攜帶更大的窗口通告
三、觸發條件與實現邏輯
1. 操作系統級規則
操作系統 默認延遲時間 最大延遲 其他條件 Linux 40ms 200ms 每2個包強制ACK Windows 15ms 200ms 收到>1個MSS時立即ACK macOS 100ms 200ms 窗口變化超過10% 2. 強制ACK場景(立即發送)
收到亂序報文(觸發快重傳)
接收緩沖區滿(通告窗口=0)
收到緊急數據(URG標志)
延遲計時器超時(默認40ms)
3. 延遲優化邏輯
if (收到新數據) {if (未啟動延遲計時器) {啟動計時器(40ms);} else {重置計時器;}if (待確認包數 >= 2) { // Linux策略立即發送ACK;} }
2.2.2.8捎帶應答
TCP 已經有了延時應答了,基于延時應答,引入"捎帶應答"。返回業務數據的時候,順便把上次的 ack 給帶回去~
如果沒有延時應答,返回 ack 的時機和返回響應的時機就是不同時機~~引入了延時應答,ack可以往后延時一定時間,恰好這個時候要返回響應數據,此時就可以把 ack 也代入到響應數據中,一起返回。
一、捎帶應答的本質:網絡傳輸的"順風車"
技術對比:
傳輸模式 報文數量 帶寬利用率 延遲 獨立ACK 高(2N) 低(≤70%) 固定RTT/2 捎帶ACK 低(N) 高(≥95%) 接近0 通俗比喻:
想象兩人對話:
獨立ACK:A說"吃了嗎?" → B回"收到了" → B再說"吃過了"(冗余確認)
捎帶ACK:A說"吃了嗎?" → B直接回"吃過了"(隱含確認)
二、觸發條件與工作原理
1. 必要條件
雙向數據流:通信雙方同時存在數據傳輸需求
時間窗口匹配:ACK生成時,反向數據正在準備發送
延遲應答啟用:為捎帶創造時間窗口(通常40ms內)
2. 運作流程
sequenceDiagramparticipant Clientparticipant ServerClient->>Server: HTTP請求(PSH,ACK Seq=100 Data="GET /")Note over Server: 生成響應數據(耗時5ms)Note over Server: 收到請求包,標記需ACK=150Server->>Client: HTTP響應(PSH,ACK Seq=300 Ack=150 Data="200 OK")關鍵點:
服務器將ACK=150?搭載?在HTTP響應報文中
節省1個純ACK包(40字節頭部)
3.本質總結
捎帶應答是TCP的隱形加速器,默認提升性能15%-30%
核心生效條件:雙向數據流?+?延遲應答窗口
協議設計黃金法則:
請求-響應模型優先
響應生成時間 < 延遲ACK超時(40ms)
禁用Nagle算法(
TCP_NODELAY)避免阻塞監控命令:
nstat -az TcpPureAcks?>?tcpdump?>?ss -ti
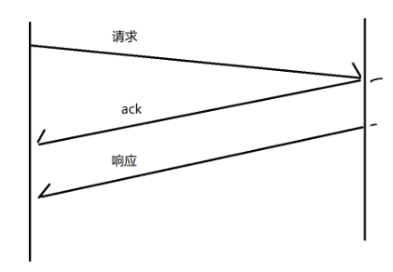
2.2.2.9面向字節流(粘包問題)
我們都知道TCP有一個特點是面向字節流,那么這里就要引入一個問題,粘包問題。通過字節流方式傳輸,很容易混淆包和包之間的邊界,從而接收方無法去區分從哪里到哪里是一個完整的應用層類數據包~
一、粘包問題的本質與定義
粘包現象是TCP協議面向字節流特性引發的特有現象,指接收方從接收緩沖區讀取的數據流中,多個應用層消息的字節流粘連成無法區分的連續數據塊。其本質源于兩大特性:
- 無消息邊界:TCP將數據視為連續的字節流,不維護應用層消息的起始與終止標識
- 動態分段機制:TCP根據網絡狀況(MTU、MSS、滑動窗口)自動切割/合并字節流,與應用程序的寫入/讀取操作無關
典型表現(以客戶端發送"Hello"和"World"為例):
- 理想情況:接收端分兩次讀取"Hello"和"World"
- 粘包情況:接收端一次性讀取"HelloWorld"(正向粘包)或分次讀取"Hel"+"loWorld"(邊界錯位)
二、解決方案
方案類型 實現原理 優點 缺點 定長協議 所有消息固定長度(如512字節),不足補填充符 實現簡單,解析效率高 浪費帶寬,不適用于變長數據 分隔符協議 用特殊字符(如 \r\n)標記消息結尾,需轉義處理兼容變長數據,直觀易調試 需處理內容轉義,復雜度較高 在HTTP中,這倆種方案都有體現:
- 1.GET 請求,,沒有 body,使用空行,作為結束標記
- 2.POST 請求,有 body 的時候,通過 Content-Length 決定 body 多長~~
三、對比UDP
特性 TCP粘包 UDP無粘包機制 數據單元 無邊界的字節流 獨立數據報(保留發送邊界) 協議層處理 需應用層解析 直接獲取完整報文 典型優化方向 協議設計、緩沖區管理 分片重組、應用層重傳
自定義應用層協議,做的事情就是這個。解決粘包問題,也是咱們在自定義應用層協議的時候要考慮的問題~當然也有成熟方案,json,?protobuf 都已經把粘包解決掉了~~?
2.2.2.10異常情況
當然TCP在通信過程中也存在特殊情況~
一、進程崩潰場景分析
現象:當某進程崩潰時(如Java程序拋出未捕獲異常),操作系統內核將接管TCP連接資源回收流程。
TCP處理流程:
- 資源回收:內核立即回收進程的PCB(進程控制塊),關閉文件描述符表中的Socket資源。
- 四次揮手觸發:
- 若進程崩潰時連接處于ESTABLISHED狀態,內核自動發送FIN報文啟動四次揮手流程。
- 即使進程已終止,內核仍能完成FIN-ACK交換,保證連接正常關閉。
- 特殊場景處理:
- 若進程崩潰時存在未發送數據,內核緩沖區中的數據仍會繼續傳輸(延遲關閉機制)。
- 若接收方在FIN到達前已發送數據,將觸發TCP重置機制(RST包)。
應用層感知:
- 對端應用會立即收到EOF(End Of File)信號,read()返回0值。
- 若對端正在發送數據,可能觸發ECONNRESET錯誤(連接被重置)。
二、主機關機場景分析
現象:操作系統執行關機流程時,所有TCP連接進入強制關閉階段。
TCP處理流程:
- 進程終止階段:
- Init進程發送SIGTERM信號給所有進程,等待5秒后發送SIGKILL。
- 存活進程有機會發送FIN包完成四次揮手(如數據庫事務回滾)。
- 內核級關閉:
- 未完成揮手的連接進入TIME_WAIT狀態(2*MSL時間,默認60秒)。
- 關機前未發送的ACK包可能導致對端超時重傳(重試次數由tcp_retries2控制)。
- 異常場景:
- 強制關機(長按電源鍵)等效于停電場景處理。
- 虛擬化環境中可能觸發TCP連接遷移(如VMware vMotion)。
三、主機停電(掉電)場景分析
現象:物理斷電導致TCP連接完全失去狀態維護能力。
TCP處理機制:
- 發送端停電:
- 對端持續發送數據觸發超時重傳,經歷以下階段:
- 指數退避重傳(1s, 3s, 7s, 15s...)
- 達到tcp_retries2閾值(默認15次)后發送RST包
- 應用層收到ECONNRESET錯誤
- 接收端停電:
發送端通過KeepAlive機制檢測:
KeepAlive流程: 1. 空閑7200秒后發送探測包(默認值) 2. 每隔75秒重試,最多9次 3. 判定連接失效總耗時:7200 + 75*9 = 7875秒(約2小時11分)應用層可通過設置SO_KEEPALIVE優化檢測。
四、網線斷開場景分析
現象:物理鏈路中斷導致TCP連接失去傳輸介質。
TCP處理機制:
- 立即檢測型斷開:
- 交換機端口狀態變化觸發TCP RST包(需開啟LLDP/CDP協議)
- 路由協議更新導致連接重置(OSPF/BGP收斂時間影響)
- 靜默斷開檢測:
- 發送端通過以下機制感知:
連續發送3個KeepAlive探測包無響應 根據RTO(Retransmission Timeout)計算重傳超時: math RTO = SRTT + max(G, 4*RTTVAR)3.?應用層表現:
- 出現"Network is unreachable"或"Host unreachable"錯誤
- 數據庫連接池進入連接熔斷狀態
網絡恢復處理:
- 短時斷開(<RTO時間):TCP自動恢復,應用無感知
- 長時斷開:
- 應用需實現重連機制(如指數退避算法)
- 使用TCP持久化特性(RFC 5482)防止路由表過期
2.3對比UDP與TCP
對標UDP和TCP就著重在傳輸的可靠程度與效率進行對比啦~
1. 可靠性
TCP通過確認機制、重傳機制、流量控制和擁塞控制確保數據完整性和順序,適用于對數據完整性要求高的場景(如文件傳輸、郵件收發)
UDP則不提供確認或重傳機制,采用“盡力而為”的交付方式,可靠性較低,但適合實時性要求高的場景(如視頻通話、在線游戲)
2. 高效率
UDP因無連接建立、無確認過程和更小的頭部開銷(僅8字節 vs TCP的20字節)而傳輸效率更高,延遲更低
TCP的連接管理(三次握手/四次揮手)、錯誤檢查和重傳機制增加了開銷,導致傳輸速度較慢。
總結以下~
- 可靠傳輸:TCP更優,適合數據完整性優先的場景。
- 高效率:UDP更優,適合實時性要求高的場景。
3.小結
今天的分享到這里就結束了,喜歡的小伙伴點點贊點點關注,需要之前所有的源代碼可以去我的gitee上就可以啦~你的支持就是對我最大的鼓勵,大家加油!
愛吃烤雞翅的酸菜魚 (crjs-hao) - Gitee.com![]() https://gitee.com/crjs-hao另外最后的最后,歡迎大家加入我的社區哦,初創社區難免經驗不足,請大家多多包涵,也歡迎大家前來多多交流。
https://gitee.com/crjs-hao另外最后的最后,歡迎大家加入我的社區哦,初創社區難免經驗不足,請大家多多包涵,也歡迎大家前來多多交流。
愛吃烤雞翅的酸菜魚社區-CSDN社區云![]() https://bbs.csdn.net/forums/aaa1f71356f6475db42ea9ea09a392bc?spm=1001.2014.3001.6682
https://bbs.csdn.net/forums/aaa1f71356f6475db42ea9ea09a392bc?spm=1001.2014.3001.6682






的作用是什么?)



:Spring Boot + AI + Vue3 + OSS + DashScope 構建多模態視覺理解平臺(附完整源碼))





:gst-rtcp-server安裝和部署實現簡單的rtsp-server服務器推流Demo)


)