記錄一些基本概念,不涉及公式推導,因為數學不好,記了也沒啥用,但是知道一些基本術語以及其中的關系,對神經網絡訓練有很大幫助。
可能有些概念不會講得很詳細,但是當你有了這個概念,你就知道往這個方向去獲取更詳細的信息,不至于連往哪走都不知道。
下面以多元線性回歸模型為例
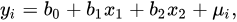
1.模型
模型訓練過程就是利用已知的x和y,求解b的過程,b也稱為權重。
雖然沒有那么簡單,但是訓練完成的模型本質上就是一組權重值,如
[b1, b2,b2......]
所謂保存模型,就是把這一組值保存到文件中,需要用的時候,再從文件中讀取。
正常的模型文件,還會保存訓練中用到的訓練庫信息,優化器信息,損失函數信息等。
2.訓練數據,驗證數據,測試數據。
訓練數據:用于訓練模型的數據。
驗證數據:可以看做訓練數據的一部分,但是不參與模型訓練,其主要作用是用于訓練過程中調整超參數(如學習率、正則化系數)或選擇最佳模型配置,避免過擬合。
驗證數據:用于驗證模型訓練的好壞。
3.參數和超參數
參數:是模型訓練中自動調節的參數,即權重b.
超參數:一般指需要人工手動調節的參數,函數等(但是也可以設置自動調節)。常見的超參數是學習率,損失函數,優化器,網絡層數,節點數等等。
4.損失函數
模型訓練,求解權重,實際上也是求解損失函數的過程。
對于多元線性回歸模型,最常用的損失函數就是最小二乘法。
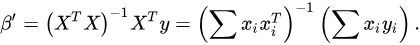
在不同模型訓練時,損失函數有很多種選擇。
損失函數的含義就是找到一組值(權重),使得預測值和實際值之間的距離最小。
當損失函數越小,代表預測值和實際值越接近,
 如何遷移數據庫到新服務器?)



)









:圖像處理基礎)




