數字IC后端低功耗設計實現案例分享(3個power domain,2個voltage domain)
Q1: 電路如下圖,clk是一個很慢的時鐘test_clk(屬于DFT的),DFF1與and 形成一個clock gating check。跑pr 發現,時鐘樹綜合CTS階段(Clock Tree Syntheis)會給and的B pin 和DFF1的CK pin插如很多cdb cell 用來balance ,我實在想不出來有什么好balance的,因為時鐘很慢,setup 是沒有問題的。
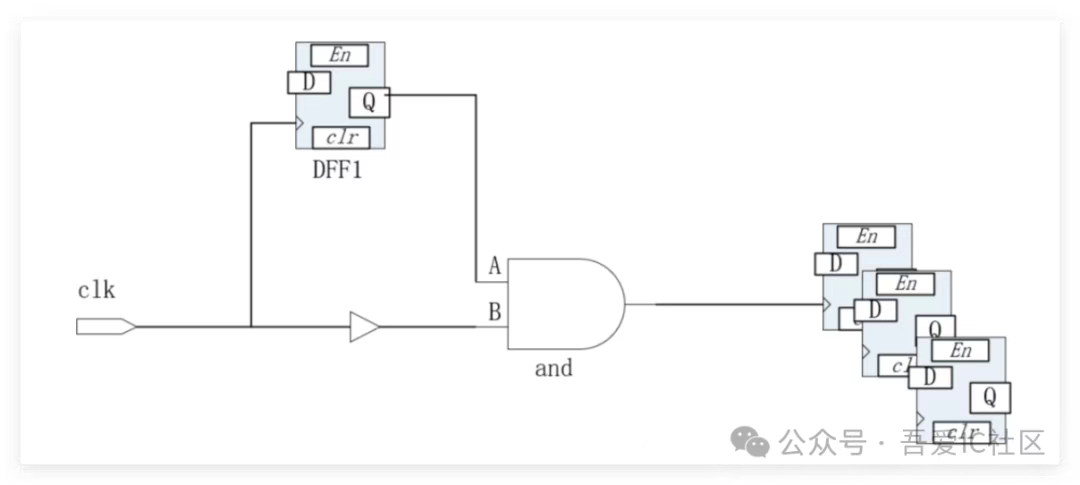
測試1:and 的B pin 設置ignore。結果:and 不插cdb,時鐘latency做短了,但是DFF1的CK 換上插很多cdb。這可以滿足我目前的需求了。
測試2:DFF1的CK pin 設置ignore,我懷疑是DFF1的latency 比較長,于是被迫造成and 被拉長。
結果:DFF1的CK pin確實不插cdb了,但是and 的B 還是插了很多cdb,完全想不明白與誰balance。
問題:innovus 長clock tree 時候,把and 不當做sink 點,不會balance的啊?sink 點應該是DFF和icg啊,為什么這里and的B 插入那么多cdb做balance啊?
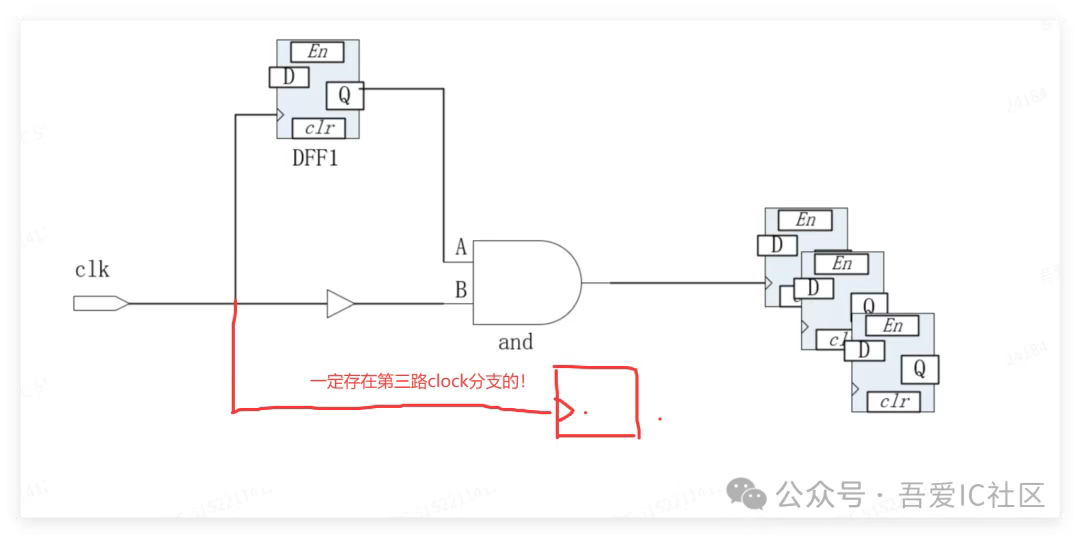
從你的兩種測試結果上看,這個clk一定還有第三路clock分支,如我畫出來的。其實都是被這路clock path balance的。
1)AND與門B pin設置ignore pin,僅僅是與門的B到Y這段timing arc斷了,但是A pin還是會穿過與門再到后面寄存器的。
2)DFF1這顆寄存器的輸出端如果沒有定義任何時鐘,默認情況工具做tree會自動生成clock_gen這樣的skew group。如果不想自己生成這樣的skew group,可以設置如下變量為false。
這個變量設置成false后,clk長時鐘樹只能長到DFF1的CLK pin。但這樣處理后,and輸出到后面寄存器CLK的這段tree就漏做了!
set_ccopt_property extract_clock_generator_skew_groups false
所以建議先把時鐘結構畫完整,否則是不太有利于后續的時鐘樹質量分析。
復雜時鐘設計時鐘樹綜合(clock tree synthesis)常見20個典型案例
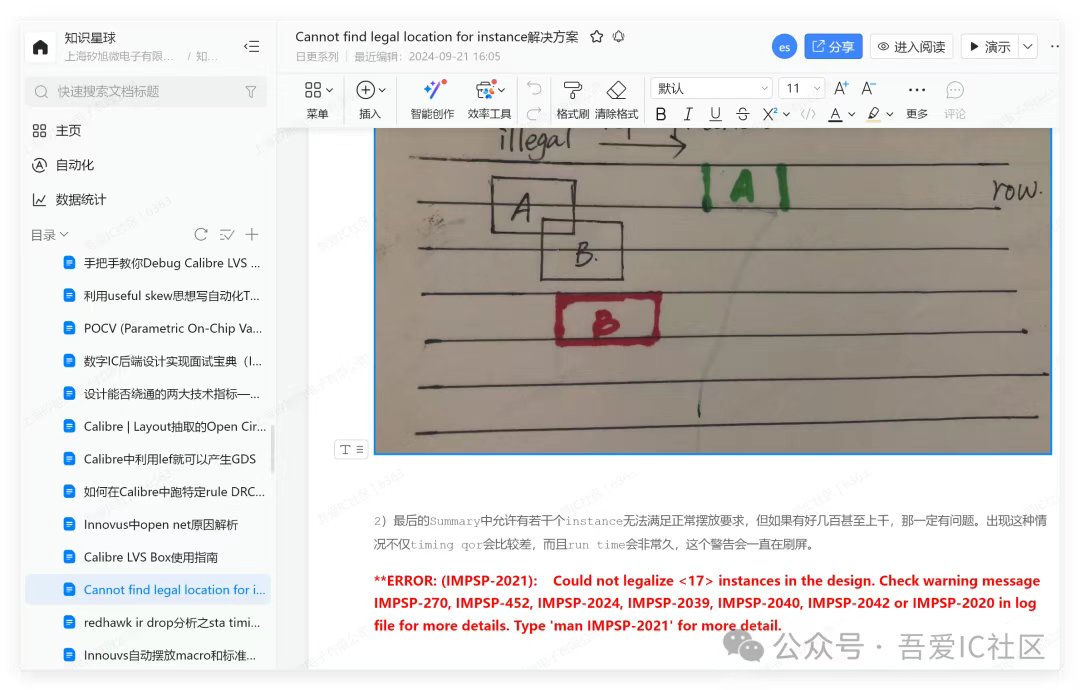
Q2: 請教一個問題,工具提示我找不到legal location 給這兩個spare cell,但是select出來的結果又顯示這里位置非常合理 row 正確、沒有放反、沒有overlap。請問還可能是什么原因呢?


報這個警告僅僅告訴你corase placement后這顆cell在做refinePlace擺放到row時發現在以當前這個點為中心點,半徑為128row高度的范圍內都沒找到合適的位置,即corase placement和refinePlace之間的一致性不太好。但工具仍然會在超出128row高度距離外給這顆cell找到一個位置擺放它的,擺放好后這顆cell肯定也是legal的,不會有overlap啥的。
數字IC后端實現時鐘樹綜合系列教程 | Clock Tree,Clock Skew Group之間的區別和聯系
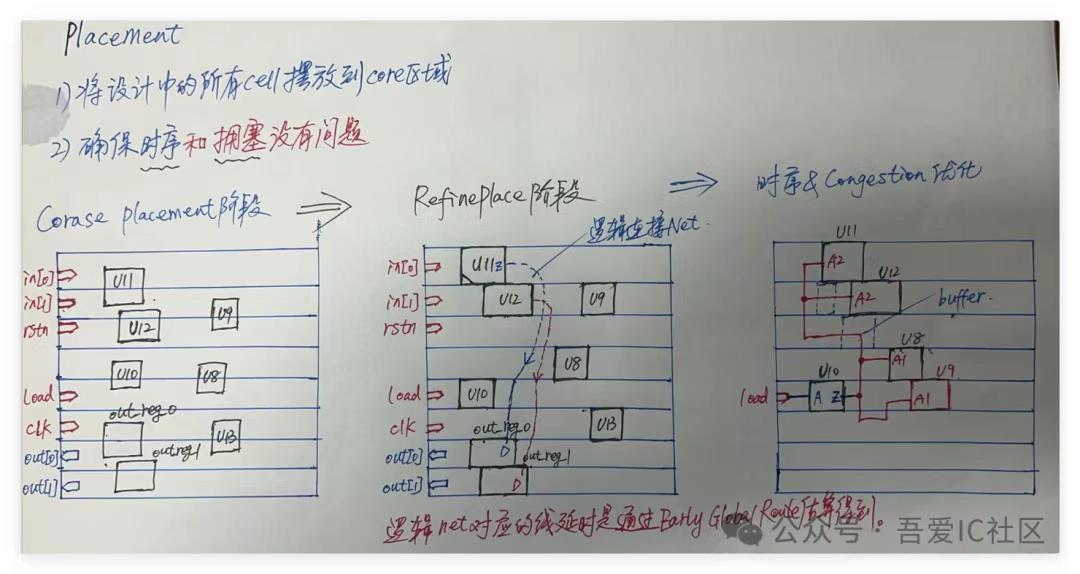
另外建議在PR Flow和Timing ECO階段把spare cell fixed住,不要隨意參與refinePlace過程。
Q3:星主,請問一下,我跑完pr之后,reg2out的最長路徑上插了將近20個buf和inv,這條路徑邏輯只有四層,pr后密度60%,沒有擁塞問題,路徑長度1500左右,并且沒有繞線,這種情況要如何去優化減少reg2out跑pr插入過多的單元?謝謝。
reg2out這個group path的effort設置成low,并且把output delay調整到比較合適的值,使得setup violation不要太大。
你這個路徑上插了20個buffer,我猜測不是工具為了修max transition加入的,因為1500um的距離最多也就是插個幾顆就夠了。所以這里大部分buffer可能是hold buffer。
你看看這些buffer的名字是否帶有PHC的關鍵詞? 這條接口相關的timing path一定要找設計確認是否屬于同步接口?只有同步接口才需要優化時序。
由于Innovus默認會開啟useful skew flow,所以對于接口相關的路徑切記不要開啟useful skew,否則很容易有大量的hold violation。
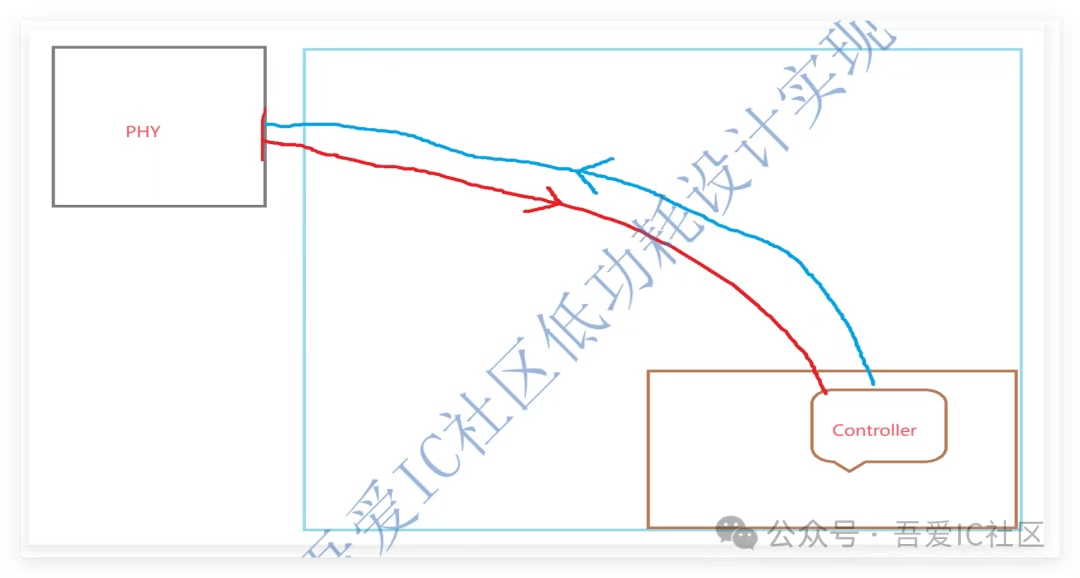
Q4:我的模塊與交接的一個模塊,有高速接口檢查,現在是發現我送給那個模塊的時鐘樹做長了,請問這些路徑我怎么單拎出來做短呢?
根據這些告訴接口去抓對應的寄存器,然后做tree的時候設置一個正值insertion delay。當然對于頻率要求高的,我們還得把這些寄存器擺放到這個接口io port附近。
咱們訓練營項目分享的這個案例跟你的情況類似。我們解決的方法就是把controller擺放至靠近phy,并且把模塊內部controller這部分的clock tree盡量做短。
Q5: 老師,我在挪cell的時候不小心把IP的位置動了,然后發現IP的寬度和之前不一樣了,這里會是什么原因呢?
這是一個非常典型的EDA工具bug,容易出現在Innovus 2018,2019版本中。
小編在7年前就遇到過這個bug,當時花了很多時間來debug解決掉的。
做過咱們社區IC后端訓練營項目的同學都知道,我們在將PrimeTime DMSA返回來的timing eco腳本讀入innovus前,會開啟batchMode,這個模式可以批量處理腳本命令(ecoAddRepeater和ecoChangeCell)。
如果不開啟這個batchMode,EDA工具每執行一條命令就需要做一次refinePlace,做一次RC抽取,報告一次時序!
setEcoMode -batchMode true -updateTiming false -refinePlace false
而且我們直播課也強調過這個batchMode模式僅局限于執行插buffer,換cell驅動的場景,其他情況必須把這個batchMode關閉即設置成false,否則就容易出現這個同學遇到的問題。
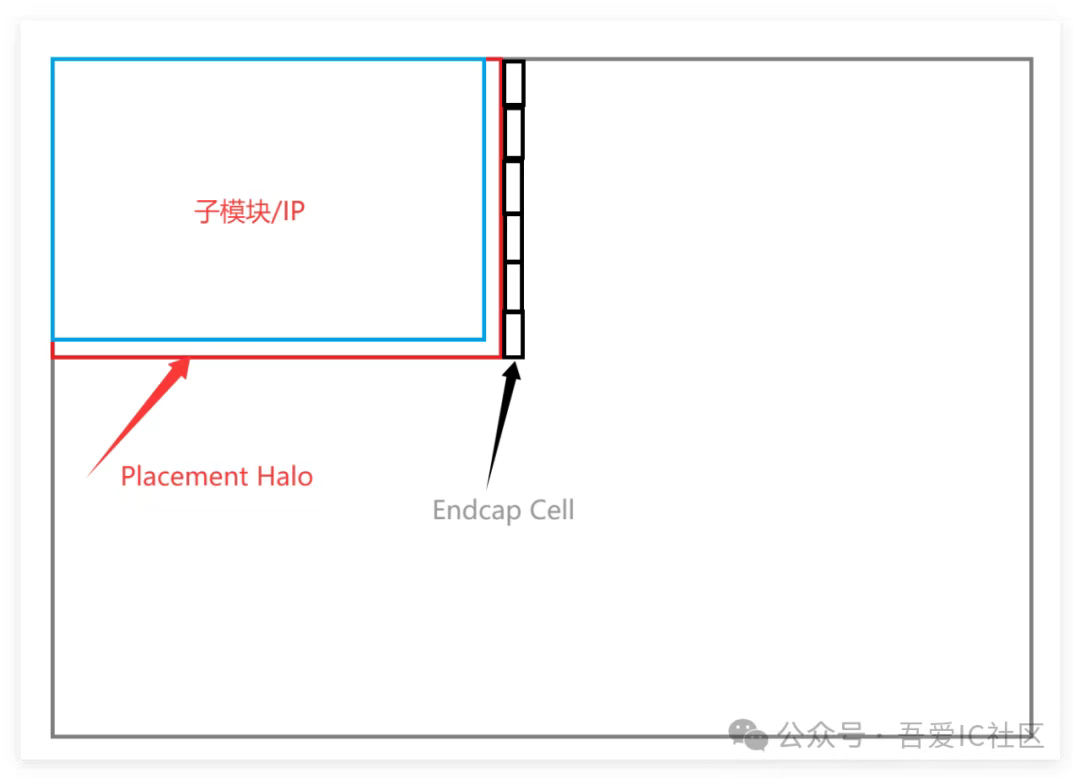
下圖所示為做Timing ECO之前的子模塊和頂層的部分示意圖。此時子模塊/IP的大小還是正常的,邊上也包圍著2um左右的placement halo,halo邊上也加好了endcap cell(Boundary cell)。
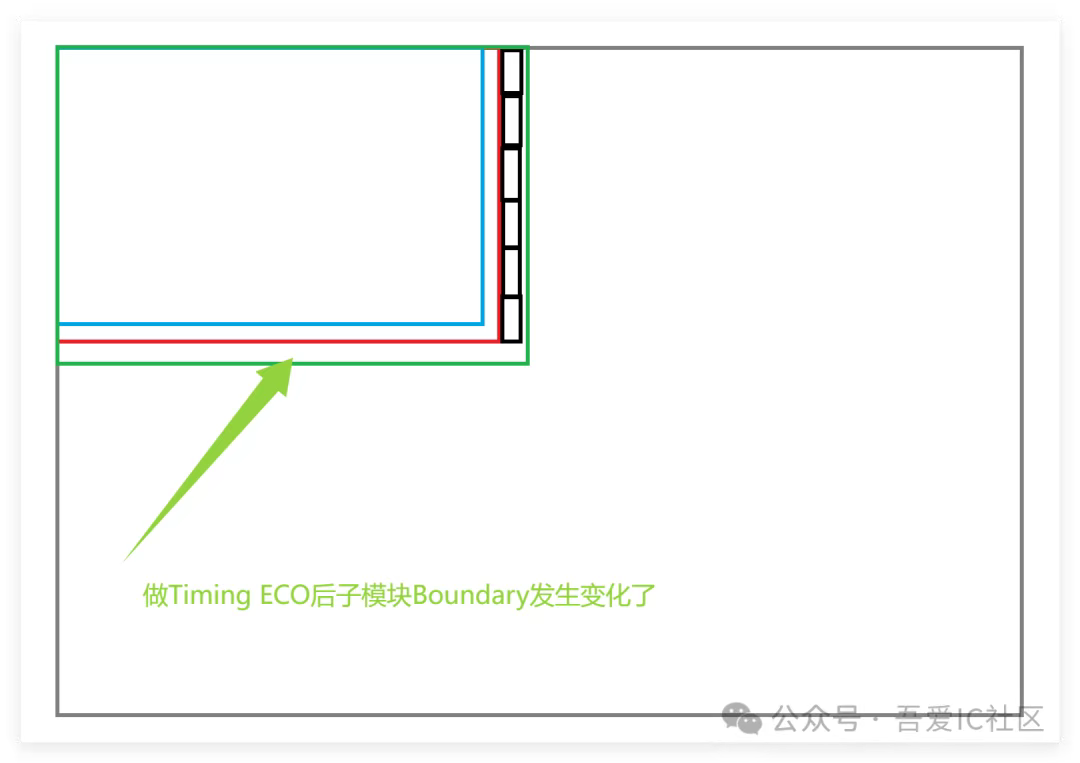
但是當這位同學做完Timing ECO后發現子模塊/IP已經和現有的標準單元,endcap cell overlap了!第一次遇到這種情況肯定就不淡定了,不知道的還真以為自己挪過這個子模塊/IP了。
而且牛逼的地方是當你想把這個子模塊/IP調整恢復到原來位置的時候,發現回不去了,怎么調整都無法回到過去了。原因是EDA工具已經把這個子模塊/IP的lef改了!
因此,batchMode開啟要慎重。執行ecoAddRepeater和ecoChangeCell后必須執行下面的命令。
setEcoMode -reset
Q6:請教星主和各位前輩,現在我有一個多power domain的設計。TOP下有模塊A,A的子模塊為B,B的子模塊為C,C中包含一些memory。對于這種設計來說,在floorplan的時候,PD之間有沒有比較建議的規劃方式?
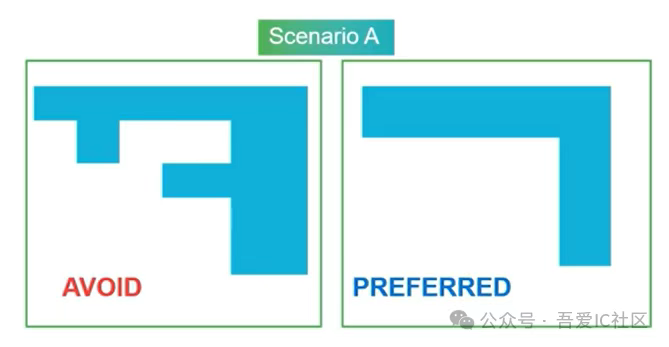
Case1: Power Domain形狀盡量規則
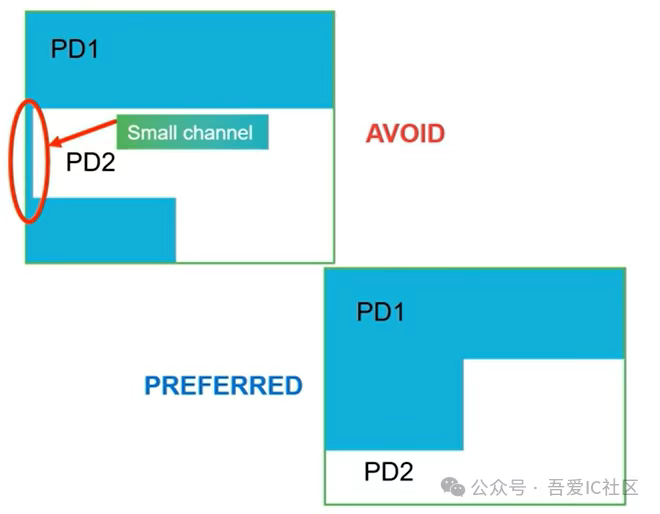
通常情況power domain的形狀(子模塊單獨harden模塊)要盡量規則,特別是timing和routing都不太好做的設計。下圖左側存在大量拐角及窄channel都是一個不好floorplan的表現。右側所示的模塊切分相對更好,但這種L型的形狀在模塊直角轉彎處也非常容易有timing和routing問題。
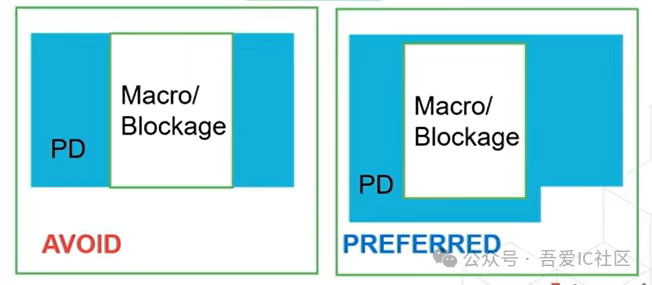
Case2: 避免Macro或Blockage放置在Power Domain中間區域
這個就是我們一直提倡的擺放Macro的方法或原則——Macro盡量擺放在模塊或Power Domain的邊界處。所以在做模塊或Power Domain切分時需要考慮好內部Macro的情況,特別是那種寬度或高度個別大的Macro。
Case3: 避免thin channel的PD
Case4: Power Domain邊界處盡量不要擺放Default PD的Memory
當PD1接口信號要往左下角出來和Default PD進行交互時,PD1邊界處的Macro會擋住標準單元的擺放和阻擋接口信號線的routing。
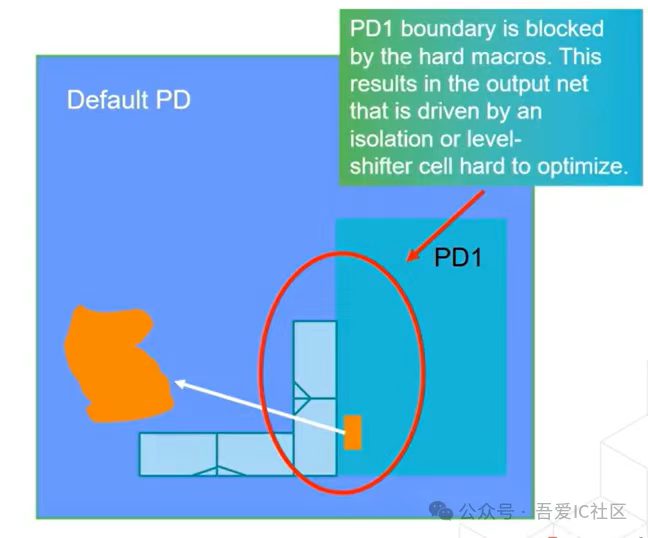
而且我們知道PD1接口出來的信號還需要插isolation cell,如果這類isolation cell被擺放至圖中的黃色區域,肯定會有max transition violation。不巧的是這類信號對應的net還必須設置dont touch。
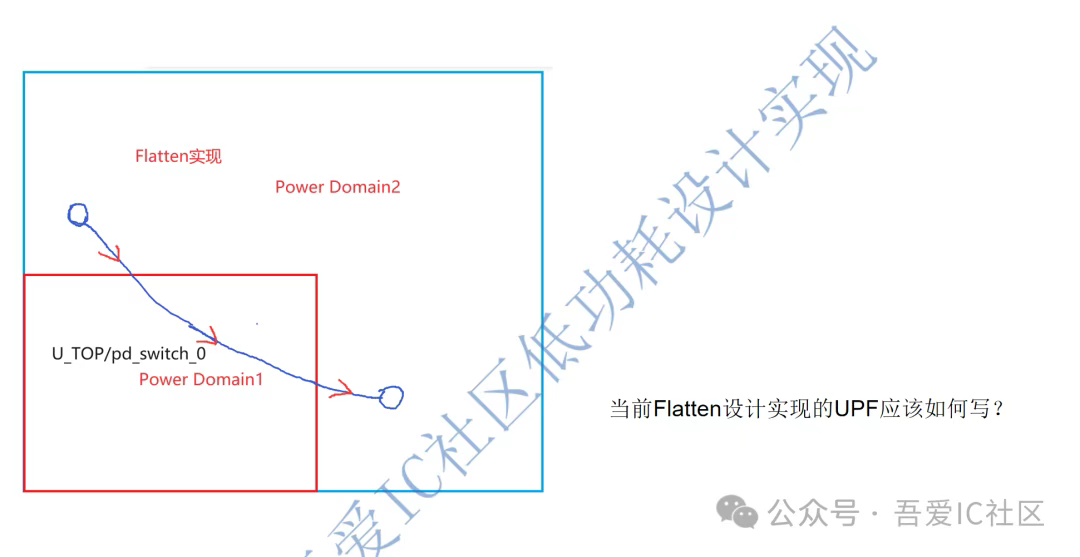
【思考題】下圖所示一個低功耗設計實現案例。我們在PR實現時應該如何避免這類timing path在PD1中插buffer? 如何避免工具把這類相關net的routing跨在PD1上?
)


)

)

)






)




——3DRPG游戲(2))