文章目錄
- InstructBLIP:邁向通用視覺語言模型的指令微調研究總結
- 一、研究背景與目標
- 二、核心方法
- 數據構建與劃分
- 模型架構
- 訓練策略
- 三、實驗結果
- 零樣本性能
- 消融實驗
- 下游任務微調
- 定性分析
- 可視化結果展示
- 四、結論與貢獻
InstructBLIP:邁向通用視覺語言模型的指令微調研究總結
論文題目:InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning
論文鏈接:https://arxiv.org/pdf/2305.06500
一、研究背景與目標
-
挑戰
視覺-語言任務因視覺輸入的多樣性和任務復雜性,難以通過單一模型實現通用化。現有方法中,多任務學習缺乏指令引導導致泛化能力弱,基于圖像描述數據訓練的視覺組件難以支撐復雜任務。 -
目標
提出 InstructBLIP 框架,通過視覺-語言指令微調,使模型能通過統一自然語言接口解決多種視覺-語言任務,實現零樣本泛化和下游任務微調的最優性能。
二、核心方法
數據構建與劃分
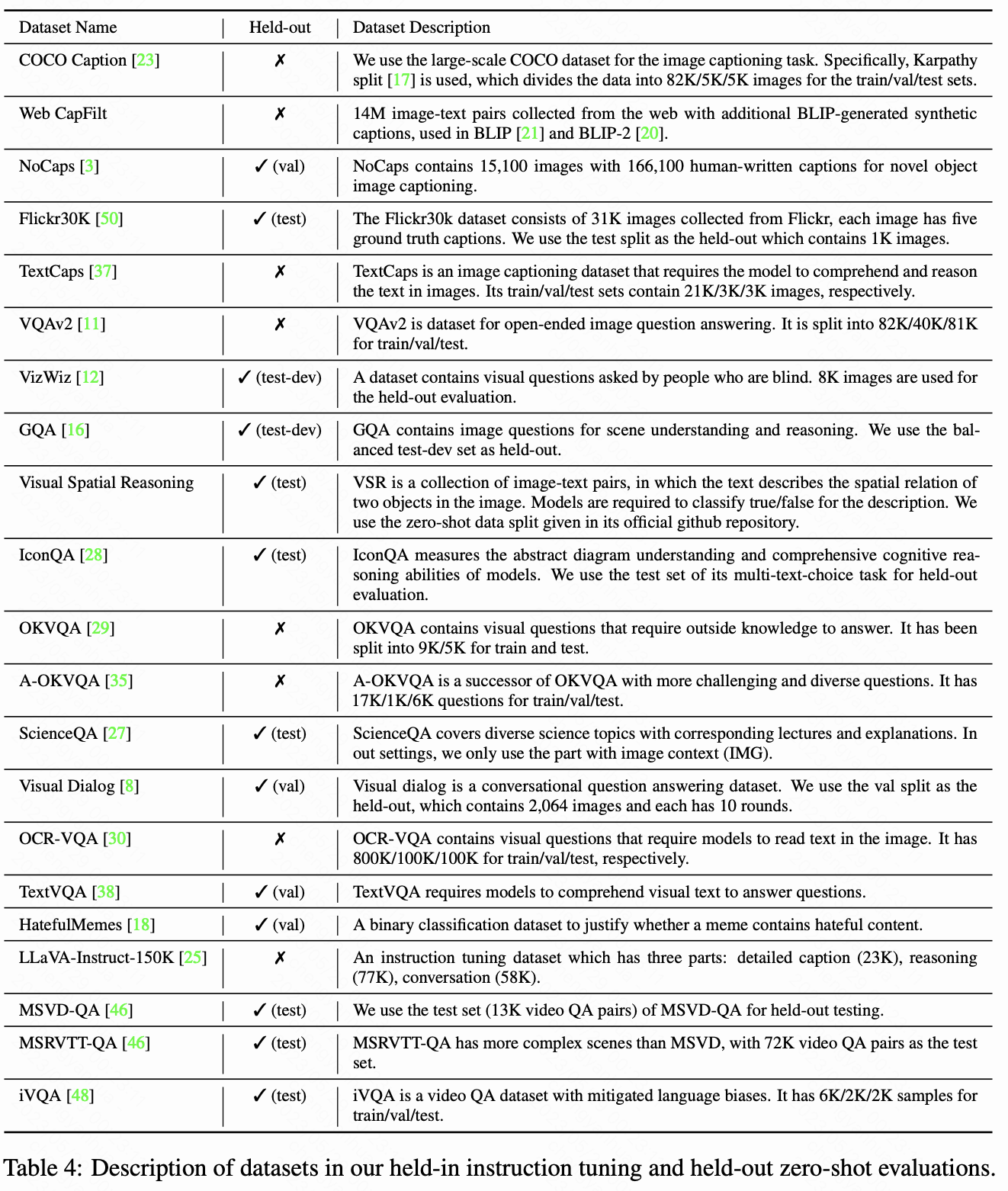
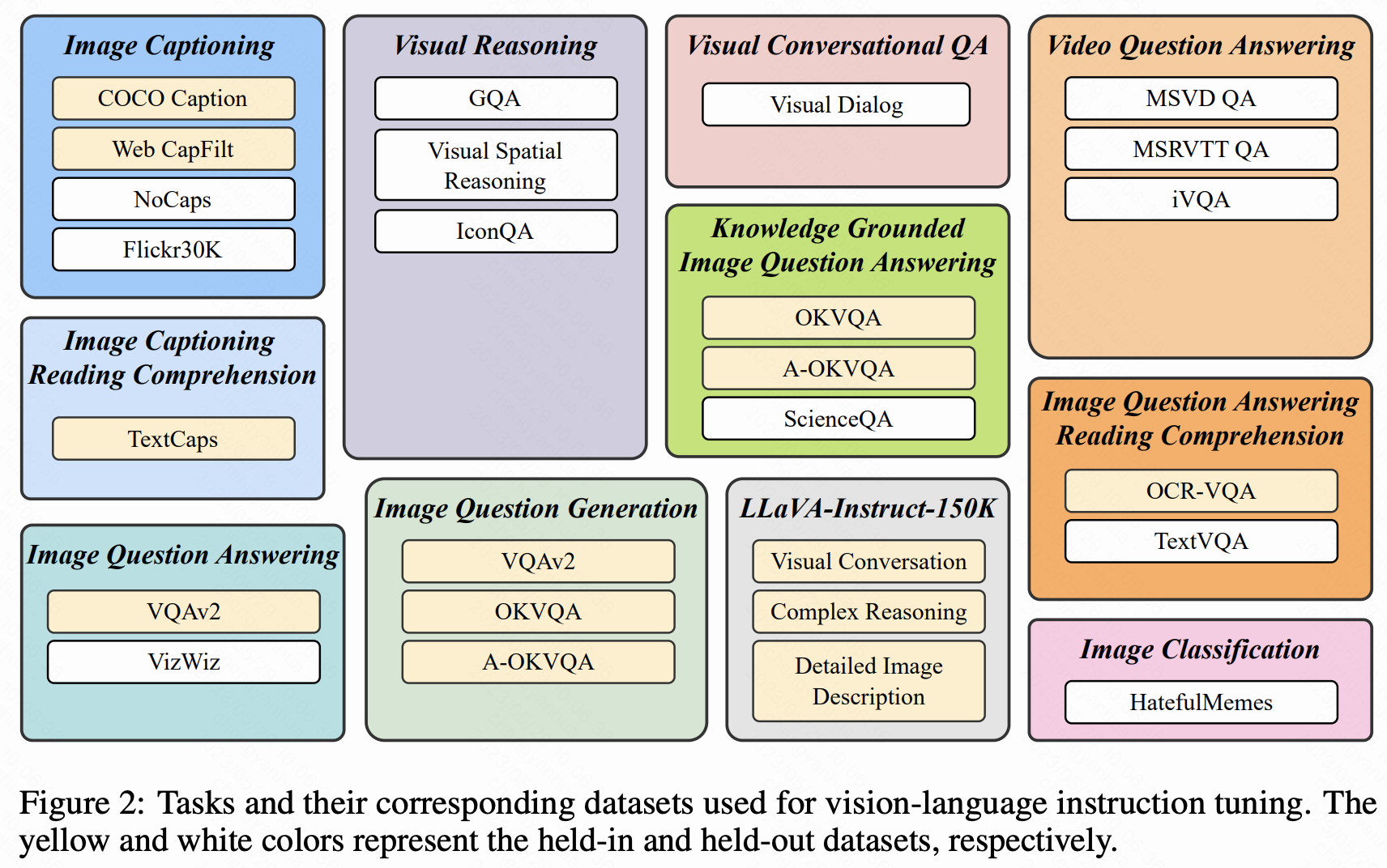
- 收集 26 個公開數據集,轉化為指令微調格式,涵蓋 11 類任務(如圖像 captioning、視覺推理、視頻問答等)。
- 劃分 13 個數據集為訓練集(held-in),13 個為零樣本評估集(held-out),并保留 4 類任務(如視頻 QA、視覺對話)用于任務級零樣本測試。
指令數據:

模型架構
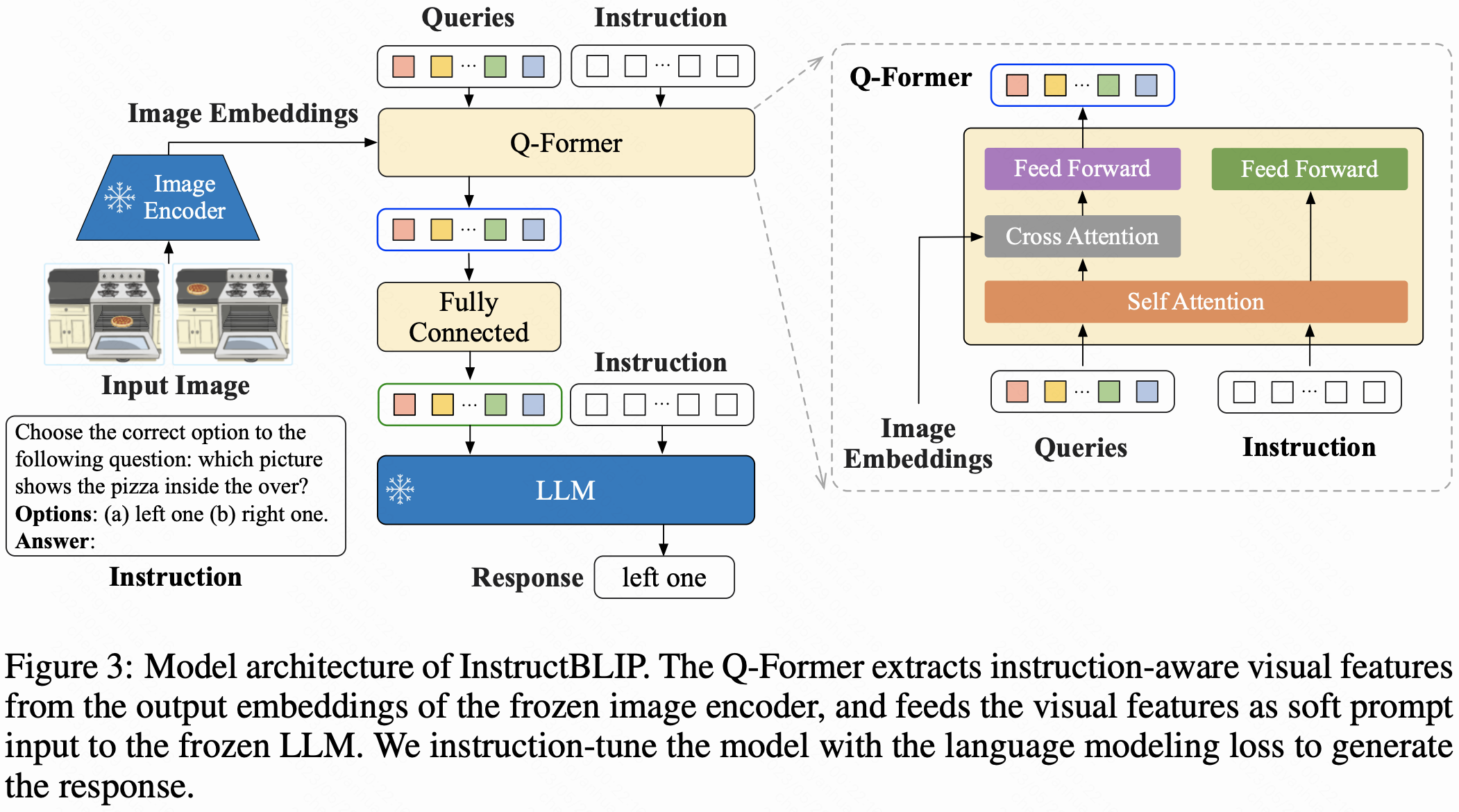
- 基于 BLIP-2 的模塊化設計,包含凍結的圖像編碼器、LLM(如 FlanT5、Vicuna)和可微調的 Query Transformer(Q-Former)。
- 創新點:引入指令感知的視覺特征提取,將文本指令輸入 Q-Former,使其提取與指令相關的視覺特征,增強任務適配性。
訓練策略
- 平衡采樣:按數據集大小的平方根比例采樣,避免小數據集過擬合、大數據集欠擬合,并手動調整特定數據集權重(如降低 A-OKVQA、提高 OKVQA 權重)。
pd=Sd∑i=1DSip_d = \frac{\sqrt{S_d}}{\sum_{i=1}^{D} \sqrt{S_i}} pd?=∑i=1D?Si??Sd??? - 微調僅更新 Q-Former,凍結圖像編碼器和 LLM,減少訓練參數,提升效率。
三、實驗結果
零樣本性能
- 在 13 個 held-out 數據集上全面超越 BLIP-2 和 Flamingo,例如 InstructBLIP FlanT5 XL 相對 BLIP-2 平均提升 15.0%,4B 參數模型性能超過 80B 參數的 Flamingo,平均提升 24.8%。
- 在未訓練過的任務(如視頻 QA)上表現優異,MSRVTT-QA 相對最優結果提升 47.1%。
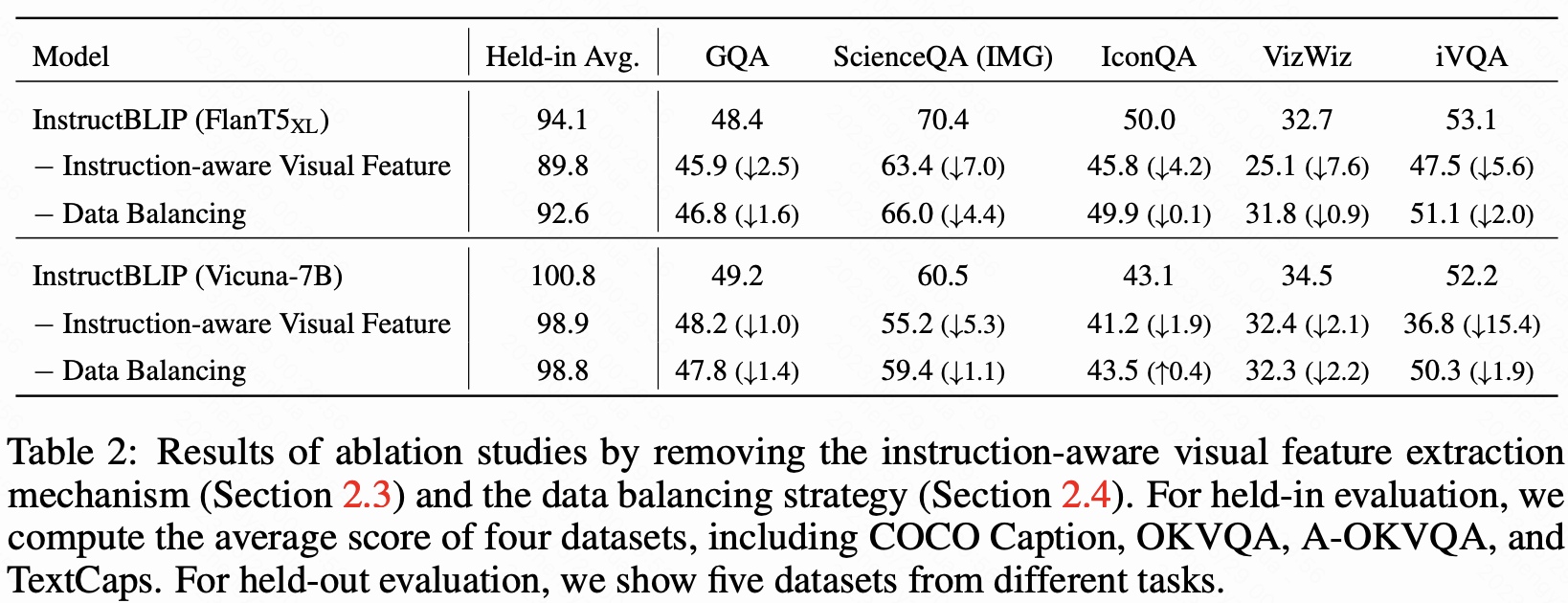
消融實驗
- 移除指令感知特征提取后,空間 / 時間推理任務(如 ScienceQA、iVQA)性能顯著下降(最多降低 7.6%)。
- 移除平衡采樣導致訓練不穩定,整體性能下降。
下游任務微調
- 作為初始化模型,在 ScienceQA(圖像上下文)、OCR-VQA 等任務上刷新 SOTA,例如 ScienceQA 準確率達 90.7%。
- 凍結視覺編碼器,訓練參數從 1.2B 減至 188M,大幅提升微調效率。
定性分析
- 展現復雜視覺推理(如從場景推斷災害類型)、知識關聯(如識別名畫并介紹)、多輪對話等能力,響應更貼合指令意圖,細節更準確。
可視化結果展示

四、結論與貢獻
-
核心貢獻:
- 系統研究視覺-語言指令微調,驗證其對零樣本泛化的有效性。
- 提出指令感知特征提取和平衡采樣策略,提升模型適應性和訓練穩定性。
- 開源基于 FlanT5 和 Vicuna 的 InstructBLIP 模型,為通用多模態 AI 研究提供基礎。
-
優勢:兼顧零樣本泛化能力和下游任務微調效率,在多樣化視覺-語言任務中表現出通用性和優越性。




——3DRPG游戲(2))

)






(上))





