上篇文章【[論文品鑒] DeepSeek V3 最新論文 之 DeepEP】 介紹了分布式并行策略中的EP,簡單的提到了其他幾種并行策略,但礙于精力和篇幅限制決定將內容分幾期,本期首先介紹DP,但并不是因為DP簡單,相反DP的水也很深,例如:“DP到底同步的是什么數據?怎么同步的?“,“AllReduce/Ring-AllReduce是什么?”,“ZeRO1、2、3又都是什么?” 等各種問題,會結合PyTorch代碼,盡量做到詳細由淺入深。
單機單卡
在深入分布式并行策略前,先回顧一下單機單卡的訓練模式:

CPU加載數據,并將數據分成batch批次CPU將batch批次數據傳給GPUGPU進行前向傳播計算得到lossGPU再通過反向傳播通過loss得到梯度GPU再通過梯度更新參數
偽代碼:
model = Model(xx) # 1. 模型初始化
optmizer = Optimizer(xx) # 2. 優化器初始化
output = model(input) # 3. 模型計算
loss = loss_function(output, target) # 4. loss計算
loss.backward() # 5. 反向傳播計算梯度
optimizer.step() # 6. 優化器更新參數
DP
就像 多線程編程 一樣,可以通過引入 多個GPU 來提高訓練效率,這就引出了最基礎的 單機多卡 DP,即 Data Parallel 數據并行。

CPU加載數據,并將數據拆分,分給不同的GPUGPU0將模型復制到 其他所有GPU- 每塊
GPU獨立的進行前向傳播和反向傳播得到梯度 - 其余所有
GPU把梯度傳給GPU0 GPU0匯總全部梯度進行全局平均計算GPU0通過全局平均的梯度更新自己的模型GPU0再把最新的模型同步到其他GPU
DP的PyTorch偽代碼,相比于單機單卡,大部分都沒有變化,只是把模型換了DataParallel模型,在PyTorch中通過nn.DataParallel(module, device_ids) 實現:
model = Model(xx) # 1. 模型初始化(沒變化)
model_new = torch.nn.DataParallel(model, device_ids=[0,1,2]) # 1.1 啟用DP (新增)
optmizer = Optimizer(xx) # 2. 優化器初始化(不變)
output = model_new(input) # 3. 模型計算,替換使用DP(變更)
loss = loss_function(output, target) # 4. loss計算(不變)
loss.backward() # 5. 反向傳播計算梯度(不變)
optimizer.step() # 6. 優化器更新參數 (不變)
可見DP使用上非常簡單,通過nn.DataParallel套上之前的模型即可。
但是DP存在 2個 比較嚴重的問題:
- 數據傳輸量較大:不考慮
CPU將input數據拆分傳輸給每塊GPU,單獨看GPU間的數據傳遞;對于GPU0它需要把整個模型的參數廣播到其他所有GPU,假設有 N N N塊GPU,那么就需要傳輸 ( N ? 1 ) ? w (N-1)*w (N?1)?w參數,同時GPU0也需要從其他所有GPU上Reduce所有梯度,那么就要傳輸 ( N ? 1 ) ? g (N-1)*g (N?1)?g,所以對于GPU0來說要傳輸 ( N ? 1 ) ? ( w + g ) (N-1)*(w +g) (N?1)?(w+g)的數據,同理對于其他GPU來說,要傳輸與來自GPU0的參數,與傳出自己那份梯度。所以整體上個說,GPU數量多 N N N越大,傳輸的數據量就越多。 GPU0的壓力太大:它要收集梯度、更新參數、同步參數,計算和通信壓力都很大
接下來看一下更高級用法 DDP
DDP
DDP 即 Distributed Data Parallel,多機多卡的分布式數據并行。

與 DP 最主要的區別就是,解決了 DP 的 主節點瓶頸,實現了真正的 分布式通信。
而精髓就是 Ring-AllReduce,下面介紹它是如何實現 梯度累計 的:
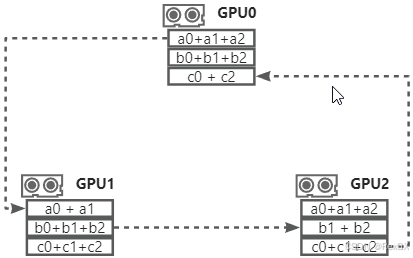
- 假設梯度目前都是單獨存在于不同GPU上,而目標是將三個GPU的梯度進行累計,也就是得到下圖中三個梯度的和,
a0+a1+a2與b0+b1+b2和c0+c1+c2

- 首先第一階段:
GPU0將a0發送給GPU1去求和a0+a1,GPU1將b1發送給GPU2去求和b1+b2,GPU2將c2發送給GPU0去求和c0+c2

- 然后,繼續累加,將
GPU0上的c0+c2發送給GPU1去求c0+c1+c2,GPU1將a0+a1發送給GPU2去求a0+a1+a2,將GPU2將b1+b2發送給GPU0去求b0+b1+b2

- 此時第一階段完成,通過
Scatter-Reduce將參數分發后集合,分別得到了各個參數梯度累計結果

- 之后的第二節階段,通過
All-Gather將各個參數的梯度進行傳播,使得每個GPU上都得到了完整的梯度結果 - 首先,
GPU0將完整的b0+b1+b2傳遞給GPU1,同理GPU1和GPU2也傳遞完整的梯度

- 最后,再將剩余的梯度進行傳遞
- 最終每個設備得到了所有參數的完整梯度累計

在 DDP 的Ring-AllReduce 中還有一個細節:如果每個參數都這么Ring著進行信息梯度累計,那么通信壓力太大了;
所以設計了桶,通過將參數分桶聚合,也就是一個桶中維護了多個參數,當整個桶中的所有梯度都計算完畢后,再以桶維度進行Ring的梯度累計,這樣降低了通信壓力,提高了訓練效率。
DDP的落地,相較于DP會復雜很多,首先簡單理解幾個概念:
world:代表著DDP集群中的那些卡的rank:world中,每張卡的唯一標識nccl、gloo:都是通信庫,也就是那些分布式原語的實現,現在普遍都用老黃家的NCCL,搭配RMDA食用效率更高
接下來看一下DDP的PyTorch偽代碼:
# 首先需要在每張卡,也就是進程單位設置一下,可以理解為在“組網” (新增)
import torch
import torch.distributed as dist
dist.init_process_group(backend = "nccl", # 使用NCCL通信rank = xx, # 這張卡的標識world_size = xx # 所有卡的數量
)
torch.cuda.set_device(rank) # 綁定這個進程的GPU# 然后是模型定義(變化)
model = Model(xx).cuda(rank)
model_ddp = nn.parallel.DistributedDataParallel(mode, device_ids=[rank]) # 相較于DP,這里用DDP來包裝模型# 優化器(沒變)
optimizer = Optimizer(xx)# 分布式數據加載(新增)
train_sampler = torch.utils.data.distributed.DsitributedSampler(dataset,num_replicas = world_size,rank = rank
)
dataloader = DataLoader(dataset,batch_size = per_gpu_batch_size,sampler = train_sampler
)# 訓練(不變)
output = model_ddp(input)
loss = loss_function(output, target)
loss.backward()
optimizer.step()# 訓練后結束"組網"
dist.destroy_process_group()# 使用torchrun啟動DDP
torchrun train.py # torchrun是pytorch官方DDP的最佳實踐,就別用其他的了
FSDP
不論是DP還是DDP的數據并行,都有一個核心問題:模型在每個GPU上都存儲一份,如果模型特別大,單卡顯存不足的話就無法訓練。
這就引入了 FSDP(fully sharded data parallel)核心思想是:把模型的參數、梯度、優化器狀態 分片存儲,顯著降低顯存占用。
分片機制:
- 參數分片:把模型的參數切分到所有GPU上,每個GPU僅存儲部分參數
- 前向傳播:通過
AllGather收集完整參數 -> 計算 -> 丟棄 非本地分片(不在顯存中存儲,僅僅是計算用) - 反向傳播:通過
AllGather收集參數 -> 計算梯度 -> 再通過reduce-scatter同步梯度分片 - 優化器狀態:每個GPU僅維護與其參數分片對應的優化器狀態
但這時候就會有疑問了:把模型分片存儲,這還算DP嗎,這不成了MP么?
確實,FSDP融合DP和MP兩種思想,但核心仍然是DP,因為它仍然是在 數據維度 進行并行(不同GPU處理不同數據),并且每個GPU都獨立的完整前向+反向傳播;這是用DP的思想,去解決DP單卡顯存瓶頸的問題。
“FSDP is DP with model sharding, not MP. It extends DP beyond single-device memory limits.”
—— PyTorch Distributed Team, Meta AI
下面展示FSDP的FULLY_SHARD策略,也就是對標ZeRO-3的訓練流程:
- 通過
FULLY_SHARD策略,將參數、梯度、優化器狀態進行了分片

- 在
前向傳播中,由于每個GPU都只有部分參數,所以當走到缺失那部分參數的時候,依賴其他GPU將參數傳進來,執行完畢后就丟棄;通過這種方式,使得即使每個GPU只保存部分參數,但依然可以完成整個前向傳播

- 當得到output開始計算
梯度時,每個GPU完整自己那部分的梯度計算,在此過程中如果本地沒有相對應的參數,也依然需要從其他GPU傳過來;當完成梯度計算后,再把梯度發送給負責更新這部分參數的優化器分片的GPU,由它進行本地參數更新;這樣就完成了一次前向+反向傳播

再來看看FSDP的PyTorch偽代碼:
# “組網”,也就是設置分布式環境方式和DDP沒有區別(不變)
import torch.distributed as dist
from torch.distrbuted.fsdp import FullyShardDataParallel as FSDP
def setup(rank, world_size): dis.init_process_group("nccl", rank=rank, world_size=world_size)torch.cuda.set_device(rank)# 使用FSDP包裝模型,同時設置分片策略(新增)
from torch.distributed.fsdp.wrap import size_based_auto_wrap_policy
model = Model(xx)
model_fsdp = FSDP(mode, auto_wrap_policy=size_based_auto_wrap_policy, # 按層大小自動分片mixed_precision=True, # 啟用混合精度device_id=rank,sharding_strategy=torch.distributed.ShardingStrategy.FULLY_SHARD # 相當于ZeRO-3
)# 數據加載和分布式采樣,和DDP沒有區別(不變)
from torch.utils.data.distributed import DistributedSampler
dataset = datasets(xx)
sampler = DistributedSampler(dataset, num_replicas=world_size, rank=rank)
dataloader == torch.utils.data.DataLoader(datase4t, batch_size=64, sampler=sampler)# 訓練和DP、DDP沒有區別(不變)
for epoch in range(epochs):sampler.set_epoch(epoch)for batch in dataloader:data, target = batck[0].to(rank), batch[1].to(rank) # H2Doptimizer.zero_grad()output = model_fsdp(mode) # 使用fsdp包裝的model進行前向傳播loss = loss(output, target)loss.backward()optimizer.step()
ZeRO1/2/3
ZeRO 是微軟家 DeepSpeed 中的核心技術,思想和 FSDP 是相同,二者都是 通過分片消除模型冗余存儲,擴大分布式并行訓練能力,只不過 FSDP 是 PyTorch 的官方實現版。
ZeRO(Zero Redundancy Optimizer)有三種策略:
ZeRO-1:只分片 優化器狀態ZeRO-2:分片 梯度 和 優化器狀態 ,對應了FSDP的SHARD_GRAD_OP策略ZeRO-3:分片 參數、梯度 和 優化器狀態,對應了FSDP的FULLY_SHARD策略
雖然 ZeRO 因為深度集成在 DeepSpeed 中,還可以利用上 DeepSpeed 的其他特性,但從生態偏好上講,個人更推薦使用 PyTorch官方的 FSDP。

-題目:わたしの友達)
)






醫院信息系統,讓醫療數據互聯互通)





)



