 本作品采用知識共享署名-非商業性使用-相同方式共享 4.0 國際許可協議進行許可。
本作品采用知識共享署名-非商業性使用-相同方式共享 4.0 國際許可協議進行許可。
本作品 (李兆龍 博文, 由 李兆龍 創作),由 李兆龍 確認,轉載請注明版權。
文章目錄
- 引言
- Compaction Algorithms
- Compact Execution Flow Based On Velox
- LocalMergeSource的管道分離流式讀取
- 基于LoserTree的歸并排序
- Window算子實現流式計算
- TableWrite的多路流式寫入
- 結束語
引言
時序數據庫與關系型數據庫一個比較大的功能差異為Deduplicate,時序數據庫默認攜帶,而關系型數據庫依賴于索引和查詢時主動去重。
以Influxdb舉例子闡述Deduplicate功能:
INSERT temperature,device_id=sensor1 v1=25,v2=25 1620000000000000000
INSERT temperature,device_id=sensor1 v1=26 1620000000000000000
一般有兩種Deduplicate粒度
第一種為Field-Level Updates,上述數據會被合并為:
INSERT temperature,device_id=sensor1 v1=26,v2=25 1620000000000000000
其選擇策略為tag+time相同的情況下,相同field的選擇lsn大的,field取最后一個非空的
第二種為Row-Level Deduplication,上述數據會被合并為:
INSERT temperature,device_id=sensor1 v1=26 1620000000000000000
單純的基于lsn行選擇。
Compaction Algorithms
首先定義 Amplification:
- Write Amplification: 指寫入存儲設備的數據量與寫入數據庫的數據量的比率。例如向數據庫寫入 10 MB 數據,而觀察到的磁盤寫入為 30 MB,則寫入放大率為 3。基于SSD的存儲只能寫入有限次數,因此寫入放大會縮短SSD的使用壽命。
- Read Amplification:指每個查詢的磁盤讀取次數。例如如果需要讀取 5 頁來響應查詢,則讀取放大為 5。寫入放大和讀取放大的單位不同。寫入放大衡量實際寫入的數據量比應用程序認為的寫入量多,而讀取放大則指計算執行查詢所需的磁盤讀取次數比認為的多。
- Space Amplification:指磁盤上實際存儲的物理數據量相對于用戶數據的邏輯大小的放大倍數
名詞定義:
- T:層之間的大小比值
- L:LSM樹的層數
- B:SST文件大小

時序數據庫中為了提高查詢的效率,數據需要基于時間分shard,這種情況下全局看基本可以認為都是TWCS(Time Window Compaction Strategy)策略,因為老舊shard在經歷FullCompact后有且只有一個Sort Runs,在活躍shard中基于不同的考量會有不同的實現方式。
在influxdb1.x中使用了Tiered,多層內均無序,Compact是在每一層選擇可壓縮的文件,CompactScheduler調度執行。
在GrepTimeDB中使用N-Level,只有兩層,內部允許N個Sort Runs,在讀寫放大之間做權衡
在influxdb3.0中使用了Tiered+Leveled,L0無序,剩下的層數有序,Rocksdb的默認Compact策略也是這樣的。
但是值得一提的是時序數據庫的Timestamp是去重的主鍵列,不能簡單的依賴時間去重,因為兩次寫入的時間也可能是重復的,合并的關鍵在于真實時間上后來的需要覆蓋前面的,從實現上來講一致性引擎的LSN就很合適。
但是這為Compaction的算法實現帶來了一點復雜度,如果不按照LSN順序進行合并,會導致字段覆蓋邏輯錯誤,破壞數據一致性。舉以下例子:

錯誤的合并順序:
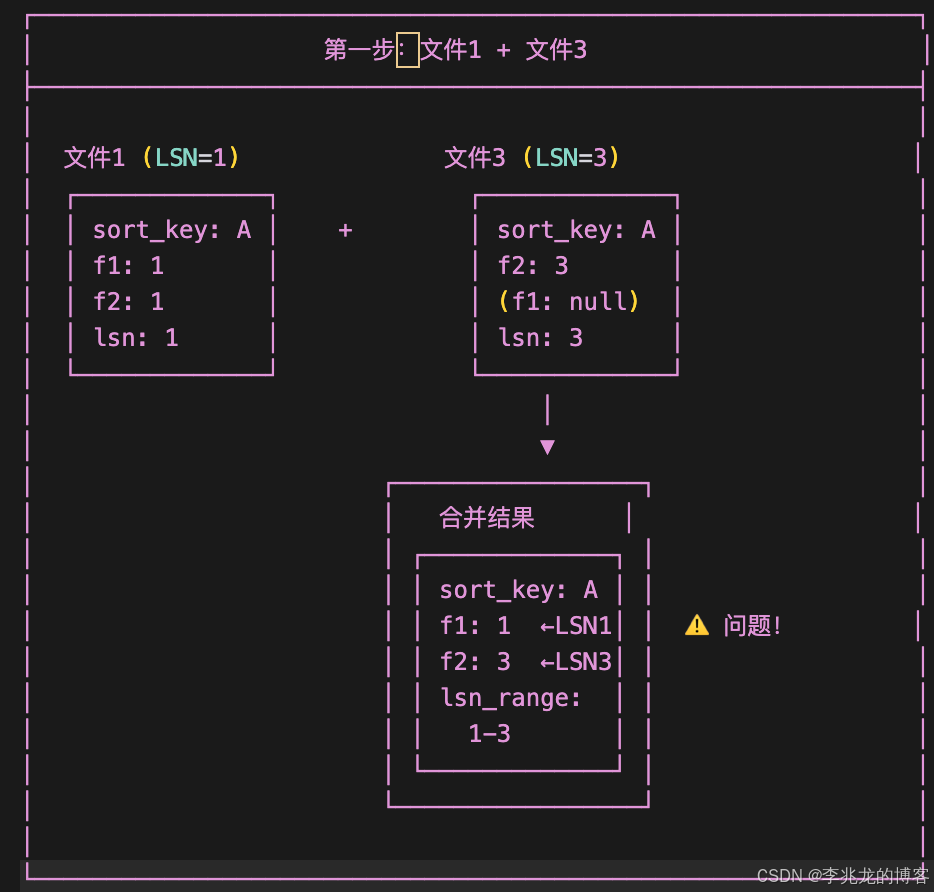
f1字段來自LSN=1的文件;f2字段來自LSN=3的文件。形成了LSN差值為1-3的混合記錄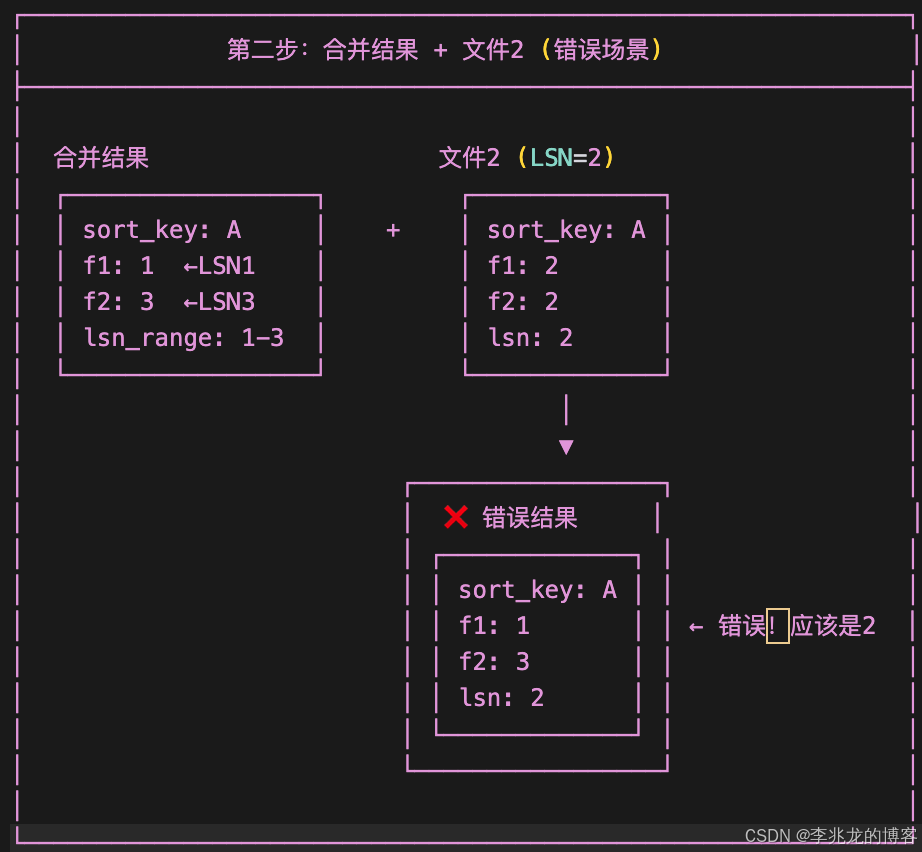
由于合并結果中f1和f2的LSN分別為1和3,都不等于文件2的LSN=2, 按照LSN覆蓋規則,LSN=2無法覆蓋LSN=3的f2字段, 但LSN=2應該覆蓋LSN=1的f1字段,導致邏輯混亂。
正確的合并順序如下: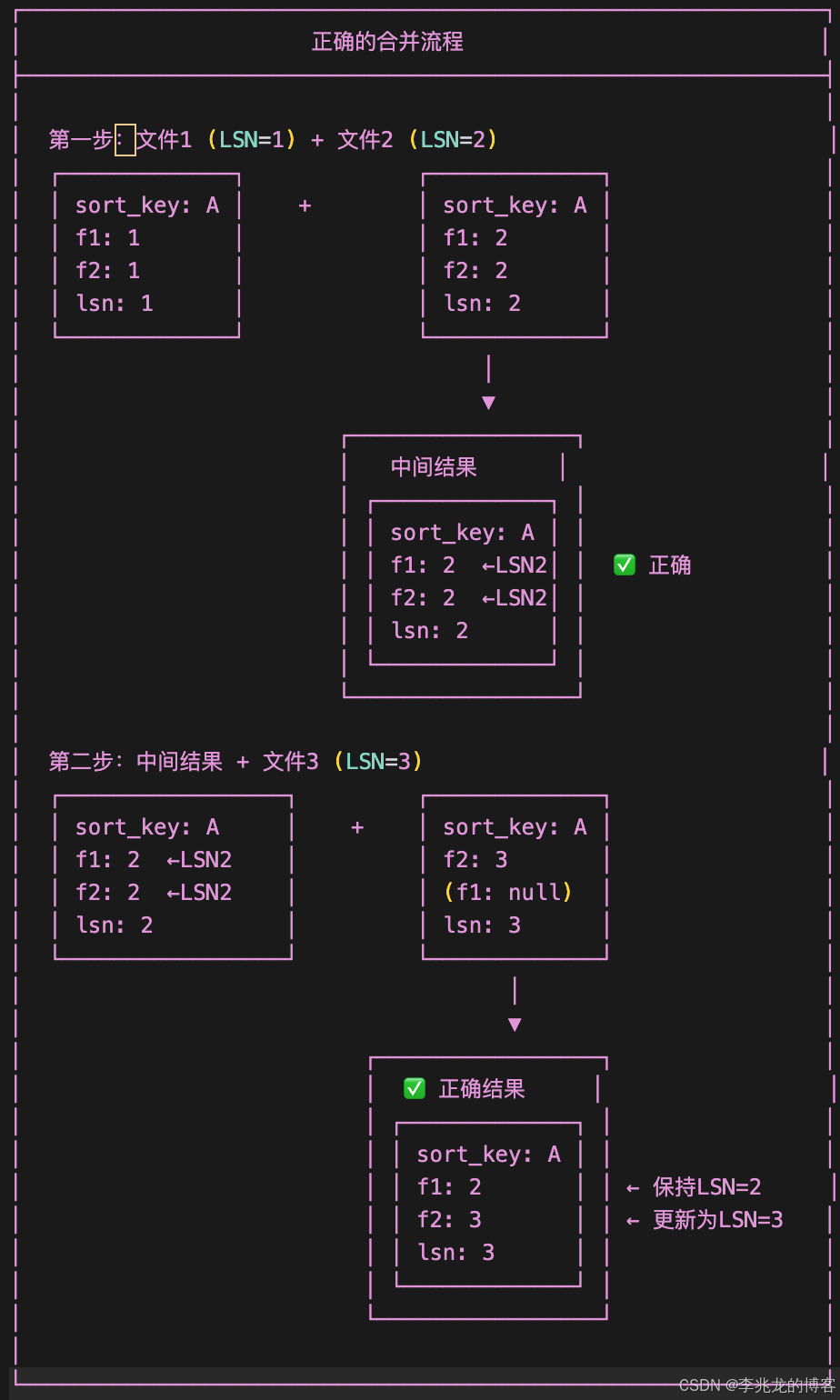
這要求我們再Compact的時候需要合并 LSN 臨近的文件。
從實現的角度上講,GrepTimedb和influxdb3.0的引擎是類似的,適用于時間線爆炸的場景,而influxdb1.x在時間線較少的場景下依然有較強的競爭力,Compaction的設計上也有區別。
時序數據庫Compact最在意什么呢?不同的業務場景有不同的答案:TTL短的業務,寫入量大,查詢量大,存儲量相對少,可以Tired+Level均衡讀寫;TTL長的業務,相對不是特別關心實時數據查詢性能,TWCS冷shard可以理解為Level,所以活躍shard可以采用Tired這樣的寫入友好的策略;
回到實現的角度,自然Tiered是最簡單的,因為Compaction的時候只需要維護LSN的區間有序就可以,compact的時候需要保證LSN連續的文件執行合并。influxdb1.x引入了一個Generations的概念,代表一次compact的輸出,其文件名組成為000001-01.tsm,前面是Generations,后面是按文件大小切分的chunk,合并的時候只允許Generations連續的執行合并,這其實就是LSN相鄰的文件合并,因為數據中沒有存儲LSN(TSI+SeriesFile+TSM,沒有行的概念,無法支持行去重),只能在Compact上下功夫,這樣的壞處自然就是事實數據查詢性能差。
如果是Level策略,且只支持行級別去重,文件的行中存儲一個LSN,這樣Compact策略就比較自由,因為文件本身內部附帶LSN信息,在合并的過程中建立WindowBuild內部可以基于LSN作去重,對于Compact的策略沒有影響。
但是要是Level策略+支持Field級別去重,這就比較麻煩了,就像上面舉的例子,事實上因為文件內部記錄的是行級別的LSN,但是合并后可能存在不同LSN的數據被合并到一行,如果只記錄一個LSN這會導致其中有些列的LSN被強行升級了,這會導致去重出現錯誤的數據覆蓋。
這個時候有三種解決問題的思路:
第一種方法是簡單的記錄field級別LSN,在寬列場景下幾乎不可用,因為存儲空間占用太大
第二種方法是記錄添加一個額外的列,記錄出現Field覆蓋時Field的LSN,這樣可以大大減少冗余的LSN存儲,畢竟列覆蓋是極少數情況,但是需要給原始文件再加一列,因為Parquet等文件格式支持復雜類型,這樣做也是可以的
第三種是Compact在選擇文件時不僅僅考慮SortKey,而且需要考慮LSN的連續,具體的實現是在L0沉降L1時執行下述操作,是最優選擇:
- L0為Tired,選擇需要被合并的文件,要求LSN連續,計算其LSN區間,為區間1
- 選擇L1中和L0文件SortKey重疊的文件,計算其LSN區間,為區間2
- 查找L1中區間1與區間2的空洞文件,計算其LSN區間,為區間3
- 三部分文件組成一個Compact任務,合并后更新Compact文件LSN區間,如果目標文件較大,可以拆分成多個,但是LSN區間是一樣的
所以采用特殊的Compact策略可以實現低成本Field/Row Level 的Deduplicate。
Compact Execution Flow Based On Velox
這一節和文章題目沒有關系,單純的記錄一下
基于執行引擎做Compact已經不是什么稀奇的事情了,畢竟一個好的執行引擎庫基本上可以認為是AP的基礎庫了,而且Compact可以被抽象為算子的組合,在Velox中,我們可以把Compact抽象為TableScan+LocalMerge+Window+TableWrite的算子組合。
其實現的技術要點如下:
LocalMergeSource的管道分離流式讀取
在Velox的LocalMerge操作中,PlanBuilder階段傳入的TableScan算子并不是直接轉換為LocalMergeSource,而是通過管道分離和數據流重定向過程實現的。
管道 0 (Producer Pipeline):
TableScanNode → CallbackSink → LocalMergeSource[0]
↓
管道 1 (Producer Pipeline):
TableScanNode → CallbackSink → LocalMergeSource[1]
↓
管道 2 (Producer Pipeline):
TableScanNode → CallbackSink → LocalMergeSource[2]
↓
管道 3 (Consumer Pipeline):
LocalMergeOperator ← LocalMergeSource[0,1,2]
數據生產階段:每個TableScan管道中的數據流
TableScanOperator::getOutput()
↓
CallbackSink::addInput(RowVectorPtr input)
↓
consumer(input, future) // 這是LocalMergeSource的enqueue函數
↓
LocalMergeSource::enqueue(input, future)
↓
LocalMergeSourceQueue::enqueue(input) // 數據進入隊列
數據消費階段:LocalMerge管道中的數據流
LocalMerge::getOutput()
↓
TreeOfLosers::next() // 從多個source中選擇最小值
↓
LocalMergeSource::next() // 從隊列中取數據
↓
LocalMergeSourceQueue::next()
↓
返回排序后的RowVector
這樣做有以下好處:
- 不同的并行性要求:生產者管道 (TableScan): 需要多線程并行處理,充分利用 I/O 帶寬;消費者管道 (LocalMerge): 必須單線程執行,保證排序的正確性
- 數據流控制:生產者和消費者解耦,以支持背壓控制(backpressure),生產者可以快速寫入緩沖區,消費者按需讀取
- 內存管理:
- LocalMergeSource提供緩沖隊列,支持流式處理,當緩沖區滿時,生產者會被阻塞,防止內存溢出
- 可以基于緩沖隊列實現精確的內存控制
- 容錯性:管道間獨立,單個管道失敗不影響其他
- 生產者管道故障:不會直接影響消費者管道,可以獨立重試
- 消費者管道故障:不會影響生產者的數據生成
- 部分失敗處理:某個生產者失敗時,其他生產者可以繼續工作
基于LoserTree的歸并排序
在Velox Window操作的LocalMerge場景中,需要處理多個已排序(基于提前指定的timestamp || measurement || tags作為排序key)的數據流并將其合并為一個全局有序的結果。
假設待排序列數為 N,待排元素總個數為 n,復雜度分析:
| LoserTree | 堆排序 | |
|---|---|---|
| 空間復雜度 | O(N) | O(N) |
| 單次調整時間復雜度 | O(n*logN) | O(2n*logN) |
| 整體排序完成時間復雜度 | O(logN) | O(2*logN) |
在調整LoserTree時,由于只需比較和更新對應葉子節點的路徑上的節點,無需比較兄弟節點,因此在最壞情況下,單次調整敗者樹的時間復雜度為 O(logN)。
而堆排單次調整則需要比較兄弟節點,這里有常數級別的優化。
Window算子實現流式計算
認為每個窗口函數都通過一個 OVER 子句來運行,規定了 Window 函數的聚合方式。
窗口函數支持:
- 排名函數:ROW_NUMBER、RANK、DENSE_RANK
- 聚合函數:SUM、COUNT、AVG、MIN、MAX等作為窗口函數
- 分析函數:LAG、LEAD、FIRST_VALUE、LAST_VALUE等
RANGE框架邊界類型:
- kUnboundedPreceding:之前的全部
- kPreceding:之前的N個
- kCurrentRow:當前行
- kFollowing:之后的N個
- kUnboundedFollowing:之后的全部
樣例sql:
- sum(value) over (partition by partition_key order by order_key rows between unbounded preceding and current row) as running_sum
- avg(value) over (partition by partition_key order by order_key rows between 2 preceding and 2 following) as moving_avg
- row_number() over (partition by partition_key order by order_key) as rn
- c0, c1, c2, first_value(c0) OVER (PARTITION BY c1 ORDER BY c2 DESC NULLS FIRST {})
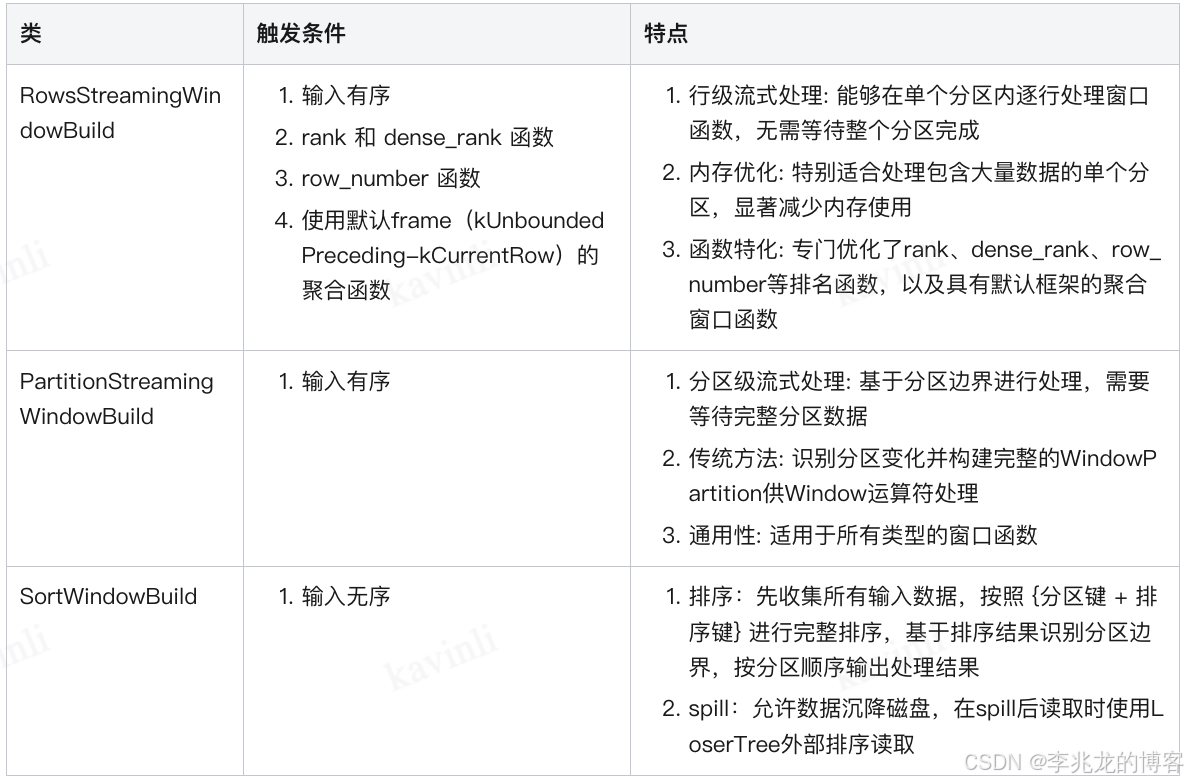
window的區間劃分類有三種
TableWrite的多路流式寫入
A[TableWriter] --> B[HiveDataSink]
B --> C[ParquetWriter]
C --> D[WriteFileSink]
D --> E[S3WriteFile/LocalFile]
|
F[Input Data] --> A
A --> G[addInput]
G --> H[appendData]
H --> I[write method]
I --> J[Row Group Buffer]
J --> K[Flush Policy Check]
K --> L[Write Row Group]
L --> M[Footer Writing]
RowGroup默認刷新大小:
- rowsInRowGroup: 1’024 * 1’024
- bytesInRowGroup: 128 * 1’024 * 1’024
Compact需要基于sortkey和文件大小在compact的過程中切分輸出文件
TableWrite運算符目前無法做到,只能通過Partition和bucket來分區,這種情況在分區時采用hash來選擇排序key所屬的文件,而不是range,需要修改PartitionIdGenerator,實現range形式的partitionID分配。
結束語
想明白上述問題以后Compact就剩下工程問題了,需要聚焦在Compact任務的調度(分池,并發限制),與Catalog的交互,Garbage Collector的設計。















![題海拾貝:P8598 [藍橋杯 2013 省 AB] 錯誤票據](http://pic.xiahunao.cn/題海拾貝:P8598 [藍橋杯 2013 省 AB] 錯誤票據)



