?實驗四 ?卷積神經網絡CNN
一、實驗學時:?2學時
二、實驗目的
- 掌握卷積神經網絡CNN的基本結構;
- 掌握數據預處理、模型構建、訓練與調參;
- 探索CNN在MNIST數據集中的性能表現;
三、實驗內容
實現深度神經網絡CNN。
四、主要實驗步驟及結果
1.搭建一個CNN網絡,使用MNIST手寫數字數據集進行訓練與測試,并體現模型最終結果,CNN網絡的具體框架可參考下圖,也可自己設計:
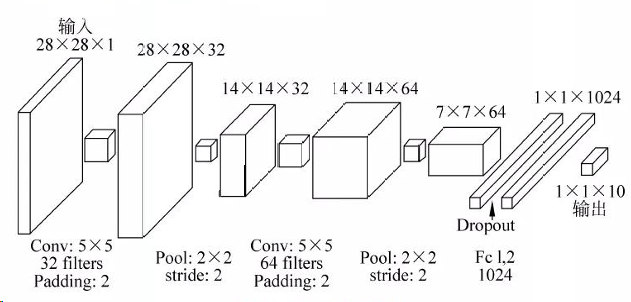
圖4-1 CNN架構圖
(1)該圖表示輸入層為28*28*1的尺寸,符合MNIST數據集的標準尺寸。
(2)第一個卷積層,使用5*5卷積核,32個濾波器,填充(Padding)為2。輸出尺寸為28*28*32。
(3)第一個池化層,使用2*2池化窗口,步長(stride)為2。輸出尺寸為14*14*32。
(4)第二個卷積層,使用5*5卷積核,64個濾波器,填充(Padding)為2。輸出尺寸為14*14*64。
(5)第二個池化層,使用2*2池化窗口,步長(stride)為2。輸出尺寸為7*7*64。
(6)全連接層包含1024個神經元,輸出尺寸為1*1*1024。
(7)Dropout層用于防止過擬合。
(8)輸出層包含10個神經元,對應手寫數字的0-9。輸出尺寸為1*1*10。
模型實現:
以該架構圖搭建CNN網絡,使用MNIST手寫數字數據集進行訓練與測試,訓練和測試結果如圖4-2所示:
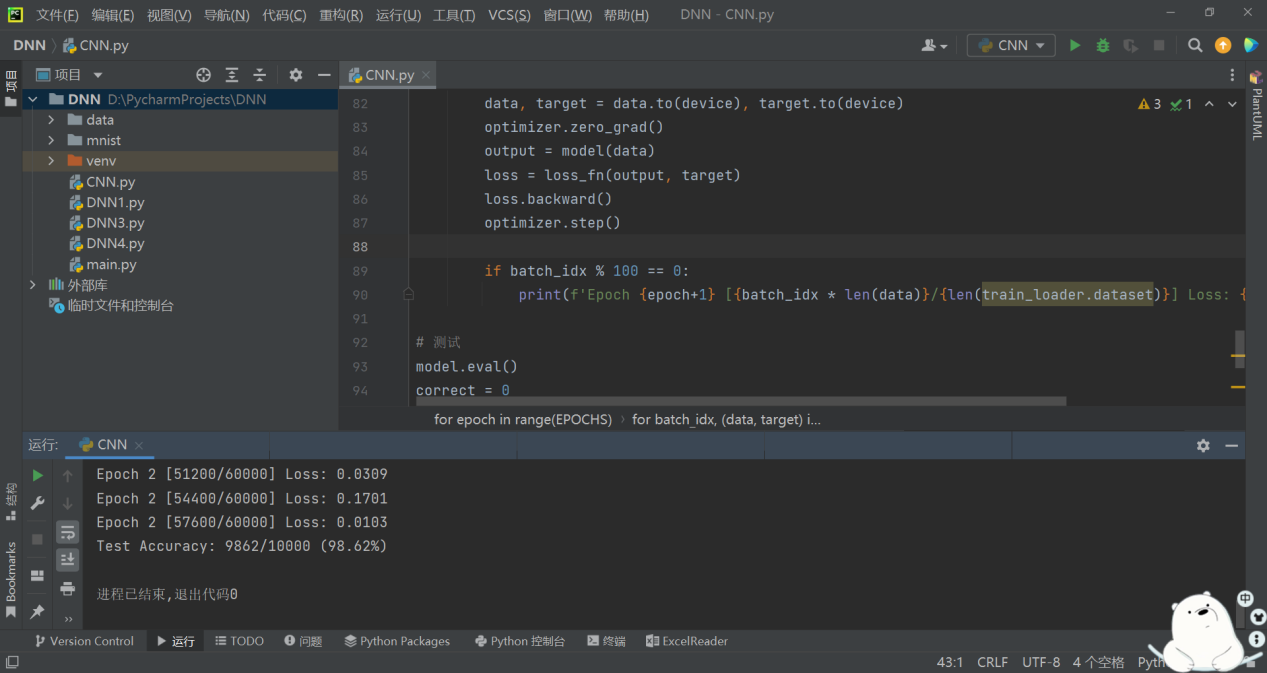
圖4-2?CNN測試結果
2.嘗試使用不同的數據增強方法、優化器、損失函數、學習率、batch size和迭代次數來進行訓練,記錄訓練過程,評估模型性能,保存最佳模型。
| 編號 | batch size | 訓練輪次 | 學習率 | 數據增強方法 | 優化器 | 實驗結果 |
| 1 | 32 | 2 | 1e-4 | 無 | Adam | 98.62% |
| 2 | 64 | 2 | 1e-4 | 無 | Adam | 98.56% |
| 3 | 64 | 4 | 1e-4 | 無 | Adam | 99.08% |
| 4 | 64 | 4 | 3e-4 | 無 | Adam | 99.08% |
| 5 | 64 | 4 | 3e-4 | 旋轉+平移 | Adam | 98.90% |
| 5 | 64 | 4 | 3e-4 | 無 | Adam(L2正則化) | 99.23% |
| 6 | 64 | 4 | 1e-4 | 無 | SGD+momentum | 97.30% |
其中數據增強方法采用隨機旋轉和平移嗎,原始代碼中包含ToTensor()和Normalize(),給原始代碼添加隨機旋轉10度和隨機平移10%,代碼如下:
# 數據加載(歸一化)
transform = torchvision.transforms.Compose([torchvision.transforms.RandomRotation(10), # 隨機旋轉10度torchvision.transforms.RandomAffine(0, translate=(0.1, 0.1)), # 隨機平移10%torchvision.transforms.ToTensor(),torchvision.transforms.Normalize((0.1307,), (0.3081,))
])優化器選擇方面使用SGD+momentum(0.9)替代原Adam優化器,
# 使用SGD+momentum
optimizer = torch.optim.SGD(model.parameters(), lr=LEARN_RATE, momentum=0.9)根據訓練過程記錄的數據,最佳模型尊卻綠為99.23%,最佳模型代碼如下:
import torch
import torchvision
import torch.nn as nn
from torch.utils.data import DataLoaderBATCH_SIZE = 64
EPOCHS = 4
LEARN_RATE = 3e-4
DROPOUT_RATE = 0.5device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')# 數據加載(歸一化)
transform = torchvision.transforms.Compose([# torchvision.transforms.RandomRotation(10), # 隨機旋轉10度# torchvision.transforms.RandomAffine(0, translate=(0.1, 0.1)), # 隨機平移10%torchvision.transforms.ToTensor(),torchvision.transforms.Normalize((0.1307,), (0.3081,))
])train_data = torchvision.datasets.MNIST(root='./mnist',train=True,download=True,transform=transform
)
train_loader = DataLoader(train_data, batch_size=BATCH_SIZE, shuffle=True)test_data = torchvision.datasets.MNIST(root='./mnist',train=False,transform=transform
)
test_loader = DataLoader(test_data, batch_size=1000, shuffle=False)class CNN(nn.Module):def __init__(self):super(CNN, self).__init__()self.conv_layers = nn.Sequential(# 第一層卷積:5x5 卷積核,32 個過濾器,padding=2nn.Conv2d(1, 32, kernel_size=5, padding=2),nn.ReLU(),nn.MaxPool2d(kernel_size=2, stride=2), # 池化后 14x14x32# 第二層卷積:5x5 卷積核,64 個過濾器,padding=2nn.Conv2d(32, 64, kernel_size=5, padding=2),nn.ReLU(),nn.MaxPool2d(kernel_size=2, stride=2) # 池化后 7x7x64)self.fc_layers = nn.Sequential(nn.Linear(64 * 7 * 7, 1024), # 全連接層:7x7x64 → 1024nn.ReLU(),nn.Dropout(DROPOUT_RATE), # Dropout層nn.Linear(1024, 10) # 輸出層:1024 → 10)self._initialize_weights()def _initialize_weights(self):for m in self.modules():if isinstance(m, nn.Conv2d):nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')if m.bias is not None:nn.init.constant_(m.bias, 0)elif isinstance(m, nn.Linear):nn.init.kaiming_normal_(m.weight, mode='fan_in', nonlinearity='relu')nn.init.constant_(m.bias, 0)def forward(self, x):x = self.conv_layers(x)x = x.view(x.size(0), -1) # 展平操作x = self.fc_layers(x)return xmodel = CNN().to(device)
loss_fn = nn.CrossEntropyLoss().to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=LEARN_RATE, weight_decay=1e-5)
# optimizer = torch.optim.SGD(model.parameters(), lr=LEARN_RATE, momentum=0.9) # 使用SGD+momentum
# 訓練循環
for epoch in range(EPOCHS):model.train()for batch_idx, (data, target) in enumerate(train_loader):data, target = data.to(device), target.to(device)optimizer.zero_grad()output = model(data)loss = loss_fn(output, target)loss.backward()optimizer.step()if batch_idx % 100 == 0:print(f'Epoch {epoch + 1} [{batch_idx * len(data)}/{len(train_loader.dataset)}] Loss: {loss.item():.4f}')# 測試
model.eval()
correct = 0
with torch.no_grad():for data, target in test_loader:data, target = data.to(device), target.to(device)output = model(data)pred = output.argmax(dim=1)correct += pred.eq(target).sum().item()print(f'Test Accuracy: {correct}/{len(test_loader.dataset)} ({100. * correct / len(test_loader.dataset):.2f}%)')3.使用畫圖工具將自己的學號逐個寫出,使用保存的最佳模型對每個數字進行推理,比較模型對每個數字的準確率預測,也可以嘗試實現一個實時識別手寫數字的demo。
(1)使用畫圖工具將自己的學號逐個寫出,進行反色處理,并將圖片命名為“x_001.png”格式。
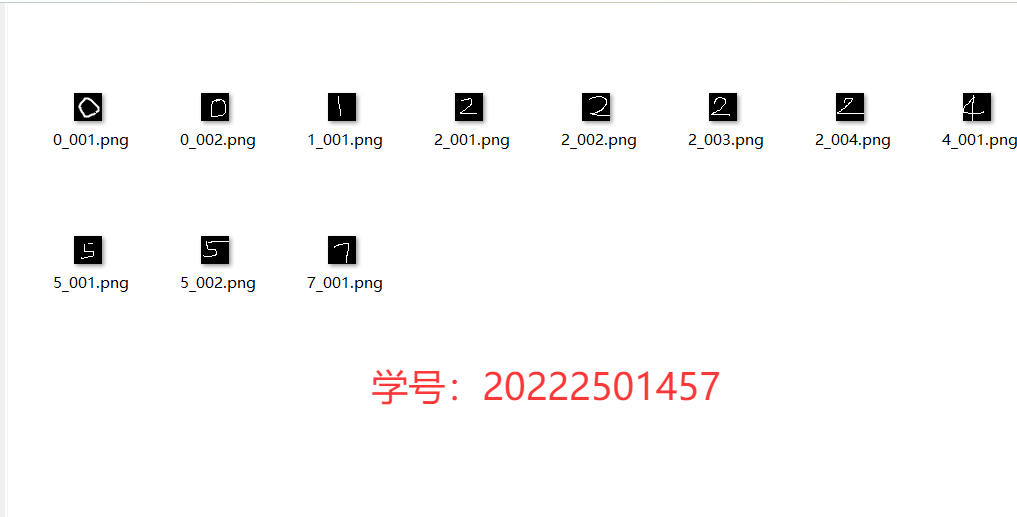
圖4-3手寫數字
(2)在訓練代碼(CNN.py)中添加模型保存代碼。
torch.save(model.state_dict(), 'mnist_cnn.pth')(3)編寫推理代碼讀取img文件夾中的手寫圖片并預測,預測代碼如下所示:
import torch
import torch.nn as nn
from torchvision import transforms
from PIL import Image
import numpy as np
import os# 定義模型結構(需與訓練代碼一致)
class CNN(nn.Module):def __init__(self):super(CNN, self).__init__()self.conv_layers = nn.Sequential(nn.Conv2d(1, 32, kernel_size=5, padding=2),nn.ReLU(),nn.MaxPool2d(2, 2),nn.Conv2d(32, 64, kernel_size=5, padding=2),nn.ReLU(),nn.MaxPool2d(2, 2))self.fc_layers = nn.Sequential(nn.Linear(64 * 7 * 7, 1024),nn.ReLU(),nn.Dropout(0.5),nn.Linear(1024, 10))def forward(self, x):x = self.conv_layers(x)x = x.view(x.size(0), -1)x = self.fc_layers(x)return x# 加載模型
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = CNN().to(device)
model.load_state_dict(torch.load('mnist_cnn.pth', map_location=device))
model.eval()# 定義預處理(與訓練一致)
transform = transforms.Compose([transforms.Resize((28, 28)), # 確保輸入為28x28transforms.Grayscale(num_output_channels=1), # 轉換為單通道transforms.ToTensor(),transforms.Normalize((0.1307,), (0.3081,))
])# 遍歷img文件夾中的圖片并推理
img_dir = 'img'
digit_stats = {str(i): {'correct': 0, 'total': 0} for i in range(10)}for filename in os.listdir(img_dir):if filename.lower().endswith(('.png', '.jpg', '.jpeg')):# 從文件名中提取真實標簽(假設文件名為 "label_xxx.png")try:true_label = filename.split('_')[0] # 例如文件名 "3_001.png" → 標簽為3true_label = int(true_label)if true_label < 0 or true_label > 9:continueexcept:print(f"跳過文件 {filename}(文件名格式錯誤)")continue# 加載并預處理圖像img_path = os.path.join(img_dir, filename)image = Image.open(img_path)image = transform(image).unsqueeze(0).to(device) # 添加batch維度# 推理with torch.no_grad():output = model(image)pred = output.argmax(dim=1).item()# 統計結果digit_stats[str(true_label)]['total'] += 1if pred == true_label:digit_stats[str(true_label)]['correct'] += 1print(f"圖片 {filename} 真實標簽: {true_label}, 預測: {pred} → {'正確' if pred == true_label else '錯誤'}")# 計算每個數字的準確率
accuracies = {}
for digit in digit_stats:if digit_stats[digit]['total'] > 0:acc = digit_stats[digit]['correct'] / digit_stats[digit]['total']accuracies[digit] = accprint(f"數字 {digit} 的準確率: {acc:.2%}")預測結果如圖4-4所示:
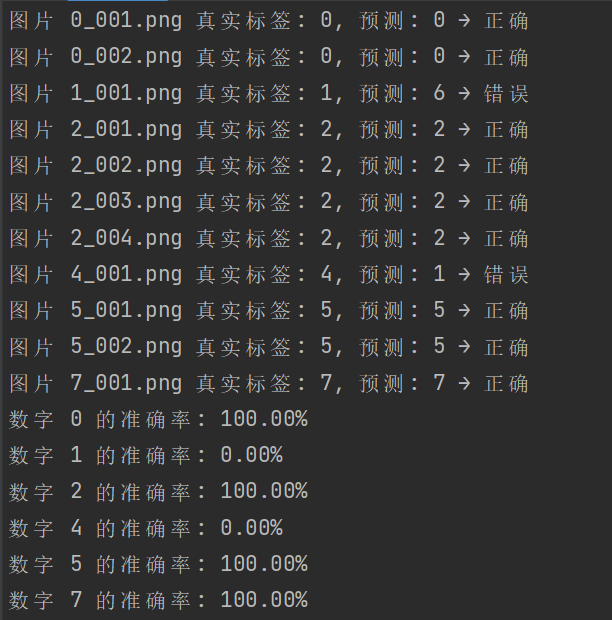
圖4-4預測結果
預測結果顯示“1”和“4”預測結果錯誤,其他均正確。
五、實驗小結(包括問題和解決辦法、心得體會、意見與建議等)
1.問題和解決辦法:
問題1:RuntimeError: Dataset not found. You can use download=True to download it。
解決方法:添加下載訓練集的參數download=True。
問題2:使用SGD+momentum優化器后,準確率反而下降了。
解決方法:因為SGD對學習率比較敏感,學習率沒有適配,使用StepLR梯度衰減,另外也可以增加訓練輪次。
問題3:預測結果全部錯誤。
解決方法:圖片要像素28*28,且黑色背景,白色筆跡,對Windows畫圖的圖片反色處理即可。
2.心得體會:通過本次CNN手寫數字識別實驗的完整實踐,我深刻體會到深度學習模型性能的提升是一個系統工程,需要從數據、模型、訓練策略到結果分析的全流程精細化把控,嘗試使用不同的數據增強方法、優化器、損失函數、學習率、batch size和迭代次數來進行訓練,迭代出最佳模型,再手寫數字進行測試。通過以上的學習和實踐,我對神經網絡的原理和應用有了更深入的理解。神經網絡的發展給人工智能帶來了巨大的影響,它在圖像識別、自然語言處理等領域發揮著重要的作用。我相信,隨著技術的進步,神經網絡將會有更廣泛的應用。




![題海拾貝:P8598 [藍橋杯 2013 省 AB] 錯誤票據](http://pic.xiahunao.cn/題海拾貝:P8598 [藍橋杯 2013 省 AB] 錯誤票據)










)



