【頭歌實驗】Keras機器翻譯實戰
第1關:加載原始數據
編程要求
根據提示,在右側編輯器補充代碼,實現load_data函數,該函數需要加載path所代表的文件中的數據,并將文件中所有的內容按\n分割,轉換成一個列表后返回。
代碼
#coding:utf8
import osdef load_data(path):'''讀取原始語料數據:param path: 文件路徑:return: 句子列表,如['he is a boy.', 'she is a girl']'''#*********Begin*********#with open (path,'r',encoding='utf-8') as file:content = file.readlines()return [line for line in content]#*********End*********#第2關:Tokenize
相關知識
為了完成本關任務,你需要掌握什么是 Tokenize ,以及怎樣實現 Tokenize 。
為什么需要 Tokenize
對于深度學習和機器學習程序來說,除了數字之外,什么都不認識。也就是說假設現在有一個機器翻譯的程序,能將英語翻譯成法語,然后我們把英語句子作為輸入,輸入到程序中。此時程序其實會將句子中的單詞、符號等信息轉換成數字,再丟給模型去計算。所以將單詞轉換成數字是實現機器翻譯的第一步,而 Tokenize 就是最為常用的一種將單詞轉換成數字的方式。
什么是 Tokenize
Tokenize 看起來高大上,其實就是將每個單詞都映射成一個數字而已。例如現在語料庫中的句子如下:
[‘The quick brown fox jumps over the lazy dog .’, ‘By Jove , my quick
study of lexicography won a prize .’, ‘This is a short sentence .’]
那么 Tokenize 就是統計所有句子中出現的不同的詞,然后將每個單詞與一個數字對應起來。如:
{‘the’: 1, ‘quick’: 2, ‘a’: 3, ‘brown’: 4, ‘fox’: 5, ‘jumps’: 6,
‘over’: 7, ‘lazy’: 8, ‘dog’: 9, ‘by’: 10, ‘jove’: 11, ‘my’: 12,
‘study’: 13, ‘of’: 14, ‘lexicography’: 15, ‘won’: 16, ‘prize’: 17,
‘this’: 18, ‘is’: 19, ‘short’: 20, ‘sentence’: 21}
所以經過 Tokenize 后,語料庫中的句子變成了只有數字的列表,如下所示:
[[1, 2, 4, 5, 6, 7, 1, 8, 9], [10, 11, 12, 2, 13, 14, 15, 16, 3, 17],
[18, 19, 3, 20, 21]]
怎樣實現 Tokenize
keras 為我們已經實現好了 Tokenize 功能,我們只需調用接口即可實現 Tokenize 。示例代碼如下:
from keras.preprocessing.text import Tokenizer
# 語料
x = ['The quick brown fox jumps over the lazy dog .', 'By Jove , my quick study of lexicography won a prize .', 'This is a short sentence .']
# 實例化Tokenizer對象,使用單詞級別的Tokenize
x_tk = Tokenizer(char_level=False)
# 對語料進行Tokenize
x_tk.fit_on_texts(x)
# 打印Tokenize的語料
print(x_tk.texts_to_sequences(x))
編程要求
根據提示,在右側編輯器補充代碼,實現tokenize函數。
代碼
#coding:utf8
from keras.preprocessing.text import Tokenizerdef tokenize(data):'''tokenize:param data: 語料,類型為list:return: tokenize后的語料,類型為list'''#*********Begin*********#x=[]x=data# 實例化Tokenizer對象,使用單詞級別的Tokenizex_tk = Tokenizer(char_level=False)# 對語料進行Tokenizex_tk.fit_on_texts(x)# 打印Tokenize的語料#print(x_tk.texts_to_sequences(x))return x_tk.texts_to_sequences(x)#*********End*********#
第3關:padding
相關知識
為了完成本關任務,你需要掌握:什么是 padding 以及怎樣實現 padding。
為什么要 padding
通常情況下語料庫中的每個句子中的單詞數量不可能會是完全一致的。就比如上一關中用來舉例的語料中3條句子的單次數量是不同的。
但是在搭建神經網絡時,神經網絡中每層的神經元的個數其實就已經確定下來了。特別是輸入層的神經元數量,每一個神經元代表著一個詞。
一邊是單次數量不確定,另一邊是需要確定好單詞數量,怎么辦呢?這個時候可以使用 padding 方法。
什么是 padding
padding 其實就是設定一個最大的單詞數量,當 tokenize 后的句子中單詞數量小于最大單詞數量時,就在后面補0。
假設 tokenize 后的句子為:[18 19 3 20 21],最大單詞數量為10,那么 padding 后的句子為:[18 19 3 20 21 0 0 0 0 0]。
怎樣實現 padding
keras 同樣為我們實現好了 padding 功能,省得我們重新造輪子。示例代碼如下:
from keras.preprocessing.sequence import pad_sequences
# tokenize后的語料
x = [[[18 19 3 20 21]]]
# 打印padding的結果,最大單詞數量為10
print(pad_sequences(x, maxlen=10, padding='post'))
題目
編程要求
根據提示,在右側編輯器補充代碼,實現 padding 函數。注意:最大單次數量為data中所有句子的單次數量的最大值。
代碼
#coding:utf8
from keras.preprocessing.sequence import pad_sequencesdef padding(data):'''padding,最大單詞數量為data中所有句子的單詞數量的最大值:param data: 語料,類型為list:return: padding后的語料,類型為list'''#*********Begin*********## tokenize后的語料x = datamaxlen=(max(len(x) for x in data))# 打印padding的結果,最大單詞數量為10return pad_sequences(x, maxlen, padding='post')#*********End*********#
第4關:搭建雙向RNN神經網絡
相關知識
為了完成本關任務,你需要掌握:
RNN ;
RNN 即循環神經網絡,RNN 通常作用于語言處理,目前最為常見的自然語言處理就是通過 RNN 或者 RNN 的變種實現的。由于語言的數據量十分龐大使用普通的全連接網絡進行訓練需要的參數存在幾何倍增加,同時我們每說一句話都是存在一定的時序的,時序的不同表達的意思也不同。對于這種問題來說,全連接網絡的處理能力就有點捉襟見肘了。
比如現在有個句子,句子最后面有一處缺失,需要使用神經網絡來預測一下這個缺失的詞是什么。句子是這樣的:“我喜歡阿倫艾弗森,我平常愛和朋友打___。”當我們把這個句子輸入到全連接網絡中可能會得到其他結果,比如和朋友打架、和朋友打年糕等等。這些結果都忽略了之前文字帶來的影響,但是輸入到 RNN 中就不一樣了, RNN 會“記住”之前的內容,他記下了“阿倫艾弗森”發現他是一個籃球巨星,因此 RNN 會推斷輸出和朋友打籃球。
那么 RNN 是如何保留這種“記憶”的呢?請觀察下圖的左邊部分, RNN 神經網絡結構圖, x為輸入的數據,同時右側的圓圈也是 RNN 的輸入,這部分輸入的就是之前的記憶,由這兩種輸入共同決定最后的輸出。
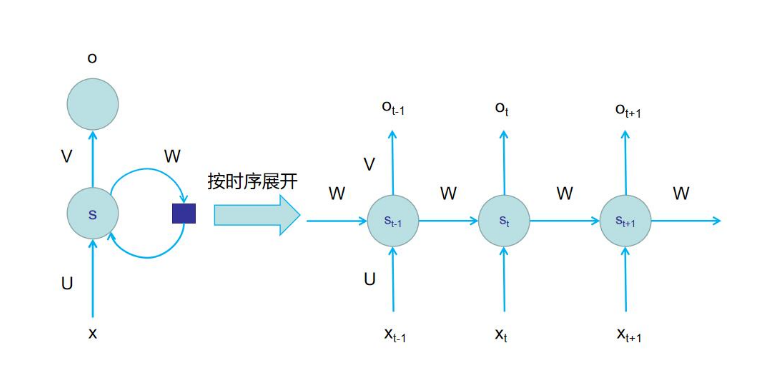
對于上圖的左邊部分不是特別容易理解,我們將其展開進行進一步解釋。看右邊部分中位于中間的神經元,該神經元的輸入源自兩個方面,一個是下方的x ,x代表的是當前時刻輸入的外部數據也就是上文舉例的句子中的漢字或者詞語,另一個來自上一個神經元傳遞的s,s代表的是內部數據也就是上一個神經元經過計算后保留的記憶。將這兩種輸入共同作用在當前神經元上,經過計算后輸出O。這就是為什么喜歡使用 RNN 處理語言問題的主要原因。
但是這種最普通的 RNN 有一個弊端,就是只能從前往后,這樣會導致一個問題,就是當前的輸出至于前一時刻的輸入和輸出有關。那有沒有既能從前往后,又能從后往前呢?有!那就是雙向 RNN 。
雙向 RNN
為什么需要既能從前往后又能從后往前的 RNN 呢,因為如果僅僅是從前往后的方式來理解句子的語義的話,會有可能產生歧義。例如:“He said, Teddy bears are on sale” 和 “He said, Teddy Roosevelt was a great President。在上面的兩句話中,當我們看到“Teddy”和前兩個詞“He said”的時候,我們有可能無法理解這個句子是指President還是Teddy bears。因此,為了解決這種歧義性,我們需要從后往前看。這就是雙向 RNN 所能實現的。
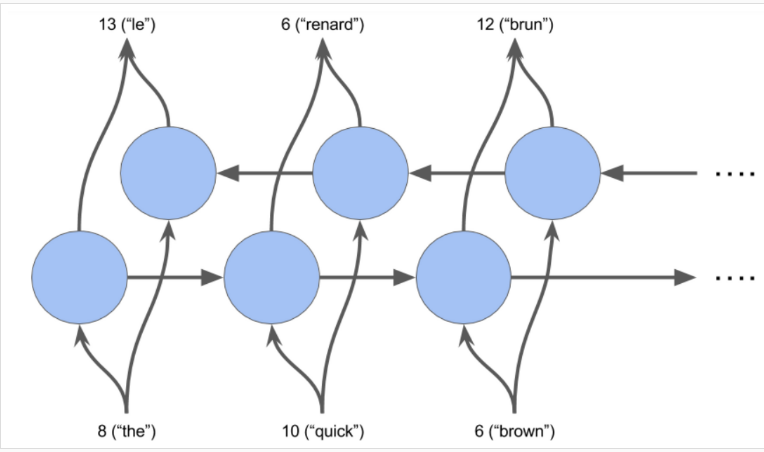
怎樣搭建雙向 RNN 神經網絡
以將英語翻譯成法語的功能為例。當我們把英語和法語的語料進行 tokenize 和padding 處理后,就可以將經過處理后的英語語料作為伸進網絡的輸入,將經過處理后的法語語料作為輸出。所以這個網絡應該是一個處理分類問題的神經網絡。
因此,網絡的輸出層其實就是一個全連接層,神經元的數量就是法語 tokenize 后詞的數量,激活函數是softmax。
確定了輸出層后,就要確定處理輸入層數據的層了。很明顯,就是用雙向 RNN ! keras 中有相應的接口來幫助我們實現雙向 RNN 。示例代碼如下:
# SimpleRNN表示RNN,Bidirectional表示雙向的意思。128表示RNN有128個神經元,由于我們需要RNN處理后的序列,所以return_sequences為True,dropout是隨機丟棄的概率,能夠防止過擬合
Bidirectional(SimpleRNN(128, return_sequences = True, dropout=0.1), input_shape=input_shape)
知道怎樣構建雙向 RNN 層之后,相信你能夠很輕松的構建出整個神經網絡了。
編程要求
根據提示,在右側編輯器補充代碼,實現build_model函數,該函數的功能是構建一個含有128個神經元的雙向 RNN 層和含有french_vocab_size個神經元的全連接層的神經網絡。(怎樣將層與層之間連接起來,請查閱 keras 官方文檔。)
代碼
from keras.models import Sequential
from keras.layers import Dense, SimpleRNN, Bidirectionaldef build_model(input_shape, french_vocab_size):'''tokenize:param input_shape: 英語語料的shape,類型為list:param french_vocab_size: 法語語料詞語的數量,類型為int:return: 構建好的模型'''#*********Begin*********## 創建序列模型model = Sequential()# 添加雙向RNN層作為第一層,指定input_shapemodel.add(Bidirectional(SimpleRNN(128, return_sequences=True), input_shape=input_shape))# 添加全連接層model.add(Dense(french_vocab_size, activation='softmax'))# 編譯模型model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])return model#*********End*********#第5關:實現機器翻譯
相關知識
為了完成本關任務,你需要將前面所有的知識融會貫通。
機器翻譯流程
1.分別對英語語料和法語語料進行 tokenlize 處理,以及 padding 處理;
2.構建神經網絡;
3.編譯神經網絡,訓練;
4.加載訓練后的模型并進行翻譯。
編程要求
根據提示,在右側編輯器補充代碼,實現機器翻譯功能。由于平臺無法訓練太久,所以這里只訓練30個epoch,若想達到比較好的翻譯效果,可以在自己電腦上訓練久一點。
PS:請不要修改 Begin-End 之外的代碼!
代碼
#coding:utf8
import os
import warnings
warnings.filterwarnings('ignore')
os.environ["TF_CPP_MIN_LOG_LEVEL"] = "2"
from keras.models import Sequential, Model
from keras.layers import Input, Dense, SimpleRNN, Bidirectional, TimeDistributed
from keras.preprocessing.sequence import pad_sequences
from keras.preprocessing.text import Tokenizer
from keras.losses import sparse_categorical_crossentropy
from keras.optimizers import Adam
import numpy as npdef load_data(path):'''讀取原始語料數據,只讀取前3000條文本:param path: 文件路徑:return: 句子列表,如['he is a boy.', 'she is a girl']'''with open(path, 'r') as f:return f.readlines()[:3000]def tokenize(data):'''tokenize:param data: 語料,類型為list:return: (tokenize后的語料,tokenizer對象)'''x_tk = Tokenizer(char_level = False)x_tk.fit_on_texts(data)return x_tk.texts_to_sequences(data), x_tkdef padding(data, length=None):'''padding,最大單詞數量為dlength:param data: 語料,類型為list:param data: 詞數量,類型為int:return: padding后的語料,類型為list'''if length is None:length = max([len(sentence) for sentence in data])return pad_sequences(data, maxlen = length, padding = 'post')def build_model(input_shape, french_vocab_size):'''tokenize:param input_shape: 英語語料的shape,類型為list:param french_vocab_size: 法語語料詞語的數量,類型為int:return: 構建好的模型'''model = Sequential()model.add(Bidirectional(SimpleRNN(128, return_sequences=True, dropout=0.1), input_shape=input_shape[1:]))model.add(Dense(french_vocab_size, activation='softmax'))return modeldef logits_to_text(logits, tokenizer):"""將神經網絡的輸出轉換成句子:param logits: 神經網絡的輸出:param tokenizer: 語料的tokenizer:return: 神經網絡的輸出所代表的字符串"""index_to_words = {id: word for word, id in tokenizer.word_index.items()}index_to_words[0] = '<PAD>'return ' '.join([index_to_words[prediction] for prediction in np.argmax(logits, 1)])#*********Begin*********#
english_sentences = load_data('small_vocab_en.txt')
french_sentences = load_data('small_vocab_fr.txt')
preproc_english_sentences, english_tokenizer = tokenize(english_sentences)
preproc_french_sentences, french_tokenizer = tokenize(french_sentences)
max_english_sequence_length = max([len(i) for i in preproc_english_sentences])
max_french_sequence_length = max([len(j) for j in preproc_french_sentences])
max_length = max(max_english_sequence_length,max_french_sequence_length)
preproc_english_sentences = padding(preproc_english_sentences, max_length)
preproc_french_sentences = padding(preproc_french_sentences, max_length)
english_vocab_size = len(english_tokenizer.word_index) + 1
french_vocab_size = len(french_tokenizer.word_index) + 1
tmp_x = preproc_english_sentences.reshape((*preproc_english_sentences.shape, 1)
)
preproc_french_sentences = preproc_french_sentences.reshape((*preproc_french_sentences.shape,1)
)
model = build_model(tmp_x.shape, french_vocab_size)
#*********End*********## 編譯神經網絡
model.compile(loss=sparse_categorical_crossentropy, optimizer = Adam(1e-3))
# 訓練(這里只訓練30個epoch)
model.fit(tmp_x, preproc_french_sentences, batch_size=512, epochs=30, validation_split=0.2, verbose=0)# 保存翻譯結果
with open('result.txt', 'w') as f:for i in range(10):result = english_sentences[i]+' -> ' + logits_to_text(model.predict(np.expand_dims(tmp_x[i], 0))[0], french_tokenizer)f.write(result)

)

)







)







