一、RNN的長期依賴問題
 ? ? ? ??可以看到序列越長累乘項項數越多,項數越多就可能會讓累乘結果越小,此時對于W 的更新就取決于第一項或者是前幾項,也就是RNN模型會丟失很多較遠時刻的信息而 更關注當前較近的幾個時刻的信息,即沒有很好的長期依賴。 通俗來說就是模型記不住以前的東西。但很多時候我們都希望模型記得更久的信息。
? ? ? ??可以看到序列越長累乘項項數越多,項數越多就可能會讓累乘結果越小,此時對于W 的更新就取決于第一項或者是前幾項,也就是RNN模型會丟失很多較遠時刻的信息而 更關注當前較近的幾個時刻的信息,即沒有很好的長期依賴。 通俗來說就是模型記不住以前的東西。但很多時候我們都希望模型記得更久的信息。
二、LSTM模型結構
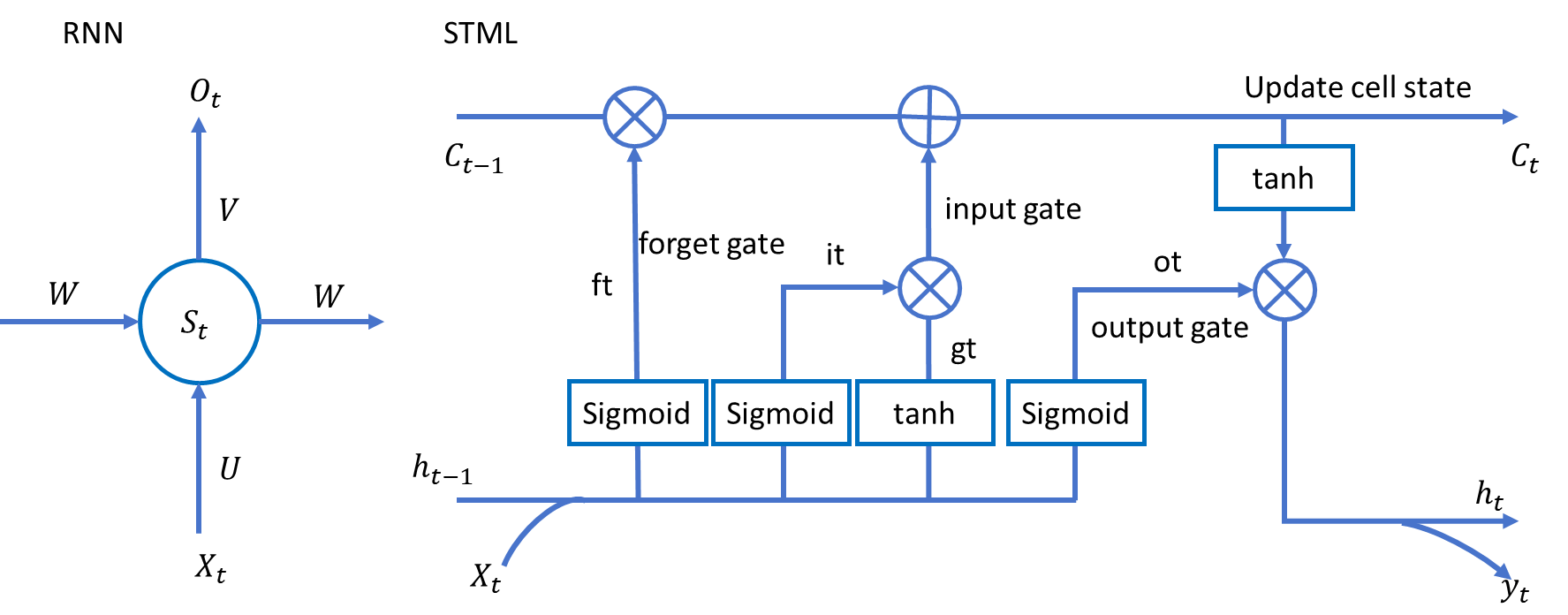
????????為了解決RNN的長期依賴問題,研究者對傳統RNN的結構進行了優化,提出了 LSTM。
????????通俗來說,RNN就好比是一個給什么都想要的人, 而LSTM是一個給東西還得挑一挑,挑一些有用的人。 這就導致RNN東西越來越多,多到放不下,然后直接把以前的東西丟掉,而LSTM從 一開始就精挑細選把沒用的丟掉,因此在容量一定的情況下LSTM可以裝入更長時間 的信息,并且這些信息都是相對更有用的。
????????LSTM的這種特性是通過門結構來實現的。‘門’的作用就是控制信息保留或丟棄的程 度。
注意:
????????這里的“門”不是只有開關狀態,即是否全部保留或者丟棄,而是保留或者 丟棄的程度。
2.1、輸入門(input gate)
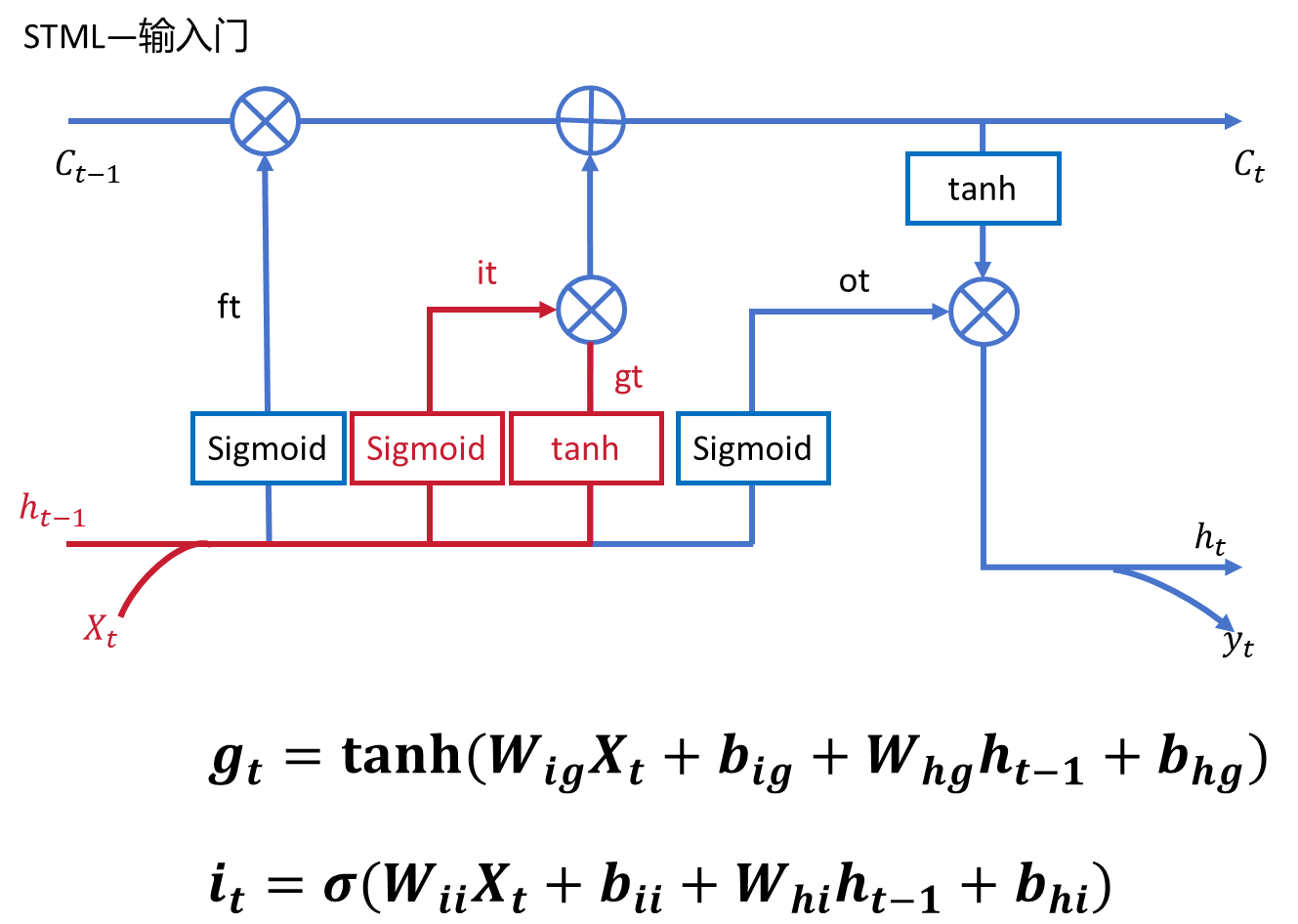
????????sigmoid函數的輸出范圍是0到1,這是一個很 好的性質,我們可以把它的輸出理解為一個概率值或者是權重,即需要保留的程度, 當輸出為1時為全保留,當輸出為0時為全部不保留或者說全部遺忘(實際上, sigmoid函數不會就輸出0或者1),當輸出置于0和1之間時就是以一定程度保留。?
????????我們可以看到輸入依然是上一時間步的隱藏狀態和當前時間 步的輸入,也就是這個保留的程度是通過上一時間步的隱藏狀態和當前時間步的輸入 學習得到的,也就是說LSTM模型對新輸入進行挑選的過程,而這種挑選又是基于以 前的經驗進行的。 現在我們已經單獨分析完輸入門的兩個分支了,它們結合就很簡單了,之間進行,i_t表示的是保留的程度是一個0到1之間g_t是傳統RNN 的部分表示原始的輸出,那么將他們相乘就很容易理解了,就是選擇一定程度的原始 輸入作為輸出。?
2.2、遺忘門(forget gate)
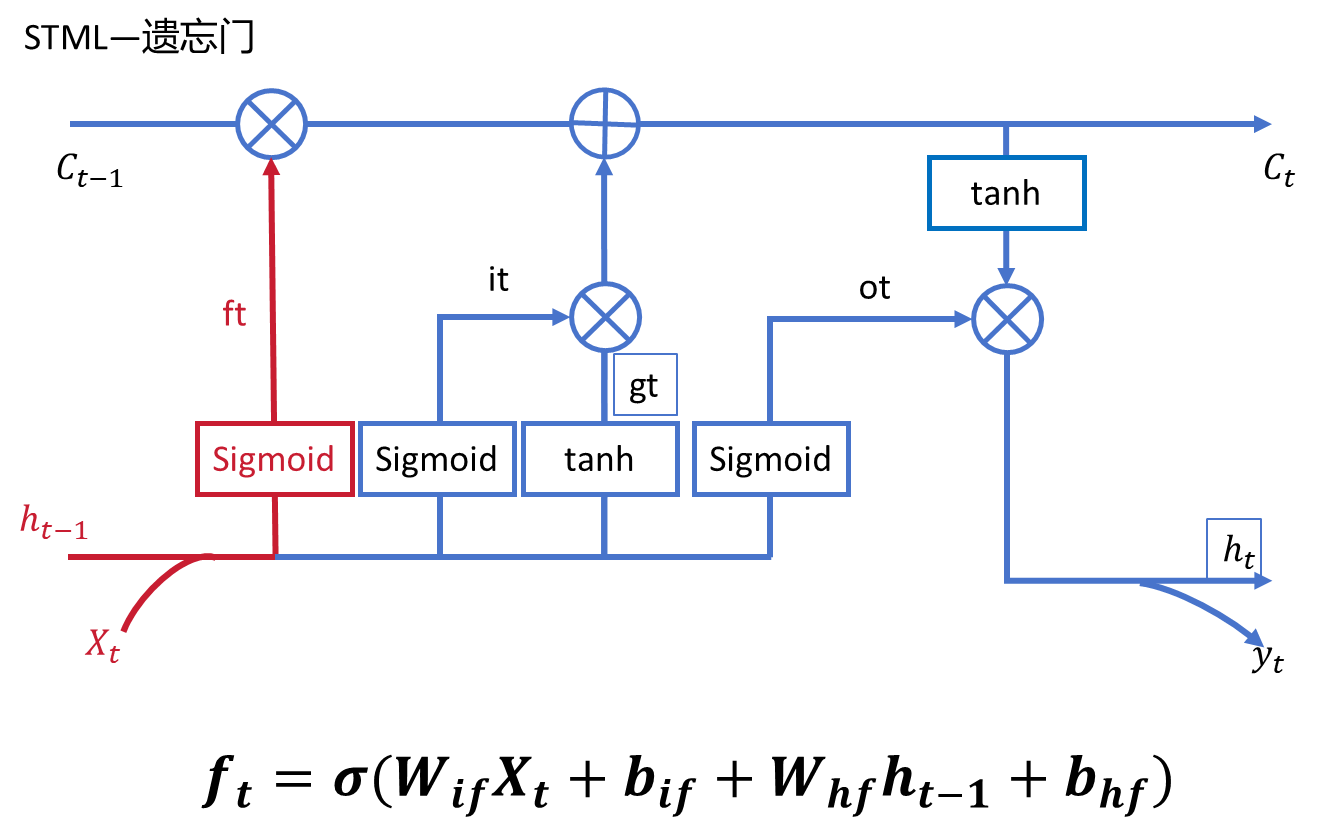
????????sigmoid的作用就很清晰了,充當的就是‘門’的結構,即程度。在組 件中點擊LSTM下的forget gate 可以看到標紅部分就是遺忘門的結構。依然是輸入上 一時間步的隱藏狀態和當前時間步的輸入,經過sigmoid函數輸出,輸出的就是一個 介于0和1之間表示程度的值 。
說是‘遺忘’但本質上還是保留的程度
2.3、update cell state(細胞更新單元)
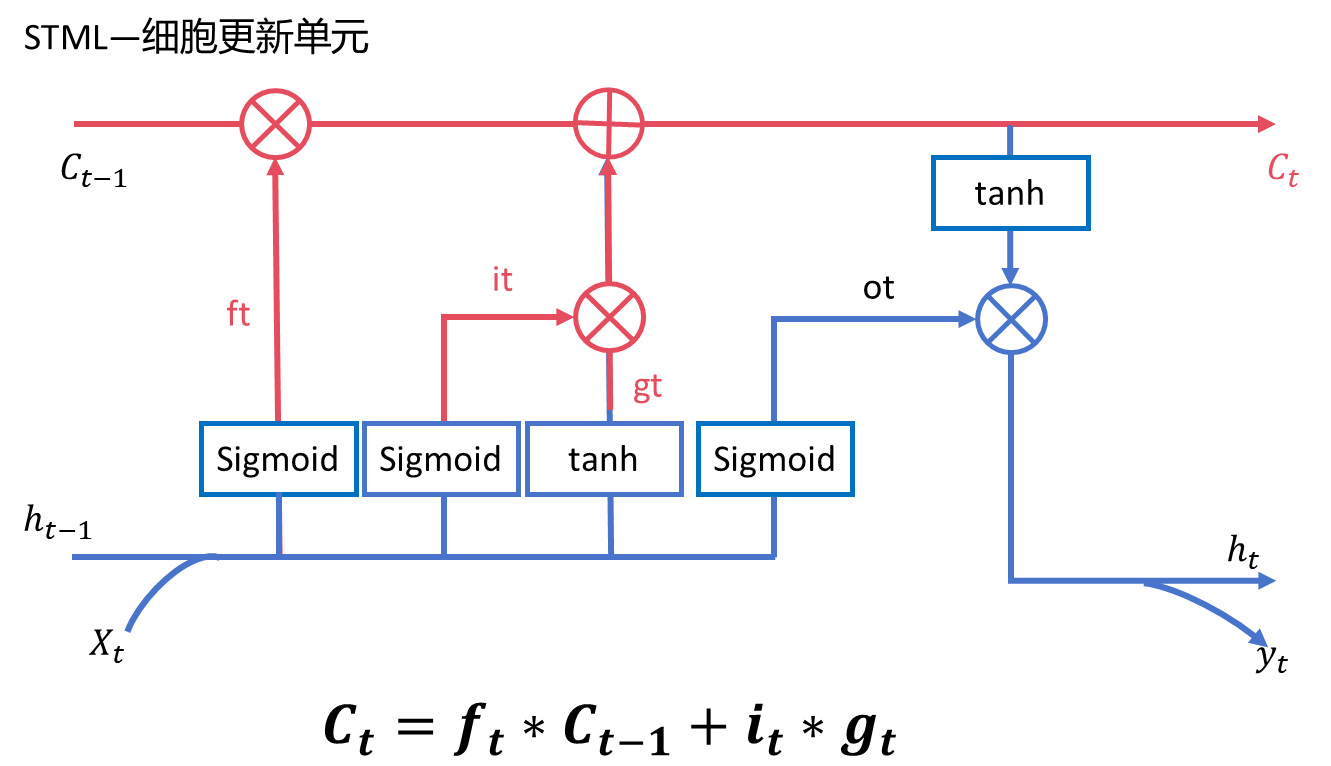
????????可以看到這個分支是隨著時間步進行更新的,遺忘門就是控制模型記憶的, 控制保留多少以前的記憶。然后加上 i_t和g_t 相乘的結果,實際上就是加上輸入門的輸 入結果,也就是說將多少當前時間步的信息加入到記憶之中。總的來說, 分支的信 息走向就是:先選擇性保留之前的記憶,再選擇性加入當前的信息,得到新的記憶。?
2.4、輸出門(output gate)
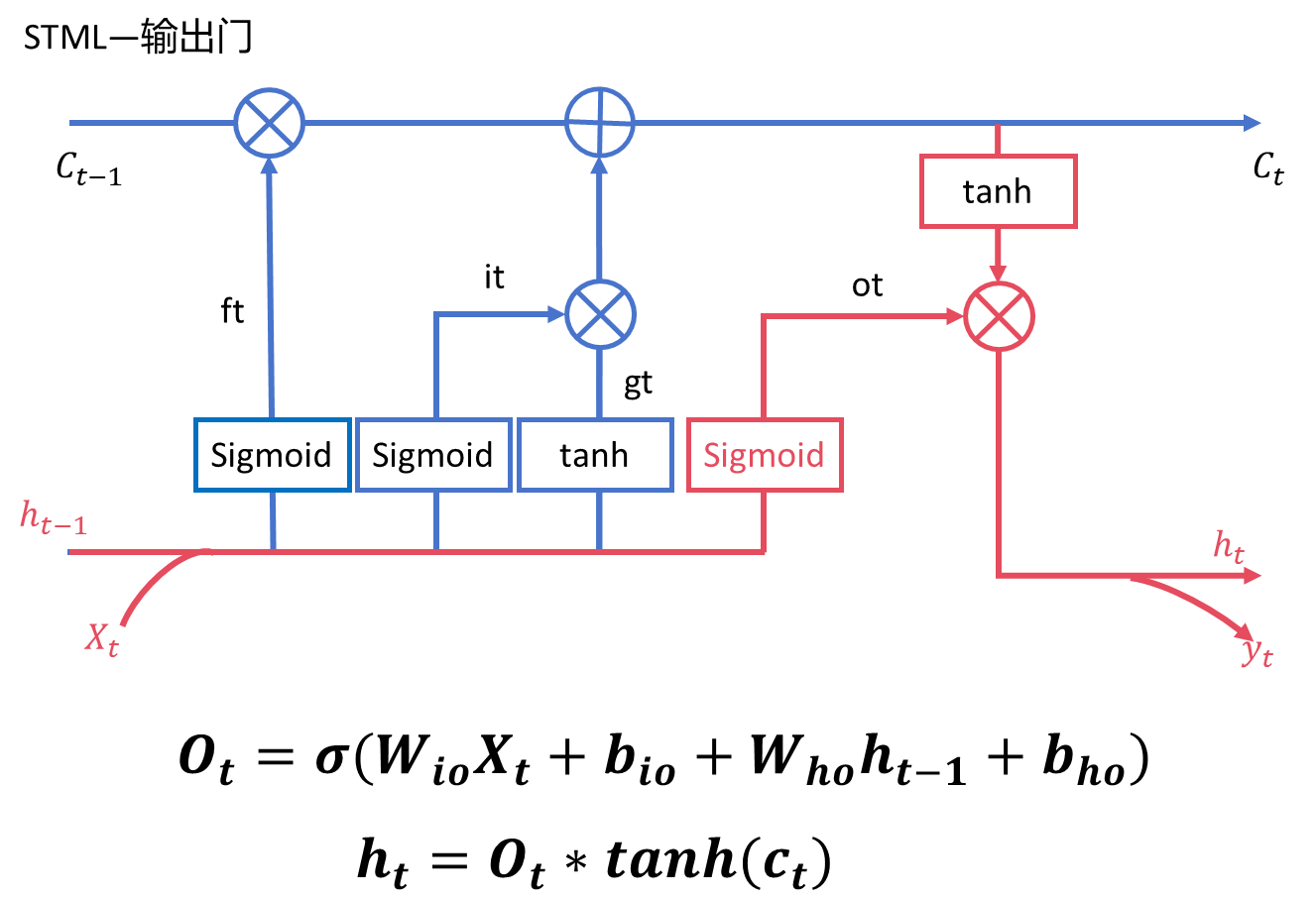
????????通過sigmoid函數控制輸出的程度,然后當前時刻的記憶經過tanh激活,再將兩者相乘得到了 即隱藏狀態的輸出。

import torch
import numpy as np
from torch import nn# 1. 字符輸入
text = "In Beijing Sarah bought a basket of apples In Guangzhou Sarah bought a basket of bananas"# 設置隨機種子,保證實驗的可重復性
torch.manual_seed(1)# 3. 數據集劃分
# input_seq 是輸入序列,去掉了最后一個字符
input_seq = [text[:-1]]
# output_seq 是目標序列,去掉了第一個字符,與 input_seq 錯開一位
output_seq = [text[1:]]
print("input_seq:", input_seq)
print("output_seq:", output_seq)# 4. 數據編碼:one-hot 編碼
# 獲取文本中所有不重復的字符
chars = set(text)
# 將字符排序,保證編碼的一致性
chars = sorted(list(chars))
print("chars:", chars)
# 創建字符到數字的映射字典
char2int = {char: ind for ind, char in enumerate(chars)}
print("char2int:", char2int)
# 創建數字到字符的映射字典
int2char = dict(enumerate(chars))
print("int2char:", int2char)
# 將輸入序列中的字符轉換為數字編碼
input_seq = [[char2int[char] for char in seq] for seq in input_seq]
print("input_seq:", input_seq)
# 將輸出序列中的字符轉換為數字編碼
output_seq = [[char2int[char] for char in seq] for seq in output_seq]
print("output_seq:", output_seq)# one-hot 編碼函數,用于將數字編碼轉換為 one-hot 向量
def one_hot_encode(seq, bs, seq_len, size):# 創建一個形狀為 (batch_size, seq_len, vocab_size) 的零矩陣features = np.zeros((bs, seq_len, size), dtype=np.float32)# 遍歷 batch 中的每個序列for i in range(bs):# 遍歷序列中的每個時間步for u in range(seq_len):# 將對應字符的索引位置設置為 1.0features[i, u, seq[i][u]] = 1.0# 將 numpy 數組轉換為 PyTorch 張量return torch.tensor(features, dtype=torch.float32)# 對輸入序列進行 one-hot 編碼
input_seq = one_hot_encode(input_seq, 1, len(text) - 1, len(chars))
# 將輸出序列轉換為 PyTorch 長整型張量,并調整形狀為 (seq_len * batch_size)
output_seq = torch.tensor(output_seq[0], dtype=torch.long).view(-1)
print("output_seq:", output_seq)# 5. 定義前向模型
class Model(nn.Module):def __init__(self, input_size, hidden_size, out_size):super(Model, self).__init__()self.hidden_size = hidden_size# 定義一個 LSTM 層,輸入維度為 input_size,隱藏層維度為 hidden_size,層數為 1,batch_first=True 表示輸入張量的第一個維度是 batch sizeself.lstm1 = nn.LSTM(input_size, hidden_size, num_layers=1, batch_first=True)# 定義一個全連接層,將 LSTM 的輸出映射到詞匯表大小self.fc1 = nn.Linear(hidden_size, out_size)def forward(self, x):# 通過 LSTM 層得到輸出和隱藏狀態# out 的形狀為 (batch_size, seq_len, hidden_size)# hidden 是一個包含 (h_n, c_n) 的元組,每個的形狀為 (num_layers, batch_size, hidden_size)out, hidden = self.lstm1(x)# 將 LSTM 的輸出調整形狀為 (seq_len * batch_size, hidden_size),以便輸入到全連接層x = out.contiguous().view(-1, self.hidden_size)# 通過全連接層得到最終的輸出x = self.fc1(x)return x, hidden# 實例化模型,輸入大小為詞匯表大小,隱藏層大小為 32,輸出大小為詞匯表大小
model = Model(len(chars), 32, len(chars))# 6. 定義損失函數和優化器
# 使用交叉熵損失函數,常用于多分類問題
cri = nn.CrossEntropyLoss()
# 使用 Adam 優化器,學習率為 0.01
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)# 7. 開始迭代訓練
epochs = 1000
for epoch in range(1, epochs + 1):# 通過模型得到輸出和隱藏狀態output, hidden = model(input_seq)# 計算損失loss = cri(output, output_seq)# 清空梯度optimizer.zero_grad()# 反向傳播計算梯度loss.backward()# 更新模型參數optimizer.step()# 8. 顯示頻率設置if epoch == 1 or epoch % 50 == 0:print(f"Epoch [{epoch}/{epochs}], Loss {loss:.4f}")# 預測接下來的幾個字符
input_text = "I" # 初始輸入字符
to_be_pre_len = 20 # 預測的長度# 進行預測
for i in range(to_be_pre_len):# 將當前輸入文本轉換為字符列表chars = [char for char in input_text]# 將字符列表轉換為數字編碼的 numpy 數組character = np.array([[char2int[c] for c in chars]])# 對數字編碼進行 one-hot 編碼character = one_hot_encode(character, 1, character.shape[1], len(chars))# 將 numpy 數組轉換為 PyTorch 張量character = torch.tensor(character, dtype=torch.float32)# 將 one-hot 編碼的輸入送入模型進行預測out, hidden = model(character)# 獲取最后一個時間步輸出中概率最大的字符的索引char_index = torch.argmax(out[-1]).item()# 將預測的數字索引轉換為字符,并添加到輸入文本中input_text += int2char[char_index]
# 打印預測結果
print("預測到的:", input_text)?
三、LSTM“不會”梯度消失和梯度爆炸的原因
3.1、RNN的梯度消失和梯度爆炸
????????梯度消失和梯度爆炸是由于RNN的在時間維度上的權值 進行了共享,導致計算梯度時會進行連乘,連乘會導致梯度消失或者梯度爆炸,但是 需要注意的是:當時間步長的時候,連乘的負面效應才會顯現的更加明顯,即意味 著:近距離(近期記憶)并不會消失,但是遠距離(連乘的多了)才會有梯度消失和 梯度爆炸的問題。也就是說:RNN 所謂梯度消失的真正含義是,梯度被近距離梯度 主導,導致模型難以學到遠距離的依賴關系。這其實和傳統的MLP結構的梯度消失和 梯度爆炸并不同,因為傳統MLP在不同的層中并不會權值共享。
3.2、LSTM為什么“不會”梯度消失和梯度爆炸
LSTM也會梯度消失和梯度爆炸!
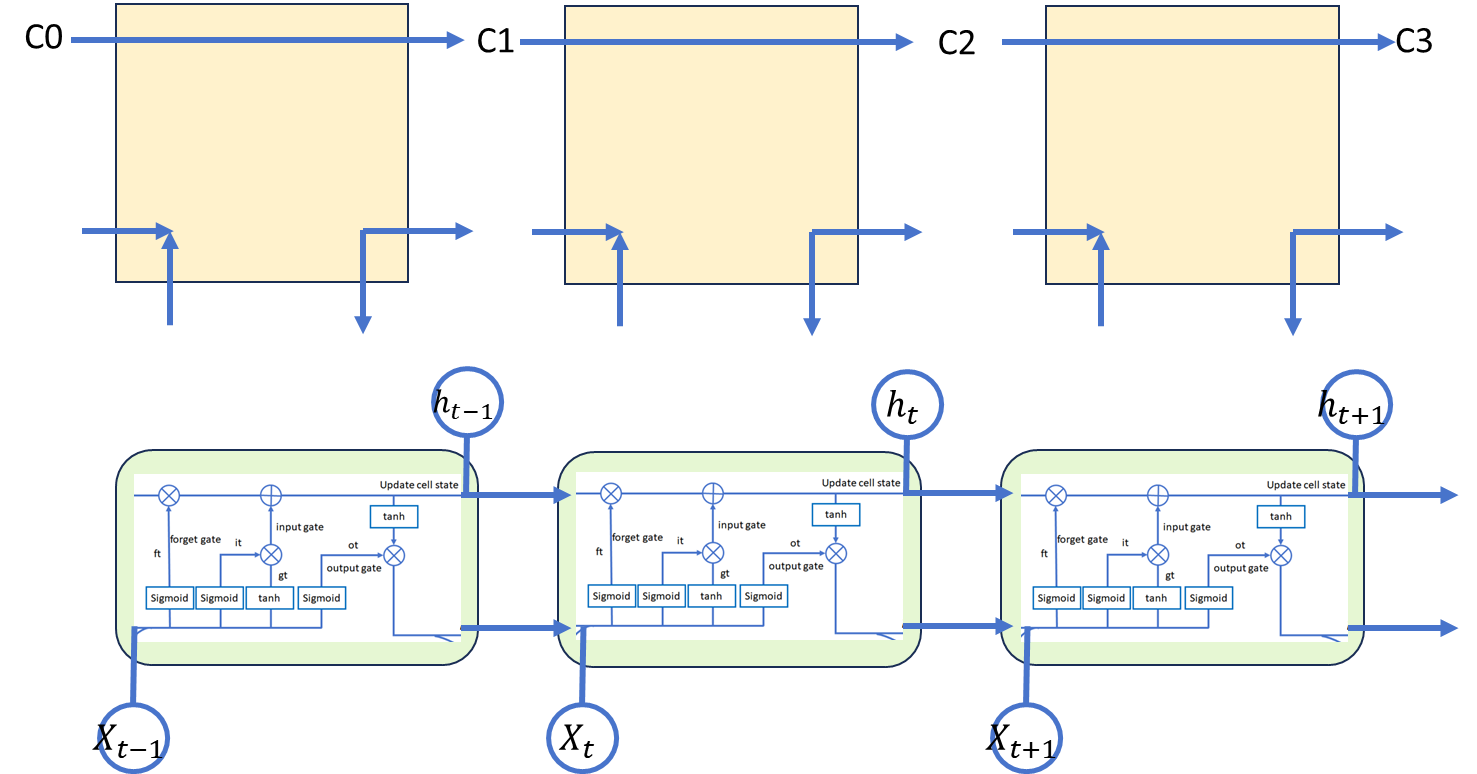

對于現在的LSTM有三種情況:
????????1、如果我們把讓遺忘門的輸出趨近于1,例如模型初始化時會把 forget bias 設置成 較大的正數,讓遺忘門飽和),這時候遠距離梯度不消失;
????????2、遺忘門接近 0,但這時模型是故意阻斷梯度流的(例如情感分析任務中有一條樣 本 “A,但是 B”,模型讀到“但是”后選擇把遺忘門設置成 0,遺忘掉內容 A,這是合理 的);
????????3、如果 f 介于 [0, 1] 之間的情況,在這種情況下只能說 LSTM 改善(而非解決)了 梯度消失的狀況。
?




![[爬蟲知識] Cookie與Session](http://pic.xiahunao.cn/[爬蟲知識] Cookie與Session)




)


)

的類型詳解)




