目錄
一、RAGFlow 框架
二、Dify 框架
三、兩者集成
四、深度對比
1. 核心定位對比
2. 核心功能對比
3. 技術架構對比
4. 部署與成本
5. 適用場景推薦
總結
一、RAGFlow 框架
RAGFlow 是一個專注于深度文檔理解和檢索增強生成(RAG)技術的框架。它的核心優勢在于結合了大規模檢索系統和生成式模型(如 GPT 系列),能夠從海量數據中快速定位相關信息,并生成符合上下文語義的自然語言回復。RAGFlow 支持多模態數據(如文本、圖片、表格等),并通過混合檢索技術(結合傳統檢索和深度學習模型)提高檢索結果的準確性和相關性。
RAGFlow是一個專為深度文檔理解和檢索增強生成而設計的引擎,它結合了預訓練的大型語言模型(LLMs)和高效的檢索技術,為用戶提供了一個強大的工具來處理復雜的問題和場景。RAGFlow的核心優勢在于其混合檢索能力,它能夠從大規模知識庫中檢索相關文檔,然后將這些信息與模型的生成能力相結合,生成更準確、更全面的答案。這種混合方法特別適用于處理需要深度理解和綜合多個信息源的問題,如智能客服、搜索引擎和知識庫應用。
RAGFlow的工作流程包括兩個主要部分:檢索和生成。在檢索階段,RAGFlow使用高效的檢索算法從知識庫中找到與用戶查詢最相關的文檔片段;在生成階段,這些片段被編碼并輸入到預訓練的模型中,模型在生成文本時會考慮這些檢索到的信息,從而生成更精確的答案。RAGFlow還支持多模態數據,如圖像和表格,以提供更全面的文檔理解和生成能力。
二、Dify 框架
Dify 是一個開源的 LLM(大型語言模型)應用開發平臺,旨在簡化生成式 AI 應用的創建和部署。它支持多種預訓練模型(如 DeepSeek、Claude3 等),并提供可視化的工作流編排工具,幫助開發者快速構建生產級 AI 應用。
Dify是一個開源的LLM應用開發平臺,它提供了一站式的解決方案,使得開發者能夠快速地從原型設計到產品部署。Dify的核心是其對LLM(大型語言模型)的集成,它支持多種預訓練模型,并且允許用戶自定義模型的訓練和微調。Dify的用戶界面直觀,功能全面,使得開發者無需具備深厚的技術背景,也能輕松地開發基于LLM的應用。
三、兩者集成
在RAGFlow與Dify的集成中,Dify充分利用了RAGFlow的深度文檔理解和檢索增強生成能力,將其無縫地融入到其應用開發流程中。這使得Dify用戶能夠構建更智能、更高效的文檔處理和知識檢索應用。通過Dify,開發者可以輕松地將RAGFlow的檢索結果與模型的生成能力相結合,實現對復雜文檔的深度理解和精準回答,從而提升應用的用戶體驗和問題解決能力。Dify的API支持也讓開發者能夠靈活地定制和擴展其應用功能,以滿足不同場景的需求。
四、深度對比
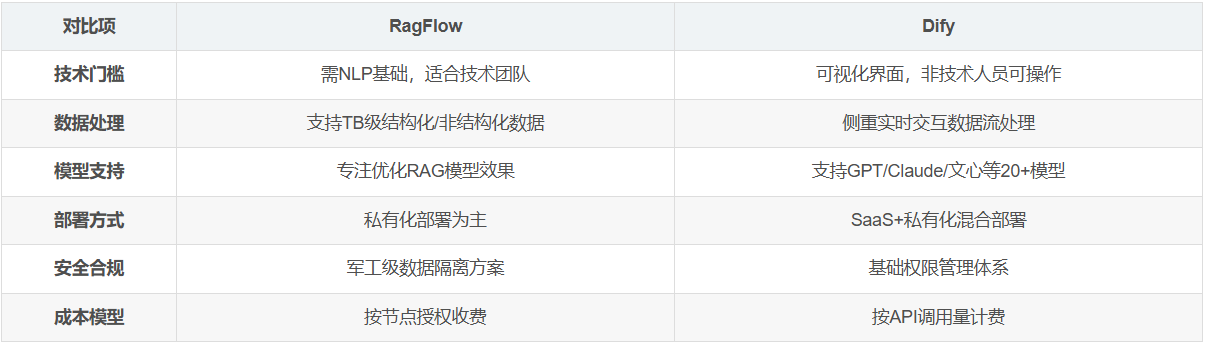
以下是?ragflow、Dify、FastGPT?的詳細對比,從功能定位、技術特點到適用場景進行綜合分析,幫助您根據需求選擇最合適的工具:
1. 核心定位對比
| 工具 | 核心定位 | 適用對象 |
|---|---|---|
| Ragflow | 專注于?RAG(檢索增強生成)?的引擎,強調復雜文檔解析與高精度知識檢索。 | 企業級用戶、需處理多格式數據的開發者。 |
| Dify | 通用型AI應用開發平臺,支持低代碼構建多種AI應用(如聊天機器人、自動化流程)。 | 開發者、企業需快速迭代AI功能的場景。 |
| FastGPT | 輕量級?對話生成框架,基于大模型快速部署問答系統,側重高效響應與簡單集成。 | 中小項目、需快速上線對話功能的場景。 |
2. 核心功能對比
| 功能 | Ragflow | Dify | FastGPT |
|---|---|---|---|
| 文檔處理 | ?? 多格式解析(PDF/Word/OCR/表格等) | ?? 基礎文本解析 | ?? 文本/簡單文件解析 |
| 檢索能力 | ?? 多路召回+重排序,支持結構化數據 | ?? 基于向量檢索,依賴外部模型 | ?? 基礎向量檢索 |
| 模型支持 | ? 固定RAG流程,依賴內置解析與檢索模型 | ?? 支持多模型(OpenAI、Claude、開源LLM、商用模型) | ?? 主要支持ChatGLM系列,可有限接入其他開源模型(支持中轉接口) |
| 可視化界面 | ?? 配置化界面 | ?? 低代碼工作流設計器 | ?? 簡單配置面板 |
| 擴展性 | ?? 插件擴展(數據源/解析器) | ?? API + 插件系統 + 代碼級自定義 | ? 僅支持基礎配置,無深度擴展接口 |
| 自動化流程 | ?? 自動化文檔解析→檢索→生成流水線 | ?? 可視化工作流編排(多模型協作+業務邏輯) | ? 僅問答流程自動化,無復雜邏輯控制 |
3. 技術架構對比
| 工具 | 技術棧 | 核心優勢 |
|---|---|---|
| Ragflow | Milvus + PostgreSQL + 自研解析算法,多路召回+LLM重排序。 | 高精度檢索,復雜文檔解析能力強,適合企業級場景。 |
| Dify | 微服務架構,支持云原生部署,集成LangChain等框架。 | 靈活可擴展,多模型支持,適合復雜業務流開發。 |
| FastGPT | 基于MongoDB + 向量數據庫,輕量級API架構。 | 部署簡單,響應快,資源占用低。 |
4. 部署與成本
| 工具 | 部署方式 | 開源情況 | 學習成本 |
|---|---|---|---|
| Ragflow | Docker/K8s,需較高配置資源。 | 開源(Apache 2.0) | 較高(需熟悉RAG流程) |
| Dify | 云服務/私有部署,支持Serverless。 | 核心開源,高級功能付費。 | 中等(可視化操作) |
| FastGPT | Docker一鍵部署,輕量級。 | 開源(MIT協議) | 低(配置簡單) |
5. 適用場景推薦
- 選擇 Ragflow:
需處理?PDF、掃描件、表格等復雜文檔,且對檢索精度要求高的場景,如法律合同分析、醫療報告處理。 - 選擇 Dify:
需要快速構建?多模型協作的AI應用(如智能寫作+數據分析),或需自定義復雜業務流程的企業。 - 選擇 FastGPT:
追求?低成本快速部署對話系統,如教育問答、電商客服等輕量級場景。
總結
1. RAGFlow:企業級復雜文檔處理專家
- 定位:專為高精度非結構化數據(PDF、掃描件、表格)檢索設計,強調工業級準確率。
- 核心優勢:
- 模型支持:內置多模態解析引擎(OCR、表格識別),檢索層集成混合檢索(關鍵詞+向量+語義),但生成層依賴固定模型,靈活性低。
- 擴展性:可通過插件接入企業私有數據源(如內部數據庫),或擴展文件解析器(如定制版式合同)。
- 自動化流程:從文檔上傳到答案生成全鏈路自動化,適合法律審查、金融報告分析等需嚴格流程控制的場景。
- 適用場景:醫療報告結構化、法律合同比對、學術論文解析。
2. Dify:低代碼AI應用工廠
- 定位:以可視化編排為核心,支持快速構建復雜AI應用(如客服+工單系統+數據分析混合應用)。
- 核心優勢:
- 模型支持:無綁定模型,可自由切換GPT-4、Claude、文心一言等,支持私有化部署開源模型(如LLaMA)。
- 擴展性:開放API與SDK,可集成外部服務(如CRM系統);支持自定義Python插件,滿足開發級需求。
- 自動化流程:通過拖拽式工作流設計器,實現多模型接力處理(如先分類用戶意圖→調用不同模型生成響應→記錄日志)。
- 適用場景:智能客服系統、自動化報表生成、多模型協作的營銷工具。
3. FastGPT:輕量級問答部署利器
- 定位:專注快速搭建垂直領域問答機器人,強調“開箱即用”與低資源消耗。
- 核心優勢:
- 模型支持:默認適配ChatGLM系列,輕量化微調(LoRA)支持領域知識快速注入,但對其他模型兼容性較差。
- 擴展性:僅提供基礎配置選項(如調整問答模版、修改檢索閾值),無法深度定制流程或集成外部系統。
- 自動化流程:問答鏈路自動化(用戶輸入→檢索→生成),但缺乏分支邏輯、多步驟交互等高級控制。
- 適用場景:教育知識庫問答、電商產品咨詢、企業內部FAQ系統。
的類型詳解)








)
 相關函數)
緩存穿透、緩存擊穿、緩存雪崩)



安裝教程詳解:第二篇)


![[原創]X86C++反匯編01.IDA和提取簽名](http://pic.xiahunao.cn/[原創]X86C++反匯編01.IDA和提取簽名)
