
看了b站一個清華博士的視頻做的筆記,對于人工智能的底層原理,訓練方式,以及生成式文本輸出,圖片生成的底層原理有了一個了解,算是一個還不錯的科普文。之前一直想要了解一下機器學習的入門原理,神經網絡相關的,但是這個詞一聽好像于自己而言難度有點大了,但是b站的各種通俗易懂的科普視頻總會給我不一樣的輸入。
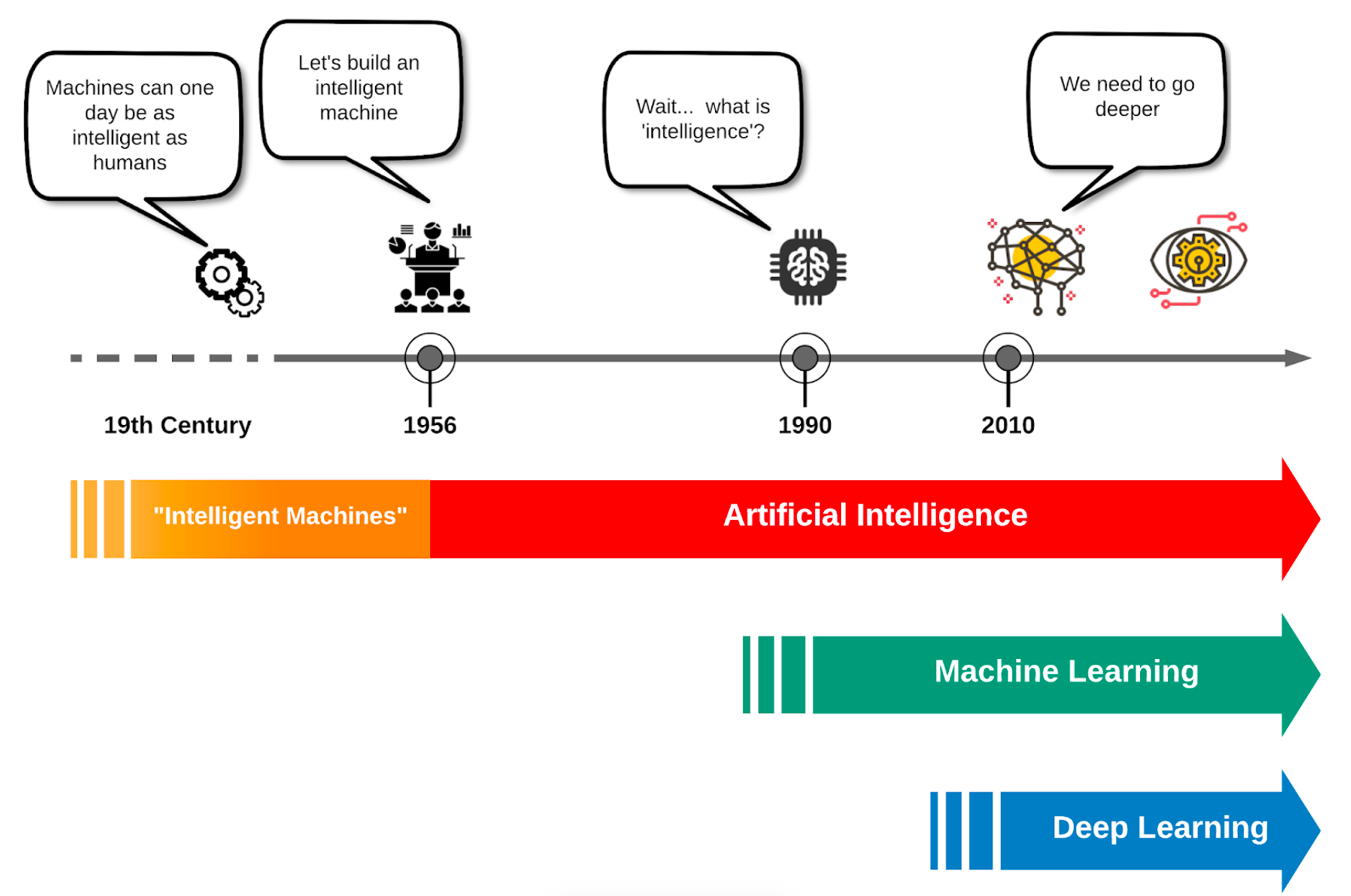
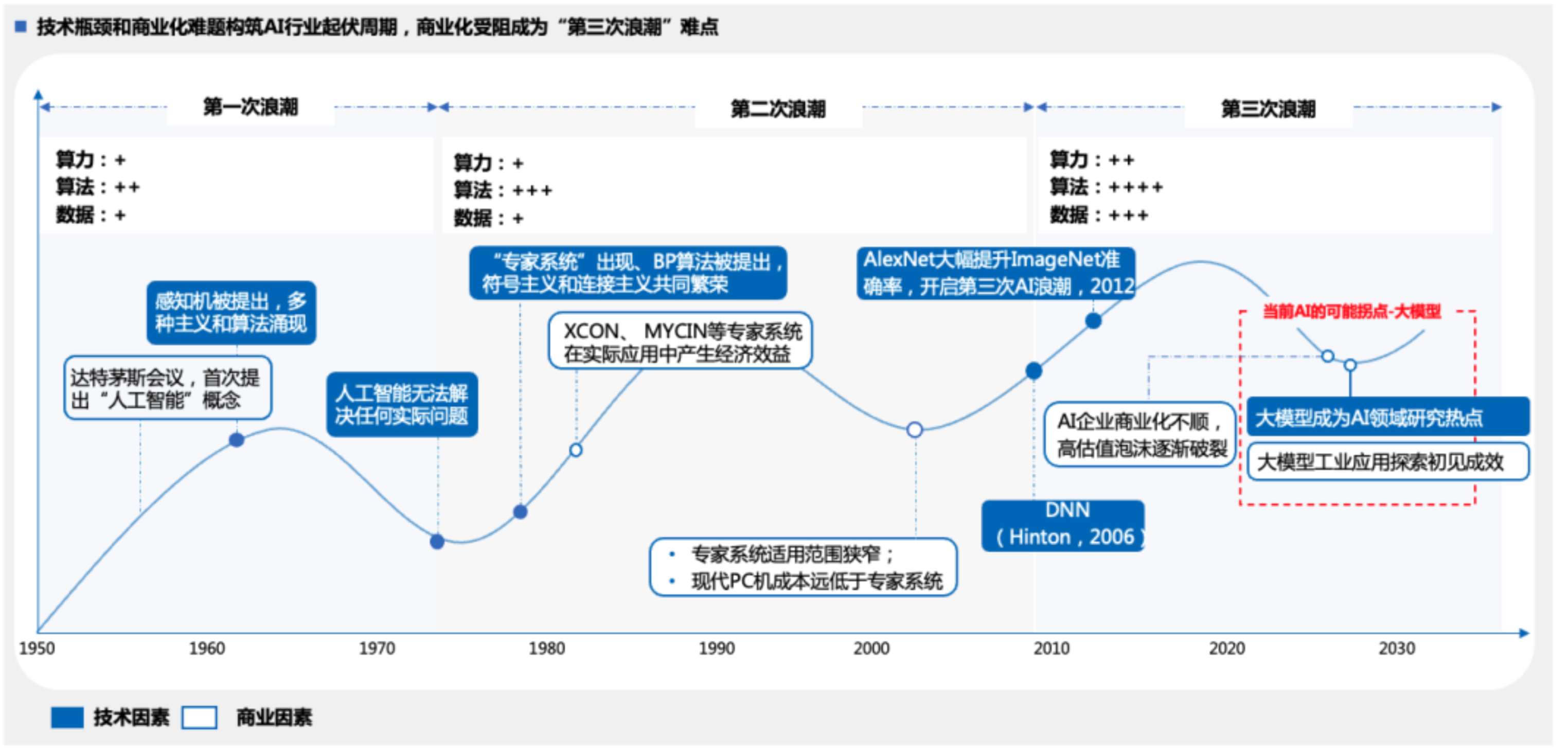
1. 人工智能發展的各階段
人工智能發展的幾個階段:
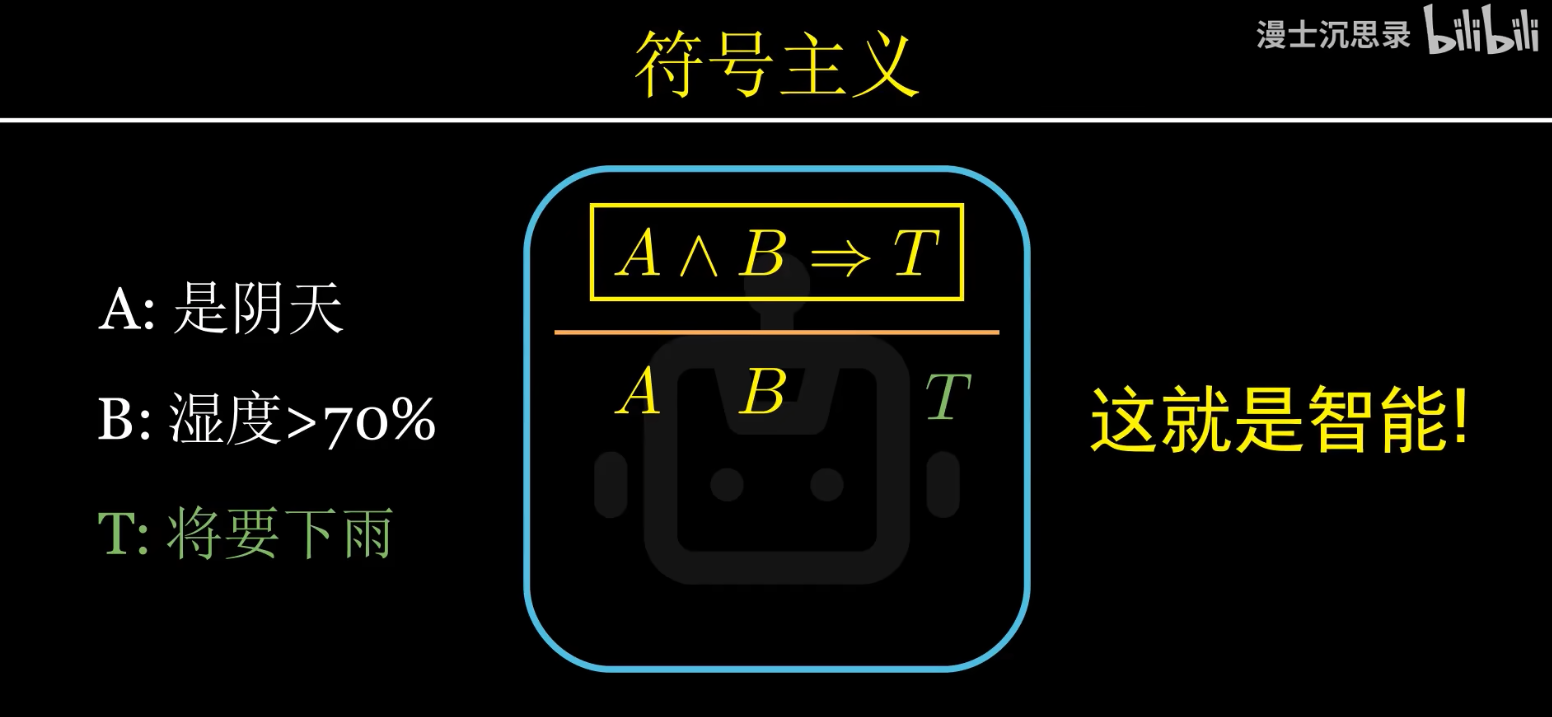
1)符號主義:
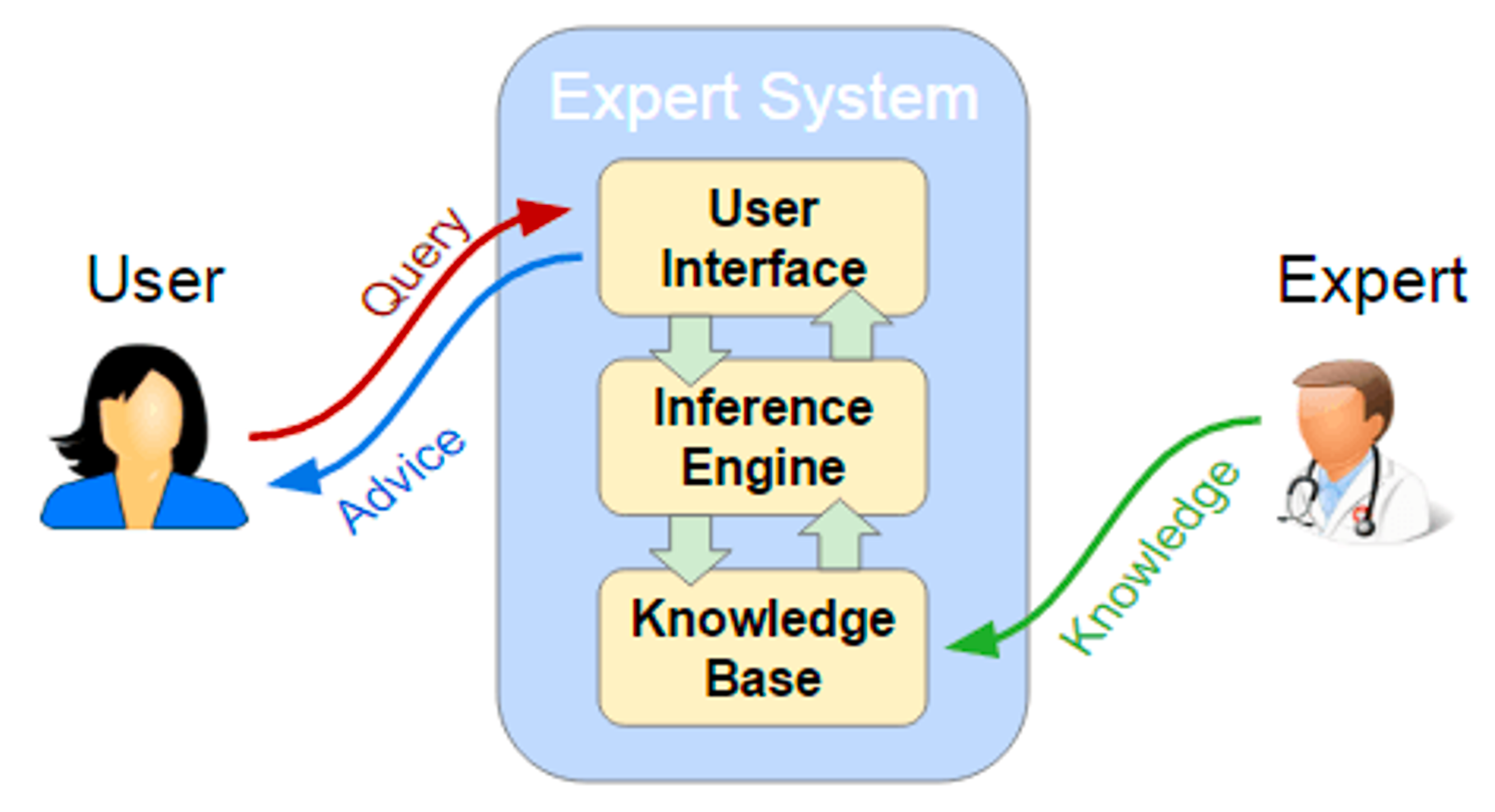
1960-1970年代:早期專家系統 ,在這個時期,AI研究主要集中在符號主義,以邏輯推理為中心。此時的AI主要是基于規則的系統,比如早期的專家系統。
2)聯結主義:
又稱為神經網絡或基于學習的AI .
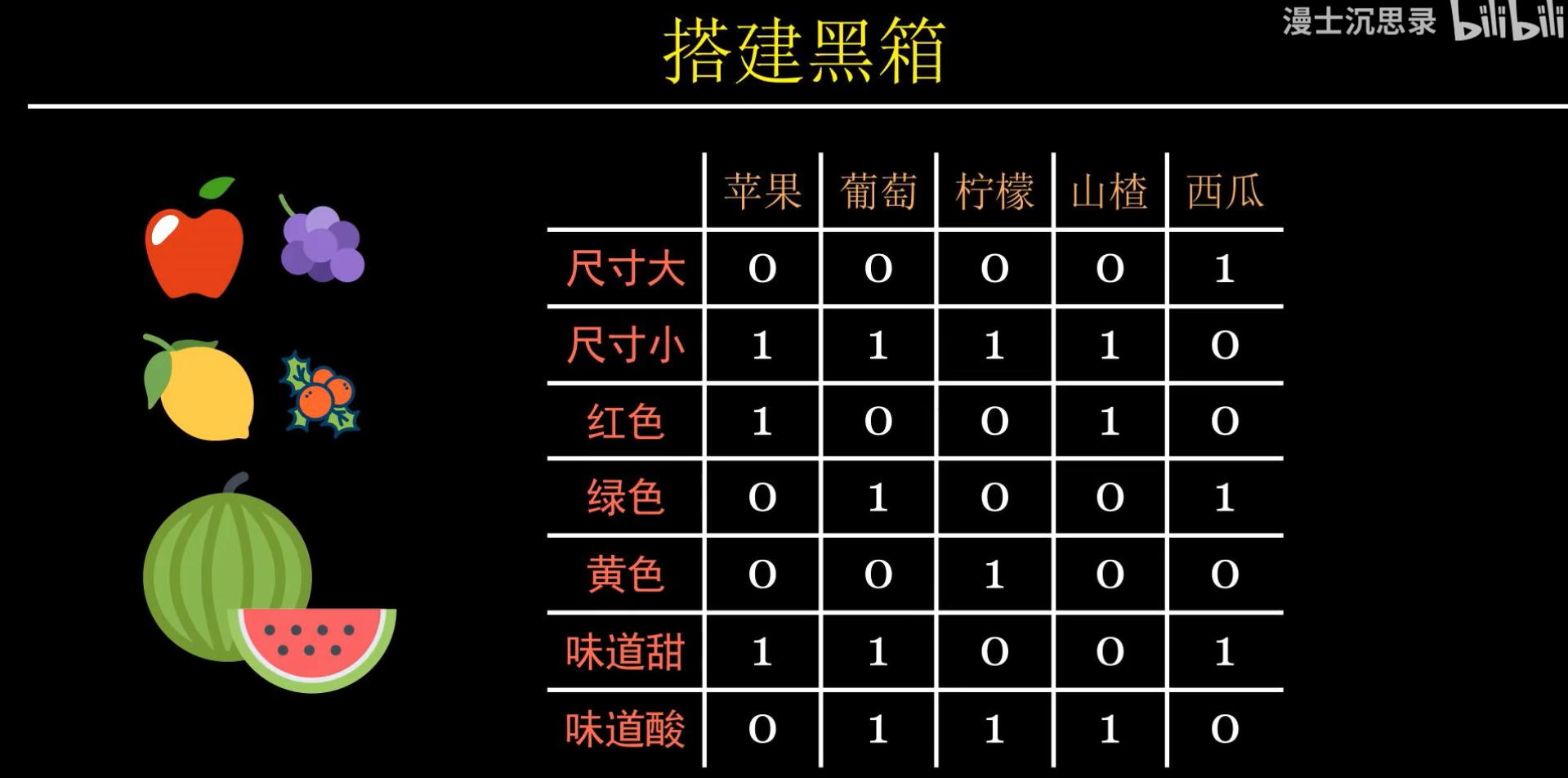
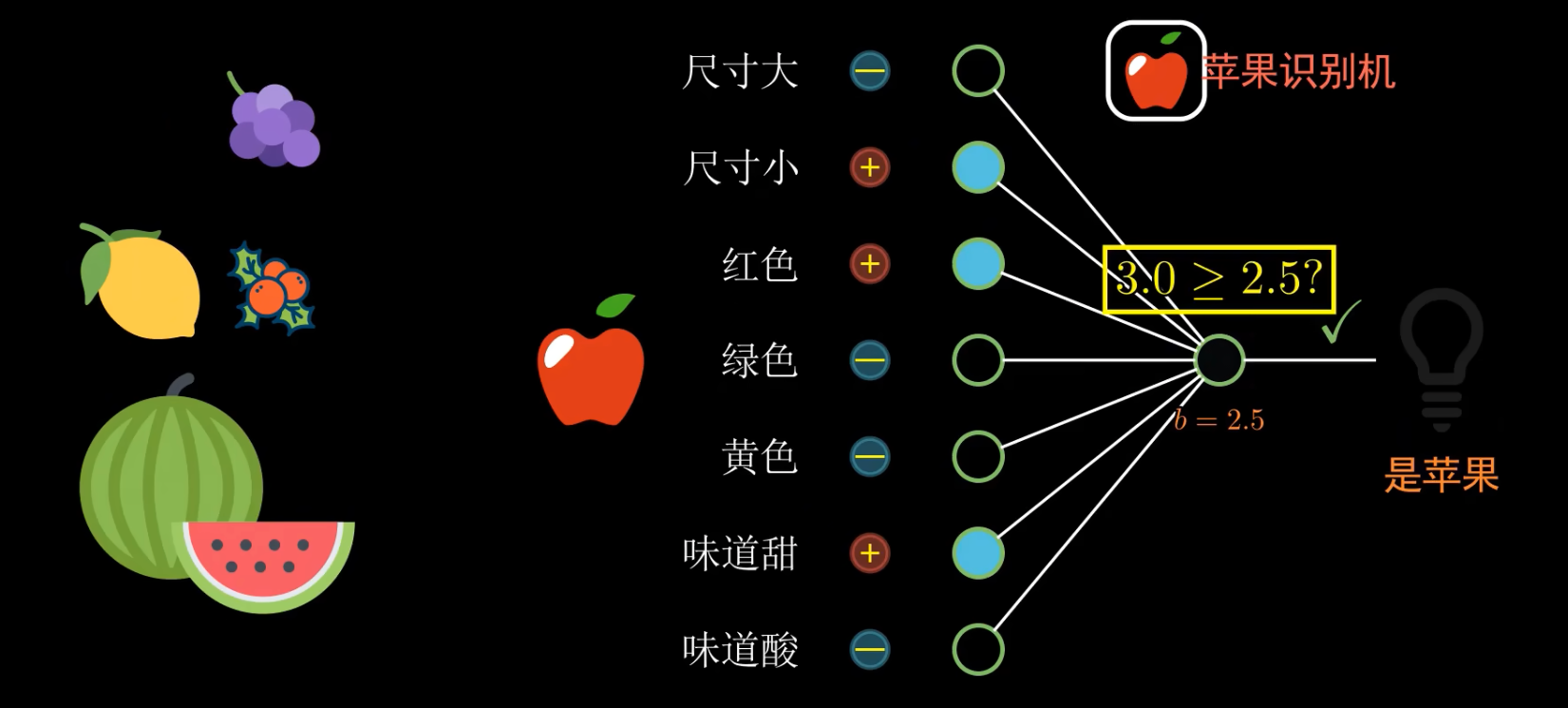
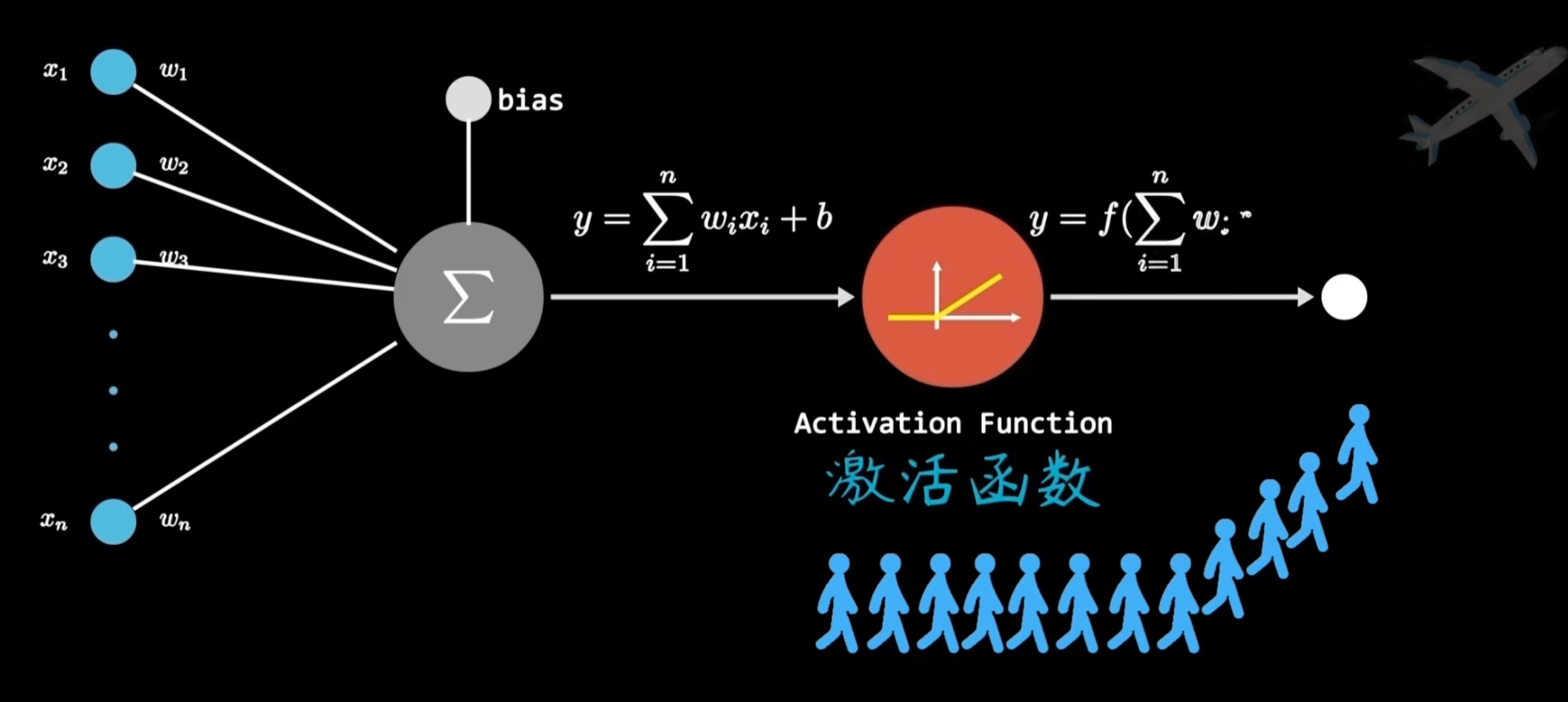
例如這個黑箱要識別一個蘋果,它會根據不同的描述特征來對蘋果進行識別,分別乘以一個正相關和負相關的系數,最后得出一個值:
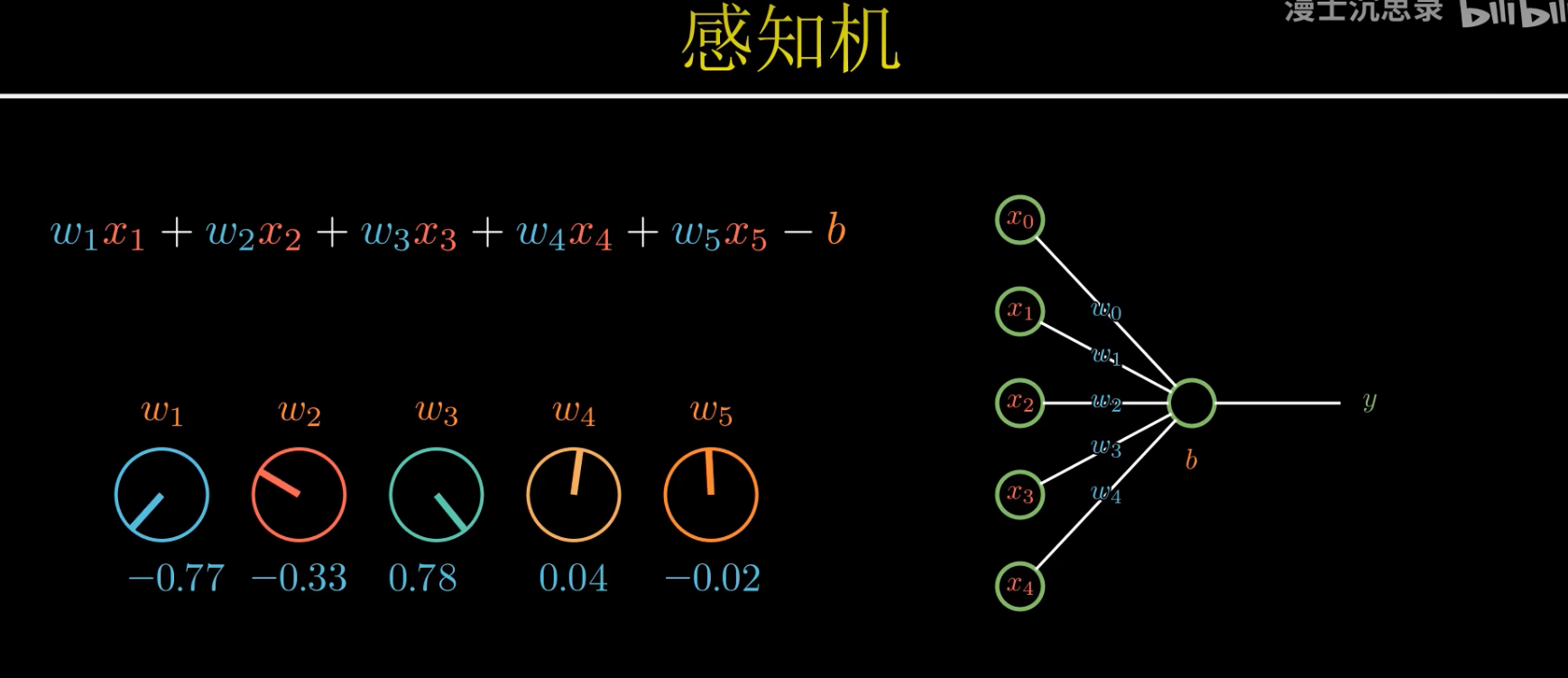
計算系數:感知機,類似神經元
識別結果:
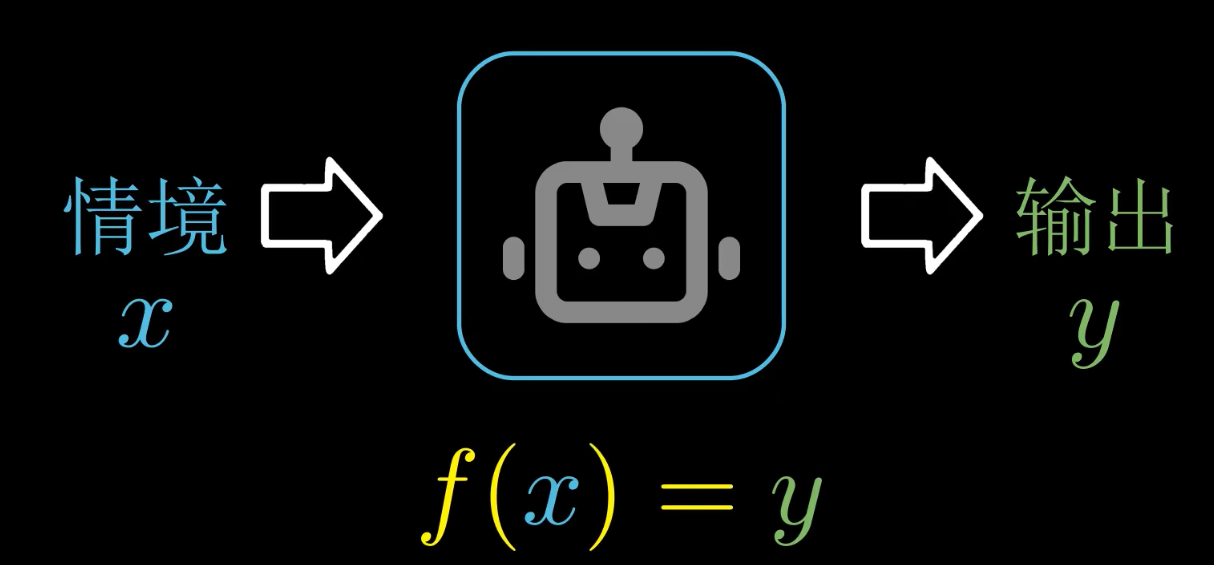
2. 智能的本質
智能的本質就是針對不同的情景給出針對性的輸出反應

用數學公式簡單可以表達為: (Funcitons describe the world !)
3. 神經網絡
神經網絡這個詞聽起來就比較復雜,《深度學習革命》一書中針對這個詞的來源進行了非常詳細的來源記錄,它正式被提出是在1958年,心理學家Frank Rosenblatt提出感知機(Perceptron),這是第一個可訓練的神經網絡模型,用于模式識別。Rosenblatt在論文中明確使用了“神經網絡”(neural network)一詞,強調其與生物神經系統的相似性。
經常聽到像卷積神經網CNN,循環神經網絡RAN,生成對抗網絡GAN,圖神經網絡GNN這些術語,其實這些都是深度學習的算法模型,屬于深度學習的使用工具。在實際的場景中經常會多個結合一起使用。
那么深度學習=神經網絡? 實際上深度學習是使用多層神經網絡的方法,但神經網絡本身只是其中一種技術。
人工智能(AI) #讓機器模仿人類智能的大概念(比如會下棋、識圖的機器都算AI)。
│
└── 機器學習(ML) #AI的一個分支,通過數據自動學習規律(比如用大量貓狗圖片訓練模型區分貓狗)。 │└── 深度學習(DL) #機器學習的一個分支,用多層神經網絡模擬人腦學習(比如用CNN識別圖片中的貓)。│├── CNN:處理圖像(掃描局部特征)├── RNN:處理序列(帶記憶分析)└── GAN:生成數據(真假對抗)不同算法模型的對比:
| 模型 | 中文全稱 | 核心能力 | 典型應用場景 | 優點 | 缺點 |
| CNN | 卷積神經網絡 | 圖像特征提取 | 人臉識別、醫學影像 | 局部感知、參數共享 | 不擅長序列數據 |
| RNN/LSTM | 循環神經網絡/長短期記憶網絡 | 序列建模 | 語音識別、文本生成 | 記憶上下文信息 | 計算效率低、長序列處理弱 |
| GAN | 生成對抗網絡 | 數據生成 | AI繪畫、圖像修復 | 生成質量高 | 訓練不穩定 |
| Transformer | Transformer(無通用中文譯名) | 全局依賴建模 | 機器翻譯、文本生成 | 并行計算、長距離依賴強 | 資源消耗大 |
| ResNet | 殘差網絡 | 極深網絡訓練 | 圖像分類、目標檢測 | 解決梯度消失 | 結構復雜 |
| 自編碼器 | 自編碼器 | 數據壓縮與重建 | 圖像去噪、異常檢測 | 無監督學習 | 生成能力有限 |
| GNN | 圖神經網絡 | 圖結構分析 | 社交網絡、藥物研發 | 建模復雜關系 | 計算復雜度高 |
| CapsNet | 膠囊網絡 | 空間層次理解 | 姿態估計 | 對空間變換魯棒 | 應用不廣泛 |
看到b站有個對神經網絡的比喻,感覺還蠻貼合的的,神經網絡有點類似機場的構造,不過機場流動是單向的,不過神經網絡有反向傳播。下面這個是操作動線類比,
機場動線:值機柜臺 → 安檢門 → 免稅店 → 登機口 → 起飛
神經網絡:輸入層 → 隱藏層1(激活)→ 隱藏層2(激活)→ 輸出層 → 預測結果

神經元就是機場的各個服務節點,例如安檢口,行李托放點,免稅店等,
激活函數就等于各個通道的開關邏輯,例如安檢口檢查到違規金屬就攔截,否則放行; vip 通道可以讓vip 客戶直接放行,經濟艙客戶需要派對等候放行;
損失函數就是類似客戶滿意度調查,也就是實際登機時間和預期登機時間的差距;
梯度下降就是類似于流程優化,例如排隊時間過長需要增開通道或者人員配比。
舉個場景例子:
場景:訓練一個判斷「旅客是否攜帶違禁品」的神經網絡
- 輸入層:旅客的行李X光圖像(像素數據)
- 隱藏層1:安檢口初步識別金屬物品(邊緣檢測)
- 激活函數:ReLU決定是否觸發開箱檢查
- 隱藏層2:分析物品形狀是否匹配危險品數據庫
- 輸出層:Sigmoid輸出危險概率(0-1之間)
- 損失函數:對比預測結果與人工檢查結果
- 梯度下降:優化X光機靈敏度(權重)和開箱閾值(偏置)
通過數萬次「模擬旅客安檢」,最終讓系統自動學會精準識別危險品。
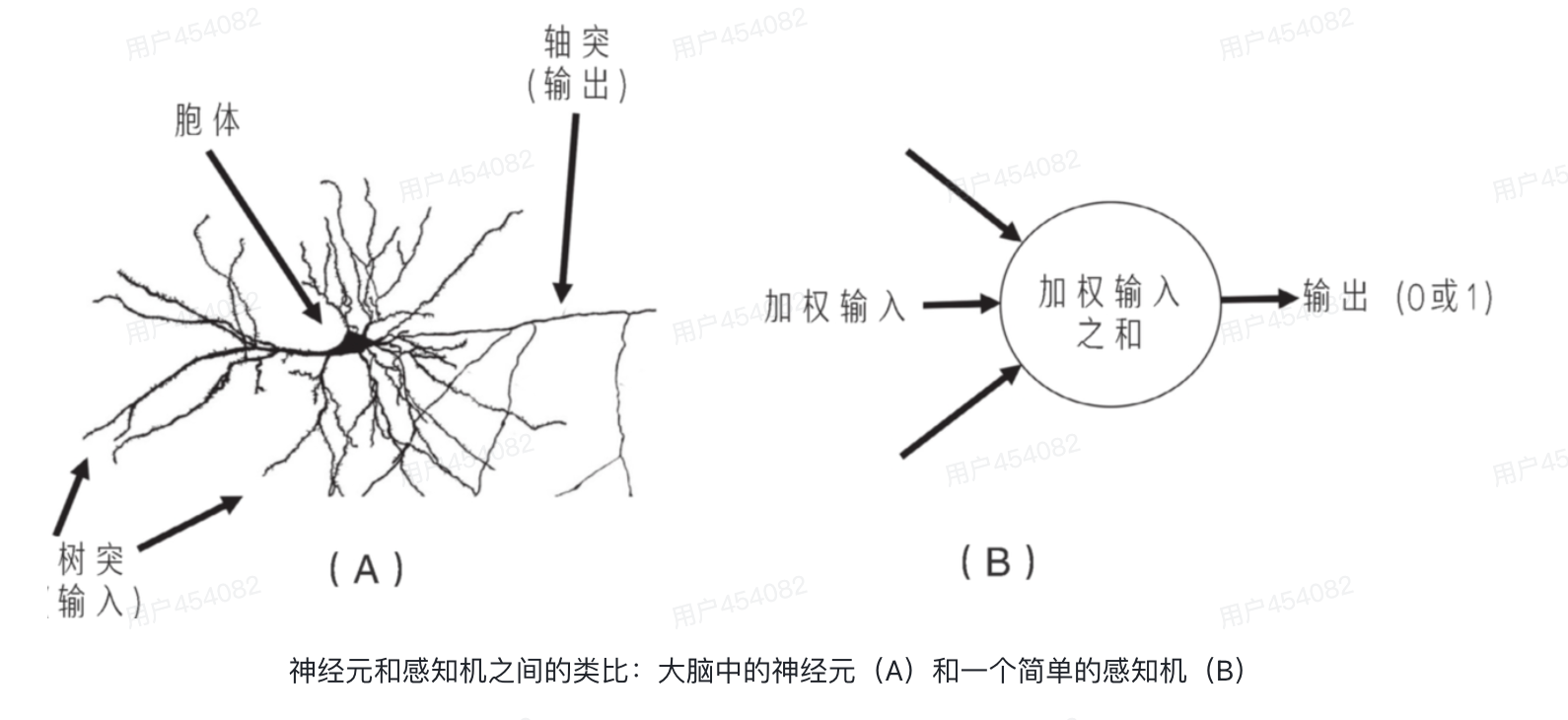
4. 感知機
最近看了人工智能的發展史才get 到感知機這個概念,這其實可以類比人的大腦神經結構:
簡單的說,一個神經元把它從其他神經元接收到的所有輸入信號加起來,如果達到某個特定的閾值水平,它就會被激活。
那么感知機是什么?
感知機就是一個根據加權輸入的總和是否滿足閾值來做出是或否(輸出1或0)的決策的簡單程序
?
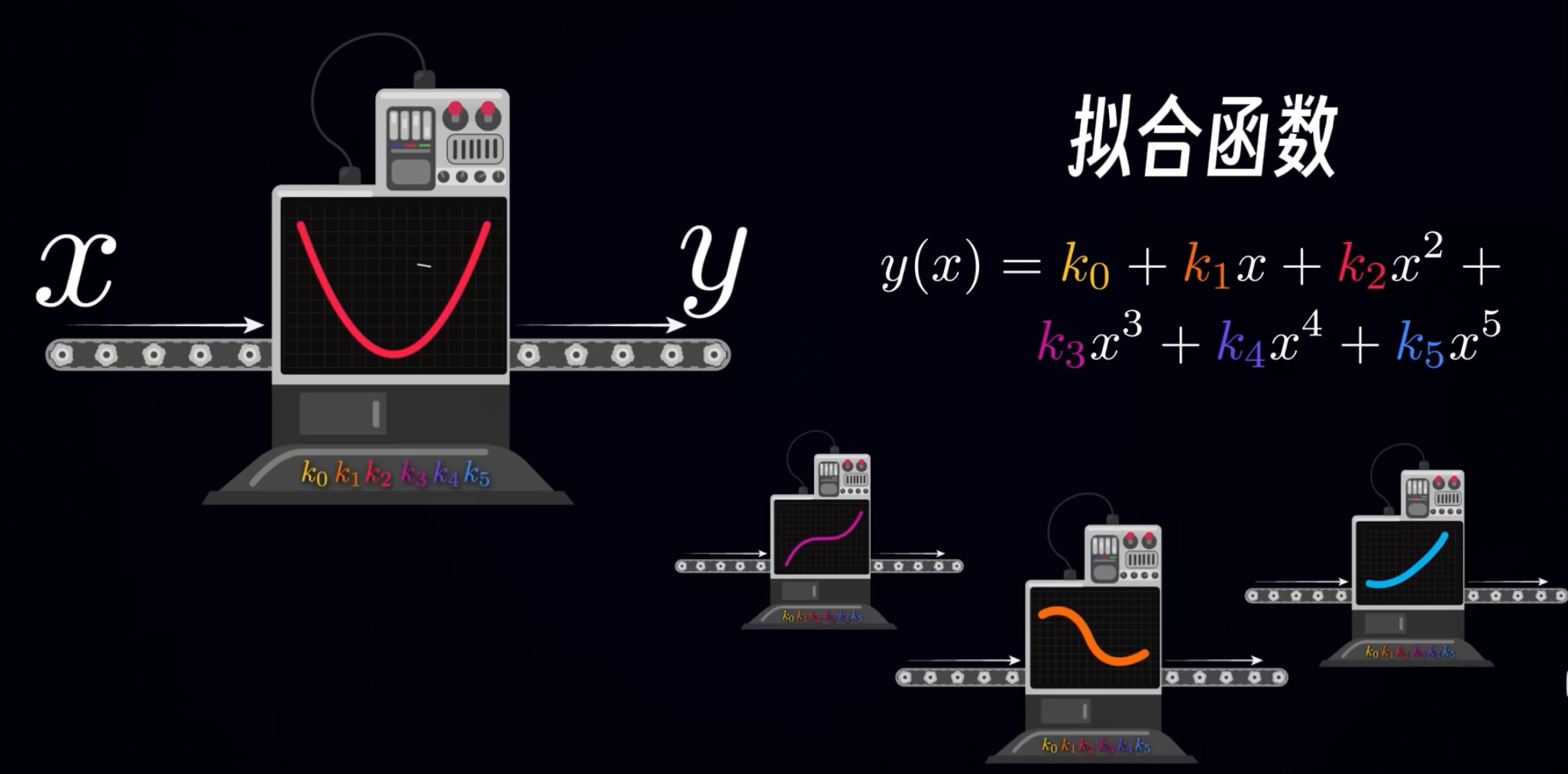
5. 擬合函數
擬合函數又叫預測函數,智能的本質是一個黑箱,這個黑箱能夠從輸入和輸出的聯系中找到一個對應關系,在數據驅動的智能領域中,所謂的智能,本質上就是給你一堆點,然后用一個函數擬合它們之間的關系。
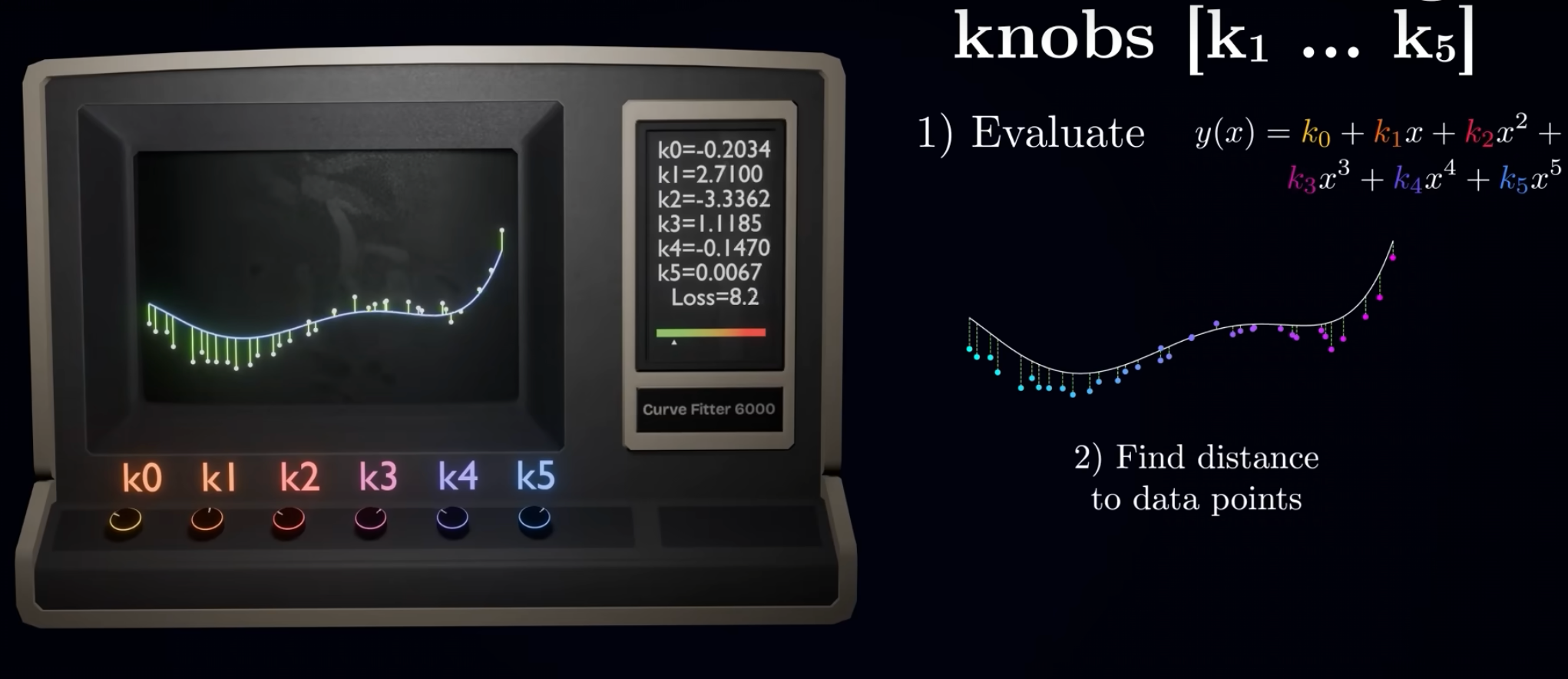
6. 損失函數
損失函數又叫代價函數。損失函數的值其實就是真實值與預測函數之間的差值大小,也就是針對每個x的輸出y值 和預測函數y值的絕對值差距大小。 損失函數值越小,輸出越精確
7. 激活函數
激活函數用于神經網絡中,用來決定神經元是否應該被激活,也就是是否將信號傳給下一代。它主要是用來在神經網絡中增加非線性,可以用來處理更復雜的情況
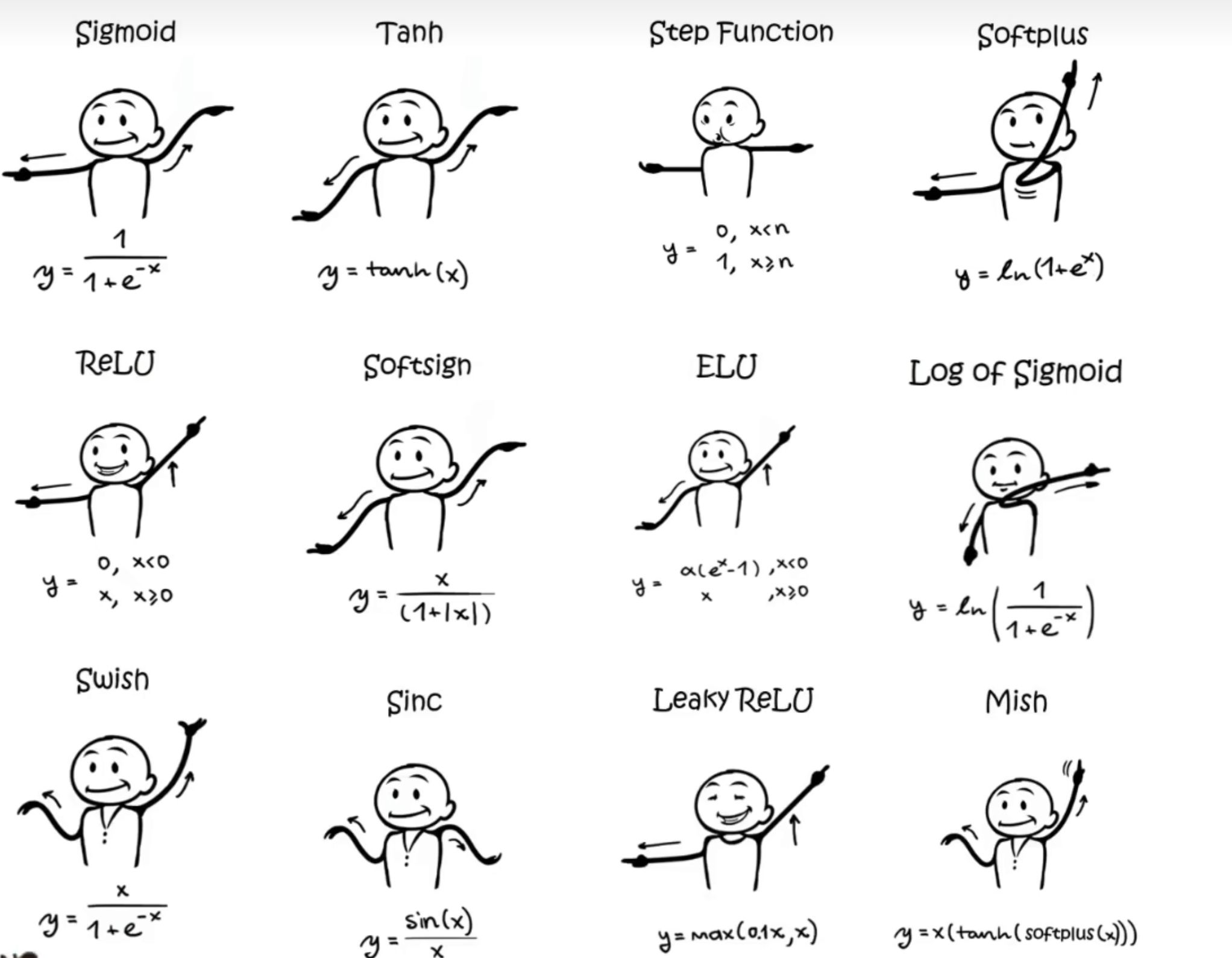
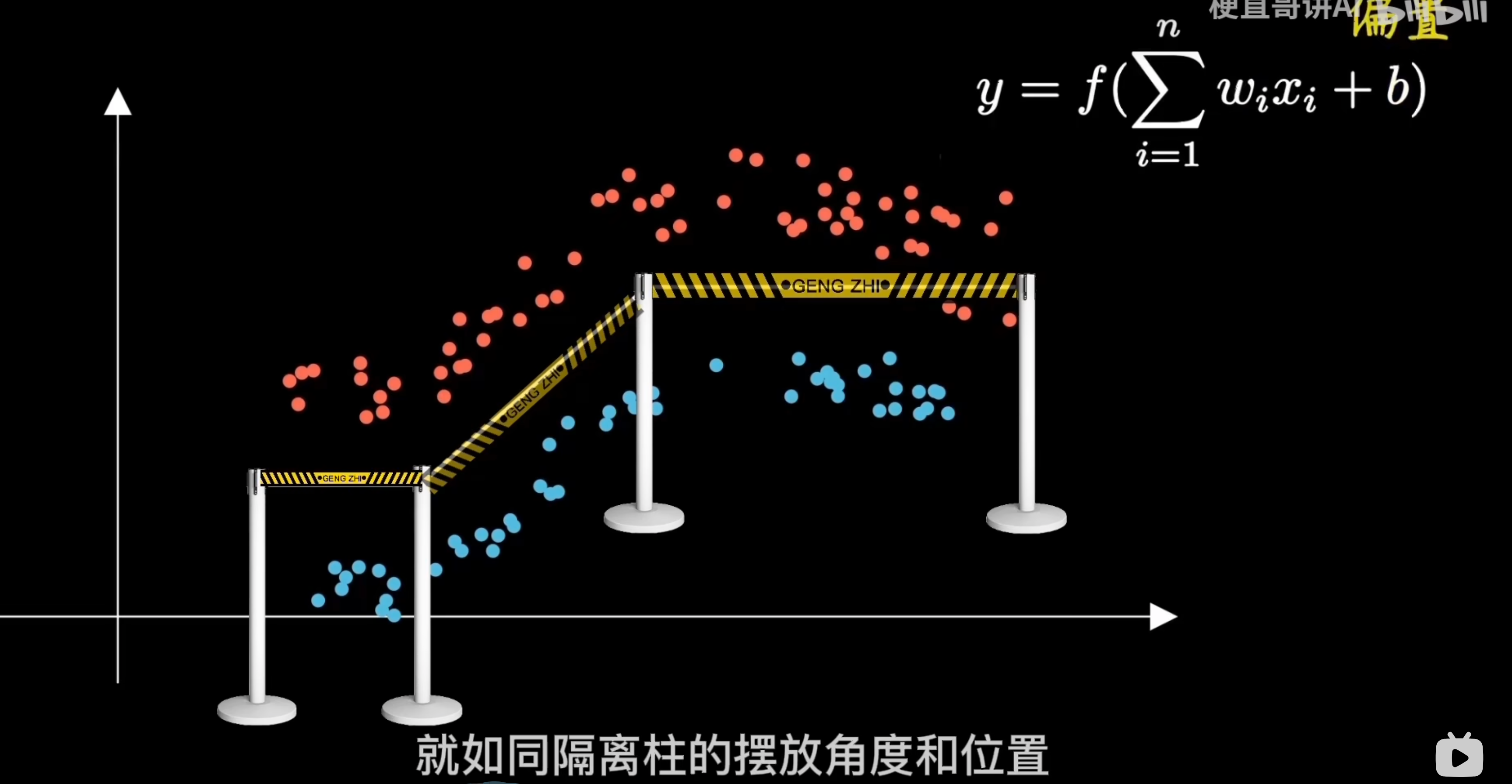
各種激活函數,最常用的是ReLU 。這個函數的形狀還有人將它比喻為排隊時候的隔離柱,直線折線曲線,隨意調整角度位置,
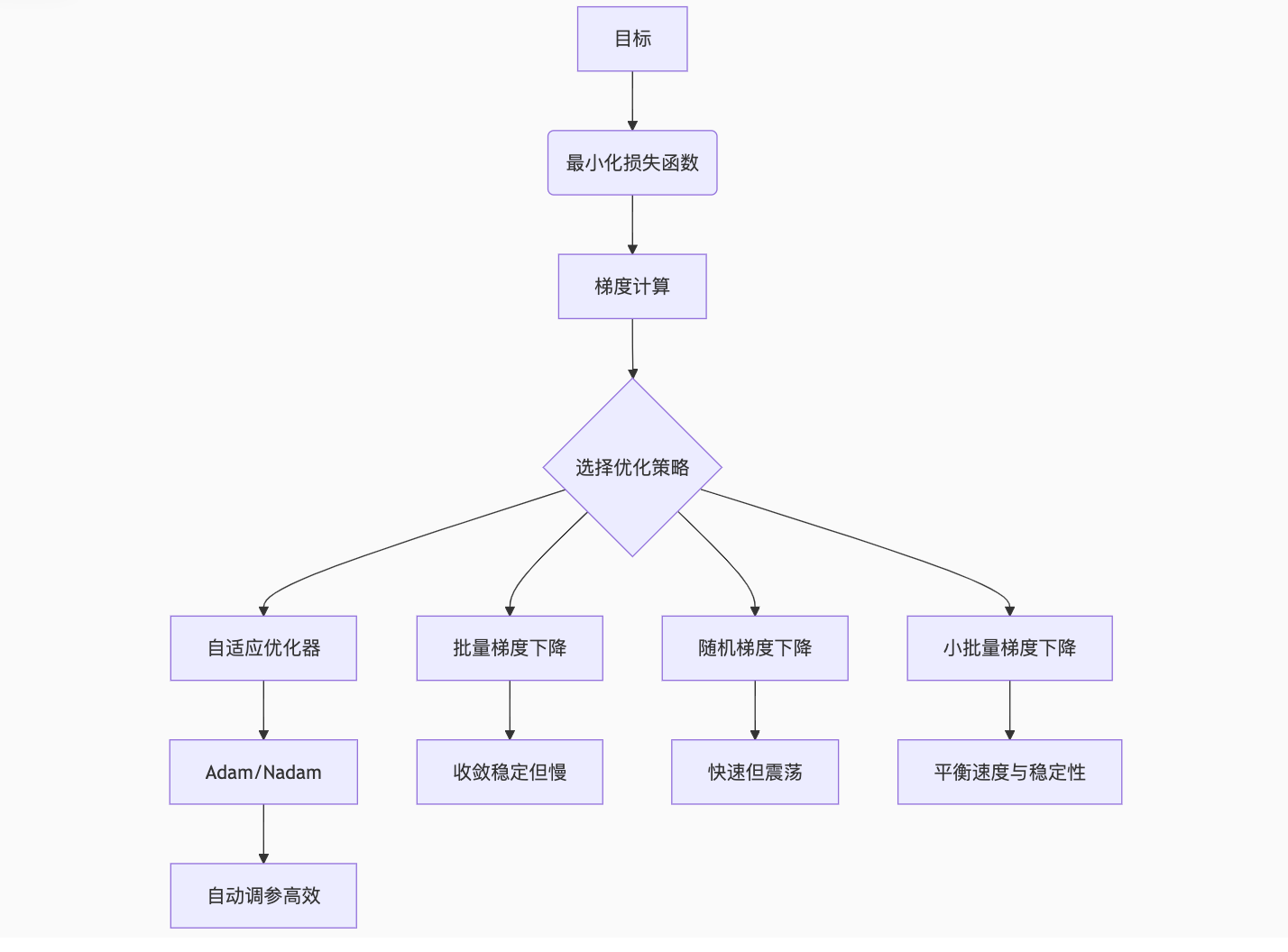
8. 梯度下降算法
梯度下降算法是眾多人工智能算法的基礎和鼻祖。 如何獎勵懲罰一個神經網絡,也就是如何通過數據來訓練網絡找到最好的參數:梯度下降 算法 ,梯度下降其實就是一種優化方法,用來調整模型的參數,使得損失函數值最小化。
類比就是如果你要快速下山,那么每次你需要找到往下最陡峭的點然后一步一步調整下去,步長其實就是學習率。

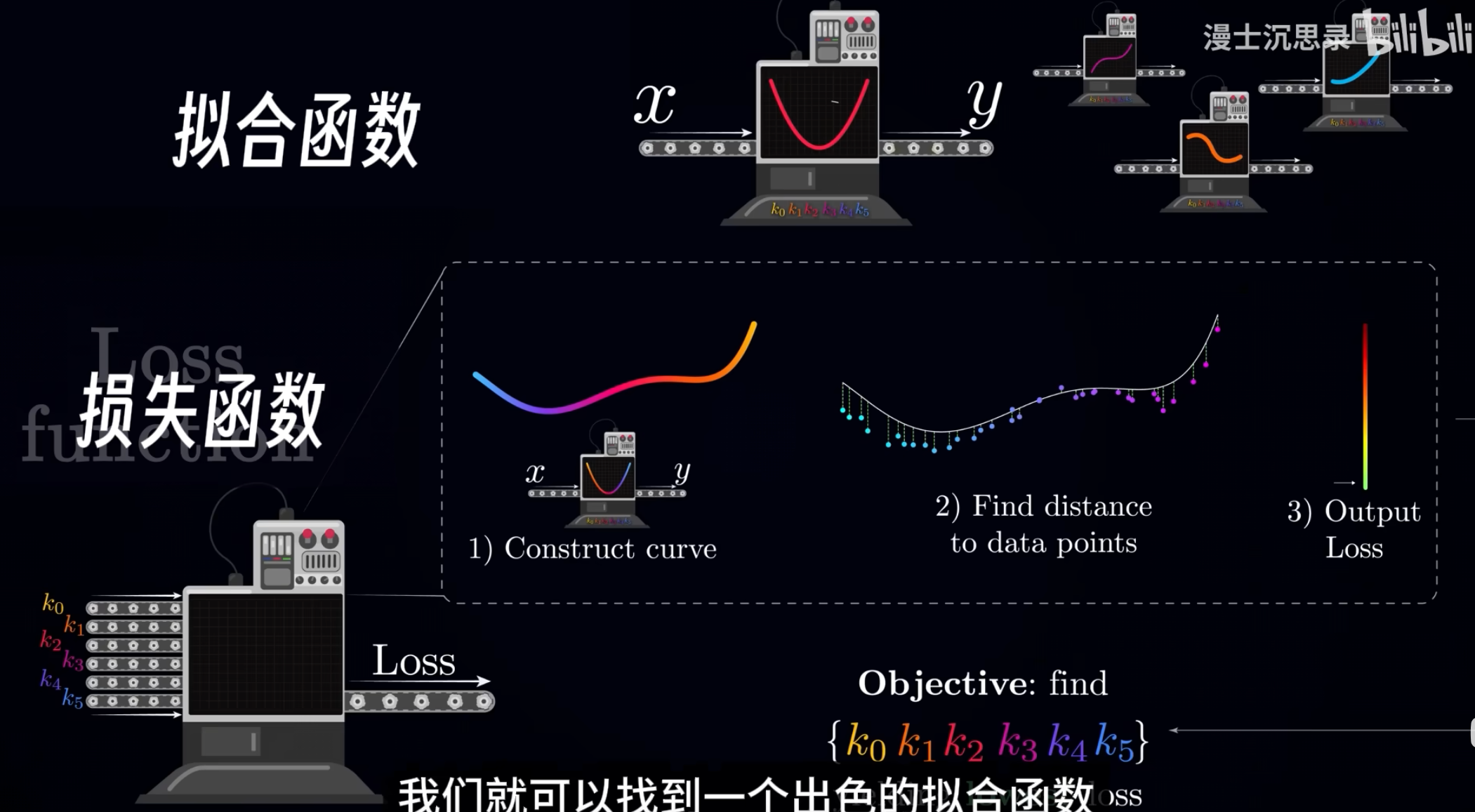
梯度算法的認知圖譜:
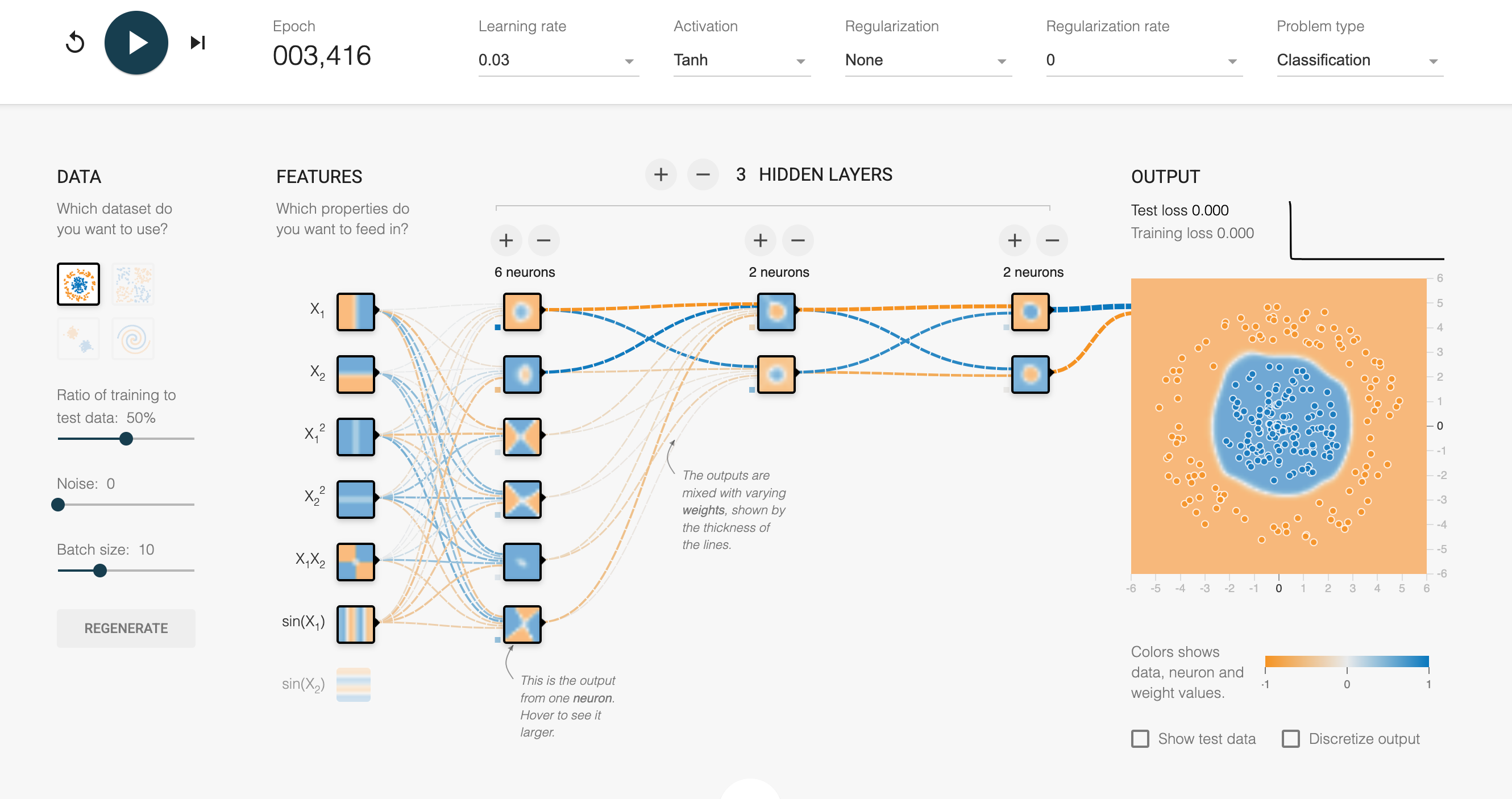
一個可視化的神經網絡平臺
谷歌推出的一個神經網絡可視化教學平臺,通過設置不同類型數據集,輸入特征選擇,神經網絡結構的隱藏層和激活函數,設置不同是訓練參數集如學習率等來觀察模型訓練中的動態變化。
A Neural Network Playground
9. Transformer
Transformer 也是一種深度學習模型,它的核心思想是“Attention is all you need ”, Transformer 完全基于注意力機制,區別與RNN 和CNN 。 它由兩部分組成,編碼器(Encoder) 和解碼器(Decoder) . 每個部分都是由多個相同的層堆疊而成,每層包含了多頭注意力機制(Multi-head Attention) 和位置全連接前饋網絡。
那么什么是注意力機制?每個詞都能關注句子中的其他詞,從而理解句子的含義
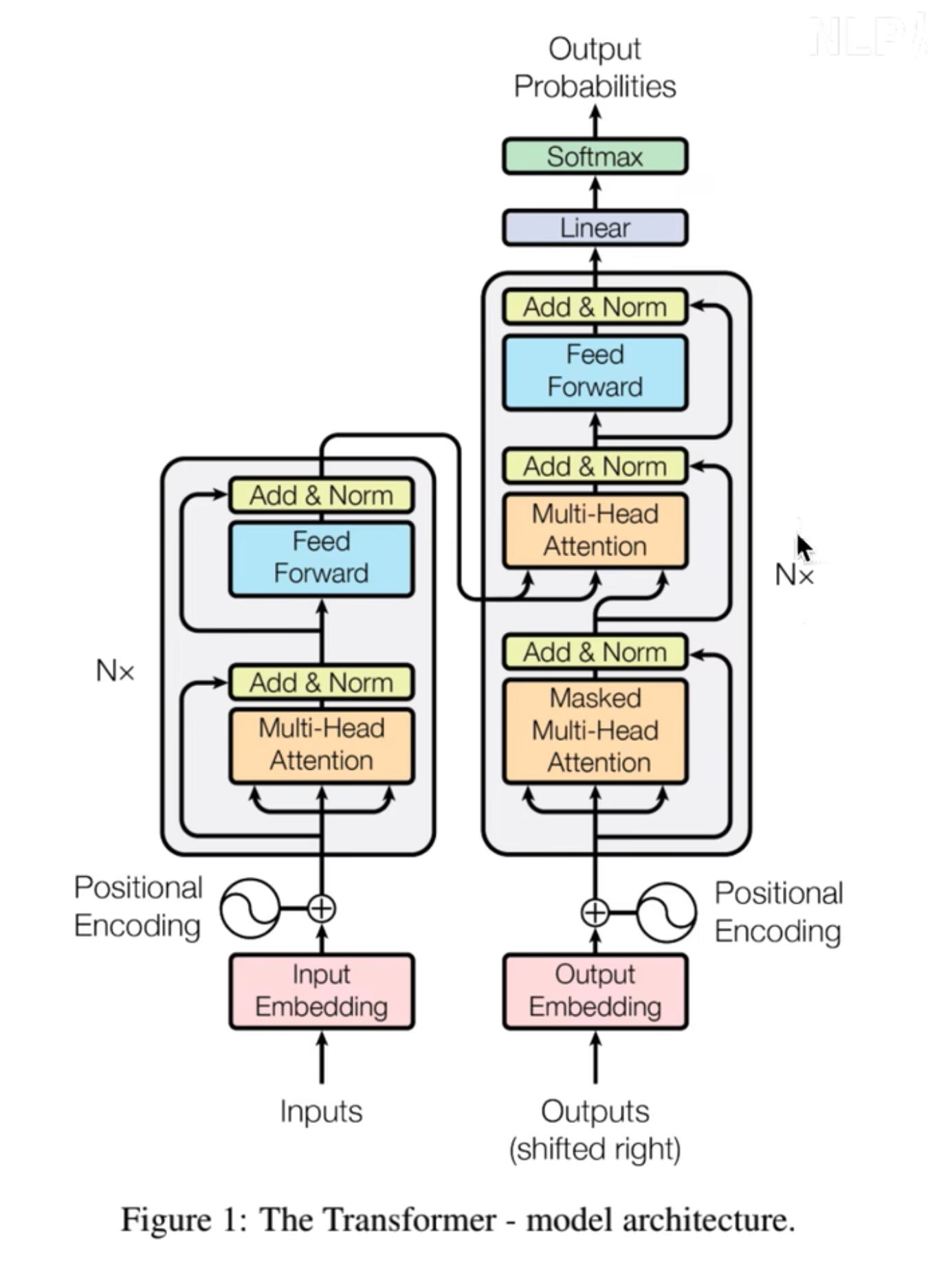
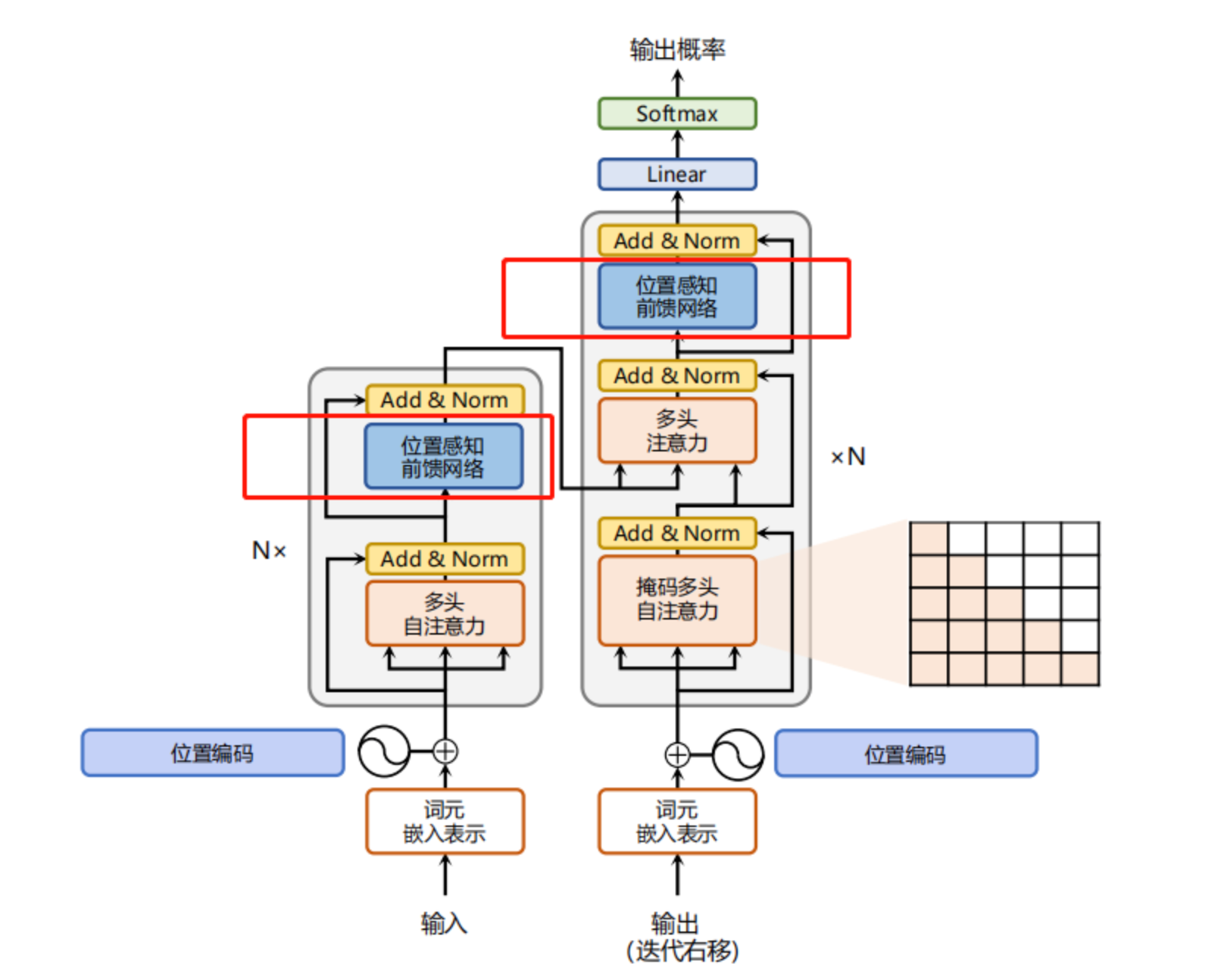
數學不好,Transformer 里面涉及復雜的數學知識有點令人費解,它的主要流程是:
輸入處理階段需要分詞、嵌入、位置編碼。編碼器部分需要自注意力和前饋網絡,解碼器部分需要掩碼注意力和交叉注意力。輸出生成需要線性層和softmax。
讓deepseesk 通俗講解一下:



b站視頻推薦:
王木頭學科學的個人空間-王木頭學科學個人主頁-嗶哩嗶哩視頻
90分鐘!清華博士帶你一口氣搞懂人工智能和神經網絡_嗶哩嗶哩_bilibili







--對象內存布局)
)










:常見屬性和函數)