目錄
TCP協議概述
1. 基礎尋址段??
??2. 序列控制段??
??3. 控制信息段??
??4. 流量控制段??
??5. 校驗與應急段??
??6. 擴展功能段??
??7. 數據承載段??
?TCP原理
確認應答與序列號(安全機制)
超時重傳機制(安全機制)?
連接管理機制(安全機制)?
滑動窗口(效率機制)
流量控制(安全機制)
擁塞控制(安全機制)?
延遲應答(效率機制)?
捎帶應答(效率機制)?
粘包問題?
TCP異常情況
?TCP/UDP對比
TCP協議概述
TCP(Transmission Control Protocol)是互聯網通信中最核心的傳輸層協議,為應用程序提供可靠、有序的端到端數據傳輸服務。作為現代網絡通信的基石,TCP通過多種機制在保證數據可靠性的同時,盡可能提升傳輸效率。
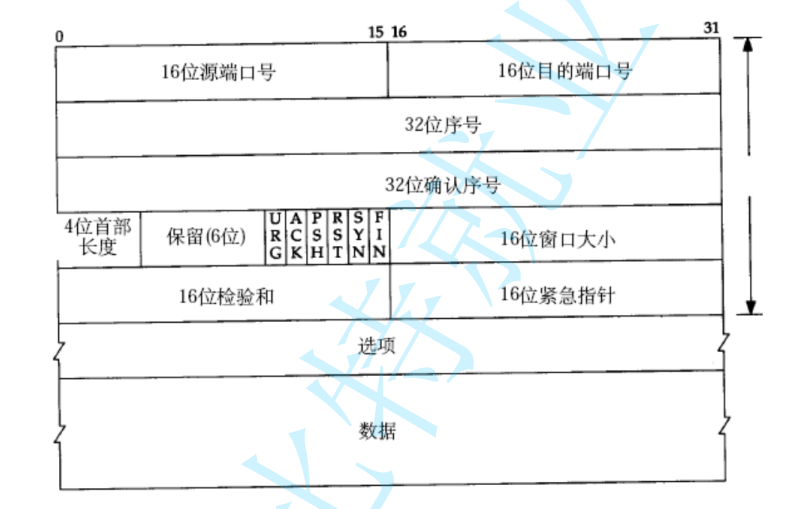
1. 基礎尋址段??
-
??16位源端口號??(0-15位)
標識發送方應用程序的端口號(范圍:0-65535)
示例:Web服務器通常使用80端口,SSH使用22端口 -
??16位目的端口號??(16-31位)
標識接收方應用程序的端口號
技術細節:客戶端端口通常為隨機高位端口(>1024)
??2. 序列控制段??
-
??32位序號??(32-63位)
當前報文段第一個字節的全局編號
作用:解決網絡包亂序問題,如初始隨機值ISN=123456 -
??32位確認號??(64-95位)
期望收到的下一個字節序號(ACK=1時有效)
工作邏輯:若收到seq=1000的包,則回復ack=1001
??3. 控制信息段??
-
??4位首部長度??(96-99位)
以??4字節??為單位的TCP首部總長度(范圍:5-15 → 20-60字節)
計算示例:首部長度值=5 → 實際長度=5x4=20字節 -
??6位保留字段??(100-105位)
保留位(全置0),為未來協議擴展預留 -
??6個標志位??(106-111位)
- ??URG??:緊急指針有效(用于發送中斷命令)
- ??ACK??:確認號有效(建立連接后始終為1)
- ??PSH??:接收方應立即推送數據給應用層
- ??RST??:強制重置異常連接
- ??SYN??:發起連接同步請求(三次握手首個包)
- ??FIN??:正常關閉連接請求(四次揮手首個包)
??4. 流量控制段??
- ??16位窗口大小??(112-127位)
接收方當前可接收的字節數(滑動窗口核心參數)
動態計算:窗口值=接收緩沖區空閑空間
??5. 校驗與應急段??
-
??16位檢驗和??(128-143位)
覆蓋首部、數據和偽首部的CRC校驗值
防篡改機制:發送方計算,接收方驗證 -
??16位緊急指針??(144-159位)
URG=1時生效,標識緊急數據結束位置
應用場景:Telnet中斷字符傳輸
??6. 擴展功能段??
- ??選項??(長度可變,160位起)
可選擴展功能,常見類型:- ??MSS??(最大報文長度):協商雙方MTU
- ??Window Scale??:窗口縮放因子(突破65535限制)
- ??SACK??:選擇性確認(精確重傳)
- ??Timestamp??:時間戳(計算RTT與防序號回繞)
??7. 數據承載段??
- ??數據??(首部之后)
應用層傳遞的有效載荷(如HTTP請求、文件流等)
技術規范:數據長度=IP報文總長 - IP頭 - TCP頭
?TCP原理
TCP對數據傳輸提供的管控機制,主要體現在兩個方面:安全和效率。 這些機制和多線程的設計原則類似:保證數據傳輸安全的前提下,盡可能的提高傳輸效率。內容全展開的話實在是太多了,所以我只寫點重要的
確認應答與序列號(安全機制)
確認應答是TCP的最核心機制,正是這個機制支持了TCP的可靠傳輸!
確認應答和序列號是TCP用來保證數據不亂、不丟、不被篡改的核心機制。每次發送數據時,TCP會為數據塊分配一個序列號(比如從12345開始),接收方收到后必須回一個ACK包,明確告訴對方“下一個我要的是序列號12345+數據長度的位置”。比如你發了一個序列號1001-2000的包,對方ACK就回2001,相當于說“2000之前的我全收到了,下次從2001開始發”。
序列號還有個隱藏的安全作用:連接建立時初始序列號是隨機生成的(比如不是從0開始),這讓攻擊者很難偽造數據包插入到現有連接里,因為猜不中正確的序列號范圍。接收方會嚴格檢查每個包的序列號是否在預期窗口內,不符合的直接丟掉,防止中間人亂塞數據。
ACK包雖然簡單,但設計得很聰明。比如發送方連續發三個包(序列號1-1000、1001-2000、2001-3000),接收方可能直接回一個ACK=3001,表示前面三個包都收到了。這種“累積確認”機制減少了ACK的數量,同時讓發送方明確知道哪些數據需要重傳(比如如果ACK卡在1001不動,說明第二個包丟了)。序列號和ACK配合起來,既管順序又管確認,把不可靠的IP協議硬生生改造成了可靠傳輸。
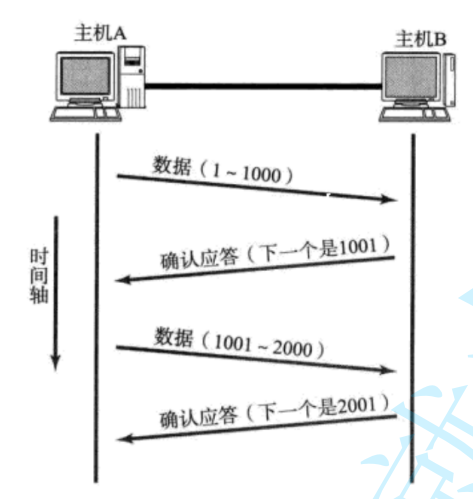
TCP將每個字節的數據都進行了編號。即為序列號
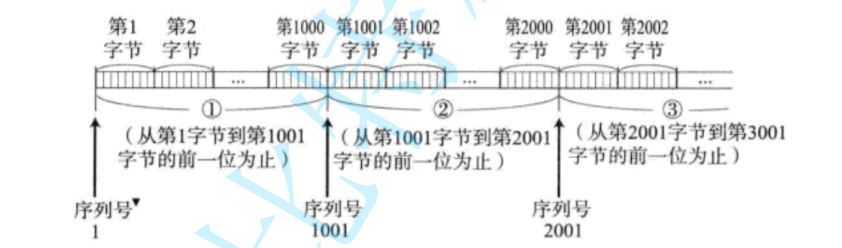
每一個ACK都帶有對應的確認序列號,意思是告訴發送者,我已經收到了哪些數據;下一次你從哪里開始發。
如何區分數據包是不是ACK
區分普通數據包和ACK包主要看兩個地方:一是TCP頭部的標志位,二是數據包有沒有實際內容。普通數據包一般帶著應用層的數據(比如網頁內容或文件片段),雖然它可能同時帶有ACK標志(表示確認之前收到的數據),但重點是它有實際數據在傳輸。而純ACK包的作用僅僅是確認對方發來的數據,所以它的ACK標志位會置1,但數據部分完全是空的,長度為零。類似地,SYN(連接請求)和FIN(斷開請求)包也會通過自己的標志位(SYN=1或FIN=1)暴露身份,它們同樣不攜帶數據,只負責控制連接的建立或關閉。簡單來說,看標志位有沒有特殊標記,再看有沒有“貨”(數據)在里面,基本就能分清了。?
超時重傳機制(安全機制)?
超時重傳就是TCP用來對付數據包半路消失的保底手段。發送方每發一個包就啟動一個定時器,如果超過一定時間還沒收到對方的確認(ACK),就默認這包丟了,立刻重新傳一次。比如你傳了個序號1001-2000的數據塊,結果對方沒回ACK,等超時了就直接再發一遍,確保數據最終能送到。
超時時間不是固定的,而是根據歷史往返時間動態算出來的。比如之前發個包平均0.1秒就能收到ACK,這次超時時間可能設成0.3秒(留點緩沖防網絡波動)。如果重傳后還沒收到ACK,下次超時時間會直接翻倍(比如從0.3秒變成0.6秒),避免在極端擁堵時反復重傳雪上加霜。
重傳的包到了接收方那里也不用擔心重復。接收方早就記著已經收過哪些序號,如果發現是重復數據(比如同一個序號傳了兩次),直接扔掉多余的,只留一份給上層應用,同時照樣回ACK。這樣既解決了丟包問題,又不會讓應用層收到重復數據。
超時重傳和快速重傳(比如連收三個重復ACK就提前重傳)是互補的。超時重傳屬于“寧可多等也要確認真丟了”,而快速重傳更敏捷,但兩者最終目的都是把數據可靠送達。整個機制全靠發送方自己判斷和兜底,不依賴接收方主動報錯。
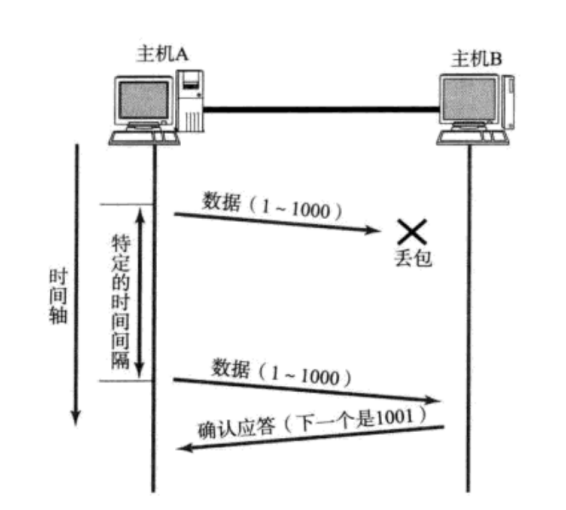
正常流程??
- 主機A發送數據段(序列號1~1000)
- 主機B接收成功后返回ACK=1001(表示期望接收下一字節序號)
- 主機A收到ACK后繼續發送新數據
??異常處理?(如圖)?
- 若主機A的數據包在網絡中丟失(圖中標注"X")
- 主機A在??500ms超時窗口??內未收到確認,觸發重傳原數據(1~1000)
但是,主機A未收到B發來的確認應答,也可能是因為ACK丟失了
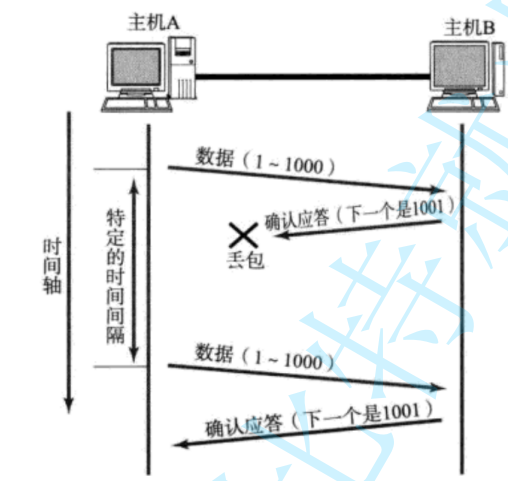
- 主機A首次等待500ms未收到ACK,重傳數據
- 如果第二次仍未收到ACK,等待時間翻倍至??1000ms(2×500ms)??后再次重傳
- 持續重傳直至收到ACK或達到最大次數(強制斷開連接)
- 主機B通過序列號檢測到重復數據,自動丟棄冗余包(避免應用層收到重復內容)?
為什么會丟包?
丟包可能因為網絡擁堵(比如路由器處理不過來直接丟棄數據包)、硬件故障(比如網線接觸不良或路由器性能差)、信號干擾(無線網絡受距離或障礙物影響)、配置問題(防火墻或路由策略錯誤攔截數據),或者協議本身的機制(比如TCP重傳前故意丟棄重復包)。此外,數據包傳輸路徑中的節點(如交換機、運營商設備)超載或異常也可能導致丟包。如果是廣域網,跨地區鏈路不穩定或帶寬不足會更常見。簡單來說,只要傳輸路徑上的任何一個環節出問題或扛不住壓力,都可能讓數據包“消失”。
重復數據怎么辦
接收方內部有個叫“接收緩沖區”的內存空間,專門存已經收過的數據和對應的序號。比如你發了個1-1000的數據包,對方確認要1001之后,如果同樣的數據包又傳了一次,接收方一查發現這序號在緩沖區里已經存在,直接就把后來的重復包扔了,根本不會讓應用程序讀到兩條一樣的。哪怕發送方因為網絡問題反復發同一個包,到應用層這里(比如inputStream.read)還是只會拿到一條數據,完全不用擔心重復扣錢或者處理錯數據這種問題。并且“接收緩沖區”還能對數據進行重新排序,確保發送的數據和應用讀取的數據一致
連接管理機制(安全機制)?
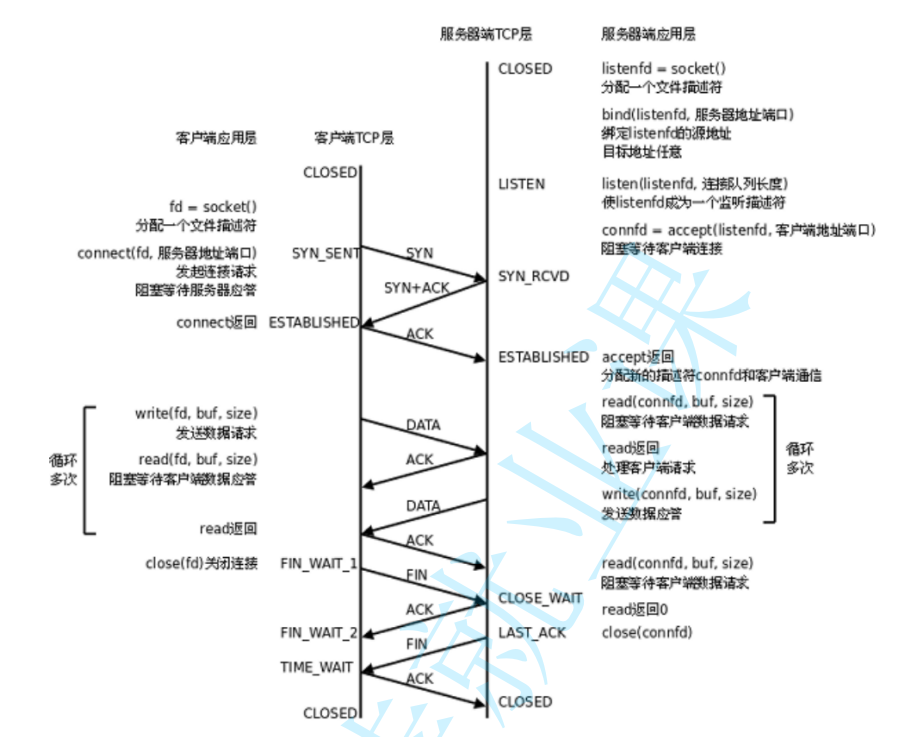
在正常情況下,TCP要經過三次握手建立連接,四次揮手斷開連接
TCP通過經典的“三次握手”建立連接,這一過程看似簡單,實則暗藏安全設計。當客戶端發起連接時,會發送一個攜帶??隨機生成序列號??的SYN報文。服務器收到后,不僅會回復自己的隨機序列號(SYN-ACK報文),還會將客戶端的初始序列號+1作為確認依據。這種隨機數的引入,使得攻擊者難以偽造合法的序列號組合,有效防止了中間人攻擊或會話劫持。
針對常見的SYN洪泛攻擊(攻擊者發送大量偽造SYN請求耗盡服務器資源),現代系統普遍采用??SYN Cookie機制??。服務器在收到SYN報文時,并不立即分配內存資源,而是通過加密算法生成一個“臨時憑證”作為響應報文的序列號。只有當客戶端返回正確的ACK確認(攜帶憑證解密后的信息),服務器才會正式分配連接資源。這種“先驗證后建連”的策略,既保障了正常用戶的連接效率,又大幅提高了攻擊成本。
連接建立后,TCP通過??序列號與確認號機制??保障數據完整性。每個數據包都攜帶唯一序列號,接收方會嚴格檢查這些序號是否連續且在預期窗口范圍內。例如,若收到一個序列號遠大于當前窗口的數據包,TCP會直接丟棄并觸發重傳機制。這種動態校驗不僅能識別網絡傳輸中的亂序或丟包,還能攔截攻擊者偽造或篡改的數據注入。
此外,TCP的??滑動窗口機制??也具備安全屬性。接收方通過動態調整窗口大小,不僅能實現流量控制,還能在遭遇異常流量(如短時間內大量重復數據包)時縮小窗口,間接限制攻擊者的數據發送速率,為系統爭取應急響應時間。
TCP通過“四次揮手”優雅地關閉連接,這一過程中的狀態管理也隱含安全考量。例如,主動關閉方在發送最終ACK后會進入??TIME_WAIT狀態??,等待足夠時間以確保對方收到確認。這種設計不僅是為了處理網絡中可能滯留的延遲數據包,還能防止攻擊者利用舊連接的殘留信息偽造新連接。
對于異常終止(如RST報文強制斷開),操作系統內核會嚴格校驗RST報文的序列號是否合法。如果檢測到序列號與當前連接不匹配,系統會直接忽略異常請求,避免攻擊者通過偽造RST報文實施“連接重置攻擊”。
盡管TCP內置了多重防護,但其設計初衷并非解決所有安全問題。例如:
- ??數據明文傳輸??:TCP不提供加密功能,攻擊者仍可能竊聽數據內容,需依賴TLS/SSL等協議實現加密。
- ??依賴隨機數質量??:序列號的隨機性直接影響安全性,早期系統因隨機數生成缺陷曾引發攻擊,現代操作系統已采用更安全的隨機數算法(如基于硬件熵源)。
- ??協議棧實現差異??:不同廠商對TCP協議棧的實現可能存在漏洞,需通過系統更新及時修補。
?如果你懶得去理解,那只需要記住下面這些東西,首先是三次握手,A向B發送SYN(這時是在告訴B,我的發送能力沒問題),B收到SYN后向A發送SYN和ACK(這是在告訴A,我的接收能力沒問題,并且你的發送能力沒問題),此時A向B發送ACK(這是告訴B,你的發送能力沒問題,并且我的接收能力沒問題).完成以上操作A和B就記錄了對方的信息(在握手的過程中會針對一些重要的參數進行協商,比如通信過程中的序列號從幾開始),也就是構成了邏輯上的連接,關于四次揮手,
沒什么好說的和三次握手的邏輯差不多,只需要特別注意一點,假設是A發起的請求,那么當B發送FIN后A會進入TIME_WAIT狀態,這主要是為了確保A能對FIN進行處理發出ACK,否則B收不到A的ACK就會超時重傳,產生bug
為什么三次握手可以是三次,而四次揮手是四次
三次握手能合并成三次,是因為服務器在收到客戶端SYN后,內核會同時觸發ACK(確認)和發送自己的SYN(同步請求),這兩個操作發生在同一時間點,直接合并成一次??SYN+ACK??響應。而四次揮手會拆成四次,是因為當一方發送FIN(結束請求)后,對方的ACK是內核自動回復的,但另一端的FIN需要等應用程序主動執行
close()才會觸發。這兩個動作(ACK和FIN)的觸發時機完全獨立,一個由系統自動處理,一個依賴程序主動操作,沒法打包成一次發送,所以揮手需要多一步,變成四次。當然實際情況要復雜的多,四次揮手有的時候會變成三次,當看到延時應答這一機制的時候我們再說
滑動窗口(效率機制)
滑動窗口說白了就是讓發送方不用傻等確認(ACK),可以一口氣多發幾個包。比如你傳文件時,接收方會告訴發送方自己還能收多少數據(這個數叫窗口大小),發送方就按這個額度不斷發,不用每發一個包都停下來等回復。窗口里的數據只要還沒確認,就暫時占著位置,等前面的ACK陸續回來,窗口就跟著往前“滑”,騰出位置發后面的數據。這樣網絡帶寬就被持續填滿,效率自然高了。
接收方的窗口大小也不是固定的,會根據自己處理能力動態調整。比如接收方的應用程序如果讀取慢了,緩沖區快滿了,窗口就會變小甚至關窗,告訴發送方“別發了,我處理不過來了”。反過來,如果接收方處理得快,窗口開大,發送方就能飆高速。這種實時反饋讓雙方節奏同步,既不會撐死接收方,也不會讓發送方閑著。
實際傳數據時,窗口還會結合確認機制一起用。比如發送方發出去1-1000、1001-2000、2001-3000三個包,只要收到第一個包的ACK,哪怕后面兩個包還沒確認,窗口也會直接滑到3001繼續發新數據。如果中間有包丟了,接收方會一直要求重傳丟失的部分,窗口也會卡在丟包的位置等補傳,這樣既能保證數據順序,又能盡量維持傳輸速度。
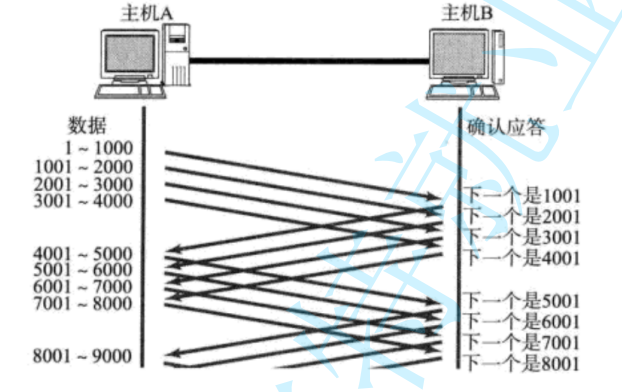
- 窗口大小指的是無需等待確認應答而可以繼續發送數據的最大值。上圖的窗口大小就是4000 個字節(四個段)。
- 發送前四個段的時候,不需要等待任何ACK,直接發送;
- 收到第一個ACK后,滑動窗口向后移動,繼續發送第五個段的數據;依次類推;
- 操作系統內核為了維護這個滑動窗口,需要開辟 發送緩沖區 來記錄當前還有哪些數據沒有 應答;只有確認應答過的數據,才能從緩沖區刪掉;
- 窗口越大,則網絡的吞吐率就越高;?
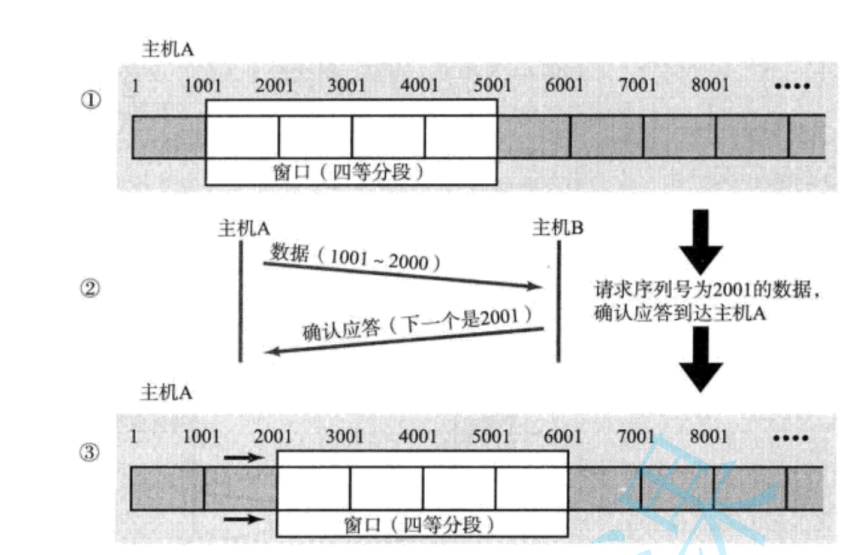
那么如果出現了丟包,如何進行重傳?這里分兩種情況討論。
情況一:數據包已經抵達,ACK被丟了。?
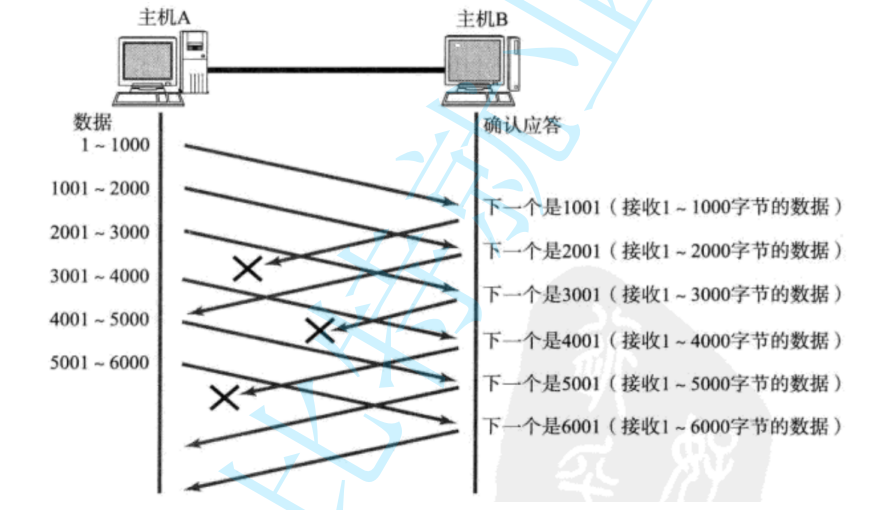
這種情況下,部分ACK丟了并不要緊,因為可以通過后續的ACK進行確認;?
情況二:數據包直接丟了。
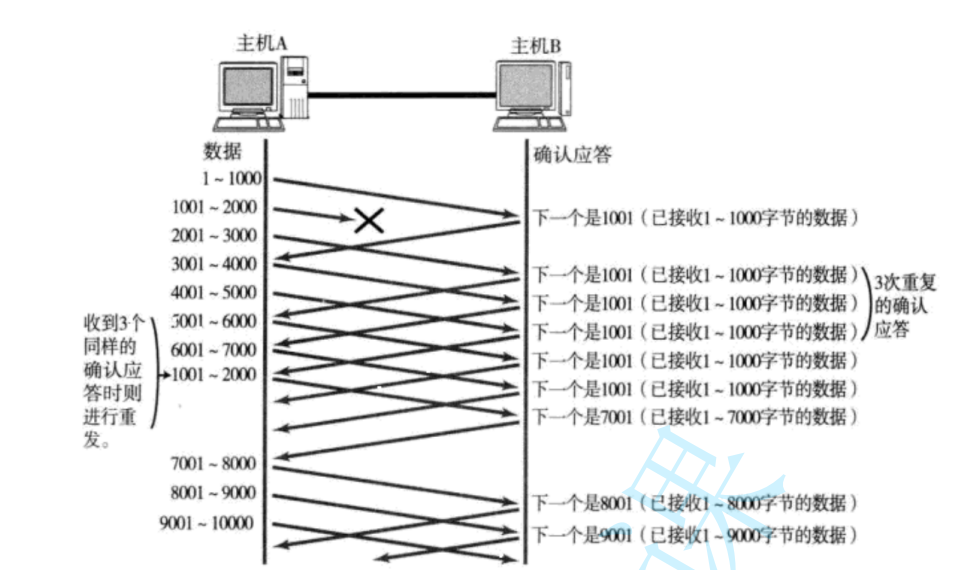
- 當某一段報文段丟失之后,發送端會一直收到 1001 這樣的ACK,就像是在提醒發送端 "我想 要的是 1001" 一樣;
- 如果發送端主機連續三次收到了同樣一個 "1001" 這樣的應答,就會將對應的數據 1001 - 2000 重新發送;
- 這個時候接收端收到了 1001 之后,再次返回的ACK就是7001了(因為2001 - 7000)接收端 其實之前就已經收到了,被放到了接收端操作系統內核的接收緩沖區中;?
這種機制被稱為 "高速重發控制"(也叫 "快重傳")
流量控制(安全機制)
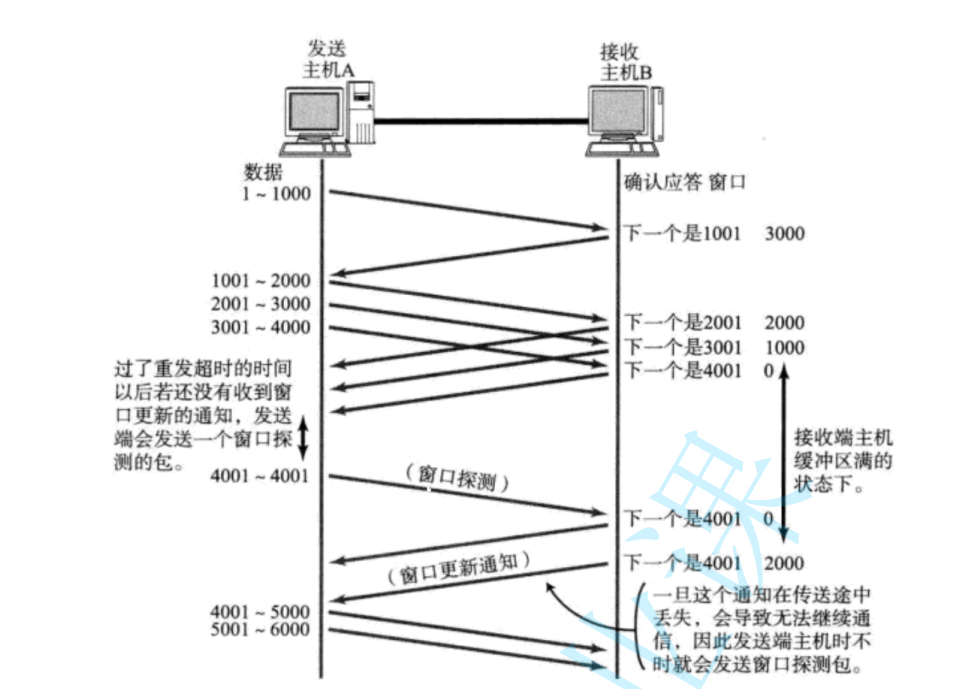
流量控制的核心目的是防止發送方把接收方“沖垮”。接收方每次發確認(ACK)時會帶上自己的接收窗口大小,這個數值代表當前緩沖區還能存多少數據。比如接收方說窗口還剩1000字節,發送方最多只能發這么多,發完就必須等新的窗口更新,否則不準繼續發。如果接收方處理慢了,緩沖區快滿了,窗口會越來越小甚至變成零,這時候發送方就徹底暫停,直到對方重新開窗。
窗口更新不是單次操作,而是動態調整的。比如接收方每次從緩沖區取走數據后,可用空間變大,就會在新的ACK中攜帶更大的窗口值,發送方看到后就能逐步恢復發送速度。這種實時反饋讓發送方的節奏完全跟著接收方的處理能力走,避免數據積壓導致內存溢出或丟包。
零窗口的情況需要特殊處理。如果接收方窗口變零,發送方會啟動“持續計時器”,定期發探測包(比如空數據+ACK),詢問對方窗口是否恢復。一旦收到非零窗口的回復,發送方立刻繼續傳數據,避免雙方卡死。整個過程不需要應用層參與,全靠TCP協議自己協調,既安全又省心。
流量控制和擁塞控制容易混淆,但目標不同。流量控制只關心接收方的處理能力,是點對點的安全機制;擁塞控制關注整個網絡的擁堵程度,防止全局性的過載。兩者配合使用,保證數據傳輸既高效又穩定。
擁塞控制(安全機制)?
擁塞控制的核心是讓發送方主動探測網絡承受能力,避免把鏈路塞爆(也就是考慮通信過程中, 中間節點的情況)。它通過動態調整“擁塞窗口”的大小來控制發送速率。比如剛開始傳數據時,窗口很小(比如1個包),每收到一個ACK就把窗口翻倍,指數級增長直到出現丟包或達到閾值,這階段叫慢啟動。一旦觸發閾值,就進入擁塞避免階段,窗口改為線性增長(比如每輪加1),用更保守的方式試探網絡極限。
如果發生超時丟包(比如ACK死活等不到),說明網絡可能徹底堵死,這時候窗口會直接砍到1,重新開始慢啟動,同時把閾值設為丟包時窗口的一半。但如果是快速重傳(比如連收三個重復ACK),說明只是部分丟包,網絡還有救,窗口會降到當前值的一半加3,進入快速恢復階段,一邊補傳丟包一邊等新ACK,避免完全重置窗口。
現代算法(如Cubic或BBR)會更智能地預測帶寬。比如Cubic用三次函數模擬窗口增長,丟包后先降窗口,再按曲線緩慢爬升,而不是機械地翻倍或加1。BBR則直接測量鏈路最小延遲和最大帶寬,動態計算發包速率,盡量繞開擁堵。這些機制讓TCP既能榨干空閑帶寬,又能在擁堵時及時剎車,平衡速度和穩定性。
擁塞控制的最終目標是在“發太快導致丟包”和“發太慢浪費帶寬”之間找到平衡點。整個過程完全由發送方自主決策,不需要和接收方或路由器協商,靠的純屬算法預測和反饋調整。
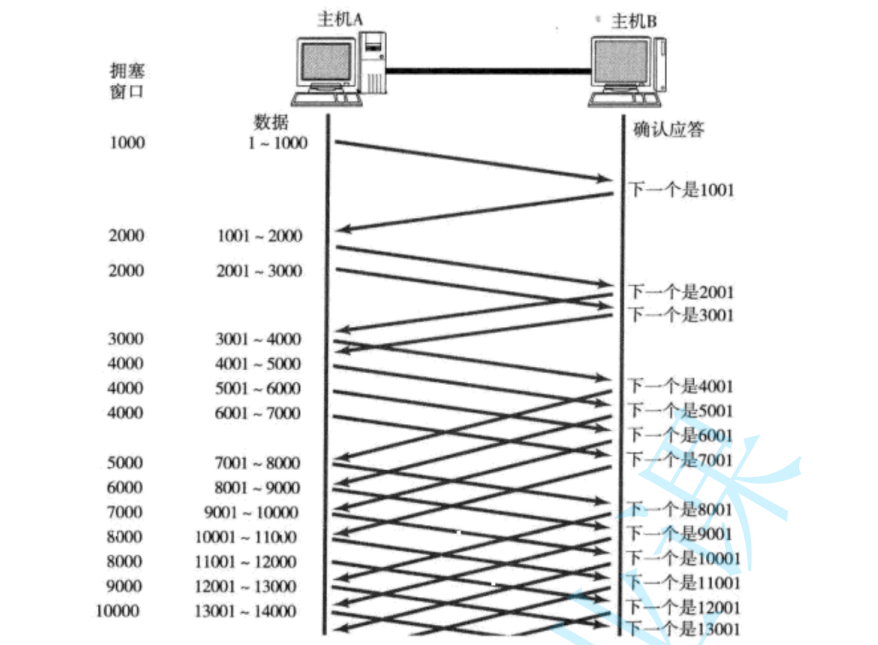
- 此處引入一個概念程為擁塞窗口
- 發送開始的時候,定義擁塞窗口大小為1;
- 每次收到一個ACK應答,擁塞窗口加1;
- 每次發送數據包的時候,將擁塞窗口和接收端主機反饋的窗口大小做比較,取較小的值作為 實際發送的窗口;?
像上面這樣的擁塞窗口增長速度,是指數級別的。"慢啟動" 只是指初使時慢,但是增長速度非常快。為了不增長的那么快,因此不能使擁塞窗口單純的加倍。 此處引入一個叫做慢啟動的閾值 當擁塞窗口超過這個閾值的時候,不再按照指數方式增長,而是按照線性方式增長
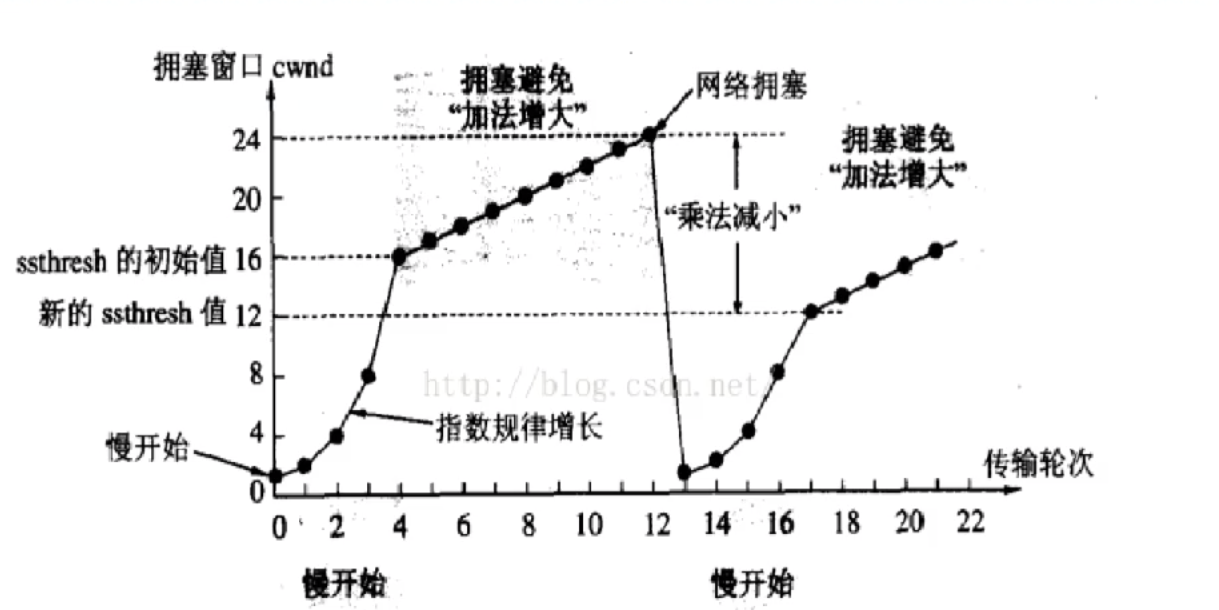
- 當TCP開始啟動的時候,慢啟動閾值等于窗口最大值;
- 在每次超時重發的時候,慢啟動閾值會變成原來的一半,同時擁塞窗口置回1;?
少量的丟包,我們僅僅是觸發超時重傳;大量的丟包,我們就認為網絡擁塞; 當TCP通信開始后,網絡吞吐量會逐漸上升;隨著網絡發生擁堵,吞吐量會立刻下降;擁塞控制,歸根結底是TCP協議想盡可能快的把數據傳輸給對方,但是又要避免給網絡造成太大壓力的折中方案。?
延遲應答(效率機制)?
延遲應答的核心思路是減少ACK包的數量,提升網絡利用率。接收方收到數據后不會馬上回ACK,而是稍微等一小段時間(比如40毫秒),如果這段時間內正好有數據要發給對方,就把ACK捎帶在數據包里一起發出去,省掉單獨發ACK的開銷。如果等半天也沒數據要發,再單獨回一個ACK,防止發送方誤以為丟包。
這種延遲不是無限制的。操作系統通常會設置最大延遲時間(比如Linux默認40ms),超時后必須發ACK,否則發送方的超時重傳機制會被觸發,反而浪費帶寬。另外,如果接收方的窗口大小(空閑緩沖區)有顯著變化,比如突然騰出大量空間,也會立刻更新窗口并發送ACK,避免發送方卡在零窗口狀態。
延遲應答和滑動窗口配合起來效果更好。比如接收方攢了幾個ACK一起發,發送方看到連續確認后,可以一次性發更多數據,減少來回等待的時間。但極端情況下(比如實時性要求高的場景),可能會手動關閉延遲應答,換回即時ACK,用帶寬換低延遲。整體來說,延遲應答是在可靠性和效率之間找平衡的典型操作。
填坑
延時應答拖延了ACK的回應時間,一旦ACK滯后,就有機會和FIN合并在一起,于是四次揮手就變成了三次
捎帶應答(效率機制)?
捎帶應答是建立在延時應答的基礎上的
捎帶應答說白了就是“搭便車發ACK”。當通信雙方有雙向數據傳輸時,如果接收方剛好要發數據給對方,就會把該回的ACK塞到數據包里一起發走,而不是單獨發一個純ACK包。比如客戶端傳了個文件塊,服務器處理完正好要返回處理結果,這時候ACK就跟著結果數據一起傳回去,省了一次單獨確認的交互。
這種機制最明顯的優勢是減少網絡上的小包數量。單獨發ACK雖然只有幾十字節,但在高并發或弱網環境下,積少成多會占用不少帶寬和連接資源。捎帶應答把確認動作“寄生”在正常數據流里,相當于用順風車代替專車,自然更高效。
不過捎帶應答依賴雙向通信的場景。如果一方只收不發(比如下載大文件時服務器持續傳數據,客戶端很少回傳),ACK就只能單獨發。這時候可能會結合延遲應答——等40毫秒看是否有數據要發,實在沒有才單獨回ACK。兩者配合起來,能在大部分場景下把冗余的ACK壓縮到最少。
實際抓包時能看到,像HTTP接口的請求-響應模式就特別適合捎帶應答。客戶端發POST請求后,服務器的響應數據包里會同時包含對請求的ACK和對響應數據的序列號,一次交互完成兩種操作,效率直接拉滿。
粘包問題?
粘包問題本質上是接收方無法正確拆分出發送方原本傳輸的數據塊。因為TCP是流式協議,數據像水管里的水一樣連續傳輸,沒有固定分界。比如發送方快速發了“Hello”和“World”兩個包,接收方可能一次讀到“HelloWorld”,粘成一個包,也可能分兩次讀成“He”和“lloWorld”,完全不確定。
出現粘包主要兩個原因:一是發送方內核的Nagle算法把小包合并發送(比如攢夠一個MSS大小才發),二是接收方從緩沖區讀取數據時,可能一次性讀了多個包或者半個包。這和TCP的設計有關——它只管把數據流可靠送到,不管應用層怎么定義“消息”的邊界。
解決辦法全靠應用層自己定規則。常見的有三種:1. ??固定長度??,比如每個包固定100字節,不夠就補空格;2. ??分隔符??,比如每個包末尾加換行符\n,接收方按這個切分;3. ??頭部聲明長度??,比如前4字節表示后續數據長度,先讀頭部再讀對應長度的內容。像HTTP協議就用了Content-Length頭明確數據體大小。
實際開發中,像WebSocket這類協議已經內置了幀結構(比如頭部的掩碼和長度字段),根本不需要操心粘包。但如果自己寫底層通信,比如用Netty,就得通過編解碼器(如LengthFieldBasedFrameDecoder)預先處理粘包問題,否則業務邏輯會被不完整的數據搞崩潰。
TCP異常情況
TCP遇到異常時處理方式各不相同。比如進程突然掛了或者機器重啟,內核會正常回收連接資源,發FIN包通知對方關閉,和手動close()沒區別,對方能按四次揮手流程安全斷開。但如果是機器直接斷電或者網線被拔了,接收方完全不知道連接已經斷掉,這時候如果接收方嘗試往這個連接寫數據,協議棧會發現對方根本不存在,直接回一個RST重置包強制關閉連接。
就算接收方一直不寫數據,TCP自己也帶了個保活定時器(默認兩小時觸發一次),定期發探測包確認對方是否活著。如果連續多次沒回應,就認定連接已死,自動釋放資源。不過這個機制一般要手動開啟(設置SO_KEEPALIVE選項),不是所有連接都默認啟用。
應用層協議為了更靈敏,通常會自己加檢測。比如HTTP長連接可能設置30秒無請求就主動斷掉,或者像QQ這類即時通訊軟件,一旦發現收不到心跳包回應,立刻嘗試重連,而不是傻等TCP的保活機制。這種雙保險讓異常斷開的恢復更快,用戶體驗更穩。
關于心跳包
心跳包說白了就是應用層自己搞的“存活檢測”。比如客戶端和服務器建立長連接后,如果長時間沒數據往來,中間的路由器或者防火墻可能會把連接掐掉。這時候雙方約定每隔一段時間(比如30秒)發個固定格式的小數據包(比如內容為
ping),對方收到立刻回個pong,這樣既告訴中間設備“這連接還在用”,又能確認對方還活著。如果超過一定次數沒收到心跳回復(比如連續3次
ping沒回應),就認為網絡斷了或者對方宕機,應用層會主動觸發重連邏輯,而不是傻等TCP的保活機制(默認兩小時才檢測)。像微信聊天、在線游戲這種實時性高的場景,心跳包間隔可能短到1秒,確保掉線能秒級感知。心跳包一般會盡量精簡,只帶必要信息(比如時間戳或序號),避免浪費帶寬。有些協議還會在心跳里夾帶業務狀態,比如設備上報電量、服務端推送配置更新,做到“一包兩用”。不過核心目標始終是維持連接活性,尤其在移動網絡(4G/5G)下,基站資源有限,心跳包能有效防止連接被系統回收。
和TCP自帶的保活機制相比,心跳包完全由應用層控制,靈活性更高。比如可以根據網絡質量動態調整間隔——Wi-Fi環境下心跳調慢,蜂窩網絡下調快,甚至后臺運行時暫停心跳省電,這些細節都是協議自己說了算。
?TCP/UDP對比
我們說了TCP是可靠連接,那么是不是TCP一定就優于UDP呢?TCP和UDP之間的優點和缺點,不能簡單,絕對的進行比較
- TCP用于可靠傳輸的情況,應用于文件傳輸,重要狀態更新等場景;
- UDP用于對高速傳輸和實時性要求較高的通信領域,例如,早期的QQ,視頻傳輸等。另外 UDP可以用于廣播;
歸根結底,TCP和UDP都是程序員的工具,什么時機用,具體怎么用,還是要根據具體的需求場景去判定。?



:常見屬性和函數)














,整合IK分詞器和安裝Kibana)
