目錄
模型結構:
Memory-efficient implementation:
實驗:
1. 在大規模模型上效果顯著:
2. 在不同類型任務上的效果:
為什么MLP對效果有提升的幾點猜測:
1.?并非所有token對生成質量的影響相同
2. 關鍵選擇點的權重累積機制
3. 從互信息的角度解釋
4.?因果語言模型的傳統因子化順序
屈折語中的語法一致性挑戰
非因果因子化順序的優勢(多token預測提升對復雜語法結構(如屈折、一致關系)的處理能力)
通過隱式建模非因果依賴,減少因局部錯誤導致的全局矛盾
問題:
模型結構:
單token預測:
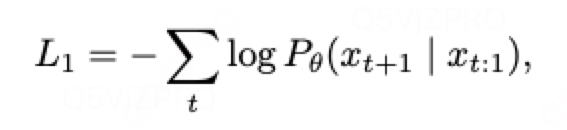
多token預測:
model??應用一個共享trunk來針對
產生一個latent 表示
,接著送入到n個獨立的head來并行預測未來n個tokens。
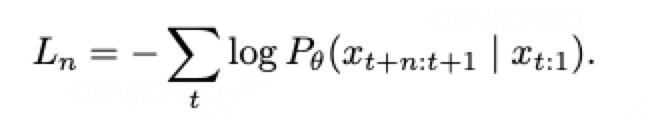
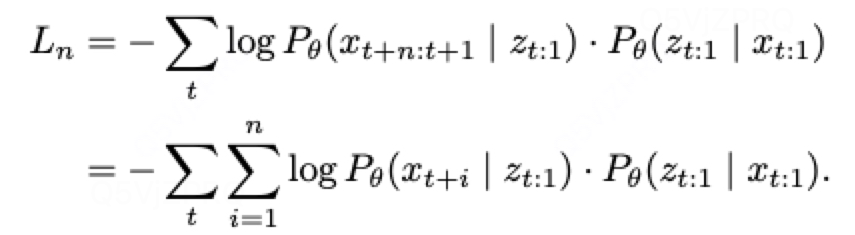
其中:
![]()
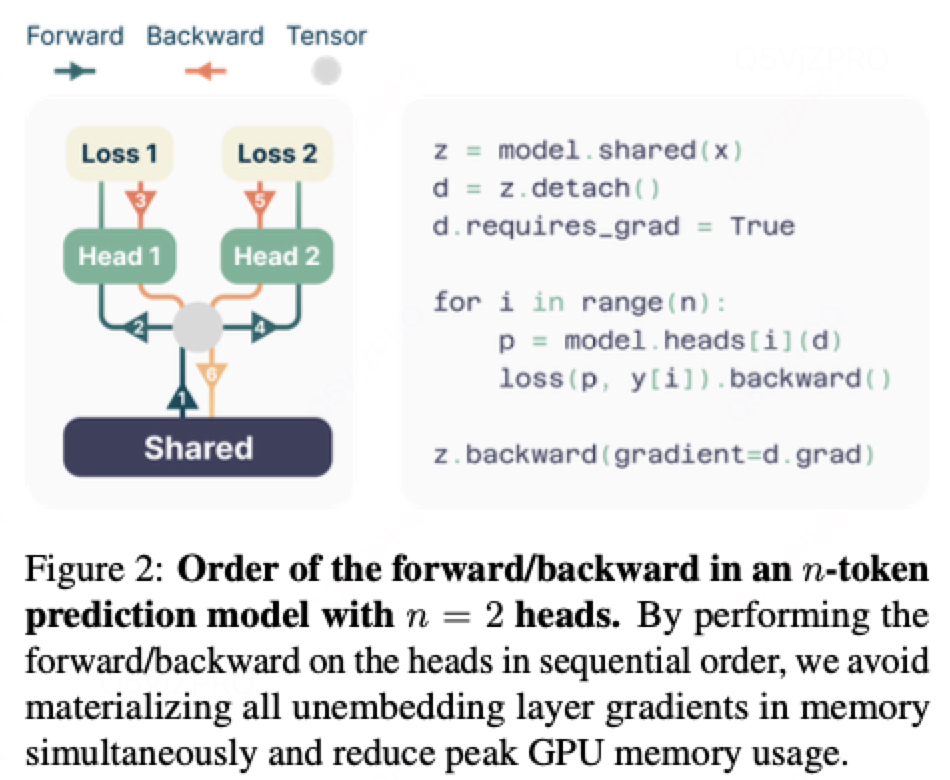
Memory-efficient implementation:
由于詞表大小V遠大于維度d,所以logit的計算,由(d,V)變化為 (d,V*N),是GPU memery使用的瓶頸。解決辦法為序列話的計算每個獨立輸出頭的前向和反向傳播過程,在trunk進行梯度累加。在計算
之前
的計算已經被釋放掉。將CPU的memery峰值從
降低為
。
實驗:
1. 在大規模模型上效果顯著:
小規模模型的局限性
-
模型容量不足:小模型(如百萬或十億參數級)難以同時捕捉多個時間步的復雜依賴關系。多令牌預測需要模型理解長距離上下文和跨步關聯,這對小模型來說過于困難。
-
邊際收益低:在小規模實驗中,多令牌預測可能僅帶來微弱的效果提升(如困惑度略微下降),無法證明其額外計算成本是合理的。
2. 在不同類型任務上的效果:
2.1在choice task上面沒有提升性能,可能需要放大模型大小才能看到效果。
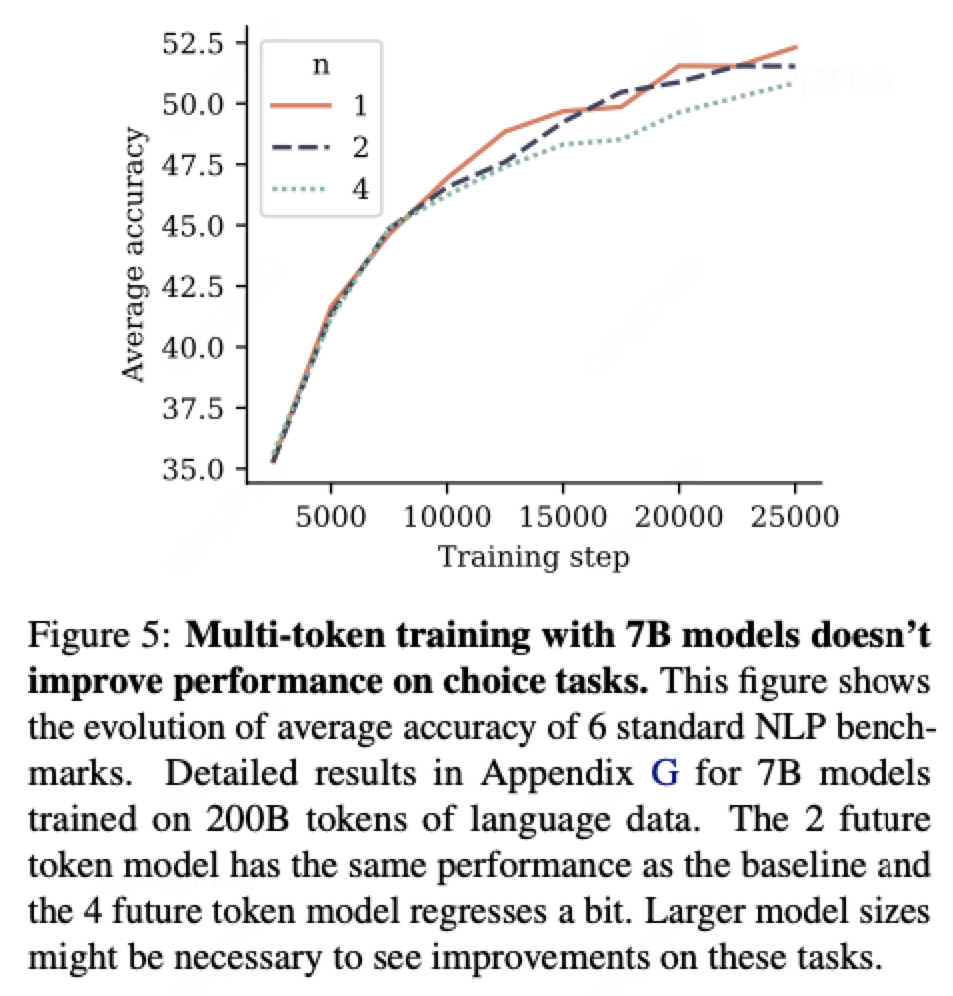
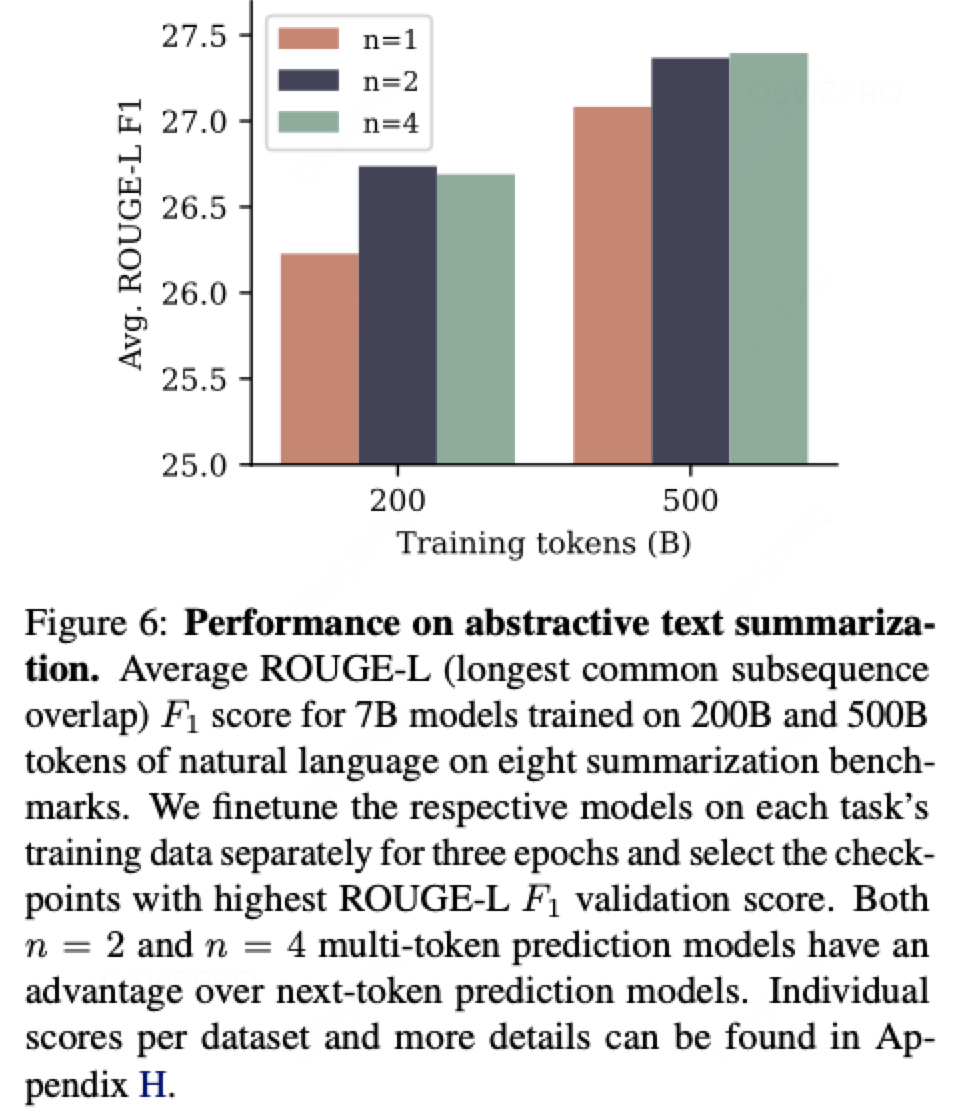
2.2 在抽象文本總結任務上有提升:
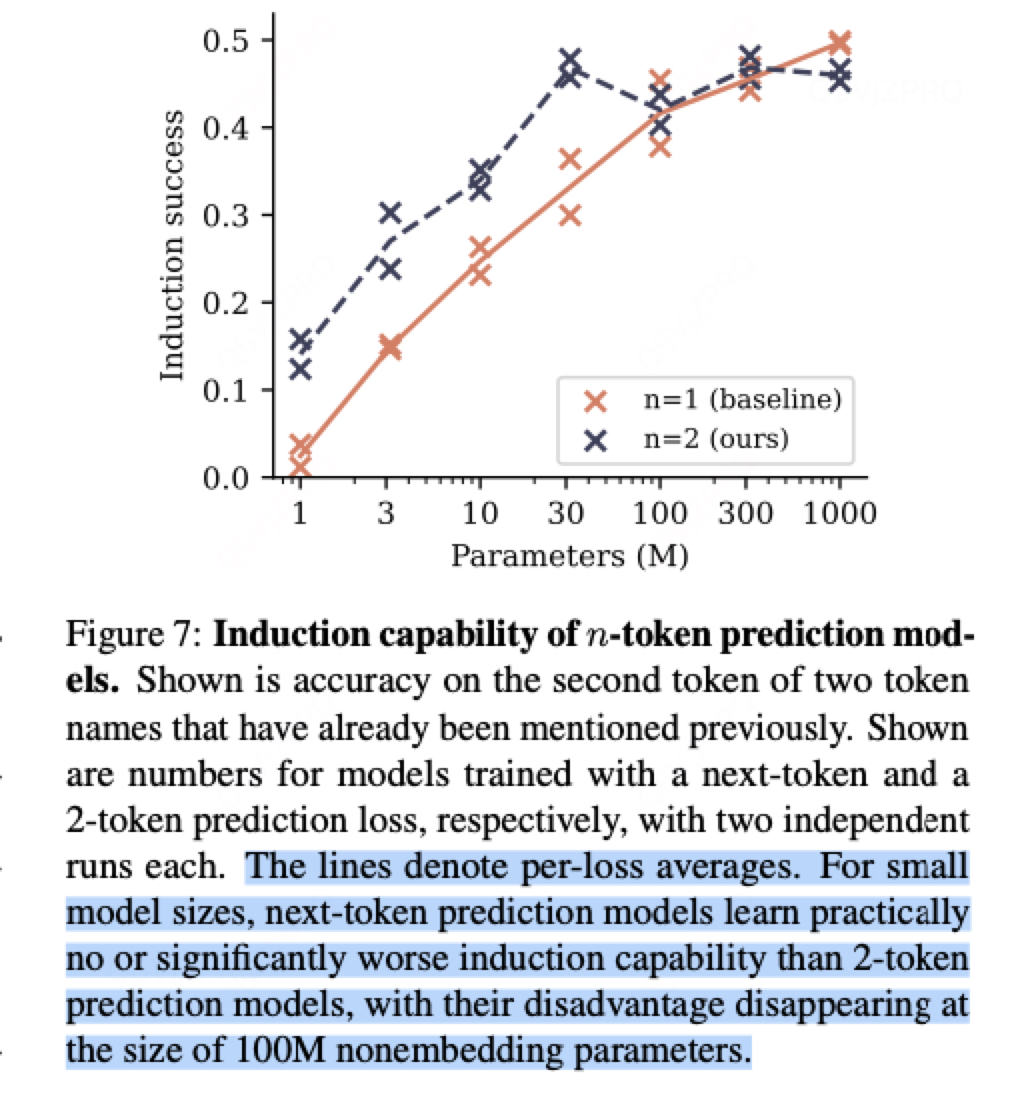
2.3:歸納能力:隨著模型大小增大,兩者能力趨于相同。
為什么MLP對效果有提升的幾點猜測:
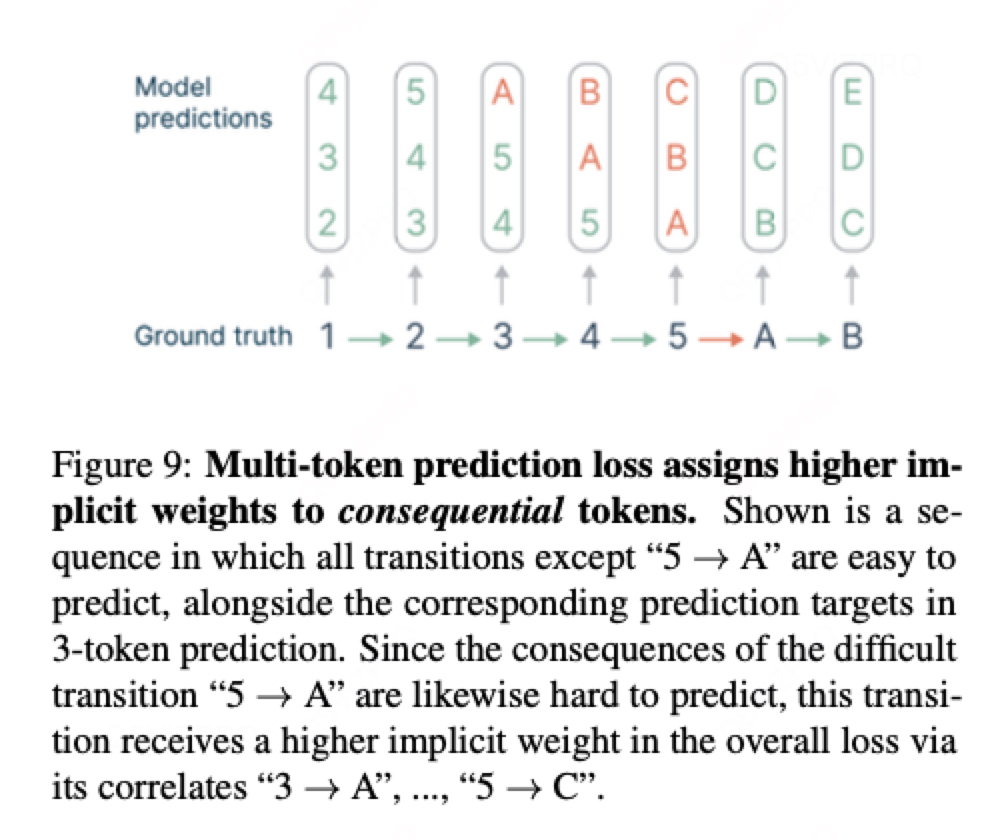
1.?并非所有token對生成質量的影響相同
在語言模型生成文本時,某些token的決策對整體質量至關重要,而另一些則影響較小(如風格變化)。
-
關鍵選擇點(Choice Points):影響文本高層語義的token(例如問答中的核心術語、邏輯轉折詞),錯誤會導致回答偏離主題。
-
無關緊要的token(Inconsequential Transitions):僅影響局部風格(如近義詞替換),不影響后續內容。
2. 關鍵選擇點的權重累積機制
關鍵選擇點(如位置?t)的決策錯誤會直接影響后續多個token的生成。例如:
-
若模型在?t 處預測錯誤,可能導致?t+1,t+2,…,t+n?的預測全部偏離正確路徑。
-
此時,總損失中會包含?Lt+1,Lt+2,…,Lt+n?,這些損失均與?t?處的錯誤相關。
數學推導(以n=5為例):
-
關鍵選擇點(如位置?t)的錯誤會影響后續5個token的預測,其總權重為:
這里的權重?k?表示第?k?步的損失對關鍵點的梯度貢獻。
-
無關緊要的token(如位置?t+1)僅影響后續4個token,總權重為
,但實際實現中可能簡化為固定權重?n。
多token預測的損失函數在反向傳播時,關鍵點的梯度會從多個未來位置的損失中累積:
-
傳統自回歸:位置?t?的錯誤僅通過?Lt+1的梯度更新參數。
-
多token預測:位置?t?的錯誤通過?Lt+1,Lt+2,…,Lt+n 的梯度疊加更新參數,形成更高的有效權重(梯度在反向傳播時會自然累積到共同依賴的關鍵點上)。
例如,若位置?t 是生成回答中的核心術語(如“量子力學”),其錯誤會導致后續所有相關解釋偏離正軌。此時,模型從多個未來位置的損失中接收到更強的信號,迫使它優先學習正確預測此類關鍵點。
3. 從互信息的角度解釋
還沒完全理解,理解后再更新
4.?因果語言模型的傳統因子化順序
-
基本公式:因果語言模型(如GPT)將文本序列的聯合概率分解為自回歸形式,即按時間順序逐個預測下一個token
-
特點:生成順序嚴格從前向后(如首先生成?x1?,再基于?x1??生成?x2?,依此類推)。
-
局限性:某些語言結構(如屈折語中的語法一致性)需要逆向或跳躍式依賴,傳統順序可能不高效。
屈折語中的語法一致性挑戰
-
示例:德語句子
Wie konnten auch Worte meiner durstenden Seele genügen?
包含以下語法依賴:-
動詞?genügen?要求其賓語為與格(Dative Case)。
-
名詞?Seele?為陰性單數與格,因此所有修飾成分(如物主代詞?meiner?和分詞?durstenden)必須與其在性、數、格上一致。
-
-
關鍵矛盾:
-
傳統自回歸順序需先生成?meiner?和?durstenden,再生成?Seele?和?genügen。
-
但實際上,后續的?genügen?和?Seele?的語法要求決定了前面的?meiner?和?durstenden?的形式。
-
非因果因子化順序的優勢(多token預測提升對復雜語法結構(如屈折、一致關系)的處理能力)
-
逆向推理:若模型能先預測后續關鍵token(如?genügen?和?Seele),再生成前面的修飾詞(如?meiner?和?durstenden),可更高效確保語法一致性。
-
示例中的理想順序:
主句→genu¨gen→Seele→meiner→durstenden主句→genu¨gen→Seele→meiner→durstenden -
優勢:先生成核心動詞和名詞,再根據其語法要求調整修飾詞形態,避免回溯錯誤。
通過隱式建模非因果依賴,減少因局部錯誤導致的全局矛盾
-
傳統單步預測:模型僅基于上文生成下一個token,無法顯式利用后續token的語法信息。
-
多token預測(如4-token):
-
強制模型在生成當前token時,潛在表示(latent activations)中需編碼后續多個token的信息。
-
例如,生成?meiner?時,模型已隱式預判后續的?durstenden、Seele、genügen?的語法要求,從而正確選擇與格陰性單數形式。
-
-
訓練機制:多token預測損失函數要求模型同時預測多個位置,迫使潛在表示包含未來上下文信息。
問題:
為什么多token預測可以對關鍵點錯誤施加高權重懲罰?loss不是獨立的?為什么損失函數中每個token的權重與其對后續token的影響相關?






,整合IK分詞器和安裝Kibana)









)


