文章目錄
- 1. Redis Sentinel的概念
- 1.1 基本概念
- 1.2 引出高可用
- 2. Redis Sentinel的部署(基于docker)
- 2.1 部署
- 2.2 驗證
- 2.3 選舉流程

Redis 的主從復制模式下,?旦主節點由于故障不能提供服務,需要人工進行主從切換,同時?量的客?端需要被通知切換到新的主節點上,對于上了?定規模的應用來說,這種?案是無法接受的,于是Redis從2.8開始提供了RedisSentinel(哨兵)來解決這個問題
1. Redis Sentinel的概念
1.1 基本概念
在介紹RedisSentinel之前,先對?個名詞概念進?必要的說明
Redis Sentinel 是Redis 的?可?實現?案,在實際的?產環境中,對提?整個系統的?可?是?常有幫助的
1.2 引出高可用
主從復制模式很好,但是并不是萬能的,它同樣遺留下以下?個問題:
- 主節點發?故障時,進?主從切換的過程是復雜的,需要完全的??參與,導致故障恢復時間?法保障。
- 主節點可以將讀壓?分散出去,但寫壓?/存儲壓?是?法被分擔的,還是受到單機的限制。
其中第?個問題是高可用問題,即Redis哨兵主要解決的問題;第?個問題是屬于存儲分布式的問題,留給Redis集群去解決。
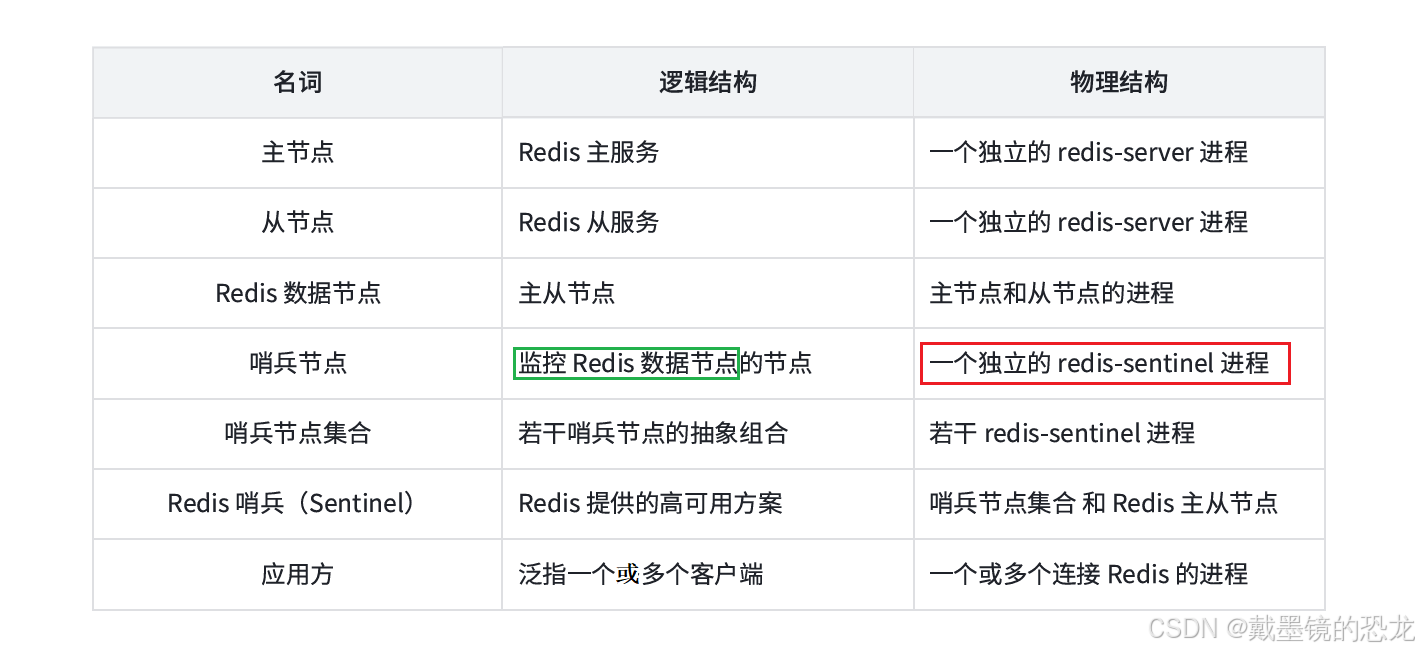
人工恢復主節點故障
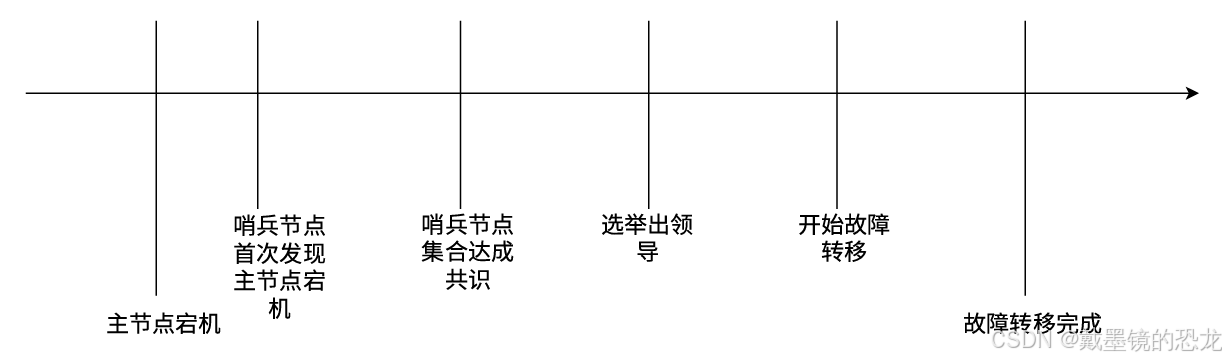
Redis 主從復制模式下,主節點故障后需要進?的人工工作是?較繁瑣的,我們在圖中?致展?了整體過程
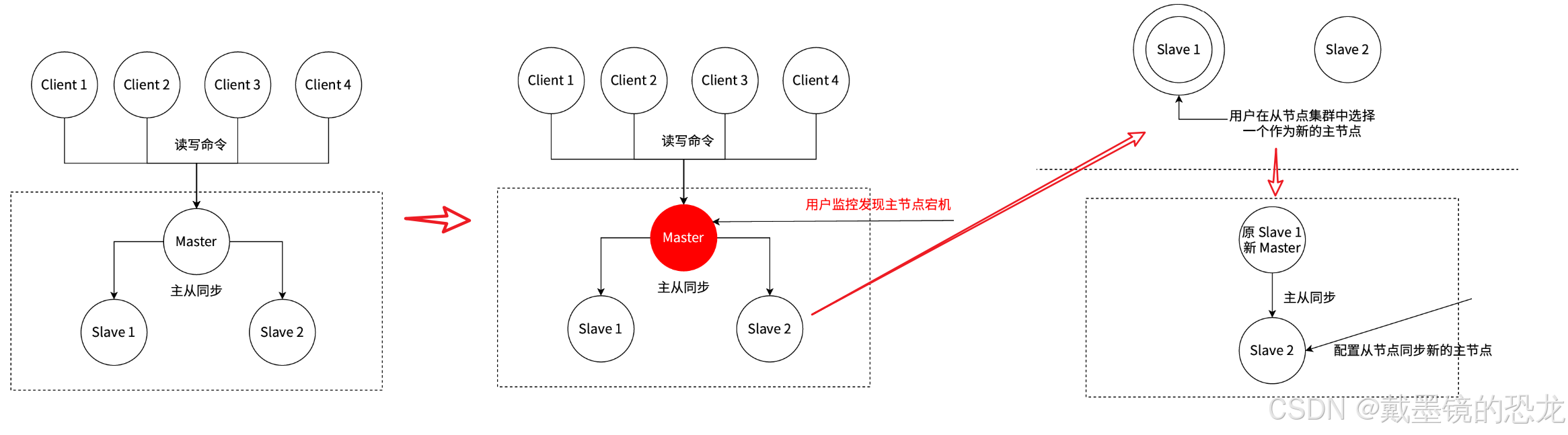
哨兵?動恢復主節點故障
當主節點出現故障時,RedisSentinel能?動完成故障發現和故障轉移,并通知應用方,從?實現真正的?可?。
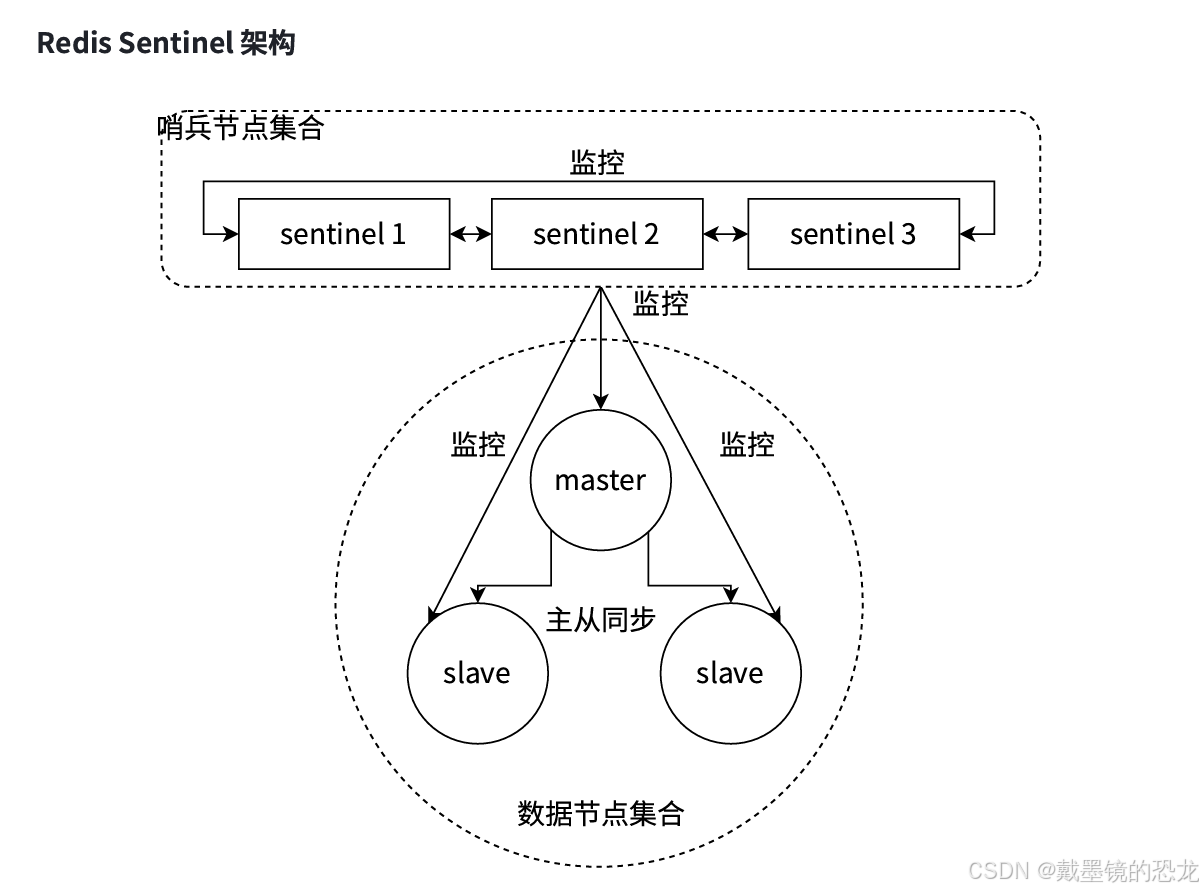
Redis Sentinel 是?個分布式架構,其中包含若?個Sentinel節點和Redis數據節點,每個Sentinel 節點會對數據節點和其余Sentinel節點進?監控(這些進程之間,建立tcp長連接,定期發送心跳包)。
- 當它發現節點不可達時,會對節點做下線表示。
- 如果下線的是主節點,它還會和其他的Sentinel節點進?“協商”(防止誤判),當?多數Sentinel節點對主節點不可達這個結論達成共識之后,它們會在內部“選舉”出?個領導節點來完成?動故障轉移的?作,同時將這個變化實時通知給Redis應用方。
整個過程是完全?動的,不需要人工介入
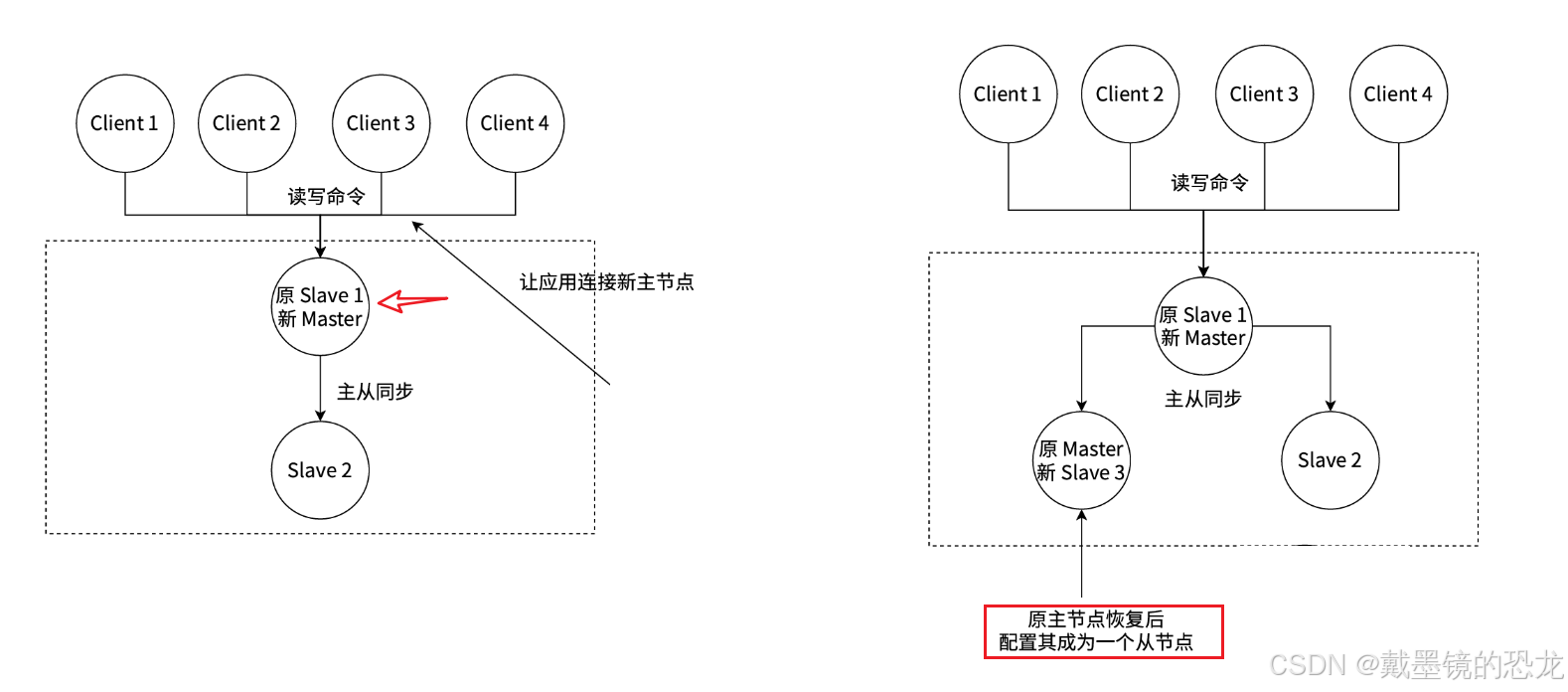
針對主節點故障的情況,故障轉移流程?致如下:
- 主節點故障,從節點同步連接中斷,主從復制停?。
- 哨兵節點通過定期監控發現主節點出現故障。哨兵節點與其他哨兵節點進?協商,達成多數認同主節點故障的共識。這步主要是防?該情況:出故障的不是主節點,?是發現故障的哨兵節點,該情況經常發?于哨兵節點的?絡被孤?的場景下。
- 哨兵節點之間使?Raft算法選舉出?個領導??,由該節點負責后續的故障轉移?作。
- 哨兵領導者開始執?故障轉移:從節點中選擇?個作為新主節點(
slaveof no one);讓其他從節點同步新主節點(slaveof host port)- 通知應?層轉移到新主節點。
通過上面的介紹,可以看出Redis Sentinel具有以下幾個功能:
- 監控:Sentinel節點會定期檢測Redis數據節點、其余哨兵節點是否可達。
- 故障轉移:實現從節點晉升(promotion)為主節點并維護后續正確的主從關系。
- 通知:Sentinel節點會將故障轉移的結果通知給應??
2. Redis Sentinel的部署(基于docker)
2.1 部署
- 安裝docker和docker-compose
apt install docker-compose
- 停?之前的redis-server
# 停?redis-server
service redis-server stop# 停?redis-sentinel 如果已經有的話.
service redis-sentinel stop
- 使?docker獲取redis鏡像
docker pull redis:5.0.9
解決 Docker 錯誤:docker: Get https://registry-1.docker.io/v2/: net/http: request canceled 的問題
# 1. 修改 Docker 配置文件
sudo nano /etc/docker/daemon.json# 2.將以下內容添加到配置文件中:
{"registry-mirrors" : ["https://docker.m.daocloud.io","https://docker-cf.registry.cyou"],"insecure-registries" : ["docker.mirrors.ustc.edu.cn"],"debug": true,"experimental": false
}
# 3.重啟 Docker 服務
sudo systemctl restart docker

編排redis主從節點:創建三個容器,作為redis數據節點
- 編寫docker-compose.yml
創建/root/redis/docker-compose.yml,同時cd到yml所在?錄中,編寫yml文件
version: '3.7'
services:master:image: 'redis:5.0.9'container_name: redis-masterrestart: alwayscommand: redis-server --appendonly yesports:- 6379:6379slave1:image: 'redis:5.0.9'container_name: redis-slave1restart: alwayscommand: redis-server --appendonly yes --slaveof redis-master 6379ports:- 6380:6379slave2:image: 'redis:5.0.9'container_name: redis-slave2restart: alwayscommand: redis-server --appendonly yes --slaveof redis-master 6379ports:- 6381:6379
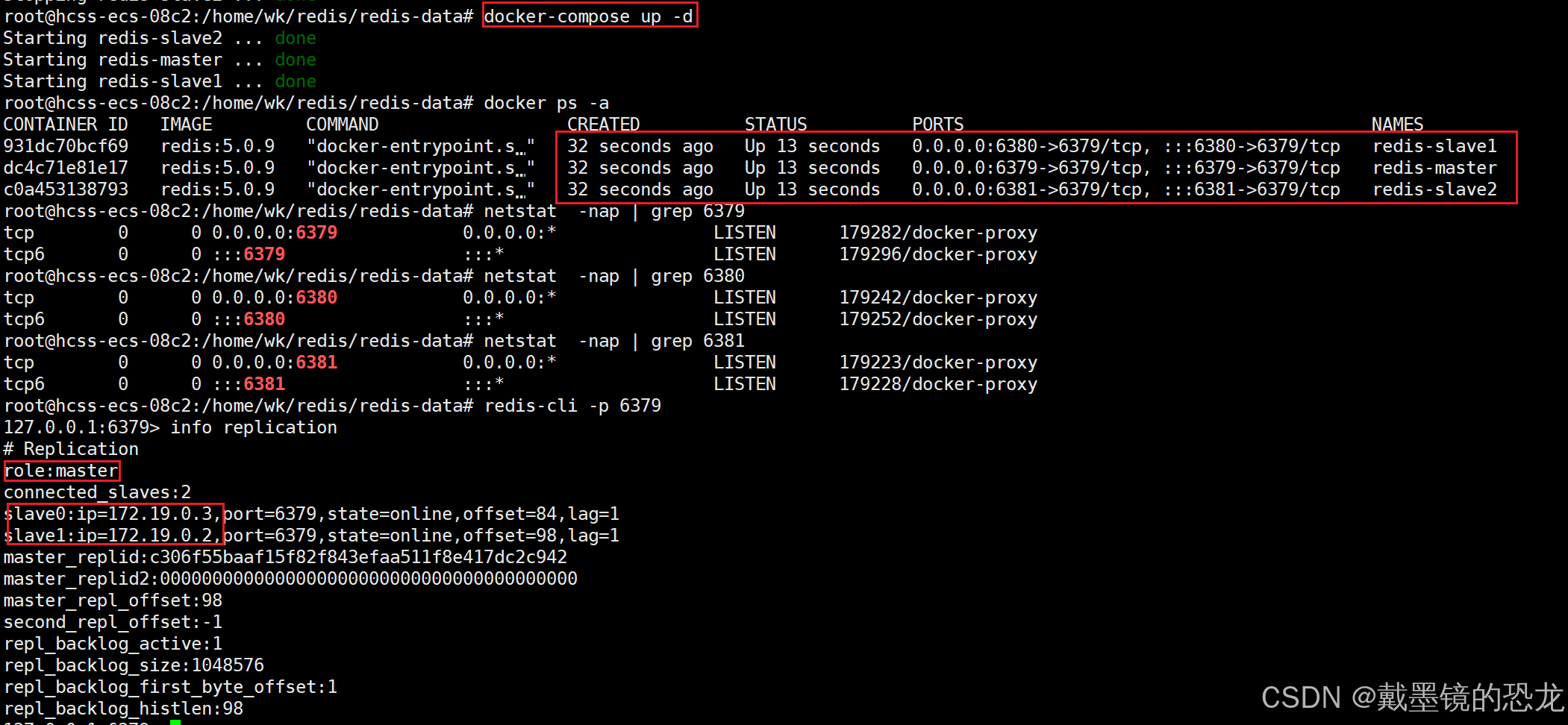
- 啟動所有容器
docker-compose up -d
- 查看運??志
docker-compose logs
編排 redis-sentinel節點
- 編寫docker-compose.yml
創建/root/redis-sentinel/docker-compose.yml,同時cd到yml所在?錄中
version: '3.7'services:sentinel1:image: 'redis:5.0.9'container_name: redis-sentinel-1restart: alwayscommand: redis-sentinel /etc/redis/sentinel.confvolumes:- ./sentinel1.conf:/etc/redis/sentinel.confports:- "26379:26379"sentinel2:image: 'redis:5.0.9'container_name: redis-sentinel-2restart: alwayscommand: redis-sentinel /etc/redis/sentinel.confvolumes:- ./sentinel2.conf:/etc/redis/sentinel.confports:- "26380:26379" sentinel3:image: 'redis:5.0.9'container_name: redis-sentinel-3restart: alwayscommand: redis-sentinel /etc/redis/sentinel.confvolumes:- ./sentinel3.conf:/etc/redis/sentinel.confports:- "26381:26379"
networks:default:external:name: redis-data_default
- 創建配置?件
創建sentinel1.conf、sentinel2.conf、sentinel3.conf,三份?件的內容是完全相同的
bind 0.0.0.0
port 26379
sentinel monitor redis-master redis-master 6379 2
sentinel down-after-milliseconds redis-master 1000
sentinel monitor主節點名 主節點ip 主節點端? 法定票數
sentinel down-after-milliseconds:主節點和哨兵之間通過?跳包來進?溝通,如果?跳包在指定的時間內還沒回來,就視為是節點出現故障.
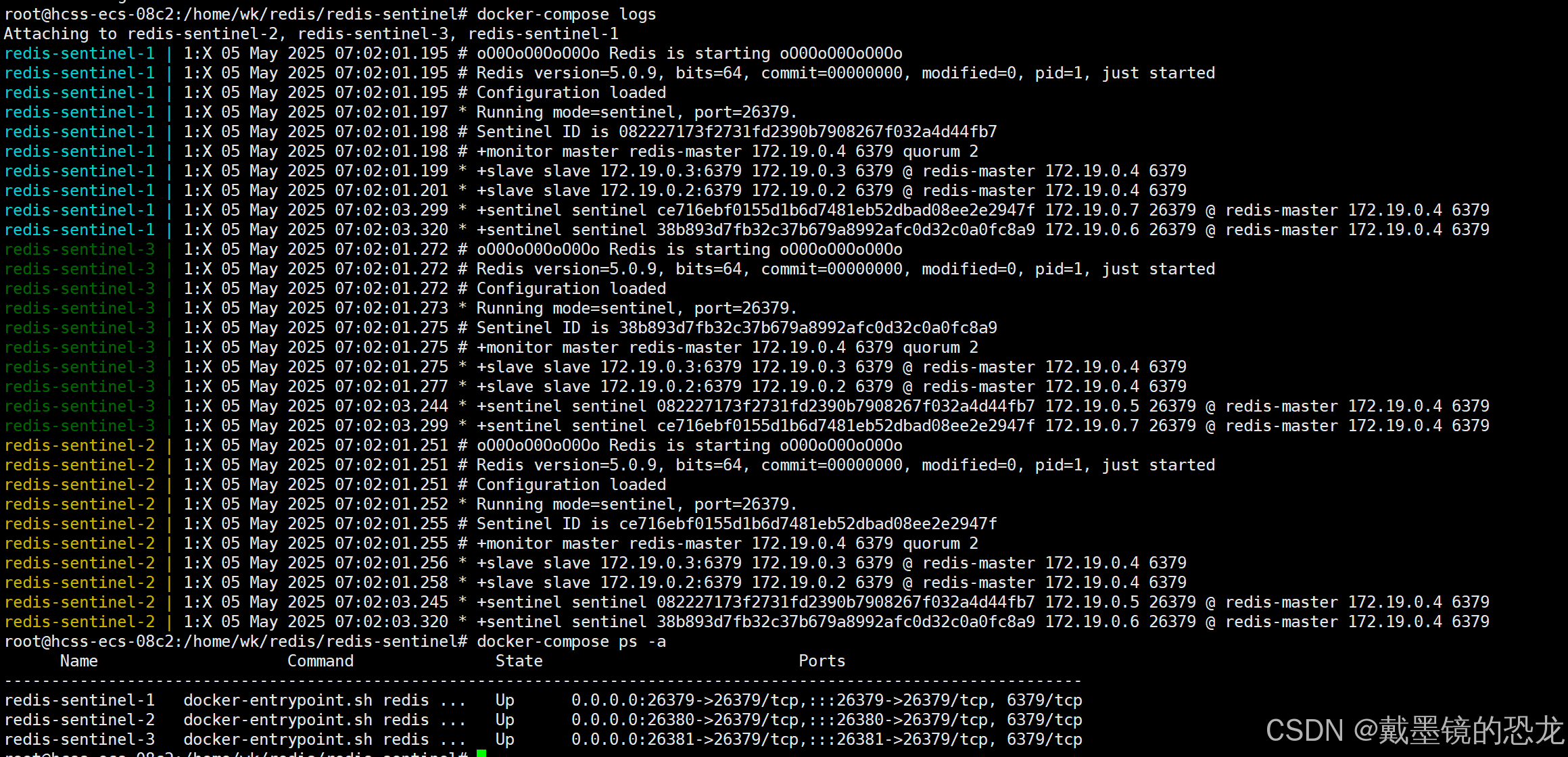
- 啟動所有容器
docker-compose up -d
- 查看運??志
docker-compose logs
2.2 驗證
至此,我們的節點就編排好了
下面我們來驗證一下哨兵效果
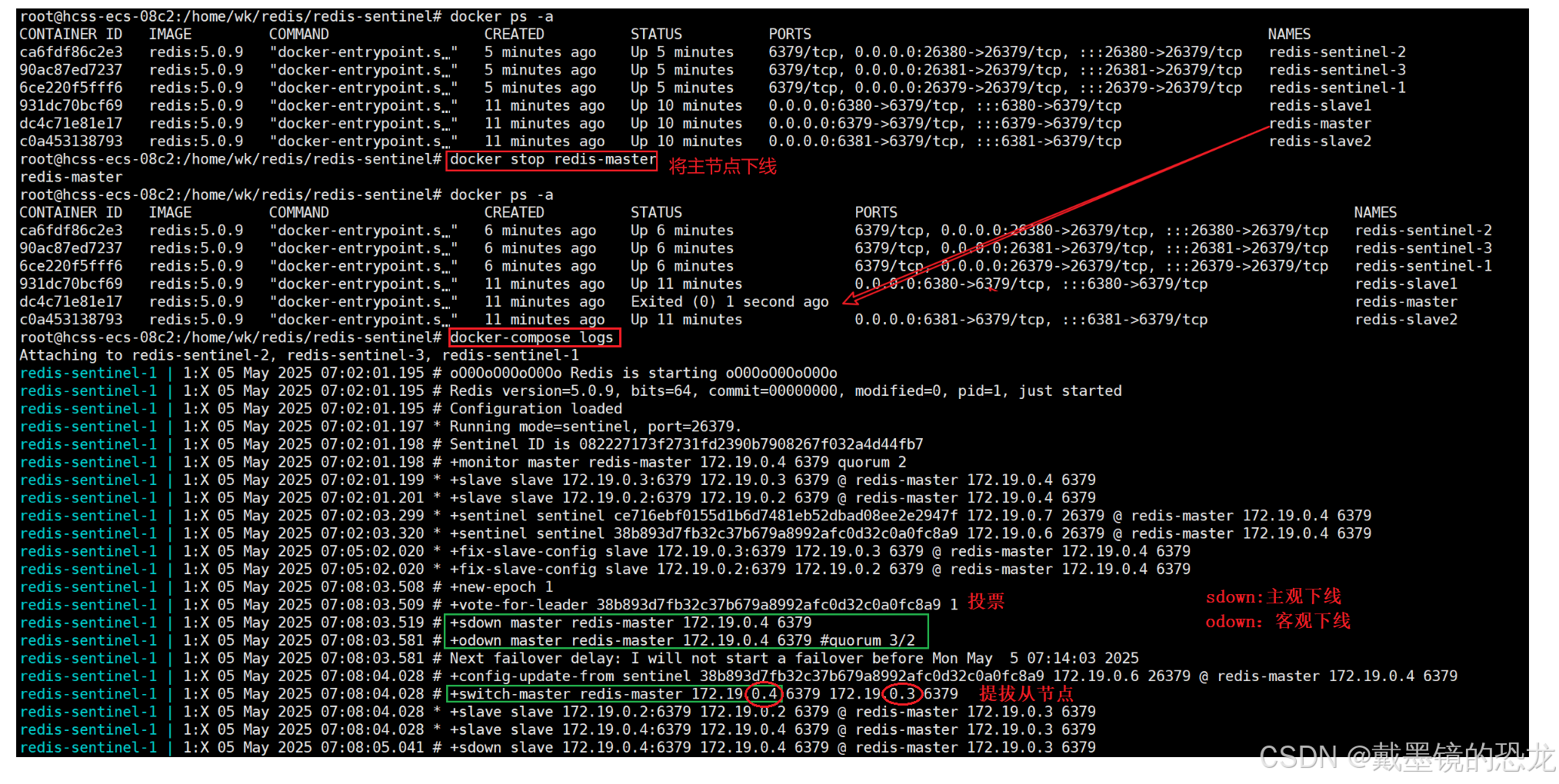
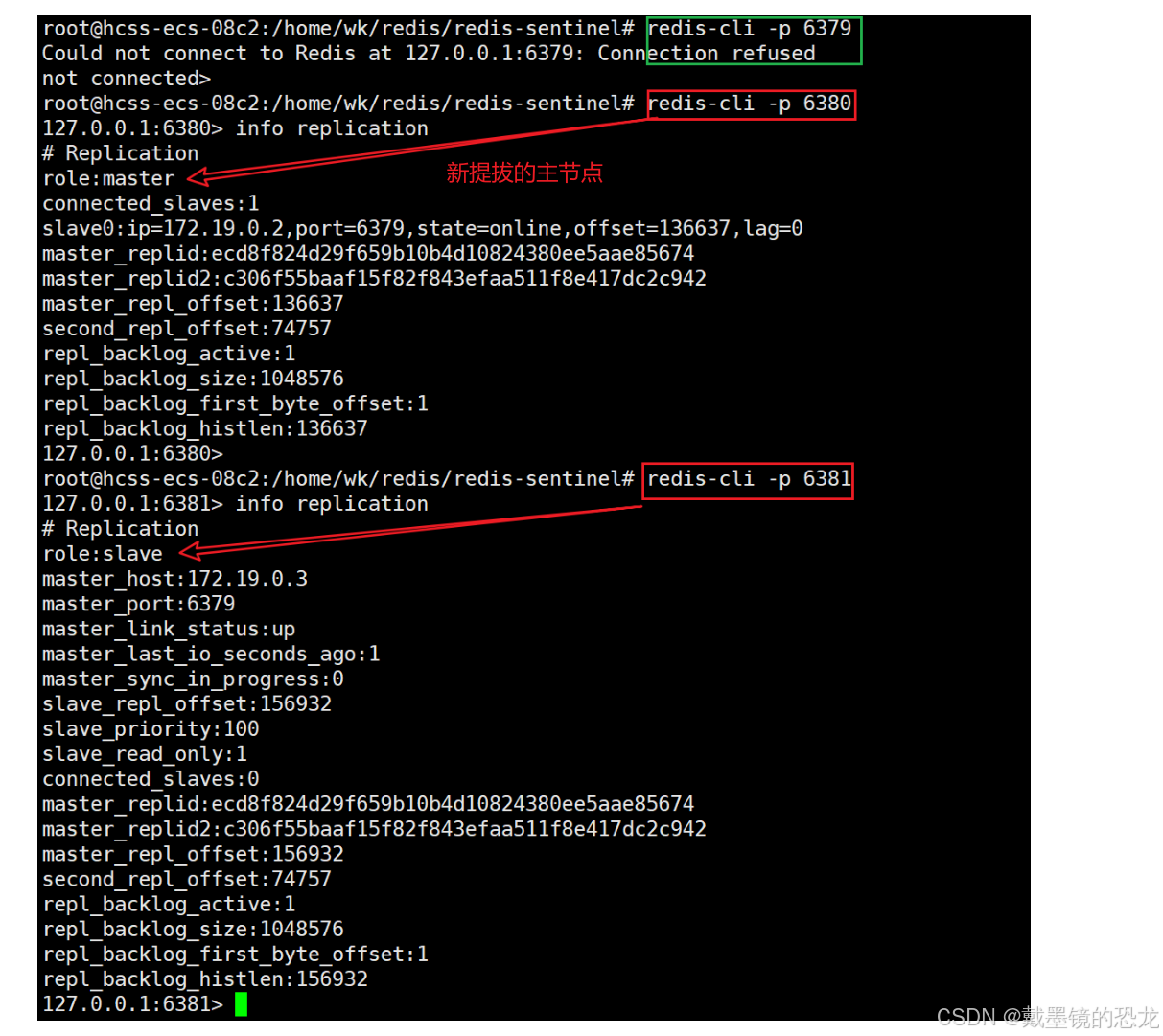
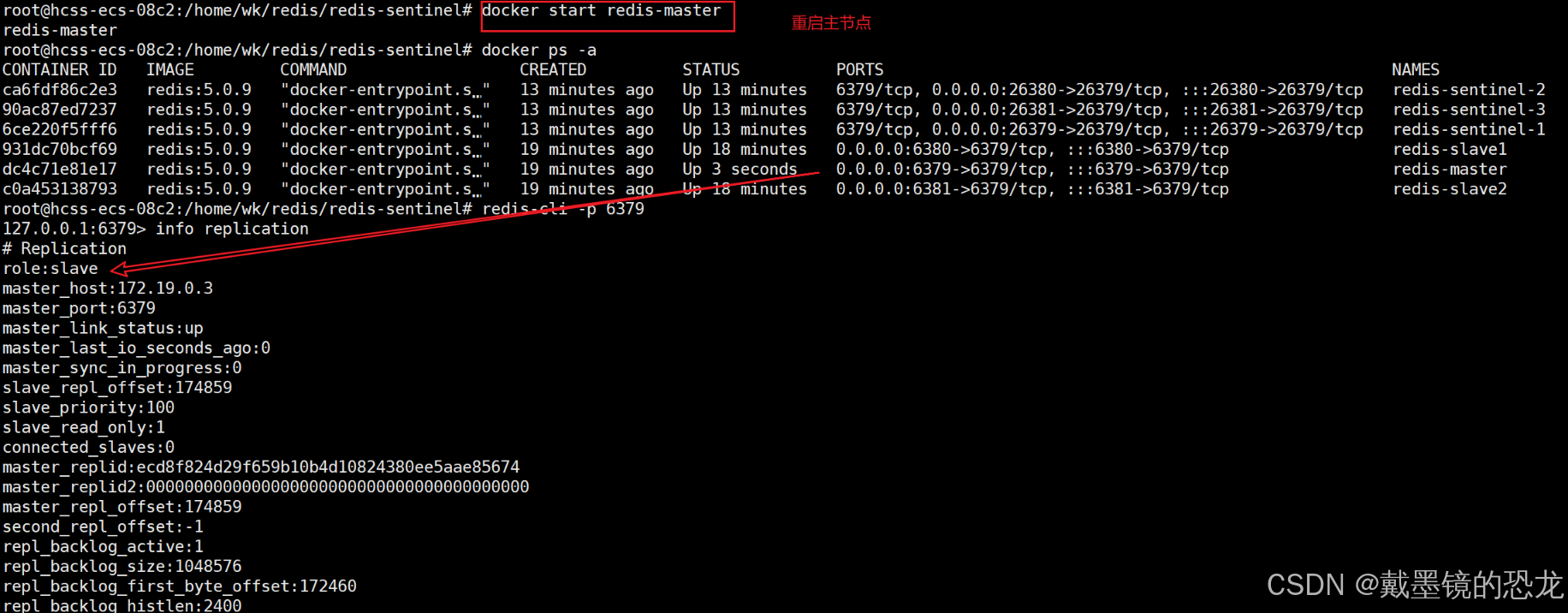
結論
- Redis主節點如果宕機,哨兵會把其中的?個從節點,提拔成主節點.
- 當之前的Redis主節點重啟之后,這個主節點被加?到哨兵的監控中,但是只會被作為從節點使?
2.3 選舉流程
假定當前環境如上?介紹,三個哨兵(sentenal1、sentenal2、sentenal3),?個主節點(redis-master),兩個從節點(redis-slave1,redis-slave2),當主節點出現故障,就會觸發重新?系列過程
- 主觀下線
當redis-master 宕機,此時redis-master和三個哨兵之間的?跳包就沒有了,此時站在三個哨兵的?度來看,redis-master出現嚴重故障,因此三個哨兵均會把redis-master判定為主觀下線(SDown)
- 客觀下線
此時,哨兵sentenal1、sentenal2、sentenal3均會對主節點故障這件事情進?投票,當故障得票數>=配置的法定票數之后,此時意味著redis-master故障這個事情被做實了,此時觸發客觀下線(ODown)
- 選舉出哨兵的leader
接下來需要哨兵把剩余的slave中挑選出?個新的master,這個?作不需要所有的哨兵都參與,只需要選出個代表(稱為leader),由leader負責進?slave升級到master的提拔過程,這個選舉的過程涉及到Raft 算法。
下面的過程是面試重點
選舉leader的過程:
- 每個哨兵都只有一票
- 當哨兵A第一個發現主節點是客觀下線時,就立即給自己投一票,并告知哨兵B、C(相當于拉票)
- 哨兵B、C反應慢半拍,當收到哨兵A的告知,并且自己手中的票還在,就投給哨兵A
- 若有多個拉票請求,則投給先到達的
- 如果總票數超過哨兵數量的一半,則leader選舉完成(哨兵個數為奇數個,就是為了方便投票)
- 其實,投票的過程,就是看哪個哨兵的反應快(網絡延遲小)
leader選好后,就需要推舉從節點,從節點變為主節點的過程:
- 查看節點優先級:每個redis節點,都配置了一個優先級
slave-priority,優先級高的勝出- 優先級相同,查看offset:
offset越大,表示從節點同步主節點的數據越多,二者越接近,offset大的勝出- 優先級、offset都相同,查看runid:節點的
runid是隨機的,此時就看緣分了
新的主節點選好后,leader就會控制這個節點,執行slave no one,成為master節點;在控制其它節點,執行slaveof,讓這些節點,以新的master作為主節點。
上述過程,都是"??值守",Redis?動完成的,這樣做就解決了主節點宕機之后需要???預的問題,提?了系統的穩定性和可?性
?些注意事項:
- 哨兵節點不能只有?個,否則哨兵節點掛了也會影響系統可?性.
- 哨兵節點最好是奇數個,?便選舉leader,得票更容易超過半數.
- 哨兵節點不負責存儲數據,仍然是redis主從節點負責存儲
- 哨兵節點可以使用配置不是很高的節點
- 哨兵+主從復制解決的問題是"提?可?性",不能解決"數據極端情況下寫丟失"的問題
- 即主節點寫的數據,從節點還未同步,主節點就掛了。所以需要寫多份數據
- 哨兵+主從復制不能提?數據的存儲容量,當我們需要存的數據接近或者超過機器的物理內存,這樣的結構就難以勝任了
- 為了能存儲更多的數據,需要引?了集群
















教程 | 小程序UI設計進階!控件可見性設置)
![2025年滲透測試面試題總結-快手[實習]安全工程師(題目+回答)](http://pic.xiahunao.cn/2025年滲透測試面試題總結-快手[實習]安全工程師(題目+回答))
)

