引言:
上期我們講了什么是邏輯回歸,了解了它如何利用Sigmoid函數將線性回歸的輸出轉化為概率,并通過最大似然估計來尋找最佳參數。今天,我們將繼續這段旅程,學習如何訓練這個
模型、如何評估它的表現,以及如何在真實世界中應用它。
回顧第一篇結尾,我們得到了(對數)似然函數,目標是找到使其最大化的參數θ。但如何找到呢?—— 梯度下降,如果模型訓練好了,如何衡量它的好壞?—— 評估指標,在本篇文章當中我們用鳶尾花分類這個經典案例講解如何運用我們之前所學的知識,構建一個預測模型。
(找到使其最大化的參數θ所用到的梯度下降在這篇文章【機器學習十大算法】線性回歸(二)中有詳細的理論解釋。)
Step1:下載數據集
鏈接: https://pan.baidu.com/s/1yIMbV6xO_P_3TdTNLGs4NQ?pwd=732q提取碼: 732q?
先簡單觀察一下這個數據集
特征說明:
| 列名 | 含義 | 數據類型 | 說明 |
|---|---|---|---|
| S_L | 花萼長度 | 數值型 | Sepal Length |
| S_W | 花萼寬度 | 數值型 | Sepal Width |
| P_L | 花瓣長度 | 數值型 | Petal Length |
| P_W | 花瓣寬度 | 數值型 | Petal Width |
| response | 鳶尾花種類 | 文本型 | 分類標簽 |
?類別分布:
數據集中包含三種鳶尾花:
| 類別 | 樣本數量 |
|---|---|
| 山鳶尾 | 50 |
| 雜色鳶尾 | 50 |
| 維吉尼亞鳶尾 | 50 |
(這給數據集只是方便教學使用,在實際開發當中我們并不總能找到這么完美的數據集)
Step2:導入必要的庫(我用的軟件是pycharm,用conda管理環境,具體可參考這篇Conda 環境管理與 PyCharm 集成實戰:從創建到包安裝的全方位指南)
pip install pandas numpy matplotlib seaborn scikit-learn openpyxl或者激活conda環境后:
conda install pandas numpy matplotlib seaborn scikit-learn openpyxl分析一下這些庫:
pandas: 數據分析和處理的“瑞士軍刀”,提供 DataFrame 來輕松處理表格數據。numpy: 用于高效數值計算的底層庫,核心是多維數組 (ndarray)。matplotlib: Python 中最基礎、最通用的數據可視化庫,用于創建各種圖表。seaborn: 基于 Matplotlib,提供更美觀、更強大的統計圖表,尤其適合探索性數據分析。scikit-learn: 機器學習的標準庫,提供易于使用的算法和工具,用于模型訓練和評估。openpyxl: 用于讀取和寫入?.xlsx?格式 Excel 文件的庫。
Step3:數據加載和探索
這步主要是讓你清楚數據集的結構等等,在數據集較為龐大的時候尤為重要
# -*- coding: gbk -*- #編碼聲明,防止非 UTF-8 報錯
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.svm import SVC
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report# 設置中文字體支持
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用來正常顯示中文標簽
plt.rcParams['axes.unicode_minus'] = False # 用來正常顯示負號# 加載數據(記得將數據集導入pycharm項目,最簡單的方法就是拖進去)
df = pd.read_excel('Data1-train.xlsx', sheet_name='Sheet1')# 數據探索
print("數據集形狀:", df.shape)
print("\n前5行數據:")
print(df.head())
print("\n數據基本信息:")
print(df.info())
print("\n描述性統計:")
print(df.describe())
print("\n類別分布:")
print(df['response'].value_counts())結果:
數據集形狀: (154, 5)前5行數據:S_L S_W P_L P_W response
0 5.1 3.5 1.4 0.2 山鳶尾
1 4.9 3 1.4 0.2 山鳶尾
2 4.7 3.2 1.3 0.2 山鳶尾
3 4.6 3.1 1.5 0.2 山鳶尾
4 5 3.6 1.4 0.2 山鳶尾數據基本信息:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 154 entries, 0 to 153
Data columns (total 5 columns):# Column Non-Null Count Dtype
--- ------ -------------- ----- 0 S_L 151 non-null object1 S_W 151 non-null object2 P_L 151 non-null object3 P_W 151 non-null object4 response 151 non-null object
dtypes: object(5)
memory usage: 6.1+ KB
None描述性統計:S_L S_W P_L P_W response
count 151 151 151.0 151.0 151
unique 36 24 44.0 23.0 4
top 5 3 1.5 0.2 山鳶尾
freq 10 26 14.0 28.0 50類別分布:
response
山鳶尾 50
雜色鳶尾 50
維吉尼亞鳶尾 50
response 1
Name: count, dtype: int64Process finished with exit code 0
這樣我們不僅對數據集有個大概的了解還能及時發現異常,看完之后我們就可以將數據探索這部分的代碼注釋掉了,結果會決定我們后面對數據進行預處理的方法(前面我們提到,數據集不總是完美的,可能會有數據缺失,類別不平衡的問題,這個時候我們就可以根據需要選擇重采樣等方法去進行數據預處理)
觀察后我們發現了異常,類別分布中顯示將response錯誤認為是一種類別并且顯示數量為1,在Step4我們做些處理刪掉這一行。
Step4:數據預處理
#刪除異常值
df_0 = df[df['response'] != 'response']
# 刪除空行,刪除缺失值
df_0 = df_0.dropna()# 確認數據清理后的形狀
print("清理后數據集形狀:", df_0.shape)# 分離特征和目標變量
X = df_0.iloc[:, :-1].values # 所有行,除最后一列外的所有列
y = df_0.iloc[:, -1].values # 所有行,只取最后一列# 將類別標簽轉換為數值
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
y = le.fit_transform(y)# 查看編碼映射
print("類別編碼:", list(le.classes_))
print("編碼對應:", dict(zip(le.classes_, le.transform(le.classes_))))# 劃分訓練集和測試集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42, stratify=y)print(f"訓練集大小: {X_train.shape}") # (樣本數, 特征數)
print(f"測試集大小: {X_test.shape}")# 特征標準化
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
結果如下:

代碼解析:
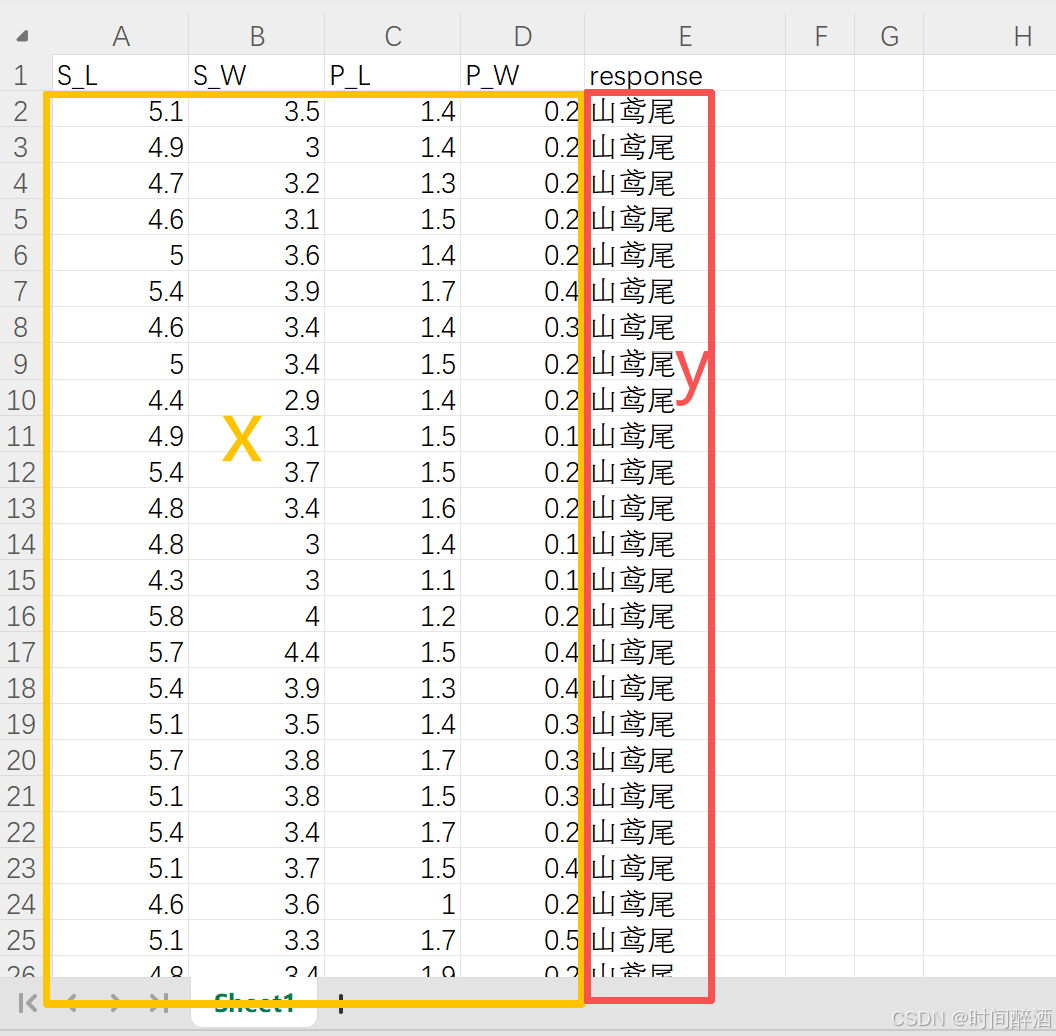
# 分離特征和目標變量:
x = df_0.iloc[:, :-1].values
?iloc 是基于整數位置的索引。 : 表示選擇所有行。 :-1 表示選擇從第一列到倒數第二列(不包含最后一列)。.values 將選取的 DataFrame 部分轉換為 NumPy 數組。(這部分代碼用于提取所有特征列,并將它們存儲在 NumPy 數組? x?中)
y = df_0.iloc[:, -1].values ?
其他同上,.values?將選取的 最后一列轉換為 NumPy 數組。(這部分代碼用于提取目標變量列(通常是分類標簽),并存儲在 NumPy 數組? y 中。)
簡單來說就是這么選的:
# 將類別標簽轉換為數值:
from sklearn.preprocessing import Label
le = LabelEncoder( )
(LabelEncoder 的作用是將分類的文本標簽(如 '山鳶尾', '雜色鳶尾')轉換為機器可以理解的數字格式(如 0, 1, 2)。)?
y = le.fit_transform(y)
le.fit(y) :LabelEncoder會掃描? y??數組,找出所有唯一的類別標簽,并學習它們之間的映射關系。 le.transform(y) :根據學習到的映射關系,將? y 數組中的每個文本標簽替換為對應的數字。 fit_transform(y)?結合了上述兩個步驟,一步完成學習和轉換。 轉換后的數值型 y 已經被重新賦值,供后續模型使用。
# 查看并打印編碼映射:
list(le.classes_)
le.classes_ 是? LabelEncoder? 在? fit??過程中學習到的所有唯一類別標簽(按字母順序排序)。這里將其轉換為列表,方便查看。
dict(zip(le.classes_, le.transform(le.classes_)))
le.transform(le.classes_) : 將所有唯一的類別標簽再次進行轉換,得到它們對應的數字編碼。? zip(le.classes_, le.transform(le.classes_)) : 將原始類別標簽和它們的數字編碼一 一配對。? dict(...): 將這些配對轉換成一個字典,例如 `{'山鳶尾': 0, '雜色鳶尾': 1, '維吉尼亞鳶尾': 2}`。 ( 這段代碼的作用是清晰地展示原始文本標簽和它們被轉換后的數字標簽之間的對應關系。)
#劃分訓練集和測試集
from sklearn.model_selection import train_test_split : 導入用于劃分數據集的函數。
?X_train, X_test, y_train, y_test = train_test_split( X, y, test_size=0.2, random_state=42, stratify=y)?:?
test_size=0.2 : 指定將 20% 的數據用作測試集,剩下的 80% 用作訓練集。
?random_state=42 : 這是一個種子值,用于確保每次運行代碼時,數據集的劃分都是相同的,這有助于復現實驗結果。如果省略,每次劃分都會不同。
stratify = y: 這是非常重要的一點。它表示在劃分訓練集和測試集時,保持原始? y??數組中各類別的比例分布。 (例如,如果原始數據中有 50% 的 '山鳶尾',那么訓練集和測試集中的 '山鳶尾' 比例也應該大致是 50%。 這樣做對于處理類別不平衡的數據集非常重要,可以確保模型的訓練和評估在各個類別上都盡可能公平。)
# 特征標準化
scaler = StandardScaler()X_train = scaler.fit_transform(X_train)X_test = scaler.transform(X_test)scaler = StandardScaler(): 創建一個標準化工具,準備好進行標準化的“算法”。
scaler.fit_transform(X_train):
學習 (fit)?訓練集?X_train?的每個特征的均值和標準差。
應用 (transform)?學習到的均值和標準差,將?X_train?的數值標準化。
scaler.transform(X_test):
應用 (transform)?之前從?X_train?中學習到的相同的均值和標準差,將測試集?X_test?的數值標準化。
最終的效果:
X_train?和?X_test?中的所有數值都被縮放到一個共同的尺度(均值為 0,標準差為 1)。這樣,在后續的機器學習模型訓練和預測中,各個特征之間的數值差異就不會因為其原始的量級不同而造成不公平的影響,模型可以更有效地學習。
本文總結
在本篇文章中,我們以一個經典的鳶尾花分類數據集為例,完整地演示了構建一個機器學習預測模型的第一步和第二步:
-
數據加載與探索 (Data Loading & Exploration)
-
使用?
pandas?庫讀取 Excel 格式的數據集。 -
通過?
.shape,?.head(),?.info(),?.describe(),?.value_counts()?等方法快速了解數據集的全貌,包括數據規模、特征類型、缺失值、統計信息和類別分布。 -
關鍵發現:在探索過程中,我們敏銳地發現了數據中的異常行(
‘response‘?被錯誤地當作了一個類別標簽)和數據缺失問題。
-
-
數據預處理 (Data Preprocessing)
-
數據清洗 (Data Cleaning):果斷地刪除了包含異常值和缺失值的行,保證了數據質量。
-
特征與標簽分離 (Feature/Target Split):使用?
.iloc?將數據明確劃分為特征矩陣?X?和目標變量?y。 -
標簽編碼 (Label Encoding):利用?
LabelEncoder?將文本形式的花卉種類標簽(如‘山鳶尾’)轉換為數值形式(如 0, 1, 2),這是模型能夠處理的前提。 -
數據集劃分 (Train-Test Split):使用?
train_test_split?方法將數據劃分為訓練集和測試集,并設置了?stratify?參數以確保訓練集和測試集中各類別的比例一致,這對于獲得可靠的模型評估結果至關重要。 -
特征標準化 (Feature Standardization):使用?
StandardScaler?對特征數據進行標準化處理,將不同尺度的特征縮放到同一標準正態分布下,從而大幅提升許多機器學習模型(如邏輯回歸、SVM)的性能和訓練速度。
-
至此,我們已經擁有了一個干凈、規整、且經過預處理的訓練集 (X_train,?y_train) 和測試集 (X_test,?y_test),為下一步的模型訓練做好了萬全準備。
下一步預告:數據準備就緒后,我們將進入下一個環節——數據可視化。在下一篇文章中,我們將:
-
使用預處理好的數據集進行可視化。
-
詳細分析可視化圖標所蘊含的信息
-
詳細分析每一條代碼的含義一步步敲出數據可視化
-
深入講解并運用三種可視化圖標來全面觀察數據集,對比分析不同模型反映出什么樣的數據信息。
敬請期待:邏輯回歸(三):從原理到實戰 - 訓練、評估與應用指南??(鏈接將在文章發布后更新)
作者本人水平有限,非常歡迎任何反饋和指正,請隨時指出我可能存在的誤解、遺漏或表述不當之處。
我將繼續深入學習機器學習和統計學領域,并持續更新我的理解和最佳實踐。我愿意虛心接受反饋,不斷打磨和完善我的內容,以便為讀者提供更可靠、更有價值的信息。






Yolo V8神經網絡的基礎應用)

)
-----目標檢測和圖像分類、語義分割的區別)

:k8s環境使用helm部署Seaweedfs集群)
)

如何實現)

的三種文件組織形式,工程文件,自由文件與存盤文件)

)
