文章目錄
- Kernal
- 引入
- 定義
- Mercer定理
- 描述
- 有限情形證明
- 一般情形證明
Kernal
引入
??在實際數據中常常遇到不可線性分割的情況,此時通常需要將其映射到高維空間中,使其變得線性可分。例如二維數據:
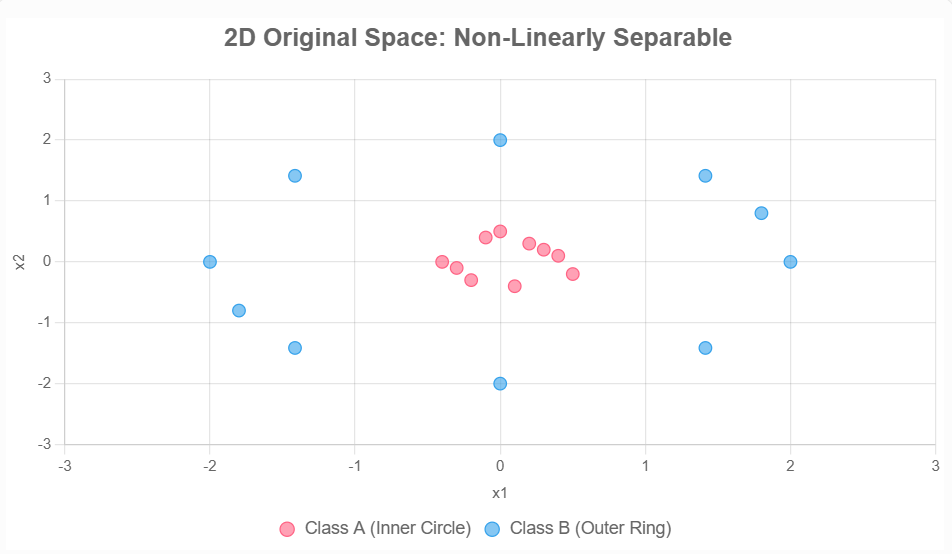
通過映射 ? ( x 1 , x 2 ) = ( x 1 2 , 2 x 1 x 2 , x 2 2 ) \phi(x_1, x_2) = (x_1^2, \sqrt{2}x_1x_2, x_2^2) ?(x1?,x2?)=(x12?,2?x1?x2?,x22?),將數據投影到三維空間,下面展示的是一個二維投影(三維畫不出來):
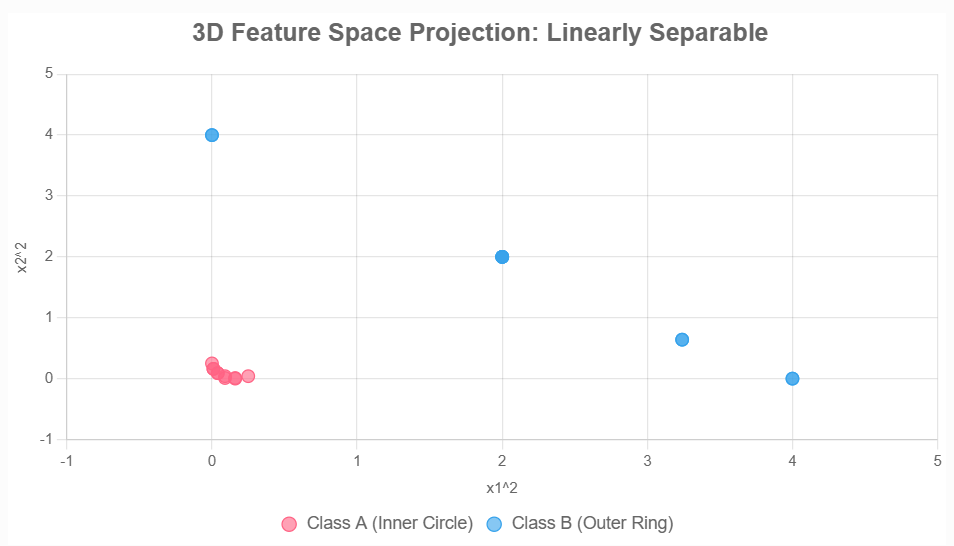
??于是我們可以找到一個超平面(如 x 1 2 + x 2 2 = c x_1^2 + x_2^2 = c x12?+x22?=c)來把兩類數據分開。這種投影方法被稱為顯式投影法,即構造出一個函數 ? ( x ) \phi(x) ?(x)將數據從原始空間投影到高維空間。
??在一些模型中(如SVM),需要計算高維空間下數據點之間的內積 x 1 ? x 2 x_1^\top x_2 x1??x2?,反映數據點之間的相似度。然而將數據點投影后再計算會產生許多時間花費和空間花費。那有沒有什么方法能直接計算出內積,跳過投影的過程呢?~~有的兄弟,有的。~~于是核方法誕生了。
定義
??核方法(Kernel Methods)是一類機器學習算法,旨在通過將數據從原始空間隱式映射到高維特征空間來解決非線性問題,同時利用核函數高效計算特征空間中的內積,而無需顯式計算高維特征向量。
??設輸入空間為 X \mathcal{X} X,如下形式的函數稱為核函數:
K : X × X → R \mathcal{K}: \mathcal{X} \times \mathcal{X} \to \mathbb{R} K:X×X→R
滿足其對應的Gram矩陣是正定的或半正定的,這保證了核函數在數學上定義了一個有效的內積空間。
??則這個核函數一定能寫成某個高維空間的內積 K ( x , x ′ ) = ? ( x ) ? ? ( x ′ ) \mathcal{K}(x,x') = \phi(x)^\top\phi(x') K(x,x′)=?(x)??(x′),這由Mercer定理支持。
Mercer定理
描述
??如果核函數 K : X × X → R \mathcal{K}: \mathcal{X} \times \mathcal{X} \to \mathbb{R} K:X×X→R滿足Mercer條件,即正定性,則存在一個映射 ? : X → H \phi: \mathcal{X} \to \mathcal{H} ?:X→H,將 x x x映射到某個希爾伯特空間,使得:
K ( x , x ′ ) = ? ( x ) T ? ( x ′ ) \mathcal{K}(x, x') = \phi(x)^T\phi(x') K(x,x′)=?(x)T?(x′)
有限情形證明
先在有限數據集 { x 1 , . . . , x N } ? X \set{x_1, ..., x_N} \subset \mathcal{X} {x1?,...,xN?}?X上證明:由于 K \mathcal{K} K是對稱正定矩陣,則可以分解為
K = U ? Λ U Λ = diag? ( λ 1 , . . . , λ N ) , λ i ≥ 0 \mathcal{K} = U^\top\Lambda U \\ \Lambda = \text{diag }(\lambda_1, ..., \lambda_N), \lambda_i \ge 0 \\ K=U?ΛUΛ=diag?(λ1?,...,λN?),λi?≥0
U U U是正交矩陣, U ? U = I U^\top U=I U?U=I,列向量 u 1 , . . . , u N u_1, ..., u_N u1?,...,uN?是特征向量。
定義特征映射為 ? : X → R N \phi:\mathcal{X} \to \mathbb{R}^N ?:X→RN為:
? ( x i ) = Λ 1 / 2 u i \phi(x_i) = \Lambda^{1/2}u_i ?(xi?)=Λ1/2ui?
其中 Λ 1 / 2 = diag? ( λ 1 , . . . , λ N ) \Lambda^{1/2} = \text{diag }\left(\sqrt{\lambda_1}, ..., \sqrt{\lambda_N}\right) Λ1/2=diag?(λ1??,...,λN??)
驗證內積:
? ( x i ) ? ? ( x j ) = u i ? Λ u j = K ( x i , x j ) \phi(x_i)^\top\phi(x_j) = u_i^\top \Lambda u_j = \mathcal{K}(x_i, x_j) ?(xi?)??(xj?)=ui??Λuj?=K(xi?,xj?)
補充:若 K \mathcal{K} K的秩 r < N r < N r<N,(可能有零特征值),特征空間的維度可以降為 r r r,即只保留非零特征值對應的分量。
這證明了對于有限數據集,核函數可以通過特征分解構造一個有限維特征空間的內積。
一般情形證明
??為了嚴謹性,對于一般核函數 K ( x , x ′ ) \mathcal{K}(x, x') K(x,x′),輸入空間 X \mathcal{X} X可能是連續的(如 X = R d \mathcal{X} = \mathbb{R}^d X=Rd或緊致域),且核函數可能定義在無窮多點上。Mercer定理的完整形式需要函數空間的理論,特別是再生核希爾伯特空間(RKHS)。
??假設:
(1) X \mathcal{X} X是緊致集
(2) K ( x , x ′ ) \mathcal{K}(x, x') K(x,x′)是對稱的、連續的,且滿足Mercer條件(正定性)。
(3)正定性在連續情形下定義為:對于任意平方可積函數 f ∈ L 2 ( X ) f \in \mathcal{L}^2(\mathcal{X}) f∈L2(X),有:
? X × X f ( x ) K ( x , x ′ ) f ( x ′ ) d x d x ′ ≥ 0 \iint_{\mathcal{X} \times \mathcal{X}} f(x)\mathcal{K}(x, x')f(x')dxdx' \ge 0 ?X×X?f(x)K(x,x′)f(x′)dxdx′≥0
??然后對 K \mathcal{K} K進行特征展開,核函數 K ( x , x ′ ) \mathcal{K}(x, x') K(x,x′)作為一個對稱正定算子,可以通過特征值分解表示。定義積分算子:
( T K f ) ( x ) = ∫ X K ( x , x ′ ) f ( x ′ ) d x ′ (T_Kf)(x) = \int_\mathcal{X}\mathcal{K}(x, x')f(x')dx' (TK?f)(x)=∫X?K(x,x′)f(x′)dx′
T K T_K TK?是一個緊致、自我伴隨的算子(因為 K \mathcal{K} K對稱且連續)。根據希爾伯特-施密特理論, T K T_K TK?有可數個特征值 λ i ≥ 0 \lambda_i \ge 0 λi?≥0和對應的特征函數 ψ i ( x ) \psi_i(x) ψi?(x),滿足:
T K ψ i = λ i ψ i , ∫ X K ( x , x ′ ) ψ i ( x ′ ) d x ′ = λ i ψ i T_K \psi_i = \lambda_i\psi_i, \int_\mathcal{X}\mathcal{K}(x, x')\psi_i(x')dx' = \lambda_i\psi_i TK?ψi?=λi?ψi?,∫X?K(x,x′)ψi?(x′)dx′=λi?ψi?
特征函數 { ψ i } \left\{\psi_i\right \} {ψi?}構成了 L 2 ( X ) \mathcal{L}^2(\mathcal{X}) L2(X)的正交基,滿足:
∫ X ψ i ( x ) ψ j ( x ) d x = δ i j \int_\mathcal{X}\psi_i(x)\psi_j(x)dx = \delta_{ij} ∫X?ψi?(x)ψj?(x)dx=δij?
核函數可以表示為特征展開:
K ( x , x ′ ) = ∑ ∞ i = 1 λ i ψ i ( x ) ψ i ( x ′ ) \mathcal{K}(x,x') = \underset{i=1}{\overset{\infty}{\sum}}\lambda_i\psi_i(x)\psi_i(x') K(x,x′)=i=1∑∞??λi?ψi?(x)ψi?(x′)
這一級數在 X × X \mathcal{X} \times \mathcal{X} X×X上均勻收斂(因為 K \mathcal{K} K連續且 X \mathcal{X} X緊致)
然后我們構造特征映射 ? : X → H \phi: \mathcal{X} \to \mathcal{H} ?:X→H,其中 H \mathcal{H} H是希爾伯特空間(通常是 l 2 l^2 l2,無窮維序列空間),可以理解為無限維的歐幾里得空間。
? ( x ) = ( λ 1 ψ 1 ( x ) , λ 1 ψ 2 ( x ) , . . . ) \phi(x) = \left(\sqrt{\lambda_1}\psi_1(x), \sqrt{\lambda_1}\psi_2(x), ... \right) ?(x)=(λ1??ψ1?(x),λ1??ψ2?(x),...)
每個 ? ( x ) \phi(x) ?(x)是一個無窮序列,其分量為 λ i ψ i ( x ) \sqrt{\lambda_i}\psi_i(x) λi??ψi?(x)
在 H \mathcal{H} H中的內積定義為:
? ( x ) ? ? ( x ′ ) = ∑ ∞ i = 1 ( λ i ψ i ( x ) ) ( λ i ψ i ( x ′ ) ) = ∑ ∞ i = 1 λ i ψ i ( x ) ψ i ( x ′ ) = K ( x , x ′ ) \phi(x)^\top\phi(x') = \underset{i=1}{\overset{\infty}{\sum}}\left(\sqrt{\lambda_i}\psi_i(x)\right)\left(\sqrt{\lambda_i}\psi_i(x')\right)=\underset{i=1}{\overset{\infty}{\sum}}\lambda_i\psi_i(x)\psi_i(x') = \mathcal{K}(x,x') ?(x)??(x′)=i=1∑∞??(λi??ψi?(x))(λi??ψi?(x′))=i=1∑∞??λi?ψi?(x)ψi?(x′)=K(x,x′)






教程 | 小程序UI設計進階!控件可見性設置)
![2025年滲透測試面試題總結-快手[實習]安全工程師(題目+回答)](http://pic.xiahunao.cn/2025年滲透測試面試題總結-快手[實習]安全工程師(題目+回答))
)




:進程狀態)

Service)



