注意:目前方法將基于前一章批量數據庫導入的修改!!!!請先閱讀上篇文章的操作。抄襲注明來源
背景
上一節說的方法可以批量導入文件到數據庫,但是無法解決已經上傳的條目更新問題。簡單來說,不會覆蓋原始數據,只會在數據庫后面增加新的條目,并沒有達到更新數據的目的,只能說上一篇文章解決了運營階段智能體能夠和數據后臺的連接,是一把鑰匙。那么本文解決的就是更新的問題【在原始條目上】
思想來源
你需要注意的是,經過我不斷測試下來,字節的這個SQL自定義采用的是Oracle的方式,普通的REPLACE等操作指令不認,會報SQL語句語法錯誤的問題。其次,如果你采用MERGE等操作手段,你會發現SQL語句過于繁瑣,對大批量數據寫入數據庫不友好,插件難以制作。因此,本人不得已采用了一種方式,那就是先刪除原始節點再上傳,同時,我更新了插件代碼,同步生成對應的DEL語句指令
插件2.0代碼
from runtime import Args
#注意下面的 read_excels根據自己設置的插件名稱會有調整。
from typings.test.test import Input, Output
import requests
import io
import pandas as pd
import re
def remove_apostrophe(input_str: str) -> str:"""移除字符串中的英文單引號"""return input_str.replace("'", "’")def handler(args: Args[Input])->Output:# 文檔地址 urlurl = args.input.file_link# 數據庫表明database_table = args.input.database_table# 數據庫表字段名(注意:文檔的表頭名字必須與數據庫表字段名相同)database_table_list = args.input.database_table_listresponse = requests.get(url)values_list = []del_list = []s = ""m = ""if response.status_code == 200:df = pd.read_excel(io.BytesIO(response.content))for index, row in df.iloc[0:].iterrows():for i in database_table_list:res = row[i]if i == "product_name":res = remove_apostrophe(row[i])if i == "erp_code":del_list.append(str(res)) # 直接添加完整的ERP代碼s = f"{s}'{res}',"values_list.append(f"({s[:-1]})")s = ""for i in database_table_list:m = f"{m}{i},"del_content = f"DELETE FROM {database_table} WHERE erp_code IN ({', '.join(f"'{x}'" for x in del_list)});"content = f"INSERT INTO {database_table} ({m[:-1]}) VALUES {', '.join(values_list)};"else:content = f"無法從網址獲取文件,狀態碼:{response.status_code}"del_content = f"無法從網址獲取文件,狀態碼:{response.status_code}"return {"insert_output1":content, "del_output2":del_content}
工作流2.0修改部分展示(完整請私信我)

效果展示
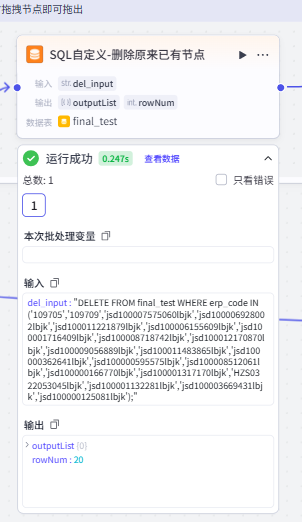
都維持在20條,沒有機械式的簡單增加






)



:終極對比指南)






》閱讀筆記:p82-p82)
)
)
