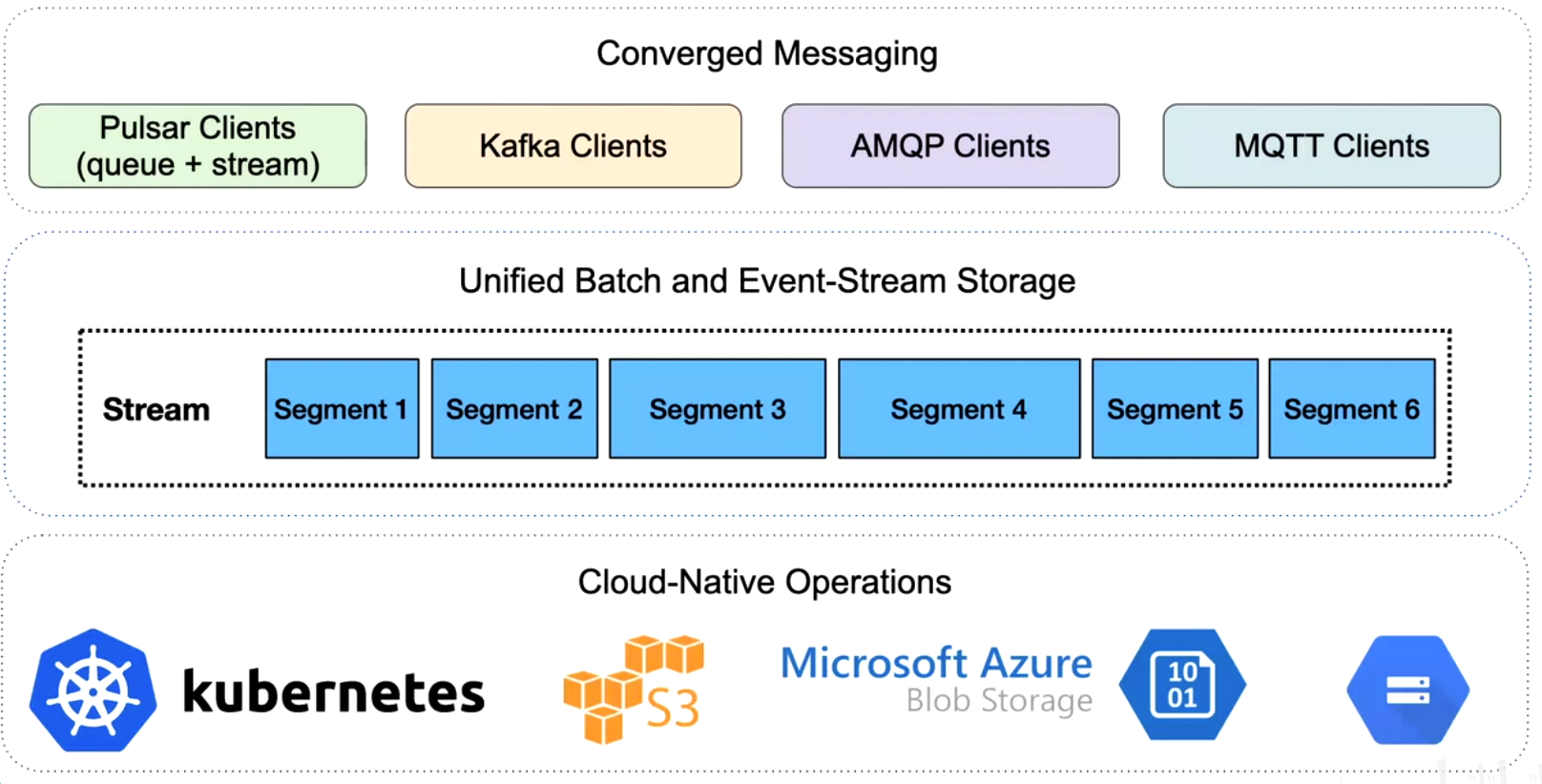
Apache Pulsar 消息、流、存儲的融合
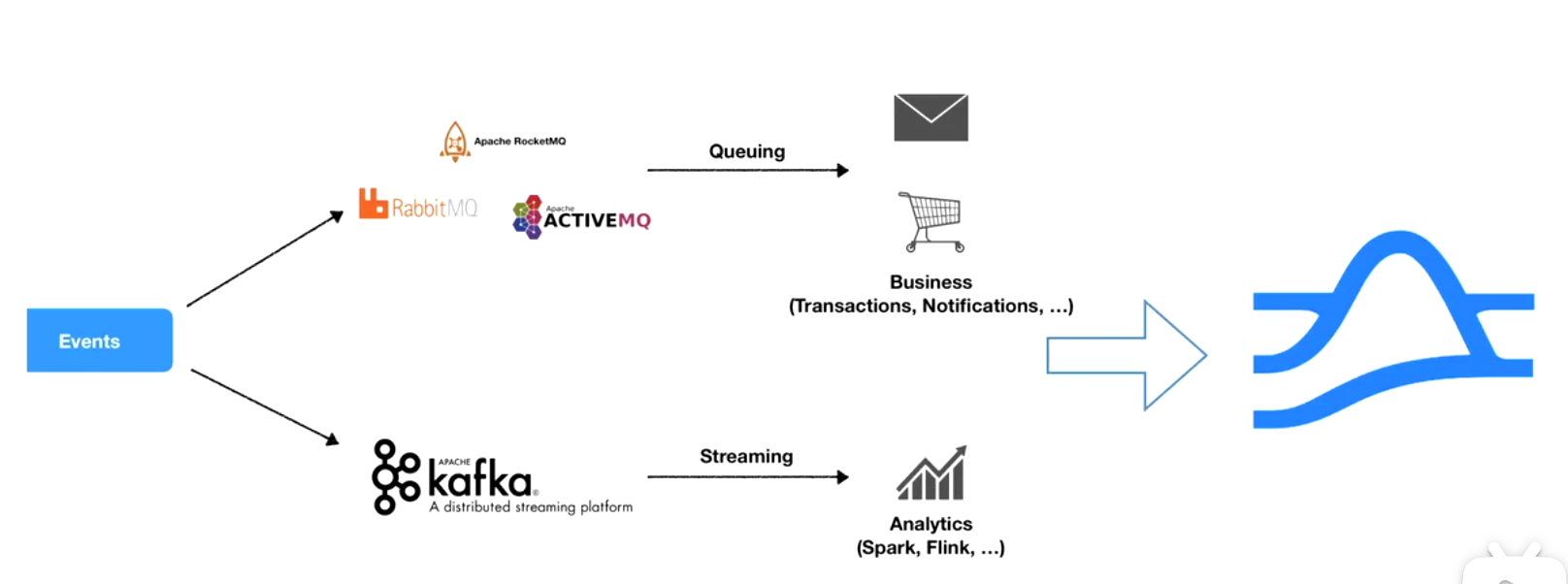
消息隊列在大層面有兩種不同類型的應用,一種是在線系統的message queue,一種是流計算,data pipeline的streaming高throughout,一致性較低,延遲較差的過程。
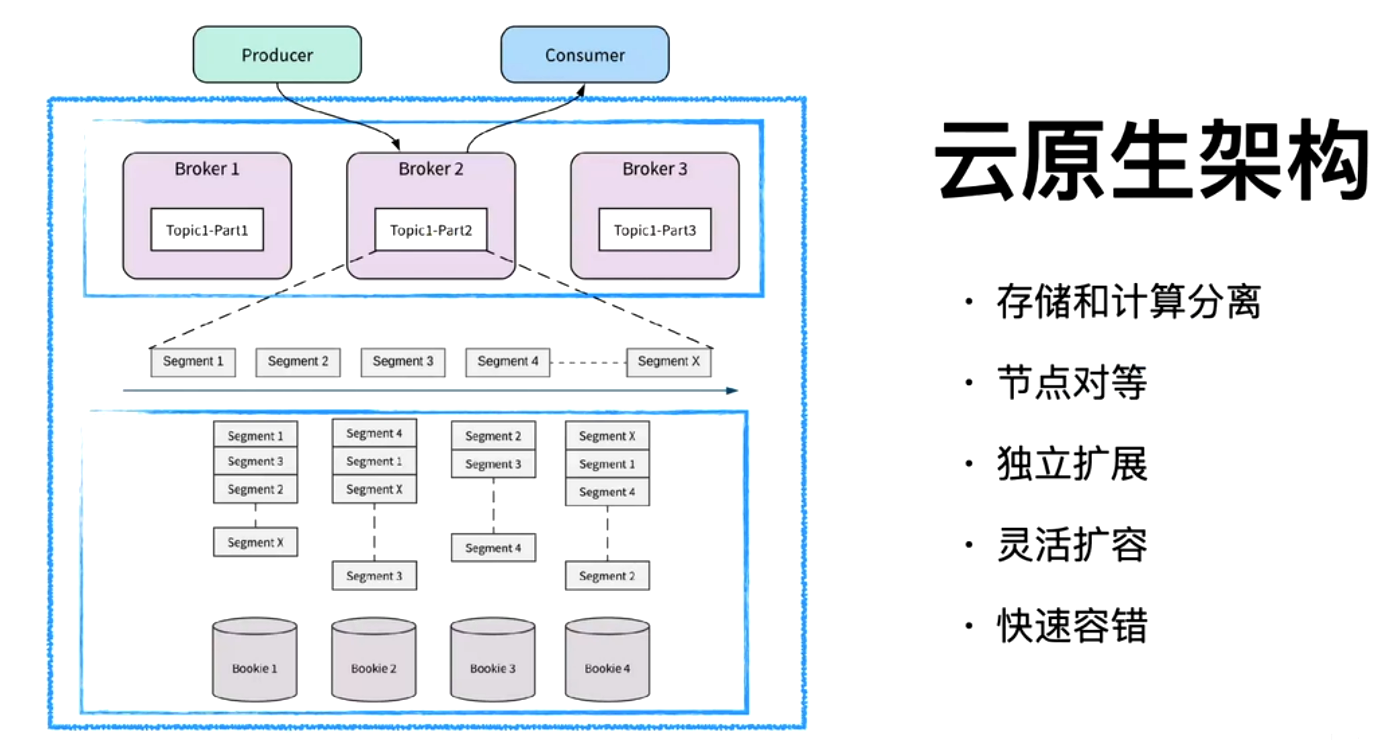
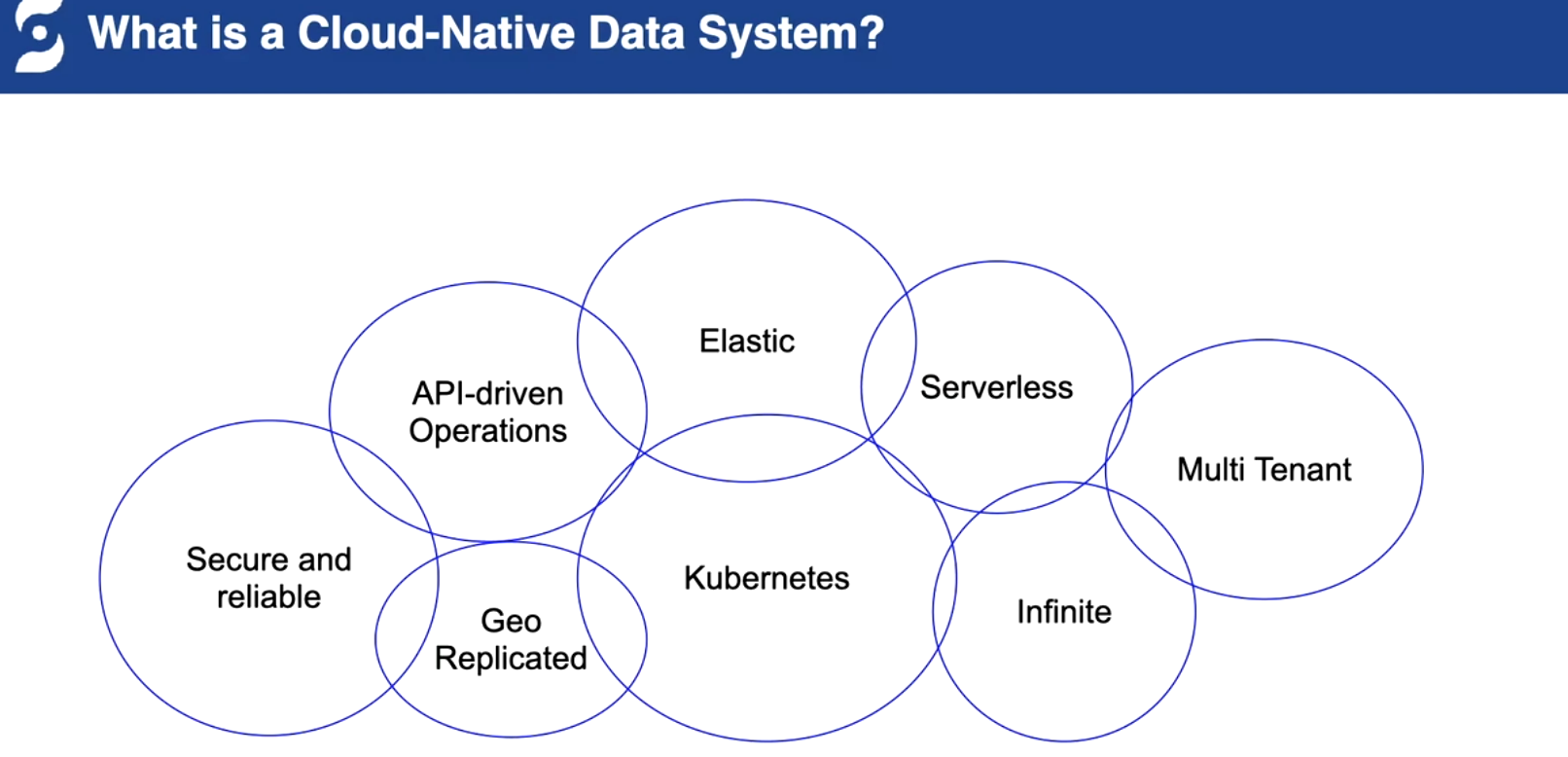
存算分離?擴容和縮容快速
segment 打散(時間和容量切分)多機器能力
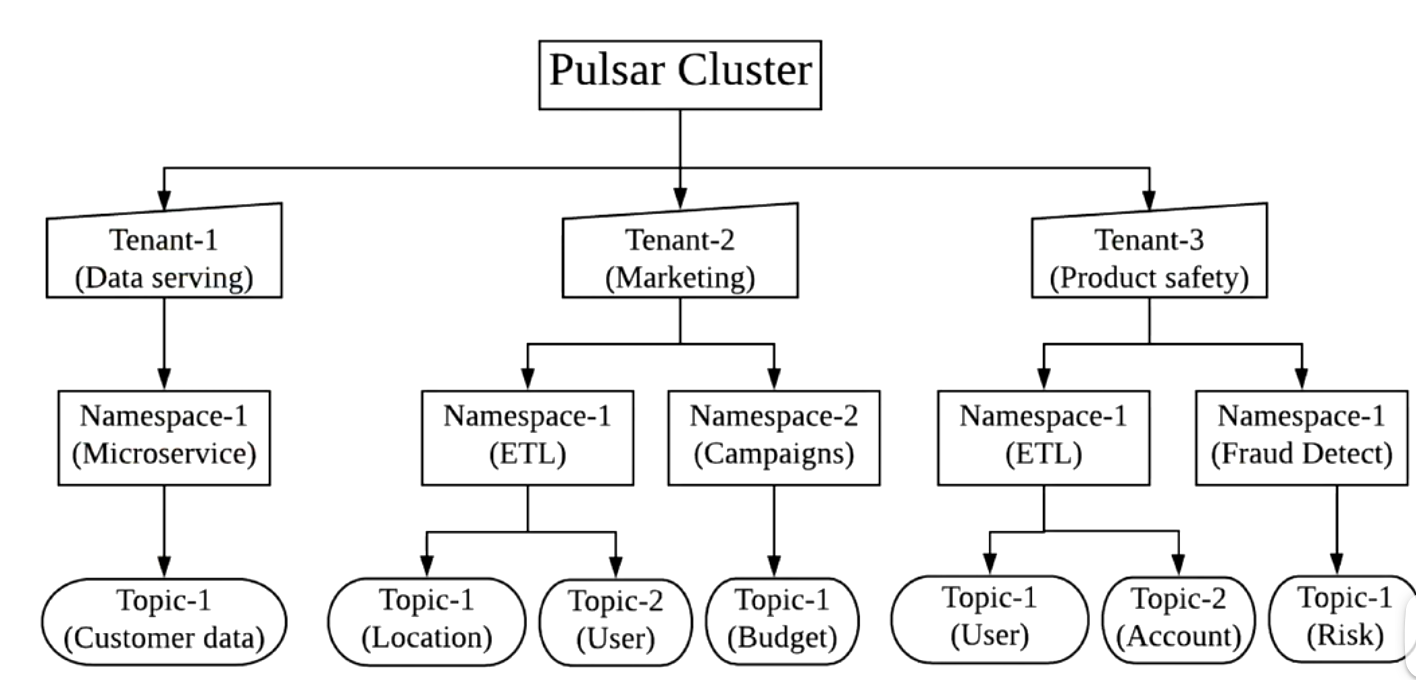
多租戶的能力,配額

原來的架構,多種消息中間件不同場景不同選型
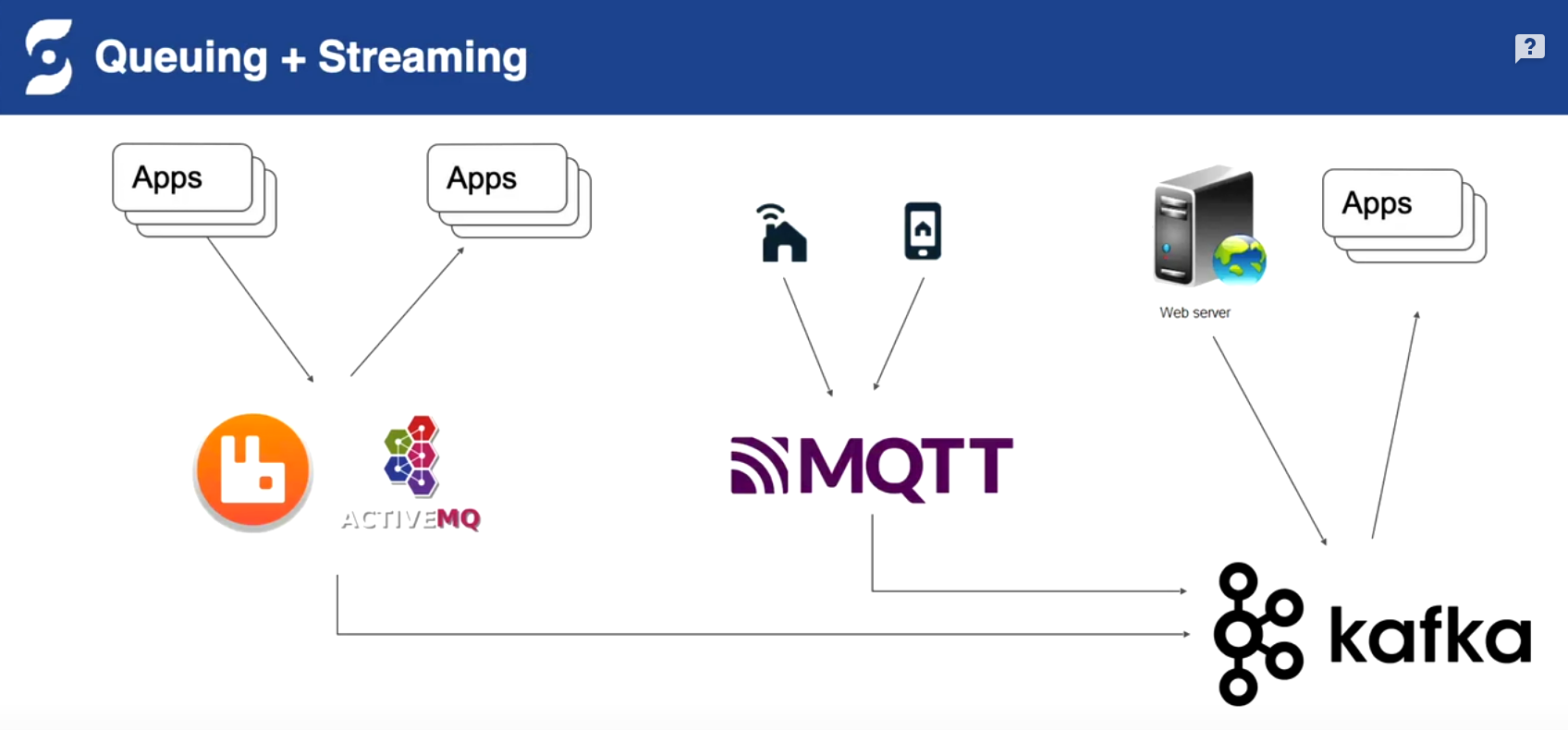
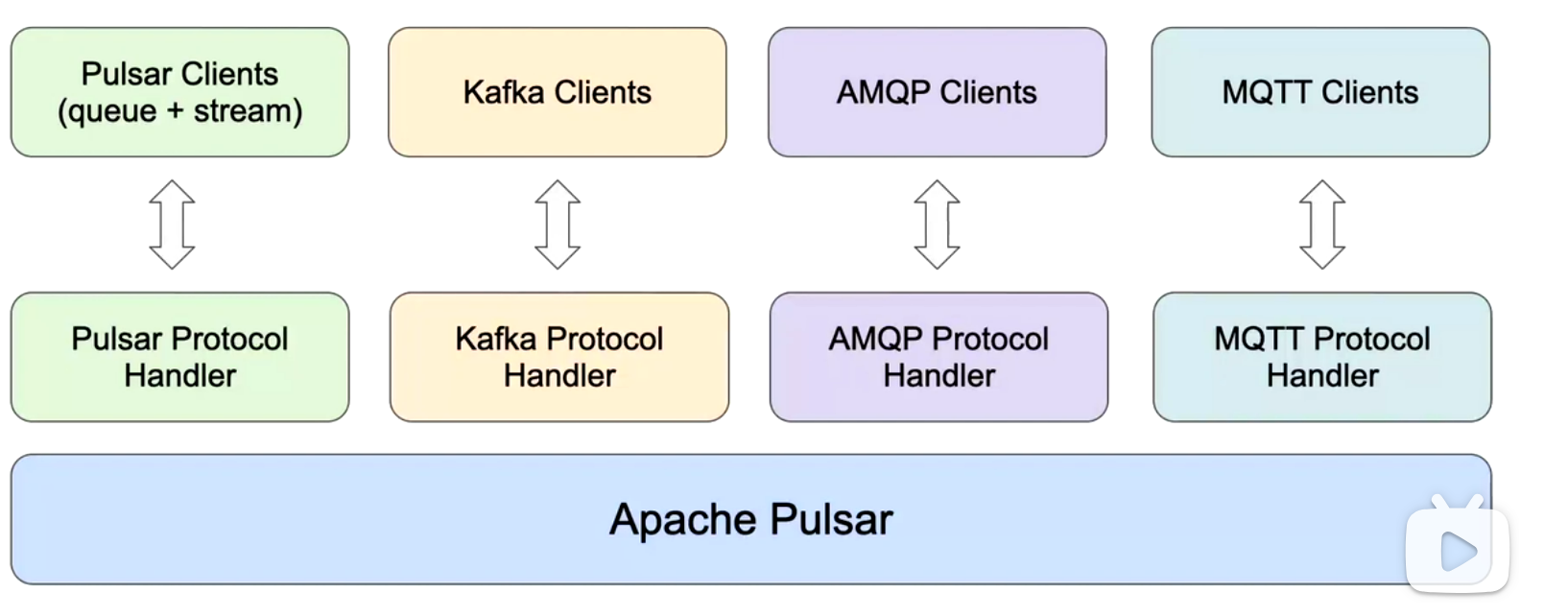
統一兼容舊系統協議,統一存儲bookkeeper
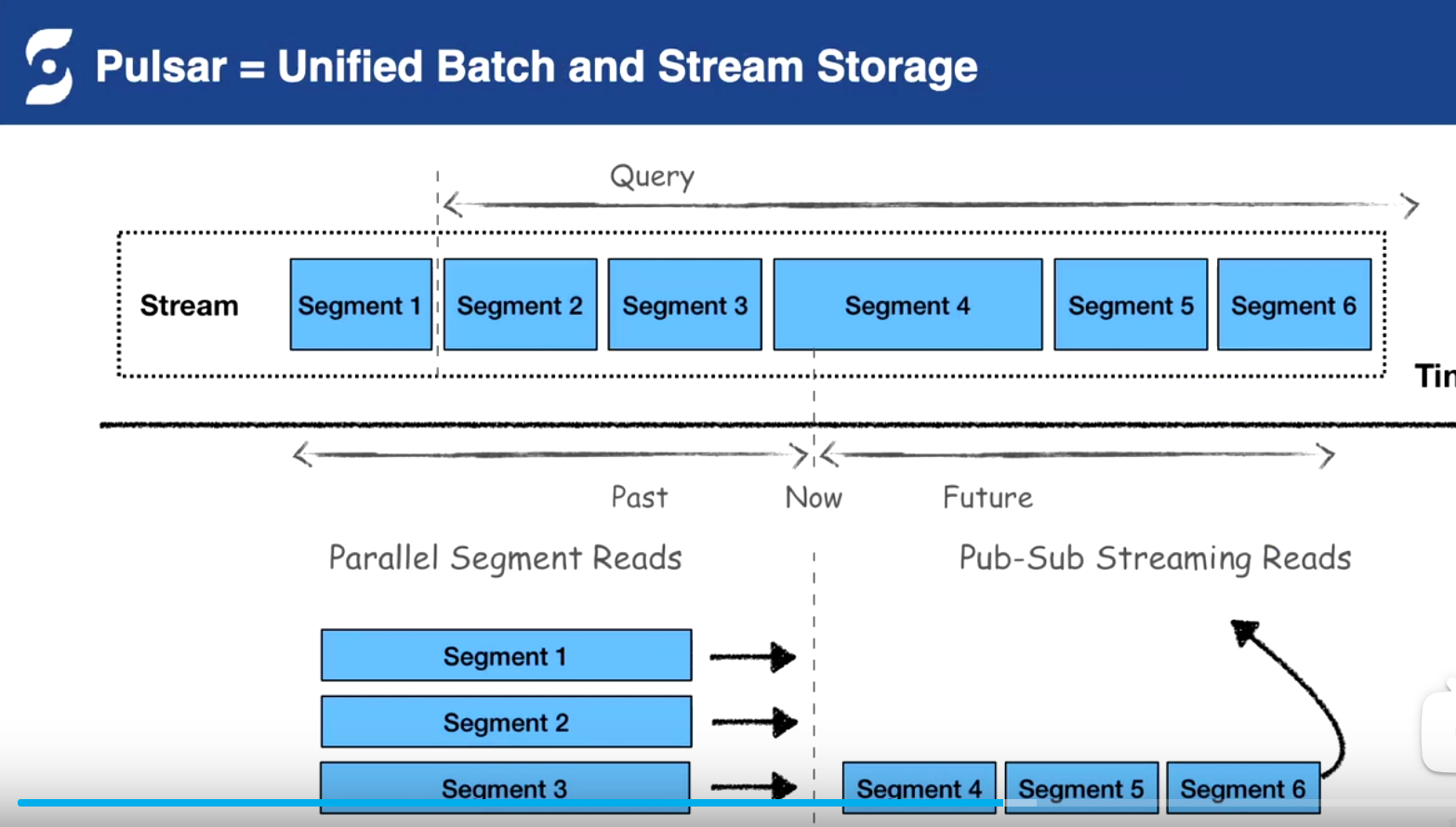
內部二級分層存儲,統一批存儲和流存儲(之前外部系統計算存儲到HDFS)
統一抽象管理,統一視圖topic抽象,但是優化存儲位置歷史數據列存等
云原生的能力
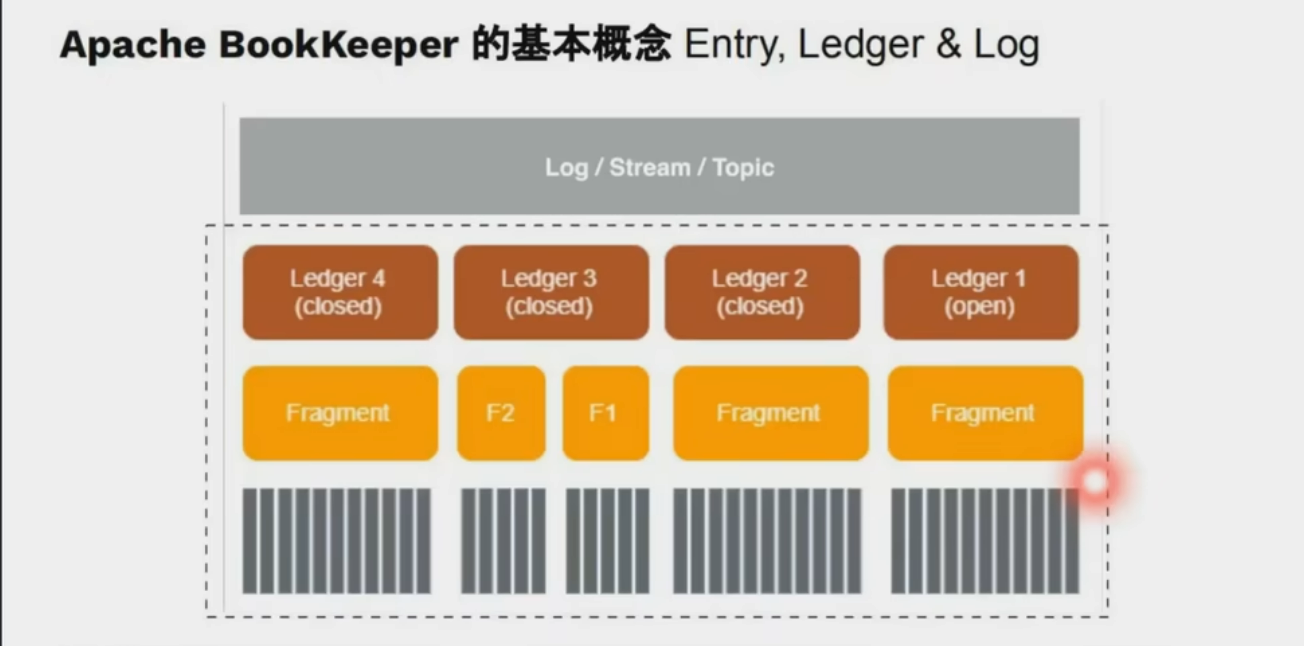
Apache BookKeeper:Apache?Pulsar的高可用強一致低延遲的存儲實現
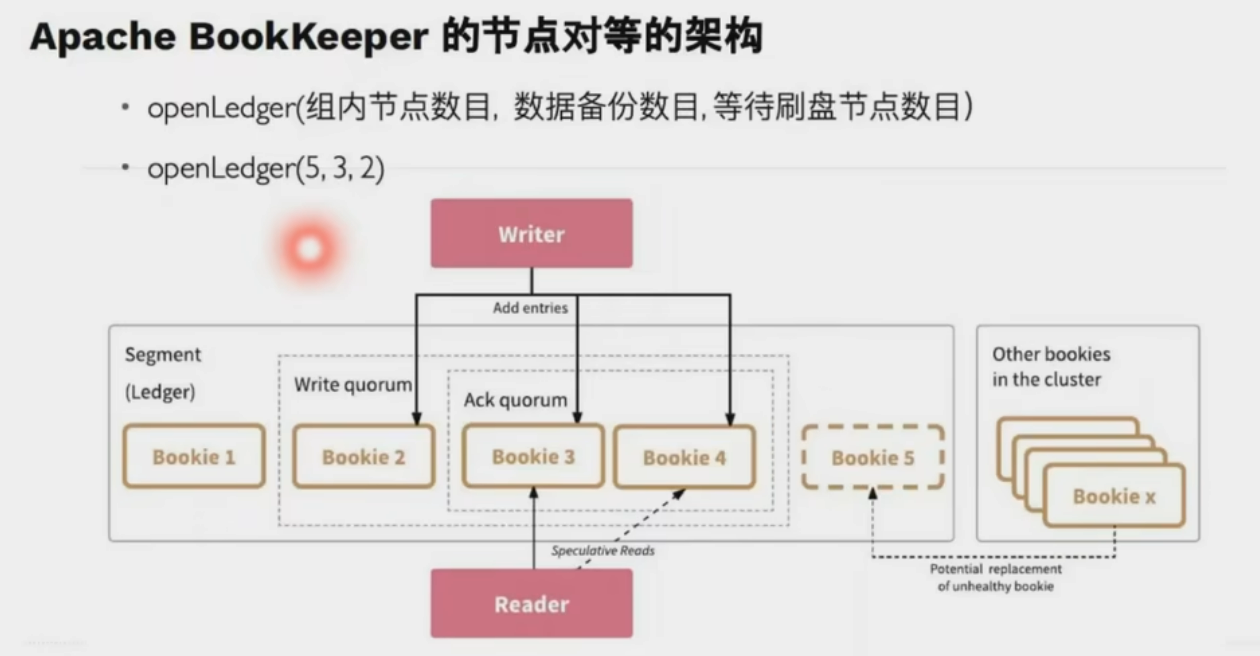
可調整(帶寬,災備等級,一致性等級)
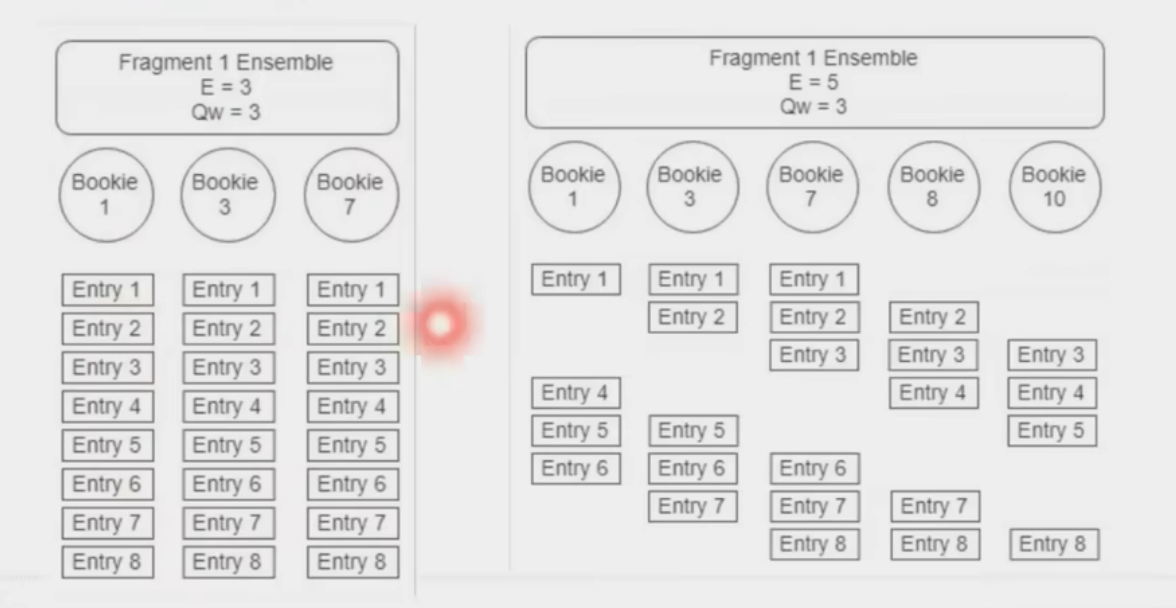

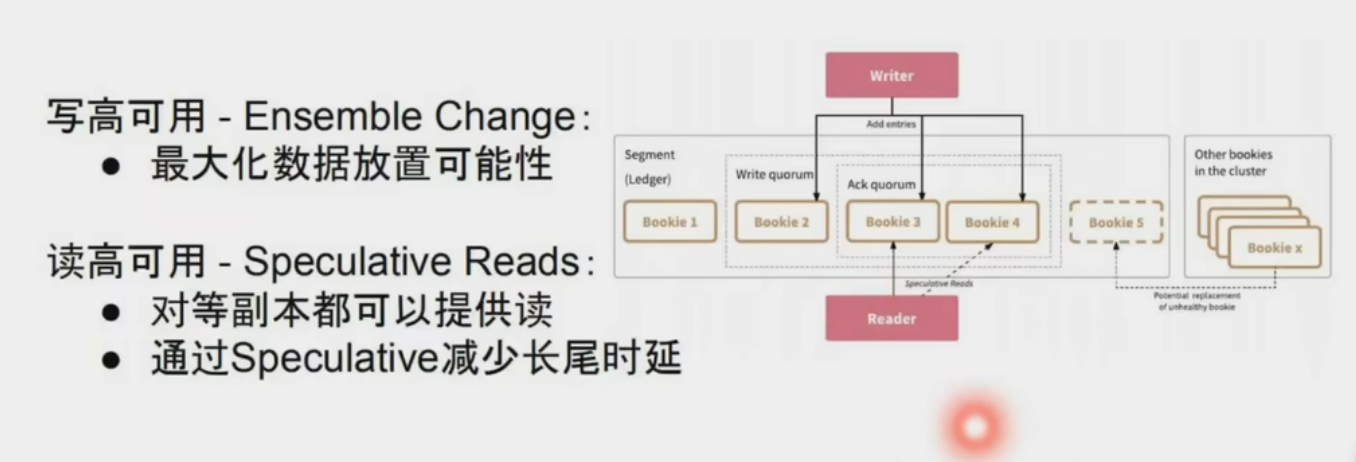
新起一份fragment承載寫
writer變成master,底層存儲是對等節點(區別raft一致性)
兩個writer有點像paxos
磁盤隔離WAL,數據盤隔離(可變換)
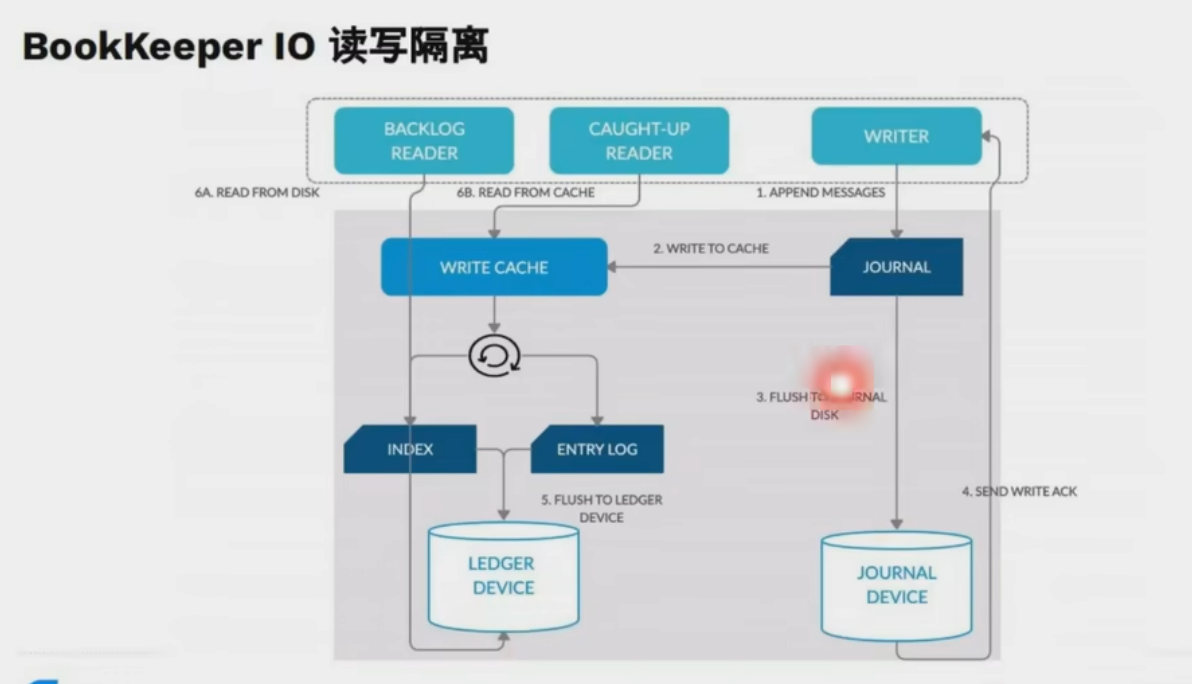
PMEM,快,容量小,壽命高,比SSD更適合做journal
Apache Pulsar 依賴的 Apache BookKeeper 作為其底層存儲引擎,其架構設計與優化機制具有鮮明的分布式系統特征。以下從架構概念、適用場景、高可用優化及一致性保障等維度進行結構化解析:
一、核心架構概念
-
?存儲單元與數據結構?
- ?Entry?:最小存儲單元,每個 Entry 包含唯一遞增的序列號,支持隨機訪問和批量讀取2。
- ?Ledger?:由多個 Entry 組成的有序日志段,具有不可變性(一旦關閉無法追加)和原子性(寫入成功或全失敗)26。
- ?Stream?:邏輯上的無限數據流,由多個 Ledger 組成;當單個 Ledger 達到空間或時間閾值時,自動創建新 Ledger2。
- ?Bookie 節點?:存儲節點,每個節點包含 Journal(預寫日志)、Entry Log(Entry 持久化文件)和 Index Files(索引文件)6。
-
?分片存儲架構?
Pulsar 將 Topic 分區的數據切分為多個 Segment(即 BookKeeper Ledger),每個 Segment 獨立存儲于不同 Bookie 節點,實現細粒度負載均衡和擴展性37。
二、適用場景
- ?消息系統?:為 Pulsar 提供持久化存儲,支持低延遲(<5ms)的流式追尾寫入25。
- ?分布式日志?:適用于需要強一致性與容錯的日志存儲(如 HDFS NameNode 的 Edit Log)6。
- ?WAL(預寫日志)?:為數據庫或分布式系統提供事務日志的高可靠存儲6。
- ?跨數據中心復制?:支持多集群間的數據同步與一致性保障2。
三、讀寫高可用優化
- ?Quorum 機制?
寫入時客戶端并行發送 Entry 至多個 Bookie 節點,需多數節點(例如 3/5)確認成功,確保數據冗余且容忍節點故障1。 - ?動態 Ensemble 調整?
根據負載動態調整寫入的 Bookie 節點組合,避免熱點問題并提升吞吐量1。 - ?并行讀取優化?
讀操作可并發從多個副本獲取數據,優先返回最快響應,降低延遲16。 - ?分片存儲負載均衡?
通過 Segment 切分策略,將數據均勻分布至集群,避免單節點瓶頸37。
四、一致性保障機制
- ?寫入一致性?
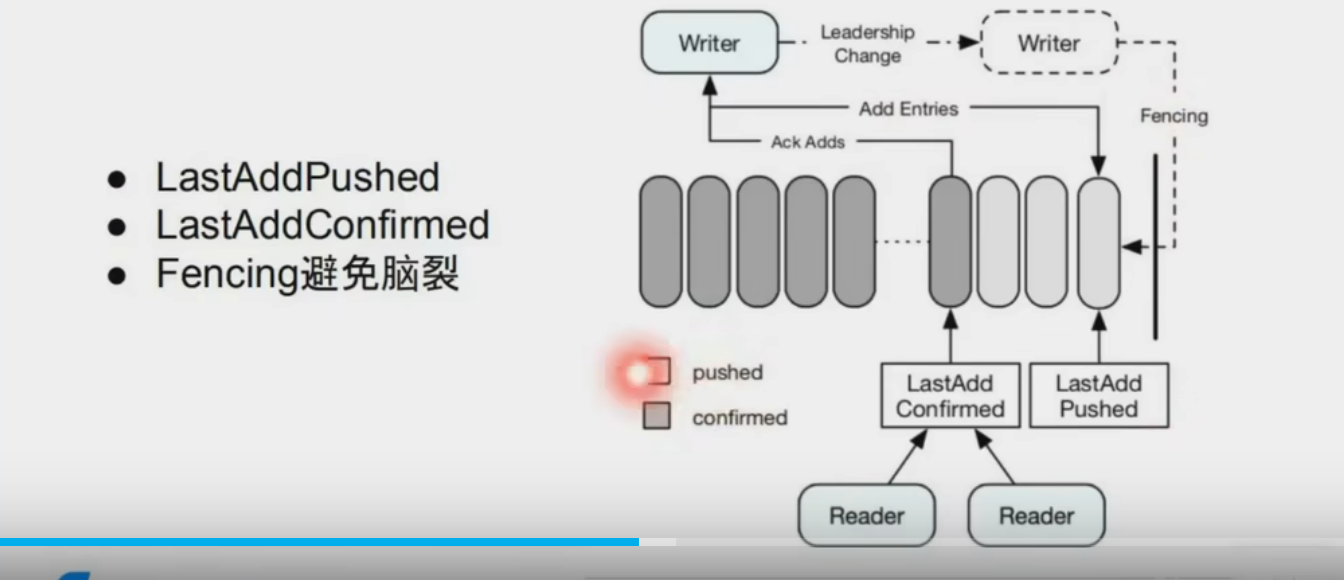
基于 Quorum 的多數確認策略,保證至少多數副本持久化成功后才返回客戶端確認16。 - ?LastAddConfirmed (LAC)?
客戶端通過 LAC 標記追蹤已持久化的最新 Entry,確保讀操作僅訪問已確認數據18。 - ?Fencing 機制?
當檢測到舊 Writer 可能異常時,新 Writer 通過 fencing 操作標記舊 Ledger 為不可寫,避免多 Writer 沖突(腦裂)18。 - ?Ledger 不可變性?
已關閉的 Ledger 不可修改,防止數據篡改并簡化一致性管理2。
五、Writer 腦裂避免
- ?Fencing 流程?:新 Writer 啟動時會對舊 Ledger 發起 fencing 請求,通過元數據服務(如 ZooKeeper)驗證所有權,確保同一時刻僅一個有效 Writer18。(實際上也就是用外部選主,簡化存儲層設計,達到對等節點)
- ?原子性元數據更新?:Ledger 元數據(如狀態、Owner)需通過原子操作更新,避免并發沖突6。
六、其他重要概念
- ?跨機房復制?:通過異步復制機制實現多集群間數據同步,支持地理容災2。
- ?分層存儲?:支持將冷數據遷移至廉價存儲(如 HDFS),降低存儲成本6。
- ?計算存儲分離?:Pulsar Broker 處理計算邏輯,BookKeeper 專注存儲,提升系統彈性與擴展性37。
通過上述設計,BookKeeper 在高吞吐、低延遲與強一致性之間取得平衡,成為云原生場景下可靠的分布式存儲基石。
深入對比 Apache Pulsar 與 Kafka

kafka橫向擴展困難,以及kafka的彈性伸縮困難


以下從追尾讀、切Segment、容錯恢復遷移速度、存算分離等角度對Kafka與Pulsar進行深度對比分析:
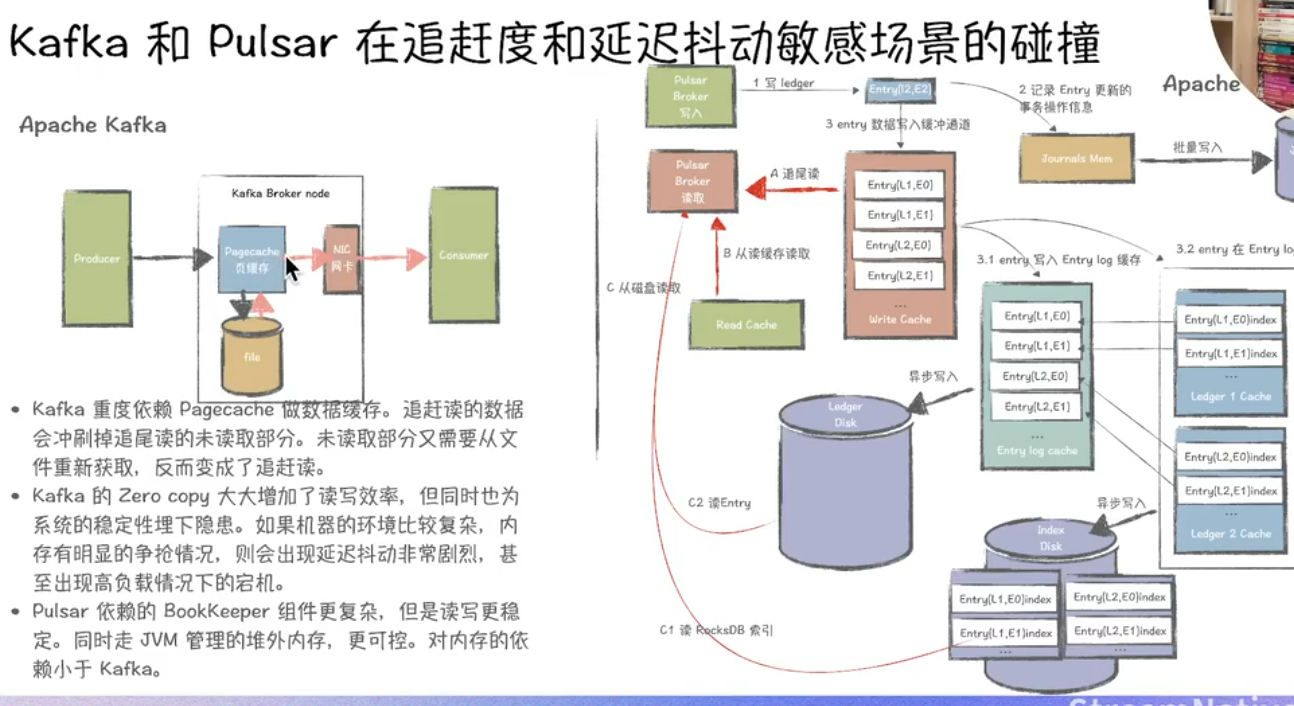
一、追尾讀(Tailing Reads)
-
?Kafka?
- 采用消費者主動拉取機制,尾部讀取延遲受消費者輪詢頻率影響。在高吞吐場景下,若Topic分區數過多或消費者組協調復雜,可能出現尾部延遲波動現象25。
- Broker同時承擔計算與存儲職責,尾部讀取可能因磁盤IO壓力導致性能下降8。
- 從kafka的架構設計上來看,為了支持高性能讀寫,數據生產與消費都是走pagecache,當讀寫消費速率相差不大時,無需經過磁盤。但當延遲消費N設置得比較大的時候,page cache 數據不存在舊數據,只能從磁盤中加載,從而降低吞吐。Kafka積壓問題
-
?Pulsar?
- 通過無狀態Broker和預讀緩存機制優化尾部讀取性能,在同等負載下延遲可穩定低于5ms5。
- 存儲與計算分離架構減少了Broker的磁盤IO競爭,結合BookKeeper的條帶化寫入策略,尾部讀取吞吐量更高38。
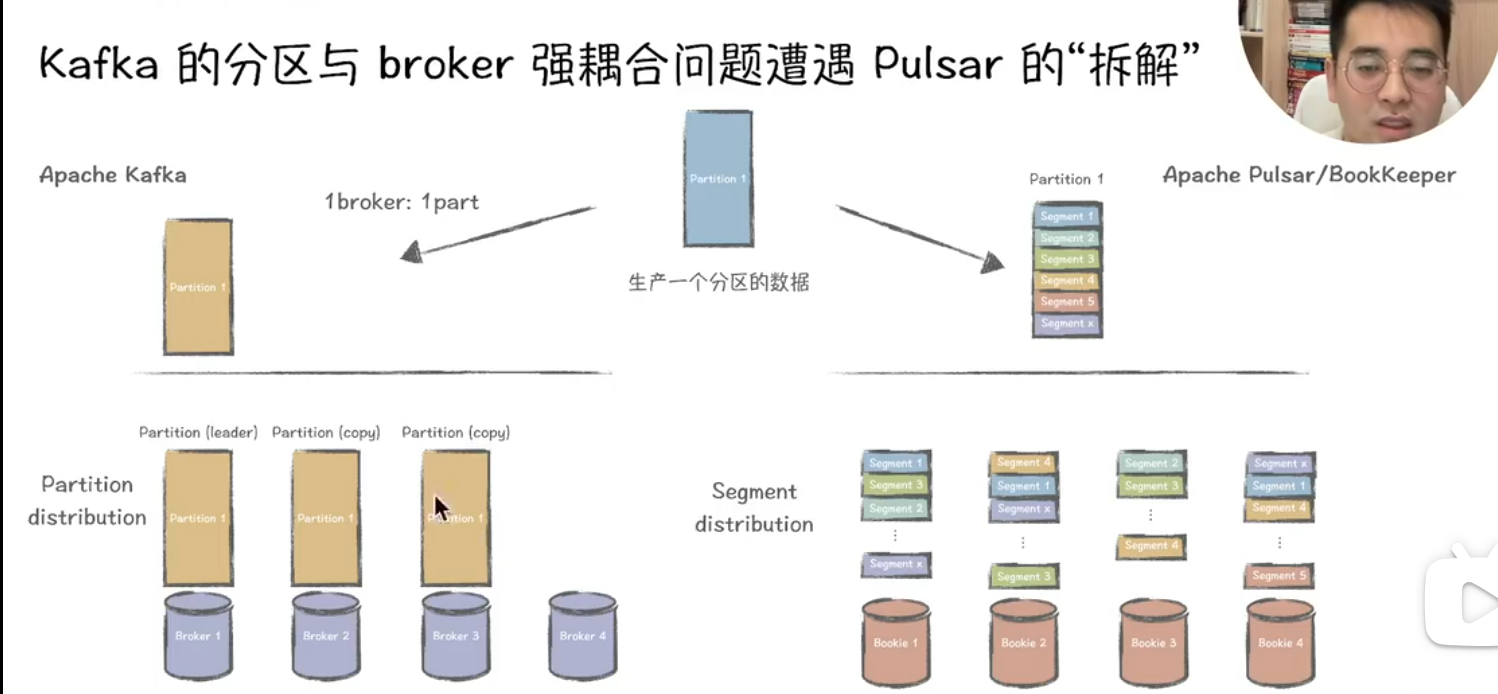
二、切Segment機制
-
?Kafka?
- 每個分區由多個Segment文件組成,按時間或大小拆分。切Segment時需同步更新索引文件,若寫入速率極高可能導致短暫寫入阻塞3。
- Segment文件本地存儲,擴容時需跨節點遷移數據,影響集群整體性能6。
-
?Pulsar?
- 基于BookKeeper存儲層,Segment(Ledger)以分布式副本形式存儲在多個Bookie節點上,切Segment僅需關閉當前Ledger并創建新Ledger,過程無阻塞38。
- 新Segment寫入直接分配到可用Bookie節點,天然支持水平擴展,無需數據遷移3。
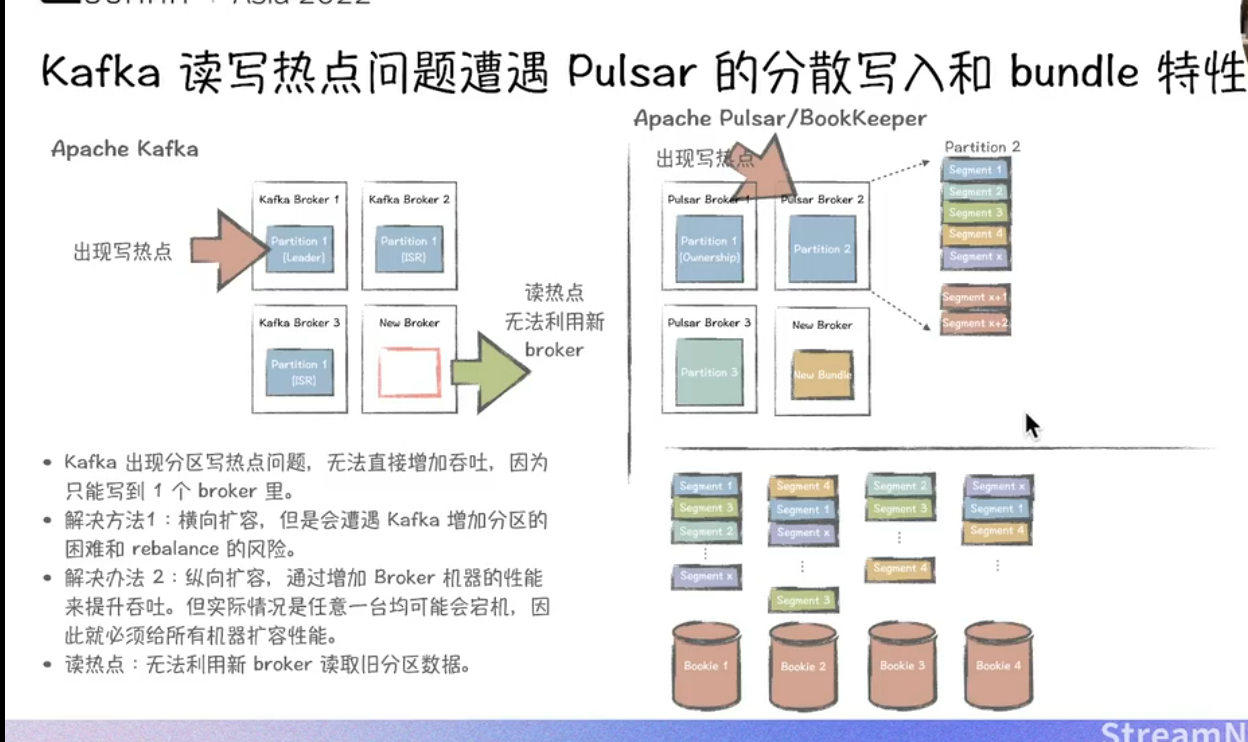
三、容錯恢復與遷移速度
-
?Kafka?
- 副本恢復依賴ISR(In-Sync Replicas)機制,副本同步過程需全量復制數據,遷移速度受網絡帶寬和磁盤I/O限制6。
- 分區再平衡時需重新選舉Leader并同步數據,大規模集群下耗時顯著增長3。
-
?Pulsar?
- 存儲層BookKeeper采用多副本Quorum寫入(Write Quorum + Ack Quorum),單Bookie故障時自動切換至健康節點,恢復無需數據拷貝,僅需重放未確認的Entry8。
- Broker無狀態設計,故障節點可快速替換,Topic分區自動遷移至新Broker,延遲僅取決于ZooKeeper元數據同步時間36。
四、存算分離架構
-
?Kafka?
- 存算一體架構,Broker同時負責消息處理和存儲,擴容需同時調整計算與存儲資源,難以獨立擴展6。
- 云原生適配性較弱,需依賴外部工具(如Kubernetes StatefulSets)實現動態擴縮容3。
-
?Pulsar?
- ?計算層(Broker)與存儲層(Bookie)完全解耦?,支持獨立擴縮容。Broker無狀態,可快速水平擴展;Bookie節點動態增減不影響數據一致性38。
- 原生適配云原生環境,結合Kubernetes可實現秒級彈性伸縮,資源利用率提升30%以上36。
- 數據存儲采用分層設計,冷熱數據可分離至不同存儲介質(如SSD/HDD),進一步降低成本8。
五、其他關鍵差異
| 維度 | Kafka | Pulsar |
|---|---|---|
| ?多租戶支持? | 需手動隔離,依賴外部管控工具7 | 原生支持租戶級資源配額及Namespace隔離3 |
| ?Topic擴展性? | 單集群支持約數萬Topic6 | 單集群支持超50萬Topic且性能穩定3 |
| ?數據一致性? | 依賴ISR機制,極端場景可能丟數8 | Quorum寫入+強一致性模型,金融級可靠性8 |
總結
- ?Kafka?更適合對吞吐量要求極高且集群規模相對固定的場景,但運維復雜度較高。
- ?Pulsar?在動態擴縮容、低延遲追尾讀、快速容錯恢復等方面優勢顯著,尤其適合云原生環境及需要強一致性的金融級應用35。
:終極對比指南)






》閱讀筆記:p82-p82)
)
)


LLM數據基礎-分詞算法(2))


Python爬蟲高階:動態頁面處理與云原生部署全鏈路實踐(Selenium、Scrapy、K8s))
——排序)


