大語言模型與RAG的應用越來越廣泛,但在處理長文檔時仍面臨不少挑戰。今天我們來聊聊一個解決這類問題的新方法——LongRefiner。
背景問題:長文檔處理的兩大難題
使用檢索增強型生成(RAG)系統處理長文檔時,主要有兩個痛點:
- 信息雜亂:長文檔中往往包含大量與用戶問題無關的內容,就像大海撈針,模型很難準確找到真正有用的信息。
- 計算成本高:處理完整長文檔會大大增加輸入長度,導致計算資源消耗增加,系統響應變慢,尤其在實際應用中更為明顯。
LongRefiner:三步走策略
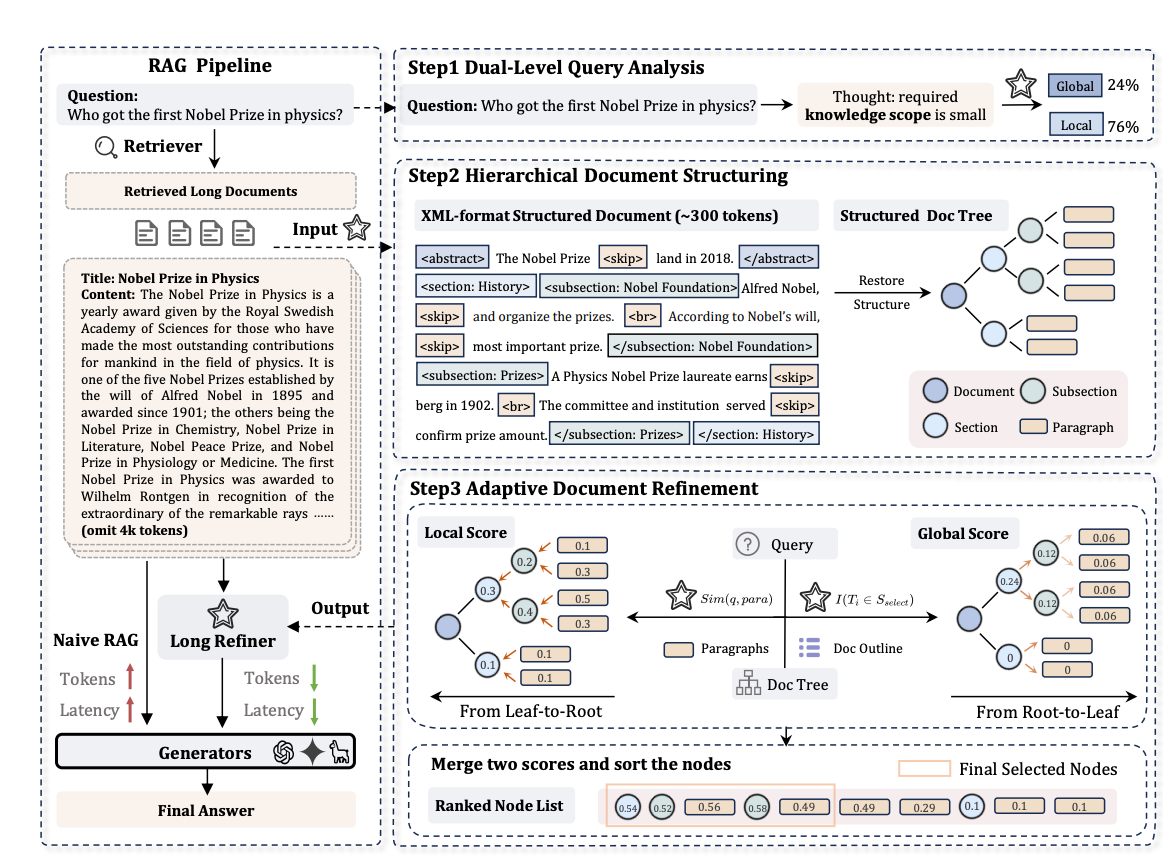
如圖所示,針對這些問題,研究者提出了LongRefiner,一個即插即用的文檔精煉系統。它通過三個關鍵步驟來提高長文檔處理效率:
1. 雙層查詢分析
不同的問題需要不同深度的信息,LongRefiner把查詢分為兩種類型:
- 局部查詢:只需要文檔中某個部分或片段的信息就能回答
- 全局查詢:需要對整個文檔進行全面理解才能回答
系統會先判斷用戶的問題屬于哪種類型,然后再決定需要提取多少信息。
2. 文檔結構化處理
把雜亂無章的長文檔變成有條理的結構化文檔,主要包括:
- 設計基于XML的文檔結構表示方式,用特殊標簽(如
<section>、<subsection>)標記出文檔的層次結構 - 利用維基百科網頁數據建立文檔結構樹,方便后續處理
3. 自適應文檔精煉
根據不同問題類型,系統會從兩個角度評估文檔各部分的重要性:
- 局部視角:從文檔的最小單元(如段落)開始,計算與查詢的相關性
- 全局視角:從文檔的整體結構出發,確保能夠全面理解文檔
最后,系統會結合這兩種視角的評分,篩選出最相關的內容來回答問題。
實驗成果:事實勝于雄辯
研究者在多種問答數據集上進行了測試,結果相當出色:
- 在保持低延遲的情況下,LongRefiner在所有測試數據集上都取得了最佳性能
- 與現有方法相比,性能提升了9%以上
- 與直接使用完整文檔的方法相比,LongRefiner將標記使用量減少了10倍,延遲降低了4倍,同時在多數數據集上性能反而更好
關鍵發現
實驗分析還揭示了幾個有意思的發現:
- 系統中的三個組件(雙層查詢分析、文檔結構化、自適應精煉)缺一不可,移除任何一個都會導致性能明顯下降
- 隨著模型參數的增加,性能提升會逐漸變小
- LongRefiner在處理較長文檔時表現尤為出色
- 該方法在不同的基礎生成器上都能表現穩定
總結
LongRefiner為長文檔的RAG系統提供了一種高效的解決方案。通過理解查詢類型、結構化文檔以及自適應精煉機制,它成功地在保持高性能的同時大幅降低了計算成本。這一研究為未來大語言模型處理長文檔問題提供了新的思路。
對于需要處理大量長文檔的應用場景,如智能客服、文檔檢索系統、知識庫問答等,LongRefiner無疑是一個值得關注的技術。

)




)












