1.上傳spark安裝包到某一臺機器(自己在finaShell上的機器)。
2.解壓。 把第一步上傳的安裝包解壓到/opt/module下(也可以自己決定解壓到哪里)。對應的命令是:tar -zxvf 安裝包 -C /opt/module
3.重命名。進入/opt/module/目錄下把解壓的內容重命名一下。命令是:mv spark-3.1.1-bin-hadoop3.2/ spark-standalone
4.配置環境變量,更新spark路徑。命令為:/etc/profile.d/my_env.sh
5.同步環境變量,并使用source命令讓它生效。
6.修改workers.template文件。這個文件在spark的安裝目錄下的conf目錄下,先把名字改為workers,然后把內容設置為三臺機器的主機名,具體如下。
自己三臺機器名字:
hadoop100
hadoop101
hadoop102
7.修改spark-env.sh.template文件。先把名字改成spark-env.sh,然后修改內容,添加JAVA_HOME環境變量和集群對應的master節點以及通信端口,具體如下。
SPARK_MASTER_HOST=hadoop100(自己所配置下的機器名字)
SPARK_MASTER_PORT=7077
8.同步設置完畢的Spark目錄到其他節點。使用我們之前分發的命令:
xsync /opt/module/spark-standalone/
9.啟動SPARK集群。進入到hadoop100(自己所配置下的機器名字)機器,切換目錄到/opt/module/spark-standalone/sbin下,運行命令 ./start-all.sh。
注意,這里不要省略./,它表示的是當前目錄下的start-all命令,如果省略了./,它就會先去環境變量PATH中指定的目錄來找這個命令。
10.驗收效果。通過jps命令去每臺機器上查看運行的進程。請觀察是否在hadoop100上看到了master,worker在hadoop101,hadoop102上看到了worker。
11.查看啟動效果。打開瀏覽器,輸入hadoop100:8080。看到效果如:
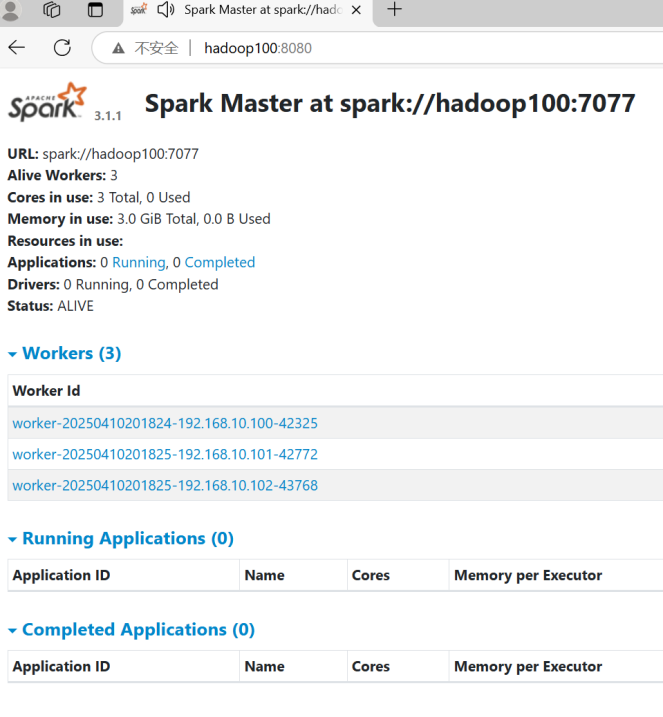






)


)









