1. 安裝
pip install edge-tts
2. 命令行使用
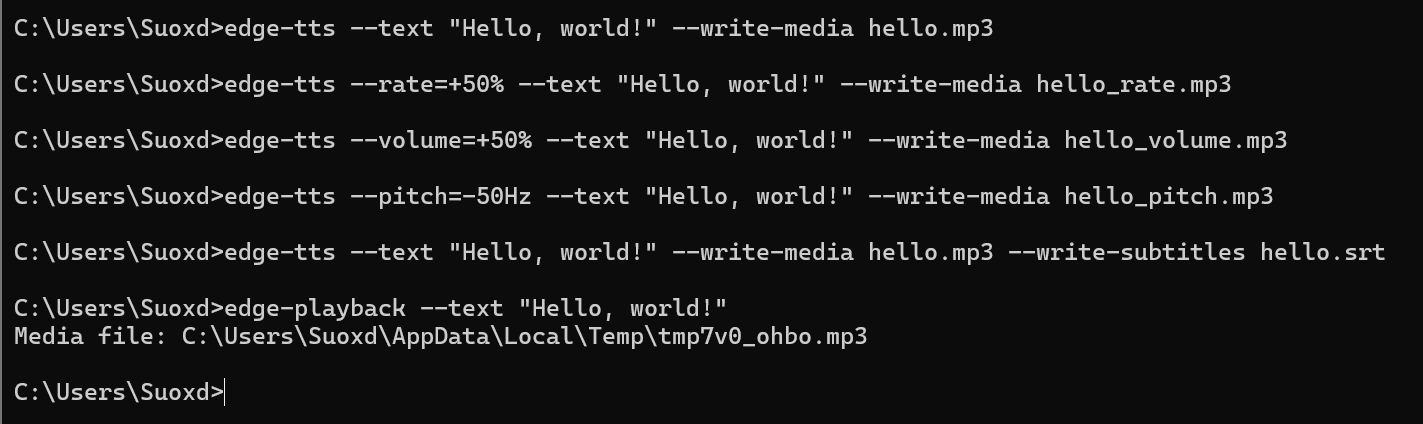
# 生成語音文件
# -f:要轉換語音的文本文件,例如一個txt文件
# --text:指明要保存的mp3的文本
# --write-media:指明保存的mp3文件路徑
# --write-subtitles:指定輸出字幕/歌詞路徑
# --rate:調整語速,+50%加快了50%
# --volume:調整音量 +50%音量提高了50%
# --pitch:調整頻率 -50Hz頻率降低了50Hz
# --voice:指明了使用哪種語音和風格的發音人
edge-tts --text "Hello, world!" --write-media hello.mp3
# 修改語音速度、音量、頻率的效果(使用+-表示默認基礎上增減)
edge-tts --rate=+50% --text "Hello, world!" --write-media hello_rate.mp3
edge-tts --volume=+50% --text "Hello, world!" --write-media hello_volume.mp3
edge-tts --pitch=-50Hz --text "Hello, world!" --write-media hello_pitch.mp3
# 直接播放(相當于文件生成到臨時目錄)
edge-playback --text "Hello, world!"
3. 編碼使用
import asyncio
import edge_ttsTEXT = "Hello World!"
VOICE = "en-GB-SoniaNeural"
OUTPUT_FILE = "test.mp3"async def amain() -> None:"""Main function"""communicate = edge_tts.Communicate(TEXT, VOICE)submaker = edge_tts.SubMaker()with open(OUTPUT_FILE, "wb") as file:async for chunk in communicate.stream():if chunk["type"] == "audio":file.write(chunk["data"])
4. 修改語音模型
有300多種模型可以選擇,(edge-tts --list-voices)相關配置如下:
| 模型名稱 | 性別 | 風格 | 聲音特點 |
|---|---|---|---|
| af-ZA-AdriNeural | 女 | 普通 | 友好、積極 |
| af-ZA-WillemNeural | 男 | 普通 | 友好、積極 |
| am-ET-AmehaNeural | 男 | 普通 | 友好、積極 |
| am-ET-MekdesNeural | 女 | 普通 | 友好、積極 |
| ar-AE-FatimaNeural | 女 | 普通 | 友好、積極 |
| ar-AE-HamdanNeural | 男 | 普通 | 友好、積極 |
| ar-BH-AliNeural | 男 | 普通 | 友好、積極 |
| ar-BH-LailaNeural | 女 | 普通 | 友好、積極 |
| ar-DZ-AminaNeural | 女 | 普通 | 友好、積極 |
| ar-DZ-IsmaelNeural | 男 | 普通 | 友好、積極 |
| ar-EG-SalmaNeural | 女 | 普通 | 友好、積極 |
| ar-EG-ShakirNeural | 男 | 普通 | 友好、積極 |














)


)

