5月16日復盤
一、圖像處理之目標檢測
1. 目標檢測認知
? Object Detection,是指在給定的圖像或視頻中檢測出目標物體在圖像中的位置和大小,并進行分類或識別等相關任務。
? 目標檢測將目標的分割和識別合二為一。
? What、Where
2. 使用場景
目標檢測用于以下場景:
- 圖像處理;
- 自動駕駛:檢測周圍的車輛、行人、交通燈、道路標志等;
- 安防監控:監控公共場,發現異常行為,保障公共安全;
- 人臉檢測;
- 醫學影像分析:在醫學影像方面可以識別腫瘤、組織變異等,用于醫療輔助;
- 無人機應用:識別特定目標,引導無人機飛行,比如監測天氣、線路檢測、搜尋救援、軍事等;
- 缺陷檢測:工業;
更多場景:140個場景
【https://blog.csdn.net/wcl291121957/article/details/138313404】
【https://blog.csdn.net/wcl291121957/article/details/138318995】
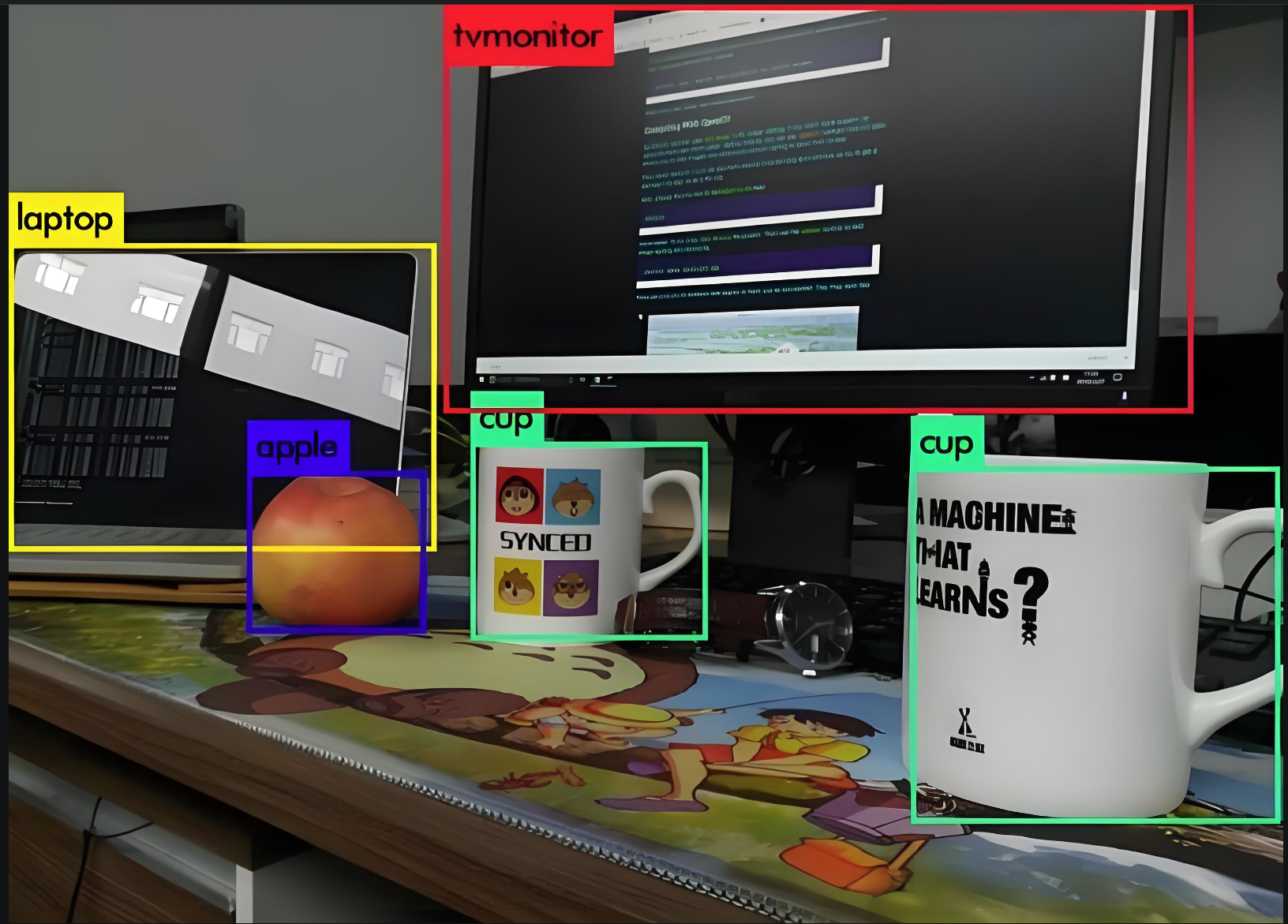
3. 目標識別與標注
目標識別包含了分類 + 坐標位置(x, y, w, h)
What、where
二、目標檢測網絡基礎
1. 目標檢測方法
Detection主要分為以下三個支系:
| one-stage系 | two-stage系 | ||
|---|---|---|---|
| 主要算法 | YOLO系列、SSD、RetinaNet | Fast R-CNN、Faster R-CNN | R-CNN、SPPNet |
| 檢測精度 | 較低(隨著網絡的改進,精度也不低) | 較高 | 極高 |
| 檢測速度 | 較快(達到實時視頻流級別) | 較慢,5 fps | 極慢 |
| 鼻祖 | YOLOv1 | Fast R-CNN | R-CNN |
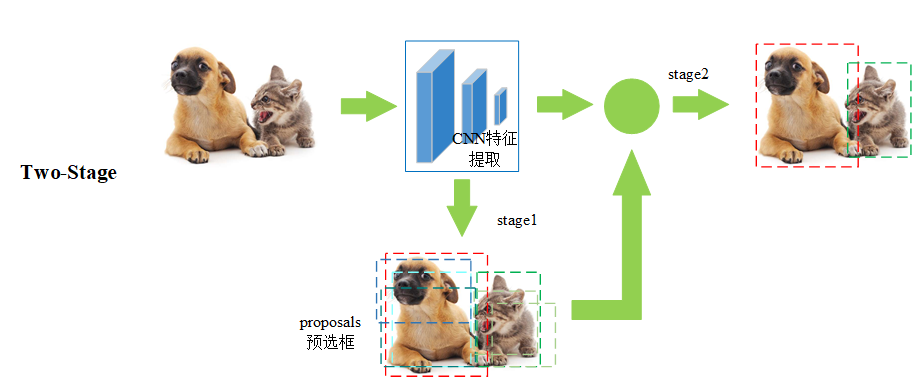
1.1 two-stage
雙階段,兩部到位,特點如下:
- 候選區域生成:第一階段生成候選區域(Region Proposals);
- 區域分類和回歸:第二階段對候選區域進行分類和回歸,即對每個候選區域進行目標分類和位置精修。
- 代表算法:R-CNN(Region-CNN)系列,包括Fast R-CNN、Faster R-CNN、Mask R-CNN等。
基本流程:

比如貓狗混合圖:
1.2 one-stage
單階段,一步到位,特點如下:
- 端到端訓練:直接從圖像中提取特征并進行分類和回歸,即同時進行目標分類和位置回歸。
- 實時性高:由于僅有一個階段,計算速度快,適合實時應用。
- 代表算法:YOLO(You Only Look Once)系列、SSD等。
基本流程:
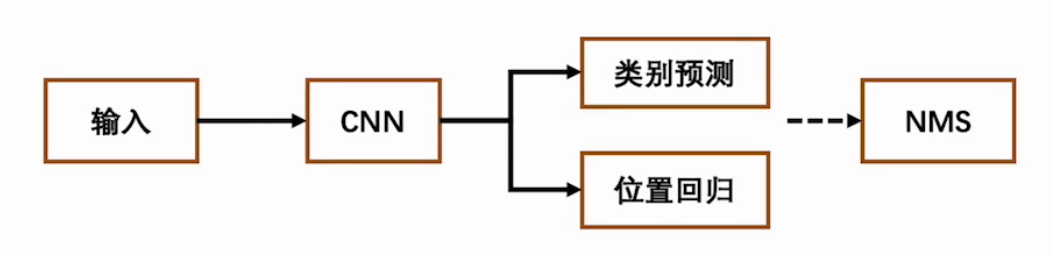
比如貓狗混合圖:

2. 目標檢測指標
2.1 目標框指標
在目標檢測中,每個檢測出的目標物體通常都會標注一個框(Bounding Box),用于表示目標的位置和大小,這個框叫目標框。
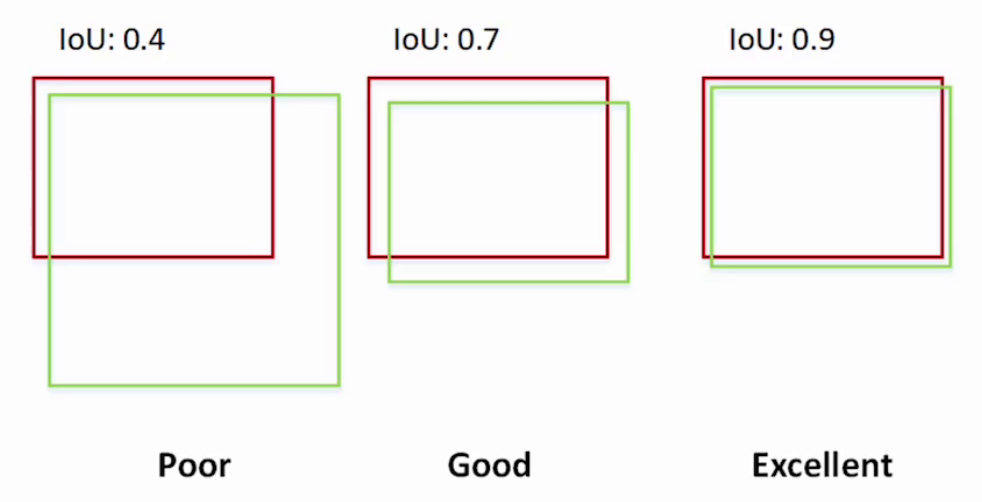
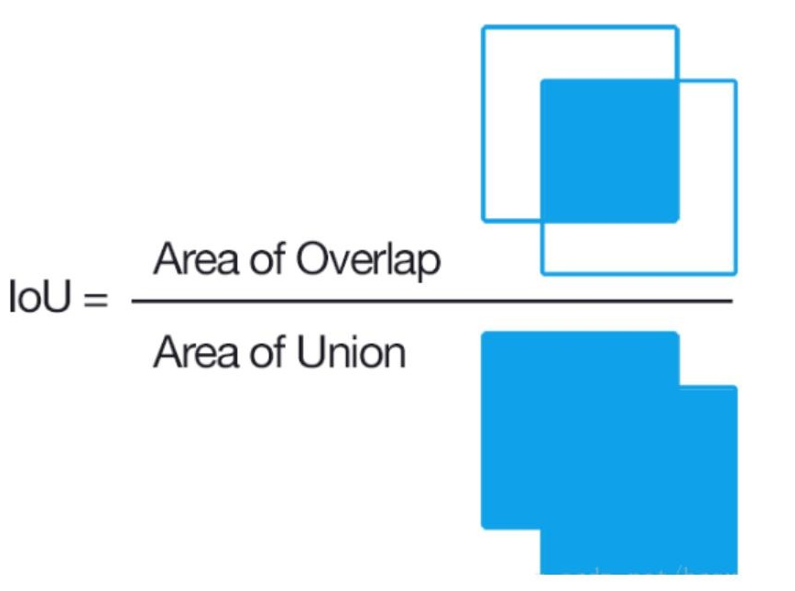
2.1.1 IoU
基礎英文單詞:【交集】Intersection 【并集】Union
loU(Intersection over Union),預選框正確性的度量指標。
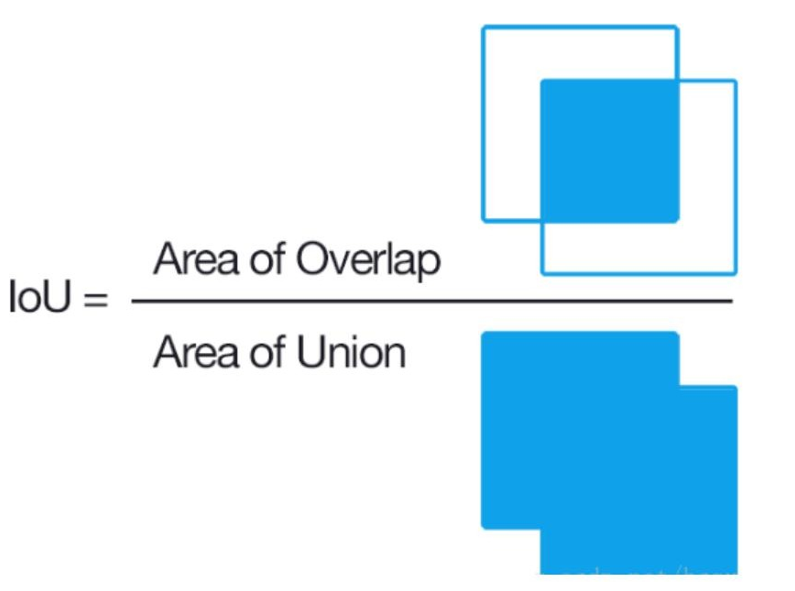
前景目標交并比:
I o U = A ∩ B A ∪ B IoU=\frac{\mathrm{A\cap B}}{\mathrm{A\cup B}} IoU=A∪BA∩B?
**比如:**紅框是真實位置及大小,綠色框是預選框
2.1.2 Confidence

- 假設現在你是唐伯虎,你需要在一群人中找到秋香(檢測人臉)。你們應該都已經找到了,并且很自信地肯定,綠色框內的人臉就是秋香。但是計算機沒有這么自信呀,它只能夠生成一系列預測框(紅色框),每個框有一個值,稱之為置信度,置信度可以暫時理解為自信程度,類比到你自己,你們是不是很自信地認為綠色框框就是秋香的臉,如果你百分百肯定這個框就是秋香,那好,這個框框的置信度就為 1,只是聽大家說秋香長得很漂亮,這時候有些人會覺得黃色框框里的人長得也挺漂亮,我覺得黃色框框內的人是秋香,但是又看看綠色框框,好像這個才是秋香,糾結來糾結去,一下子拿不定主意,所以現在的他顯得有點不夠自信了,不過他最終還是做出了如下判斷

- 目標檢測過程中,往往最后會生成很多的預測框,每個預測框自身都會帶一個置信度,用來衡量預測框內為目標(秋香)的自信程度,自信程度越高,說明當前訓練的模型對于這個框的結果越認可。這個認可的自信程度就被稱為置信度。
在目標檢測中,目標框會標注一個置信度(Confidence Score),通常指的是模型對于預測結果的置信程度。
置信度通常是一個0到1之間的實數,是由神經網絡模型預測出來的,代表著模型對該預選框的信心。
置信度一般分為兩部分:
- 目標存在置信度(Objectness score):一個標量,表示預選框中存在(任何)目標的概率。
- 類別置信度(Class confidence):多個標量(每個類別一個),預選框中目標屬于每一個類別的概率。
置信度是通過神經網絡模型在訓練過中學習得到的:
- 分類損失(Classification loss):用于計算類別置信度的誤差。
- 定位損失(Localization loss):用于計算預選框與實際標注框之間的位置誤差。
- 目標存在的損失(Objectness loss):用于計算目標存在置信度的誤差。
綜合置信度:
在某些目標檢測算法(如YOLO)中,綜合置信度通常表示為:
綜合置信度 = 目標存在的置信度 × 類別置信度 綜合置信度=目標存在的置信度×類別置信度 綜合置信度=目標存在的置信度×類別置信度
置信度的預測機制使得目標檢測算法能夠在復雜的圖像中準確地定位和識別目標物體。
2.2 精度和召回率
精度和召回率的計算是基于置信度閾值來計算的,即IOU的最小值;
2.2.1 混淆矩陣
? 混淆矩陣是一種特定的表格布局,用于可視化監督學習算法的性能,特別是分類算法。在這個矩陣中,每一行代表實際類別,每一列代表預測類別。矩陣的每個單元格則包含了在該實際類別和預測類別下的樣本數量。通過混淆矩陣,我們不僅可以計算出諸如準確度、精確度和召回率等評估指標,還可以更全面地了解模型在不同類別上的性能。
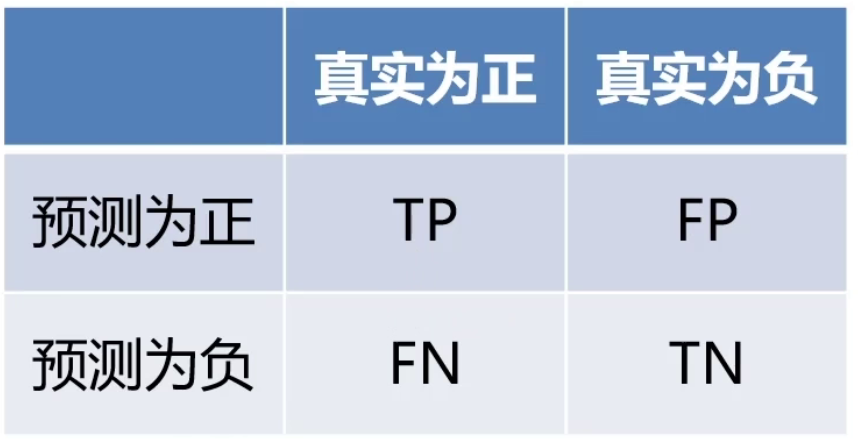
混淆矩陣的四個基本組成部分是:
- True Positives(TP):當模型預測為正類,并且該預測是正確的,我們稱之為真正(True Positive);
- True Negatives(TN):當模型預測為負類,并且該預測是正確的,我們稱之為真負(True Negative);
- False Positives(FP):當模型預測為正類,但該預測是錯誤的,我們稱之為假正(False Positive);
- False Negatives(FN):當模型預測為負類,但該預測是錯誤的,我們稱之為假負(False Negative)
2.2.2 Precision和Recall
參考下圖

2.2.4 小案例
以下是一個關于精度(Precision)和召回率(Recall)的小測試題,用于理解精度和召回率。
假設在一個二分類任務中,我們有以下的混淆矩陣(Confusion Matrix):
| 預測為正類(Positive) | 預測為負類(Negative) | |
|---|---|---|
| 實際為正類(True Positive) | 50 (TP) | 10(FN) |
| 實際為負類(True Negative) | 5(FP) | 35 (TN) |
請計算以下指標:
- 精度(Precision): (50)/50 + 5 = 10 / 11
- 召回率(Recall): (50) / (50 + 10) = 5 / 6
2.3 mAP的計算
- 平均平均精確度(mean Average Precision,mAP) 是在不同置信度閾值下計算的平均精確度(Average Precision, AP)的平均值
- AP 是在不同召回率水平下的精確度平均值,而 mAP 則是多個類別上的 AP 的平均值
- mAP 衡量的是模型在所有類別上的好壞
- mAP 計算步驟
- 計算每個類別的 AP:對于數據集中包含的每個類別,分別計算 AP
- 計算 mAP:將所有類別的 AP 取平均值,得到 mAP
mAP(Mean Average Precision)是評估模型效果的綜合指標,是根據recall和Precision計算出來的。
2.3.1 計算步驟
- 根據IoU劃分TP和FP;
- 按置信度從大到小進行排序,計算從Top-1到Top-N對應的Precision值和Recall值;
- 繪制P-R曲線,進行AP(面積)計算;
- A P 50 {AP}_{50} AP50??:設定目標框置信度閥值(IoU),常用閥值0.5,這意味著如果一個預測框和真實框之間的IoU大于或等于0.5,則認為該預測框是正確的(即正樣本),否則認為是錯誤的(即負樣本);
- A P 75 {AP}_{75} AP75??:設定目標框置信度閥值(IoU),常用閥值0.75,這意味著如果一個預測框和真實框之間的IoU大于或等于0.75,則認為該預測框是正確的(即正樣本),否則認為是錯誤的(即負樣本);
- A P 50 ? 95 {AP}_{50-95} AP50?95?:閥值設置為0.50、0.55、0.60…·…0.95,針對每個閥值分別求AP之后再求平均值。
2.3.2 案例分析
場景假設:假如有8個( 即真實值為正, TP+FN=8 ) 目標,檢索出來20個目標框(ID),即預測值為正(TP+FP=20)。
注意:8個目標不是說一張圖有8個label,是所有樣本,所有分類一共8個label,比如可能10000張高鐵圖片,抽煙的人檢測到8人。
我們設定一個閾值,比如50%,來決定哪個樣本被劃分為正類,哪個樣本被劃分為負類。如果一個樣本的置信度評分超過50%,我們就把它看作是正類;如果低于50%,則視為負類。
然后,可以按照置信度評分對所有目標框進行排序。從置信度最高的目標框開始,計算當前狀態下模型的精確率和召回率,然后依次增加目標框,再次計算精確率和召回率。重復這個過程,直到遍歷完所有目標框。這樣,就得到了一系列的精確率和召回率值。
①、目標框的置信度(Confidence Score)以及正負樣本預測結果如下表:
| ID | Confidence | TP | FP | IoU | Label |
|---|---|---|---|---|---|
| 1 | 0.23 | 0 | 1 | 0.1 | 0 |
| 2 | 0.76 | 1 | 0 | 0.8 | 1 |
| 3 | 0.01 | 0 | 1 | 0.2 | 0 |
| 4 | 0.91 | 1 | 0 | 0.9 | 1 |
| 5 | 0.13 | 0 | 1 | 0.2 | 0 |
| 6 | 0.45 | 0 | 1 | 0.3 | 0 |
| 7 | 0.12 | 1 | 0 | 0.8 | 1 |
| 8 | 0.03 | 0 | 1 | 0.2 | 0 |
| 9 | 0.38 | 1 | 0 | 0.9 | 1 |
| 10 | 0.11 | 0 | 1 | 0.1 | 0 |
| 11 | 0.03 | 0 | 1 | 0.2 | 0 |
| 12 | 0.09 | 0 | 1 | 0.4 | 0 |
| 13 | 0.65 | 0 | 1 | 0.3 | 0 |
| 14 | 0.07 | 0 | 1 | 0.2 | 0 |
| 15 | 0.12 | 0 | 1 | 0.1 | 0 |
| 16 | 0.24 | 1 | 0 | 0.8 | 1 |
| 17 | 0.10 | 0 | 1 | 0.1 | 0 |
| 18 | 0.23 | 0 | 1 | 0.1 | 0 |
| 19 | 0.46 | 0 | 1 | 0.1 | 0 |
| 20 | 0.08 | 1 | 0 | 0.9 | 1 |
②、按照置信度降序排序
| ID | Confidence | Label |
|---|---|---|
| 4 | 0.91 | 1 |
| 2 | 0.76 | 1 |
| 13 | 0.65 | 0 |
| 19 | 0.46 | 0 |
| 6 | 0.45 | 0 |
| 9 | 0.38 | 1 |
| 16 | 0.24 | 1 |
| 1 | 0.23 | 0 |
| 18 | 0.23 | 0 |
| 5 | 0.13 | 0 |
| 7 | 0.12 | 1 |
| 15 | 0.12 | 0 |
| 10 | 0.11 | 0 |
| 17 | 0.10 | 0 |
| 12 | 0.09 | 0 |
| 20 | 0.08 | 1 |
| 14 | 0.07 | 0 |
| 8 | 0.03 | 0 |
| 11 | 0.03 | 0 |
| 3 | 0.01 | 0 |
③、TOP-N概念理解:以返回的前N個框計算指標,N從1開始直到所有目標框結束。
如果N=5,則可計算出:TP = 2 , FP = 3,共有目標8個
Precision = 2/5 = 40%
Recall = 2/8 = 25%
| ID | Score | Label | 混淆矩陣 |
|---|---|---|---|
| 4 | 0.91 | 1 | True Positives |
| 2 | 0.76 | 1 | True Positives |
| 13 | 0.65 | 0 | False Positives |
| 19 | 0.46 | 0 | False Positives |
| 6 | 0.45 | 0 | False Positives |
如果N = 3 呢?則可計算出:TP = 2 , FP = 1,共有目標8個
Precision = 2/3 = 66.7%
Recall = 2/8 = 25%
隨著N的增大,召回率必然不會變小,但是精度也是很難評。
④、mAp計算
PASCAL VOC 2010以前:設置11個recall閾值[0, 0.1, 0.2, …, 1],計算Recall大于等于每一個閾值時的最大Precision,AP即平均值
A P = 1 11 ∑ r ∈ { 0 , 0.1 , . . . , 1 } p i n t e r p ( r ) p i n t e r p ( r ) = max ? r ~ : r ~ ≥ r p ( r ~ ) r ~ 表示處于閾值 r 和下一級閾值之間的 r e c a l l 值 ( 相同的閾值可能對應不同的精度 ) \mathrm{AP}=\frac{1}{11}\sum_{r\in\{0,0.1,...,1\}}p_{interp(r)}\quad p_{interp(r)}=\max_{\tilde{r}:\tilde{r}\geq r}p(\tilde{r}) \\ \tilde{r}表示處于閾值r和下一級閾值之間的recall值(相同的閾值可能對應不同的精度) AP=111?r∈{0,0.1,...,1}∑?pinterp(r)?pinterp(r)?=r~:r~≥rmax?p(r~)r~表示處于閾值r和下一級閾值之間的recall值(相同的閾值可能對應不同的精度)
以上數據整理如下:
| ID | Score | Label | Recall | Precision |
|---|---|---|---|---|
| 4 | 0.91 | 1 | 1/8(0.125) | 1/1 |
| 2 | 0.76 | 1 | 2/8(0.25) | 2/2 |
| 13 | 0.65 | 0 | 2/8(0.25) | 2/3 |
| 19 | 0.46 | 0 | 2/8(0.25) | 2/4 |
| 6 | 0.45 | 0 | 2/8(0.25) | 2/5 |
| 9 | 0.38 | 1 | 3/8(0.375) | 3/6 |
| 16 | 0.24 | 1 | 4/8(0.5) | 4/7 |
| 1 | 0.23 | 0 | 4/8(0.5) | 4/8 |
| 18 | 0.23 | 0 | 4/8(0.5) | 4/9 |
| 5 | 0.13 | 0 | 4/8(0.5) | 4/10 |
| 7 | 0.12 | 1 | 5/8(0.625) | 5/11 |
| 15 | 0.12 | 0 | 5/8(0.625) | 5/12 |
| 10 | 0.11 | 0 | 5/8(0.625) | 5/13 |
| 17 | 0.10 | 0 | 5/8(0.625) | 5/14 |
| 12 | 0.09 | 0 | 5/8(0.625) | 5/15 |
| 20 | 0.08 | 1 | 6/8(0.75) | 6/16 |
| 14 | 0.07 | 0 | 6/8(0.75) | 6/17 |
| 8 | 0.03 | 0 | 6/8(0.75) | 6/18 |
| 11 | 0.03 | 0 | 6/8(0.75) | 6/19 |
| 3 | 0.01 | 0 | 6/8(0.75) | 6/20 |
于是就有了下面的數據:
| R | 0 | 0.1 | 0.2 | 0.3 | 0.4 | 0.5 | 0.6 | 0.7 | 0.8 | 0.9 | 1.0 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| P | 1.0 | 1.0 | 1.0 | 0.5 | 0.571 | 0.571 | 0.455 | 0.375 | 0 | 0 | 0 |
于是可以計算出mAP值:
A P = 1 11 ( 1 + 1 + 1 + 0.5 + 0.571 + 0.571 + 0.455 + 0.375 + 0 + 0 + 0 ) = 49.75 % \begin{aligned}&\mathrm{AP}=\frac{1}{11}(1+1+1+0.5+0.571+0.571+0.455+0.375+0+0+0)\\&=49.75\%\end{aligned} ?AP=111?(1+1+1+0.5+0.571+0.571+0.455+0.375+0+0+0)=49.75%?
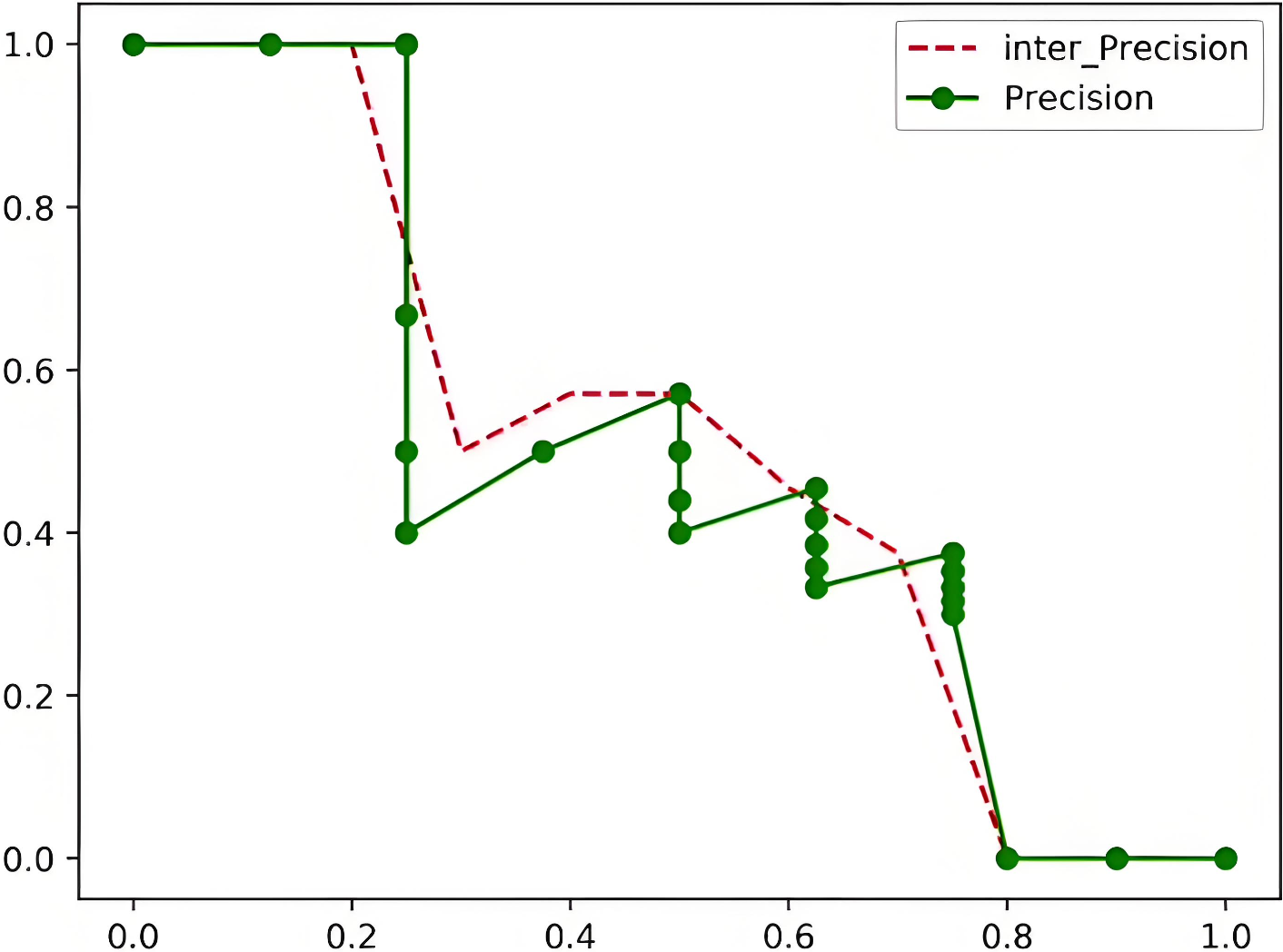
PASCAL VOC 2010以后采用面積法:
假設真實目標數為M,recall取樣間隔為[0, 1/M, …, M/M],假設有 8 個目標,recall 取值 = [0, 0.125, 0.25, 0.375, 0.5, 0.625, 0.75, 0.875, 1.0]
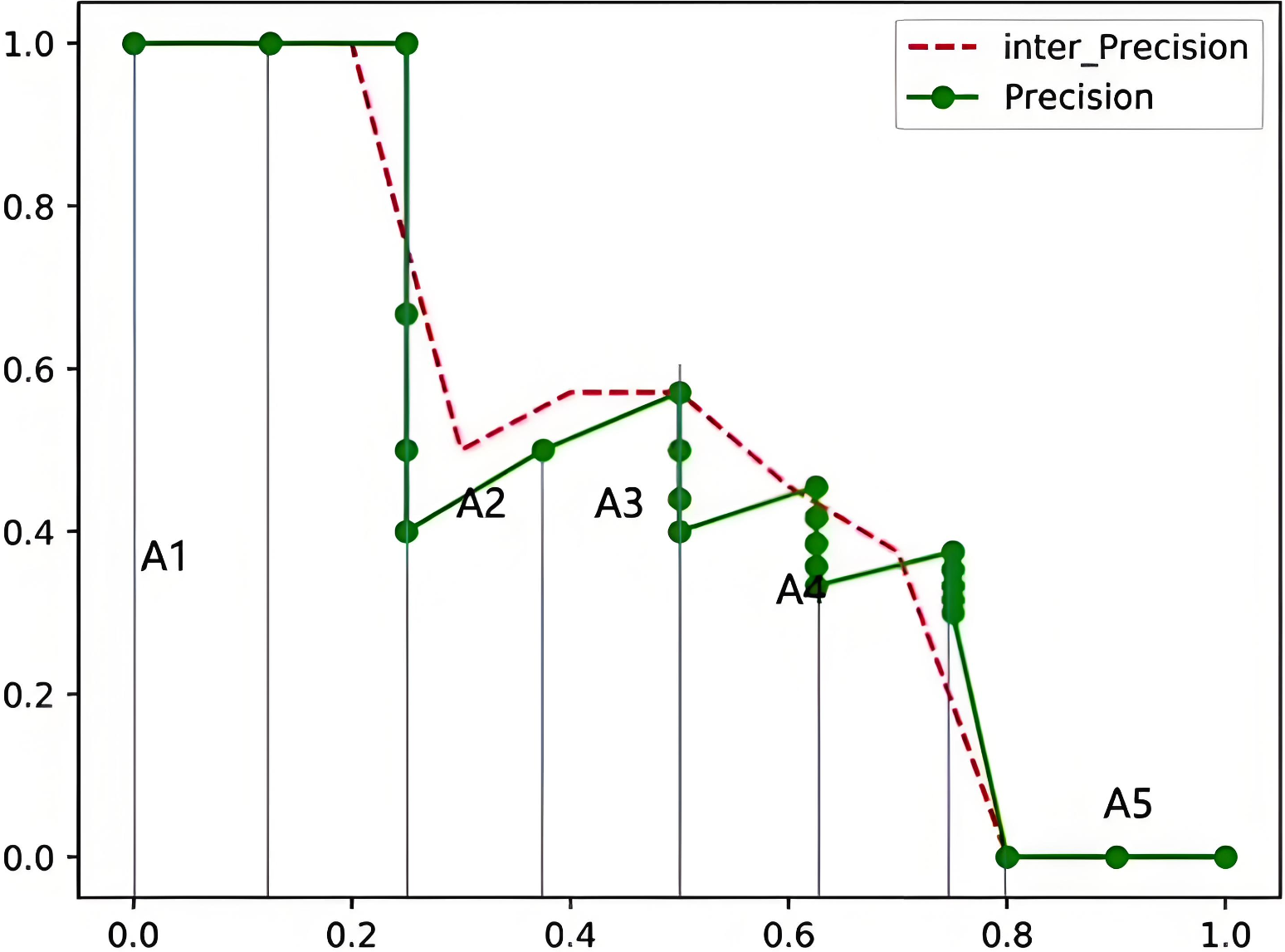
把各塊面積加起來就是mAP值了:
注意:高還是閾值r和下一級閾值之間最高的精度,寬其實就是1/M
m A P = 0.12 5 ? 1 + ( 0.25 ? 0.125 ) ? 1 + ( 0.375 ? 0.25 ) ? 0.5 + ( 0.5 ? 0.375 ) ? 0.571 + ( 0.625 ? 0.5 ) ? 0.455 + ( 0.75 ? 0.675 ) ? 0.375 + ( 0.875 ? 0.75 ) ? 0 = 48.7 % \begin{aligned} &\mathrm{mAP=0.125^{\star}1+(0.25-0.125)^{\star}1+(0.375-} \\ &0.25)^{\star}0.5+(0.5-0.375)^{\star}0.571+(0.625- \\ &0.5)^\star0.455+(0.75-0.675)^\star0.375+(0.875-0.75)^\star0 \\ &=48.7\% \end{aligned} ?mAP=0.125?1+(0.25?0.125)?1+(0.375?0.25)?0.5+(0.5?0.375)?0.571+(0.625?0.5)?0.455+(0.75?0.675)?0.375+(0.875?0.75)?0=48.7%?
3. 后處理方法NMS
目標檢測的后處理方法主要用于優化檢測結果,比如檢測出來的各個目標有多個目標框怎么搞?
非極大值抑制(Non-maximum suppression, NMS)是目標框后處理方法,是非常重要的一個環節。
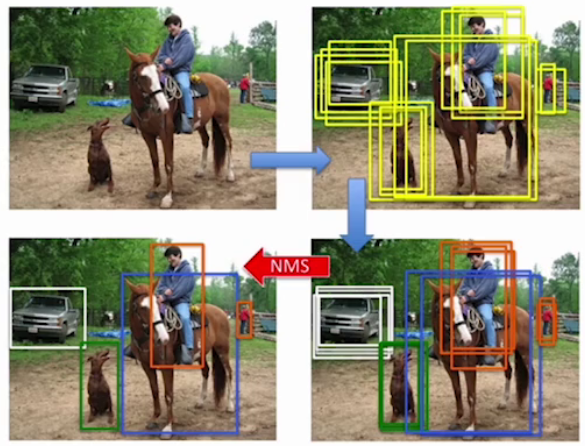
上圖最終輸出的目標框計算過程如下:按照類別各自分開處理
- 設定目標框置信度閾值,常用閾值0.5,小于該值的框會被過濾掉;
- 根據置信度降序排列候選框;
- 選取置信度最高的框A添到輸出列表,并將其從候選框列表中刪除;
- 候選框列表中所有框依次與A計算loU,刪除大于IoU閾值的框;
- 重復上述過程,直到候選框列表為空;
- 輸出列表就是最后留下的目標框;
4. 檢測速度
4.1 前傳耗時
單位ms,從輸入圖像到輸出最終結果所消耗的時間,包括前處理耗時(如圖像歸一化)、網絡前傳耗時、后處理耗時(如非極大值抑制)。
4.2 FPS
FPS(Frames Per Second,每秒幀數),每秒鐘能處理的圖像的數量,實時監測要求 FPS 達到 30
4.3 FLOPS
FLOPS(Floating Point Operations Per Second,每秒浮點運算次數)是衡量計算設備性能的一個重要指標,特別是在高性能計算和深度學習領域。它表示設備在一秒內可以執行的浮點運算次數
- KFLOPS:每秒千次浮點運算( 1 0 3 10^3 103 FLOPS)
- MFLOPS:每秒百萬次浮點運算( 1 0 6 10^6 106FLOPS)
- GFLOPS:每秒十億次浮點運算( 1 0 9 10^9 109FLOPS)
- TFLOPS:每秒萬億次浮點運算( 1 0 12 10^{12} 1012FLOPS)
- PFLOPS:每秒千萬億次浮點運算( 1 0 15 10^{15} 1015FLOPS)
5. 整體網絡結構
目標檢測網絡主要由Backbone、Neck、Head三塊組成。
5.1 網絡結構圖

結構圖內部展開:
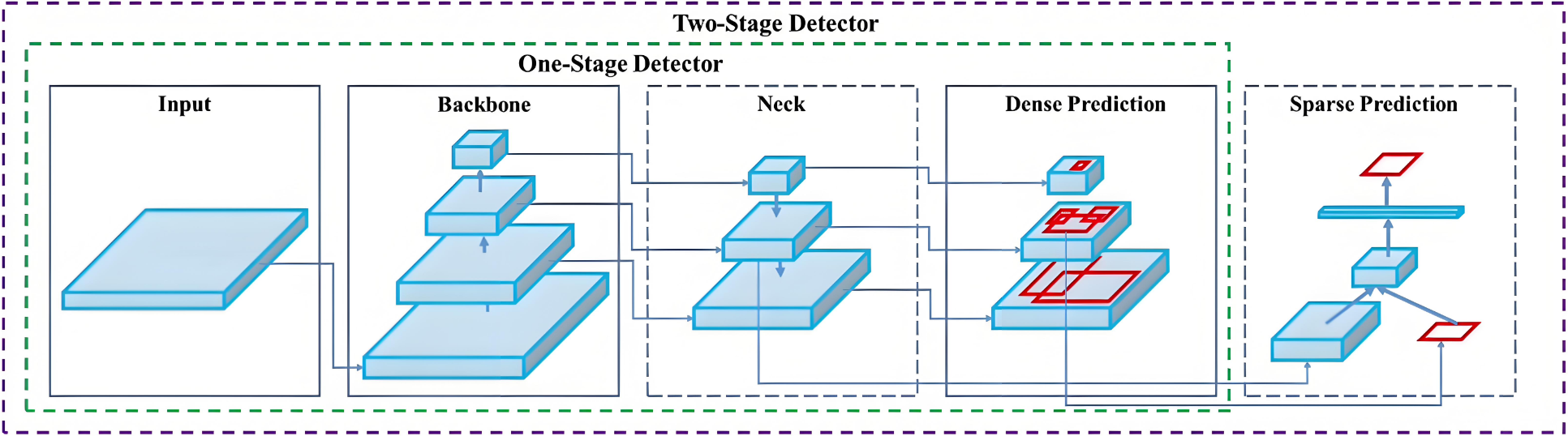
5.1.1 Backbone network
- 描述:
- Backbone network,即主干網絡(骨干網絡),目標檢測網絡最為核心的部分,主要是使用不同的卷積神經網絡構建
- 任務:
- 特征提取:從輸入圖像中提取特征信息,這些特征通常包含豐富的信息,能夠幫助后續模塊進行目標檢測
5.1.2 Neck network
- 描述:
- Neck network,即頸部網絡,主要對主干網絡輸出的特征進行整合,常見的整合方式FPN(Feature Pyramid Network);
- 任務:
- 特征融合:將主干網絡提取的多尺度特征進行融合,以增強特征的表達能力和魯棒性
5.1.3 Detection head
- 描述:
- Detection head,即檢測頭,在特征之上進行預測,包括物體的類別和位置
- 任務:
- 目標檢測:檢測頭的主要任務是基于融合后的特征圖,通過回歸任務預測邊界框的坐標,通過分類任務預測目標的類別,生成最終的檢測結果,包括邊界框和類別
5.2 YOLO網絡結構
| Model | Backbone | Neck | Head | Prediction Loss |
|---|---|---|---|---|
| v1 | GoogLeNet | None | FC → 7×7×(5+5+20) | MSE Loss |
| v2 | Darknet19 | Passthrough | 13×13×5×(5+20) | MSE Loss |
| v3 | Darknet53 | FPN | 13×13×3×(5+80), 26×26×3×(5+80), 52×52×3×(5+80) | MSE Loss |
| v4 | Darknet53_CSP | SPP、FPN、PAN | 13×13×3×(5+80), 26×26×3×(5+80), 52×52×3×(5+80) | CIoU Loss |
| v5 | Darknet53_CSP | SPP, cspFPN, cspPAN | 13×13×3×(5+80), 26×26×3×(5+80), 52×52×3×(5+80) | GIoU Loss |
三、 目標檢測數據集
1. PASCAL VOC
共20類,主要用于目標檢測。
VOC2007: 9963張圖,24640個標注目標。
VOC2012: 23080圖片,54900目標
https://www.kaggle.com/datasets/zaraks/pascal-voc-2007

分類結構如下:
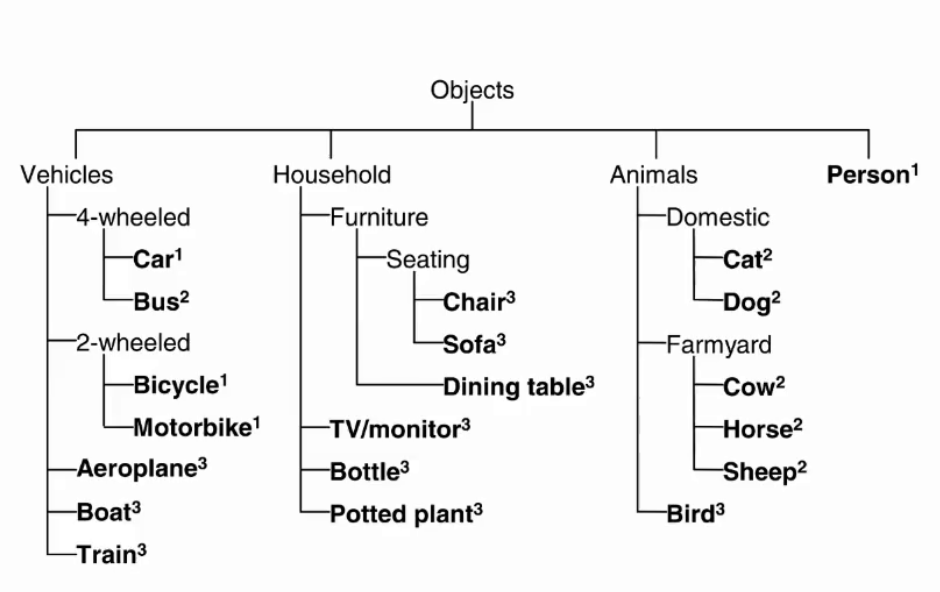
目標檢測如下:

圖像分割:

行為識別:

人體布局:

2. MS COCO
MS COCO數據集,全稱是Microsoft Common Objects in Context.
- 80分類、20萬個圖像、超過50萬目標標注。
- 可用來圖像識別、目標檢測和分割等任務。
- 數據集分為訓練集、驗證集和測試集。
https://www.kaggle.com/datasets/awsaf49/coco-2017-dataset
四、YOLOV1全解
? You Only Look Once,把檢測問題轉化成回歸問題,一個CNN就搞定了!!!效率高,可對視頻進行實時檢測,應用領域非常廣,到V3的時被美國軍方用于軍事行動,作者出于某種壓力就退出了后續版本的更新,改由其他大佬繼承衣缽!
作者:
? Joseph Redmon ,Santosh Divvala , Ross Girshick 和 Ali Farhadi 。
? Joseph Redmon 是YOLO系列的主要創始人,他在華盛頓大學進行研究工作時提出了 YOLO 的概念。
論文:
? https://www.cv-foundation.org/openaccess/content_cvpr_2016/papers/Redmon_You_Only_Look_CVPR_2016_paper.pdf
1. 發展歷史
當年Fast R-CNN效果很好,但是速度太慢,距離實時檢測差得遠,于是YOLO橫空出世。
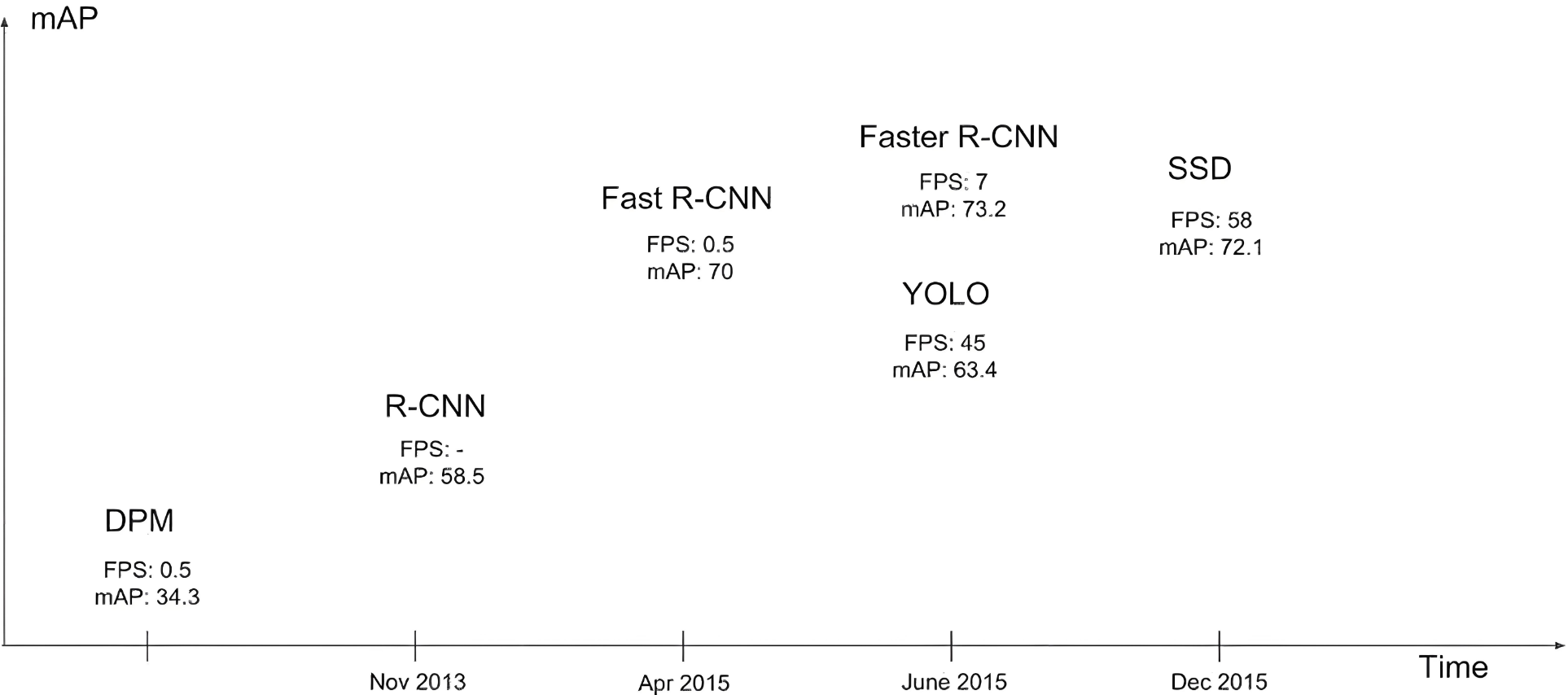
YOLO發展歷史:
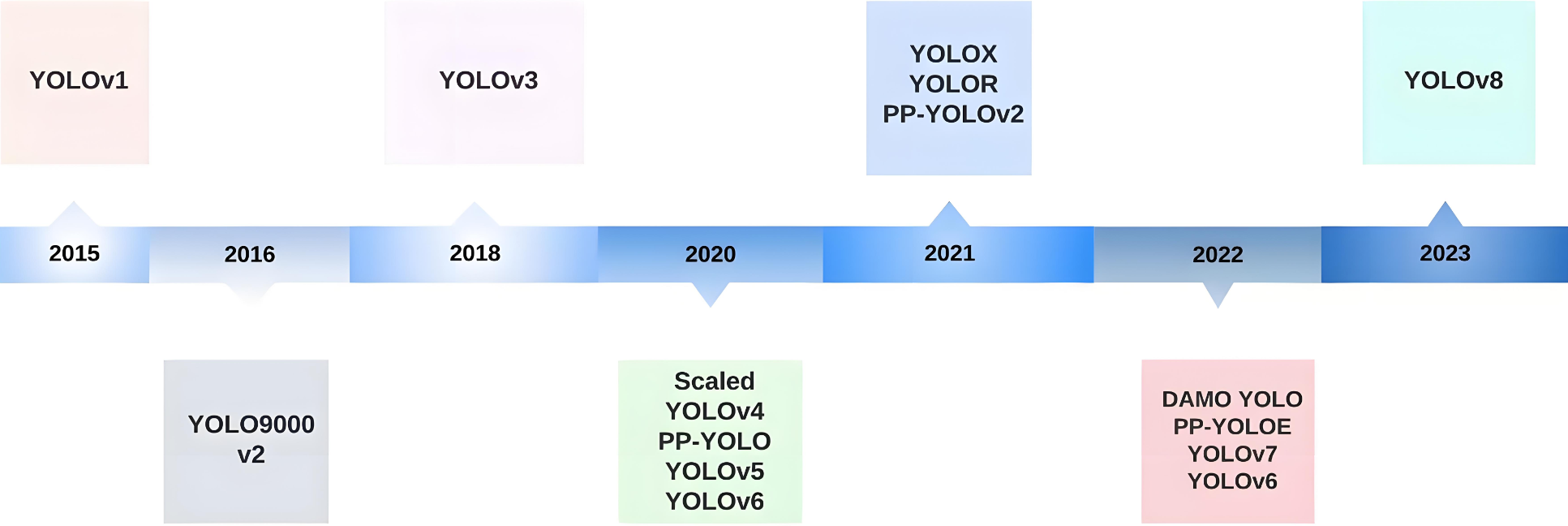
2. 網絡特征
? 直接對輸入圖預測出邊框坐標(x,y,w,h)和物體類別?、置信度(Confidence),是典型的One-stage目標檢測方法,運行速度快,可以做到實時檢測。

3. 網絡結構
結構:24個卷積層,4個池化,2個全連接層

4. 核心思想
4.1 候選框策略
- 將輸入圖像分為 S × S S\times S S×S 個grid;
- 每個grid預測 B B B 個Bounding Box,每個bbox包含4個坐標和置信度;
- 每個grid預測 C C C 類類別概率
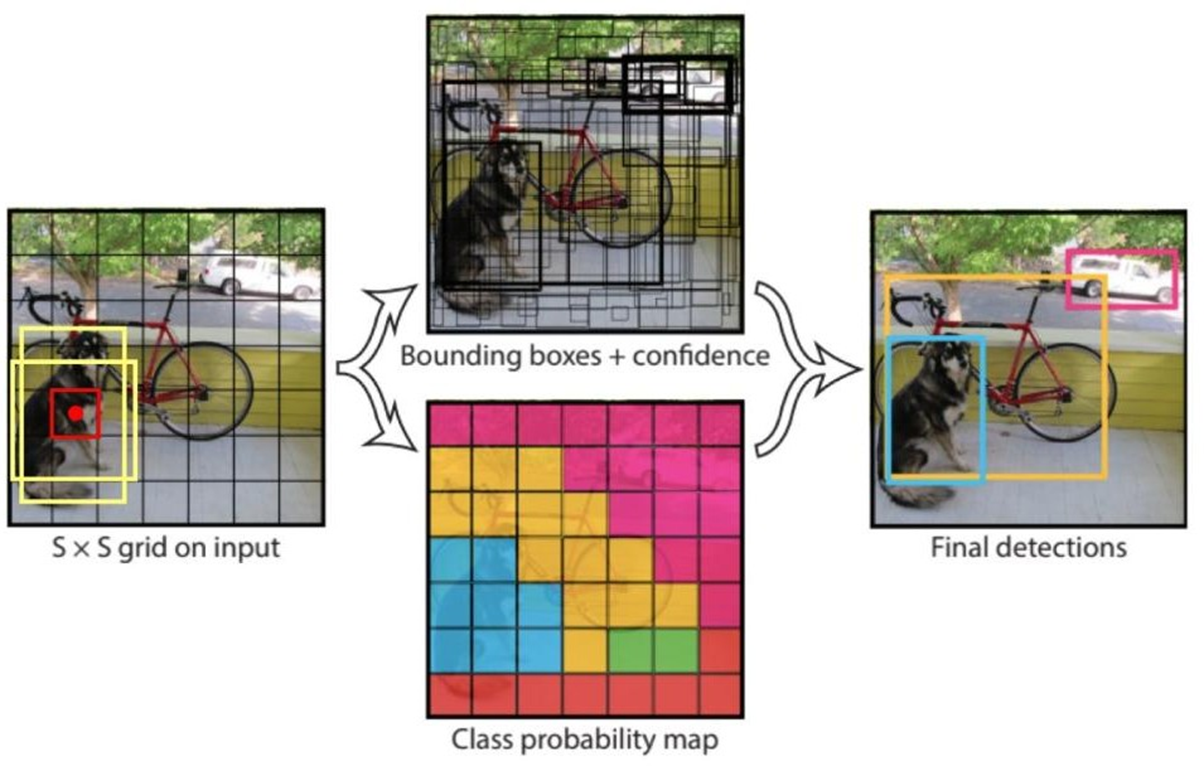
4.2 預測流程
- 將圖片劃分為 7 × 7 7 \times 7 7×7 個Grid
- 目標中心落在哪個grid cell里,就由其預測
- 每個grid預測 2 2 2 個bbox
- 每個grid預測 20 20 20 個類別概率(當時VOC數據集是20分類)

合體效果圖如下:
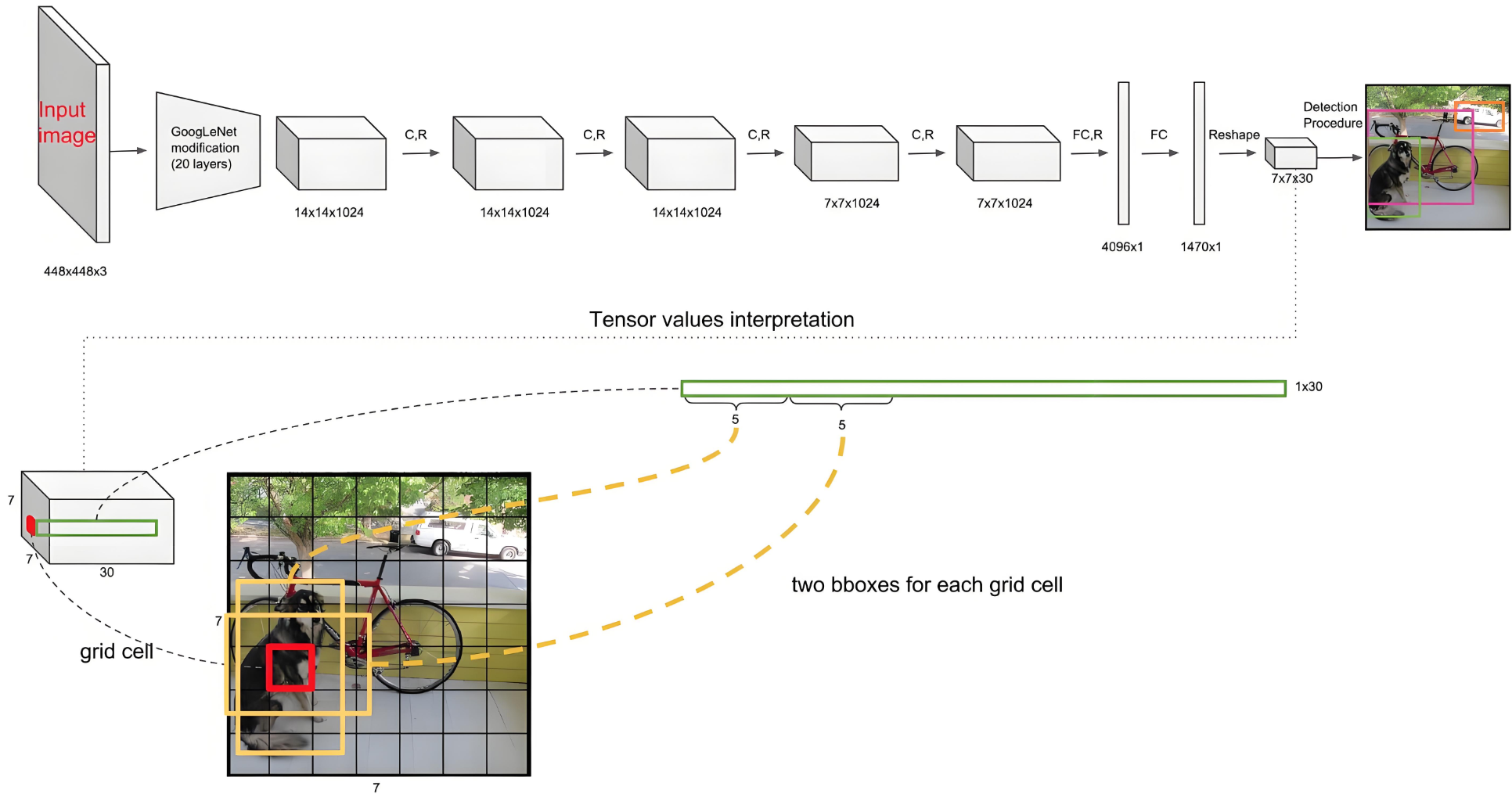
圖中數字解釋:
- 7 × 7:表示把圖片分成7 × 7共49個Grid;
- 30則代表每個Grid有30個參數:20 +2 × (1+4)=30
? 20個分類、2個Bounding(候選框),每個候選框分別有1個Confidence和(x,y,w,h)表示的坐標位置 。
4.3 坐標詳解
在 YOLOv1 中,模型預測的 x, y, w, h 是目標邊界框(Bounding Box)的參數,具體含義如下:
1. x 和 y:
x和y表示預測邊界框的中心點相對于當前網格單元的偏移量。- 具體來說:
- 每個圖像被劃分為一個
S x S的網格(例如 YOLOv1 默認是7 x 7)。 - 如果某個目標的中心落在某個網格單元中,則該網格單元負責預測該目標。
x和y是相對于該網格單元左上角的歸一化偏移量,取值范圍為[0, 1]。- 歸一化的意思是:假設每個網格單元的實際寬度和高度為 1,則
x和y是中心點距離網格單元左上角的相對位置。
- 每個圖像被劃分為一個
2. w 和 h:
w和h表示預測邊界框的寬度和高度,但它們是相對于整個圖像的歸一化值。- 具體來說:
w是預測框的寬度與整個圖像寬度的比值。h是預測框的高度與整個圖像高度的比值。- 因此,
w和h的取值范圍通常也是[0, 1]。
總結:
x, y:表示邊界框中心點相對于所在網格單元的歸一化偏移量。w, h:表示邊界框的寬度和高度相對于整個圖像的歸一化值
4.3.1 公式
-
計算中心點的實際坐標:

-
計算邊界框的實際寬度和高度:
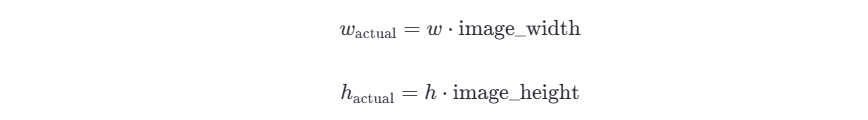
-
得到邊界框的四個頂點坐標:

4.3.2 示例
假設我們有一張輸入圖像,大小為 448x448(YOLOv1 默認輸入尺寸)。我們將圖像劃分為 7x7 的網格,每個網格單元的大小為:
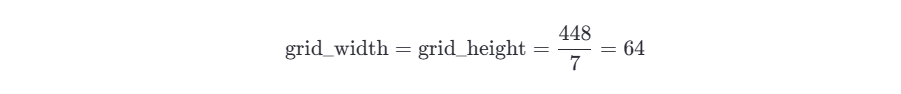
現在,假設某個目標的中心點落在網格單元 (3, 2) 中(即第 3 列、第 2 行的網格單元),并且模型預測的邊界框參數為:
- x=0.3(中心點相對于網格單元左上角的歸一化偏移量)
- y=0.7(中心點相對于網格單元左上角的歸一化偏移量)
- w=0.5(邊界框寬度相對于圖像寬度的歸一化值)
- h=0.4(邊界框高度相對于圖像高度的歸一化值)
我們需要計算這個邊界框的實際像素坐標。




5. 損失函數
5.1 整體概覽
整個損失函數由5部分組成:
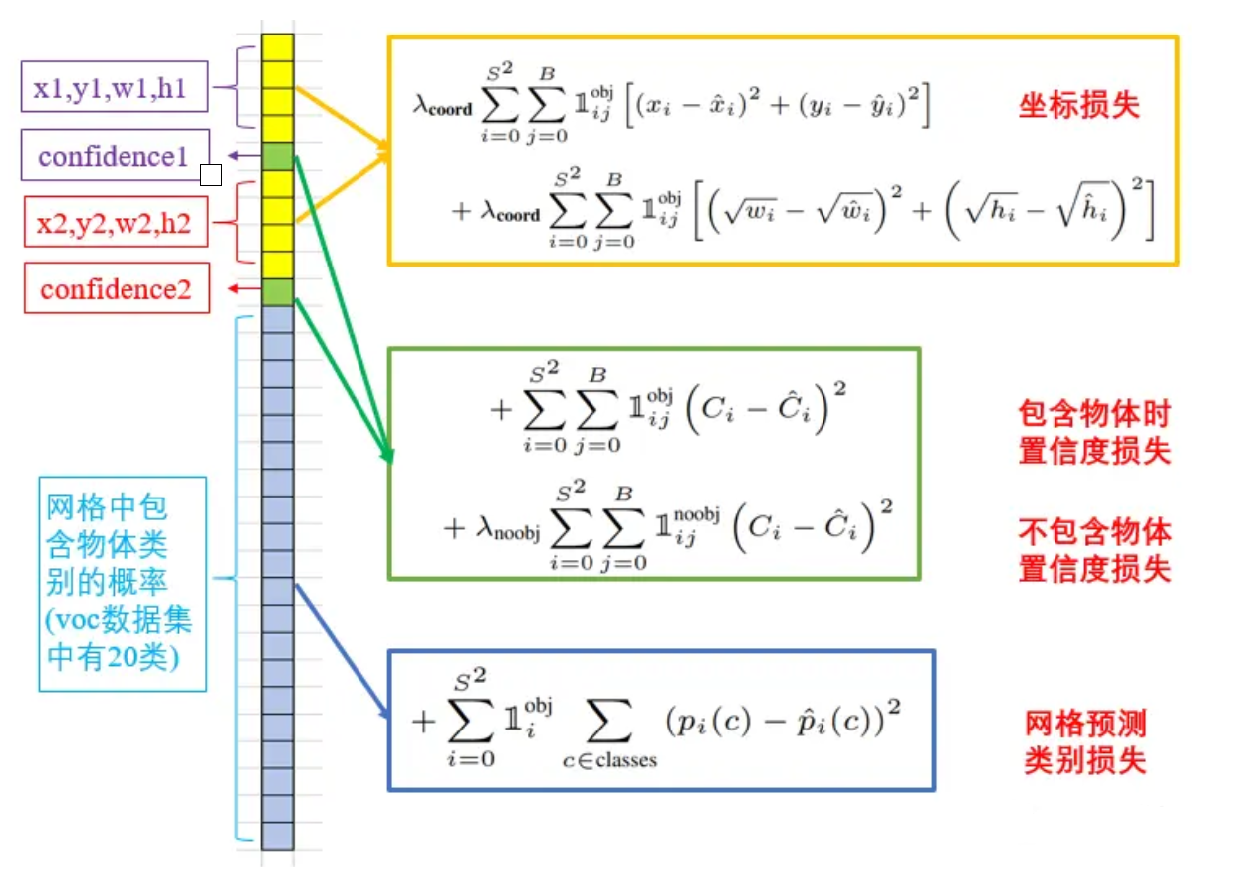
整體合并后公式如下:
λ c o o r d ∑ i = 0 S 2 ∑ j = 0 B 1 i j o b j [ ( x i ? x ^ i ) 2 + ( y i ? y ^ i ) 2 ] 【注解:邊框中心點誤差】 + λ c o o r d ∑ i = 0 S 2 ∑ j = 0 B 1 i j o b j [ ( w i ? w ^ i ) 2 + ( h i ? h ^ i ) 2 ] 【注解:邊框寬高誤差】 + ∑ i = 0 S 2 ∑ j = 0 B 1 i j o b j ( C i ? C ^ i ) 2 【注解:有物體時置信度誤差】 + λ noobj ∑ i = 0 S 2 ∑ j = 0 B 1 i j noobj ( C i ? C ^ i ) 2 【注解:無物體時置信度誤差】 + ∑ i = 0 S 2 1 i o b j ∑ c ∈ c l a s s e s ( p i ( c ) ? p ^ i ( c ) ) 2 【注解:網格內有物體時的分類誤差】 \begin{gathered} \lambda_{\mathbf{coord}}\sum_{i=0}^{S^{2}}\sum_{j=0}^{B}\mathbb{1}_{ij}^{\mathrm{obj}}\left[\left(x_{i}-\hat{x}_{i}\right)^{2}+\left(y_{i}-\hat{y}_{i}\right)^{2}\right]【注解:邊框中心點誤差】 \\ +\lambda_{\mathbf{coord}}\sum_{i=0}^{S^{2}}\sum_{j=0}^{B}\mathbb{1}_{ij}^{\mathrm{obj}}\left[\left(\sqrt{w_{i}}-\sqrt{\hat{w}_{i}}\right)^{2}+\left(\sqrt{h_{i}}-\sqrt{\hat{h}_{i}}\right)^{2}\right] 【注解:邊框寬高誤差】\\ +\sum_{i=0}^{S^2}\sum_{j=0}^B\mathbb{1}_{ij}^{\mathrm{obj}}\left(C_i-\hat{C}_i\right)^2 【注解:有物體時置信度誤差】\\ +\lambda_\text{noobj}\sum_{i=0}^{S^2}\sum_{j=0}^B\mathbb{1}_{ij}^\text{noobj}\left(C_i-\hat{C}_i\right)^2 【注解:無物體時置信度誤差】\\ +\sum_{i=0}^{S^2}\mathbb{1}_i^\mathrm{obj}\sum_{c\in\mathrm{classes}}\left(p_i(c)-\hat{p}_i(c)\right)^2 【注解:網格內有物體時的分類誤差】 \\ \end{gathered} λcoord?i=0∑S2?j=0∑B?1ijobj?[(xi??x^i?)2+(yi??y^?i?)2]【注解:邊框中心點誤差】+λcoord?i=0∑S2?j=0∑B?1ijobj?[(wi???w^i??)2+(hi???h^i??)2]【注解:邊框寬高誤差】+i=0∑S2?j=0∑B?1ijobj?(Ci??C^i?)2【注解:有物體時置信度誤差】+λnoobj?i=0∑S2?j=0∑B?1ijnoobj?(Ci??C^i?)2【注解:無物體時置信度誤差】+i=0∑S2?1iobj?c∈classes∑?(pi?(c)?p^?i?(c))2【注解:網格內有物體時的分類誤差】?
公式解釋:
- λ c o o r d \lambda_{coord} λcoord?是一個權重系數,用于平衡坐標損失與其他損失項,論文中設置的值為 5
- S 2 S^2 S2表示有多少個 grid,
- B 表示框的個數,在 YOLOv1 中是 2 種,即 B 為 2
- obj 表示有物體時的情況
- noobj 表示沒有物體時的情況
- i j i j ij 表示第 i 個 的第 j 個框
- 1 i j o b j 1_{ij}^{obj} 1ijobj?是一個指示函數,當某個邊界框負責某個對象時為 1,否則為 0
- x i 和 y i x_i和y_i xi?和yi?表示實際的坐標, x i ^ 和 y i ^ \hat{x_i}和\hat{y_i} xi?^?和yi?^?表示預測的坐標
- w i 和 h i w_i和h_i wi?和hi?表示實際的寬高, w i ^ 和 h i ^ \hat{w_i}和\hat{h_i} wi?^?和hi?^?表示預測的寬高
- C i C_i Ci?表示實際的置信度分數( C i = P r ( o b j ) ? I o U C_i=Pr(obj)*IoU Ci?=Pr(obj)?IoU), C i ^ \hat{C_i} Ci?^?表示預測的置信度分數
- λ n o o b j \lambda_{noobj} λnoobj?一個較小的權重系數,用來減少無對象區域的置信度損失的影響,論文中設置的值為 0.5
- 1 i j n o o b j 1_{ij}^{noobj} 1ijnoobj?是一個指示函數,當某個邊界框負責某個對象時為 0,否則為 1
- p i ( c ) p_i(c) pi?(c)是第 i 個網格單元格中對象的真實類別分布, p i ^ ( c ) \hat{p_i}(c) pi?^?(c)是預測的類別概率分布
5.2 詳細解讀
公式部分非常規操作詳解:
①、關于開根號
$$
\begin{gathered}
\lambda_{\mathbf{coord}}\sum_{i=0}{S{2}}\sum_{j=0}{B}\mathbb{1}_{ij}{\mathrm{obj}}\left[\left(\sqrt{w_{i}}-\sqrt{\hat{w}_{i}}\right){2}+\left(\sqrt{h_{i}}-\sqrt{\hat{h}_{i}}\right){2}\right] \
\
開根號是為了減少在反向傳播更新參數時大框對小框的影響
\end{gathered}
$$
②、關于S的平方以及i和j
+ ∑ i = 0 S 2 ∑ j = 0 B I i j o b j ( C i ? C ^ i ) 2 + λ noobj ∑ i = 0 S 2 ∑ j = 0 B 1 i j noobj ( C i ? C ^ i ) 2 這里的 i 和 j 表示第 i 個 c e l l 的第 j 個框,訓練時只有一個匹配 S 2 則表示共有 7 ? 7 共 49 個 G r i d C e l l \begin{gathered} +\sum_{i=0}^{S^2}\sum_{j=0}^B\mathbb{I}_{ij}^{\mathrm{obj}}\left(C_i-\hat{C}_i\right)^2 \\ +\lambda_\text{noobj}\sum_{i=0}^{S^2}\sum_{j=0}^B\mathbb{1}_{ij}^\text{noobj}\left(C_i-\hat{C}_i\right)^2 \\ \\ 這里的i和j表示第i個cell的第j個框,訓練時只有一個匹配\\ {S^2}則表示共有7 * 7 共49個Grid Cell \end{gathered} +i=0∑S2?j=0∑B?Iijobj?(Ci??C^i?)2+λnoobj?i=0∑S2?j=0∑B?1ijnoobj?(Ci??C^i?)2這里的i和j表示第i個cell的第j個框,訓練時只有一個匹配S2則表示共有7?7共49個GridCell?
③、關于權重系數
$$
\begin{gathered}
\lambda_{\mathbf{coord}} \
\
\lambda_{\mathbf{coord}} 表示調高位置(坐標和寬高都加入了該系數)誤差的權重,畢竟這玩意很重要,設置為5
\end{gathered}
$$
④、關于不含物體的置信度
λ noobj ∑ i = 0 S 2 ∑ j = 0 B 1 i j noobj ( C i ? C ^ i ) 2 noobj表示沒有物體時的情況 λ noobj = 0.5 用于調整沒有目標時的權重系數 \begin{gathered} \lambda_\text{noobj}\sum_{i=0}^{S^2}\sum_{j=0}^B\mathbb{1}_{ij}^\text{noobj}\left(C_i-\hat{C}_i\right)^2 \\ \\ \text{noobj}表示沒有物體時的情況 \\ \lambda_\text{noobj}=0.5用于調整沒有目標時的權重系數 \end{gathered} λnoobj?i=0∑S2?j=0∑B?1ijnoobj?(Ci??C^i?)2noobj表示沒有物體時的情況λnoobj?=0.5用于調整沒有目標時的權重系數?


6. 算法性能對比
各網絡性能對比:
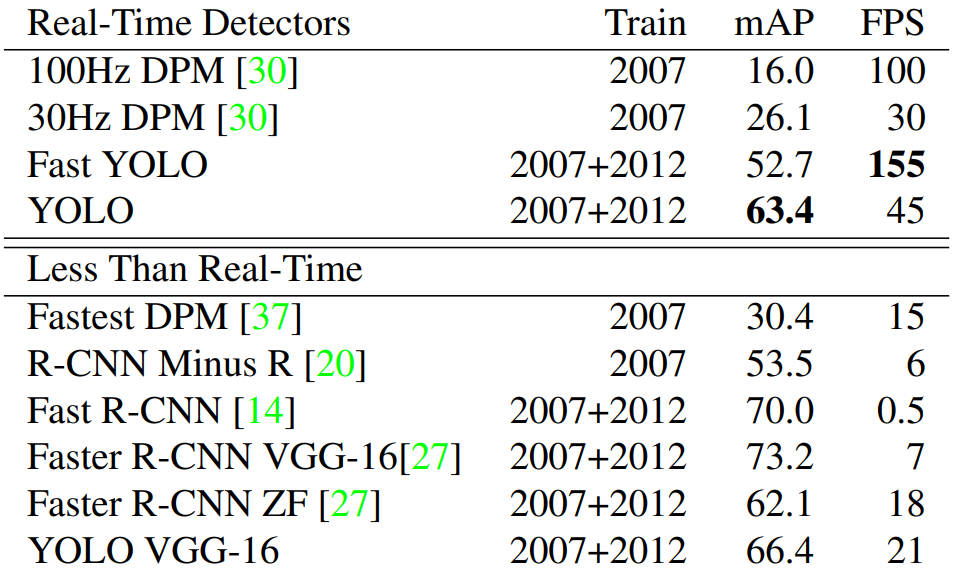
和Fast R-CNN多維度對比:

- Fast R-CNN:
- Correct:71.6%的檢測結果是正確的
- Loc:8.6%的錯誤是由于定位不準確
- Sim:4.3%的錯誤是由于相似類別的誤分類
- Other:1.9%的錯誤是由于其他原因。
- Background:13.6%的錯誤是將背景誤判為對象
- YOLO:
- Correct:65.5%的檢測結果是正確的
- Loc:19.0%的錯誤是由于定位不準確
- Sim:6.75%的錯誤是由于相似類別的誤分類
- Other:4.0%的錯誤是由于其他原因
- Background:4.75%的錯誤是將背景誤判為對象
7. YOLOV1特點總結
下面我們對YOLOV1做個總結
7.1 優點
- 更快更簡單:可達到45fps,遠高于Faster R-CNN系列,輕松滿足視頻目標檢測。
- 避免產生背景錯誤:YOLO區域選擇階段是對整張圖進行輸入,上下文充分利用,不易出現錯誤背景信息。
7.2 缺點
-
定位精度低:網格劃分有些粗糙和單一,多少難定
-
每個Cell只預測一個類別,如重疊或距離太近效果比較差
-
小物體檢測效果一般,長寬比可選尺寸及比例單一
五、YOLOV2
V2對V1進行了諸多的提升和改進。
論文地址:
? https://openaccess.thecvf.com/content_cvpr_2017/papers/Redmon_YOLO9000_Better_Faster_CVPR_2017_paper.pdf
1. 和V1對比
加入不同優化點后產生的效果對比

1.1 加入BN
(YOLOV1出來的時候還沒有BN)
-
V2加入Batch Normalization
-
網絡的每一層的輸入都做了歸一化,收斂相對更容易
-
經過Batch Normalization處理后的網絡會提升2.4%的mAP
-
目前Batch Normalization已經成網絡必備處理
1.2 更大分辨率
高分辨率分類器的思路如下:
- 預訓練:首先,基礎網絡(如Darknet-19)在ImageNet數據集上以較低分辨率(如224x224)進行預訓練,這一步是為了讓模型學習到基本的圖像特征表示。
- 調整輸入分辨率:為了提高模型對不同尺寸物體的檢測能力,會增加輸入圖像的分辨率,并在這個更高的分辨率下繼續訓練模型。例如,將輸入分辨率從224x224增加到448x448,并在ImageNet上再次微調網絡。這有助于模型適應更高分辨率下的特征提取。
- 目標檢測微調:最后一步是在目標檢測數據集(如Pascal VOC或COCO)上微調模型。這意味著使用特定于目標檢測的數據和標簽來優化模型參數,使其能夠有效地執行目標檢測任務。對于VOC數據集,這意味著模型被訓練來識別并定位20種類別的對象。
通過這種方式,YOLOv2確保了模型不僅能夠在低分辨率圖像上表現良好,而且在高分辨率圖像上也能夠有效工作。這對于目標檢測任務尤其重要,因為高分辨率圖像可以提供更多的細節信息,有助于更精確地定位和識別小目標。這個高分辨率的分類網絡使 mAP 增加了近 4%
-
V1訓練時用224×224,測試時用448×448,影響最終效果
-
V2訓練時額外進行10次448×448的訓練微調
-
使用高分辨率分類器后,YOLOV2的mAP提升了約4%
1.3 網絡結構
采用darknet-19作為主干網絡:
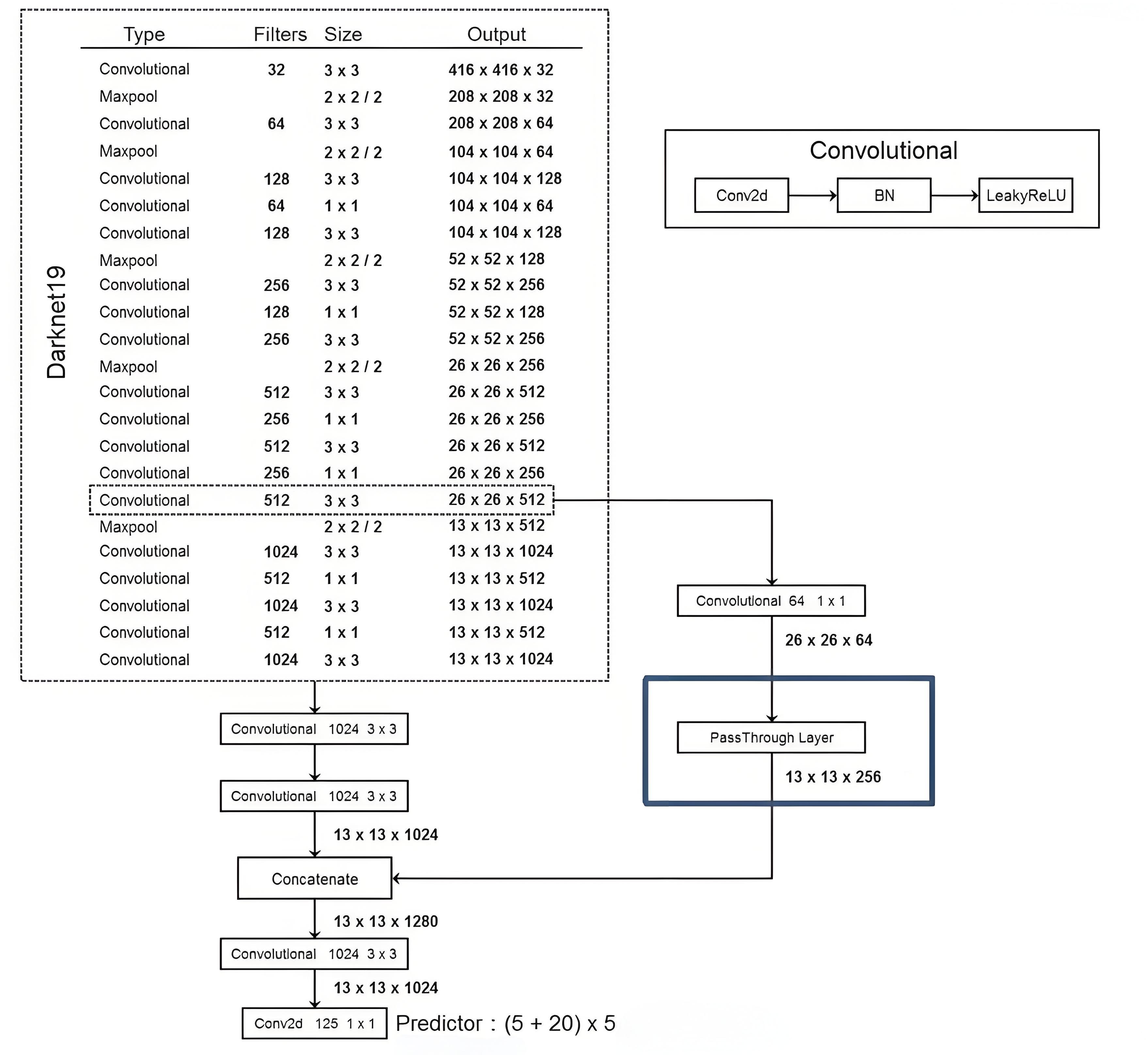
- Darknet,實際輸入為416*416
- 沒有FC層,5次降采樣(416 ?32=13)
- 1*1卷積節省了很多參數
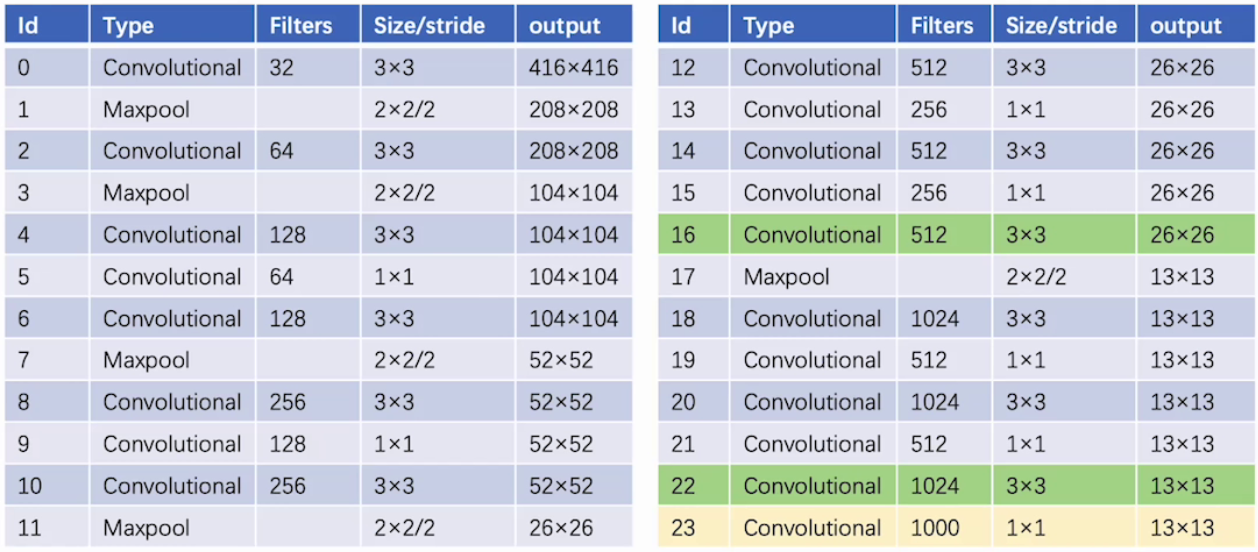
包含:19個conv層、5個max pooling層、無FC層,每個conv層后接入BN層
1.4 邊框策略
在YOLOv2中,引入了Anchor Boxes(先驗框)的思想來替代YOLOv1中直接預測邊界框的方式。
1.4.1 Anchor Boxes
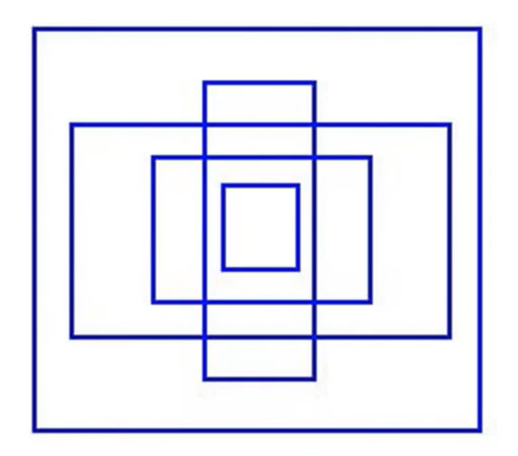
? 先驗框是在訓練神經網絡之前定義的框,用于指導網絡學習如何預測目標的位置和類別。YOLOv2中的先驗框是基于訓練數據集中的目標邊界框而來的,它們代表了不同尺寸和比例的目標。
1.4.2 聚類先驗框
YOLOv2使用K-means聚類算法來提取先驗框。K-means是一種無監督學習算法,用于將數據點分為K個不同的簇,以便找到數據的聚類結構。在YOLOv2中,K表示使用的先驗框數量,值為5。
先明確目的:K-means算法的目標是將訓練數據中的邊界框分配到最接近的聚類中心,以便找到最佳的先驗框。
使用K-means聚類算法對訓練數據中的邊界框進行聚類,以確定先驗框的大小和比例。聚類通常在邊界框的寬度和高度上進行,以找到不同尺寸和比例的先驗框。
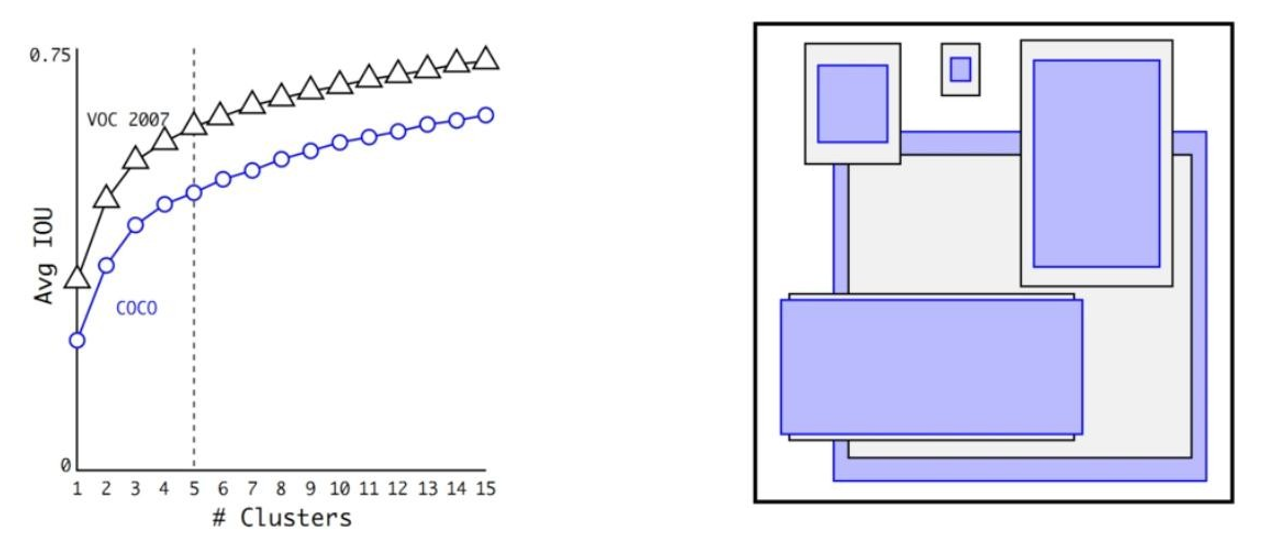
計算步驟:

如下圖,選取不同的 k 值(聚類的個數)運行 K-means算法,并畫出平均 IOU 和 K 值的曲線圖。當 k = 5 時,可以很好的權衡模型復雜性和高召回率。與手工挑選的相比,K-means 算法挑選的檢測框形狀多為瘦高型。
-
整體Precious降低0.3%,但是召回率卻從81%提升到88%;

1.5 損失函數
1.5.1 輸出特征維度
-
通道數:num_anchors x (4+1 + num_classes)
-
每個anchor都有4個邊界框回歸參數( t x , t y , t w , t h t_x, t_y, t_w, t_h tx?,ty?,tw?,th?) + 置信度 + 類別概率
-
VOC數據集20類、COCO數據集80類
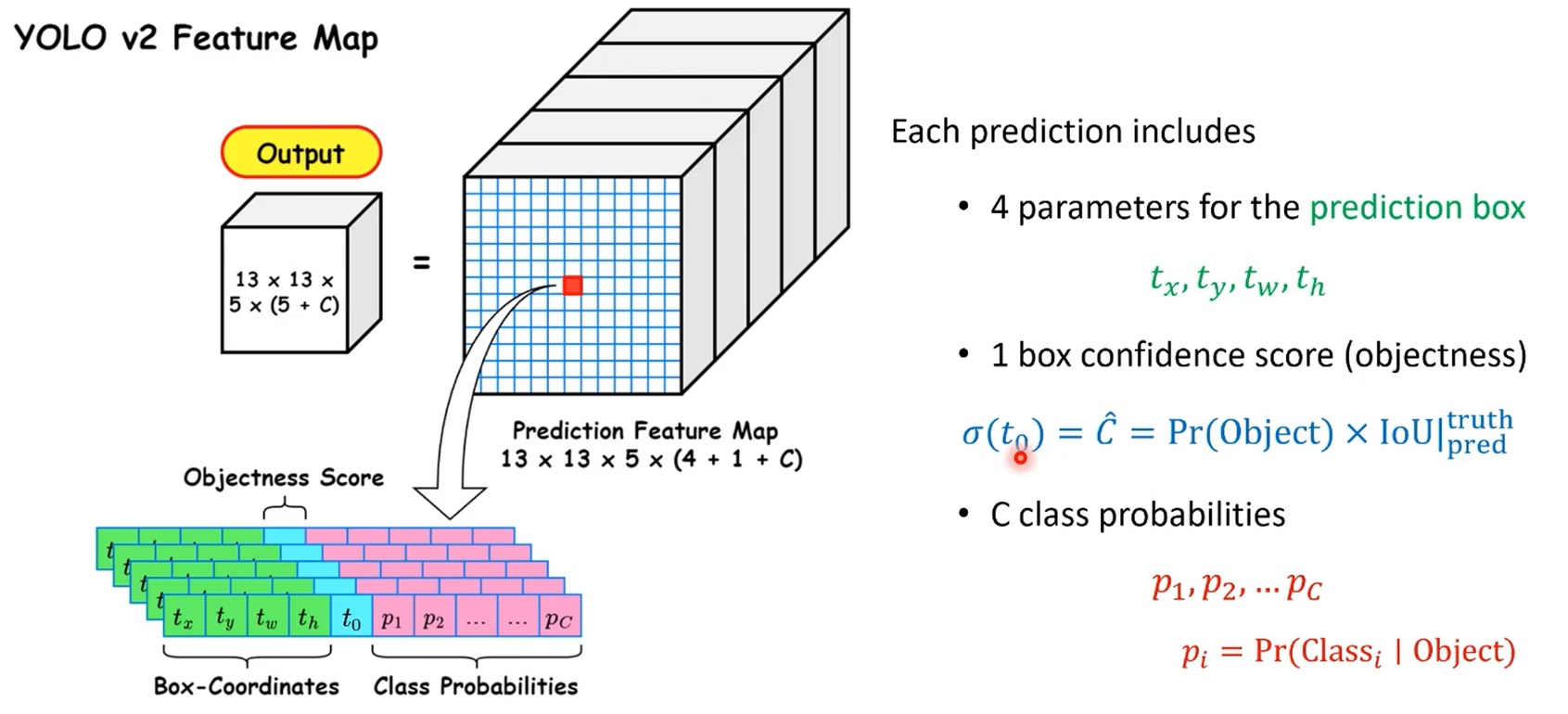
t x 、 t y t_x、t_y tx?、ty?是模型預測的中心坐標偏移量, t w 和 t h t_w和t_h tw?和th?是模型預測的寬度、高度的相對偏移量
yolov1和yolov2輸出對比
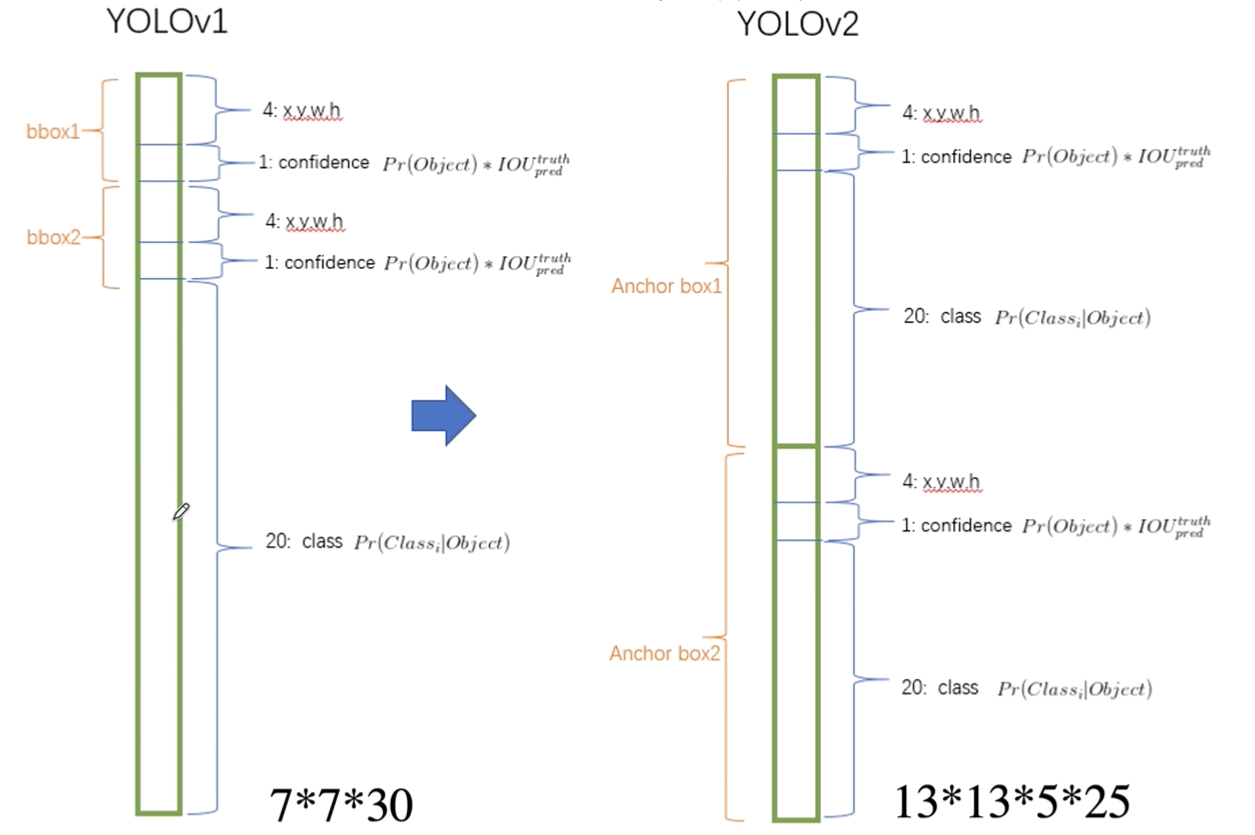
YOLOV1是通過模型直接預測位置和大小,這就帶來了一系列問題:
- 違背了YOLO的以格子為中心點的預測思想;
- 導致收斂很慢,模型很不穩定,尤其剛開始進行訓練的時候;
1.5.2 損失原理

yolov2損失,原論文沒有給具體損失函數,根據代碼和結合yolov1所得:
注意:下圖紫色為錨框的信息,紅色是預測框信息(這里是根據預測值由左邊的公式所得),綠色依舊為真實值

1.6 邊界框回歸
YOLOv2 不是直接預測邊界框的位置,而是預測相對于 Anchor Boxes 的偏移量。這意味著每個 Anchor Box 會預測一個小的偏移量,用以調整 Anchor Box 的位置和大小,使之更接近真實的目標框。
1.6.1 邊界框回歸
參考圖如下:
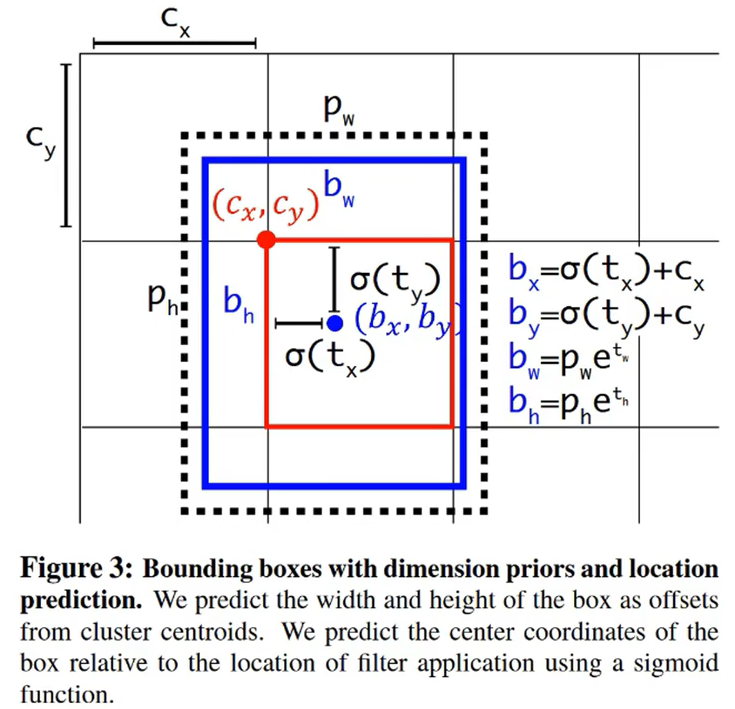
計算公式如下:
- t x 、 t y t_x、t_y tx?、ty?是網絡預測的中心坐標偏移量
- c x 、 c y c_x、c_y cx?、cy?是單元格與圖像左上角的偏移量
- σ \sigma σ是 Sigmoid 函數,用于將 t x 和 t y t_x和t_y tx?和ty?映射到 [0,1] 區間內
- b x 、 b y b_x、b_y bx?、by?是最終預測的邊界框中心坐標
- b w 和 b h b_w和b_h bw?和bh?是最終預測編輯框的大小
- p w 和 p h p_w和p_h pw?和ph?是 Anchor Box 的寬度和高度
- t w 和 t h t_w和t_h tw?和th?是寬度、高度的相對偏移量
公式如下:
b x = σ ( t x ) + c x b y = σ ( t y ) + c y b w = p w e t w b h = p h e t h \begin{aligned} &b_{x} =\sigma\left(t_x\right)+c_x \\ &b_{y} =\sigma\left(t_y\right)+c_y \\ &b_{w} =p_we^{t_w} \\ &b_{h} =p_he^{t_h} \end{aligned} ?bx?=σ(tx?)+cx?by?=σ(ty?)+cy?bw?=pw?etw?bh?=ph?eth??
這樣我們就可以保證,中心坐標點不會飄出整個框。
例子參考如下:
例如預測值: ( σ ( t x ) , σ ( t y ) , t w , t h ) = ( 0.2 , 0.1 , 0.2 , 0.32 ) , a n c h o r 框為: p w = 3.19275 , p h = 4.00944 在特征圖位置: b x = 0.2 + 1 = 1.2 b y = 0.1 + 1 = 1.1 b w = 3.19275 ? e 0.2 = 3.89963 b h = 4.00944 ? e 0.32 = 5.52151 \begin {aligned} \text{例如預測值:} \\ &(\sigma\left(t_x\right), \sigma\left(t_y\right), t_w, t_h) =(0.2,0.1,0.2,0.32),\\ &{anchor框為:}p_{w}=3.19275,p_{h}=4.00944 \\ \\ \text{在特征圖位置:} \\ &b_{x}=0.2+1=1.2\\ &b_{y}=0.1+1=1.1\\ &b_{w}=3.19275*e^{0.2}=3.89963\\ &b_{h}=4.00944*e^{0.32}=5.52151 \\ \end{aligned} 例如預測值:在特征圖位置:?(σ(tx?),σ(ty?),tw?,th?)=(0.2,0.1,0.2,0.32),anchor框為:pw?=3.19275,ph?=4.00944bx?=0.2+1=1.2by?=0.1+1=1.1bw?=3.19275?e0.2=3.89963bh?=4.00944?e0.32=5.52151?
1.6.2 坐標映射
在畫候選框的時候需要映射到原始圖片:13 × 32 = 416
在原圖中的位置: b x = 1.2 ? 32 = 38.4 b y = 1.1 ? 32 = 35.2 b w = 3.89963 ? 32 = 124.78 b h = 5.52151 ? 32 = 176.68 \begin {aligned} \text{在原圖中的位置:} \\ &b_{x} =1.2*32=38.4 \\ & b_{y} =1.1*32=35.2 \\ &b_{w} =3.89963*32=124.78 \\ &b_{h} =5.52151*32=176.68 \end{aligned} 在原圖中的位置:?bx?=1.2?32=38.4by?=1.1?32=35.2bw?=3.89963?32=124.78bh?=5.52151?32=176.68?
1.7 特征融合
最后一層時感受野太大了,小目標可能丟失了,需融合之前的特征。
id=16的conv層與id=22的conv層進行passthrough,用于提升小目標檢測精度。
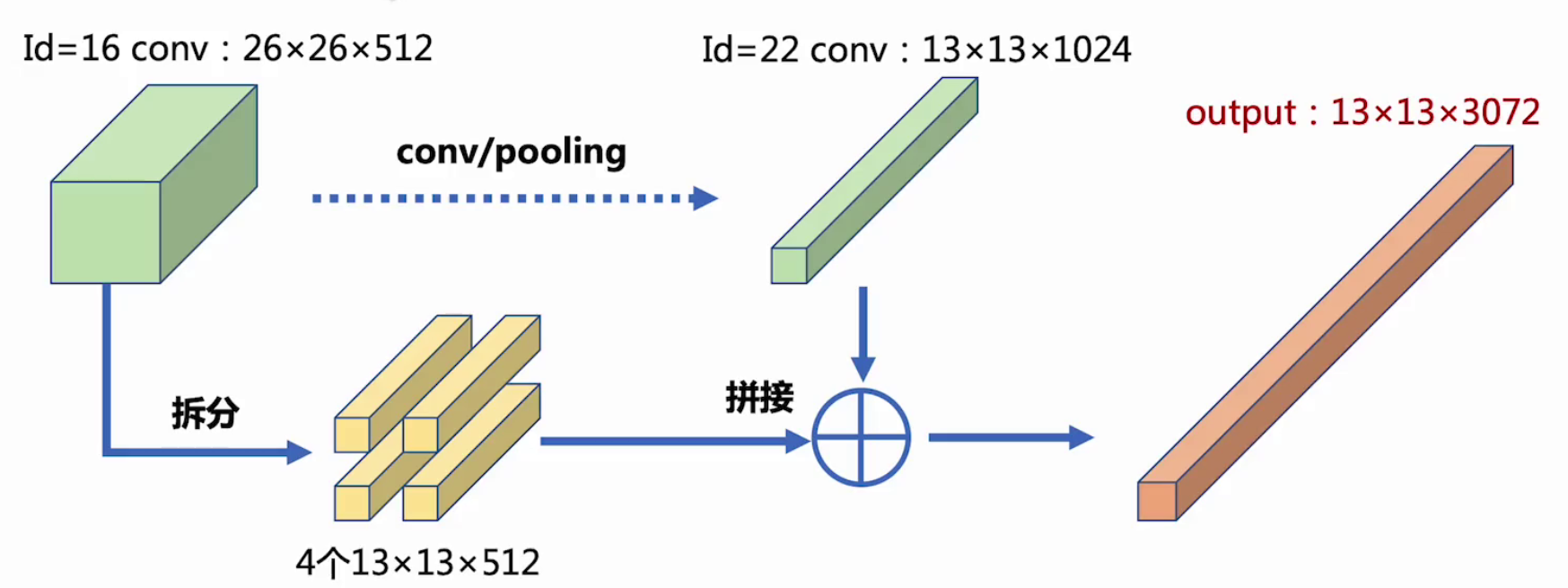
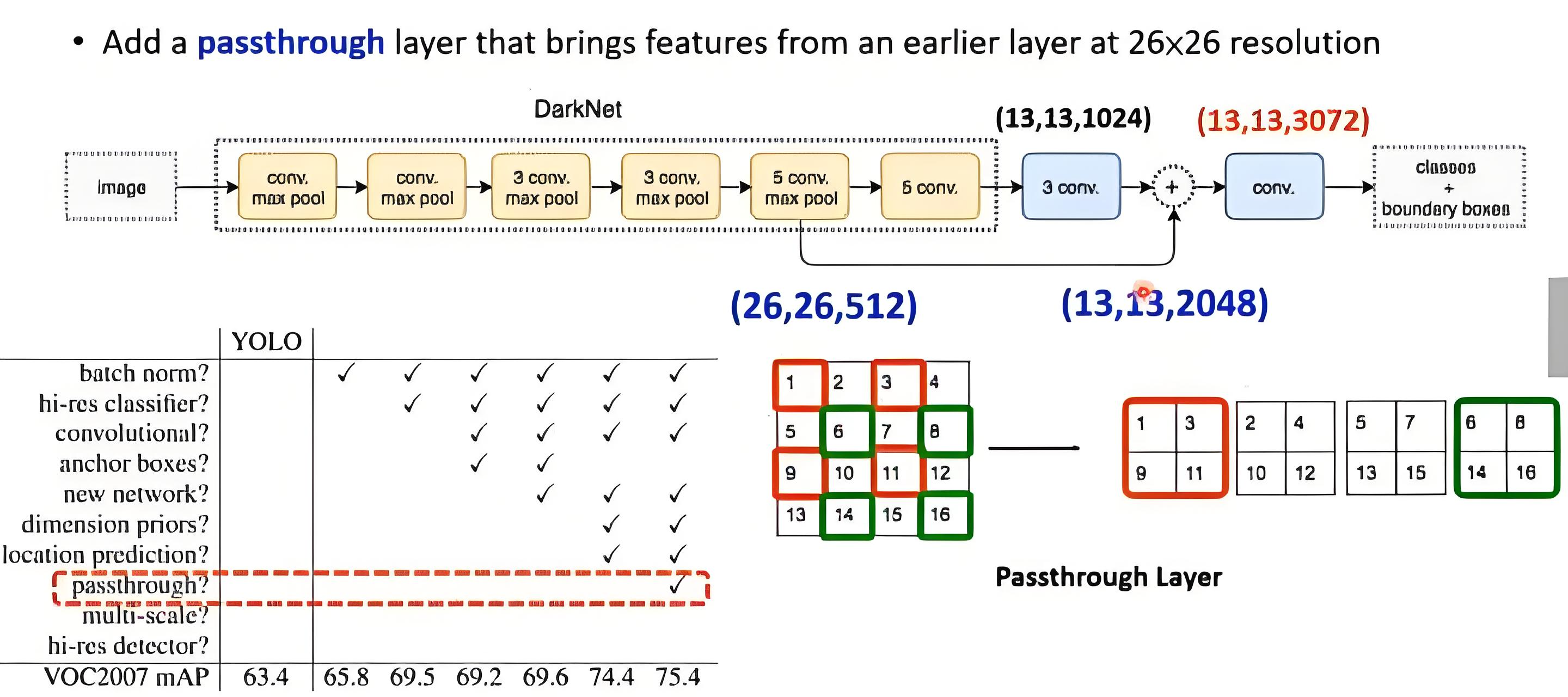
1.7 訓練策略優化
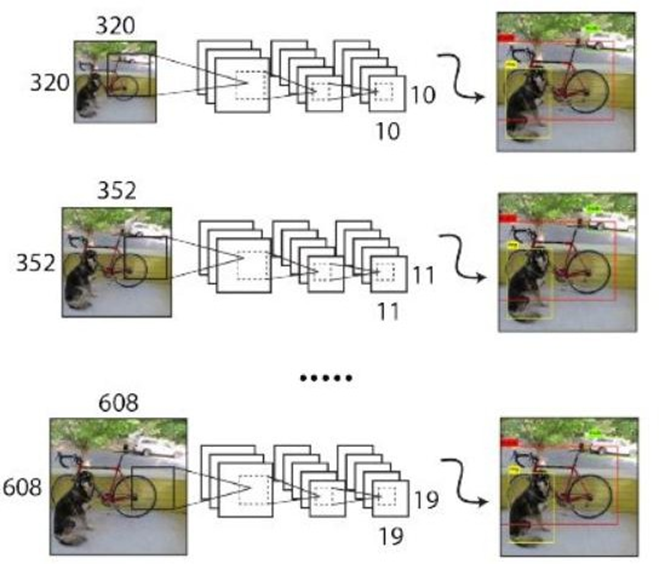
采用多尺度訓練方法:
-
先用224*224對主干網絡進行預訓練,再用448 x 448對主干網絡進行微調(10輪)
-
設計了416 x 416和544 x 544兩種輸入尺寸的網絡
-
由于沒有FC層,可輸入任意尺寸圖像,整個網絡下采樣倍數是32,共有320、352、384、416、448、…、608等10種輸入圖像尺寸,每10個batch就隨機更換一種尺寸
2. 性能對比
這里簡單的看下就行了,實際主要還是和V1對比

六、YOLOV3
原作者做完V3就退出了。
論文地址:
? https://arxiv.org/pdf/1804.02767.pdf
1. 一圖表意圖
略微有點過分,但是沒有針對任何人的意思~~~
2. 優化的點
- 改進網絡結構,使其更適合小目標檢測
- 特征做的更細致,融入多特征圖信息來預測不同規格物體
- 更豐富的先驗框,3種scale,每種3個規格,共9種
- softmax改進,預測多標簽任務
3. 網絡結構
3.1 主干網絡
YOLOV3主干結構采用darknet-53。
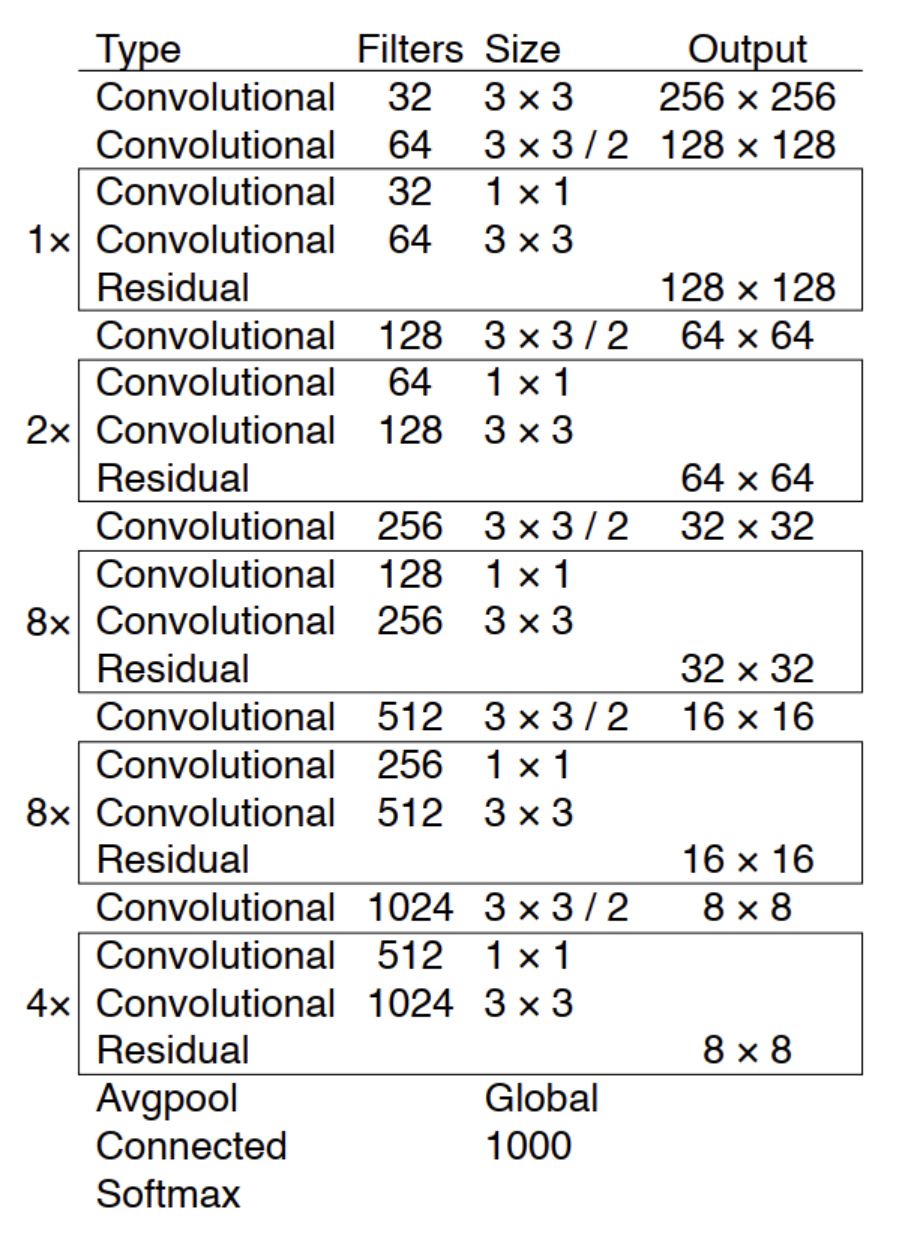
沒有池化和FC,尺寸變換是通過Stride實現的,簡單粗暴效果好!
3.2 整體結構
整體網絡基本融合了當下幾種優秀套路~
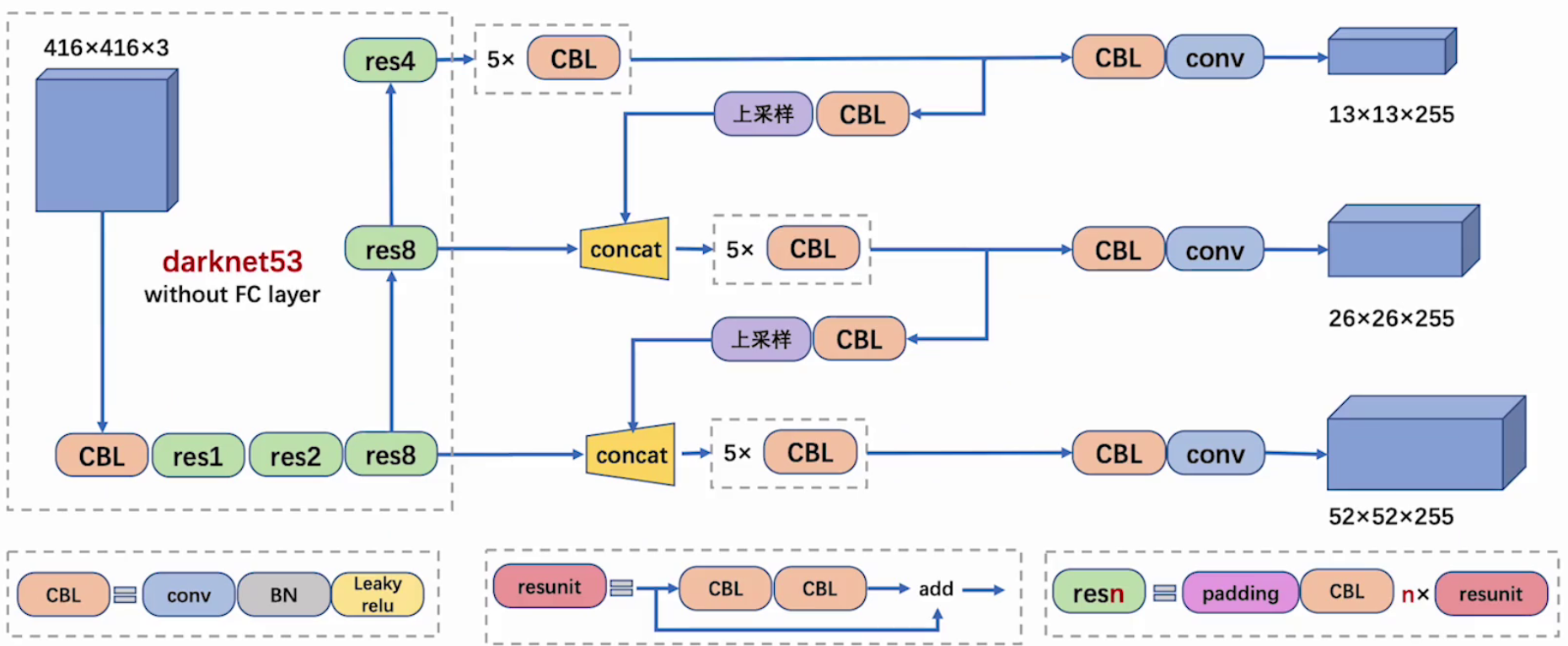
有4個坐標變換系數( t x , t y , t w , t h t_x, t_y, t_w, t_h tx?,ty?,tw?,th?)+置信度+類別概率,使用1 x 1卷積預測,通道數=3 x (4+1+80) = 255
3.3 特征輸出
特征圖尺寸越小,感受野越大,他們分別適配不同大小的目標;
-
52 × 52感受野更小,更適合檢測小目標;
-
13 × 13感受野更大,更適合檢測大目標;

參考下面的圖可知: 255 = 3 × (1 + 4 + 80)
3.4 特征融合
3.4.1 FPN
Feature Pyramid Networks for Object Detection
用于目標檢測的特征金字塔網絡
先觀察下面四張圖:
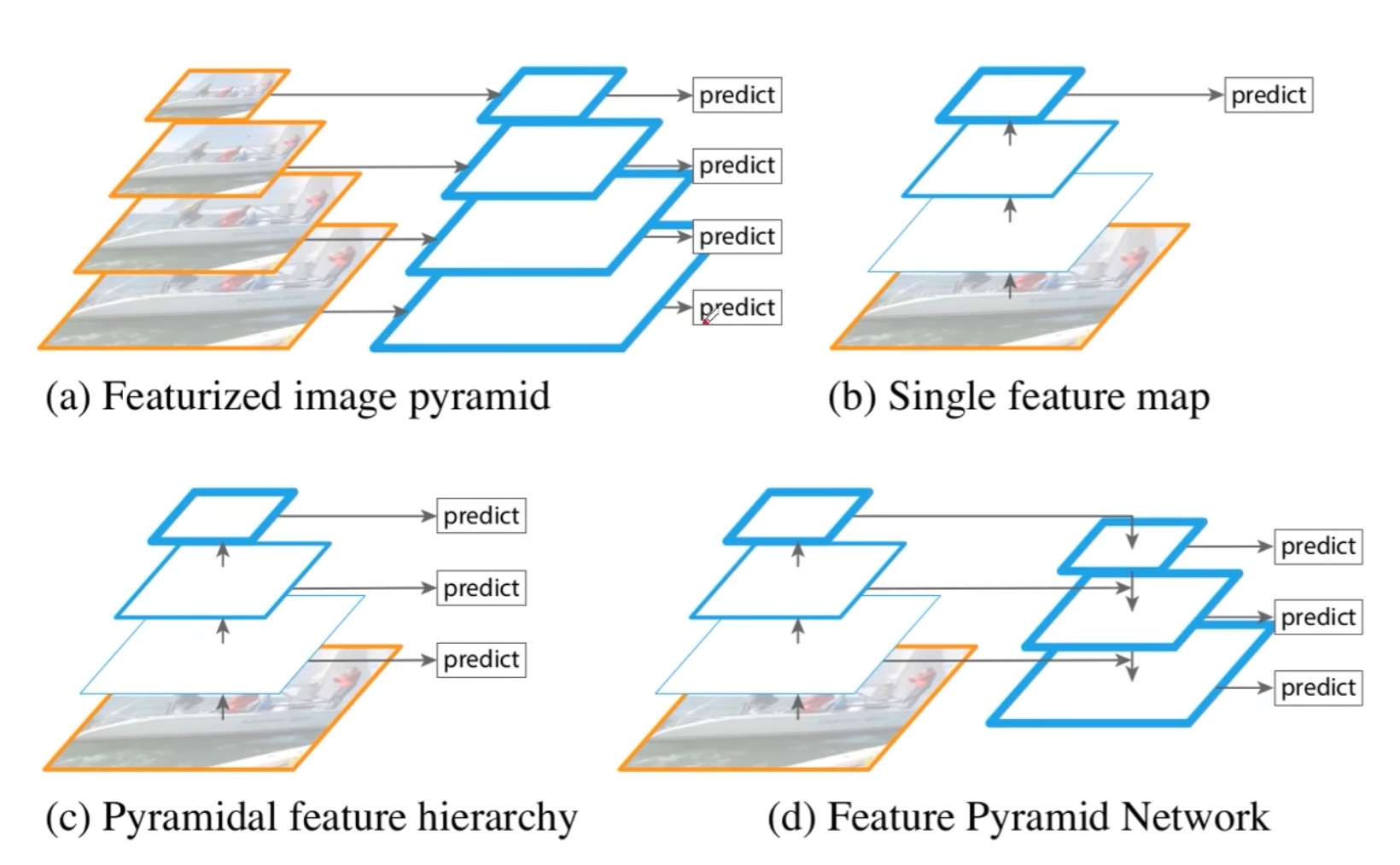
-
圖a:特征化圖像金字塔
①、當我們要檢測不同的尺度目標時,需要把圖像送入不同的尺度
②、需要根據不同的尺度圖片一次進行預測
③、需要多少個不同尺度就需要預測多少次,效率較低
-
圖b:單特征映射
①、得到一個特征圖并進行預測
②、特征丟失,對于小目標效果不好;
-
圖c:金字塔特征層次結構
①、把圖像傳給backbone,在傳播的過程中分別進行預測
②、相互之間獨立,特征沒有得到充分利用
-
圖d:特征金字塔網絡
①、不是簡單的不同特征圖上進行預測
②、會對不同的特征圖進行融合后進行預測
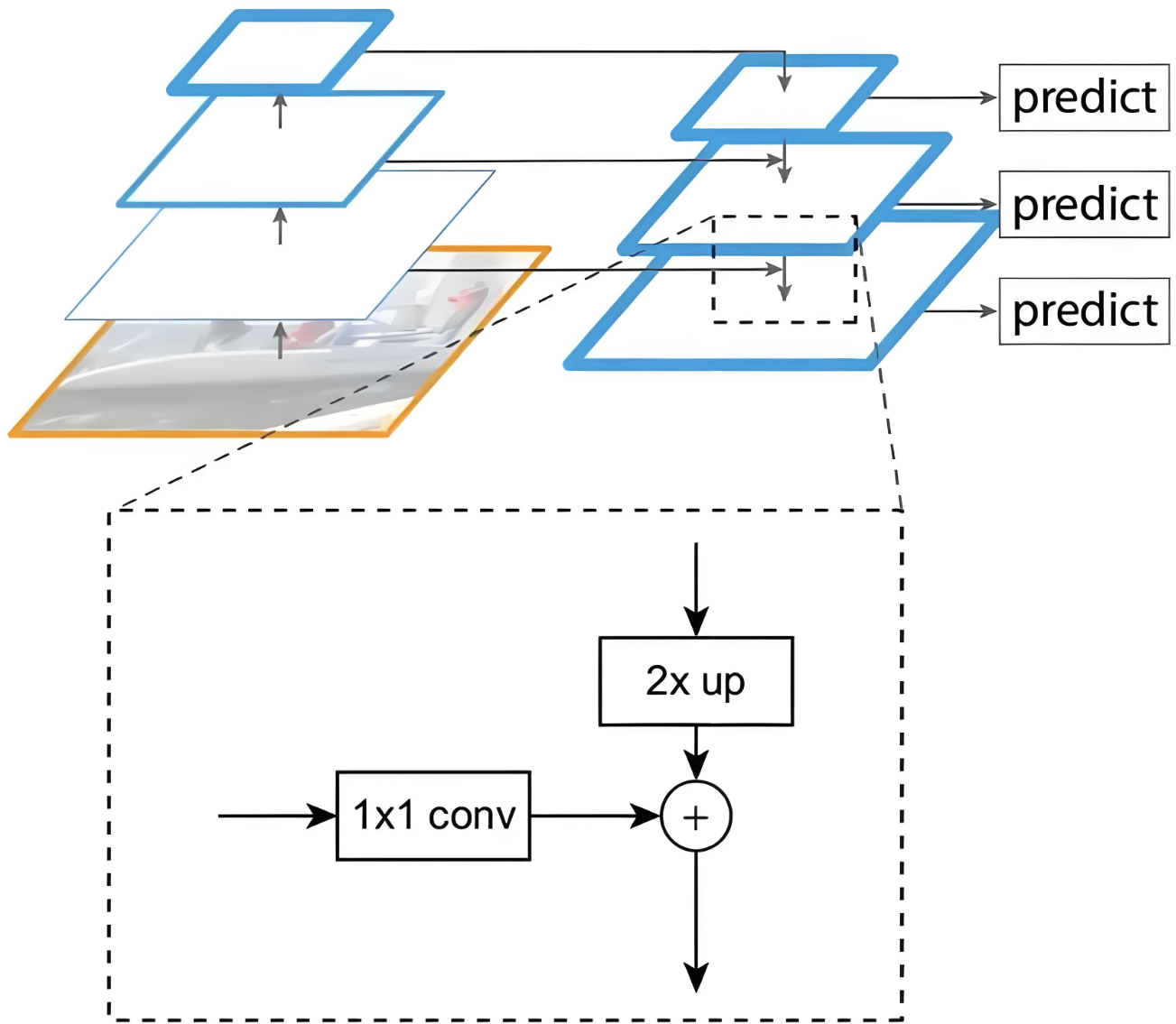
3.4.2 FPN融合細節
融合細節如下圖:藝高者膽大
-
1 × 1卷積完成channel的一致性
-
2 × up完成尺寸的一致性
-
這樣就可以進行特征相加了
3.4.3 整體結構
通過整體結構去更好的理解FPN的特征融合過程:
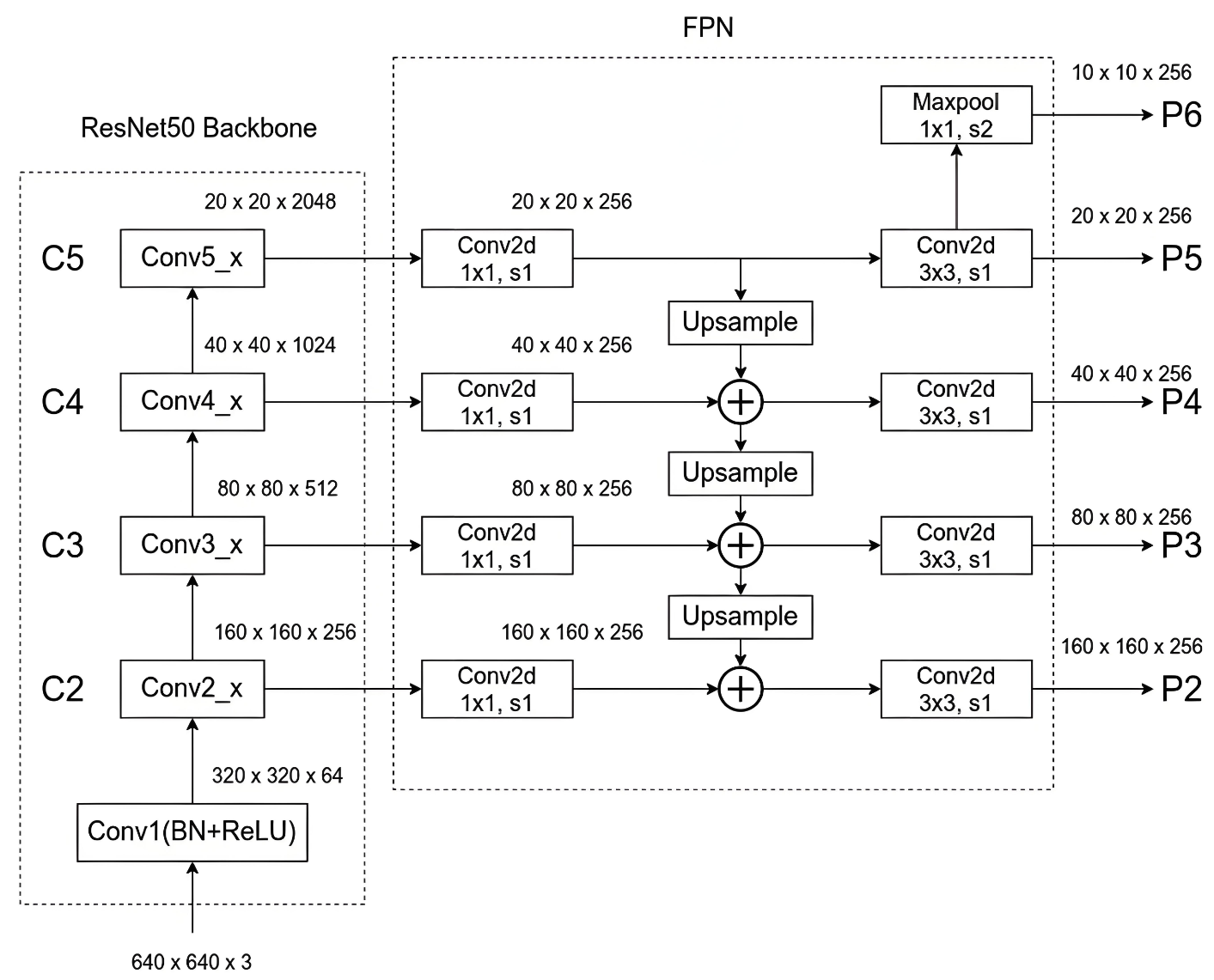
3.5 先驗框優化
共設計了9種先驗框:
- 13×13特征圖上:(116 × 90),(156 × 198),(373 × 326)
- 26×26特征圖上:(30 × 61),(62 × 45),(59 × 119)
- 52×52特征圖上:(10 × 13),(16 × 30),(33 × 23)

-
預選框個數:
**YOLOV2: **13 x 13 x 5=845個預測框
YOLOV3:(13 x 13+26 x 26+52 x 52) x 3=10647個利用閾值過濾掉置信度低于閾值的預選框。
每個cell同樣最終只預測一個結果,取置信度最大的。
4. 損失函數
4.1 softmax替代
YOLOV3在預測類別時采用了logistic regression,每個類別單獨使用二分類的logistic回歸,而不是softmax;
我們這里假設為二分類:
i f y = 1 : p ( y ∣ x ) = y ^ if ? y = 0 : p ( y ∣ x ) = 1 ? y ^ 聯合起來: p ( y ∣ x ) = y ^ y ( 1 ? y ^ ) ( 1 ? y ) 展開并取對數如下:預測為正樣本的損失加上預測為負樣本的損失 log ? p ( y ∣ x ) = ylog ( y ^ ) + ( 1 ? y ) log ? ( 1 ? y ^ ) = ? L ( y ^ , y ) \begin{aligned} &\mathrm{if}\quad y=1:\quad p(y\mid x)=\hat{y} \\ &\operatorname{if} \quad y=0:\quad p(y\mid x)=1-\hat{y} \\ 聯合起來: \\ &p(y\mid x)=\hat{y}^y(1-\hat{y})^{(1-y)} \\ 展開并取對數如下:預測為正樣本的損失加上預測為負樣本的損失 \\ &\log p(y\mid x)=\text{ylog}(\hat{y})+(1-y)\log(1-\hat{y})=-L(\hat{y},y) \end{aligned} 聯合起來:展開并取對數如下:預測為正樣本的損失加上預測為負樣本的損失?ify=1:p(y∣x)=y^?ify=0:p(y∣x)=1?y^?p(y∣x)=y^?y(1?y^?)(1?y)logp(y∣x)=ylog(y^?)+(1?y)log(1?y^?)=?L(y^?,y)?
4.2 整體損失函數
L o s s = λ c o o r d ∑ i = 0 S 2 ∑ j = 0 B I i j o b j [ ( x i ? x ^ i j ) 2 + ( y i ? y ^ i j ) 2 ] + λ c o o r d ∑ i = 0 S 2 ∑ j = 0 B I i j o b j [ ( w i j ? w ^ i j ) 2 + ( h i j ? h ^ i j ) 2 ] + ∑ i = 0 S 2 ∑ j = 0 B I i j o b j [ C ^ i j log ? ( C i j ) + ( 1 ? C ^ i j ) log ? ( 1 ? C i j ) ] + λ n o o b j ∑ i = 0 S 2 ∑ j = 0 B I i j n o o b j [ C ^ i j log ? ( C i j ) + ( 1 ? C ^ i j ) log ? ( 1 ? C i j ) ] + ∑ i = 0 S I i j o b j ∑ c ∈ c l a s s e s ( [ P ^ i j log ? ( P i j ) + ( 1 ? P ^ i j ) log ? ( 1 ? P i j ) ] \begin{gathered} Loss=\lambda_{coord}\sum_{i=0}^{S^2}\sum_{j=0}^BI_{ij}^{obj}[(x_i-\hat{x}_i^j)^2+(y_i-\hat{y}_i^j)^2]+ \\ \lambda_{coord}\sum_{i=0}^{S^{2}}\sum_{j=0}^{B}I_{ij}^{obj}[(\sqrt{w_{i}^{j}}-\sqrt{\hat{w}_{i}^{j}})^{2}+(\sqrt{h_{i}^{j}}-\sqrt{\hat{h}_{i}^{j}})^{2}]+ \\ \sum_{i=0}^{S^2}\sum_{j=0}^BI_{ij}^{obj}[\hat{C}_i^j\log(C_i^j)+(1-\hat{C}_i^j)\log(1-C_i^j)]+ \\ \lambda_{noobj}\sum_{i=0}^{S^{2}}\sum_{j=0}^{B}I_{ij}^{noobj}[\hat{C}_{i}^{j}\log(C_{i}^{j})+(1-\hat{C}_{i}^{j})\log(1-C_{i}^{j})] +\\ \sum_{i=0}^{S}I_{ij}^{obj}\sum_{c\in classes}([\hat{P}_{i}^{j}\log(P_{i}^{j})+(1-\hat{P}_{i}^{j})\log(1-P_{i}^{j})] \end{gathered} Loss=λcoord?i=0∑S2?j=0∑B?Iijobj?[(xi??x^ij?)2+(yi??y^?ij?)2]+λcoord?i=0∑S2?j=0∑B?Iijobj?[(wij???w^ij??)2+(hij???h^ij??)2]+i=0∑S2?j=0∑B?Iijobj?[C^ij?log(Cij?)+(1?C^ij?)log(1?Cij?)]+λnoobj?i=0∑S2?j=0∑B?Iijnoobj?[C^ij?log(Cij?)+(1?C^ij?)log(1?Cij?)]+i=0∑S?Iijobj?c∈classes∑?([P^ij?log(Pij?)+(1?P^ij?)log(1?Pij?)]?
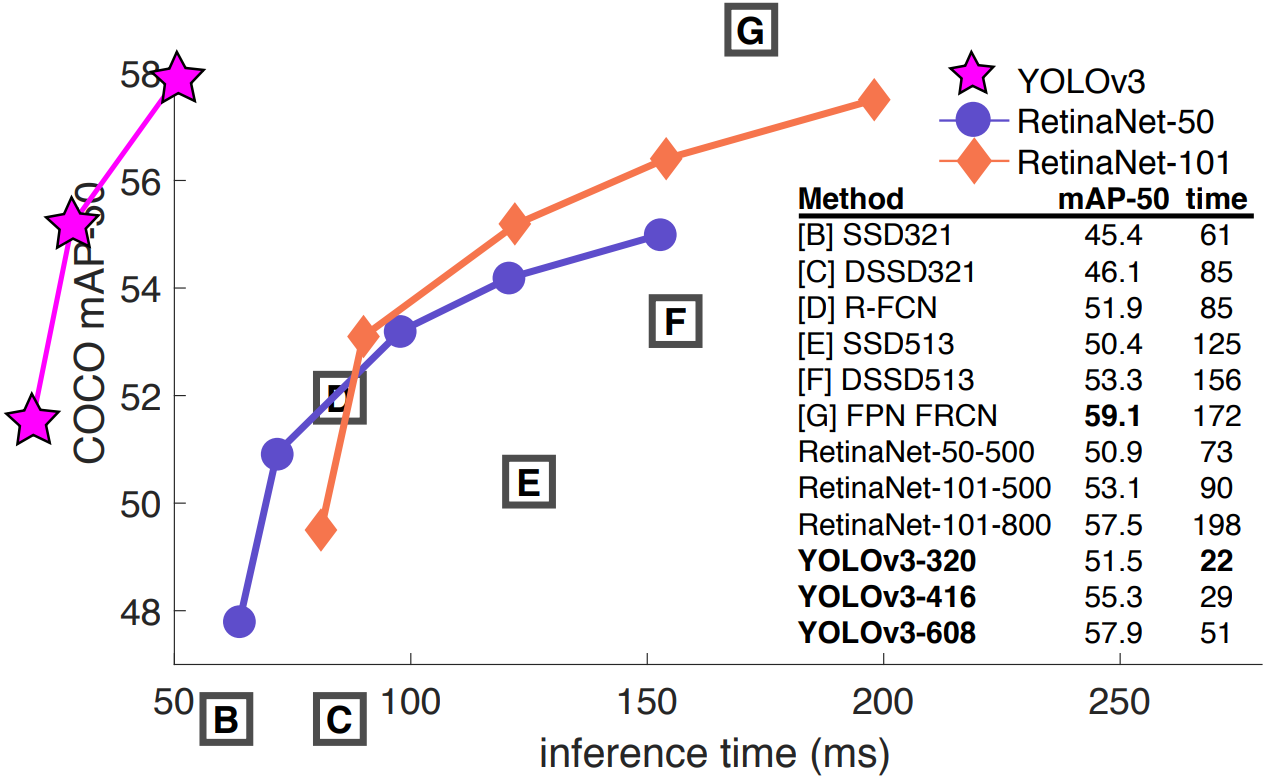
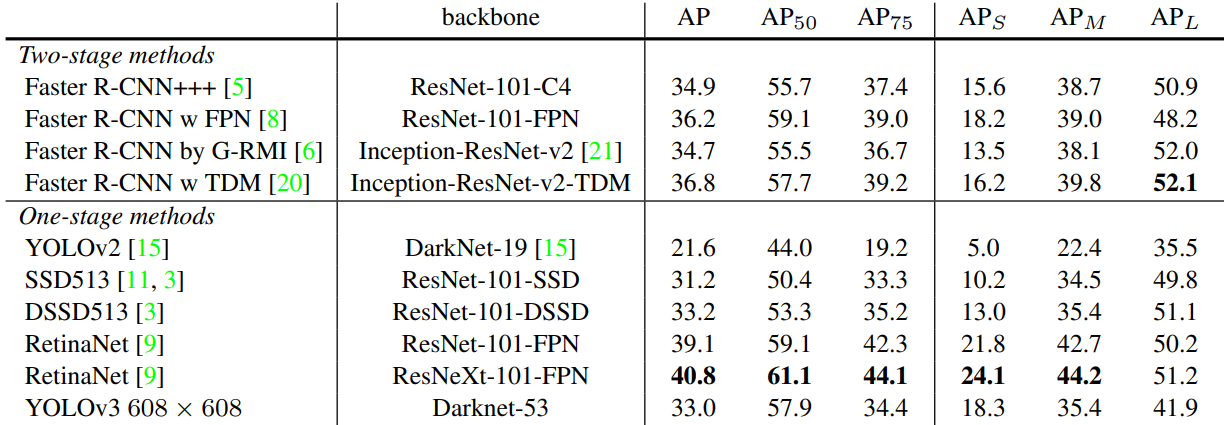
5. 性能對比
整體來看,YOLOV3性能整體比YOLOV2優秀~~
- AP50:IoU 閾值為 0.5 時的 AP 測量值
- AP75:IoU 閾值為 0.75 時的 AP 測量值
- APs:對于小目標的 AP 值
- APm:對于中等目標的 AP 值
- APL:對于大目標的 AP 值
)




)













