引言:
書接上回,如果說類和對象(上)是入門階段,類和對象(中)是中間階段,那么這次的類和對象(下)就可以當做類和對象的補充及收尾。
一:再探構造函數
- 之前我們實現構造函數時,初始化成員變量主要使用函數體內賦值,構造函數初始化還有一種方式,就是初始化列表,初始化列表的使用方式是以一個冒號開始,接著是一個以逗號分隔的數據成員列表,每個"成員變量"后面跟一個放在括號中的初始值或表達式。
- 每個成員變量在初始化列表中只能出現一次,語法理解上初始化列表可以認為是每個成員變量定義初始化的地方。
- 引用成員變量,
const成員變量,沒有默認構造的類類型變量,必須放在初始化列表位置進行初始化,否則會編譯報錯。 - C++11支持在成員變量聲明的位置給缺省值,這個缺省值主要是給沒有顯示在初始化列表初始化的成員使用的。
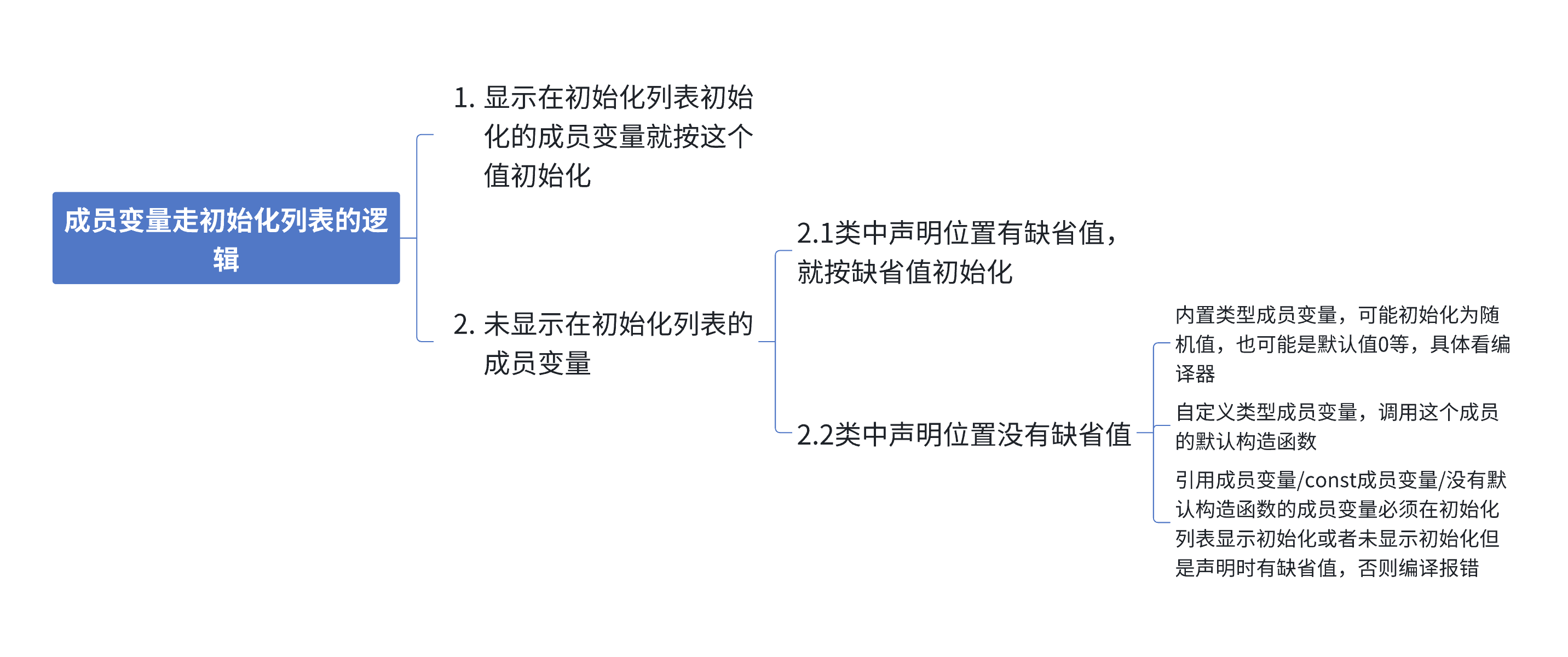
- 盡量使用初始化列表初始化,因為那些你不在初始化列表初始化的成員也會走初始化列表,如果這個成員在聲明位置給了缺省值,初始化列表會用這個缺省值初始化。如果你沒有給缺省值,對于沒有顯示在初始化列表初始化的內置類型成員是否初始化取決于編譯器,C++并沒有規定。對于沒有顯示在初始化列表初始化的自定義類型成員會調用這個成員類型的默認構造函數,如果沒有默認構造會編譯錯誤。
- 初始化列表中按照成員變量在類中聲明順序進行初始化,跟成員在初始化列表出現的的先后順序無關。建議聲明順序和初始化列表順序保持一致。
場景一:初始化列表形式


解讀:這里我們雖然在初始化列表中沒有對_day初始化,但是在聲明中給了缺省值,所以這時在初始化列表中就會拿其缺省值來進行初始化。
這里需要注意的是聲明這里只是給缺省值,并不是初始化。
場景二:自定義類型的初始化列表
在C++中規定,如果自定義類型的成員沒有默認構造函數,這時候自定義類型就需要自己來寫構造函數,而且如果成員還是類類型的變量就必須用初始化列表來初始化。
這里我們拿之前的stack和Myqueue 來舉例子:
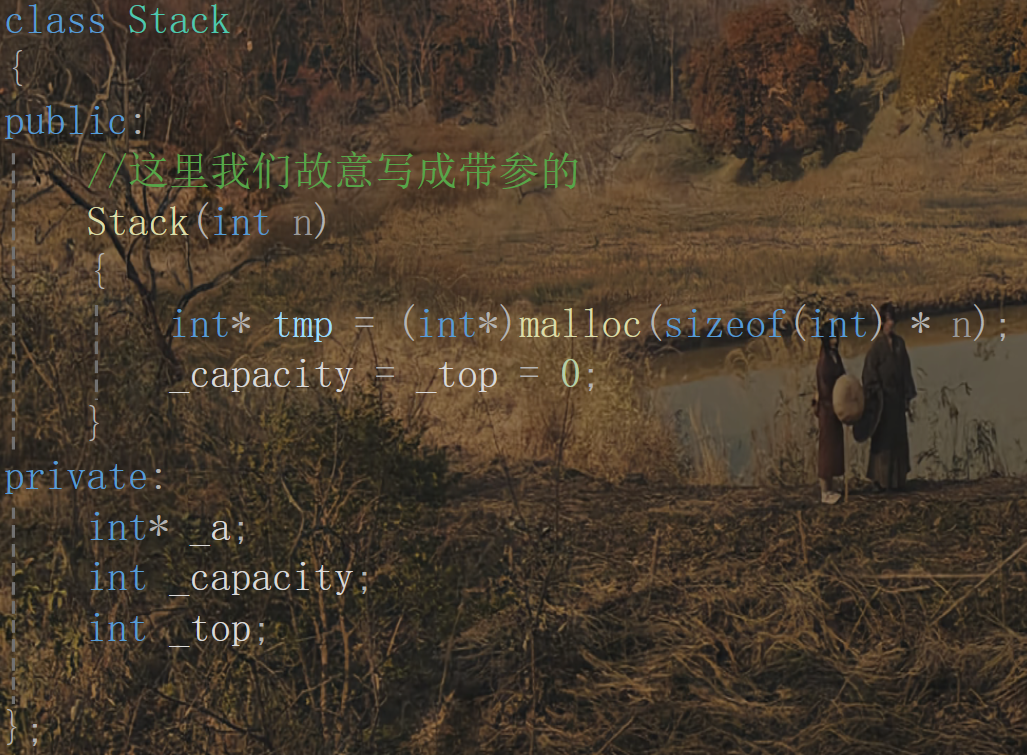
這里Stack的構造函數我們故意顯示的寫成帶參的,這樣編譯器就不會再生成構造函數,這時Stack就是沒有默認構造函數的。

這里可以看到這里在創建Myqueue類型的對象時就無法初始化,那么這時候就需要自己來寫構造函數,但是這里怎么初始化呢?沒法寫啊,這里就需要用到初始化列表:
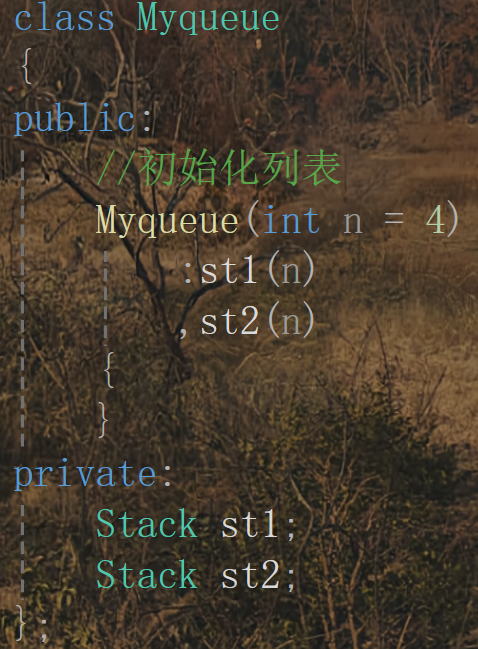
這樣就可以實現自定義類型中類類型成員的初始化了。
牛刀小試:
下面這個程序的運行結果?

解析:由于初始化列表在初始化時是按照成員的聲明順序進行初始化的,所以這里是先初始化_a2 ,但是這時_a1還是一個隨機值,因此_a2被初始化為了隨機值,接著再拿1來初始化_a1,所以_a1為1,_a2為隨機值。
下面我們運行程序來驗證一下:
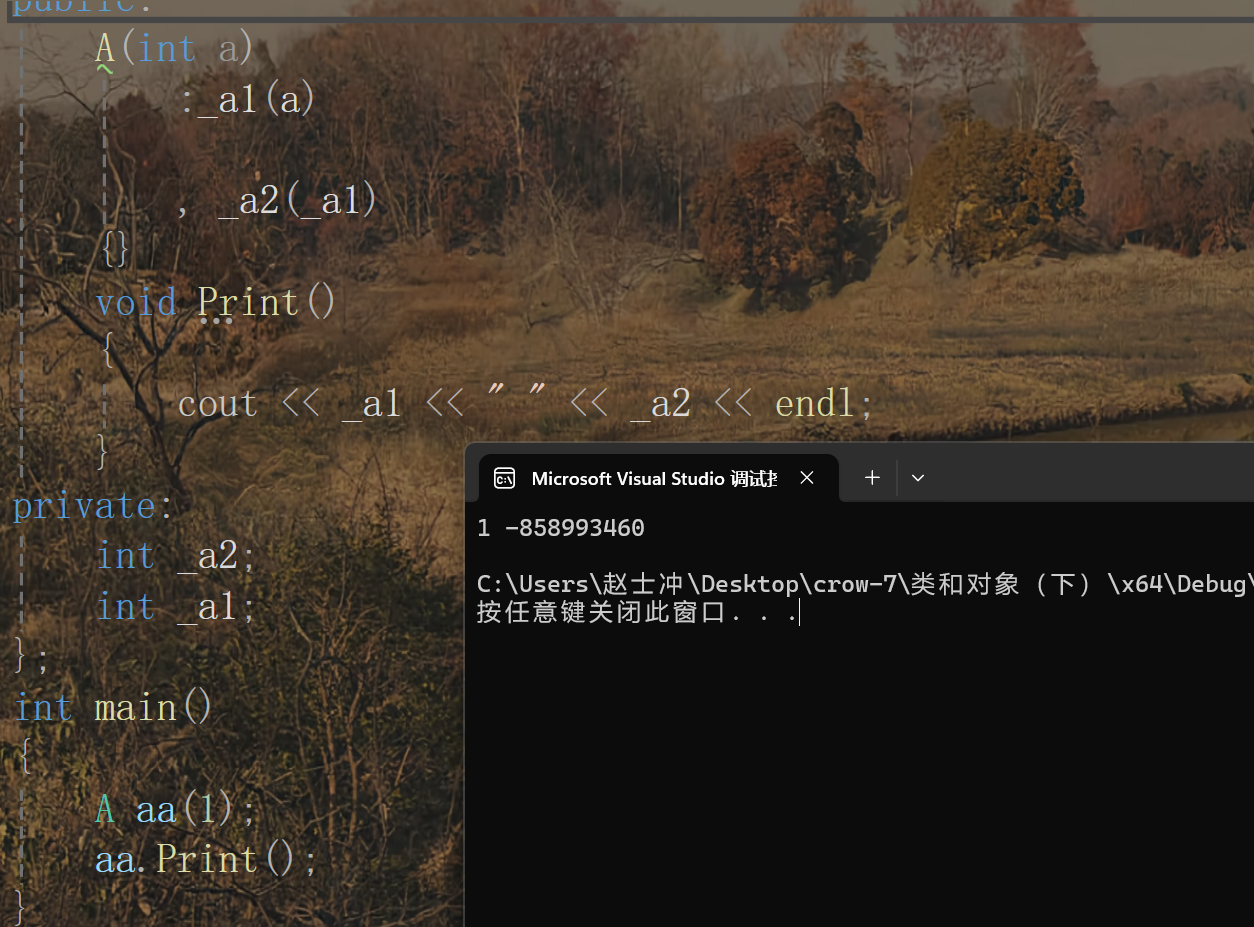
和我們分析的一樣。
小結:成員變量走初始化列表的邏輯
- 無論是否顯示寫初始化列表,每個構造函數都有初始化列表。
- 無論是否在初始化列表顯示初始化成員變量,每個成員變量都要走初始化列表初始化。
二:類型轉換
- C++支持內置類型隱式類型轉換為類類型對象,但是需要有相關內置類型為參數的構造函數。
- 構造函數前面加
explicit就不再支持隱式類型轉換。 - 類類型的對象之間也可以隱式轉換,需要相應的構造函數支持。
場景一:內置類型轉類類型對象

這是我們寫的一個類A
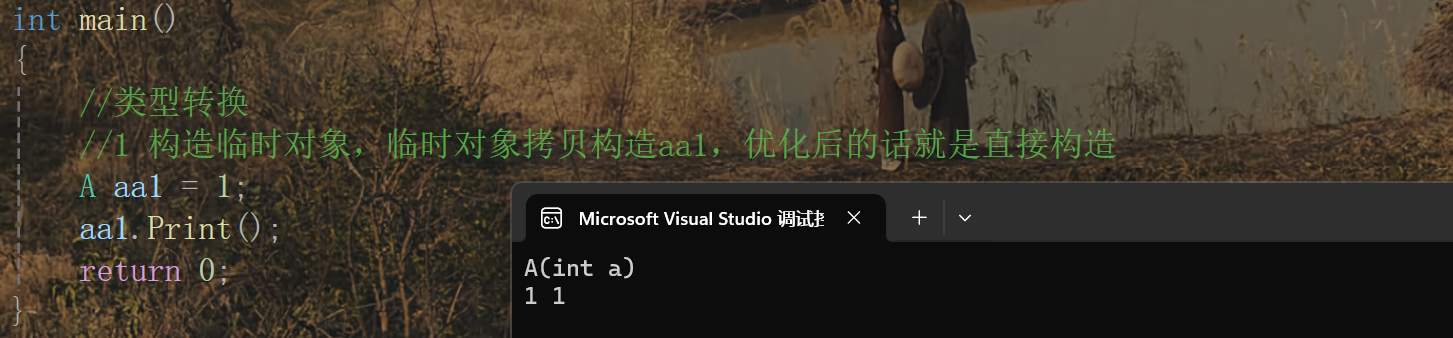
這里就是類型轉換的一個場景,并且可以看到編譯器對其進行了優化,省去了拷貝構造這一步驟。
場景二:對類型轉換臨時對象的引用
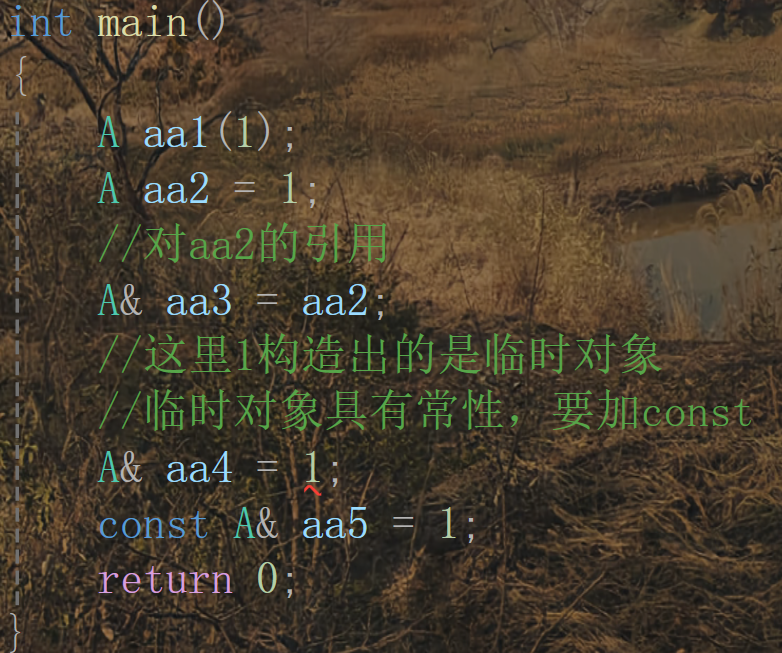
場景三:多參數轉換
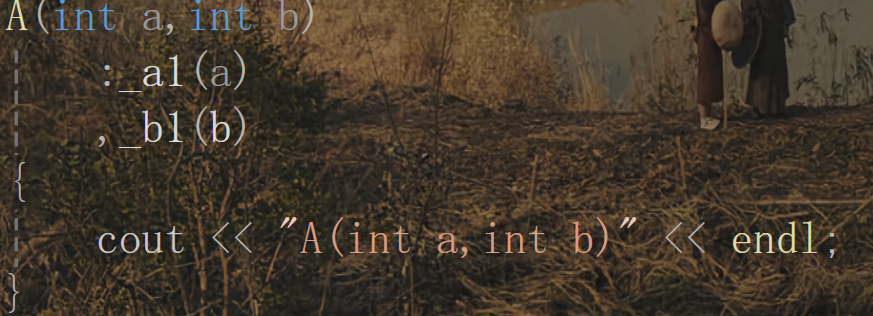
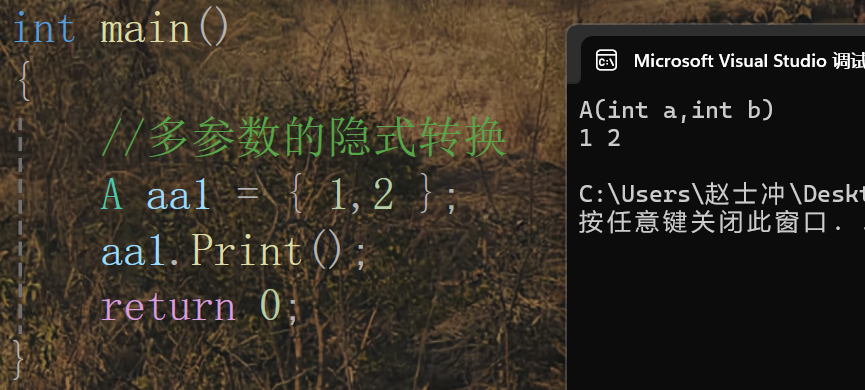
注:C++11之后才支持的多參數的類型轉換。
場景四:類類型對象的隱式轉換

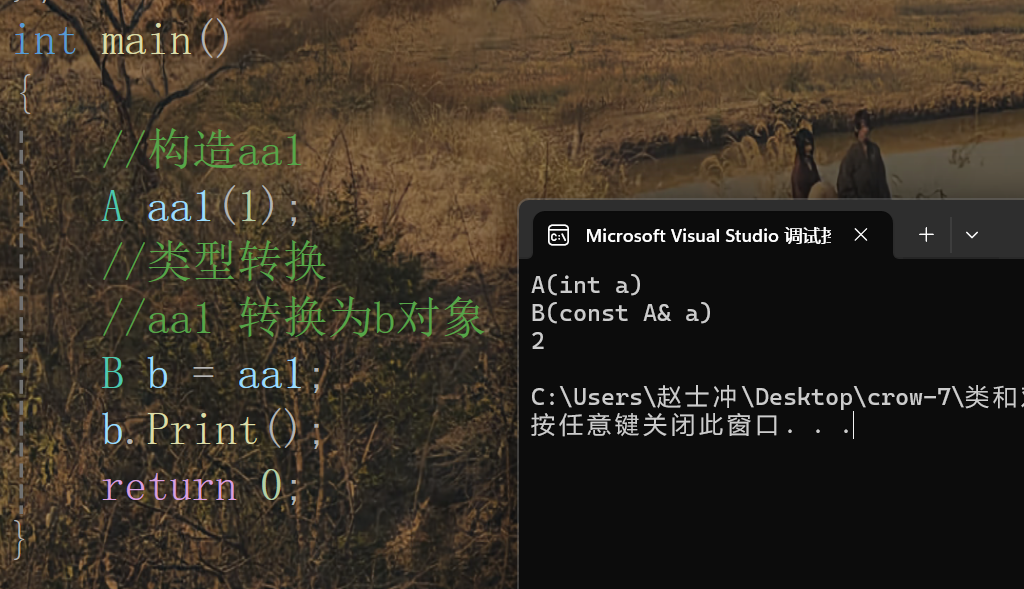
場景五:explicit 來禁用隱式類型轉換


這里我們對單參數的那個構造函數加了explicit來修飾,所以單參數的隱式類型轉換就不支持了,但是兩個參數的隱式類型轉換還是支持的。
小結:
- 如果想用隱式類型轉換,需要有對應的內置類型為參數的構造函數來支持。
- 對于這個過程是否優化,取決于具體的編譯器。
三:static成員
- 用
static修飾的成員變量,稱之為靜態成員變量,靜態成員變量一定要在類外進行初始化。 - 靜態成員變量為所有類對象所共享,不屬于某個具體的對象,不存在對象中,存放在靜態區。
- 用
static修飾的成員函數,稱之為靜態成員函數,靜態成員函數沒有this指針。 - 靜態成員函數中可以訪問其他的靜態成員,但是不能訪問非靜態的,因為沒有
this指針。 - 非靜態的成員函數,可以訪問任意的靜態成員變量和靜態成員函數。
- 突破類域就可以訪問靜態成員,可以通過
類名::靜態成員或者對象.靜態成員來訪問靜態成員變量和靜態成員函數。 - 靜態成員也是類的成員,受
public、protected、private訪問限定符的限制。 - 靜態成員變量不能在聲明位置給缺省值初始化,因為缺省值是個構造函數初始化列表的,靜態成員變量不屬于某個對象,不走構造函數初始化列表。
場景一:統計編譯器創建了多少類

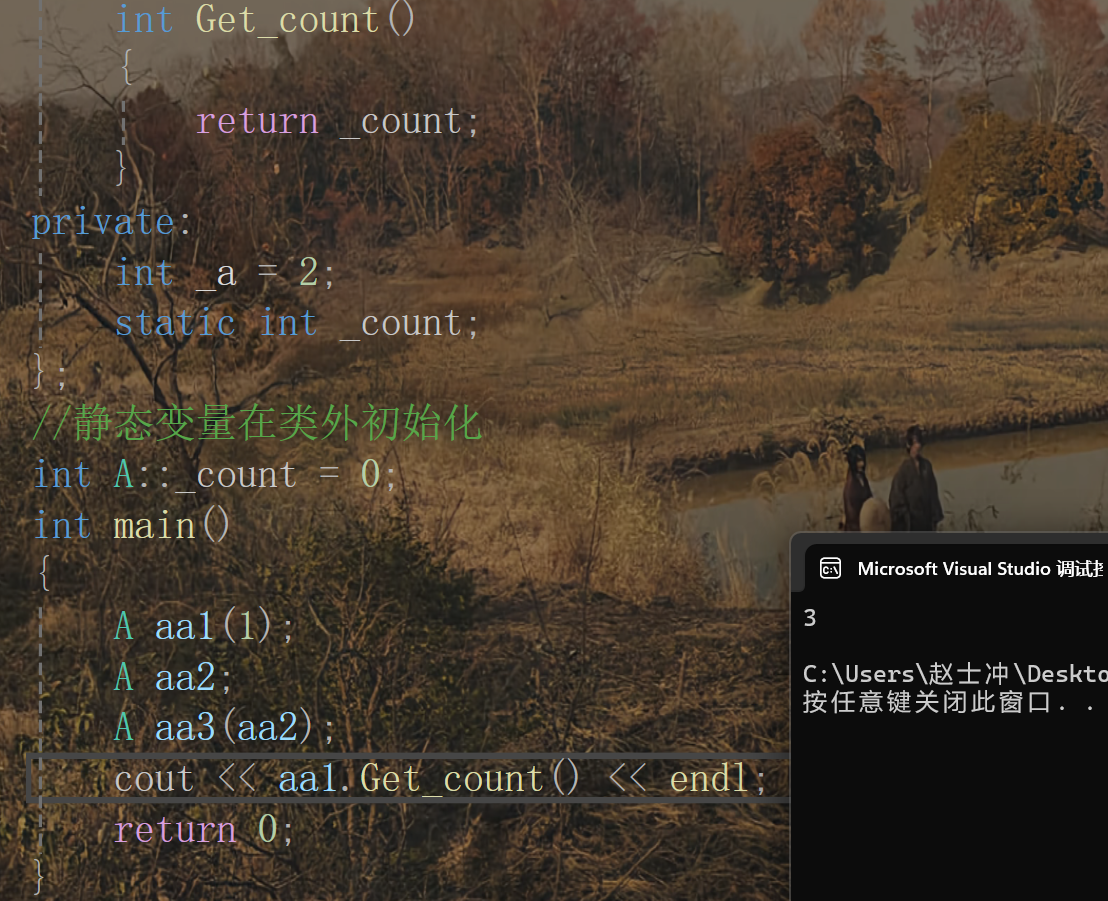
可以看到是創建了三個類。
場景二:解決特殊問題
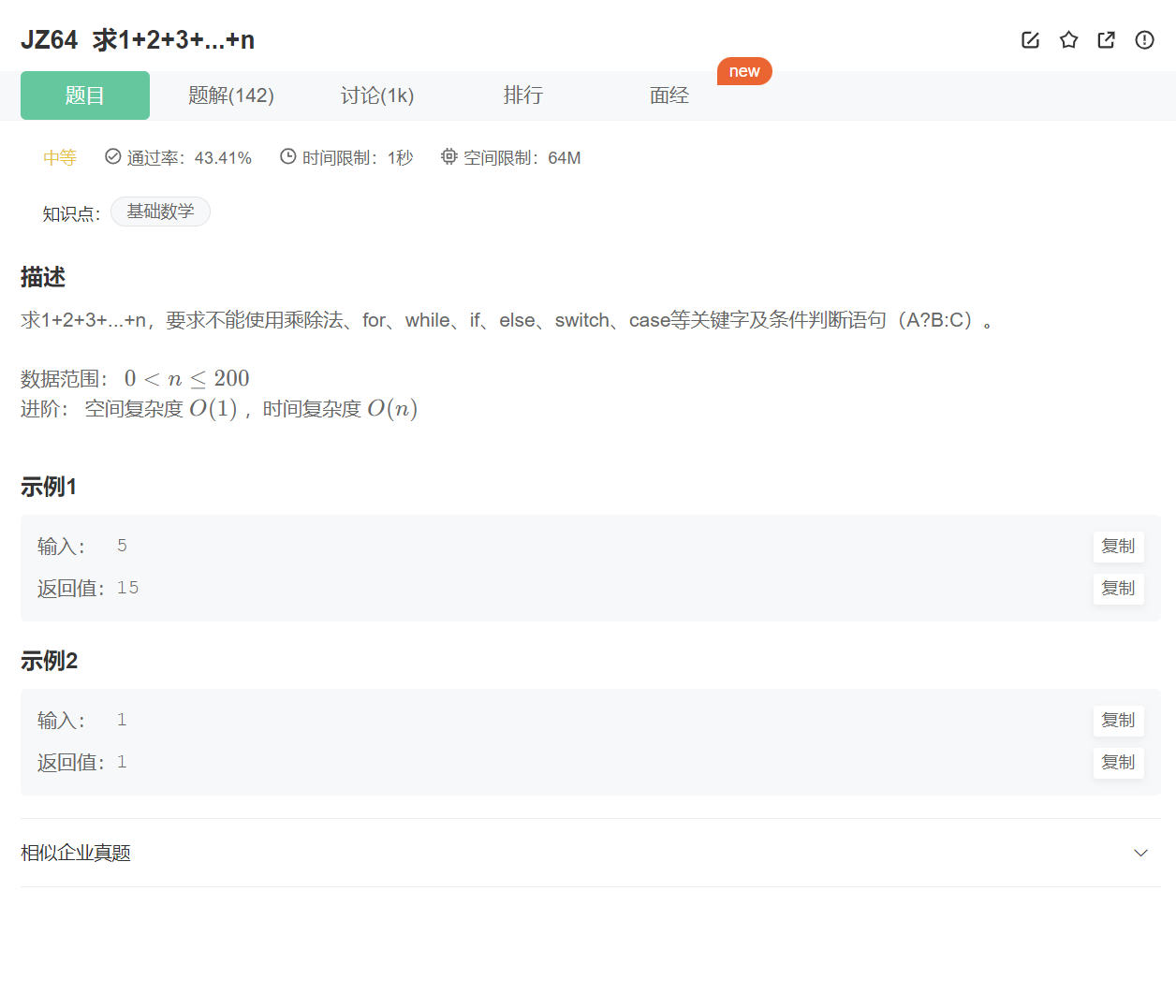
1. 題目:
2.分析:
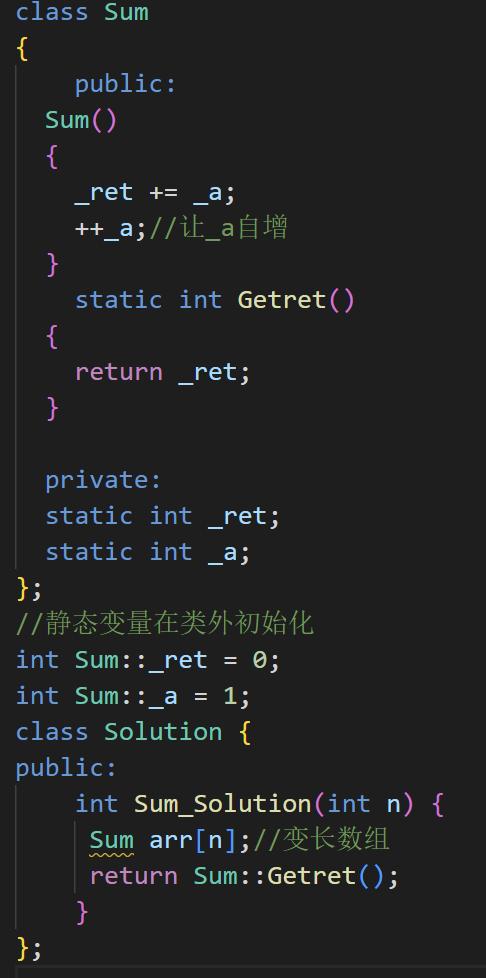
這道題要求我們計算1到n的和,看似簡單,但這道題給了我們一堆限制條件,這一下子讓我們沒有了思路,這里我就直接說怎么做了,我們可以利用構造函數自動調用的特性來解決,創建一個靜態變量,然后每次自動調用構造函數時都累加上這個變量上,最后就能計算出1到n的和。
3. 代碼:
4. 題目傳送門:
JZ64 求1+2+3+…+n
小結:
靜態變量的意義:盡可能減少全局變量的使用。
四:友元
- 友元提供了一種突破類訪問限定符封裝的方式,友元分為:友元函數和友元類,在函數聲明或者類聲明的前面加
friend,并且把友元聲明放到一個類的里面。 - 外部友元函數可訪問類的私有和保護成員,友元函數僅僅是?種聲明,他不是類的成員函數。
- 友元函數可以在類定義的任何地方聲明,不受類訪問限定符限制。
- 一個函數可以是多個類的友元函數。
- 友元類中的成員函數都可以是另一個類的友元函數,都可以訪問另一個類中的私有和保護成員。
- 友元類的關系是單向的,不具有交換性,比如A類是B類的友元,但是B類不是A類的友元。
- 友元類關系不能傳遞,如果A是B的友元,B是C的友元,但是A不是C的友元。
- 有時提供了便利。但是友元會增加耦合度,破壞了封裝,所以友元不宜多用。
流插入與流提取
我們知道C++中的輸入輸出可以自動識別類型,所謂的自動識別其實還是函數重載的作用。
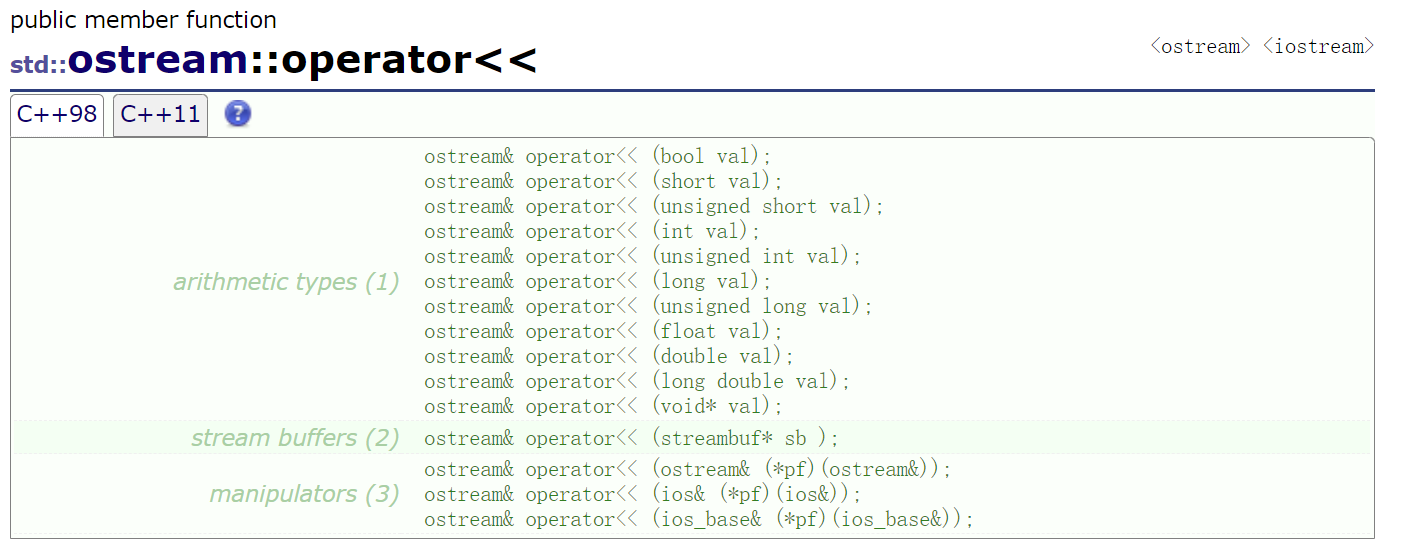
在C++網站上查詢ostream時可以看到它的一堆重載。
分析打印過程:
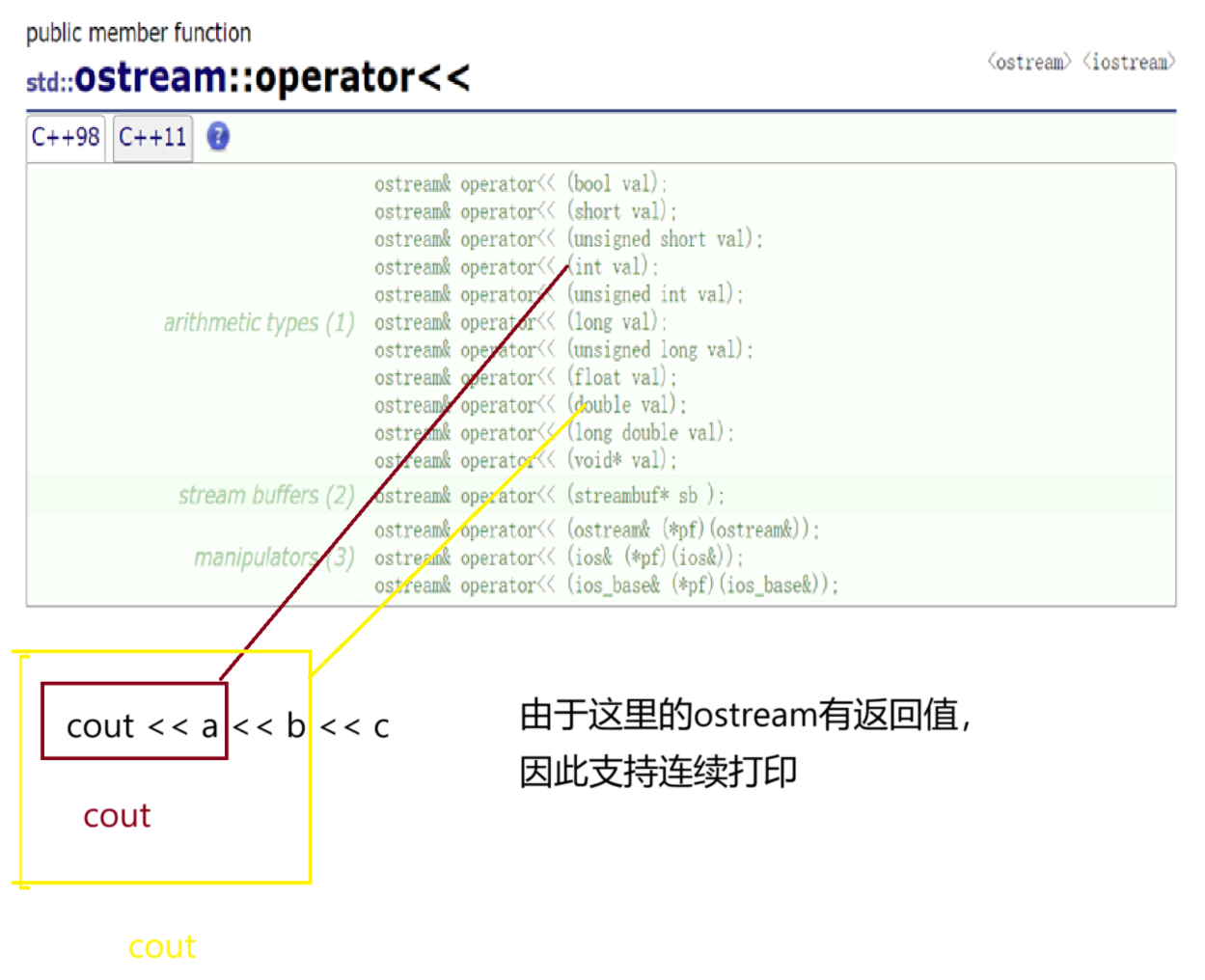
1. 流插入重載
這里我們就拿之前實現的日期類來實現一下自定義類型的流插入和流提取的重載
一開始我們可能會這樣寫:
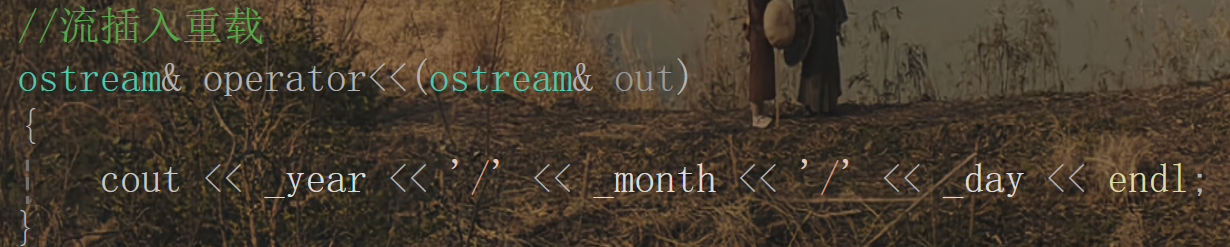

但是打印的時候我們這樣寫還不行,因為參數匹配反了,在類里面實現的重載,第一個參數默認為this指針,在這里this指針接收的是d1的地址,所以第一個參數是類類型的指針,第二個參數才是ostream,因此打印的時候要這樣寫:
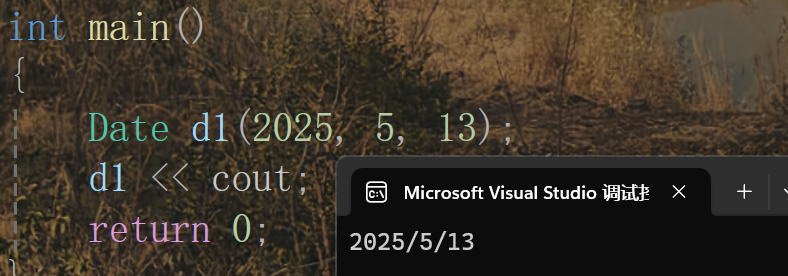
但是這樣寫跟我們之前的打印不一樣,感覺挺尷尬的。
為什么庫函數里面實現的重載參數就能匹配上呢?

那是因為庫函數里面是在ostream類里面實現的,this指針接收的是ostream類類型,我們在調用函數時,正好將cout傳過去被this指針接收,因此就對上了,但是我們不能隨意修改庫函數啊,所以我們就只好將其寫成全局的函數了。

這樣的話參數匹配不上的問題就解決了,但是這里又遇到了新的問題:這里牽扯到了訪問私有成員,如果像之前一樣都寫單獨的成員函數來獲取的話就特別麻煩,因此這里我們引入 友元 這一概念來解決這一問題。


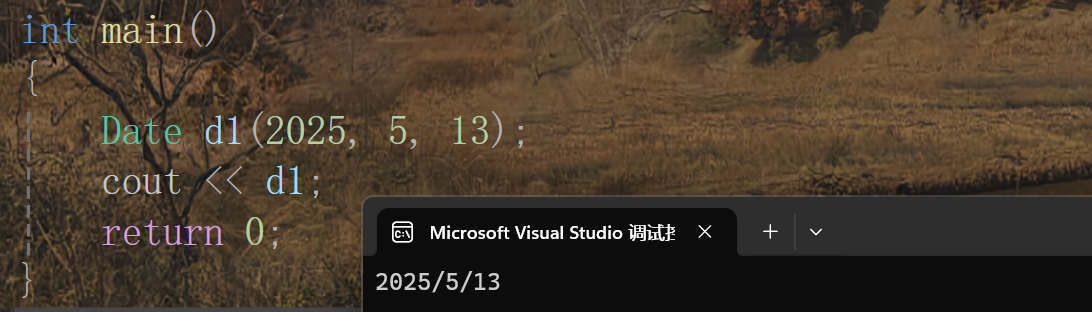
注:這里為了避免鏈接錯誤,可以讓這個重載函數成為內聯函數。
2. 流提取重載

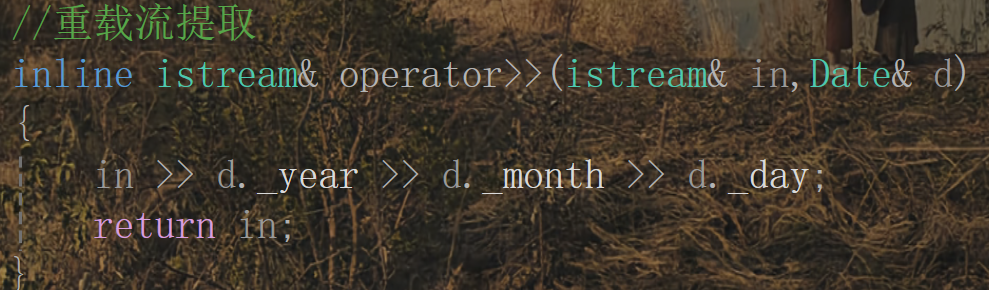
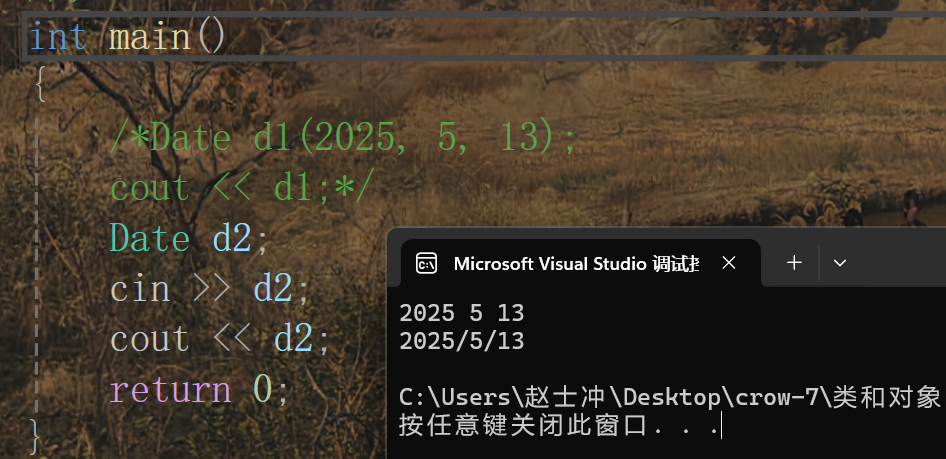
注:這里需要注意的是第二個參數就不能加const了,因為如果加const的話就該參數就為常量,就不能再給其輸入值了。
加上這兩個其實這個日期類就比較完善了,但是我們在輸入時還需要考慮一種情況:如果輸入的日期非法呢?所以在輸入這里我們可以再完善一下:
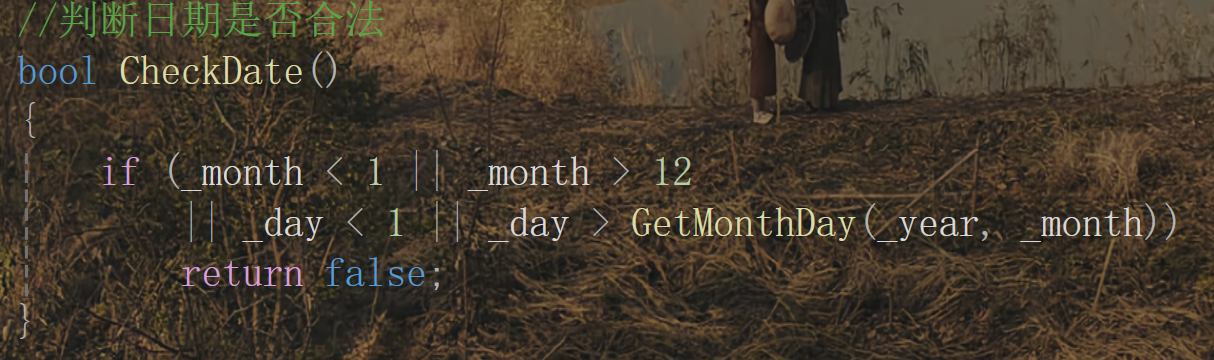
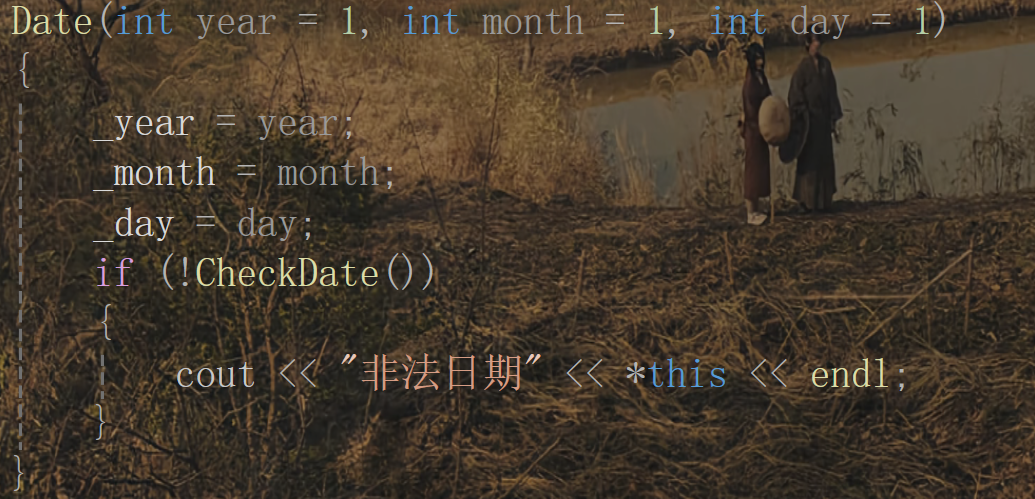
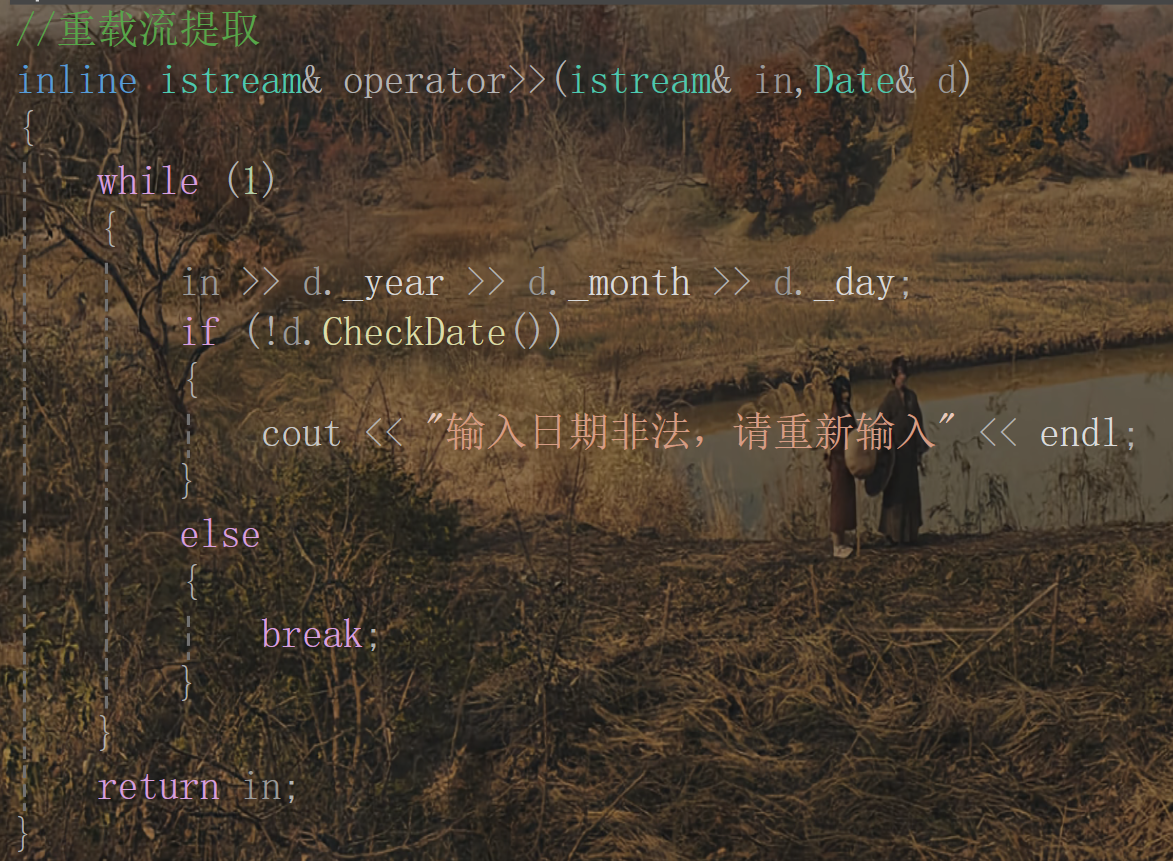
經過上面的補充,這個日期類就相對完善了。
同一個函數的多個友元

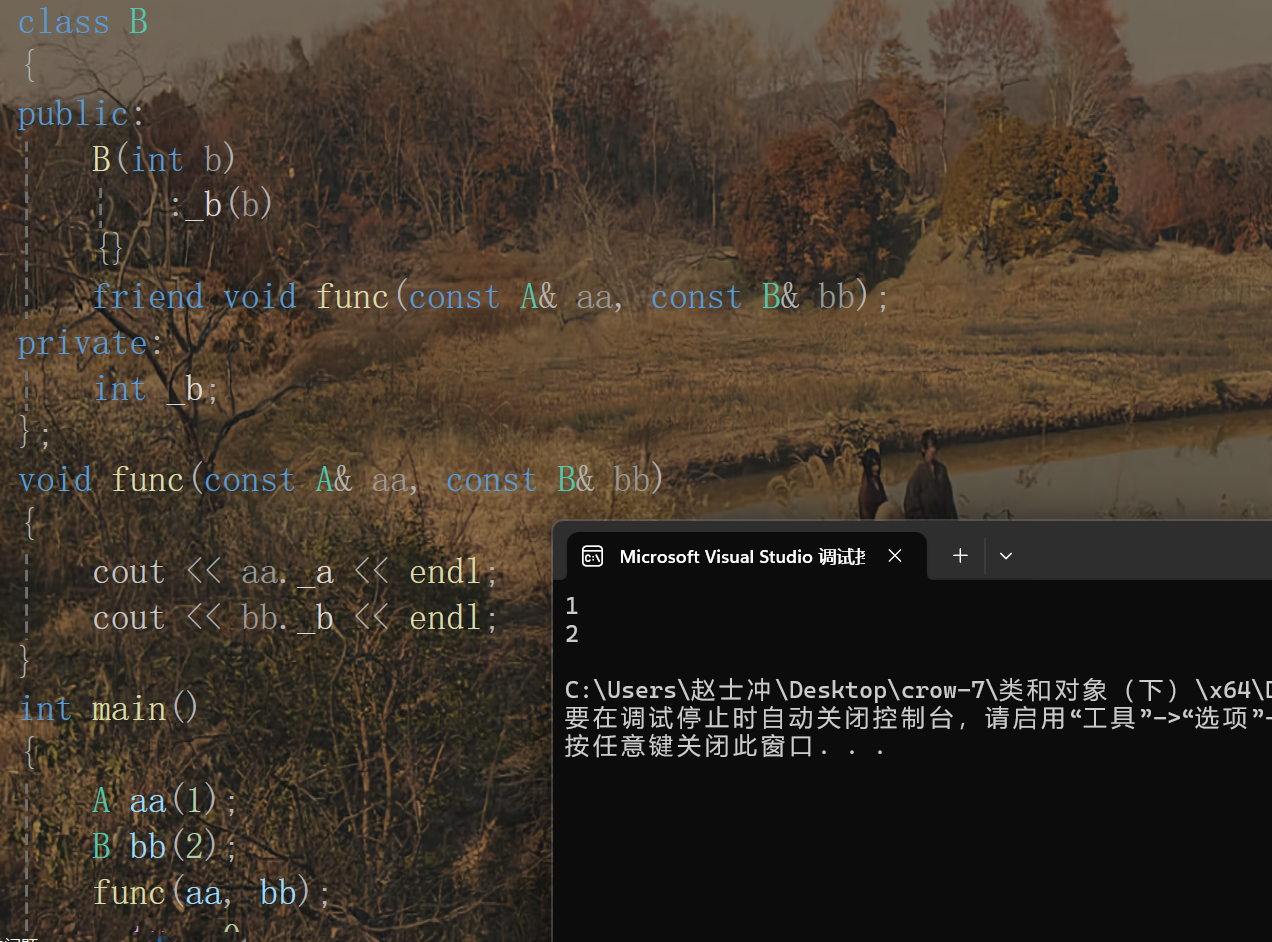
小結:
雖然友元有時候提供了便利。但是友元在一定程度上會增加耦合度,破壞了封裝,所以友元不宜多用。
五:說明
前四個板塊是需要重點來理解和掌握的,后面幾個簡單了解
六:內部類
- 如果一個類定義在另一個類的內部,這個內部類就叫做內部類。內部類是一個獨立的類,跟定義在全局相比,內部類只是受外部類類域限制和訪問限定符限制,所以外部類定義的對象中不包含內部類。
- 內部類默認是外部類的友元類。
- 內部類本質也是一種封裝,當
A類跟B類緊密關聯,A類實現出來主要就是給B類使用,那么可以考慮把A類設計為B的內部類,如果放到private/protected位置,那么A類就是B類的專屬內部類,其他地方都用不了。
場景一:計算帶有內部類的類大小
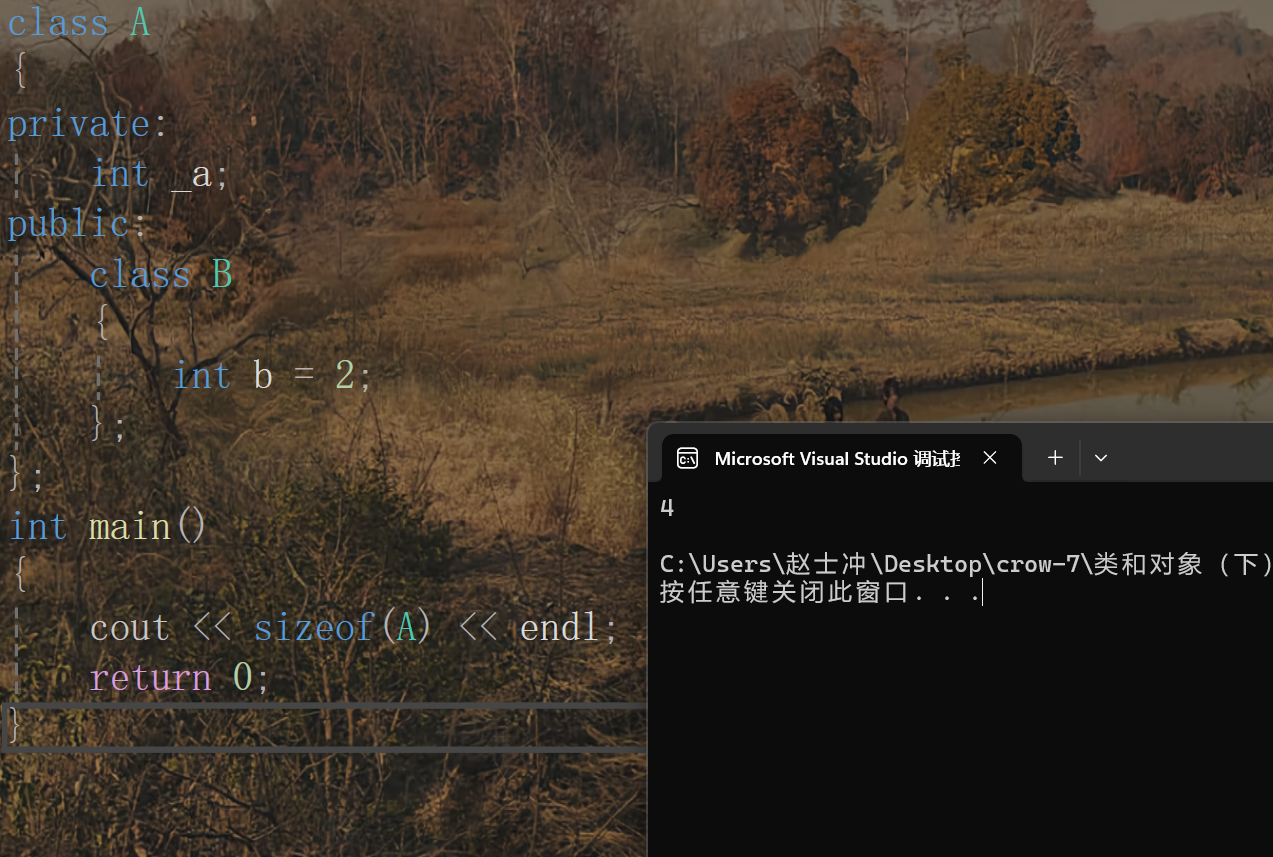
可以看到計算外部類A的時候,內部類并沒有計入其中。
場景二:友元性質

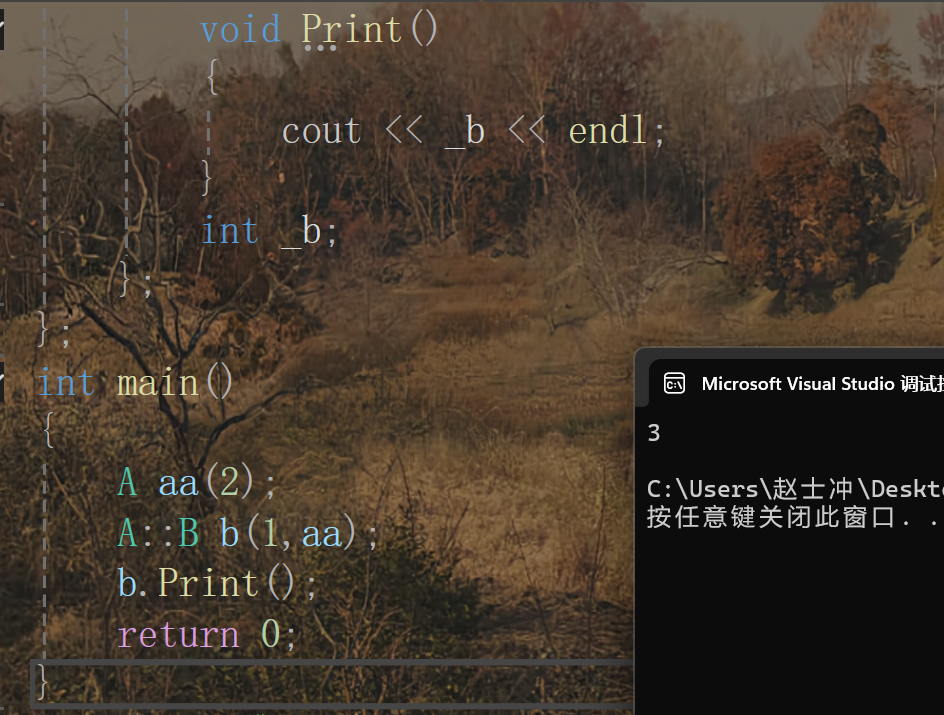
注:由于內部類B默認為外部類A的友元類,因此B可以訪問A的私有成員_a
七:匿名對象
- 用類型(實參)定義出來的對象叫做匿名對象,相比之前我們定義的類型 對象名 (實參)定義出來的叫有名對象。
- 匿名對象生命周期只在當前一行,一般臨時定義一個對象當前用一下即可,就可以定義匿名對象。
場景一:有名對象 臨時對象 匿名對象 舉例

場景二:用匿名對象來簡化步驟(特定情況下)
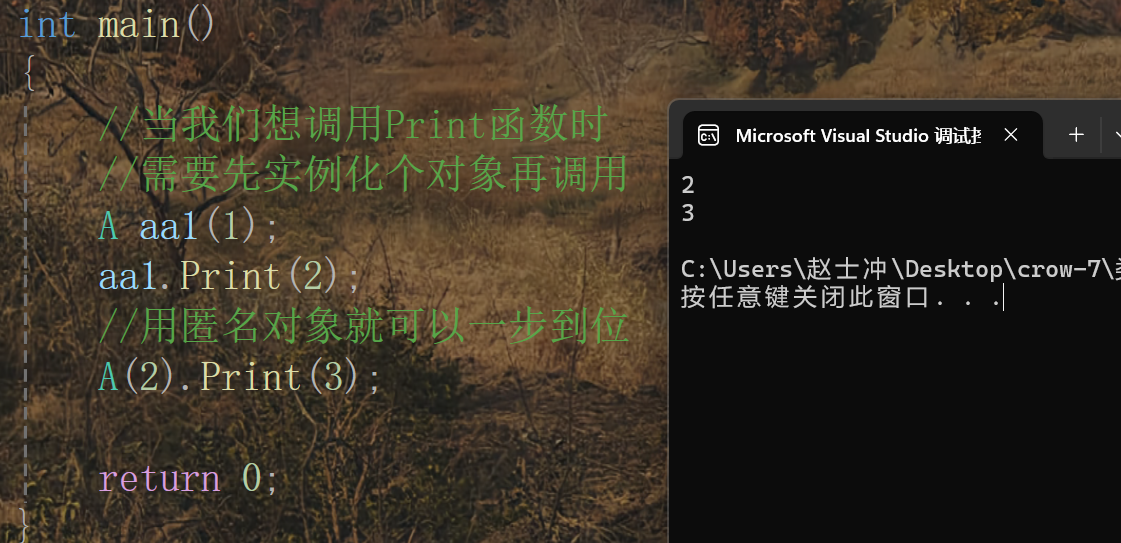
解讀:當我們只是單純地想調用某個函數時,先創建有名對象再通過對象調用這個函數就比較繁瑣,通過匿名對象我們就可以一步完成調用,而且匿名對象的生命周期只是當前一行,就像一次性紙杯一樣。
注:const可以延長臨時變量的生命周期
八:對象拷貝時的編譯器優化
- 現代編譯器會為了盡可能提高程序的效率,在不影響正確性的情況下會盡可能減少一些傳參和傳返回值的過程中可以省略的拷貝。
- 如何優化C++標準并沒有嚴格規定,各個編譯器會根據情況自行處理。當前主流的相對新?點的編譯器對于連續?個表達式步驟中的連續拷貝會進行合并優化,有些更新更"激進"的編譯器還會進行跨行跨表達式的合并優化。
linux下可以將下面代碼拷貝到test.cpp?件,編譯時用g++ test.cpp -fno-elide- constructors的方式關閉構造相關的優化。
場景一:隱式類型轉換時的編譯器優化
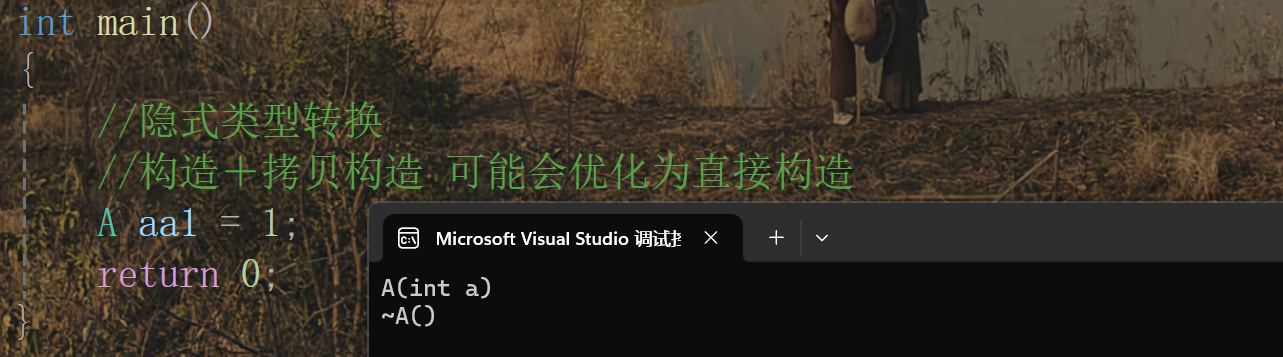
- 正常步驟:
1構造臨時對象,臨時對象再拷貝構造aa1 - 優化之后:
1直接構造aa1
場景二:傳值傳參(無優化)

- 在創建對象
aa2時調用了構造函數,在傳值傳參的時候調用了拷貝構造函數。 - 在傳值傳參時,編譯器沒有進行優化。
場景三:隱式類型傳參
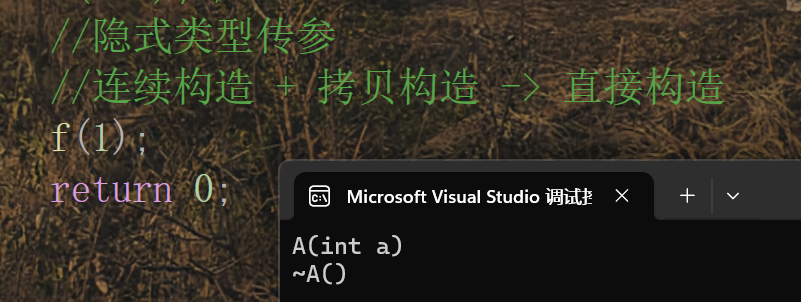
- 正常步驟:
1構造臨時對象,這個臨時對象再拷貝構造給一個新的對象。 - 優化后:
1直接構造新的對象。
場景五: 傳值返回
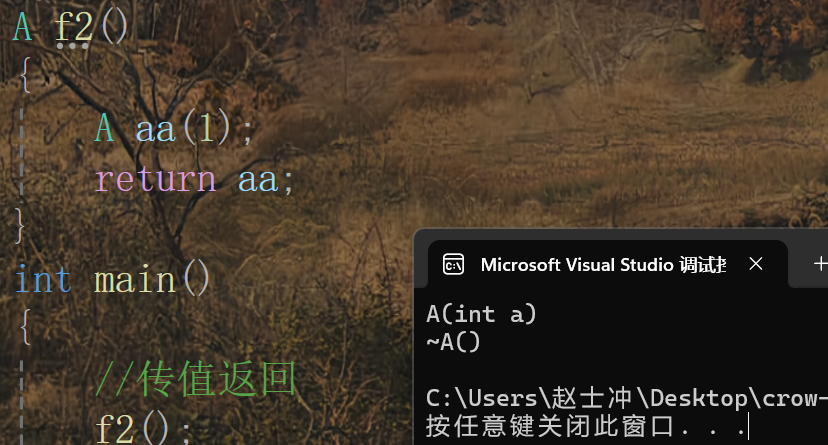
- 正常步驟:先構造局部對象
aa,再拷貝構造一份aa的形參(臨時對象)返回。 - 優化后:直接構造然后返回。
場景六: 拷貝構造+賦值重載(無法完全優化)
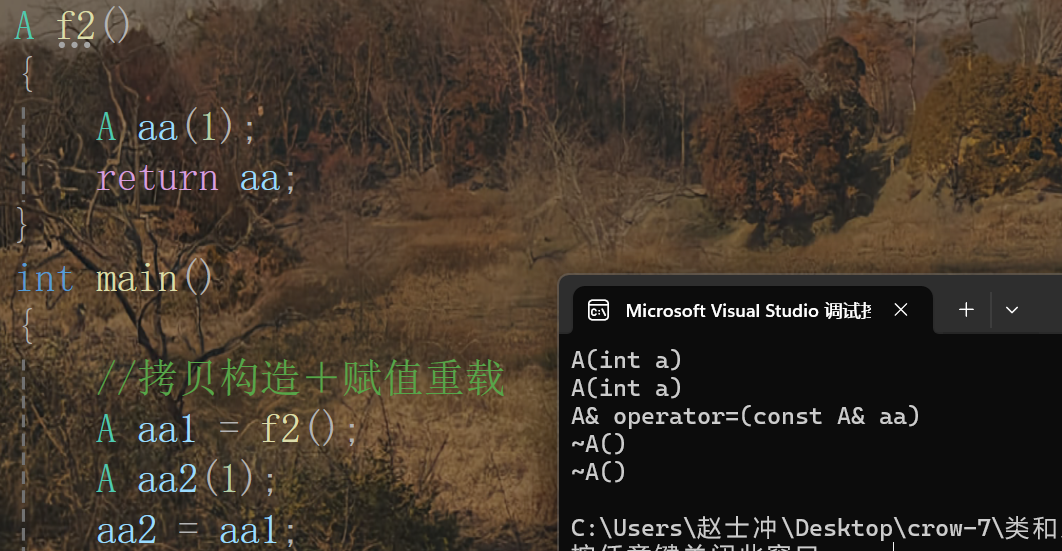
- 正常步驟:
aa先構造局部對象,然后調用拷貝構造函數來生成一份要返回的臨時對象,然后接收返回值的對象aa1來接收這個臨時對象,這里會調用拷貝構造函數,之后aa2調用構造函數初始化,aa2再調用賦值重載函數來拿aa1來完成賦值。 - 優化后: 編譯器進行了跨行合并優化,將構造的局部對象
aa和拷貝臨時對象合
并為一個直接構造,剩下的沒有進行優化。
小結:
- 不同版本的編譯器以及不同的編譯器的優化是不確定的。
- 在接收返回值是用拷貝構造比賦值重載的方式更好,更方便編譯器的優化。
總結:
到這里,類和對象我們就算是學完了,可以說已經入門C++了(開心),不過后面要學的東西還多呢(大聲)
本篇完結撒花!!!



















