目錄
一、實驗目的
二、實驗環境
三、實驗內容
3.1 完成解壓數據集相關操作
3.2分析代碼結構并運行代碼查看結果
3.3修改超參數(批量大小、學習率、Epoch)并對比分析不同結果
3.4修改網絡結構(隱藏層數、神經元個數)并對比分析不同結果
四、實驗小結
一、實驗目的
- 了解python語法
- 了解全連接神經網絡結構
- 調整超參數、修改網絡結構并對比分析其結果
二、實驗環境
Baidu 飛槳AI Studio
三、實驗內容
3.1 完成解壓數據集相關操作
輸入以下兩行命令解壓數據集
(1)cd ./data/data230? ? ?
(2)unzip Minst.zip
運行后結果如圖1所示
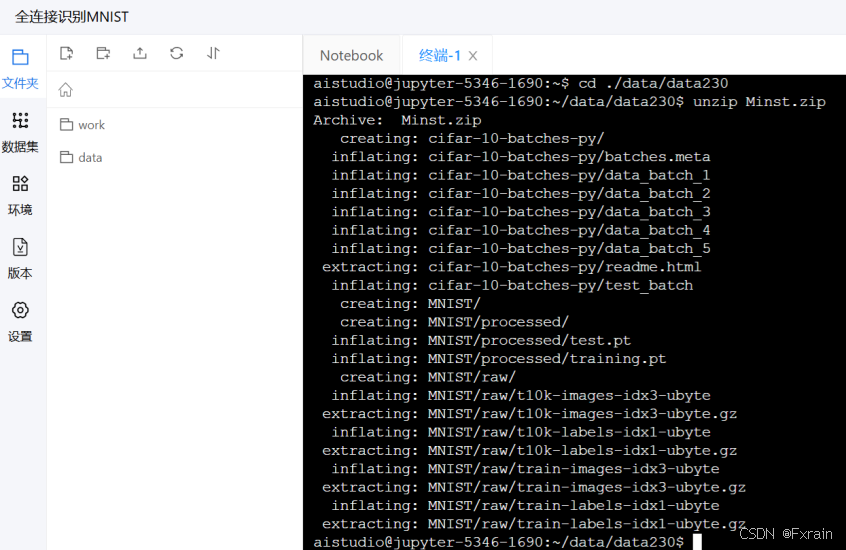
圖 1?解壓數據集
3.2分析代碼結構并運行代碼查看結果
代碼結構:
import?torchfrom?torch?import?nn,?optimfrom?torch.autograd?import?Variablefrom?torch.utils.data?import?DataLoaderfrom?torchvision?import?datasets,?transformsbatch_size?=?64learning_rate?=?0.02class?Batch_Net(nn.Module):def?__init__(self,?in_dim,?n_hidden_1,?n_hidden_2,?out_dim):super(Batch_Net,?self).__init__()self.layer1?=?nn.Sequential(nn.Linear(in_dim,?n_hidden_1),?nn.BatchNorm1d(n_hidden_1),?nn.ReLU(True))self.layer2?=?nn.Sequential(nn.Linear(n_hidden_1,?n_hidden_2),?nn.BatchNorm1d(n_hidden_2),?nn.ReLU(True))self.layer3?=?nn.Sequential(nn.Linear(n_hidden_2,?out_dim))def?forward(self,?x):x?=?self.layer1(x)x?=?self.layer2(x)x?=?self.layer3(x)return?xdata_tf?=?transforms.Compose([transforms.ToTensor(),transforms.Normalize([0.5],?[0.5])])train_dataset?=?datasets.MNIST(root='./data/data230',?train=True,?transform=data_tf,?download=True)test_dataset?=?datasets.MNIST(root='./data/data230',?train=False,?transform=data_tf)train_loader?=?DataLoader(train_dataset,?batch_size=batch_size,?shuffle=True)test_loader?=?DataLoader(test_dataset,?batch_size=batch_size,?shuffle=False)#model?=?net.simpleNet(28?*?28,?300,?100,?10)#?model?=?Activation_Net(28?*?28,?300,?100,?10)model?=?Batch_Net(28?*?28,?300,?100,?10)if?torch.cuda.is_available():model?=?model.cuda()criterion?=?nn.CrossEntropyLoss()optimizer?=?optim.SGD(model.parameters(),?lr=learning_rate)epoch?=?0for?data?in?train_loader:img,?label?=?dataimg?=?img.view(img.size(0),?-1)if?torch.cuda.is_available():img?=?img.cuda()label?=?label.cuda()else:img?=?Variable(img)label?=?Variable(label)out?=?model(img)loss?=?criterion(out,?label)print_loss?=?loss.data.item()optimizer.zero_grad()loss.backward()optimizer.step()epoch+=1if?epoch%100?==?0:print('epoch:?{},?loss:?{:.4}'.format(epoch,?loss.data.item()))model.eval()eval_loss?=?0eval_acc?=?0for?data?in?test_loader:img,?label?=?dataimg?=?img.view(img.size(0),?-1)if?torch.cuda.is_available():img?=?img.cuda()label?=?label.cuda()out?=?model(img)loss?=?criterion(out,?label)eval_loss?+=?loss.data.item()*label.size(0)_,?pred?=?torch.max(out,?1)num_correct?=?(pred?==?label).sum()eval_acc?+=?num_correct.item()print('Test?Loss:?{:.6f},?Acc:?{:.6f}'.format(eval_loss?/?(len(test_dataset)),eval_acc?/?(len(test_dataset))))代碼分析:
代碼實現了通過使用批標準化的神經網絡模型對MNIST數據集進行分類。
1.首先定義一些模型中會用到的超參數,在實驗中設置批量大小(batch_size)為64,學習率(learning_rate)為0.02
2.定義Batch_Net神經網絡類繼承自torch庫的nn.Module。
(1)定義的初始化函數_init_接收輸入維度(in_dim)、兩個隱藏層神經元數量(n_hidden_1和n_hidden_2)和輸出維度(out_dim)作為參數,定義第一層和第二層網絡結構,包括線性變換、批標準化和ReLU激活函數,第三層網絡結構只包括線性變換。
(2)定義的forward前向傳播函數接受輸入x,依次經過三層網絡結構處理后返回處理結果。
3.將數據進行預處理。包括使用transforms.ToTensor()將圖片轉換成PyTorch中處理的對象Tensor,并進行標準化操作,通過transforms.Normalize()做歸一化(減均值,再除以標準差)操作,通過transforms.Compose()函數組合各種預處理的操作。
4.下載并加載MNIST訓練數據(train_dataset)以及測試數據(test_dataset);創建數據加載器,用于批量加載訓練數據(train_loader)和測試數據(test_loader)。
5.選擇訓練的模型,實驗中選擇Batch_Net模型,判斷GPU是否可用,如果GPU可用,則將模型放到GPU上運行。在定義損失函數(criterion)和優化器(optimizer),損失函數使用交叉熵損失,優化器使用隨機梯度下降優化器。
6.開始訓練模型,遍歷訓練數據,通過img.view(img.size(0), -1)將圖像數據調整為一維張量,以便與模型的輸入匹配。計算損失值(loss)并進行反向傳播和參數更新,每100個epoch打印一次訓練損失,最后評估模型在測試集上的性能,計算并打印總損失(將損失值乘以當前批次的樣本數量,累加到eval_loss中)和準確率(eval_acc)。
運行代碼后的結果如圖所示:
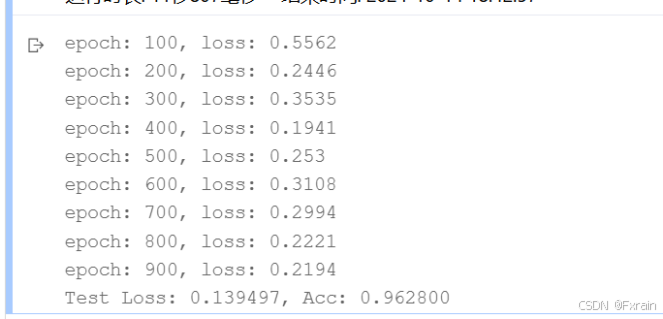
圖 2?批量大小=64,學習率=0.02,Epoch次數=100
3.3修改超參數(批量大小、學習率、Epoch)并對比分析不同結果
1.當只修改批量大小batch_size時(學習率=0.02,Epoch次數=100)
(1)batch_size=16,結果如圖3所示
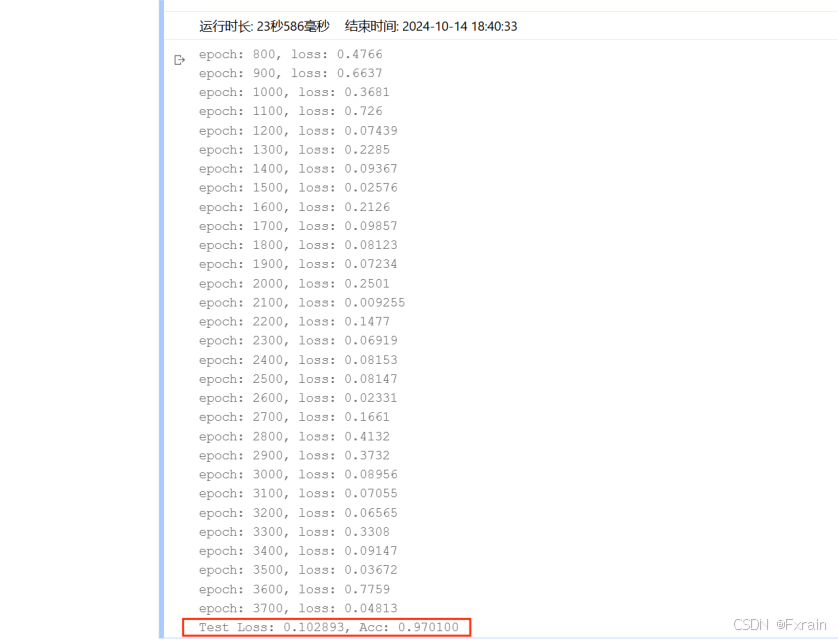
圖 3
(2)batch_size=64,結果如圖4所示
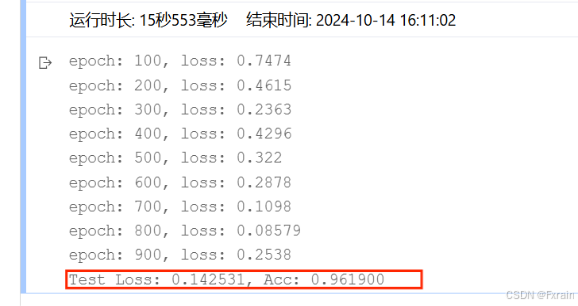
圖 4
(3)batch_size=128,結果如圖5所示
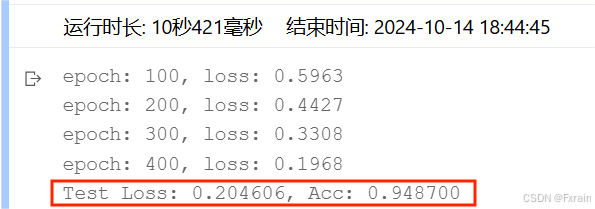
圖 5
對比總結:增大batch_size后,數據的處理速度加快,運行時間變短,跑完一次 epoch(全數據集)所迭代的次數減少。
2.當只修改學習率learning_rate時(批量大小=64,Epoch次數=100)
(1)learning_rate=0.005,結果如圖6所示。
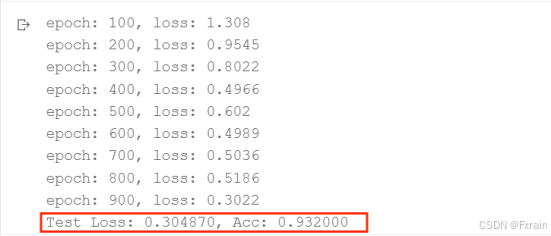
圖 6
(2)learning_rate=0.02,結果如圖7所示。
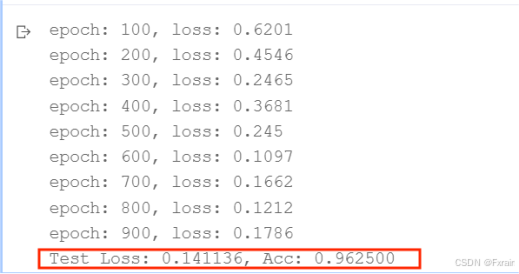
圖 7
(3)learning_rate=0.1,結果如圖8所示。
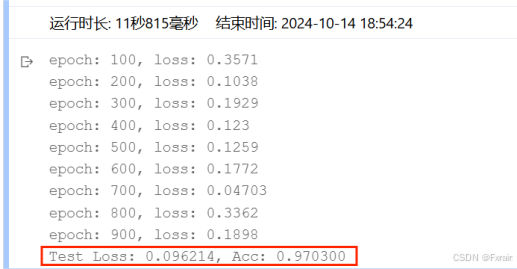
圖 8
(4)learning_rate=0.4,結果如圖9所示。
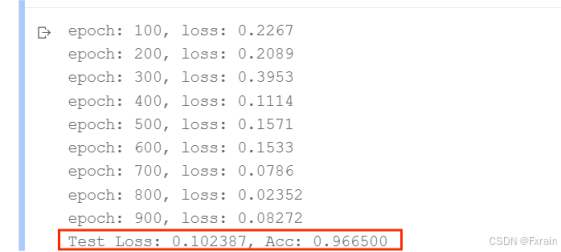
圖 9
對比總結:當學習率適當增大時可能會有助于降低損失函數,提高模型的精確度,但是當學習率超出一定范圍則會降低模型的精確率。
3.當只修改Epoch次數時(批量大小=64,學習率=0.02)
(1)Epoch=50,結果如圖10所示。
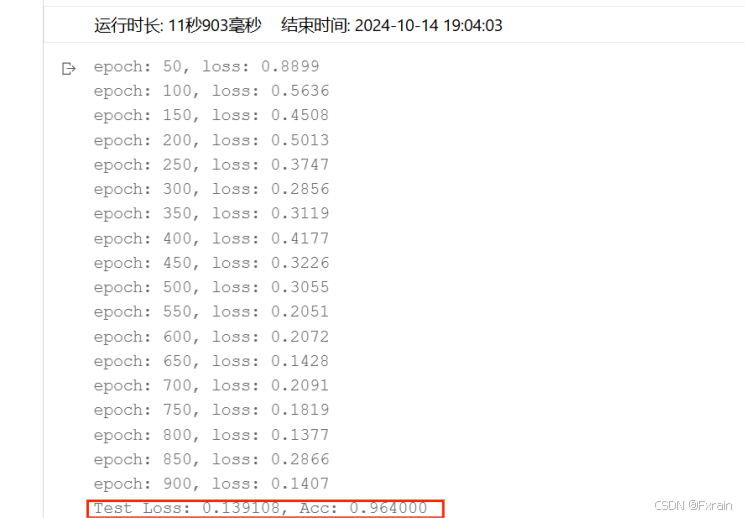
圖 10
(2)Epoch=100,結果如圖11所示。
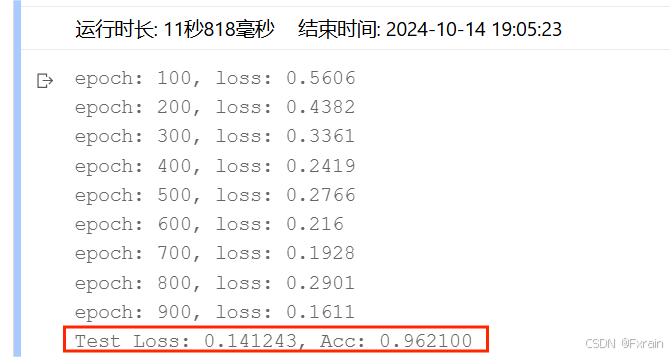
圖 11
(3)Epoch=200,結果如圖12所示。
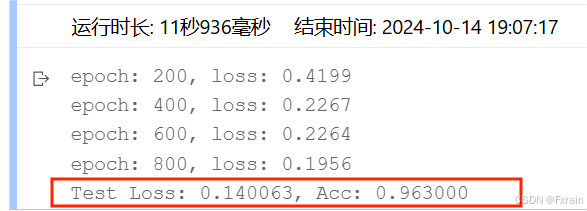
圖 12
對比總結:不同Epoch次數導致損失函數不同、模型的準確率有所差別。
3.4修改網絡結構(隱藏層數、神經元個數)并對比分析不同結果
1.修改神經網絡的隱藏層數
(1)隱藏層數為兩層時的結果(n_hidden_1、n_hidden_2),結果如圖13所示。
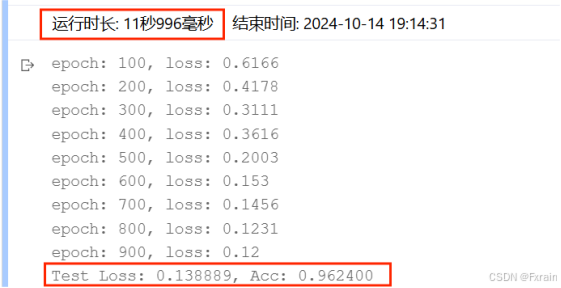
圖 13
(2)隱藏層數為三層時的結果(n_hidden_1、n_hidden_2、n_hidden_3),結果如圖14所示。
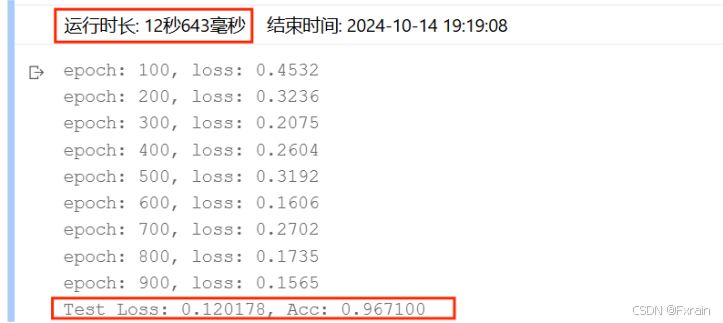
圖 14
對比結果:可以看到,增加隱藏層個數后,運行時間增加,損失函數有所降低,三層隱藏層網絡結構的模型準確率較高于兩層隱藏層模型的準確率。
2.修改神經元個數(這里基于三層隱藏層數進行實驗)
(1)神經元個數參數設定為model = Batch_Net(28 * 28, 300, 200,100, 10),結果如圖15所示。
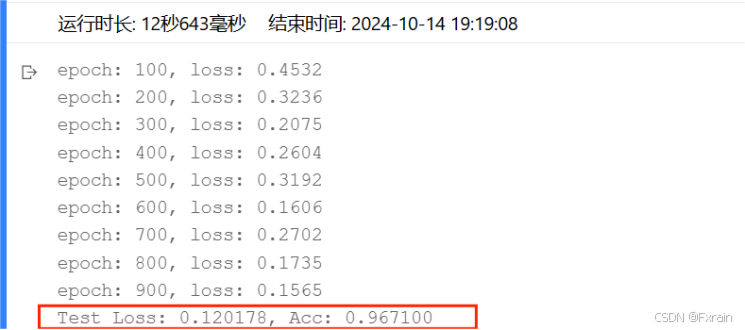
圖 15
(2)神經元個數參數設定為model = Batch_Net(28 * 28, 400, 300,200, 10),結果如圖16所示。
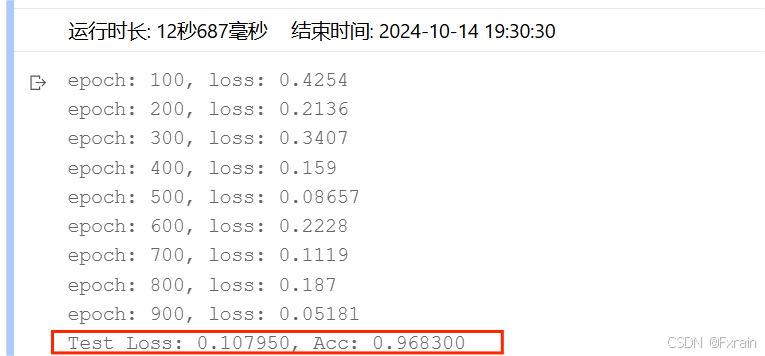
圖 16
(3)神經元個數參數設定為model = Batch_Net(28 * 28, 200, 100,50, 10),結果如圖17所示。
圖 17
四、實驗小結
超參數是在訓練神經網絡之前設置的,而不是通過訓練過程中學習得出的。常見的超參數包括學習率、批量大小、隱藏層的數量、神經元的個數等等。在使用深度神經網絡時,正確地調整超參數是提高模型性能的關鍵。





:一階低通RC濾波器 一階線性微分方程推導 拉普拉斯域表達(傳遞函數、頻率響應)分析)



)

)







