今天給大家分享下最近小編幫助學員解決的幾個經典數字IC后端項目問題。希望能夠對大家的學習和工作有所幫助。
數字IC后端項目典型問題之后端實戰項目問題記錄(2025.04.24)
數字IC后端設計實現培訓教程(整理版)
Q1: 老師好,我這個placement后from A7CORE0的path報了-3ns的wns,高亮了這條路徑之后是這樣的,為啥a7core0的pin不直接連到iso cell,而是在a7core子模塊上繞了一大圈再連到isolation cell?
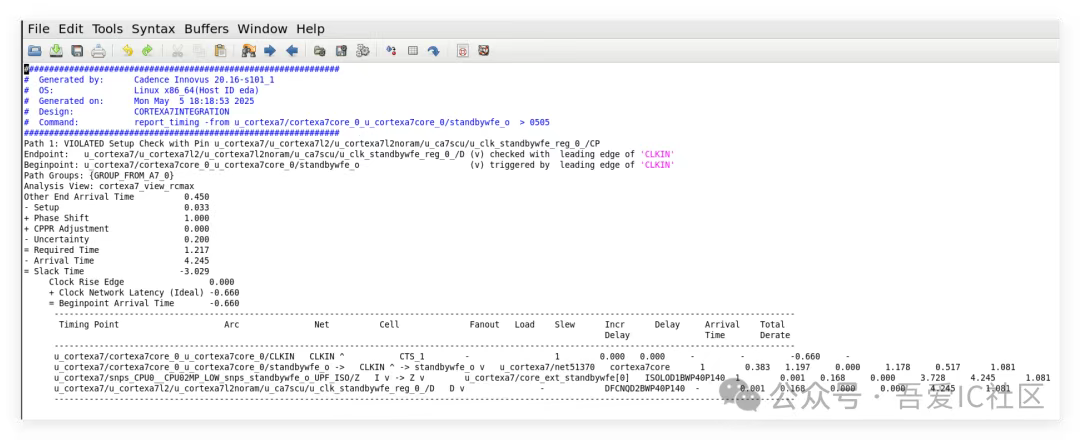
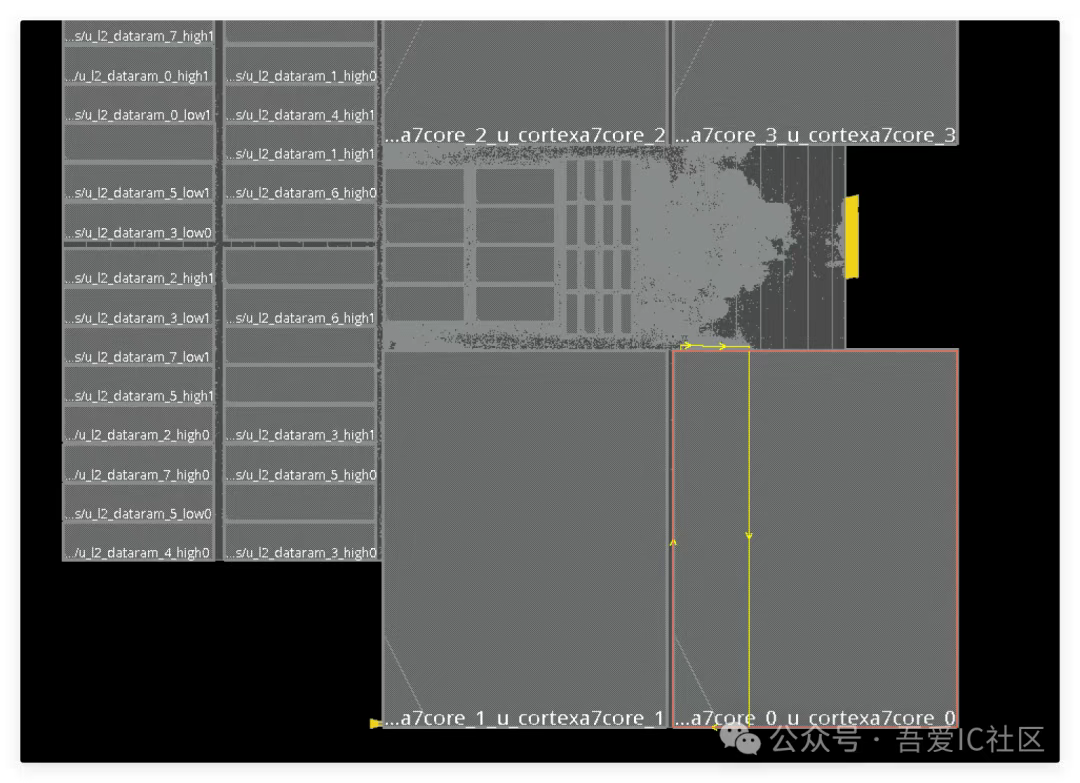
這里有timing violation主要是長線帶來的transition問題和delay問題。通過時序報告和layout高亮的路徑上看,這條路徑上沒有任何的buffer和inverter,但工具在做early global route的時候卻給規劃了這么一條虛擬走線。
這種一半是屬于工具early global route的bug。但我們自己在做子模塊lef的時候也存在一定的瑕疵,某些layer的cell blockage沒有蓋全導致工具在cell blockage和pg pin中間見縫插針,規劃了幾根走線。
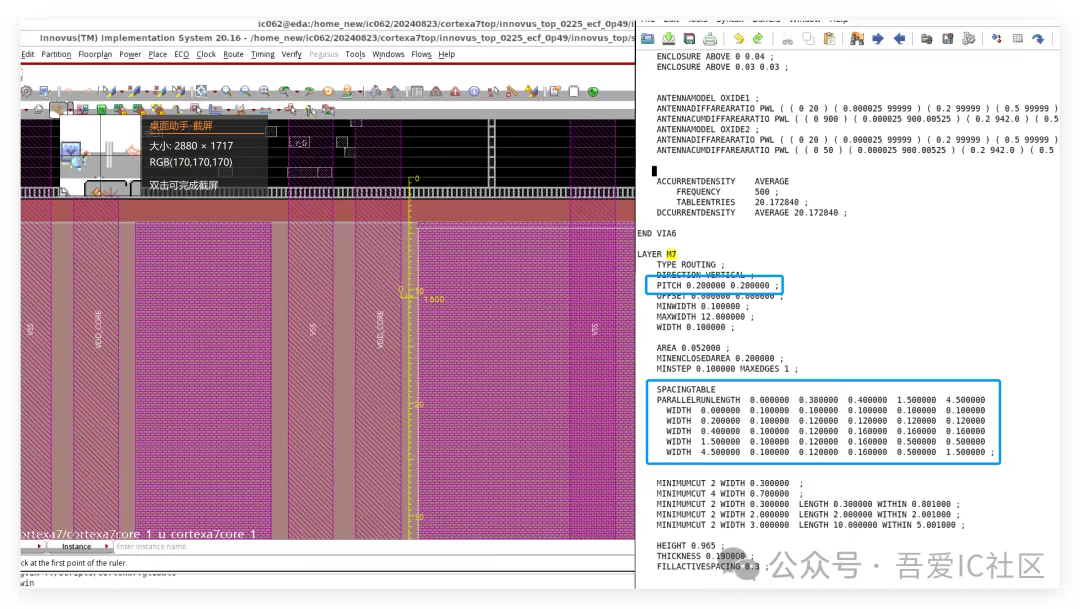
Q2:在跑Calibre LVS的時候出現了一條路徑短路,是從vss到一個io口,在innovus里顯示看了一會不知道咋看?
登錄服務器端口看到這個學員已經把Calibre LVS Short報告導入到Innovus中,說明它已經掌握到LVS debug分析的基本流程。1)查看LVS short報告2)查看LVS GDS抽取報告3)查看LVS結果報告
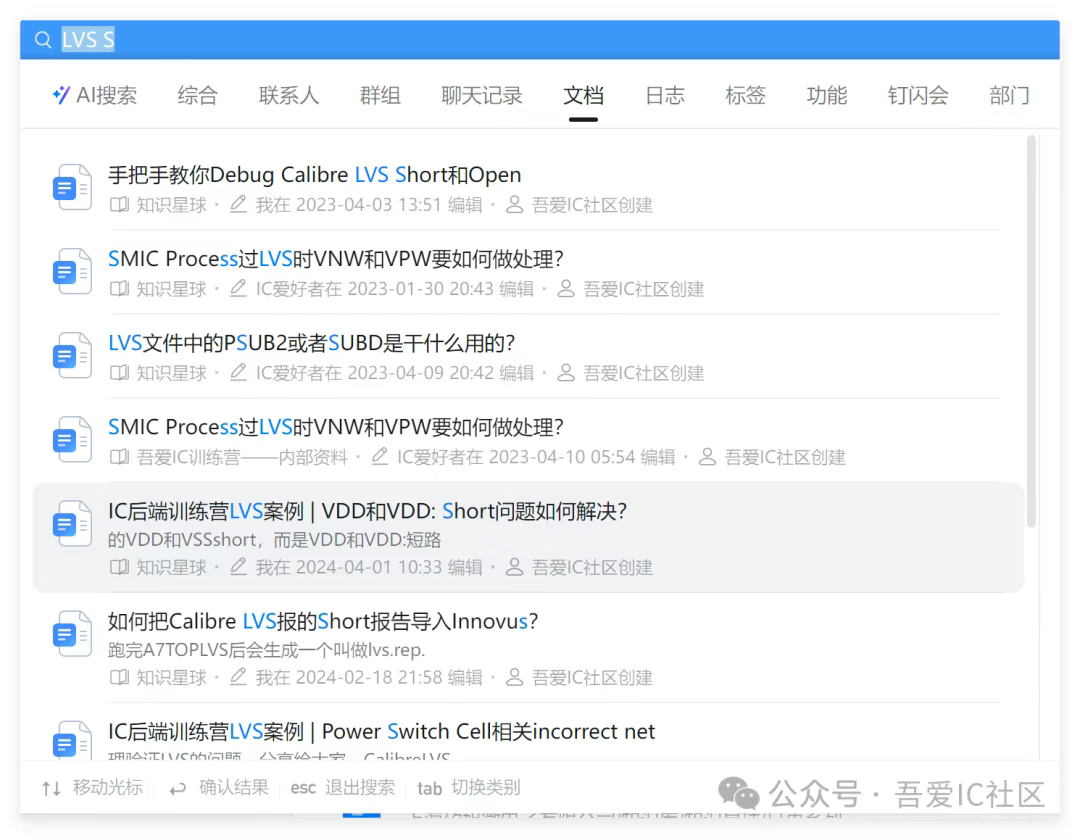
隨意選中一個short定位到具體位置后,從高亮的位置我們就可以看出PG Rail VSS和一顆cell輸出pin對應的net短路了!而且是M1搭在一起了!
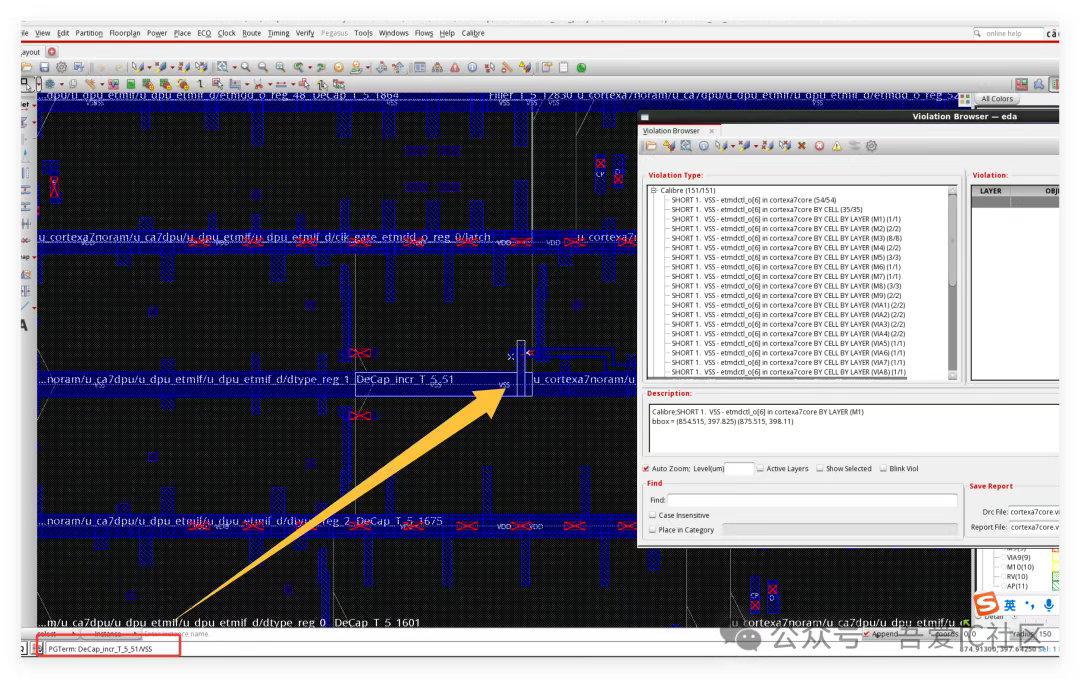
出現這個short主要原因是該學員在PR實現過程中使用了M1進行繞線!圖中所示的short位置是Decap Cell的M1 VSS PG Pin。
如果使用的是普通Filler Cell也不會出現這個問題。但這個DRC正常在innovus中就可以檢查出來的。我們接著在innovus中執行verify_drc,其結果如下圖所示。
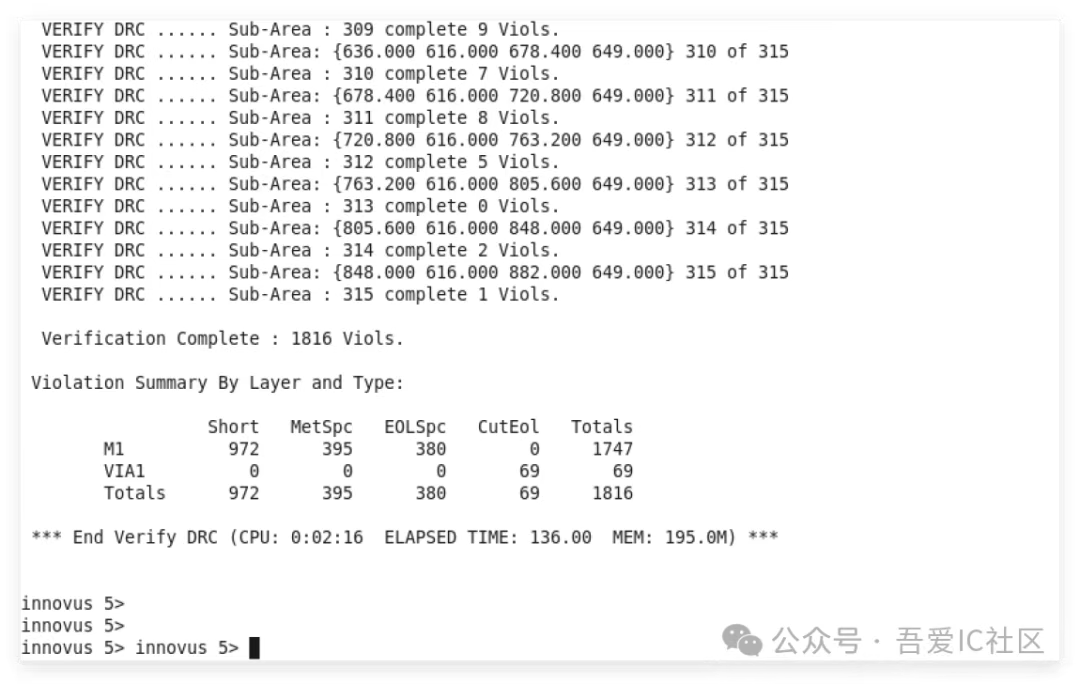
我們很清楚看到確實存在大量M1的short。
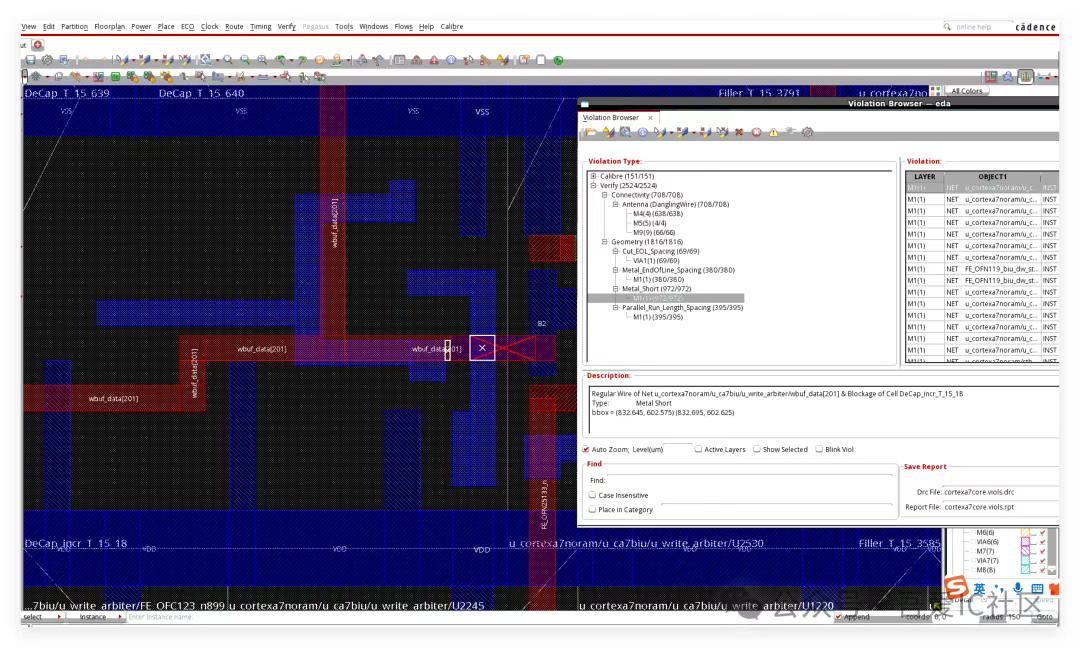
所以,我們如果想在當前database上做一些修復,我們可以在verify_drc后執行ecoRoute即可自動修復。當然我們還是建議在PR實現全流程嚴格控制global route和nanoroute的layer范圍為M2-M6。
Q3: 跑完a7top routing后NanoRoute DRC Violation如下圖所示。請問老師,這類DRC Violation應該如何分析和修復?
Innovus DRC Violation和Calibre DRC Violation分析和修復案例
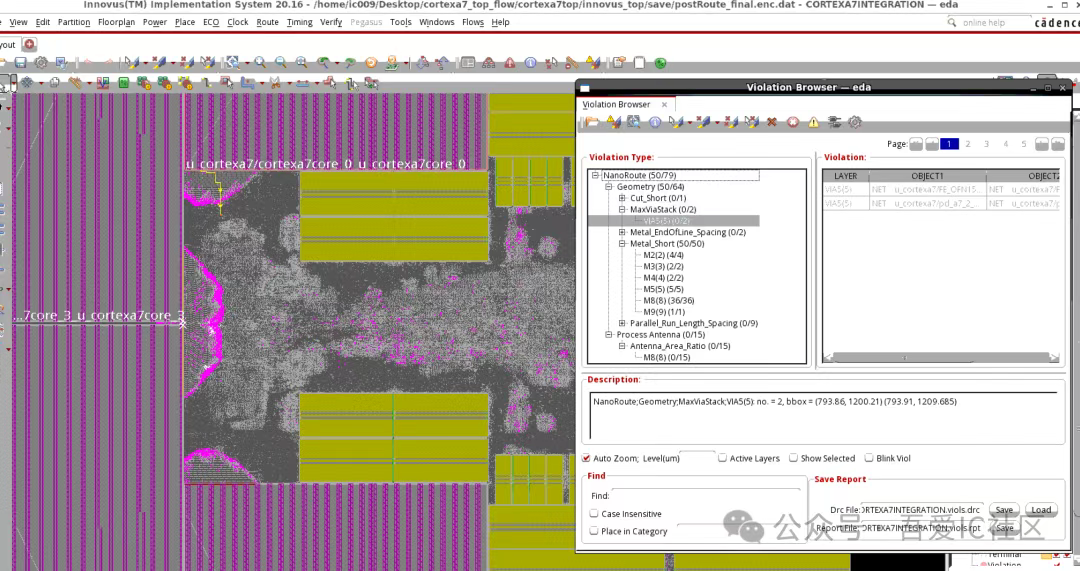
通過DRC Violation定位,我們發現主要short集中在cpu2和cpu3附近。低層的M2-M5 Short Violation是因為該學員在擺放子模塊兩個power switch cell串鏈信號時使用了M1出pin,而子模塊身上是蓋了M1-M6的routing blockage。
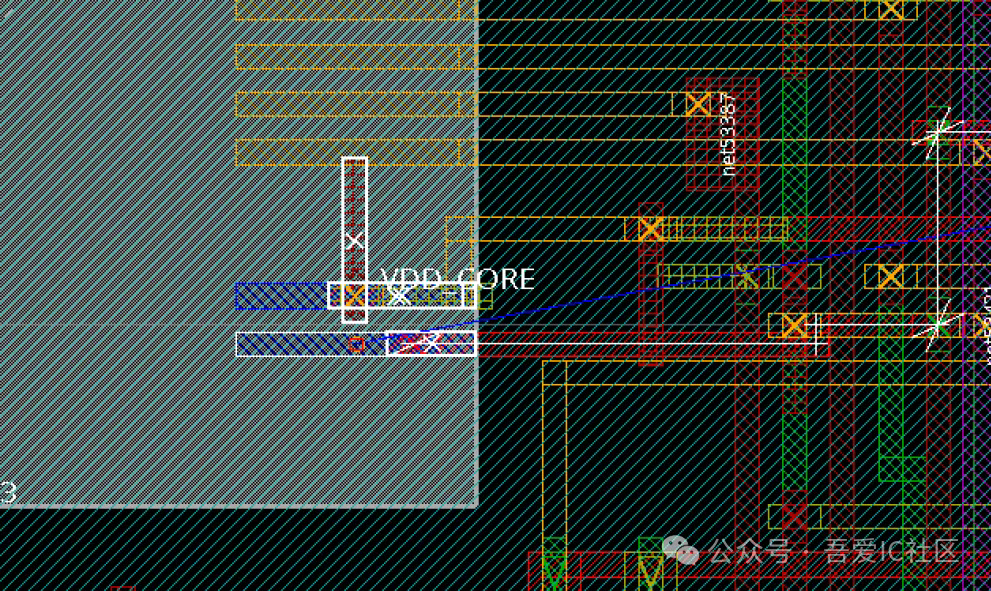
所以低層的short可以通過調整子模塊這兩個io port的出pin layer(使用橫向的Metal6即可)。值得注意的是子模塊cortexa7core_1 改完io port位置后務必更新一個最新的lef給a7top,否則后續會出現open net的情況。
其他short主要位于以下紅色框框區域。通過高亮可以發現這里的確存在異常——局部區域的cell density高達92%!
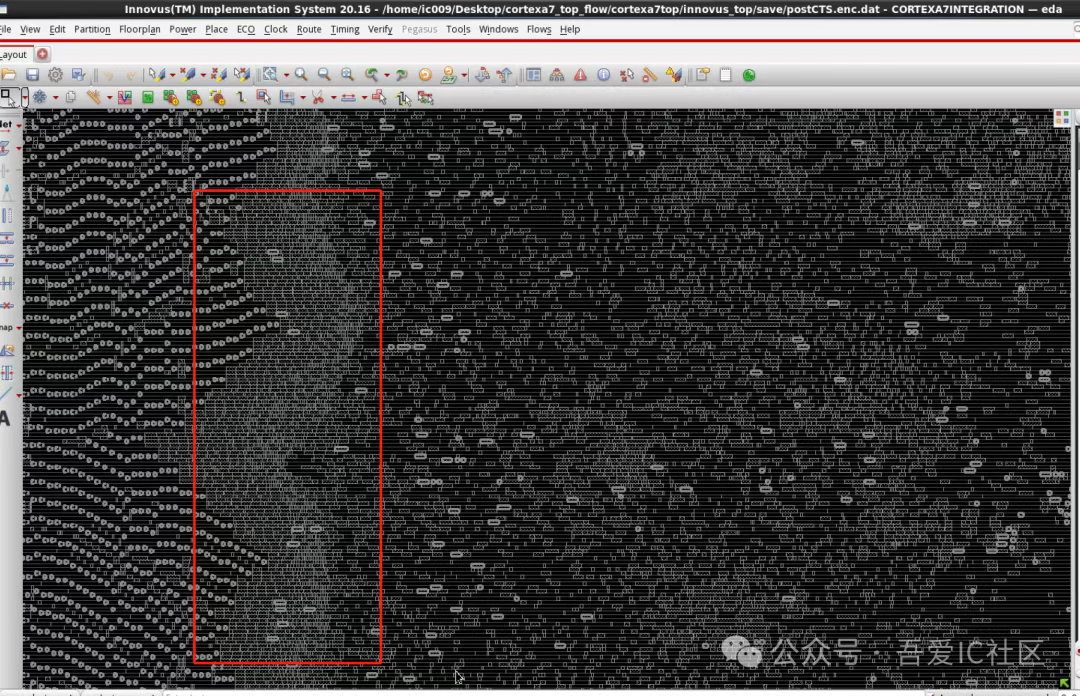
看到這里第一反應就是查看這個位置是否有region這種physical constraint。這里需要切換到floorplan view查看。因為某個module region規劃得太小也很容易出現這種現象。
數字IC后端教程之Innovus hold violation幾大典型問題

經過分析發現,該學員并沒有在這個位置加region。
這時候我們就要分析為何工具在這個位置擺放了這么多cell?
這些cell是什么階段加入的,加入的動機是什么?任何選中一顆cell后,我們可以報報看through這顆cell的timing path。
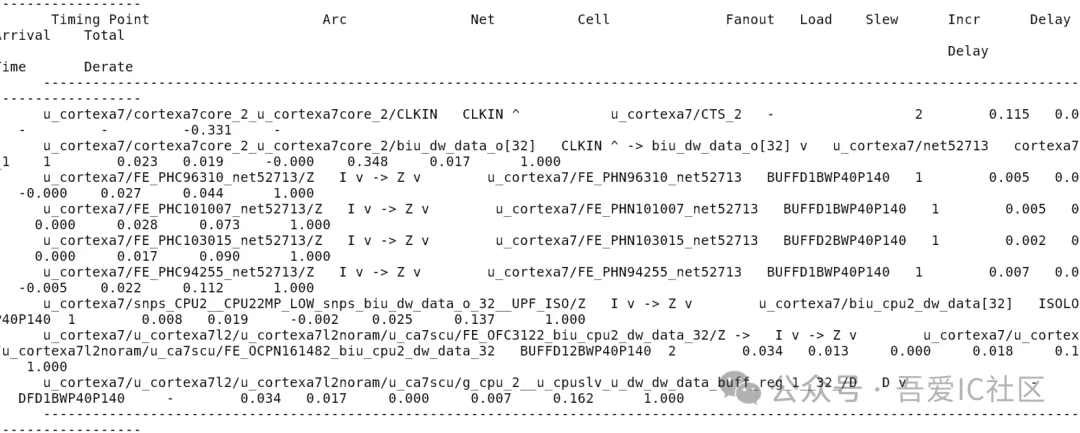
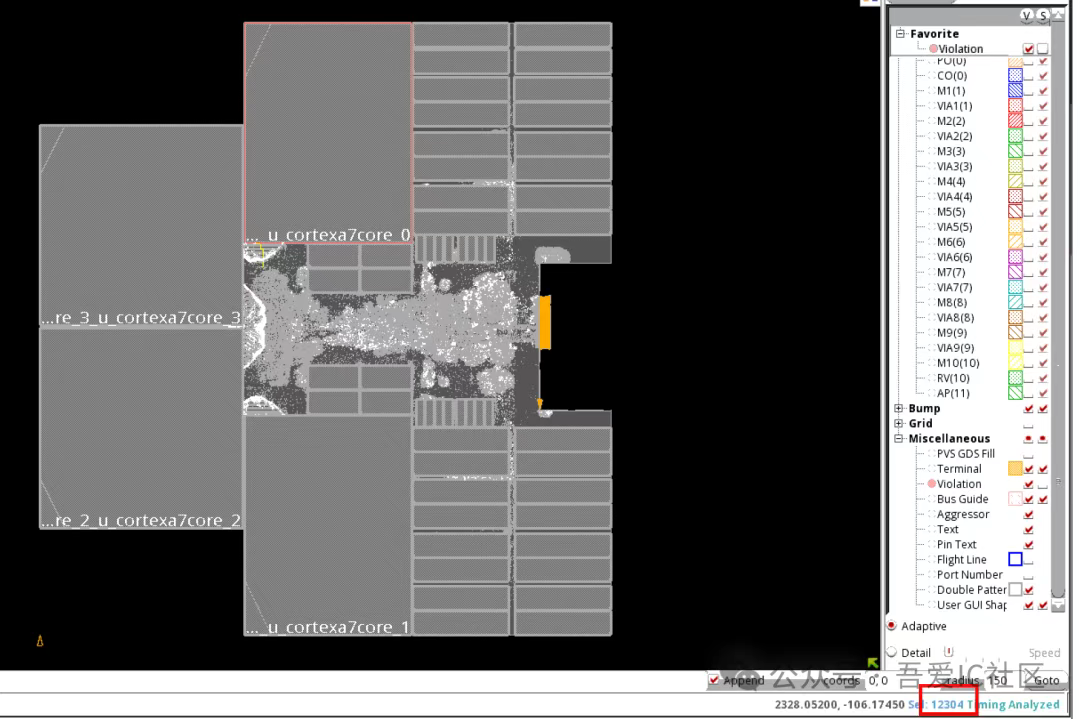
從這條timing path上看,我們就發現該區域存在大量PHC的buffer。從名字上看我們就知道這是工具修hold violation加入的。而且是為了修從cpu出發到頂層reg的hold violation而加入的。為了查看這個區域插入的hold buffer數量,我們可以在innovus中高亮出所有hold buffer(當然也可以通過dbQuery來獲取指定區域的hold buffer)。從innovus顯示的數據看,當前設計工具共插入了12304個hold buffer。
另外,我們還發現工具居然在子模塊的output pin和isolation的I pin中間插了buffer! 也就是說即便要插hold buffer也不能插在當前這個位置。出現這個現象只有一個原因!a7top PR實現階段使用的upf沒有成功讀入。
經過debug發現,該學員在跑placement時執行了free_power_intent命令!
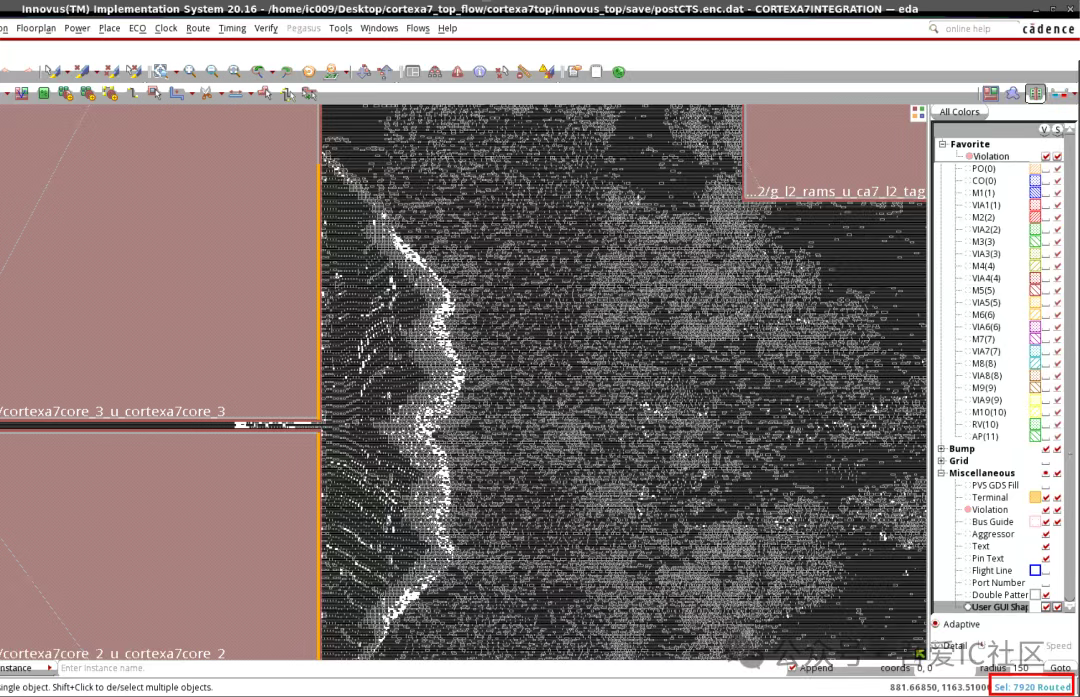
為了對比不同階段的hold buffer插入情況,我們又打開postCTS的數據,我們發現這個階段做完hold violation fixing后總插入的hold buffer數量是7920個!
【思考題】為何兩個階段插入的hold buffer數量有個突變呢?
由于咱們提供的后端flow是在postCTS修hold之前會保存一個單獨的database,所以我們此時可以打開修hold violation之前的hold情況。
經過分析發現的確存在FROM_CPU的hold violation,數值還比較大,而且TO_CPU的hold WNS都是大于0的!這是不是說明FROM_CPU和TO_CPU的timing往一邊飄?是否有機會通過調整各個子模塊的clock tree長度來優化呢?
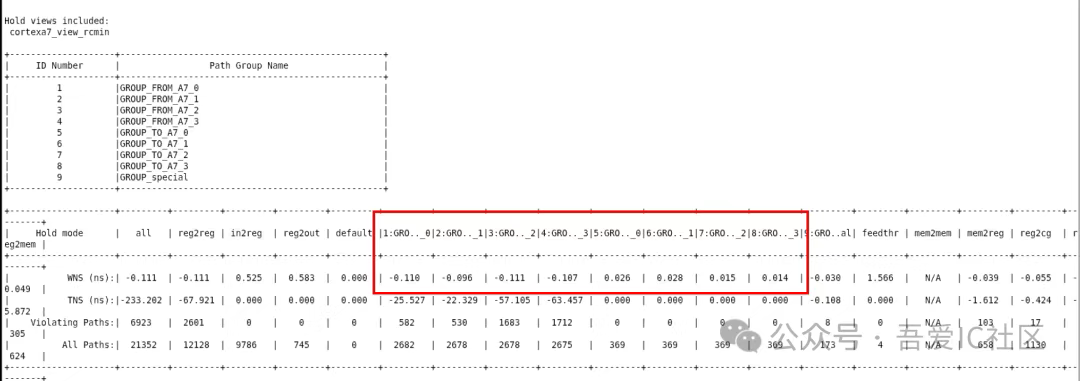
所以,遇到這類情況,我們主要可以通過以下幾種方法來修復。
1)調整clock tree,把頂層reg和子模塊reg的clock tree做balance
2)PR Flow中控制CPU接口相關的hold violation fixing的范圍,不要過修
3)在各個cpu子模塊門口添加blockage array陣列(降低local density)
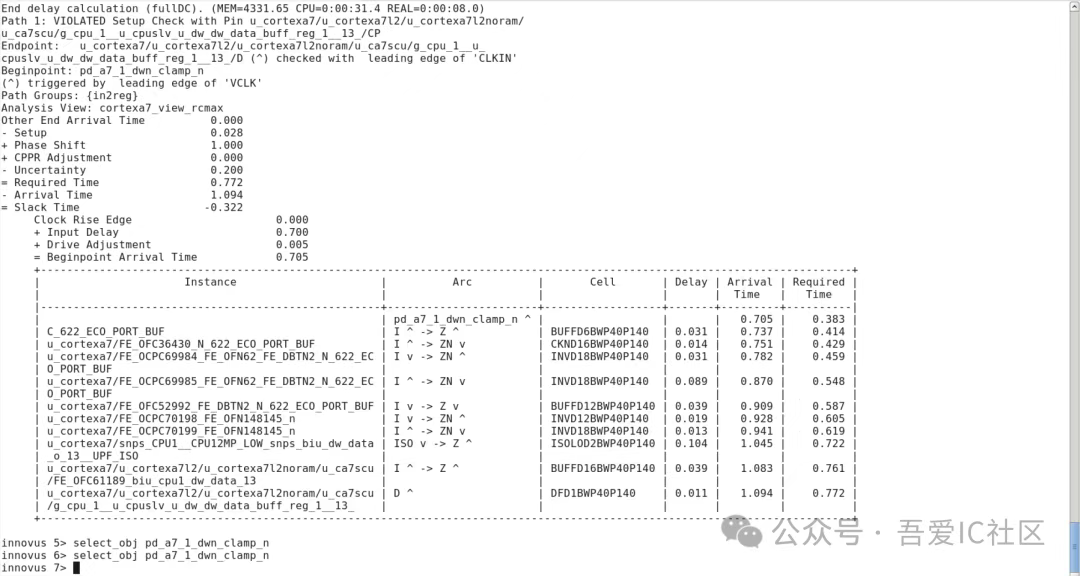
最后,小編還發現如下這類timing path也存在過渡優化的情況!這類timing path完全可以設置multicycle path!
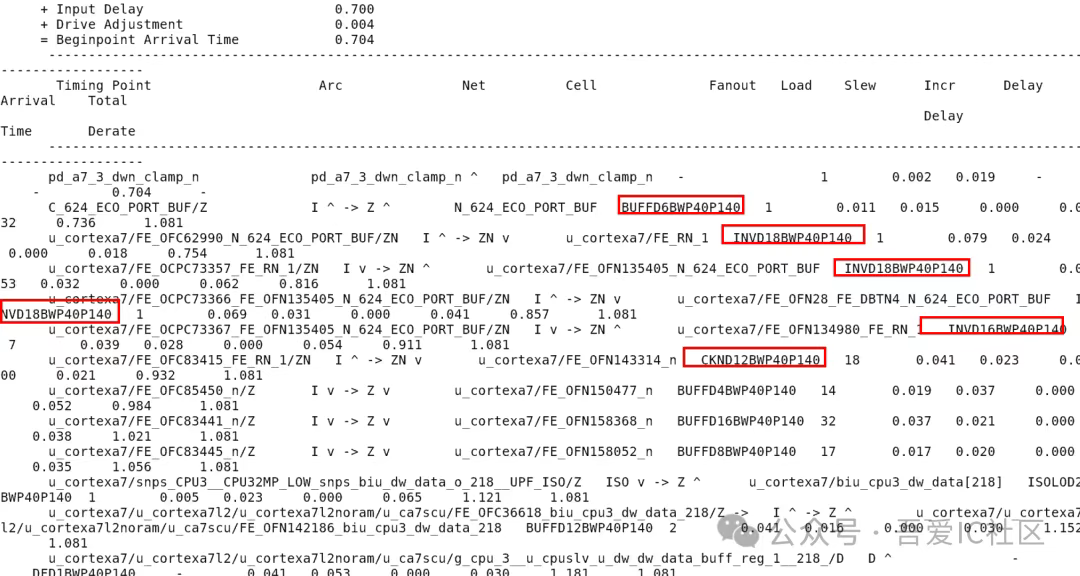
【思考題】在跑完placement后我們會檢查isolation cell的input是否有被插入buffer或inverter,請問下圖所示的路徑是否正常?該學員反饋這類timing path存在異常,請問對嗎?
)










![[手寫系列]Go手寫db — — 完整教程](http://pic.xiahunao.cn/[手寫系列]Go手寫db — — 完整教程)
)

)




