在將虛擬地址映射到段的一部分之前,視頻內存管理器調用顯示微型端口驅動程序的 DxgkDdiAcquireSwizzlingRange 函數,以便驅動程序可以設置用于訪問可能重排的分配位的光圈。 驅動程序既不能將偏移量更改為訪問分配的 PCI 光圈,也不能更改分配在光圈中占用的空間量。 例如,如果驅動程序無法在給定這些約束 (的情況下使分配 CPU 可訪問,則硬件可能耗盡) 不顯眼的光圈,則視頻內存管理器會將分配逐出到系統內存,并允許應用程序訪問其中的位。
如果在用戶模式顯示驅動程序調用 pfnLockCb 函數以請求直接訪問內存時,以前創建的分配的內容位于系統內存中,則視頻內存管理器會將系統內存緩沖區返回到用戶模式顯示驅動程序,并且顯示微型端口驅動程序不涉及訪問分配。 因此,顯示微型端口驅動程序不會修改分配的內容,并且保持為未重排格式。 這意味著,當從視頻內存中逐出 CPU 可訪問的分配時,顯示微型端口驅動程序必須取消重排分配,以便應用程序可以直接訪問生成的系統內存位。
如果逐出與當前映射用于直接應用程序訪問的分配關聯的 GPU 資源,則分配的內容將傳輸到系統內存,以便應用程序可以繼續訪問同一虛擬地址但不同的物理介質上的內容。 為了設置傳輸,視頻內存管理器調用顯示微型端口驅動程序的 DxgkDdiBuildPagingBuffer 函數來創建分頁緩沖區,GPU 計劃程序調用驅動程序的 DxgkDdiSubmitCommand 函數將分頁緩沖區排隊到 GPU 執行單元。 特定于硬件的傳輸命令位于分頁緩沖區中。 有關詳細信息,請參閱 提交命令緩沖區。 視頻內存管理器可確保視頻到系統內存的轉換對應用程序不可見。 但是,驅動程序必須確保通過 PCI 光圈對分配的字節排序與逐出分配時分配的字節順序完全匹配。
對于光圈空間段,分配的基礎位已位于系統內存中,因此無需傳輸 (逐出過程中取消重排) 數據。 因此,如果應用程序直接訪問位于光圈空間段中的 CPU 可訪問分配,則無法重排該分配。
如果某個表面可由應用程序直接通過 CPU 訪問,但將在光圈空間段中重排,則顯示驅動程序應將圖面實現為兩個不同的分配。 當用戶模式顯示驅動程序創建此類圖面時,它可以調用 pfnAllocateCb 函數,并將 D3DDDICB_ALLOCATE 結構的 NumAllocations 成員設置為 2,并將 D3DDDICB_ALLOCATE 的pAllocationInfo 數組中D3DDDI_ALLOCATIONINFO結構的 pPrivateDriverData 成員設置為指向有關分配 (的私有數據,例如其重排格式和未重排格式) 。 GPU 將使用的分配包含重排格式的位,應用程序將訪問的分配包含未重排格式的位。 視頻內存管理器調用顯示微型端口驅動程序的 DxgkDdiCreateAllocation 函數來創建分配。 對于從用戶模式顯示驅動程序傳遞的每個分配) ,顯示微型端口驅動程序解釋DXGK_ALLOCATIONINFO結構的 pPrivateDriverData 成員中的專用數據 (。 視頻內存管理器不知道分配的格式;它只是為分配分配分配特定大小和對齊方式的內存塊。 調用用戶模式顯示驅動程序的 Lock 函數以鎖定圖面進行處理會導致以下操作:
- 用戶模式顯示驅動程序調用 pfnRenderCb 函數,將命令緩沖區中的取消重排操作提交到 Direct3D 運行時和顯示微型端口驅動程序。
- 用戶模式顯示驅動程序調用 pfnLockCb 函數來鎖定未重排的分配。 請注意,用戶模式顯示驅動程序不得在 D3DDDICB_LOCK 結構的 Flags 成員中設置D3DDDILOCKCB_DONOTWAIT標志。
- pfnLockCb 函數將等待傳輸 (在分配之間展開) 。
- pfnLockCb 函數請求顯示微型端口驅動程序獲取未重排分配的虛擬地址,并將虛擬地址返回到 D3DDDICB_LOCKpData 成員中的用戶模式顯示驅動程序。
- 用戶模式顯示驅動程序將未重排分配的虛擬地址返回到 D3DDDIARG_LOCK 的 pSurfData 成員中的應用程序。
?下圖演示了如何將虛擬地址映射到線性光圈空間段的基礎頁面。
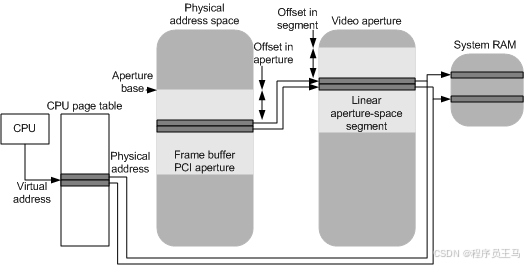
1. 重排分配與 CPU 訪問的沖突
問題背景:
某些圖形分配(如紋理)可能被硬件“重排”(swizzled)以優化 GPU 訪問性能,但這種格式對 CPU 不友好。如果應用程序需要直接通過 CPU 訪問這些分配(如 Lock 操作),則需要取消重排(unswizzle)。
約束條件:
- 顯示微型端口驅動程序(Display Miniport Driver)在 DxgkDdiAcquireSwizzlingRange 中不能修改 PCI 光圈的偏移或大小。
- 若硬件無法滿足 CPU 訪問的約束(如光圈空間不足),視頻內存管理器(VidMM)會將分配逐出(evict)到系統內存,并取消重排。
2. 系統內存中的分配訪問
直接訪問系統內存:如果分配已被逐出到系統內存,用戶模式顯示驅動(UMD)通過 pfnLockCb 直接獲取系統內存指針,微型端口驅動不參與,內容保持未重排格式。
關鍵要求:在逐出時,驅動程序必須確保取消重排,使系統內存中的數據是 CPU 可讀的線性格式。
3. GPU 資源逐出與分頁機制
動態逐出處理:
若 GPU 正在使用的分配被逐出(如因內存壓力),VidMM 會通過以下步驟透明遷移數據:
- 調用 DxgkDdiBuildPagingBuffer 創建分頁緩沖區(包含硬件特定的傳輸命令)。
- 通過 DxgkDdiSubmitCommand 提交到 GPU 執行。
- 確保遷移對應用程序透明(虛擬地址不變,物理介質變化)。
數據一致性:驅動程序必須保證 PCI 光圈中的字節順序與逐出時的系統內存完全一致。
4. 光圈空間段的特殊處理
無重排需求:光圈空間段(Aperture Segment)的分配本身位于系統內存,無需重排。若應用程序直接訪問此類分配,驅動程序必須禁止重排。
5. 雙分配策略(重排與非重排共存)
適用場景:
若一個表面需要同時滿足:
- GPU 訪問(重排格式優化性能)。
- CPU 訪問(未重排格式保證兼容性)。
實現方式:
- UMD 調用 pfnAllocateCb 創建 兩個分配(NumAllocations=2),分別存儲重排和未重排數據。
- 通過 pPrivateDriverData 傳遞格式信息(如重排參數)。
- 微型端口驅動在 DxgkDdiCreateAllocation 中解析私有數據,管理兩種格式。
Lock 操作流程:
- UMD 提交命令緩沖區(pfnRenderCb)取消重排(GPU 執行格式轉換)。
- 調用 pfnLockCb 鎖定未重排的分配(等待轉換完成)。
- 返回未重排分配的虛擬地址給應用程序。
六、關鍵驅動責任
- 格式轉換:在逐出或 Lock 時,確保重排數據轉換為線性格式。
- 雙分配管理:維護重排/未重排副本的一致性(如通過 GPU 命令同步)。
- 透明性:確保應用程序無感知(虛擬地址不變,物理介質可能變化)。
總結
這段描述揭示了 WDDM 如何平衡 GPU 性能(重排)與 CPU 可訪問性,通過動態逐出、分頁緩沖區、雙分配等機制實現高效內存管理。驅動程序需正確處理重排/取消重排、分頁操作及多副本同步,以滿足圖形和計算應用的多樣化需求。










![[手寫系列]Go手寫db — — 完整教程](http://pic.xiahunao.cn/[手寫系列]Go手寫db — — 完整教程)
)

)





![[Windows] 網絡檢測工具InternetTest v8.8.2.2503 單文件版_支持查詢IP_DNS_WIFI密碼一鍵恢復](http://pic.xiahunao.cn/[Windows] 網絡檢測工具InternetTest v8.8.2.2503 單文件版_支持查詢IP_DNS_WIFI密碼一鍵恢復)