在機器學習實戰中——是否需要歸一化(Normalization)或標準化(Standardization),取決于所使用的模型類型。
? LightGBM / XGBoost 是否需要歸一化或標準化?
不需要。
🔧 原因:
LightGBM 和 XGBoost 都是 基于決策樹的模型,它們對特征的數值分布不敏感:
- 決策樹只關心特征的相對大小和分裂點,而不是絕對數值或分布形態。
- 不存在權重乘以特征的問題,所以不需要歸一化或標準化。
?歸一化和標準化是什么,有什么區別?
| 方法 | 名稱 | 作用 | 公式 | 使用場景 |
|---|---|---|---|---|
| ? 歸一化 | Min-Max Normalization | 把數據壓縮到 [0,1] 范圍 | x' = (x - min) / (max - min) | 深度學習(如Keras) 或歐幾里得距離計算 |
| ? 標準化 | Z-score Standardization | 轉換為均值為0、方差為1的數據 | x' = (x - mean) / std | 線性回歸、SVM、KNN、神經網絡 |
🔍 舉個例子:
假設溫度范圍是 [60°C, 120°C],振動范圍是 [0.1, 10.0] mm/s
如果你用神經網絡,振動的數值對損失函數的影響將遠大于溫度 —— 所以需要歸一化/標準化。
而 LightGBM/XGBoost 會自動找到“哪個值做分裂點最好”,不會因為振動數值更大就更“重視”它。
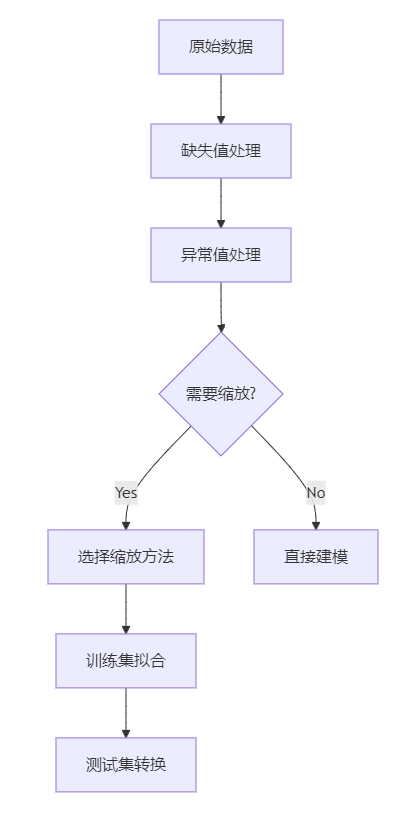
? 總結
| 問題 | 回答 |
|---|---|
| 是否需要對 LightGBM / XGBoost 做歸一化或標準化? | ? 不需要 |
| 是否建議你預處理? | ? 建議做缺失值處理,但不需要縮放 |
| 哪些模型必須做歸一化或標準化? | 神經網絡、KNN、SVM、線性模型等 |
如果未來使用 類似于Keras 的神經網絡模型(比如你前面提到的 CNN、LSTM),那就必須做歸一化或標準化。
在實際應用中,歸一化(Normalization)和標準化(Standardization)通常只選一個,其實我們不需要兩個都做,選擇哪一個取決于所用模型和數據分布。
? 選擇哪一個的判斷依據:
| 場景 | 推薦操作 | 原因 |
|---|---|---|
| 神經網絡(Keras, TensorFlow, PyTorch) | 🔹歸一化 或 🔹標準化都可,但選其一即可 | 網絡更穩定、收斂更快 |
| 數據近似服從正態分布 | ? 標準化 | 把數據壓成均值為0、標準差為1 |
| 數據在固定范圍內分布(如0-255圖像) | ? 歸一化 | 保持原分布特性,縮放到[0,1]或[-1,1] |
| KNN、SVM、線性模型 | ? 標準化更常見 | 對歐幾里得距離和梯度敏感 |
| 決策樹類模型(XGBoost、LightGBM) | ? 都不需要 | 樹模型對數據縮放不敏感 |
🔍 區別總結
| 操作 | 名稱 | 結果 | 應用常見于 |
|---|---|---|---|
x' = (x - min) / (max - min) | 歸一化 | 數據壓縮到 [0, 1] | 圖像像素、深度學習輸入 |
x' = (x - μ) / σ | 標準化 | 數據均值為0,標準差為1 | KNN/SVM/回歸/神經網絡 |
🧪 舉例代碼:
? 1. 標準化(Z-score):
from sklearn.preprocessing import StandardScalerscaler = StandardScaler()
X_scaled = scaler.fit_transform(X) # 用于訓練集 & 測試集
? 2. 歸一化(Min-Max):
from sklearn.preprocessing import MinMaxScalerscaler = MinMaxScaler()
X_scaled = scaler.fit_transform(X)
?? 注意:訓練集用
fit_transform,測試集用transform,不能重新fit!
? 最終結論:
| 問題 | 回答 |
|---|---|
| 是否需要同時做歸一化和標準化? | ? 不需要,只選其一 |
| 選哪個? | 神經網絡用歸一化或標準化都可以,推薦標準化更通用 |
| 樹模型要不要做? | ? 都不做,直接用原始數據即可 |



![[Windows] 網絡檢測工具InternetTest v8.8.2.2503 單文件版_支持查詢IP_DNS_WIFI密碼一鍵恢復](http://pic.xiahunao.cn/[Windows] 網絡檢測工具InternetTest v8.8.2.2503 單文件版_支持查詢IP_DNS_WIFI密碼一鍵恢復)




:API接口層介紹)




)





