數據庫系統概述:
1、記錄:計算機中表示和存儲數據的一種格式或方法。
2、數據庫(DataBase, DB):數據庫是長期儲存在計算機內、有組織、可共享的大量數據集合。可為各種用戶共享。
3、數據庫管理系統(DataBase Management System, DBMS):了解數據庫后,下一個問題則是如何科學地組織和存儲數據、獲取和維護數據。完成這一任務的則是一個系統軟件—數據庫管理系統。
(1)數據庫管理系統是位于用戶和操作系統之間的一層數據管理軟件,和操作系統一樣是計算機的基礎軟件。
(2)主要功能包括數據定義、數據組織,存儲和管理、數據操縱功能、數據庫的事務管理和運行管理、數據庫的建立和維護功能、其他功能。
4、數據庫系統(DataBase System, DBS):由數據庫、數據庫管理系統(及其應用開發工具)、應用程序和數據庫管理員組成的存儲、管理、處理和維護數據的系統。
5、數據管理技術經歷了人工管理、文件系統、數據庫系統三個階段
(1)人工管理階段:由用戶(程序員)自己管理數據,程序中要定義自己數據,工作量大,一次性,數據修改時,應用程序也要修改。(在大規模數據時更是幾乎不可能實現)
(2)文件系統階段:由文件系統管理數據,數據存放在硬件中,長期保存,但一個文件只對應一個應用程序,數據冗余度大,共享性差,文件數據結構變化時,應用程序中對文件的定義和數據的使用也要修改。
(3)數據庫階段:由專門的數據管理軟件,數據庫管理系統管理數據。聯機、分布式處理、多用戶、多應用共享數據。
6、數據庫底層是基于文件系統實現的,在其之上構建了一層抽象,依賴于文件系統管理底層存儲。
7、數據庫作用:
(1)簡化了應用程序,提高效率,程序員無需自己編寫復雜的數據操作在應用程序中,只需一條SQL語句。
(2)統一優化了數據存儲和提高數據查詢效率,一般程序員很難在應用程序中自行實現達到這么高效。
8、為什么定長記錄和邊長記錄要分在兩個文件?
(1)和查找效率、存儲效率、可行性等有關,定長可以直接(N-1)*100確定位置,偏移量計算簡單,變長的每條記錄長度不同。
(2)定長、變長也可以放在一起,但需要額外記錄每條記錄的邊界,且可能存儲碎片,浪費空間,文件結構也會變復雜,要額外機制區分定長和變長記錄。
9、文件系統中存取的單位是記錄。文件系統容易導致數據不一致性,由于數據重復存儲,可能有多個副本(因為沒有一個統一的軟件管理,每個應用可能都要在文件系統中存放數據?)。
10、數據模型是對現實世界數據的抽象,將具體事務抽象為計算機能處理的數據,用以描述數據、組織數據和對數據進行操作。
(1)將現實世界中的具體事務抽象、組織為數據模型,通常會先將現實世界抽象為信息世界,然后將信息世界轉換為機器世界。
(2)概念模型是現實世界到機器世界的一個中間層次。用于信息世界的建模。信息世界中的基本概念:
實體:客觀存在并可相互區別的事務
屬性:實體所具有的某一特性
碼:唯一標識實體的屬性集
實體型:用實體名及其屬性名集合來抽象和刻畫同類實體。
實體集:同一類型實體的集合
聯系:事物內部及事物間是有聯系的,在信息世界中反映為實體(型)內部的聯系和實體(型)之間的聯系。
11、關系模型
(1)最重要的一種數據模型。
(2)關系:一個關系通常對應一張表
(3)屬性:表中的一列。
(4)碼:也可稱碼鍵,表中的某個屬性組,可唯一確定一個元組,如圖中的學號可以唯一確定一個學生。
(5)域:具有相同數據類型的值的集合。屬性的取值來自某個域。如大學生年齡屬性的域是(15~45歲),性別的域是(男、女)
(6)分量:元組中的一個屬性值
(7)關系模型:對關系的描述,一般表示為:
?????? 關系名(屬性1,屬性2,…,屬性n)
例如,圖中關系可表示為:
?????? 學生(學號,姓名,年齡,性別,系名,年級)
關系模型的數據結構:

12、數據庫系統的三級模式
數據庫都采用三級模式
(1)模式:只是邏輯上的視圖
(2)外模式:數據庫用戶所能看到的數據視圖。每個用戶只能看到和訪問所對應外模式中的數據,數據庫中的其余數據是不可見的。是保證數據庫安全性的一個有力措施。
(3)內模式:也稱為存儲模型,是數據庫中數據的物理結構和存儲方式。
(4)使數據變化時,應用程序不用修改。減少了應用程序的編碼和復雜度,同時提高了數據存儲、讀取的效率。
13、數據庫系統對硬件的要求:
(1)內存大:足以存放操作系統、數據庫管理系統的核心模塊、數據緩沖區和應用程序。
(2)磁盤等存儲設備大:存放數據庫,有足夠大的磁帶作數據備份。
(3)數據通訊速度夠快:系統有較高的通道能力,以提高數據傳送率。
14、數據庫系統的主要軟件:
(1)數據庫管理系統:為數據庫建立、使用和維護配置。
(2)操作系統:支持數據庫管理系統運行
(3)開發語言、編譯系統(器):便于開發應用程序
(4)以數據庫管理系統為核心的應用開發工具:為數據庫系統開發和應用提供了良好環境。
(5)為特定應用環境開發的數據庫應用系統。
15、普通用戶可以用程序員實現設計好的簡單交互界面,替代數據庫操作指令(語言)。
關系數據庫
16、關系數據模型三要素:關系數據結構、操作集合、完整性約束
17、關系數據庫結構定義:
(1)元組:表中的一行關系
(2)候選碼:一個屬性能唯一標識一個元組
(3)主碼:多個候選碼時,選的一個關系模型屬性的集合結構,一般不變
(4)關系:不同屬性間的聯系,值,會由于關系操作不斷變化
18、關系數據庫系統只有“表”這一種數據結構,而非關系數據庫系統還有其他數據結構。
19、SQL是介于關系代數和關系演算之間的一種結構化查詢語言。
關系數據庫標準語言SQL
20、結構化查詢語言(Structured Query Language, SQL):是關系數據庫的標準語言,其功能包括查詢、數據庫模式創建、數據插入與修改、數據庫安全性完整性定義與控制等一系列功能。
21、SQL可在運行后隨時修改數據庫運行模式
22、模式:定義模式實際上定義了一個命名空間,在這個空間中可以進一步定義該模式該函的數據庫對象,例如基本表、視圖、索引等。
23、索引相當于加了一個標簽,將每個數據的標簽按某種規則放入一個存儲空間中,加快檢索。
24、數據字典:(1)關系數據庫管理系統內部的一組系統表,記錄了數據庫中所有的定義信息,包括關系模式定義、視圖定義、索引定義、完整性約束定義、各類用戶對數據的操作權限、統計信息等。
(2)關系數據庫在執行SQL的數據定義語句時,就是在更新數據字典表中的相應信息。
26、視圖:(1)是從基本表中導出的表(虛表),實際不存在,類似一個窗口,從數據庫中看到自己感興趣的數據。基本表中數據的變化會令其也隨之變化。
(2)對視圖的更新,最終要轉為對基本表的更新
(3)視圖可以讓數據庫邏輯結構改變時,應用程序不必去修改(但也只能一定程度上,應用程序仍可能會因基本表結構的改變而需要做相應修改)。
27、數據庫完整性:數據的正確性和相容性。
(1)正確性:數據是符合現實世界語義、反應當前實際狀況的
(2)相容性:數據庫同一對象在不同關系表中數據是符合邏輯的。
(3)數據的完整性:防止數據庫中存在不符合語義的數據
(4)數據的安全性:保護數據庫防止惡意破壞和非法存取。
28、每次插入記錄或對主碼列更新時,都要進行檢查。檢查都要掃描,而全表掃描時,一般通過索引,如B+樹來查找。
29、嵌入式SQL:是將SQL語句嵌入程序設計語言(C、C++、Java等)中,被嵌入的語言稱為宿主語言(主語言)。
數據庫恢復技術
30、事務:用戶定義的一個數據庫操作序列,要么全做,要么全不做,是不可分割的工作單位。(關系數據庫中,事務是一條SQL語句、一組SQL語句或整個程序)
31、數據恢復的關鍵是建立冗余數據,最常用的技術是數據轉儲和登記日志文件,通常這兩個方法會一起配合使用。
32、數據轉儲:定期將整個數據庫復制到磁帶、磁盤或其他存儲介質保存(即后備副本)。
(1)靜態轉儲:系統中無運行事務時的轉儲操作,轉儲期間不允許任何對數據庫的操作。
(2)動態轉儲:轉儲和用戶事務可以并發執行,但無法保證數據的正確有效,如剛將A=100轉儲到磁帶上,下一時刻其他事務又將A改為200,轉儲結束時A已是過時的數據。為此需建立日志文件,將轉儲期間各事務對數據庫的修改活動登記下來。
31、日志文件:記錄事務對數據庫的更新操作。
利用日志文件恢復:

32、登記日志文件的原則:
(1)登記的次序嚴格按并發事務執行的時間次序。
(2)必須先寫日志文件,后寫數據庫。
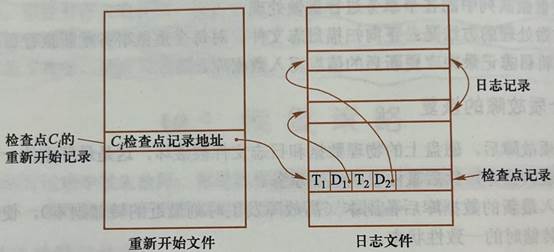
33、檢查點記錄:增加了一個重新開始文件,用以記錄各個檢查點記錄在日志文件中的地址。使用檢查點可以避免檢查點之前已經修改數據庫的事務重做操作
檢查點記錄內容:(1)建立檢查點時刻所有正在執行的事務清單(2)這些事務最近一個日志記錄的地址。
作用(1)避免數據庫恢復時要搜索所有日志記錄(2)避免更新操作已經完成的事務在恢復子系統中再次執行。
重新開始文件和具有檢查點的日志文件。
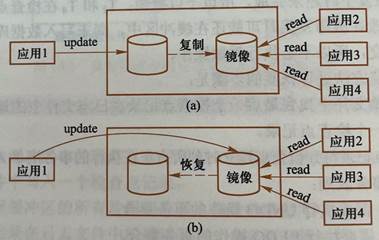
34、數據庫鏡像:
自動將整個數據庫或其中的關鍵數據復制到另一個磁盤上,數據庫更新時,自動將更新后的數據復制過去。
(1)介質故障時,可由鏡像數據庫繼續提供使用
(2)未出現故障時,數據庫鏡像還可用于并發操作,即一個用戶對數據加排他鎖時,其他用戶可以繼續讀鏡像數據庫上的數據,不必等待該用戶釋放鎖。
數據庫鏡像:
并發控制
35、事務是并發控制的基本單位
36、并發操作會導致數據的不一致性,包括:
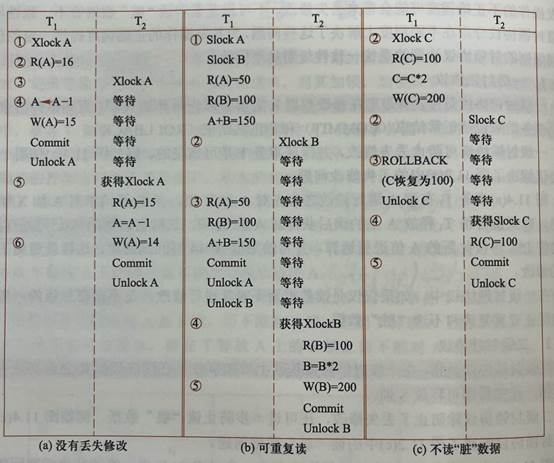
(1)丟失修改:兩個事務T1和T2讀入同一數據(同時)并修改,T2的提交破壞了T1提交的結果,使其丟失。如A=16,T1中A=16-1=15;T2中A=16-3=13。
(2)不可重復讀:T1讀取后,T2對其修改,使T1無法再次讀取到與前次相同的值。如:T1中,A=50,B=100,第一次求和=150,接著T2中B=200,T1再次求和=250,驗算不對。
(3)讀“臟”數據:T1修改數據并寫回磁盤,T2讀取相同數據,隨后T1被撤銷,此時T2讀取的數據就為“臟”,即不正確的數據。
如:A=100,T1中A=A*2=200,T2中讀A=200,T1撤銷,數據庫中A實際值變回100。

37、并發控制:使用調度方式,使用戶事務的執行不受其他事務影響。主要技術有封鎖(locking)、時間戳(timestamp)、樂觀控制法(optimistic)和多版本并發控制(multi-version concurrency control, MVCC)。
38、封鎖:排他鎖(X鎖)又稱為寫鎖。共享鎖(S鎖)又稱為讀鎖。
(1)一級封鎖協議:事務T在修改數據R前須先加X鎖,事務結束時才釋放。可解決丟失修改問題。
(2)二級封鎖協議:在一級的基礎上增加T在讀數據R前須先加S鎖,讀完后即可釋放。防止了丟失修改,并進一步解決讀“臟”數據問題。
(3)三級封鎖協議,在一級的基礎上增加T在讀數據R前須先加S鎖,事務結束時才釋放。可解決不可重復讀在內的三種數據不一致情況。
39、活鎖:T1封鎖數據R,期間T2請求封鎖R,T3又請求封鎖R,然而系統首先批準了T3的請求,此時T4又請求封鎖R,T3解除后又批準了T4的請求,以此類推,T2可能永遠等待。
40、死鎖:T1鎖R1又請求R2,T2鎖R2又請求R1,互相一直等待。
41、若多個事務的并發執行是正確的,當且僅當其結果與按某一次串行執行事務時的結果相同,該調度策略稱為可串行化。
42、兩段鎖協議可實現并發調度的可串行性(可串行化)。
(1)所有事務在對任何數據讀、寫操作前,要先申請并獲取該數據的封鎖(可以申請任何鎖,但不能釋放)。
(2)釋放一個封鎖之后,事務不再申請和獲得任務其他封鎖(可以釋放任何鎖,但不能申請)。
43、時間戳:給每個事務蓋上一個時標,若發生沖突,則回滾較早時間戳的事務。
44、樂觀控制法:認為事務執行時很少發生沖突,事務提交前才進行檢查。若發現事務中出現沖突,則拒絕提交并回滾該事務。
45、多版本并發控制:
(1)版本:數據庫中數據對象的一個快照,記錄了數據對象某個時刻的狀態。
(2)數據對象A有T1寫和T2讀兩個事務。執行時,T2無需等待T1,而是在新生成版本的A‘上執行,提交時再檢查T1是否已完成。
數據庫管理系統
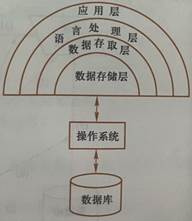
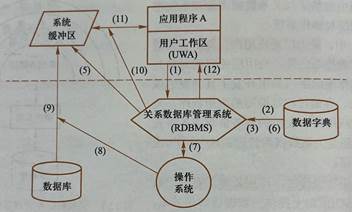
46、關系數據庫管理系統的層次結構:
(1)應用層(2)語言處理層,如SQL(3)數據存取層(4)數據存儲層(5)操作系統,保證數據庫管理系統對數據的讀寫真實映射到物理文件上。(6)數據庫
47、關系數據庫管理系統運行過程:
(1)用戶通過應用程序發出命令,如SELECT。
(2)RDBMS對命令進行語法檢查、語義檢查,用戶權限檢查。
(3)RDBMS進行查詢優化。優化器根據數據字典中的信息進行優化,將命令轉換為一串單記錄的存儲操作序列。
(4)RDBMS執行存取操作序列。
(5)RDBMS首先在緩沖區查找,若找到則轉(10),否則轉(6)
(6)RDBMS查看存儲模式,選擇從哪個文件、方式讀取哪個物理記錄。
(7)根據(6)的結果向操作系統發出讀取記錄的命令
(8)操作系統執行讀操作
(9)操作系統將數據從數據庫的存儲區送至系統緩沖區。
(10)RDBMS根據查詢命令和數據字典導出用戶所要讀取的記錄格式。
(11)RDBMS將數據記錄從系統緩沖區送至應用程序的用戶工作區。
(12)RDBMS返回執行狀態信息,如成功讀取或不超過的錯誤提示、例外狀態信息等。
動作(1)屬于應用層。動作(2)、(3)屬于語言處理層。動作(4)、(10)、(11)、(12)屬于數據存取層。動作(5)、(6)、(7)屬于數據存儲層。動作(8)、(9)由操作系統執行。
48、語言處理層:將數據庫語言轉為可執行的基本存取模塊的調用序列。數據庫語言包括數據定義語言、數據操縱語言和數據控制語言三部分。
49、關系數據庫管理系統中數據字典采用和普通數據同樣的關系表(table)來表示。

50、預編譯方法:基本思想是指在用戶提交數據操縱語句后,在運行前對它進行翻譯處理,保存產生好的可執行代碼。當需要運行時,去除保存的可執行代碼加以執行。
51、數據存取層:主要數據結構為邏輯數據記錄、邏輯塊、邏輯存取路徑(不涉及物理存儲形式,只在邏輯結構上操作)。主要任務包括:
(1)提供查找、插入、刪除、修改等基本操縱。
(2)提供存取路徑及對存取路徑的維護,如索引記錄的查找、插入、刪除、修改,若索引是B+樹,則提供B+樹的建立、查找、插入、刪除、修改等功能。
(3)對記錄和存取路徑的封鎖、解鎖操作。
(4)日志文件的登記和讀取操作。
(5)其他輔助操作,如掃描、合并/排序,其操作對象由關系、有序表、索引等。
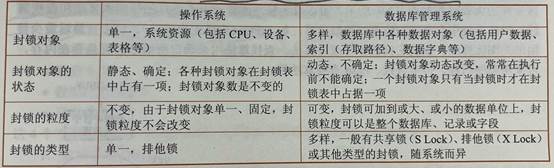
操作系統和數據庫管理系統封鎖技術比較:
52、數據存儲層:主要功能是存儲管理,包括緩沖區(buffer)管理、內外存交換、外存管理等。
(1)系統緩沖區可由內存和虛存組成。
(2)緩沖區管理調用的操作系統的操作有讀(READ)、寫(WRITE)。緩沖區管理會用到淘汰算法和查找算法,可借鑒操作系統中的淘汰算法,如FIFO(先進先出算法)、LRU(最近最少使用的先淘汰算法)。查找算法用以確定請求的頁是否在內存,有折半查找、hash查找算法等。
53、數據庫實現基礎是文件,對數據庫的任何操作最終都會轉化為對文件的操作。
54、數據庫系統是文件系統的發展。文件系統中的文件存儲的是同質實體數據,各文件間孤立,沒有體現實體間的聯系。數據庫系統中數據的物理組織必須體現實體之間的聯系,支持數據庫的邏輯結構—各種數據模型,則數據庫中要存儲下列4方面數:
(1)數據描述,即數據的外模式、模式、內模式
(2)數據本身
(3)數據之間的聯系
(4)存取路徑
55、分布式數據庫:由一組數據組成,這組數據分布在計算機網絡的不同計算機上,網絡中的每個結點具有獨立處理的能力,可以執行局部應用。同時,每個節點也能通過網絡通信系統執行全局應用。(即每個場地是獨立的數據庫系統,有自己的數據庫、用戶、服務器、DBMS,執行局部應用,具有高度自治性,同時各個場地的數據庫系統又相互協作組成一個整體。)
57、內存數據庫:即將內存作為主存儲設備的數據庫系統。
(1)內存數據庫的數據組織、存儲訪問模型和查詢處理模型都針對內存特性進行了優化設計,內存數據被處理器直接訪問。
(2)與內存訪問延遲密切相關的硬件是TLB(Translation Lookaside Buffer, 旁路緩沖,也稱為頁表緩沖)。TLB是硬件級緩存,類似CPU的cache,主要存放內存頁表。內存的頁表區中,記錄虛擬頁面和物理頁框對應關系的記錄稱為一個頁表條目(entry)。
(3)TLB中存放著一些頁表條目,CPU收到應用程序發來的虛擬地址后,會先到TLB中查找對應的頁表數據,若TLB中存放著所需的頁表,則稱為TLB命中(TLB hit)。接下來CPU會去查看TLB中頁表對應的物理內存地址中的數據是否已在一、二級緩存中,若不存在則為TLB miss,若不在則需去頁表區中尋址,將其映射關系更新到TLB中以備下次使用。由于TLB大小有限,一旦TLB miss查詢代價會很高,所以現代CPU架構都采用一些優化方法,如一開始同時在TLB和內存頁表去進行查詢,而不是在TLB miss后才啟動內存頁表查詢;使用多級TLB以及軟TLB,在CPU內容切換(context switch)時不清空(flush)TLB。
56、計算機系統中存在著兩類不同的數據處理工作:操作型處理和分析型處理,也稱作聯機事務處理(OLTP)和聯機分析處理(OLAP)。
(1)操作型處理:也稱作事務處理,通常是對一個或一組記錄的查詢和修改的數據庫日常操作,如火車售票系統、銀行系統、稅務征收管理系統。要求快速響應、安全性、完整性和事務吞吐量高。
(2)分析型處理:指對數據的查詢和分析操作,通常是對海量的歷史數據查詢和分析,如金融風險預測預警系統、證券故事違規分析系統等,訪問的數據量通常非常大,查詢和分析操作十分復雜。
的數據)

:從理論到實踐)
)







)


)




![[計算機網絡]數據鏈路層](http://pic.xiahunao.cn/[計算機網絡]數據鏈路層)